






数据结构
想要弄懂HashMap,我们就要先要了解它的数据结构,我们常见的数据结构以下几种:
数组结构,链表结构,哈希表结构。
数组结构的优势在于查找数据方便,插入数据难;
链表结构的优势在于插入数据方便,查找数据难,想要了解的话可以移步至我的上篇文章论双向链表;
而哈希表(hash表)结合了上面的优势,不管是查找数据还是插入数据都很方便,本质其实是数组+链表(红黑树)。
在jdk1.7之前呢hashmap都是数组+链表的结构,就是在hash表的节点中构建链表
jdk1.8后hash表的底层是数组+链表(红黑树)的结构,hash表在节点先构建链表结构,当链表的节点数大于8个后链表会转化为树状结构
hashmap底层逻辑
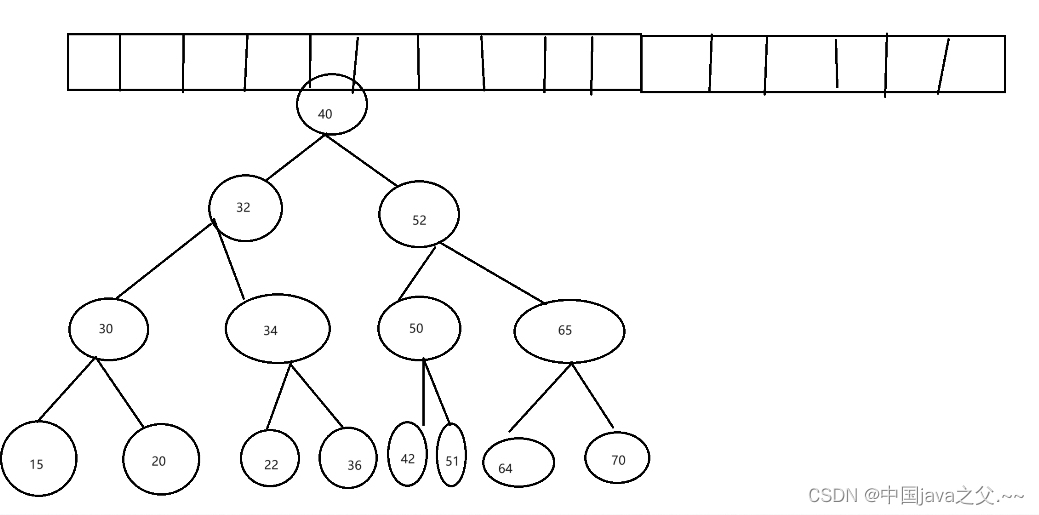
那我们主要说一下jdk1.8的hashmap(因为在节点个数到达8个前与jdk1.7一致),hashmap是通过键值对来存放数据的,具体如下:
hashmap首先通过hash算法计算键值对对应的二进制值(hash值),再将计算好的hash值对hash表的固定容量16取余来得出其下标(0~15),但是算出来的下标会出现一样的情况,所以下标第一个元素对应的就作为根节点,简单来说,如果其对应的节点为空,就作为根节点。如果元素下标相同时且节点上为非空,就链接在根节点下形成单向链表,直至链接的节点数超过及8(jdk1.7),再此之后就转变为树的结构,一般是根节点的左下节点键值对对应的hash值小于右下节点的hash值。
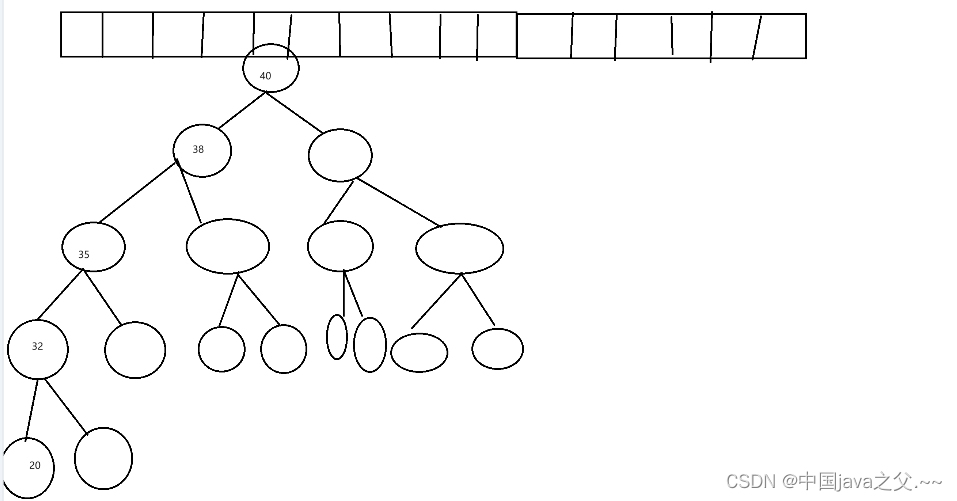
那在树的结构下,如果元素键值对所对应的hash值呈现由小到大(或由大到小),就是一节点的hash值永远比下一节点的hash值小,那还是会呈现链表的结构,导致频繁遍历,那么红黑树就出现了,通过左旋或右旋阻止其变为链表结构。(红黑树就不在过多阐述了感兴趣可以去了解一下。)
Hash冲突
其实上面以及提及,具体是根据key(键)即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经被占用了。
扩容机制
那我们在来说说默认容量16,其实是有1<<4(移位运算)得来,就是二进制的1000对应就是16。在实际开发过程中,我们需要存储的数据量往往是大于存储容器的大小,所以通常的做法就是扩容,在hashmap中不需要我们去手写其代码,当存储量超过阈值12时,就会自动触发扩容,阈值有一个计算公式:
阈值=扩容因子(默认值为0.75)*容量大小(默认容量16)
扩容的大小是原来的两倍,但是频繁的扩容会需要重新创建新的Hash表,在对数据进行迁移,对性能影响比较大。(扩容因子也叫负载因子)
扩容因子
ok,那为什么扩容因子是0.75呢?
扩容因子表示的是hash表中元素的填充程度,扩容因子的值越大,意味着触发扩容的元素个数会更多,hash冲突的概率就越高,反过来说如果扩容因子的值越小,hash冲突的概率就越小,但是对内容空间的浪费就变多了,扩容的频率也会增加,所以说需要hash冲突率与空间利用率的平衡,0.75这个值与统计学学里的泊松分布有关,上面说过,因为链表节点的阈值为8个,当扩容因子为0.75时,链表长度想要到达8的可以性几乎为0。
















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











