







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
执行 main 方法,得到如下结果:
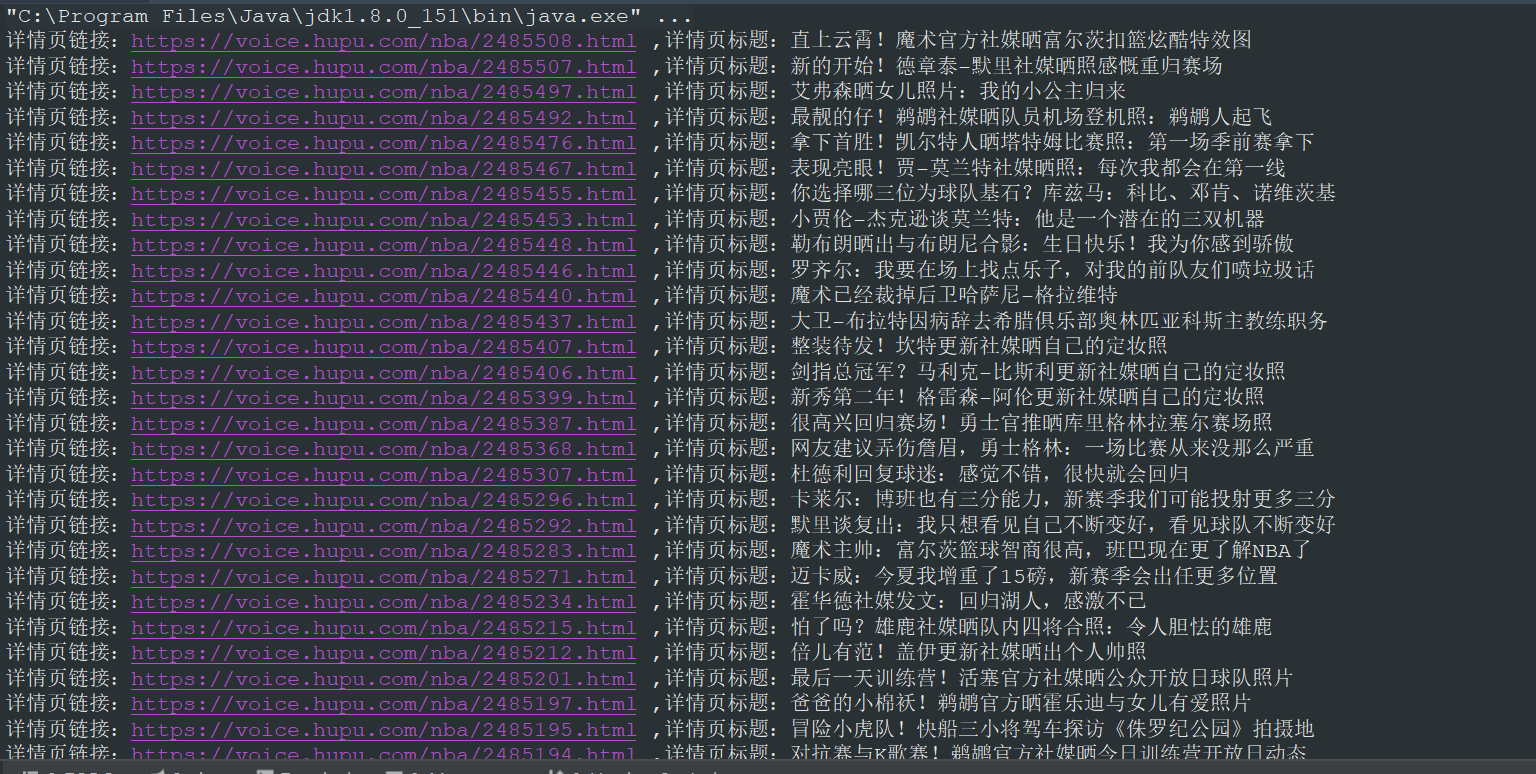
从结果中可以看出,我们已经正确的提取到了我们想要的信息,如果你想采集详情页的信息,只需要编写一个采集详情页的方法,在方法中提取详情页相应的节点信息,然后将列表页提取的链接传入提取详情页方法即可。
#### httpclient + 正则表达式
上面我们使用了 Jsoup 方式正确提取了虎扑列表新闻,接下来我们使用 httpclient + 正则表达式的方式来提取,看看使用这种方式又会涉及到哪些问题?httpclient + 正则表达式的方式涉及的知识点还是蛮多的,它涉及到了正则表达式、Java 正则表达式、httpclient。如果你还不知道这些知识,可以点击下方链接简单了解一下:
正则表达式:[正则表达式]( )
Java 正则表达式:[Java 正则表达式]( )
httpclient:[httpclient]( )
我们在 pom.xml 文件中,引入 httpclient 相关 Jar 包
关于虎扑列表新闻页面,我们在使用 Jsoup 方式的时候进行了简单的分析,这里我们就不在重复分析了。对于使用正则表达式方式提取,我们需要找到能够代表列表新闻的结构体,比如:`<div class="list-hd"> <h4> <a href="https://voice.hupu.com/nba/2485508.html" target="_blank">直上云霄!魔术官方社媒晒富尔茨扣篮炫酷特效图</a></h4></div>`这段结构体,每个列表新闻只有链接和标题不一样,其他的都一样,而且 `<div class="list-hd">`是列表新闻特有的。最好不要直接正则匹配 `a`标签,因为 `a`标签在其他地方也有,这样我们就还需要做其他的处理,增加我们的难度。现在我们了解了正则结构体的选择,我们一起来看看 httpclient + 正则表达式方式提取的代码:
/**
* httpclient + 正则表达式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void httpClientList(String url){
try {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity,“utf-8”);
if (body!=null) {
/\*
* 替换掉换行符、制表符、回车符,去掉这些符号,正则表示写起来更简单一些
* 只有空格符号和其他正常字体
*/
Pattern p = Pattern.compile(“\t|\r|\n”);
Matcher m = p.matcher(body);
body = m.replaceAll(“”);
/*
* 提取列表页的正则表达式
* 去除换行符之后的 li
*
*/
Pattern pattern = Pattern
.compile(“<div class=“list-hd”>\s*
\s* <a href=”(.*?)“\s* target=”_blank">(.*?)\s*
\s* " ); Matcher matcher = pattern.matcher(body);
// 匹配出所有符合正则表达式的数据
while (matcher.find()){
// String info = matcher.group(0);
// System.out.println(info);
// 提取出链接和标题
System.out.println(“详情页链接:”+matcher.group(1)+" ,详情页标题:"+matcher.group(2));
}
}else {
System.out.println(“处理失败!!!获取正文内容为空”);
}
} else {
System.out.println(“处理失败!!!返回状态码:” + response.getStatusLine().getStatusCode());
}
}catch (Exception e){
e.printStackTrace();
}
}
从代码的行数可以看出,比 Jsoup 方式要多不少,代码虽然多,但是整体来说比较简单,在上面方法中我做了一段特殊处理,我先替换了 httpclient 获取的字符串 body 中的换行符、制表符、回车符,因为这样处理,在编写正则表达式的时候能够减少一些额外的干扰。接下来我们修改 main 方法,运行 httpClientList 方法。
public static void main(String[] args) {
String url = “https://voice.hupu.com/nba”;
CrawlerBase crawlerBase = new CrawlerBase();
// crawlerBase.jsoupList(url);
crawlerBase.httpClientList(url);
}
运行结果如下图所示:
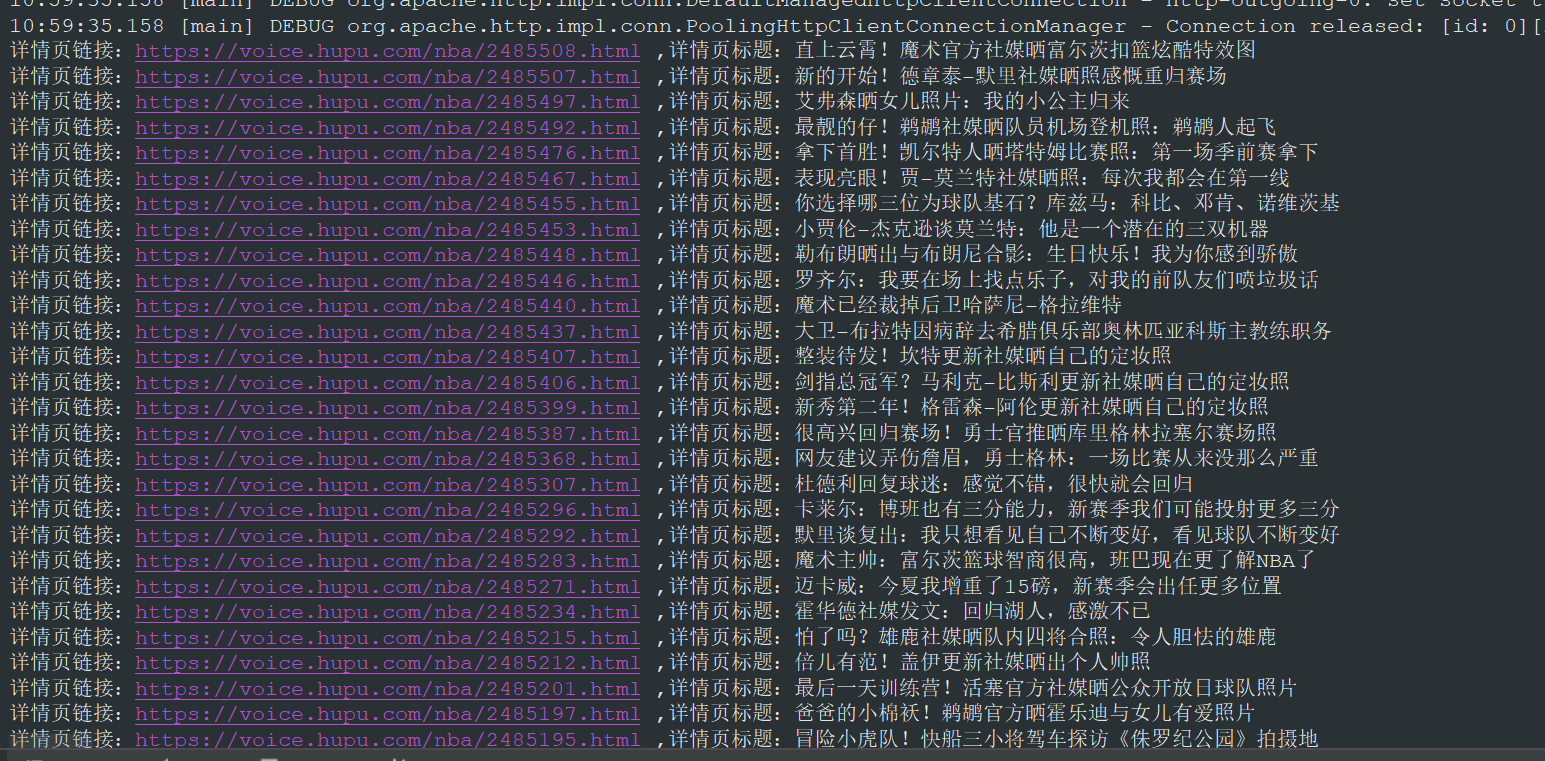
使用 httpclient + 正则表达式的方式同样正确的获取到了列表新闻的标题和详情页链接。到此 Java 爬虫系列博文第一篇就写完了,这一篇主要是 Java 网络爬虫的入门,我们使用了 jsoup 和 httpclient + 正则的方式提取了虎扑列表新闻的新闻标题和详情页链接。当然这里还有很多没有完成,比如采集详情页信息存入数据库等。
希望以上内容对你有所帮助,下一篇是模拟登陆相关的,如果你对 Java 网络爬虫感兴趣,不妨关注一波,一起学习,一起进步。
源代码:[点击这里]( )
>
> 文章不足之处,望大家多多指点,共同学习,共同进步
>
>
>
#### 最后
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
:vip204888 (备注大数据)**
[外链图片转存中...(img-NRaT4Cs1-1713299851341)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









