






1.项目简述
语音情感识别是利用计算机建立语音信息载体与情感度量之间的关系,并赋予计算机识别、理解人类情感的能力,语音情感识别在人机交互中起着重要作用,是人工智能领域重要发展方向。深度学习是基于深层神经网络的机器学习,目前在情感识别技术领域较传统算法已取得了显著的进步。本文简要叙述实现多模态情感分析系统的过程,主要包括mfcc特征提取,本地推理LSTM+CNN进行融合决策,注意力机制以及简单的交互界面。
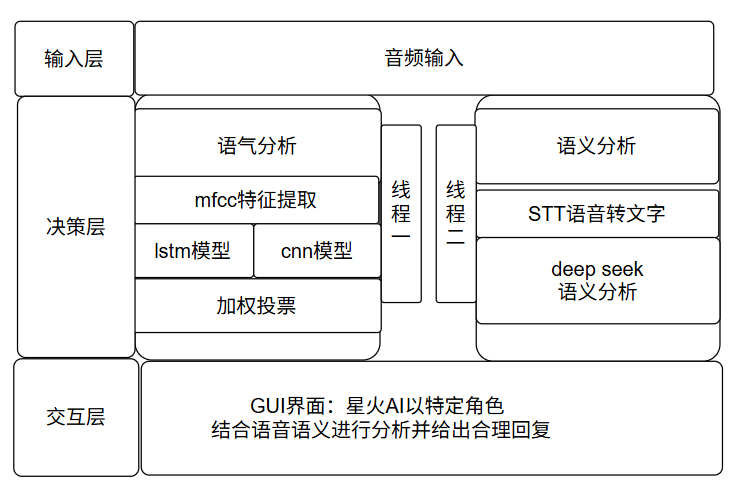
整体项目框架
2.语音数据集
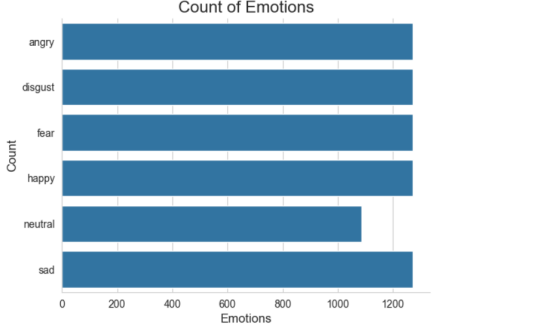
数据集介绍:采用CREMA-D数据集,CREMA-D是一个包含7,442个原始片段的数据集,这些片段来自91位演员。这些演员由48名男性和43名女性组成,年龄分布在20至74岁之间,涵盖多种族裔背景(包括非裔美国人、亚裔、白种人、西班牙裔和未指定族裔)。演员们从12种预设语句中进行朗读表达,每段语句均通过六种基本情感(愤怒、厌恶、恐惧、快乐、中性、悲伤)和四个情感强度等级(低、中、高、未指定)的组合进行呈现。六种基本情感的分布如图2.2所示。
训练过程数据集的划分见表1,其中90%的数据样本作为训练集,10%作为测试集,训练集中的20%样本作为验证数据
2.MFCC特征提取
传统声学特征主要包括韵律特征、谱特征以及音质特征。其中,韵律特征主要表现在语音抑扬顿挫,包括能量、基频、时长等相关特征。谱特征指发声运动中声道形状的变化引起的能量变化。
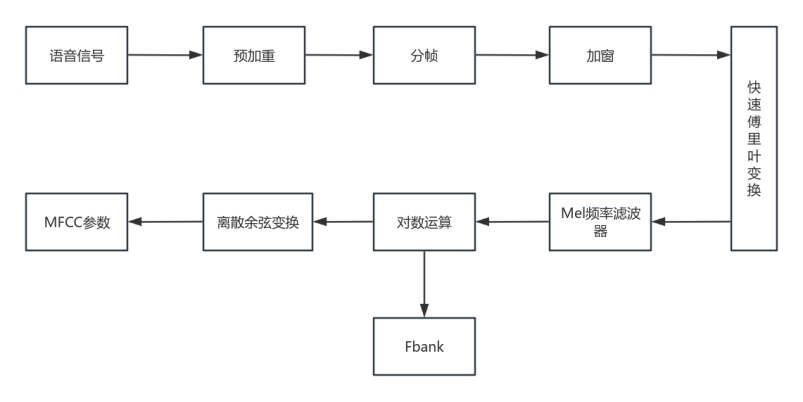
MFCC 是语音信号处理中广泛使用的特征提取方法,其主要过程包括预加重、分帧与加窗、快速傅里叶变换(Fast Fourier Transform,FFT)、梅尔滤波器组、对数压缩以及离散余弦变换(Discrete CosineTransform,DCT)等。
MFCC按连续音频的帧来进行计算,先通过快速傅里叶变换(FFT)得到该帧信号的功率谱S(n),然后转换为梅尔频率下的功率谱。MFCC梅尔频率和LPCC线性频转换关系为
式中,f 为频率,单位为Hz。
本实验MFCC特征提取参数设置:每帧2048个采样点(约93ms@22.05kHz,帧移512点(约23ms),统一重采样为22.05kHz,MFCC矩阵转置后形状为(time_steps, 13)
3.本地LSTM以及CNN推理
CNN模型:1)一个输入层接收MFCC特征矩阵,形状为 (100, 13)。2)两个结构相同的卷积模块,由一个一维卷积层、一个BN(Batch Normalization)层、一个最大池化层和一个dropout层组成。卷积层包括64个滤波器,核大小为3,步长为1,激活函数为ReLU,池化层窗口大小为2,步长为2。3)一个全连接层,激活函数为ReLU。4)一个输出层,由softmax激活。
LSTM模型:1)一个输入层接收原始的MFCC特征矩阵,形状为 (100, 13)。2)两个LSTM层,包括输入门、遗忘门、输出门[7],第一个LSTM层输入形状为(100, 13),输出形状为(100, 128),主要用于提取时序特征。第二个LSTM层输入形状为(100, 13),输出形状为(64),主要用于最终状态汇总。3)一个全连接层,输入形状为64,输出形状6,接收处理后的特征并输出[8]
4.注意力机制
注意力机制(Attention Mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像识别以及语音识别等各种不同类型的机器学习任务中。注意力机制对不同信息的关注程度(重要程度)由权值来体现,注意力机制可以视为查询矩阵(Query)、键(key)以及加权平均值构成了多层感知机(Multilayer Perceptron, MLP)。
注意力的思想,类似于寻址。给定Target中的某个元素Query,通过计算Query和各个Key的相似性或相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到最终的Attention数值。所以,本质上Attention机制是Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。其计算公式如下:
Attention(Query,Source)=i=1∑LxSimilarity(Query,Keyi)⋅Valuei
其中Lx=∣Source∣,表示Source的长度。
Attention从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大,越聚焦在对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。加权可以作用在原图上,可以作用在空间维度上,给不同区域加权,可以作用在channel维度上,给不同通道特征加权,可以作用在不同时刻历史特征上,结合循环结构添加权重。
我们采用注意力机制与CNN算法和LSTM算法相融合,具体步骤如下:1)利用CNN 提取局部声学特征。2)将 CNN 输出的特征图展开为序列形式,使用双层 LSTM,输出隐藏状态序列
(D 为 LSTM 隐藏单元数),捕获长时时间依赖。3)对 LSTM 的隐藏状态序列 H 进行加权,经过计算注意力分数,归一化权重,加权求和得到上下文向量 C,聚焦对情感分类最重要的时间帧(如语音中的重读、停顿部分)。4)将注意力输出 C 输入全连接层,通过 Softmax 分类情感类别。
将CNN 的局部特征与LSTM 的时序建模与注意力的动态聚焦相融合,CNN 捕捉声学特征(如共振峰、能量变化),LSTM 建模语音帧的时序依赖(如情感随时间的变化趋势),注意力机制过滤无关帧(如静音段),强化关键情感片段(如语调突变帧)。相比单独使用 CNN/LSTM,融合模型在长序列语音(如对话片段)中表现更优,尤其对依赖上下文的情感。
5.简单可视化实现
实现效果如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









