







 本文介绍了字符串的基本概念,包括串的定义、子串与主串,以及各种基本操作,如赋值、复制、判空等。重点讲解了顺序存储和链式存储结构,并探讨了朴素模式匹配和KMP算法在字符串匹配中的应用,分析了它们的时间复杂度。
本文介绍了字符串的基本概念,包括串的定义、子串与主串,以及各种基本操作,如赋值、复制、判空等。重点讲解了顺序存储和链式存储结构,并探讨了朴素模式匹配和KMP算法在字符串匹配中的应用,分析了它们的时间复杂度。
一. 串的定义和基本操作
1. 串的定义
串,即字符串(String)是由零个或多个字符组成的有限序列,空串可以用表示。
①子串:串中任意个连续的字符组成的子序列
②主串:包含字串的串
③字符在主串中的位置:字符在串中的位序
例如:T = "iPhone 15 Pro Max?"
i) "iPhone", "Pro M"是串T的子串
ii) T是子串"iPhone"的主串
iii) '1'在T中的位置是8(第一次出现)
串是一种特殊的线性表,数据元素间呈线性关系。
2.串的基本操作
①赋值,StrAssign(&T, chars)
②复制,StrCopy(&T, S)
③判空,StrEmpty(T)
④求串长,StrLength(T)
⑤清空,ClearStr(&T)
⑥销毁,回收存储空间,DestroyStr(&T)
⑦串连接,T为连接后的新串,Concat(&T, s1, s2)
⑧求子串,求Sub返回S中Pos位置长度为len的子串,SubStr(&Sub, s, pos, len)
⑨定位操作,返回子串T在S中第一次出现的位置,Index(S, T)
⑩比较操作,比较二进制数,ASCII码表,Unicode字符集(基于同一个字符集,可以有很多种编码方案,如UTF-8,UTF-16),StrCompare(S, T)
二. 串的存储结构
1. 串的顺序存储
/*串的顺序存储(静态数组实现)*/
#define MaxLen 25
typedef struct {
char ch[MaxLen];//定长顺序存储
int length;
}SString;
/*串的顺序存储(动态数组实现)*/
typedef struct {
char* ch;//堆分配存储
int length;
}HString;
HString S;
S.ch = (char*)malloc(sizeof(HString)*MaxLen);
S.length = 0;2. 串的链式存储
/*串的链式存储*/
typedef struct StringNode {
char ch[4];//声明为数组是为了提升存储密度
struct StringNode* next;
}StringNode,*String;3. 求子串
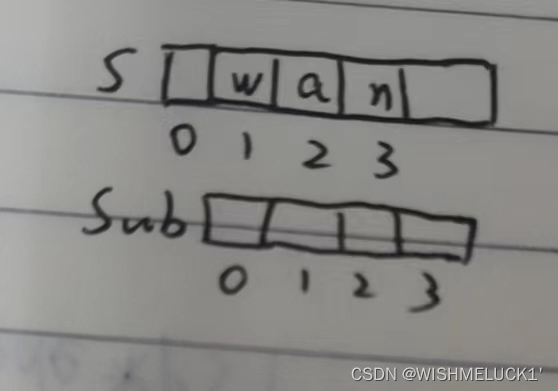
/*求子串*/
bool SubStr(SString& Sub, SString S, int pos, int len) {
if (pos + len - 1 > S.length)return false;//子串范围越界
for (int i = pos; i < pos + len; i++) {
Sub.ch[i - pos + 1] = S.ch[i];
}
Sub.length = len;
return true;
}4. 比较操作
/*比较操作*/
//S>T,返回值>0;S=T,返回值为0;S<T,返回值<0
int StrCompare(SString S, SString T) {
for (int i = 1; i < S.length && i < T.length; i++) {
if (S.ch[i] != T.ch[i])return S.ch[i] - T.ch[i];
}
//若所有字符相同,则比较长度
return S.length - T.length;
}5. 定位操作
/*定位操作*/
int Index(SString S, SString T) {
int i = 1, n = StrLength(S), m = StrLength(T);
SString sub;
while(i<=n-m+1){
SubStr(sub, S, i, m);
if (StrCompare(sub, T) != 0)++i;
else return i;
}
return 0;//S中不存在与T相等的子串
}三. 字符串——朴素模式匹配算法(暴力匹配)
1. 与定位操作代码相同的方式
2. 只更改数组下标的方式

/*字符串————朴素模式匹配算法*/
int Index(SString S, SString T) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (S.ch[i] = T.ch[i])++i, ++j;
else{
i = i - j + 2;
j = 1;
}
}
if (j > T.length)return i - T.length;//返回匹配到的第一个字符的位序
else return 0;
}最坏时间复杂度:T(n)=O(nm)。(主串长度为n,子串长度为m)
主串中关于模式串的长度m的子串有(n-m+1)个,最坏时每个模式串都匹配m次(到最后一个字符才发现不匹配),,通常情况n>>m,所以T(n)=O(nm)。
四. KMP算法
1. 延续朴素模式匹配的思想

/*KMP算法*/
int Index_KMP(SString S, SString T, int next[]) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (j == 0 || S.ch[i] == T.ch[j]) {
++i;
++j;
}
else j = next[j];
}
if (j < T.length)return i - T.length;
else return 0;
}最坏时间复杂度O(m+n),求next,O(m),匹配O(n)
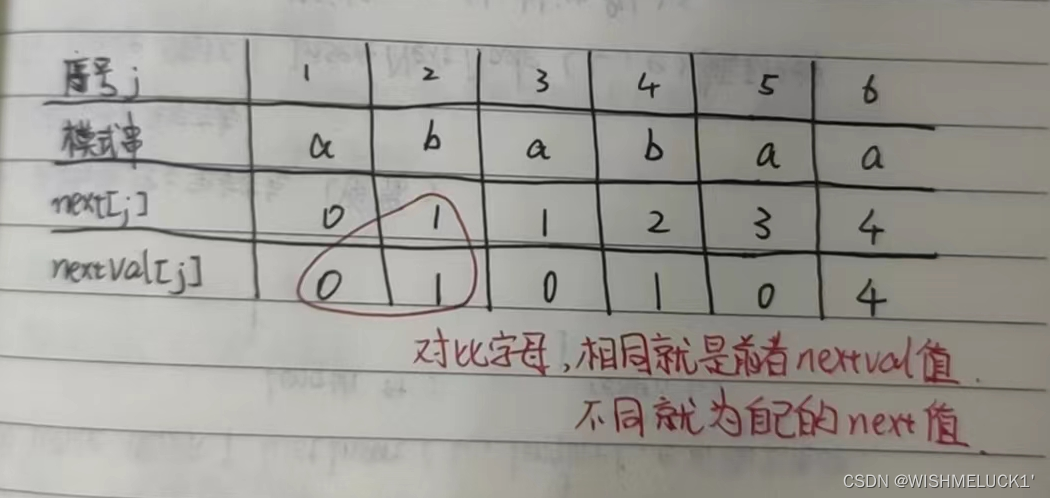
2. 求next数组(手算)
前缀:除最后一个字符以外,字符串的所有头部子串
后缀:除第一个字符外,字符串的所有尾部子串
next数组:当第j个字符匹配失败,由前1~j-1个字符组成的串记为s,则next「j」=s的最长相等前后缀长度+1,next「1」=0

3.KMP算法的进一步优化 (求nextval)
nextval数组:对next数组的优化,nextval「1」=0,当第j个字符匹配失败,若T.ch「next『j』」=T.ch「j」,则nextval「j」=nextval「next『j』」,否则nextval「j」=next「j」

具体方法
/*求nextval数组*/
int nextval[];
for (int j = 2; j <= T.length; j++) {
if (T.ch[next[j]] == T.ch[j])
nextval[j] = nextval[next[j]];
else
nextval[j] = next[j];
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











