






1.新建Scrapy框架
1.下载scrapy爬虫框架,通过pip show scrapy命令查看是否安装成功
2.下载完scrapy框架以后通过scrapy startproject project_name命令创建一个新的 Scrapy 项目,project_name是你想要为项目指定的名称
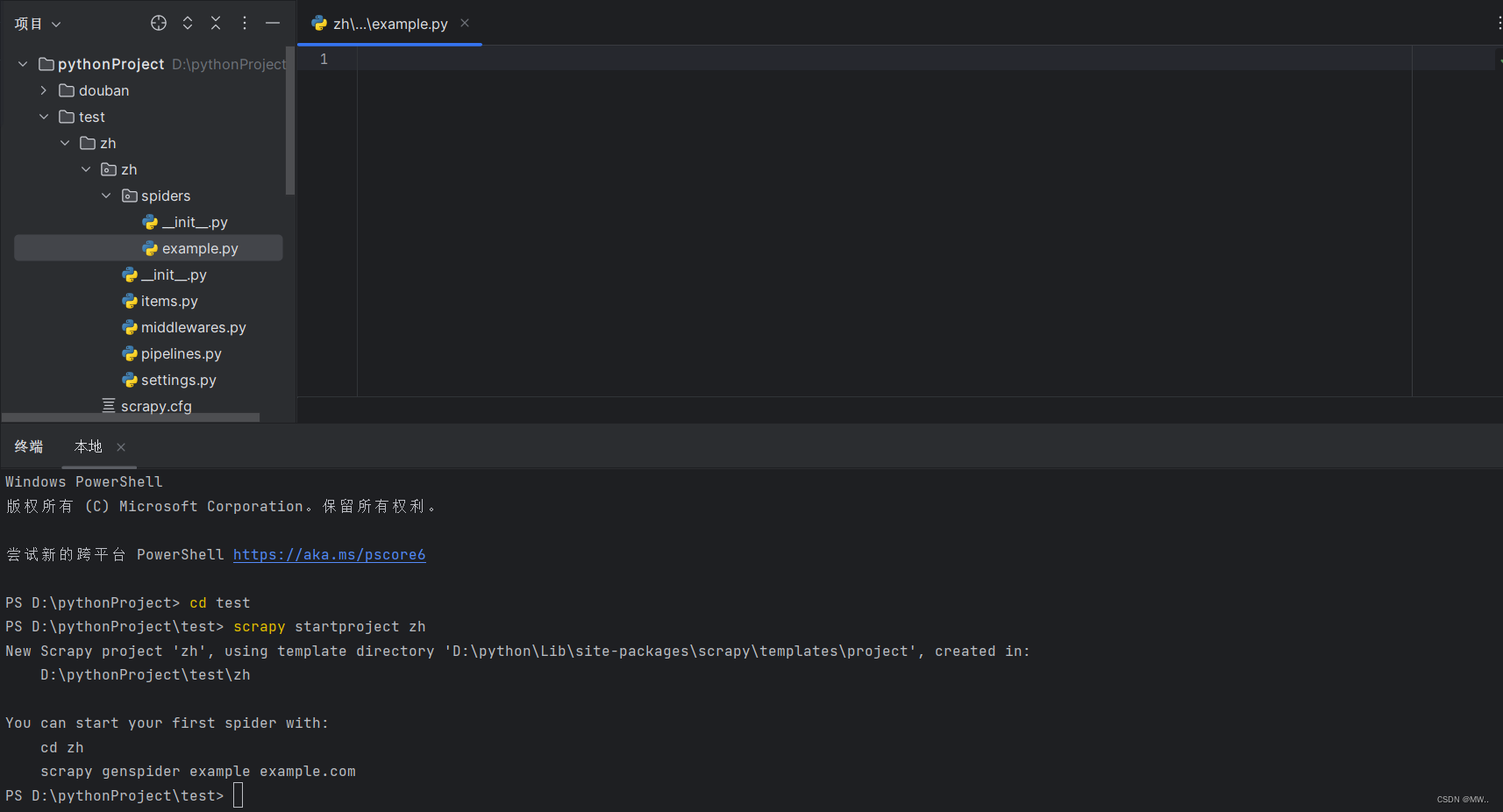
3.创建爬虫,在spiders目录下创建一个爬虫文件,创建一个类名字任意,继承scrapy.Spider
import scrapy
import json
class ExampleSpider(scrapy.Spider):
name = "example"2.爬虫代码处理
import scrapy
import json
class ExampleSpider(scrapy.Spider):
def __init__(self):
self.url = 'https://www.zhihu.com/api/v3/feed/topstory/recommend?action=down&ad_interval=-10&after_id=5&desktop=true&page_number={}&session_token=2a51fb56ffcf302376a27721df5f7213'
self.set_titles=set()
name = "example"
def start_requests(self):
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '_xsrf=6cd9a6f3-2229-4f2f-9447-cd145d4a1216; YD00517437729195%3AWM_TID=ErD12XfEMM5BAFQEABbUbA81nU4g5cm4; __snaker__id=MtGfNS0qHujluNUP; b-user-id=0ef78d7a-695d-df7e-f7e9-9c8c9cf7de69; o_act=login; ref_source=other_https://www.zhihu.com/signin?next=/; expire_in=15551999; q_c1=0f3ebd07d3754273901b99f96e20cbe8|1698370016000|1698370016000; YD00517437729195%3AWM_NI=m5VZghLDPxRxLirTH2DJ8jpynFHPaUZxvynfODwp49XWd0V48SByI%2F6yTgvCLeWPeLHceEfrTIulPdi2QM3JttPzmKk%2FXiN4sC8rt9bACniYWwxq8TAwmWg8PLygB2vsTGY%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee96f464908d0098f33a9cb08eb7c15f969a8eb1d43ab2ecb891c14eadaebab7bb2af0fea7c3b92aafeb9abbe664909ca099d17490b7beb5cb3a8896f88bf373ae9a88b1e45f9aa8ba9aed6e8d9cb991b7339c89acd1d540fc8d8e9acc25f6a79c88f54990bb99b1e8488cbdaba6e57a9897bb8dd370abee9faeb242b8aca09bf041a9f1988acd40b19df893f733a29f8d8fec5395a9b892bb6083a9a3b8e6349494b788c13ab6ad9ca8dc37e2a3; _zap=3f28e9f1-b1ca-425b-8f96-30fece870ba0; d_c0=AOCZC2o4exiPTmV7_9UaaEAsjV-Gqk7R59U=|1713366039; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1713366042; z_c0=2|1:0|10:1714986799|4:z_c0|80:MS4xVXNmTEVnQUFBQUFtQUFBQVlBSlZUUm95RFdlLWlrQWRocFduSVdDOUptVkdSSUxVU3EzcGVBPT0=|ff5309ffd2162350b7efcbe1a528299f678191dbc977359aac26779a138ac9b6; BEC=d5e2304fff7e4240174612484fe7ffa4; SESSIONID=RKulS0VvcJXRxaUPNCf5BFQAhugk1sI2rJpnxkaVLkp; JOID=W1wWBENMYCNuVL_sFUJcPqwija0JEyxSDQaCvWcuJ3w4I9-0QuOiEAZYte8eVHwArboq2jZXsB1EzmXzD7CF26A=; osd=UF0dBkhHYShsX7TtHkBXNa0pj6YCEidQBg2DtmUlLH0zIdS_Q-igGw1Zvu0VX30Lr7Eh2z1VuxZFxWf4BLGO2as=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1714995753; tst=r; KLBRSID=c450def82e5863a200934bb67541d696|1714995755|1714995616; BAIDU_SSP_lcr=https://www.baidu.com/link?url=QDCkdmq_2Wsk8fmXoEsi1I5_Zx8pl5Rm7FANw5Jug0G&wd=&eqid=93e964760018a40a000000066638c19d',
'priority': 'u=1, i',
'referer': 'https://www.zhihu.com/',
'sec-ch-ua': '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'x-api-version': '3.0.53',
'x-requested-with': 'fetch',
'x-zse-93': '101_3_3.0',
'x-zse-96': '2.0_d12mG68K1ljV2BZnPhwPUQDOMLexjCRJBTqpPsxNicPmzZ1KC3gIK1SjH4P=vP4D',
'x-zst-81': '3_2.0aR_sn77yn6O92wOB8hPZnQr0EMYxc4f18wNBUgpTQ6nxERFZKTY0-4Lm-h3_tufIwJS8gcxTgJS_AuPZNcXCTwxI78YxEM20s4PGDwN8gGcYAupMWufIeQuK7AFpS6O1vukyQ_R0rRnsyukMGvxBEqeCiRnxEL2ZZrxmDucmqhPXnXFMTAoTF6RhRuLPF7V1phOf8gL_e8cfjUeBJw39pqLCFgXKYuwCghCB0rS0LrHKIDXKW9CKo0rTv0ofk4e9NhXqNcpKxDgLcBC0_ht1wcUM0uYx8Bw0sB3Orec93gSu9vcLygHKQTxYACc9e9H0qhLLHqL9tgwpaup0ZbXOPwXfe9Cp8qp1bgwfiwH_HutmCqfzqwo0xwN8PGFmJDo9yhLGYup9kMS80wV_K6xOVCLBewNLuGHmgvLLJ4XGI9Fp8rLmFGgGuqCLPUgLYCX95JL1DbrfyCgYCBLGkrXOk9O1BGHVCweCK8CC',
}
for i in range(1,20):
url = self.url.format(i)
yield scrapy.Request(
url=url,
headers=headers,
callback=self.parse,
)
def parse(self, response):
datas = json.loads(response.text)
items= datas['data']
for item in items:
title = item['target']['question']['title']
if title not in self.set_titles:
self.set_titles.add(title)
print(f'标题:{title}')
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl example'.split())其中里面涉及到的几个方法如下
1.def __init__(self):这是 ExampleSpider 类的构造函数(初始化方法)。
self.url ='...':表示这行代码定义了一个实例变量 url,并将一个 URL 地址赋给它。用于向知乎发送请求获取数据的,其中 {} 是一个占位符,用于在后续的请求中填充具体的页码
self.set_titles=set():这行代码定义了一个实例变量 set_titles,它被初始化为空集合。


2.def start_request(self):方法是 用于生成初始的请求对象。在这个方法中,通过循环构造了多个请求对象,每个请求对象对应一个要爬取的页面。这里的循环范围是从1到19,意味着会发送20个请求。
循环内部的 url 是要请求的目标网页的 URL 地址,通过 format 方法将页码 i 插入到 URL 中,实现了每次请求不同页码的目标页面。
callback=self.parse 指定了请求完成后的回调函数为 parse 方法,表示当请求成功返回后,会将返回的响应传递给 parse 方法进行解析。

headers 是 HTTP 请求的头部信息,包含了一系列键值对,用于模拟浏览器发送请求。这些键值对中包含了诸如用户代理、引用来源、Cookie 等信息。这些信息可以让请求看起来像是从真实的浏览器发出的。
3.def parse(self,response):parse 方法用于处理服务器返回的响应数据,进行解析和提取,response为返回回来的数据对象。
data=json.loads(rseponse.text):这行代码将响应数据的文本部分(response.text)转换为 Python 中的 JSON 对象。使用 json.loads() 函数将 JSON 格式的字符串转换为 Python 的字典或列表。
items=datas[data]:表示提取数据到items
迭代数据项并提取标题并将去重后的结果打印出来

3.代码运行及结果展示
通过if判断语句作为主程序运行
调用了cmdline.execute() 函数,并传入一个字符串 'scrapy crawl example'
'scrapy' 是 Scrapy 框架的命令行工具
'crawl example' 表示要运行一个名为 'example' 的爬虫。在 Scrapy 中,通过 crawl 命令来启动指定名称的爬虫
字符串被 split() 方法拆分为一个列表,每个单词成为列表中的一个元素,以便作为参数传递给 cmdline.execute() 函数。
当这段代码被执行时,调用 Scrapy 命令行工具来启动名为 'example' 的爬虫。
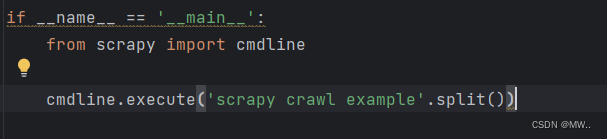
结果展示:

4.注意
如果直接重www.zhihu.com/静态页面下爬取数据只能有6条,剩下的数据都是通过调用接口返回json数据形式动态生成。


















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









