







Python语言元素
作为一个程序员,可能经常会被外行问到两个问题,其一是“什么是(计算机)程序”,其二是“写(计算机)程序能做什么”,这里我先对这两个问题做一个回答。程序是指令的集合,写程序就是用指令控制计算机做我们想让它做的事情。那么,为什么要用Python语言来写程序呢?因为Python语言简单优雅,相比C、C++、Java这样的编程语言,Python对初学者更加友好,当然这并不是说Python不像其他语言那样强大,Python几乎是无所不能的,Python可以用于服务器程序开发、云平台开发、数据分析、机器学习等各个领域。当然,Python语言还可以用来粘合其他语言开发的系统,所以也经常被戏称为“胶水语言”。
需要知道的计算机常识
在开始系统的学习编程之前,我们需要先了解一些计算机的基础知识。计算机的硬件系统通常由五大部件构成,包括:运算器、控制器、存储器、输入设备和输出设备。其中,运算器和控制器放在一起就是常说的中央处理器,它的功能是执行各种运算和控制指令。其中程序是指令的集合,写程序就是将一系列的指令按照某种方式组织到一起,然后通过这些指令去控制计算机做我们想让它做的事情。目前,使用的计算机基本都是“冯·诺依曼体系结构”的计算机,这种计算机有两个关键点:一是要将存储设备与中央处理器分开;二是将数据以二进制方式编码。
二进制是一种“逢二进一”的计数法,跟我们人类使用的“逢十进一”的计数法本质是一样的。人类因为有十根手指所以使用了十进制,因为在计数时十根手指用完之后就只能用进位的方式来表示更大的数值。要知道计算机是使用二进制计数的,不管什么数据到了计算机内存中都是以二进制形式存在的。
变量和类型
要想在计算机内存中保存数据,首先就得知道变量这个概念。在编程语言中,变量是数据的载体,简单的说就是一块用来保存数据的内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。计算机能处理的数据有很多种类型,最常见的就是数值,除了数值之外还有文本、图形、音频、视频等各种各样的数据。虽然数据在计算机中都是以二进制形态存在的,但是我们可以用不同类型的变量来表示数据类型的差异。Python中的数据类型很多,而且也允许我们自定义新的数据类型(这一点在后面会讲到),这里我们需要先了解几种常用的数据类型。
- 整型(
int):Python中可以处理任意大小的整数,而且支持二进制(如0b100,换算成十进制是4)、八进制(如0o100,换算成十进制是64)、十进制(100)和十六进制(0x100,换算成十进制是256)的表示法。 - 浮点型(
float):浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,浮点数除了数学写法(如123.456)之外还支持科学计数法(如1.23456e2)。 - 字符串型(
str):字符串是以单引号或双引号括起来的任意文本,比如'hello'和"hello"。 - 布尔型(
bool):布尔值只有True、False两种值,要么是True,要么是False。
变量命名
对于每个变量我们需要给它取一个名字,就如同我们每个人都有自己的名字一样,名字不同,含义也不同。在Python中,变量命名需要遵循以下这些规则,这些规则又分为必须遵守的硬性规则和建议遵守的非硬性规则。
- 硬性规则:
- 规则1:变量名由字母、数字和下划线构成,数字不能开头。需要说明的是,像
!、@、#这些特殊字符是不能出现在变量名中的,强烈建议尽可能使用英文字母。 - 规则2:大小写敏感,简单的说就是大写的
A和小写的a是两个不同的变量。 - 规则3:变量名不要跟Python语言的关键字(有特殊含义的单词,后面会讲到)和保留字(如已有的函数、模块等的名字)发生重名的冲突。
- 规则1:变量名由字母、数字和下划线构成,数字不能开头。需要说明的是,像
- 非硬性规则:
- 规则1:变量名通常使用小写英文字母,多个单词用下划线进行连接。
- 规则2:受保护的变量用单个下划线开头。
- 规则3:私有的变量用两个下划线开头。
当然,作为一个专业的程序员,给变量(事实上应该是所有的标识符)命名时做到见名知意也非常重要。
变量的使用
下面通过例子来说明变量的类型和变量的使用。
"""
使用变量保存数据并进行加减乘除运算
"""
a = 45 # 变量a保存了45
b = 12 # 变量b保存了12
print(a + b) # 57
print(a - b) # 33
print(a * b) # 540
print(a / b) # 3.75
在Python中可以使用type函数对变量的类型进行检查。程序设计中函数的概念跟数学上函数的概念基本一致,数学上的函数相信大家并不陌生,它包括了函数名、自变量和因变量。如果暂时不理解函数这个概念也不要紧,我们会在后续的内容中专门讲解函数的定义和使用。
"""
使用type()检查变量的类型
"""
a = 100
b = 12.345
c = 'hello, world'
d = True
print(type(a)) # <class 'int'>
print(type(b)) # <class 'float'>
print(type(c)) # <class 'str'>
print(type(d)) # <class 'bool'>
不同类型的变量可以相互转换,这一点可以通过Python的内置函数来实现。
int():将一个数值或字符串转换成整数,可以指定进制。float():将一个字符串转换成浮点数。str():将指定的对象转换成字符串形式,可以指定编码。chr():将整数转换成该编码对应的字符串(一个字符)。ord():将字符串(一个字符)转换成对应的编码(整数)。
下面的例子演示了Python中类型转换的操作。
"""
Python中的类型转换操作
"""
a = 100
b = 12.345
c = 'hello, world'
d = True
# 整数转成浮点数
print(float(a)) # 100.0
# 浮点型转成字符串 (输出字符串时不会看到引号哟)
print(str(b)) # 12.345
# 字符串转成布尔型 (有内容的字符串都会变成True)
print(bool(c)) # True
# 布尔型转成整数 (True会转成1,False会转成0)
print(int(d)) # 1
# 将整数变成对应的字符 (97刚好对应字符表中的字母a)
print(chr(97)) # a
# 将字符转成整数 (Python中字符和字符串表示法相同)
print(ord('a')) # 97
小结
在Python程序中,可以使用变量来保存数据,变量有不同的类型,变量可以做运算,也可以通过内置函数来转换变量类型。
Python运算符
| 运算符 | 描述 | |
|---|---|---|
[] [:] | 下标,切片 | |
** | 指数 | |
~ + - | 按位取反, 正负号 | |
* / % // | 乘,除,模,整除 | |
+ - | 加,减 | |
>> << | 右移,左移 | |
& | 按位与 | |
^ | | 按位异或,按位或 | |
<= < > >= | 小于等于,小于,大于,大于等于 | |
== != | 等于,不等于 | |
is is not | 身份运算符 | |
in not in | 成员运算符 | |
not or and | 逻辑运算符 | |
= += -= *= /= %= //= **= &= | 赋值运算符 |
说明: 上面这个表格实际上是按照运算符的优先级从上到下列出了各种运算符。所谓优先级就是在一个运算的表达式中,如果出现了多个运算符,应该先执行哪个运算再执行哪个运算的顺序。在实际开发中,如果搞不清楚运算符的优先级,可以使用圆括号来确保运算的执行顺序。
算术运算符
Python中的算术运算符非常丰富,除了大家最为熟悉的加减乘除之外,还有整除运算符、求模(求余数)运算符和求幂运算符。下面的例子展示了算术运算符的使用。
print(321 + 123) # 加法运算
print(321 - 123) # 减法运算
print(321 * 123) # 乘法运算
print(321 / 123) # 除法运算
print(321 % 123) # 求模运算
print(321 // 123) # 整除运算
print(321 ** 123) # 求幂运算
赋值运算符
赋值运算符应该是最为常见的运算符,它的作用是将右边的值赋给左边的变量。下面的例子演示了赋值运算符和复合赋值运算符的使用。
a = 10
b = 3
a += b # 相当于:a = a + b
a *= a + 2 # 相当于:a = a * (a + 2)
print(a) # 算一下这里会输出什么
比较运算符和逻辑运算符
比较运算符有的地方也称为关系运算符,包括==、!=、<、>、<=、>=,没有什么好解释的,需要提醒的是比较相等用的是==,请注意这里是两个等号,因为=是赋值运算符,我们在上面刚刚讲到过,==才是比较相等的运算符;比较不相等用的是!=,这不同于数学上的不等号,
逻辑运算符有三个,分别是and、or和not。and字面意思是“而且”,所以and运算符会连接两个布尔值,如果两个布尔值都是True,那么运算的结果就是True;左右两边的布尔值有一个是False,最终的运算结果就是False。相信大家已经想到了,如果and左边的布尔值是False,不管右边的布尔值是什么,最终的结果都是False,所以在做运算的时候右边的值会被跳过(短路处理),这也就意味着在and运算符左边为False的情况下,右边的表达式根本不会执行。or字面意思是“或者”,所以or运算符也会连接两个布尔值,如果两个布尔值有任意一个是True,那么最终的结果就是True。当然,or运算符也是有短路功能的,在它左边的布尔值为True的情况下,右边的表达式根本不会执行。not运算符的后面会跟上一个布尔值,它的作用是得到与该布尔值相反的值,也就是说,not后面的布尔值如果是True,运算结果就是False;而not后面的布尔值如果是False,运算结果就是True。说了一大堆,还是直接看下面例子更容易理解。
"""
比较运算符和逻辑运算符的使用
"""
flag0 = 1 == 1
flag1 = 3 > 2
flag2 = 2 < 1
flag3 = flag1 and flag2
flag4 = flag1 or flag2
flag5 = not (1 != 2)
print('flag0 =', flag0) # flag0 = True
print('flag1 =', flag1) # flag1 = True
print('flag2 =', flag2) # flag2 = False
print('flag3 =', flag3) # flag3 = False
print('flag4 =', flag4) # flag4 = True
print('flag5 =', flag5) # flag5 = False
说明:比较运算符的优先级高于赋值运算符,所以
flag0 = 1 == 1先做1 == 1产生布尔值True,再将这个值赋值给变量flag0。,进行分隔,输出的内容之间默认以空格分开。
运算符的例子
例子1:华氏温度转换为摄氏温度。
提示:华氏温度到摄氏温度的转换公式为:
C = (F - 32) / 1.8。
f = float(input('请输入华氏温度: '))
c = (f - 32) / 1.8
print('%.1f华氏度 = %.1f摄氏度' % (f, c))
说明:在使用
%.1f是一个占位符,稍后会由一个float类型的变量值替换掉它。同理,如果字符串中有%d,后面可以用一个int类型的变量值替换掉它,而%s会被字符串的值替换掉。除了这种格式化字符串的方式外,还可以用下面的方式来格式化字符串,其中{f:.1f}和{c:.1f}可以先看成是{f}和{c},表示输出时会用变量f和变量c的值替换掉这两个占位符,后面的:.1f表示这是一个浮点数,小数点后保留1位有效数字。
print(f'{f:.1f}华氏度 = {c:.1f}摄氏度')
例子2:输入圆的半径计算计算周长和面积。
radius = float(input('请输入圆的半径: '))
perimeter = 2 * 3.1416 * radius
area = 3.1416 * radius * radius
print('周长: %.2f' % perimeter)
print('面积: %.2f' % area)
例子3:输入年份判断是不是闰年。
year = int(input('请输入年份: '))
is_leap = year % 4 == 0 and year % 100 != 0 or year % 400 == 0
print(is_leap)
说明:比较运算符会产生布尔值,而逻辑运算符
and和or会对这些布尔值进行组合,最终也是得到一个布尔值,闰年输出True,平年输出False。
小结
学会使用运算符以及由运算符构成的表达式,就可以帮助我们解决很多实际的问题,运算符和表达式对于任何一门编程语言都是非常重要的。
Python分支结构
应用场景
迄今为止,我们写的Python代码都是一条一条语句顺序执行,这种代码结构通常称之为顺序结构。然而仅有顺序结构并不能解决所有的问题,比如设计一个游戏,游戏第一关的通关条件是玩家获得1000分,那么在完成本局游戏后,要根据玩家得到分数来决定究竟是进入第二关,还是告诉玩家“Game Over”,这里就会产生两个分支,而且这两个分支只有一个会被执行。类似的场景还有很多,我们将这种结构称之为“分支结构”或“选择结构”。给你一分钟的时间,你应该可以想到至少5个以上这样的例子,说的再多,都不如你多动手试一试。
if语句的使用
在Python中,要构造分支结构可以使用if、elif和else关键字。所谓关键字就是有特殊含义的单词,像if和else就是专门用于构造分支结构的关键字,很显然你不能够使用它作为变量名。下面的例子中演示了如何构造一个分支结构。
"""
用户身份验证
"""
username = input('请输入用户名: ')
password = input('请输入口令: ')
# 用户名是admin且密码是123456则身份验证成功否则身份验证失败
if username == 'admin' and password == '123456':
print('身份验证成功!')
else:
print('身份验证失败!')
需要说明的是,不同于C++、Java等编程语言,Python中没有用花括号来构造代码块而是使用了缩进的方式来表示代码的层次结构,如果if条件成立的情况下需要执行多条语句,只要保持多条语句具有相同的缩进就可以了。换句话说连续的代码如果又保持了相同的缩进那么它们属于同一个代码块,相当于是一个执行的整体。缩进可以使用任意数量的空格,但通常使用4个空格。
提示:
if和else的最后面有一个:,它是用英文输入法输入的冒号;程序中输入的'、"、=、(、)等特殊字符,都是在英文输入法状态下输入的。注意在写代码的时候都打开英文输入法(注意是英文输入法而不是中文输入法的英文输入模式),这样可以避免很多不必要的麻烦。
如果要构造出更多的分支,可以使用if...elif...else...结构或者嵌套的if...else...结构,下面的代码演示了如何利用多分支结构实现分段函数求值。
f ( x ) = { 3 x − 5 , ( x > 1 ) x + 2 , ( − 1 ≤ x ≤ 1 ) 5 x + 3 , ( x < − 1 ) f(x) = \begin{cases} 3x - 5, & (x \gt 1) \\ x + 2, & (-1 \le x \le 1) \\ 5x + 3, & (x \lt -1) \end{cases} f(x)=⎩ ⎨ ⎧3x−5,x+2,5x+3,(x>1)(−1≤x≤1)(x<−1)
"""
分段函数求值
"""
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
elif x >= -1:
y = x + 2
else:
y = 5 * x + 3
print(f'f({x}) = {y}')
根据实际需要,分支结构是可以嵌套的,例如判断是否通关以后还要根据获得的宝物或者道具的数量对表现给出等级(比如点亮两颗或三颗星星),那么就需要在if的内部构造出一个新的分支结构,同理elif和else中也可以再构造新的分支,称之为嵌套的分支结构
"""
分段函数求值
"""
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
else:
if x >= -1:
y = x + 2
else:
y = 5 * x + 3
print(f'f({x}) = {y}')
说明: 自己感受和评判一下这两种写法到底是哪一种更好。在Python之禅中有这么一句话:“Flat is better than nested”,之所以提倡代码“扁平化”,是因为代码嵌套的层次如果很多,会严重的影响代码的可读性,所以使用更为扁平化的结构在很多场景下都是较好的选择。
例子
例子1:英制单位英寸与公制单位厘米互换。
value = float(input('请输入长度: '))
unit = input('请输入单位: ')
if unit == 'in' or unit == '英寸':
print('%f英寸 = %f厘米' % (value, value * 2.54))
elif unit == 'cm' or unit == '厘米':
print('%f厘米 = %f英寸' % (value, value / 2.54))
else:
print('请输入有效的单位')
例子2:百分制成绩转换为等级制成绩。
要求:如果输入的成绩在90分以上(含90分)输出A;80分-90分(不含90分)输出B;70分-80分(不含80分)输出C;60分-70分(不含70分)输出D;60分以下输出E。
score = float(input('请输入成绩: '))
if score >= 90:
grade = 'A'
elif score >= 80:
grade = 'B'
elif score >= 70:
grade = 'C'
elif score >= 60:
grade = 'D'
else:
grade = 'E'
print('对应的等级是:', grade)
例子3:输入三条边长,如果能构成三角形就计算周长和面积。
a = float(input('a = '))
b = float(input('b = '))
c = float(input('c = '))
if a + b > c and a + c > b and b + c > a:
peri = a + b + c
print(f'周长: {peri}')
half = peri / 2
area = (half * (half - a) * (half - b) * (half - c)) ** 0.5
print(f'面积: {area}')
else:
print('不能构成三角形')
说明: 上面通过边长计算三角形面积的公式叫做海伦公式。
简单的小结
学会了Python中的分支结构和循环结构,就可以用Python程序来解决很多实际的问题了。记住了if、elif、else这几个关键字以及如何使用它们来构造分支结构,接下来介绍循环结构
循环结构
应用场景
在写程序的时候,一定会遇到需要重复执行某条指令或某些指令的场景。例如用程序控制机器人踢足球,如果机器人持球而且还没有进入射门范围,那么我们就要一直发出让机器人向球门方向移动的指令。在这个场景中,让机器人向球门方向移动就是一个需要重复的动作,当然这里还会用到上一课讲的分支结构来判断机器人是否持球以及是否进入射门范围。再举一个简单的例子,如果要实现每隔1秒中在屏幕上打印一次“hello, world”并持续打印一个小时,我们肯定不能够直接print('hello, world')这句代码写3600遍,这里我们需要构造循环结构。
所谓循环结构,就是程序中控制某条或某些指令重复执行的结构。在Python中构造循环结构有两种做法,一种是for-in循环,另一种是while循环。
for-in循环
如果明确的知道循环执行的次数,使用for-in循环,例如输出100行的”hello, world“。 被for-in循环控制的语句块也是通过缩进的方式来构造的,这一点跟分支结构完全相同。
"""
用for循环实现1~100求和
"""
total = 0
for x in range(1, 101):
total += x
print(total)
需要说明的是上面代码中的range(1, 101)可以用来构造一个从1到100的范围,当我们把这样一个范围放到for-in循环中,就可以通过前面的循环变量x依次取出从1到100的整数。当然,range的用法非常灵活,下面给出了一个例子:
range(101):可以用来产生0到100范围的整数,需要注意的是取不到101。range(1, 101):可以用来产生1到100范围的整数,相当于前面是闭区间后面是开区间。range(1, 101, 2):可以用来产生1到100的奇数,其中2是步长,即每次递增的值。range(100, 0, -2):可以用来产生100到1的偶数,其中-2是步长,即每次递减的值。
知道了这一点,我们可以用下面的代码来实现1~100之间的偶数求和。
total = 0
for x in range(2, 101, 2):
total += x
print(total)
while循环
如果要构造不知道具体循环次数的循环结构,使用while循环。while循环通过一个能够产生bool值的表达式来控制循环,当表达式的值为True时则继续循环,当表达式的值为False时则结束循环。
下面我们通过一个“猜数字”的小游戏来看看如何使用while循环。猜数字游戏的规则是:计算机出一个1到100之间的随机数,玩家输入自己猜的数字,计算机给出对应的提示信息(大一点、小一点或猜对了),如果玩家猜中了数字,计算机提示用户一共猜了多少次,游戏结束,否则游戏继续。
"""
猜数字游戏
"""
import random
# 产生一个1-100范围的随机数
answer = random.randint(1, 100)
counter = 0
while True:
counter += 1
number = int(input('请输入: '))
if number < answer:
print('大一点')
elif number > answer:
print('小一点')
else:
print('恭喜你猜对了!')
break
# 当退出while循环的时候显示用户一共猜了多少次
print(f'你总共猜了{counter}次')
break和continue
上面的代码中使用while True构造了一个条件恒成立的循环,也就意味着如果不做特殊处理,循环是不会结束的,这也就是常说的“死循环”。为了在用户猜中数字时能够退出循环结构,我们使用了break关键字,它的作用是提前结束循环。需要注意的是,break只能终止它所在的那个循环,这一点在使用嵌套循环结构时需要引起注意,下面的例子我们会讲到什么是嵌套的循环结构。除了break之外,还有另一个关键字是continue,它可以用来放弃本次循环后续的代码直接让循环进入下一轮。
嵌套的循环结构
和分支结构一样,循环结构也是可以嵌套的,也就是说在循环中还可以构造循环结构。下面的例子演示了如何通过嵌套的循环来输出一个乘法口诀表(九九表)。
"""
打印乘法口诀表
"""
for i in range(1, 10):
for j in range(1, i + 1):
print(f'{i}*{j}={i * j}', end='\t')
print()
很显然,在上面的代码中,外层循环用来控制一共会产生9行的输出,而内层循环用来控制每一行会输出多少列。内层循环中的输出就是九九表一行中的所有列,所以在内层循环完成时,有一个print()来实现换行输出的效果。
循环的例子
例子1:输入一个正整数判断它是不是素数。
提示:素数指的是只能被1和自身整除的大于1的整数。
"""
输入一个正整数判断它是不是素数
"""
num = int(input('请输入一个正整数: '))
end = int(num ** 0.5)
is_prime = True
for x in range(2, end + 1):
if num % x == 0:
is_prime = False
break
if is_prime and num != 1:
print(f'{num}是素数')
else:
print(f'{num}不是素数')
例子2:输入两个正整数,计算它们的最大公约数和最小公倍数。
提示:两个数的最大公约数是两个数的公共因子中最大的那个数;两个数的最小公倍数则是能够同时被两个数整除的最小的那个数。
"""
输入两个正整数计算它们的最大公约数和最小公倍数
"""
x = int(input('x = '))
y = int(input('y = '))
for factor in range(x, 0, -1):
if x % factor == 0 and y % factor == 0:
print(f'{x}和{y}的最大公约数是{factor}')
print(f'{x}和{y}的最小公倍数是{x * y // factor}')
break
简单的小结
学会了Python中的分支结构和循环结构,就可以解决很多实际的问题了。如果知道循环的次数,我们通常使用for循环;如果循环次数不能确定,可以用while循环。在循环中还可以使用break来提前结束循环。
分支和循环结构的应用
通过前面的学习,对Python中的分支和循环结构已经有了基本的认识。分支和循环结构的重要性不言而喻,它是构造程序逻辑的基础,对于初学者来说也是比较困难的部分。大部分初学者在学习了分支和循环结构后都能理解它们的用途和用法,但是遇到实际问题的时候又无法下手;看懂别人的代码很容易,但是要自己写出同样的代码却又很难。如果你也有同样的问题和困惑,千万不要沮丧,这只是因为你才刚刚开始编程之旅,你的练习量还没有达到让你可以随心所欲的写出代码的程度,只要加强编程练习,这个问题迟早都会解决的。下面我们就为大家讲解一些经典的案例。
经典小案例
例子1:寻找水仙花数。
说明:水仙花数也被称为超完全数字不变数、自恋数、自幂数、阿姆斯特朗数,它是一个3位数,该数字每个位上数字的立方之和正好等于它本身,例如:$ 153=13+53+3^3 $。
这个题目的关键是将一个三位数拆分为个位、十位、百位,这一点利用Python中的//(整除)和%(求模)运算符其实很容易做到,代码如下所示。
"""
找出所有水仙花数
"""
for num in range(100, 1000):
low = num % 10
mid = num // 10 % 10
high = num // 100
if num == low ** 3 + mid ** 3 + high ** 3:
print(num)
上面利用//和%拆分一个数的小技巧在写代码的时候还是很常用的。我们要将一个不知道有多少位的正整数进行反转,例如将12345变成54321,也可以利用这两个运算来实现,代码如下所示。
"""
正整数的反转
Version: 0.1
Author: 骆昊
"""
num = int(input('num = '))
reversed_num = 0
while num > 0:
reversed_num = reversed_num * 10 + num % 10
num //= 10
print(reversed_num)
例子2:百钱百鸡问题。
说明:百钱百鸡是我国古代数学家张丘建在《算经》一书中提出的数学问题:鸡翁一值钱五,鸡母一值钱三,鸡雏三值钱一。百钱买百鸡,问鸡翁、鸡母、鸡雏各几何?翻译成现代文是:公鸡5元一只,母鸡3元一只,小鸡1元三只,用100块钱买一百只鸡,问公鸡、母鸡、小鸡各有多少只?
"""
《百钱百鸡》问题
"""
# 假设公鸡的数量为x,x的取值范围是0到20
for x in range(0, 21):
# 假设母鸡的数量为y,y的取值范围是0到33
for y in range(0, 34):
z = 100 - x - y
if 5 * x + 3 * y + z // 3 == 100 and z % 3 == 0:
print(f'公鸡: {x}只, 母鸡: {y}只, 小鸡: {z}只')
上面使用的方法叫做穷举法,也称为暴力搜索法,这种方法通过一项一项的列举备选解决方案中所有可能的候选项并检查每个候选项是否符合问题的描述,最终得到问题的解。这种方法看起来比较笨拙,但对于运算能力非常强大的计算机来说,通常都是一个可行的甚至是不错的选择,只要问题的解存在就能够找到它。
例子3:斐波那契数列。
说明:斐波那契数列(Fibonacci sequence),通常也被称作黄金分割数列,是意大利数学家莱昂纳多·斐波那契(Leonardoda Fibonacci)在《计算之书》中研究在理想假设条件下兔子成长率问题而引入的数列,因此这个数列也常被戏称为“兔子数列”。斐波那契数列的特点是数列的前两个数都是1,从第三个数开始,每个数都是它前面两个数的和,按照这个规律,斐波那契数列的前10个数是:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55。斐波那契数列在现代物理、准晶体结构、化学等领域都有直接的应用。
"""
输出斐波那契数列前20个数
"""
a, b = 0, 1
for _ in range(20):
a, b = b, a + b
print(a)
例子4:打印100以内的素数。
说明:素数指的是只能被1和自身整除的正整数(不包括1)。
"""
输出100以内的素数
"""
for num in range(2, 100):
# 假设num是素数
is_prime = True
# 在2到num-1之间找num的因子
for factor in range(2, num):
# 如果找到了num的因子,num就不是素数
if num % factor == 0:
is_prime = False
break
# 如果布尔值为True在num是素数
if is_prime:
print(num)
简单的小结
还是那句话:分支结构和循环结构非常重要,是构造程序逻辑的基础,一定要通过大量的练习来达到融会贯通。
常用数据结构之列表
将一颗色子掷6000次,统计每个点数出现的次数,可以用1到6均匀分布的随机数来模拟掷色子,然后用6个变量分别记录每个点数出现的次数
import random
f1 = 0
f2 = 0
f3 = 0
f4 = 0
f5 = 0
f6 = 0
for _ in range(6000):
face = random.randint(1, 6)
if face == 1:
f1 += 1
elif face == 2:
f2 += 1
elif face == 3:
f3 += 1
elif face == 4:
f4 += 1
elif face == 5:
f5 += 1
else:
f6 += 1
print(f'1点出现了{f1}次')
print(f'2点出现了{f2}次')
print(f'3点出现了{f3}次')
print(f'4点出现了{f4}次')
print(f'5点出现了{f5}次')
print(f'6点出现了{f6}次')
上面的代码,它非常的“笨重”和“丑陋”,更可怕的是,如果要统计掷两颗或者更多的色子统计每个点数出现的次数,那就需要定义更多的变量,写更多的分支结构。讲到这里,问:有没有办法用一个变量来保存多个数据,有没有办法用统一的代码对多个数据进行操作?答案是肯定的,在Python中我们可以通过容器类型的变量来保存和操作多个数据,我们首先为大家介绍列表(list)这种新的数据类型。
定义和使用列表
在Python中,列表是由一系元素按特定顺序构成的数据序列,这样就意味着定义一个列表类型的变量,可以保存多个数据,而且允许有重复的数据。跟上一课我们讲到的字符串类型一样,列表也是一种结构化的、非标量类型,操作一个列表类型的变量,除了可以使用运算符还可以使用它的方法。
在Python中,可以使用[]字面量语法来定义列表,列表中的多个元素用逗号进行分隔,代码如下所示。
items1 = [35, 12, 99, 68, 55, 87]
items2 = ['Python', 'Java', 'Go', 'Kotlin']
除此以外,还可以通过Python内置的list函数将其他序列变成列表。准确的说,list并不是一个普通的函数,它是创建列表对象的构造器(后面会讲到对象和构造器这两个概念)。
items1 = list(range(1, 10))
print(items1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
items2 = list('hello')
print(items2) # ['h', 'e', 'l', 'l', 'o']
需要说明的是,列表是一种可变数据类型,也就是说列表可以添加元素、删除元素、更新元素,这一点跟我们上一课讲到的字符串有着鲜明的差别。字符串是一种不可变数据类型,也就是说对字符串做拼接、重复、转换大小写、修剪空格等操作的时候会产生新的字符串,原来的字符串并没有发生任何改变。
列表的运算符
和字符串类型一样,列表也支持拼接、重复、成员运算、索引和切片以及比较运算
items1 = [35, 12, 99, 68, 55, 87]
items2 = [45, 8, 29]
# 列表的拼接
items3 = items1 + items2
print(items3) # [35, 12, 99, 68, 55, 87, 45, 8, 29]
# 列表的重复
items4 = ['hello'] * 3
print(items4) # ['hello', 'hello', 'hello']
# 列表的成员运算
print(100 in items3) # False
print('hello' in items4) # True
# 获取列表的长度(元素个数)
size = len(items3)
print(size) # 9
# 列表的索引
print(items3[0], items3[-size]) # 35 35
items3[-1] = 100
print(items3[size - 1], items3[-1]) # 100 100
# 列表的切片
print(items3[:5]) # [35, 12, 99, 68, 55]
print(items3[4:]) # [55, 87, 45, 8, 100]
print(items3[-5:-7:-1]) # [55, 68]
print(items3[::-2]) # [100, 45, 55, 99, 35]
# 列表的比较运算
items5 = [1, 2, 3, 4]
items6 = list(range(1, 5))
# 两个列表比较相等性比的是对应索引位置上的元素是否相等
print(items5 == items6) # True
items7 = [3, 2, 1]
# 两个列表比较大小比的是对应索引位置上的元素的大小
print(items5 <= items7) # True
值得一提的是,由于列表是可变类型,所以通过索引操作既可以获取列表中的元素,也可以更新列表中的元素。对列表做索引操作一样要注意索引越界的问题,对于有N个元素的列表,正向索引的范围是0到N-1,负向索引的范围是-1到-N,如果超出这个范围,将引发IndexError异常,错误信息为:list index out of range。
列表元素的遍历
如果想逐个取出列表中的元素,可以使用for循环的,有以下两种做法。
方法一:
items = ['Python', 'Java', 'Go', 'Kotlin']
for index in range(len(items)):
print(items[index])
方法二:
items = ['Python', 'Java', 'Go', 'Kotlin']
for item in items:
print(item)
讲到这里,可以用列表的知识来重构上面“掷色子统计每个点数出现次数”的代码。
import random
counters = [0] * 6
for _ in range(6000):
face = random.randint(1, 6)
counters[face - 1] += 1
for face in range(1, 7):
print(f'{face}点出现了{counters[face - 1]}次')
上面的代码中,用counters列表中的六个元素分别表示1到6的点数出现的次数,最开始的时候六个元素的值都是0。接下来用随机数模拟掷色子,如果摇出1点counters[0]的值加1,如果摇出2点counters[1]的值加1,以此类推。感受一下,代码简单优雅了很多。
列表的方法
和字符串一样,列表类型的方法也很多
添加和删除元素
items = ['Python', 'Java', 'Go', 'Kotlin']
# 使用append方法在列表尾部添加元素
items.append('Swift')
print(items) # ['Python', 'Java', 'Go', 'Kotlin', 'Swift']
# 使用insert方法在列表指定索引位置插入元素
items.insert(2, 'SQL')
print(items) # ['Python', 'Java', 'SQL', 'Go', 'Kotlin', 'Swift']
# 删除指定的元素
items.remove('Java')
print(items) # ['Python', 'SQL', 'Go', 'Kotlin', 'Swift']
# 删除指定索引位置的元素
items.pop(0)
items.pop(len(items) - 1)
print(items) # ['SQL', 'Go', 'Kotlin']
# 清空列表中的元素
items.clear()
print(items) # []
提醒,在使用remove方法删除元素时,如果要删除的元素并不在列表中,会引发ValueError异常,错误消息是:list.remove(x): x not in list。在使用pop方法删除元素时,如果索引的值超出了范围,会引发IndexError异常,错误消息是:pop index out of range。
从列表中删除元素其实还有一种方式,就是使用Python中的del关键字后面跟要删除的元素,这种做法跟使用pop方法指定索引删除元素没有实质性的区别,但后者会返回删除的元素,前者在性能上略优(del对应字节码指令是DELETE_SUBSCR,而pop对应的字节码指令是CALL_METHOD和POP_TOP,不理解就跳过,不用管它!!!)。
items = ['Python', 'Java', 'Go', 'Kotlin']
del items[1]
print(items) # ['Python', 'Go', 'Kotlin']
元素位置和次数
列表类型的index方法可以查找某个元素在列表中的索引位置;因为列表中允许有重复的元素,所以列表类型提供了count方法来统计一个元素在列表中出现的次数。请看下面的代码。
items = ['Python', 'Java', 'Java', 'Go', 'Kotlin', 'Python']
# 查找元素的索引位置
print(items.index('Python')) # 0
print(items.index('Python', 2)) # 5
# 注意:虽然列表中有'Java',但是从索引为3这个位置开始后面是没有'Java'的
print(items.index('Java', 3)) # ValueError: 'Java' is not in list
再来看看下面这段代码。
items = ['Python', 'Java', 'Java', 'Go', 'Kotlin', 'Python']
# 查找元素出现的次数
print(items.count('Python')) # 2
print(items.count('Go')) # 1
print(items.count('Swfit')) # 0
元素排序和反转
列表的sort操作可以实现列表元素的排序,而reverse操作可以实现元素的反转,代码如下所示。
items = ['Python', 'Java', 'Go', 'Kotlin', 'Python']
# 排序
items.sort()
print(items) # ['Go', 'Java', 'Kotlin', 'Python', 'Python']
# 反转
items.reverse()
print(items) # ['Python', 'Python', 'Kotlin', 'Java', 'Go']
列表的生成式
在Python中,列表还可以通过一种特殊的字面量语法来创建,这种语法叫做生成式。
通过for循环为空列表添加元素。
# 创建一个由1到9的数字构成的列表
items1 = []
for x in range(1, 10):
items1.append(x)
print(items1)
# 创建一个由'hello world'中除空格和元音字母外的字符构成的列表
items2 = []
for x in 'hello world':
if x not in ' aeiou':
items2.append(x)
print(items2)
# 创建一个由个两个字符串中字符的笛卡尔积构成的列表
items3 = []
for x in 'ABC':
for y in '12':
items3.append(x + y)
print(items3)
通过生成式创建列表。
# 创建一个由1到9的数字构成的列表
items1 = [x for x in range(1, 10)]
print(items1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 创建一个由'hello world'中除空格和元音字母外的字符构成的列表
items2 = [x for x in 'hello world' if x not in ' aeiou']
print(items2) # ['h', 'l', 'l', 'w', 'r', 'l', 'd']
# 创建一个由个两个字符串中字符的笛卡尔积构成的列表
items3 = [x + y for x in 'ABC' for y in '12']
print(items3) # ['A1', 'A2', 'B1', 'B2', 'C1', 'C2']
下面这种方式不仅代码简单优雅,而且性能也优于上面使用for循环和append方法向空列表中追加元素的方式。可以简单跟大家交待下为什么生成式拥有更好的性能,那是因为Python解释器的字节码指令中有专门针对生成式的指令(LIST_APPEND指令);而for循环是通过方法调用(LOAD_METHOD和CALL_METHOD指令)的方式为列表添加元素,方法调用本身就是一个相对耗时的操作。对这一点不理解也没有关系,记住“强烈建议用生成式语法来创建列表”这个结论就可以了。
嵌套的列表
Python语言没有限定列表中的元素必须是相同的数据类型,也就是说一个列表中的元素可以任意的数据类型,当然也包括列表。如果列表中的元素又是列表,那么可以称之为嵌套的列表。嵌套的列表可以用来表示表格或数学上的矩阵,例如:保存5个学生3门课程的成绩,可以定义一个保存5个元素的列表保存5个学生的信息,而每个列表元素又是3个元素构成的列表,分别代表3门课程的成绩。但是,一定要注意下面的代码是有问题的。
scores = [[0] * 3] * 5
print(scores) # [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
看上去我们好像创建了一个5 * 3的嵌套列表,但实际上当我们录入第一个学生的第一门成绩后,你就会发现问题来了,我们看看下面代码的输出。
# 嵌套的列表需要多次索引操作才能获取元素
scores[0][0] = 95
print(scores)
# [[95, 0, 0], [95, 0, 0], [95, 0, 0], [95, 0, 0], [95, 0, 0]]
scores = [[0] * 3 for _ in range(5)]
scores[0][0] = 95
print(scores)
# [[95, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
简单的小结
Python中的列表底层是一个可以动态扩容的数组,列表元素在内存中也是连续存储的,所以可以实现随机访问(通过一个有效的索引获取到对应的元素且操作时间与列表元素个数无关)。我们暂时不去触碰这些底层存储细节以及列表每个方法的渐近时间复杂度(执行这个方法耗费的时间跟列表元素个数的关系),等需要的时候再告诉大家。现阶段,大家只需要知道列表是容器,可以保存各种类型的数据,可以通过索引操作列表元素,知道这些就足够了。
常用数据结构之元组
Python中容器型的数据类型肯定不止列表一种,接下来我们为大家讲解另一种重要的容器型数据类型,它的名字叫元组(tuple)。
定义和使用元组
在Python中,元组也是多个元素按照一定的顺序构成的序列。元组和列表的不同之处在于,元组是不可变类型,这就意味着元组类型的变量一旦定义,其中的元素不能再添加或删除,而且元素的值也不能进行修改。定义元组通常使用()字面量语法,也建议大家使用这种方式来创建元组。元组类型支持的运算符跟列表是一样。下面的代码演示了元组的定义和运算。
# 定义一个三元组
t1 = (30, 10, 55)
# 定义一个四元组
t2 = ('骆昊', 40, True, '四川成都')
# 查看变量的类型
print(type(t1), type(t2)) # <class 'tuple'> <class 'tuple'>
# 查看元组中元素的数量
print(len(t1), len(t2)) # 3 4
# 通过索引运算获取元组中的元素
print(t1[0], t1[-3]) # 30 30
print(t2[3], t2[-1]) # 四川成都 四川成都
# 循环遍历元组中的元素
for member in t2:
print(member)
# 成员运算
print(100 in t1) # False
print(40 in t2) # True
# 拼接
t3 = t1 + t2
print(t3) # (30, 10, 55, '骆昊', 40, True, '四川成都')
# 切片
print(t3[::3]) # (30, '骆昊', '四川成都')
# 比较运算
print(t1 == t3) # False
print(t1 >= t3) # False
print(t1 < (30, 11, 55)) # True
一个元组中如果有两个元素,我们就称之为二元组;一个元组中如果五个元素,我们就称之为五元组。需要提醒大家注意的是,()表示空元组,但是如果元组中只有一个元素,需要加上一个逗号,否则()就不是代表元组的字面量语法,而是改变运算优先级的圆括号,所以('hello', )和(100, )才是一元组,而('hello')和(100)只是字符串和整数。我们可以通过下面的代码来加以验证。
# 空元组
a = ()
print(type(a)) # <class 'tuple'>
# 不是元组
b = ('hello')
print(type(b)) # <class 'str'>
c = (100)
print(type(c)) # <class 'int'>
# 一元组
d = ('hello', )
print(type(d)) # <class 'tuple'>
e = (100, )
print(type(e)) # <class 'tuple'>
元组的应用场景
讲到这里,相信大家一定迫切的想知道元组有哪些应用场景,我们给大家举几个例子。
例子1:打包和解包操作。
当我们把多个用逗号分隔的值赋给一个变量时,多个值会打包成一个元组类型;当我们把一个元组赋值给多个变量时,元组会解包成多个值然后分别赋给对应的变量,如下面的代码所示。
# 打包
a = 1, 10, 100
print(type(a), a) # <class 'tuple'> (1, 10, 100)
# 解包
i, j, k = a
print(i, j, k) # 1 10 100
在解包时,如果解包出来的元素个数和变量个数不对应,会引发ValueError异常,错误信息为:too many values to unpack(解包的值太多)或not enough values to unpack(解包的值不足)。
a = 1, 10, 100, 1000
# i, j, k = a # ValueError: too many values to unpack (expected 3)
# i, j, k, l, m, n = a # ValueError: not enough values to unpack (expected 6, got 4)
有一种解决变量个数少于元素的个数方法,就是使用星号表达式,我们之前讲函数的可变参数时使用过星号表达式。有了星号表达式,我们就可以让一个变量接收多个值,代码如下所示。需要注意的是,用星号表达式修饰的变量会变成一个列表,列表中有0个或多个元素。还有在解包语法中,星号表达式只能出现一次。
a = 1, 10, 100, 1000
i, j, *k = a
print(i, j, k) # 1 10 [100, 1000]
i, *j, k = a
print(i, j, k) # 1 [10, 100] 1000
*i, j, k = a
print(i, j, k) # [1, 10] 100 1000
*i, j = a
print(i, j) # [1, 10, 100] 1000
i, *j = a
print(i, j) # 1 [10, 100, 1000]
i, j, k, *l = a
print(i, j, k, l) # 1 10 100 [1000]
i, j, k, l, *m = a
print(i, j, k, l, m) # 1 10 100 1000 []
需要说明一点,解包语法对所有的序列都成立,这就意味着对列表以及我们之前讲到的range函数返回的范围序列都可以使用解包语法。大家可以尝试运行下面的代码,看看会出现怎样的结果。
a, b, *c = range(1, 10)
print(a, b, c)
a, b, c = [1, 10, 100]
print(a, b, c)
a, *b, c = 'hello'
print(a, b, c)
例子2:交换两个变量的值。
交换两个变量的值是编程语言中的一个经典案例,在很多编程语言中,交换两个变量的值都需要借助一个中间变量才能做到,如果不用中间变量就需要使用比较晦涩的位运算来实现。在Python中,交换两个变量a和b的值只需要使用如下所示的代码。
a, b = b, a
同理,如果要将三个变量a、b、c的值互换,即b赋给a,c赋给b,a赋给c,也可以如法炮制。
a, b, c = b, c, a
需要说明的是,上面并没有用到打包和解包语法,Python的字节码指令中有ROT_TWO和ROT_THREE这样的指令可以实现这个操作,效率是非常高的。但是如果有多于三个变量的值要依次互换,这个时候没有直接可用的字节码指令,执行的原理就是我们上面讲解的打包和解包操作。
元组和列表的比较
这里还有一个非常值得探讨的问题,Python中已经有了列表类型,为什么还需要元组这样的类型呢?这个问题对于初学者来说似乎有点困难,不过没有关系,我们先抛出观点,大家可以一边学习一边慢慢体会。
-
元组是不可变类型,不可变类型更适合多线程环境,因为它降低了并发访问变量的同步化开销。关于这一点,我们会在后面讲解多线程的时候为大家详细论述。
-
元组是不可变类型,通常不可变类型在创建时间和占用空间上面都优于对应的可变类型。我们可以使用
sys模块的getsizeof函数来检查保存相同元素的元组和列表各自占用了多少内存空间。我们也可以使用timeit模块的timeit函数来看看创建保存相同元素的元组和列表各自花费的时间,代码如下所示。import sys import timeit a = list(range(100000)) b = tuple(range(100000)) print(sys.getsizeof(a), sys.getsizeof(b)) # 900120 800056 print(timeit.timeit('[1, 2, 3, 4, 5, 6, 7, 8, 9]')) print(timeit.timeit('(1, 2, 3, 4, 5, 6, 7, 8, 9)')) -
Python中的元组和列表是可以相互转换的,我们可以通过下面的代码来做到。
# 将元组转换成列表 info = ('骆昊', 175, True, '四川成都') print(list(info)) # ['骆昊', 175, True, '四川成都'] # 将列表转换成元组 fruits = ['apple', 'banana', 'orange'] print(tuple(fruits)) # ('apple', 'banana', 'orange')
简单的小结
列表和元组都是容器型的数据类型,即一个变量可以保存多个数据。列表是可变数据类型,元组是不可变数据类型,所以列表添加元素、删除元素、清空、排序等方法对于元组来说是不成立的。但是列表和元组都可以进行拼接、成员运算、索引和切片这些操作,后面我们要讲到的字符串类型也是这样,因为字符串就是字符按一定顺序构成的序列,在这一点上三者并没有什么区别。我们推荐大家使用列表的生成式语法来创建列表,它很好用,也是Python中非常有特色的语法。
字符串的使用
第二次世界大战促使了现代电子计算机的诞生,世界上的第一台通用电子计算机叫ENIAC(电子数值积分计算机),诞生于美国的宾夕法尼亚大学,占地167平米,重量27吨,每秒钟大约能够完成约5000次浮点运算,如下图所示。ENIAC诞生之后被应用于导弹弹道的计算,而数值计算也是现代电子计算机最为重要的一项功能。
随着时间的推移,虽然数值运算仍然是计算机日常工作中最为重要的组成部分,但是今天的计算机还要处理大量的以文本形式存在的信息。如果我们希望通过Python程序来操作本这些文本信息,就必须要先了解字符串这种数据类型以及与它相关的知识。
字符串的定义
所谓字符串,就是由零个或多个字符组成的有限序列,一般记为:
s
=
a
1
a
2
⋯
a
n
(
0
≤
n
≤
∞
)
s = a_1a_2 \cdots a_n \,\,\,\,\, (0 \le n \le \infty)
s=a1a2⋯an(0≤n≤∞)
在Python程序中,如果我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等。
s1 = 'hello, world!'
s2 = "你好,世界!"
print(s1, s2)
# 以三个双引号或单引号开头的字符串可以折行
s3 = '''
hello,
world!
'''
print(s3, end='')
提示:
end=''表示输出后不换行,即将默认的结束符\n(换行符)更换为''(空字符)。
转义字符和原始字符串
可以在字符串中使用\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;\t也不是代表反斜杠和字符t,而是表示制表符。所以如果字符串本身又包含了'、"、\这些特殊的字符,必须要通过\进行转义处理。例如要输出一个带单引号或反斜杠的字符串,需要用如下所示的方法。
s1 = '\'hello, world!\''
print(s1)
s2 = '\\hello, world!\\'
print(s2)
Python中的字符串可以r或R开头,这种字符串被称为原始字符串,意思是字符串中的每个字符都是它本来的含义,没有所谓的转义字符。例如,在字符串'hello\n'中,\n表示换行;而在r'hello\n'中,\n不再表示换行,就是反斜杠和字符n。大家可以运行下面的代码,看看会输出什么。
# 字符串s1中\t是制表符,\n是换行符
s1 = '\time up \now'
print(s1)
# 字符串s2中没有转义字符,每个字符都是原始含义
s2 = r'\time up \now'
print(s2)
Python中还允许在\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。另外一种表示字符的方式是在\u后面跟Unicode字符编码,例如\u9a86\u660a代表的是中文“骆昊”。运行下面的代码,看看输出了什么。
s1 = '\141\142\143\x61\x62\x63'
s2 = '\u9a86\u660a'
print(s1, s2)
字符串的运算
Python为字符串类型提供了非常丰富的运算符,我们可以使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串,我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符。
拼接和重复
下面的例子演示了使用+和*运算符来实现字符串的拼接和重复操作。
s1 = 'hello' + ' ' + 'world'
print(s1) # hello world
s2 = '!' * 3
print(s2) # !!!
s1 += s2 # s1 = s1 + s2
print(s1) # hello world!!!
s1 *= 2 # s1 = s1 * 2
print(s1) # hello world!!!hello world!!!
用*实现字符串的重复是非常有意思的一个运算符,在很多编程语言中,要表示一个有10个a的字符串,你只能写成"aaaaaaaaaa",但是在Python中,你可以写成'a' * 10。你可能觉得"aaaaaaaaaa"这种写法也没有什么不方便的,那么想一想,如果字符a要重复100次或者1000次又会如何呢?
比较运算
对于两个字符串类型的变量,可以直接使用比较运算符比较两个字符串的相等性或大小。需要说明的是,因为字符串在计算机内存中也是以二进制形式存在的,那么字符串的大小比较比的是每个字符对应的编码的大小。例如A的编码是65, 而a的编码是97,所以'A' < 'a'的结果相当于就是65 < 97的结果,很显然是True;而'boy' < 'bad',因为第一个字符都是'b'比不出大小,所以实际比较的是第二个字符的大小,显然'o' < 'a'的结果是False,所以'boy' < 'bad'的结果也是False。如果不清楚两个字符对应的编码到底是多少,可以使用ord函数来获得,例如ord('A')的值是65,而ord('昊')的值是26122。下面的代码为大家展示了字符串的比较运算。
s1 = 'a whole new world'
s2 = 'hello world'
print(s1 == s2, s1 < s2) # False True
print(s2 == 'hello world') # True
print(s2 == 'Hello world') # False
print(s2 != 'Hello world') # True
s3 = '骆昊'
print(ord('骆'), ord('昊')) # 39558 26122
s4 = '王大锤'
print(ord('王'), ord('大'), ord('锤')) # 29579 22823 38180
print(s3 > s4, s3 <= s4) # True False
需要强调一下的是,字符串的比较运算比较的是字符串的内容,Python中还有一个is运算符(身份运算符),如果用is来比较两个字符串,它比较的是两个变量对应的字符串对象的内存地址(不理解先跳过),简单的说就是两个变量是否对应内存中的同一个字符串。看看下面的代码就比较清楚is运算符的作用了。
s1 = 'hello world'
s2 = 'hello world'
s3 = s2
# 比较字符串的内容
print(s1 == s2, s2 == s3) # True True
# 比较字符串的内存地址
print(s1 is s2, s2 is s3) # False True
成员运算
Python中可以用in和not in判断一个字符串中是否存在另外一个字符或字符串,in和not in运算通常称为成员运算,会产生布尔值True或False,代码如下所示。
s1 = 'hello, world'
print('wo' in s1) # True
s2 = 'goodbye'
print(s2 in s1) # False
获取字符串长度
获取字符串长度没有直接的运算符,而是使用内置函数len,我们在上节课的提到过这个内置函数,代码如下所示。
s = 'hello, world'
print(len(s)) # 12
print(len('goodbye, world')) # 14
索引和切片
如果希望从字符串中取出某个字符,我们可以对字符串进行索引运算,运算符是[n],其中n是一个整数,假设字符串的长度为N,那么n可以是从0到N-1的整数,其中0是字符串中第一个字符的索引,而N-1是字符串中最后一个字符的索引,通常称之为正向索引;在Python中,字符串的索引也可以是从-1到-N的整数,其中-1是最后一个字符的索引,而-N则是第一个字符的索引,通常称之为负向索引。注意,因为字符串是不可变类型,所以不能通过索引运算修改字符串中的字符。
s = 'abc123456'
N = len(s)
# 获取第一个字符
print(s[0], s[-N]) # a a
# 获取最后一个字符
print(s[N-1], s[-1]) # 6 6
# 获取索引为2或-7的字符
print(s[2], s[-7]) # c c
# 获取索引为5和-4的字符
print(s[5], s[-4]) # 3 3
需要提醒大家注意的是,在进行索引操作时,如果索引越界(正向索引不在0到N-1范围,负向索引不在-1到-N范围),会引发IndexError异常,错误提示信息为:string index out of range(字符串索引超出范围)。
如果要从字符串中取出多个字符,我们可以对字符串进行切片,运算符是[i:j:k],其中i是开始索引,索引对应的字符可以取到;j是结束索引,索引对应的字符不能取到;k是步长,默认值为1,表示从前向后获取相邻字符的连续切片,所以:k部分可以省略。假设字符串的长度为N,当k > 0时表示正向切片(从前向后获取字符),如果没有给出i和j的值,则i的默认值是0,j的默认值是N;当k < 0时表示负向切片(从后向前获取字符),如果没有给出i和j的值,则i的默认值是-1,j的默认值是-N - 1。如果不理解,直接看下面的例子,记住第一个字符的索引是0或-N,最后一个字符的索引是N-1或-1就行了。
s = 'abc123456'
# i=2, j=5, k=1的正向切片操作
print(s[2:5]) # c12
# i=-7, j=-4, k=1的正向切片操作
print(s[-7:-4]) # c12
# i=2, j=9, k=1的正向切片操作
print(s[2:]) # c123456
# i=-7, j=9, k=1的正向切片操作
print(s[-7:]) # c123456
# i=2, j=9, k=2的正向切片操作
print(s[2::2]) # c246
# i=-7, j=9, k=2的正向切片操作
print(s[-7::2]) # c246
# i=0, j=9, k=2的正向切片操作
print(s[::2]) # ac246
# i=1, j=-1, k=2的正向切片操作
print(s[1:-1:2]) # b135
# i=7, j=1, k=-1的负向切片操作
print(s[7:1:-1]) # 54321c
# i=-2, j=-8, k=-1的负向切片操作
print(s[-2:-8:-1]) # 54321c
# i=7, j=-10, k=-1的负向切片操作
print(s[7::-1]) # 54321cba
# i=-1, j=1, k=-1的负向切片操作
print(s[:1:-1]) # 654321c
# i=0, j=9, k=1的正向切片
print(s[:]) # abc123456
# i=0, j=9, k=2的正向切片
print(s[::2]) # ac246
# i=-1, j=-10, k=-1的负向切片
print(s[::-1]) # 654321cba
# i=-1, j=-10, k=-2的负向切片
print(s[::-2]) # 642ca
循环遍历每个字符
如果希望从字符串中取出每个字符,可以使用for循环对字符串进行遍历,有两种方式。
方式一:
s1 = 'hello'
for index in range(len(s1)):
print(s1[index])
方式二:
s1 = 'hello'
for ch in s1:
print(ch)
字符串的方法
在Python中,我们可以通过字符串类型自带的方法对字符串进行操作和处理,对于一个字符串类型的变量,我们可以用变量名.方法名()的方式来调用它的方法。所谓方法其实就是跟某个类型的变量绑定的函数,后面我们讲面向对象编程的时候还会对这一概念详加说明。
大小写相关操作
下面的代码演示了和字符串大小写变换相关的方法。
s1 = 'hello, world!'
# 使用capitalize方法获得字符串首字母大写后的字符串
print(s1.capitalize()) # Hello, world!
# 使用title方法获得字符串每个单词首字母大写后的字符串
print(s1.title()) # Hello, World!
# 使用upper方法获得字符串大写后的字符串
print(s1.upper()) # HELLO, WORLD!
s2 = 'GOODBYE'
# 使用lower方法获得字符串小写后的字符串
print(s2.lower()) # goodbye
查找操作
如果想在一个字符串中从前向后查找有没有另外一个字符串,可以使用字符串的find或index方法。
s = 'hello, world!'
# find方法从字符串中查找另一个字符串所在的位置
# 找到了返回字符串中另一个字符串首字符的索引
print(s.find('or')) # 8
# 找不到返回-1
print(s.find('shit')) # -1
# index方法与find方法类似
# 找到了返回字符串中另一个字符串首字符的索引
print(s.index('or')) # 8
# 找不到引发异常
print(s.index('shit')) # ValueError: substring not found
在使用find和index方法时还可以通过方法的参数来指定查找的范围,也就是查找不必从索引为0的位置开始。find和index方法还有逆向查找(从后向前查找)的版本,分别是rfind和rindex,代码如下所示。
s = 'hello good world!'
# 从前向后查找字符o出现的位置(相当于第一次出现)
print(s.find('o')) # 4
# 从索引为5的位置开始查找字符o出现的位置
print(s.find('o', 5)) # 7
# 从后向前查找字符o出现的位置(相当于最后一次出现)
print(s.rfind('o')) # 12
性质判断
可以通过字符串的startswith、endswith来判断字符串是否以某个字符串开头和结尾;还可以用is开头的方法判断字符串的特征,这些方法都返回布尔值,代码如下所示。
s1 = 'hello, world!'
# startwith方法检查字符串是否以指定的字符串开头返回布尔值
print(s1.startswith('He')) # False
print(s1.startswith('hel')) # True
# endswith方法检查字符串是否以指定的字符串结尾返回布尔值
print(s1.endswith('!')) # True
s2 = 'abc123456'
# isdigit方法检查字符串是否由数字构成返回布尔值
print(s2.isdigit()) # False
# isalpha方法检查字符串是否以字母构成返回布尔值
print(s2.isalpha()) # False
# isalnum方法检查字符串是否以数字和字母构成返回布尔值
print(s2.isalnum()) # True
格式化字符串
在Python中,字符串类型可以通过center、ljust、rjust方法做居中、左对齐和右对齐的处理。如果要在字符串的左侧补零,也可以使用zfill方法。
s = 'hello, world'
# center方法以宽度20将字符串居中并在两侧填充*
print(s.center(20, '*')) # ****hello, world****
# rjust方法以宽度20将字符串右对齐并在左侧填充空格
print(s.rjust(20)) # hello, world
# ljust方法以宽度20将字符串左对齐并在右侧填充~
print(s.ljust(20, '~')) # hello, world~~~~~~~~
# 在字符串的左侧补零
print('33'.zfill(5)) # 00033
print('-33'.zfill(5)) # -0033
我们之前讲过,在用print函数输出字符串时,可以用下面的方式对字符串进行格式化。
a = 321
b = 123
print('%d * %d = %d' % (a, b, a * b))
当然,我们也可以用字符串的方法来完成字符串的格式,代码如下所示。
a = 321
b = 123
print('{0} * {1} = {2}'.format(a, b, a * b))
从Python 3.6开始,格式化字符串还有更为简洁的书写方式,就是在字符串前加上f来格式化字符串,在这种以f打头的字符串中,{变量名}是一个占位符,会被变量对应的值将其替换掉,代码如下所示。
a = 321
b = 123
print(f'{a} * {b} = {a * b}')
如果需要进一步控制格式化语法中变量值的形式,可以参照下面的表格来进行字符串格式化操作。
| 变量值 | 占位符 | 格式化结果 | 说明 |
|---|---|---|---|
3.1415926 | {:.2f} | '3.14' | 保留小数点后两位 |
3.1415926 | {:+.2f} | '+3.14' | 带符号保留小数点后两位 |
-1 | {:+.2f} | '-1.00' | 带符号保留小数点后两位 |
3.1415926 | {:.0f} | '3' | 不带小数 |
123 | {:0>10d} | '0000000123' | 左边补0,补够10位 |
123 | {:x<10d} | '123xxxxxxx' | 右边补x ,补够10位 |
123 | {:>10d} | ' 123' | 左边补空格,补够10位 |
123 | {:<10d} | '123 ' | 右边补空格,补够10位 |
123456789 | {:,} | '123,456,789' | 逗号分隔格式 |
0.123 | {:.2%} | '12.30%' | 百分比格式 |
123456789 | {:.2e} | '1.23e+08' | 科学计数法格式 |
修剪操作
字符串的strip方法可以帮我们获得将原字符串修剪掉左右两端空格之后的字符串。这个方法非常有实用价值,通常用来将用户输入中因为不小心键入的头尾空格去掉,strip方法还有lstrip和rstrip两个版本,相信从名字大家已经猜出来这两个方法是做什么用的。
s = ' jackfrued@126.com \t\r\n'
# strip方法获得字符串修剪左右两侧空格之后的字符串
print(s.strip()) # jackfrued@126.com
替换操作
如果希望用新的内容替换字符串中指定的内容,可以使用replace方法,代码如下所示。replace方法的第一个参数是被替换的内容,第二个参数是替换后的内容,还可以通过第三个参数指定替换的次数。
s = 'hello, world'
print(s.replace('o', '@')) # hell@, w@rld
print(s.replace('o', '@', 1)) # hell@, world
拆分/合并操作
可以使用字符串的split方法将一个字符串拆分为多个字符串(放在一个列表中),也可以使用字符串的join方法将列表中的多个字符串连接成一个字符串,代码如下所示。
s = 'I love you'
words = s.split()
print(words) # ['I', 'love', 'you']
print('#'.join(words)) # I#love#you
需要说明的是,split方法默认使用空格进行拆分,我们也可以指定其他的字符来拆分字符串,而且还可以指定最大拆分次数来控制拆分的效果,代码如下所示。
s = 'I#love#you#so#much'
words = s.split('#')
print(words) # ['I', 'love', 'you', 'so', 'much']
words = s.split('#', 3)
print(words) # ['I', 'love', 'you', 'so#much']
编码/解码操作
Python中除了字符串str类型外,还有一种表示二进制数据的字节串类型(bytes)。所谓字节串,就是由零个或多个字节组成的有限序列。通过字符串的encode方法,我们可以按照某种编码方式将字符串编码为字节串,我们也可以使用字节串的decode方法,将字节串解码为字符串,代码如下所示。
a = '骆昊'
b = a.encode('utf-8')
c = a.encode('gbk')
print(b, c) # b'\xe9\xaa\x86\xe6\x98\x8a' b'\xc2\xe6\xea\xbb'
print(b.decode('utf-8'))
print(c.decode('gbk'))
注意,如果编码和解码的方式不一致,会导致乱码问题(无法再现原始的内容)或引发UnicodeDecodeError错误导致程序崩溃。
其他方法
对于字符串类型来说,还有一个常用的操作是对字符串进行匹配检查,即检查字符串是否满足某种特定的模式。例如,一个网站对用户注册信息中用户名和邮箱的检查,就属于模式匹配检查。实现模式匹配检查的工具叫做正则表达式,Python语言通过标准库中的re模块提供了对正则表达式的支持,我们会在后续的课程中为大家讲解这个知识点。
简单的小结
知道如何表示和操作字符串对程序员来说是非常重要的,因为我们需要处理文本信息,Python中操作字符串可以用拼接、切片等运算符,也可以使用字符串类型的方法。
常用数据结构之集合
在学习了列表和元组之后,我们再来学习一种容器型的数据类型,它的名字叫集合(set)。说到集合这个词大家一定不会陌生,在数学课本上就有这个概念。通常我们对集合的定义是“把一定范围的、确定的、可以区别的事物当作一个整体来看待”,集合中的各个事物通常称为集合的元素。集合应该满足以下特性:
- 无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。
- 互异性:一个集合中,任何两个元素都是不相同的,即元素在集合中只能出现一次。
- 确定性:给定一个集合和一个任意元素,该元素要么属这个集合,要么不属于这个集合,二者必居其一,不允许有模棱两可的情况出现。
Python程序中的集合跟数学上的集合是完全一致的,需要强调的是上面所说的无序性和互异性。无序性说明集合中的元素并不像列中的元素那样一个挨着一个,可以通过索引实现随机访问(随机访问指的是给定一个有效的范围,随机抽取出一个数字,然后通过这个数字可以获取到对应的元素),所以Python中的集合肯定不能够支持索引运算。另外,集合的互异性决定了集合中不能有重复元素,这一点也是集合区别于列表的关键,说得更直白一些就是,Python中的集合类型会对其中的元素做去重处理。Python中的集合一定是支持in和not in成员运算的,这样就可以确定一个元素是否属于集合,也就是上面所说的集合的确定性。集合的成员运算在性能上要优于列表的成员运算,这是集合的底层存储特性(哈希存储)决定的,此处我们暂时不做讨论,大家可以先记下这个结论。
创建集合
在Python中,创建集合可以使用{}字面量语法,{}中需要至少有一个元素,因为没有元素的{}并不是空集合而是一个空字典,我们下一节课就会大家介绍字典的知识。当然,也可以使用内置函数set来创建一个集合,准确的说set并不是一个函数,而是创建集合对象的构造器,这个知识点我们很快也会讲到,现在不理解跳过它就可以了。要创建空集合可以使用set();也可以将其他序列转换成集合,例如:set('hello')会得到一个包含了4个字符的集合(重复的l会被去掉)。除了这两种方式,我们还可以使用生成式语法来创建集合,就像我们之前用生成式创建列表那样。要知道集合中有多少个元素,还是使用内置函数len;使用for循环可以实现对集合元素的遍历。
# 创建集合的字面量语法(重复元素不会出现在集合中)
set1 = {1, 2, 3, 3, 3, 2}
print(set1) # {1, 2, 3}
print(len(set1)) # 3
# 创建集合的构造器语法(后面会讲到什么是构造器)
set2 = set('hello')
print(set2) # {'h', 'l', 'o', 'e'}
# 将列表转换成集合(可以去掉列表中的重复元素)
set3 = set([1, 2, 3, 3, 2, 1])
print(set3) # {1, 2, 3}
# 创建集合的生成式语法(将列表生成式的[]换成{})
set4 = {num for num in range(1, 20) if num % 3 == 0 or num % 5 == 0}
print(set4) # {3, 5, 6, 9, 10, 12, 15, 18}
# 集合元素的循环遍历
for elem in set4:
print(elem)
需要提醒大家,集合中的元素必须是hashable类型。所谓hashable类型指的是能够计算出哈希码的数据类型,大家可以暂时将哈希码理解为和变量对应的唯一的ID值。通常不可变类型都是hashable类型,如整数、浮点、字符串、元组等,而可变类型都不是hashable类型,因为可变类型无法确定唯一的ID值,所以也就不能放到集合中。集合本身也是可变类型,所以集合不能够作为集合中的元素,这一点在使用集合的时候一定要注意。
集合的运算
Python为集合类型提供了非常丰富的运算符,主要包括:成员运算、交集运算、并集运算、差集运算、比较运算(相等性、子集、超集)等。
成员运算
可以通过成员运算in和not in 检查元素是否在集合中,代码如下所示。
set1 = {11, 12, 13, 14, 15}
print(10 in set1) # False
print(15 in set1) # True
set2 = {'Python', 'Java', 'Go', 'Swift'}
print('Ruby' in set2) # False
print('Java' in set2) # True
交并差运算
Python中的集合跟数学上的集合一样,可以进行交集、并集、差集等运算,而且可以通过运算符和方法调用两种方式来进行操作,代码如下所示。
set1 = {1, 2, 3, 4, 5, 6, 7}
set2 = {2, 4, 6, 8, 10}
# 交集
# 方法一: 使用 & 运算符
print(set1 & set2) # {2, 4, 6}
# 方法二: 使用intersection方法
print(set1.intersection(set2)) # {2, 4, 6}
# 并集
# 方法一: 使用 | 运算符
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8, 10}
# 方法二: 使用union方法
print(set1.union(set2)) # {1, 2, 3, 4, 5, 6, 7, 8, 10}
# 差集
# 方法一: 使用 - 运算符
print(set1 - set2) # {1, 3, 5, 7}
# 方法二: 使用difference方法
print(set1.difference(set2)) # {1, 3, 5, 7}
# 对称差
# 方法一: 使用 ^ 运算符
print(set1 ^ set2) # {1, 3, 5, 7, 8, 10}
# 方法二: 使用symmetric_difference方法
print(set1.symmetric_difference(set2)) # {1, 3, 5, 7, 8, 10}
# 方法三: 对称差相当于两个集合的并集减去交集
print((set1 | set2) - (set1 & set2)) # {1, 3, 5, 7, 8, 10}
通过上面的代码可以看出,对两个集合求交集,&运算符和intersection方法的作用是完全相同的,使用运算符的方式更直观而且代码也比较简短。相信大家对交集、并集、差集、对称差这几个概念是比较清楚的
集合的交集、并集、差集运算还可以跟赋值运算一起构成复合赋值运算,如下所示。
set1 = {1, 3, 5, 7}
set2 = {2, 4, 6}
# 将set1和set2求并集再赋值给set1
# 也可以通过set1.update(set2)来实现
set1 |= set2
print(set1) # {1, 2, 3, 4, 5, 6, 7}
set3 = {3, 6, 9}
# 将set1和set3求交集再赋值给set1
# 也可以通过set1.intersection_update(set3)来实现
set1 &= set3
print(set1) # {3, 6}
比较运算
两个集合可以用==和!=进行相等性判断,如果两个集合中的元素完全相同,那么==比较的结果就是True,否则就是False。如果集合A的任意一个元素都是集合B的元素,那么集合A称为集合B的子集,即对于$ \forall{a} \in {A}
,均有
,均有
,均有 {a} \in {B}
,则
,则
,则 {A} \subseteq {B} $,A是B的子集,反过来也可以称B是A的超集。如果A是B的子集且A不等于B,那么A就是B的真子集。Python为集合类型提供了判断子集和超集的运算符,其实就是我们非常熟悉的<和>运算符,代码如下所示。
set1 = {1, 3, 5}
set2 = {1, 2, 3, 4, 5}
set3 = set2
# <运算符表示真子集,<=运算符表示子集
print(set1 < set2, set1 <= set2) # True True
print(set2 < set3, set2 <= set3) # False True
# 通过issubset方法也能进行子集判断
print(set1.issubset(set2)) # True
# 反过来可以用issuperset或>运算符进行超集判断
print(set2.issuperset(set1)) # True
print(set2 > set1) # True
集合的方法
Python中的集合是可变类型,我们可以通过集合类型的方法为集合添加或删除元素。
# 创建一个空集合
set1 = set()
# 通过add方法添加元素
set1.add(33)
set1.add(55)
set1.update({1, 10, 100, 1000})
print(set1) # {33, 1, 100, 55, 1000, 10}
# 通过discard方法删除指定元素
set1.discard(100)
set1.discard(99)
print(set1) # {1, 10, 33, 55, 1000}
# 通过remove方法删除指定元素,建议先做成员运算再删除
# 否则元素如果不在集合中就会引发KeyError异常
if 10 in set1:
set1.remove(10)
print(set1) # {33, 1, 55, 1000}
# pop方法可以从集合中随机删除一个元素并返回该元素
print(set1.pop())
# clear方法可以清空整个集合
set1.clear()
print(set1) # set()
如果要判断两个集合有没有相同的元素可以使用isdisjoint方法,没有相同元素返回True,否则返回False,代码如下所示。
set1 = {'Java', 'Python', 'Go', 'Kotlin'}
set2 = {'Kotlin', 'Swift', 'Java', 'Objective-C', 'Dart'}
set3 = {'HTML', 'CSS', 'JavaScript'}
print(set1.isdisjoint(set2)) # False
print(set1.isdisjoint(set3)) # True
不可变集合
Python中还有一种不可变类型的集合,名字叫frozenset。set跟frozenset的区别就如同list跟tuple的区别,frozenset由于是不可变类型,能够计算出哈希码,因此它可以作为set中的元素。除了不能添加和删除元素,frozenset在其他方面跟set基本是一样的,下面的代码简单的展示了frozenset的用法。
set1 = frozenset({1, 3, 5, 7})
set2 = frozenset(range(1, 6))
print(set1 & set2) # frozenset({1, 3, 5})
print(set1 | set2) # frozenset({1, 2, 3, 4, 5, 7})
print(set1 - set2) # frozenset({7})
print(set1 < set2) # False
简单的小结
Python中的集合底层使用了哈希存储的方式,对于这一点我们暂时不做介绍,在后面的课程有需要的时候再为大家讲解集合的底层原理,现阶段大家只需要知道集合是一种容器,元素必须是hashable类型,与列表不同的地方在于集合中的元素没有序、不能用索引运算、不能重复。
常用数据结构之字典
迄今为止,我们已经为大家介绍了Python中的三种容器型数据类型,但是这些数据类型仍然不足以帮助我们解决所有的问题。例如,我们要保存一个人的信息,包括姓名、年龄、体重、单位地址、家庭住址、本人手机号、紧急联系人手机号等信息,你会发现我们之前学过的列表、元组和集合都不是最理想的选择。
person1 = ['王大锤', 55, 60, '科华北路62号', '中同仁路8号', '13122334455', '13800998877']
person2 = ('王大锤', 55, 60, '科华北路62号', '中同仁路8号', '13122334455', '13800998877')
person3 = {'王大锤', 55, 60, '科华北路62号', '中同仁路8号', '13122334455', '13800998877'}
集合肯定是最不合适的,因为集合有去重特性,如果一个人的年龄和体重相同,那么集合中就会少一项信息;同理,如果这个人的家庭住址和单位地址是相同的,那么集合中又会少一项信息。另一方面,虽然列表和元组可以把一个人的所有信息都保存下来,但是当你想要获取这个人的手机号时,你得先知道他的手机号是列表或元组中的第6个还是第7个元素;当你想获取一个人的家庭住址时,你还得知道家庭住址是列表或元组中的第几项。总之,在遇到上述的场景时,列表、元组、字典都不是最合适的选择,我们还需字典(dictionary)类型,这种数据类型最适合把相关联的信息组装到一起,并且可以帮助我们解决程序中为真实事物建模的问题。
说到字典这个词,大家一定不陌生,读小学的时候每个人基本上都有一本《新华字典》,如下图所示。

Python程序中的字典跟现实生活中的字典很像,它以键值对(键和值的组合)的方式把数据组织到一起,我们可以通过键找到与之对应的值并进行操作。就像《新华字典》中,每个字(键)都有与它对应的解释(值)一样,每个字和它的解释合在一起就是字典中的一个条目,而字典中通常包含了很多个这样的条目。
创建和使用字典
在Python中创建字典可以使用{}字面量语法,这一点跟上一节课讲的集合是一样的。但是字典的{}中的元素是以键值对的形式存在的,每个元素由:分隔的两个值构成,:前面是键,:后面是值,代码如下所示。
xinhua = {
'麓': '山脚下',
'路': '道,往来通行的地方;方面,地区:南~货,外~货;种类:他俩是一~人',
'蕗': '甘草的别名',
'潞': '潞水,水名,即今山西省的浊漳河;潞江,水名,即云南省的怒江'
}
print(xinhua)
person = {
'name': '王大锤', 'age': 55, 'weight': 60, 'office': '科华北路62号',
'home': '中同仁路8号', 'tel': '13122334455', 'econtact': '13800998877'
}
print(person)
通过上面的代码,相信大家已经看出来了,用字典来保存一个人的信息远远优于使用列表或元组,因为我们可以用:前面的键来表示条目的含义,而:后面就是这个条目所对应的值。
当然,如果愿意,我们也可以使用内置函数dict或者是字典的生成式语法来创建字典,代码如下所示。
# dict函数(构造器)中的每一组参数就是字典中的一组键值对
person = dict(name='王大锤', age=55, weight=60, home='中同仁路8号')
print(person) # {'name': '王大锤', 'age': 55, 'weight': 60, 'home': '中同仁路8号'}
# 可以通过Python内置函数zip压缩两个序列并创建字典
items1 = dict(zip('ABCDE', '12345'))
print(items1) # {'A': '1', 'B': '2', 'C': '3', 'D': '4', 'E': '5'}
items2 = dict(zip('ABCDE', range(1, 10)))
print(items2) # {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5}
# 用字典生成式语法创建字典
items3 = {x: x ** 3 for x in range(1, 6)}
print(items3) # {1: 1, 2: 8, 3: 27, 4: 64, 5: 125}
想知道字典中一共有多少组键值对,仍然是使用len函数;如果想对字典进行遍历,可以用for循环,但是需要注意,for循环只是对字典的键进行了遍历,不过没关系,在讲完字典的运算后,我们可以通过字典的键获取到和这个键对应的值。
person = {'name': '王大锤', 'age': 55, 'weight': 60, 'office': '科华北路62号'}
print(len(person)) # 4
for key in person:
print(key)
字典的运算
对于字典类型来说,成员运算和索引运算肯定是最为重要的,前者可以判定指定的键在不在字典中,后者可以通过键获取对应的值或者向字典中加入新的键值对。值得注意的是,字典的索引不同于列表的索引,列表中的元素因为有属于自己有序号,所以列表的索引是一个整数;字典中因为保存的是键值对,所以字典的索引是键值对中的键,通过索引操作可以修改原来的值或者向字典中存入新的键值对。需要特别提醒大家注意的是,字典中的键必须是不可变类型,例如整数(int)、浮点数(float)、字符串(str)、元组(tuple)等类型的值;显然,列表(list)和集合(set)是不能作为字典中的键的,当然字典类型本身也不能再作为字典中的键,因为字典也是可变类型,但是字典可以作为字典中的值。关于可变类型不能作为字典中的键的原因,我们在后面的课程中再为大家详细说明。这里,我们先看看下面的代码,了解一下字典的成员运算和索引运算。
person = {'name': '王大锤', 'age': 55, 'weight': 60, 'office': '科华北路62号'}
# 检查name和tel两个键在不在person字典中
print('name' in person, 'tel' in person) # True False
# 通过age修将person字典中对应的值修改为25
if 'age' in person:
person['age'] = 25
# 通过索引操作向person字典中存入新的键值对
person['tel'] = '13122334455'
person['signature'] = '你的男朋友是一个盖世垃圾,他会踏着五彩祥云去迎娶你的闺蜜'
print('name' in person, 'tel' in person) # True True
# 检查person字典中键值对的数量
print(len(person)) # 6
# 对字典的键进行循环并通索引运算获取键对应的值
for key in person:
print(f'{key}: {person[key]}')
需要注意,在通过索引运算获取字典中的值时,如指定的键没有在字典中,将会引发KeyError异常。
字典的方法
字典类型的方法基本上都跟字典的键值对操作相关,可以通过下面的例子来了解这些方法的使用。例如,我们要用一个字典来保存学生的信息,我们可以使用学生的学号作为字典中的键,通过学号做索引运算就可以得到对应的学生;我们可以把字典的值也做成一个字典,这样就可以用多组键值对分别存储学生的姓名、性别、年龄、籍贯等信息,代码如下所示。
# 字典中的值又是一个字典(嵌套的字典)
students = {
1001: {'name': '狄仁杰', 'sex': True, 'age': 22, 'place': '山西大同'},
1002: {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'},
1003: {'name': '武则天', 'sex': False, 'age': 20, 'place': '四川广元'}
}
# 使用get方法通过键获取对应的值,如果取不到不会引发KeyError异常而是返回None或设定的默认值
print(students.get(1002)) # {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'}
print(students.get(1005)) # None
print(students.get(1005, {'name': '无名氏'})) # {'name': '无名氏'}
# 获取字典中所有的键
print(students.keys()) # dict_keys([1001, 1002, 1003])
# 获取字典中所有的值
print(students.values()) # dict_values([{...}, {...}, {...}])
# 获取字典中所有的键值对
print(students.items()) # dict_items([(1001, {...}), (1002, {....}), (1003, {...})])
# 对字典中所有的键值对进行循环遍历
for key, value in students.items():
print(key, '--->', value)
# 使用pop方法通过键删除对应的键值对并返回该值
stu1 = students.pop(1002)
print(stu1) # {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'}
print(len(students)) # 2
# stu2 = students.pop(1005) # KeyError: 1005
stu2 = students.pop(1005, {})
print(stu2) # {}
# 使用popitem方法删除字典中最后一组键值对并返回对应的二元组
# 如果字典中没有元素,调用该方法将引发KeyError异常
key, value = students.popitem()
print(key, value) # 1003 {'name': '武则天', 'sex': False, 'age': 20, 'place': '四川广元'}
# 如果这个键在字典中存在,setdefault返回原来与这个键对应的值
# 如果这个键在字典中不存在,向字典中添加键值对,返回第二个参数的值,默认为None
result = students.setdefault(1005, {'name': '方启鹤', 'sex': True})
print(result) # {'name': '方启鹤', 'sex': True}
print(students) # {1001: {...}, 1005: {...}}
# 使用update更新字典元素,相同的键会用新值覆盖掉旧值,不同的键会添加到字典中
others = {
1005: {'name': '乔峰', 'sex': True, 'age': 32, 'place': '北京大兴'},
1010: {'name': '王语嫣', 'sex': False, 'age': 19},
1008: {'name': '钟灵', 'sex': False}
}
students.update(others)
print(students) # {1001: {...}, 1005: {...}, 1010: {...}, 1008: {...}}
跟列表一样,从字典中删除元素也可以使用del关键字,在删除元素的时候如果指定的键索引不到对应的值,一样会引发KeyError异常,具体的做法如下所示。
person = {'name': '王大锤', 'age': 25, 'sex': True}
del person['age']
print(person) # {'name': '王大锤', 'sex': True}
字典的应用
我们通过几个简单的例子来讲解字典的应用。
例子1:输入一段话,统计每个英文字母出现的次数。
sentence = input('请输入一段话: ')
counter = {}
for ch in sentence:
if 'A' <= ch <= 'Z' or 'a' <= ch <= 'z':
counter[ch] = counter.get(ch, 0) + 1
for key, value in counter.items():
print(f'字母{key}出现了{value}次.')
例子2:在一个字典中保存了股票的代码和价格,找出股价大于100元的股票并创建一个新的字典。
说明:可以用字典的生成式语法来创建这个新字典。
stocks = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
stocks2 = {key: value for key, value in stocks.items() if value > 100}
print(stocks2)
简单的小结
Python程序中的字典跟现实生活中字典非常像,允许我们以键值对的形式保存数据,再通过键索引对应的值。这是一种非常有利于数据检索的数据类型,底层原理我们在后续的课程中为大家讲解。再次提醒大家注意,字典中的键必须是不可变类型,字典中的值可以是任意类型。
函数模块
在讲解本节课的内容之前,我们先来研究一道数学题,请说出下面的方程有多少组正整数解。
x
1
+
x
2
+
x
3
+
x
4
=
8
x_1 + x_2 + x_3 + x_4 = 8
x1+x2+x3+x4=8
你可能已经想到了,这个问题其实等同于将8个苹果分成四组且每组至少一个苹果有多少种方案,因此该问题还可以进一步等价于在分隔8个苹果的7个空隙之间插入三个隔板将苹果分成四组有多少种方案,也就是从7个空隙选出3个空隙放入隔板的组合数,所以答案是$ C_7^3=35 $。组合数的计算公式如下所示。
C
M
N
=
M
!
N
!
(
M
−
N
)
!
C_M^N = \frac {M!} {N!(M-N)!}
CMN=N!(M−N)!M!
根据我们前面学习的知识,可以用循环做累乘的方式来计算阶乘,那么通过下面的Python代码我们就可以计算出组合数$ C_M^N $的值,代码如下所示。
"""
输入M和N计算C(M,N)
Version: 0.1
Author: 骆昊
"""
m = int(input('m = '))
n = int(input('n = '))
# 计算m的阶乘
fm = 1
for num in range(1, m + 1):
fm *= num
# 计算n的阶乘
fn = 1
for num in range(1, n + 1):
fn *= num
# 计算m-n的阶乘
fk = 1
for num in range(1, m - n + 1):
fk *= num
# 计算C(M,N)的值
print(fm // fn // fk)
函数的作用
不知大家是否注意到,上面的代码中我们做了三次求阶乘,虽然m、n、m - n的值各不相同,但是三段代码并没有实质性的区别,属于重复代码。世界级的编程大师Martin Fowler先生曾经说过:“代码有很多种坏味道,重复是最坏的一种!”。要写出高质量的代码首先要解决的就是重复代码的问题。对于上面的代码来说,我们可以将计算阶乘的功能封装到一个称为“函数”的代码块中,在需要计算阶乘的地方,我们只需要“调用函数”就可以了。
定义函数
数学上的函数通常形如y = f(x)或者z = g(x, y)这样的形式,在y = f(x)中,f是函数的名字,x是函数的自变量,y是函数的因变量;而在z = g(x, y)中,g是函数名,x和y是函数的自变量,z是函数的因变量。Python中的函数跟这个结构是一致的,每个函数都有自己的名字、自变量和因变量。我们通常把Python中函数的自变量称为函数的参数,而因变量称为函数的返回值。
在Python中可以使用def关键字来定义函数,和变量一样每个函数也应该有一个漂亮的名字,命名规则跟变量的命名规则是一致的(赶紧想一想我们之前讲过的变量的命名规则)。在函数名后面的圆括号中可以放置传递给函数的参数,就是我们刚才说到的函数的自变量,而函数执行完成后我们会通过return关键字来返回函数的执行结果,就是我们刚才说的函数的因变量。一个函数要执行的代码块(要做的事情)也是通过缩进的方式来表示的,跟之前分支和循环结构的代码块是一样的。大家不要忘了def那一行的最后面还有一个:,之前提醒过大家,那是在英文输入法状态下输入的冒号。
我们可以通过函数对上面的代码进行重构。**所谓重构,是在不影响代码执行结果的前提下对代码的结构进行调整。**重构之后的代码如下所示。
"""
输入M和N计算C(M,N)
"""
# 定义函数:def是定义函数的关键字、fac是函数名,num是参数(自变量)
def fac(num):
"""求阶乘"""
result = 1
for n in range(1, num + 1):
result *= n
# 返回num的阶乘(因变量)
return result
m = int(input('m = '))
n = int(input('n = '))
# 当需要计算阶乘的时候不用再写重复的代码而是直接调用函数fac
# 调用函数的语法是在函数名后面跟上圆括号并传入参数
print(fac(m) // fac(n) // fac(m - n))
说明:事实上,Python标准库的
math模块中有一个名为factorial的函数已经实现了求阶乘的功能,我们可以直接使用该函数来计算阶乘。将来我们使用的函数,要么是自定义的函数,要么是Python标准库或者三方库中提供的函数。
函数的参数
参数的默认值
如果函数中没有return语句,那么函数默认返回代表空值的None。另外,在定义函数时,函数也可以没有自变量,但是函数名后面的圆括号是必须有的。Python中还允许函数的参数拥有默认值,我们可以把之前讲过的一个例子“CRAPS赌博游戏”中摇色子获得点数的功能封装成函数,代码如下所示。
"""
参数的默认值
"""
from random import randint
# 定义摇色子的函数,n表示色子的个数,默认值为2
def roll_dice(n=2):
"""摇色子返回总的点数"""
total = 0
for _ in range(n):
total += randint(1, 6)
return total
# 如果没有指定参数,那么n使用默认值2,表示摇两颗色子
print(roll_dice())
# 传入参数3,变量n被赋值为3,表示摇三颗色子获得点数
print(roll_dice(3))
我们再来看一个更为简单的例子。
def add(a=0, b=0, c=0):
"""三个数相加求和"""
return a + b + c
# 调用add函数,没有传入参数,那么a、b、c都使用默认值0
print(add()) # 0
# 调用add函数,传入一个参数,那么该参数赋值给变量a, 变量b和c使用默认值0
print(add(1)) # 1
# 调用add函数,传入两个参数,1和2分别赋值给变量a和b,变量c使用默认值0
print(add(1, 2)) # 3
# 调用add函数,传入三个参数,分别赋值给a、b、c三个变量
print(add(1, 2, 3)) # 6
# 传递参数时可以不按照设定的顺序进行传递,但是要用“参数名=参数值”的形式
print(add(c=50, a=100, b=200)) # 350
注意:带默认值的参数必须放在不带默认值的参数之后,否则将产生
SyntaxError错误,错误消息是:non-default argument follows default argument,翻译成中文的意思是“没有默认值的参数放在了带默认值的参数后面”。
可变参数
接下来,我们还可以实现一个对任意多个数求和的add函数,因为Python语言中的函数可以通过星号表达式语法来支持可变参数。所谓可变参数指的是在调用函数时,可以向函数传入0个或任意多个参数。将来我们以团队协作的方式开发商业项目时,很有可能要设计函数给其他人使用,但有的时候我们并不知道函数的调用者会向该函数传入多少个参数,这个时候可变参数就可以派上用场。下面的代码演示了用可变参数实现对任意多个数求和的add函数。
"""
可变参数
"""
# 用星号表达式来表示args可以接收0个或任意多个参数
def add(*args):
total = 0
# 可变参数可以放在for循环中取出每个参数的值
for val in args:
if type(val) in (int, float):
total += val
return total
# 在调用add函数时可以传入0个或任意多个参数
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
print(add(1, 3, 5, 7, 9))
用模块管理函数
不管用什么样的编程语言来写代码,给变量、函数起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个.py文件中定义了两个同名的函数,如下所示。
def foo():
print('hello, world!')
def foo():
print('goodbye, world!')
foo() # 大家猜猜调用foo函数会输出什么
当然上面的这种情况我们很容易就能避免,但是如果项目是团队协作多人开发的时候,团队中可能有多个程序员都定义了名为foo的函数,这种情况下怎么解决命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块再使用完全限定名的调用方式就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
def foo():
print('hello, world!')
module2.py
def foo():
print('goodbye, world!')
test.py
import module1
import module2
# 用“模块名.函数名”的方式(完全限定名)调用函数,
module1.foo() # hello, world!
module2.foo() # goodbye, world!
在导入模块时,还可以使用as关键字对模块进行别名,这样我们可以使用更为简短的完全限定名。
test.py
import module1 as m1
import module2 as m2
m1.foo() # hello, world!
m2.foo() # goodbye, world!
上面的代码我们导入了定义函数的模块,我们也可以使用from...import...语法从模块中直接导入需要使用的函数,代码如下所示。
test.py
from module1 import foo
foo() # hello, world!
from module2 import foo
foo() # goodbye, world!
但是,如果我们如果从两个不同的模块中导入了同名的函数,后导入的函数会覆盖掉先前的导入,就像下面的代码中,调用foo会输出hello, world!,因为我们先导入了module2的foo,后导入了module1的foo 。如果两个from...import...反过来写,就是另外一番光景了。
test.py
from module2 import foo
from module1 import foo
foo() # hello, world!
如果想在上面的代码中同时使用来自两个模块中的foo函数也是有办法的,大家可能已经猜到了,还是用as关键字对导入的函数进行别名,代码如下所示。
test.py
from module1 import foo as f1
from module2 import foo as f2
f1() # hello, world!
f2() # goodbye, world!
标准库中的模块和函数
Python标准库中提供了大量的模块和函数来简化我们的开发工作,我们之前用过的random模块就为我们提供了生成随机数和进行随机抽样的函数;而time模块则提供了和时间操作相关的函数;上面求阶乘的函数在Python标准库中的math模块中已经有了,实际开发中并不需要我们自己编写,而math模块中还包括了计算正弦、余弦、指数、对数等一系列的数学函数。随着我们进一步的学习Python编程知识,我们还会用到更多的模块和函数。
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数,这些内置函数都是很有用也是最常用的,下面的表格列出了一部分的内置函数。
| 函数 | 说明 |
|---|---|
abs | 返回一个数的绝对值,例如:abs(-1.3)会返回1.3。 |
bin | 把一个整数转换成以'0b'开头的二进制字符串,例如:bin(123)会返回'0b1111011'。 |
chr | 将Unicode编码转换成对应的字符,例如:chr(8364)会返回'€'。 |
hex | 将一个整数转换成以'0x'开头的十六进制字符串,例如:hex(123)会返回'0x7b'。 |
input | 从输入中读取一行,返回读到的字符串。 |
len | 获取字符串、列表等的长度。 |
max | 返回多个参数或一个可迭代对象中的最大值,例如:max(12, 95, 37)会返回95。 |
min | 返回多个参数或一个可迭代对象中的最小值,例如:min(12, 95, 37)会返回12。 |
oct | 把一个整数转换成以'0o'开头的八进制字符串,例如:oct(123)会返回'0o173'。 |
open | 打开一个文件并返回文件对象。 |
ord | 将字符转换成对应的Unicode编码,例如:ord('€')会返回8364。 |
pow | 求幂运算,例如:pow(2, 3)会返回8;pow(2, 0.5)会返回1.4142135623730951。 |
print | 打印输出。 |
range | 构造一个范围序列,例如:range(100)会产生0到99的整数序列。 |
round | 按照指定的精度对数值进行四舍五入,例如:round(1.23456, 4)会返回1.2346。 |
sum | 对一个序列中的项从左到右进行求和运算,例如:sum(range(1, 101))会返回5050。 |
type | 返回对象的类型,例如:type(10)会返回int;而 type('hello')会返回str。 |
简单的小结
函数是对功能相对独立且会重复使用的代码的封装。学会使用定义和使用函数,就能够写出更为优质的代码。当然,Python语言的标准库中已经为我们提供了大量的模块和常用的函数,用好这些模块和函数就能够用更少的代码做更多的事情;如果这些模块和函数不能满足我们的要求,我们就需要自定义函数,然后用模块的概念来管理这些自定义函数。
函数应用
接下来我们通过一些案例来为大家讲解函数的应用。
经典小案例
案例1:设计一个生成验证码的函数。
说明:验证码由数字和英文大小写字母构成,长度可以用参数指定。
import random
import string
ALL_CHARS = string.digits + string.ascii_letters
def generate_code(code_len=4):
"""生成指定长度的验证码
:param code_len: 验证码的长度(默认4个字符)
:return: 由大小写英文字母和数字构成的随机验证码字符串
"""
return ''.join(random.choices(ALL_CHARS, k=code_len))
可以用下面的代码生成10组随机验证码来测试上面的函数。
for _ in range(10):
print(generate_code())
说明:
random模块的sample和choices函数都可以实现随机抽样,sample实现无放回抽样,这意味着抽样取出的字符是不重复的;choices实现有放回抽样,这意味着可能会重复选中某些字符。这两个函数的第一个参数代表抽样的总体,而参数k代表抽样的数量。
案例2:设计一个函数返回给定文件的后缀名。
说明:文件名通常是一个字符串,而文件的后缀名指的是文件名中最后一个
.后面的部分,也称为文件的扩展名,它是某些操作系统用来标记文件类型的一种机制,例如在Windows系统上,后缀名exe表示这是一个可执行程序,而后缀名txt表示这是一个纯文本文件。需要注意的是,在Linux和macOS系统上,文件名可以以.开头,表示这是一个隐藏文件,像.gitignore这样的文件名,.后面并不是后缀名,这个文件没有后缀名或者说后缀名为''。
def get_suffix(filename, ignore_dot=True):
"""获取文件名的后缀名
:param filename: 文件名
:param ignore_dot: 是否忽略后缀名前面的点
:return: 文件的后缀名
"""
# 从字符串中逆向查找.出现的位置
pos = filename.rfind('.')
# 通过切片操作从文件名中取出后缀名
if pos <= 0:
return ''
return filename[pos + 1:] if ignore_dot else filename[pos:]
可以用下面的代码对上面的函数做一个简单的测验。
print(get_suffix('readme.txt')) # txt
print(get_suffix('readme.txt.md')) # md
print(get_suffix('.readme')) #
print(get_suffix('readme.')) #
print(get_suffix('readme')) #
上面的get_suffix函数还有一个更为便捷的实现方式,就是直接使用os.path模块的splitext函数,这个函数会将文件名拆分成带路径的文件名和扩展名两个部分,然后返回一个二元组,二元组中的第二个元素就是文件的后缀名(包含.),如果要去掉后缀名中的.,可以做一个字符串的切片操作,代码如下所示。
from os.path import splitext
def get_suffix(filename, ignore_dot=True):
return splitext(filename)[1][1:]
思考:如果要给上面的函数增加一个参数,用来控制文件的后缀名是否包含
.,应该怎么做?
案例3:写一个判断给定的正整数是不是质数的函数。
def is_prime(num: int) -> bool:
"""判断一个正整数是不是质数
:param num: 正整数
:return: 如果是质数返回True,否则返回False
"""
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return num != 1
案例4:写出计算两个正整数最大公约数和最小公倍数的函数。
代码一:
def gcd_and_lcm(x: int, y: int) -> int:
"""求最大公约数和最小公倍数"""
a, b = x, y
while b % a != 0:
a, b = b % a, a
return a, x * y // a
代码二:
def gcd(x: int, y: int) -> int:
"""求最大公约数"""
while y % x != 0:
x, y = y % x, x
return x
def lcm(x: int, y: int) -> int:
"""求最小公倍数"""
return x * y // gcd(x, y)
思考:请比较上面的代码一和代码二,想想哪种做法是更好的选择。
案例5:写出计算一组样本数据描述性统计信息的函数。
import math
def ptp(data):
"""求极差(全距)"""
return max(data) - min(data)
def average(data):
"""求均值"""
return sum(data) / len(data)
def variance(data):
"""求方差"""
x_bar = average(data)
temp = [(num - x_bar) ** 2 for num in data]
return sum(temp) / (len(temp) - 1)
def standard_deviation(data):
"""求标准差"""
return math.sqrt(variance(data))
def median(data):
"""找中位数"""
temp, size = sorted(data), len(data)
if size % 2 != 0:
return temp[size // 2]
else:
return average(temp[size // 2 - 1:size // 2 + 1])
简单的小结
在写代码尤其是开发商业项目的时候,一定要有意识的将相对独立且重复出现的功能封装成函数,这样不管是自己还是团队的其他成员都可以通过调用函数的方式来使用这些功能。
函数进阶
前面我们讲到了关于函数的知识,我们还讲到过Python中常用的数据类型,这些类型的变量都可以作为函数的参数或返回值,用好函数还可以让我们做更多的事情。
关键字参数
下面是一个判断传入的三条边长能否构成三角形的函数,在调用函数传入参数时,我们可以指定参数名,也可以不指定参数名,代码如下所示。
def is_triangle(a, b, c):
print(f'a = {a}, b = {b}, c = {c}')
return a + b > c and b + c > a and a + c > b
# 调用函数传入参数不指定参数名按位置对号入座
print(is_triangle(1, 2, 3))
# 调用函数通过“参数名=参数值”的形式按顺序传入参数
print(is_triangle(a=1, b=2, c=3))
# 调用函数通过“参数名=参数值”的形式不按顺序传入参数
print(is_triangle(c=3, a=1, b=2))
在没有特殊处理的情况下,函数的参数都是位置参数,也就意味着传入参数的时候对号入座即可,如上面代码的第7行所示,传入的参数值1、2、3会依次赋值给参数a、b、c。当然,也可以通过参数名=参数值的方式传入函数所需的参数,因为指定了参数名,传入参数的顺序可以进行调整,如上面代码的第9行和第11行所示。
调用函数时,如果希望函数的调用者必须以参数名=参数值的方式传参,可以用命名关键字参数(keyword-only argument)取代位置参数。所谓命名关键字参数,是在函数的参数列表中,写在*之后的参数,代码如下所示。
def is_triangle(*, a, b, c):
print(f'a = {a}, b = {b}, c = {c}')
return a + b > c and b + c > a and a + c > b
# TypeError: is_triangle() takes 0 positional arguments but 3 were given
# print(is_triangle(3, 4, 5))
# 传参时必须使用“参数名=参数值”的方式,位置不重要
print(is_triangle(a=3, b=4, c=5))
print(is_triangle(c=5, b=4, a=3))
注意:上面的
is_triangle函数,参数列表中的*是一个分隔符,*前面的参数都是位置参数,而*后面的参数就是命名关键字参数。
我们之前讲过在函数的参数列表中可以使用可变参数*args来接收任意数量的参数,但是我们需要看看,*args是否能够接收带参数名的参数。
def calc(*args):
result = 0
for arg in args:
if type(arg) in (int, float):
result += arg
return result
print(calc(a=1, b=2, c=3))
执行上面的代码会引发TypeError错误,错误消息为calc() got an unexpected keyword argument 'a',由此可见,*args并不能处理带参数名的参数。我们在设计函数时,如果既不知道调用者会传入的参数个数,也不知道调用者会不会指定参数名,那么同时使用可变参数和关键字参数。关键字参数会将传入的带参数名的参数组装成一个字典,参数名就是字典中键值对的键,而参数值就是字典中键值对的值,代码如下所示。
def calc(*args, **kwargs):
result = 0
for arg in args:
if type(arg) in (int, float):
result += arg
for value in kwargs.values():
if type(value) in (int, float):
result += value
return result
print(calc()) # 0
print(calc(1, 2, 3)) # 6
print(calc(a=1, b=2, c=3)) # 6
print(calc(1, 2, c=3, d=4)) # 10
提示:不带参数名的参数(位置参数)必须出现在带参数名的参数(关键字参数)之前,否则将会引发异常。例如,执行
calc(1, 2, c=3, d=4, 5)将会引发SyntaxError错误,错误消息为positional argument follows keyword argument,翻译成中文意思是“位置参数出现在关键字参数之后”。
高阶函数的用法
在前面几节课中,我们讲到了面向对象程序设计,在面向对象的世界中,一切皆为对象,所以类和函数也是对象。函数的参数和返回值可以是任意类型的对象,这就意味着函数本身也可以作为函数的参数或返回值,这就是所谓的高阶函数。
如果我们希望上面的calc函数不仅仅可以做多个参数求和,还可以做多个参数求乘积甚至更多的二元运算,我们就可以使用高阶函数的方式来改写上面的代码,将加法运算从函数中移除掉,具体的做法如下所示。
def calc(*args, init_value, op, **kwargs):
result = init_value
for arg in args:
if type(arg) in (int, float):
result = op(result, arg)
for value in kwargs.values():
if type(value) in (int, float):
result = op(result, value)
return result
注意,上面的函数增加了两个参数,其中init_value代表运算的初始值,op代表二元运算函数。经过改造的calc函数不仅仅可以实现多个参数的累加求和,也可以实现多个参数的累乘运算,代码如下所示。
def add(x, y):
return x + y
def mul(x, y):
return x * y
print(calc(1, 2, 3, init_value=0, op=add, x=4, y=5)) # 15
print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=mul)) # 120
通过对高阶函数的运用,calc函数不再和加法运算耦合,所以灵活性和通用性会变强,这是一种解耦合的编程技巧,但是最初学者来说可能会稍微有点难以理解。需要注意的是,将函数作为参数和调用函数是有显著的区别的,调用函数需要在函数名后面跟上圆括号,而把函数作为参数时只需要函数名即可。上面的代码也可以不用定义add和mul函数,因为Python标准库中的operator模块提供了代表加法运算的add和代表乘法运算的mul函数,我们直接使用即可,代码如下所示。
import operator
print(calc(1, 2, 3, init_value=0, op=operator.add, x=4, y=5)) # 15
print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=operator.mul)) # 120
Python内置函数中有不少高阶函数,我们前面提到过的filter和map函数就是高阶函数,前者可以实现对序列中元素的过滤,后者可以实现对序列中元素的映射,例如我们要去掉一个整数列表中的奇数,并对所有的偶数求平方得到一个新的列表,就可以直接使用这两个函数来做到,具体的做法是如下所示。
def is_even(num):
return num % 2 == 0
def square(num):
return num ** 2
numbers1 = [35, 12, 8, 99, 60, 52]
numbers2 = list(map(square, filter(is_even, numbers1)))
print(numbers2) # [144, 64, 3600, 2704]
当然,要完成上面代码的功能,也可以使用列表生成式,列表生成式的做法更为简单优雅。
numbers1 = [35, 12, 8, 99, 60, 52]
numbers2 = [num ** 2 for num in numbers1 if num % 2 == 0]
print(numbers2) # [144, 64, 3600, 2704]
Lambda函数
在使用高阶函数的时候,如果作为参数或者返回值的函数本身非常简单,一行代码就能够完成,那么我们可以使用Lambda函数来表示。Python中的Lambda函数是没有的名字函数,所以很多人也把它叫做匿名函数,匿名函数只能有一行代码,代码中的表达式产生的运算结果就是这个匿名函数的返回值。上面代码中的is_even和square函数都只有一行代码,我们可以用Lambda函数来替换掉它们,代码如下所示。
numbers1 = [35, 12, 8, 99, 60, 52]
numbers2 = list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers1)))
print(numbers2) # [144, 64, 3600, 2704]
通过上面的代码可以看出,定义Lambda函数的关键字是lambda,后面跟函数的参数,如果有多个参数用逗号进行分隔;冒号后面的部分就是函数的执行体,通常是一个表达式,表达式的运算结果就是Lambda函数的返回值,不需要写return 关键字。
如果需要使用加减乘除这种简单的二元函数,也可以用Lambda函数来书写,例如调用上面的calc函数时,可以通过传入Lambda函数来作为op参数的参数值。当然,op参数也可以有默认值,例如我们可以用一个代表加法运算的Lambda函数来作为op参数的默认值。
def calc(*args, init_value=0, op=lambda x, y: x + y, **kwargs):
result = init_value
for arg in args:
if type(arg) in (int, float):
result = op(result, arg)
for value in kwargs.values():
if type(value) in (int, float):
result = op(result, value)
return result
# 调用calc函数,使用init_value和op的默认值
print(calc(1, 2, 3, x=4, y=5)) # 15
# 调用calc函数,通过lambda函数给op参数赋值
print(calc(1, 2, 3, x=4, y=5, init_value=1, op=lambda x, y: x * y)) # 120
提示:注意上面的代码中的
calc函数,它同时使用了可变参数、关键字参数、命名关键字参数,其中命名关键字参数要放在可变参数和关键字参数之间,传参时先传入可变参数,关键字参数和命名关键字参数的先后顺序并不重要。
有很多函数在Python中用一行代码就能实现,我们可以用Lambda函数来定义这些函数,调用Lambda函数就跟调用普通函数一样,代码如下所示。
import operator, functools
# 一行代码定义求阶乘的函数
fac = lambda num: functools.reduce(operator.mul, range(1, num + 1), 1)
# 一行代码定义判断素数的函数
is_prime = lambda x: x > 1 and all(map(lambda f: x % f, range(2, int(x ** 0.5) + 1)))
# 调用Lambda函数
print(fac(10)) # 3628800
print(is_prime(9)) # False
提示1:上面使用的
reduce函数是Python标准库functools模块中的函数,它可以实现对数据的归约操作,通常情况下,过滤(filter)、映射(map)和归约(reduce)是处理数据中非常关键的三个步骤,而Python的标准库也提供了对这三个操作的支持。提示2:上面使用的
all函数是Python内置函数,如果传入的序列中所有布尔值都是True,all函数就返回True,否则all函数就返回False。
简单的小结
Python中的函数可以使用可变参数*args和关键字参数**kwargs来接收任意数量的参数,而且传入参数时可以带上参数名也可以没有参数名,可变参数会被处理成一个元组,而关键字参数会被处理成一个字典。Python中的函数是一等函数,可以赋值给变量,也可以作为函数的参数和返回值,这也就意味着我们可以在Python中使用高阶函数。如果我们要定义的函数非常简单,只有一行代码且不需要函数名,可以使用Lambda函数(匿名函数)。
函数高级应用
在上一节课中,我们已经对函数进行了更为深入的研究,还探索了Python中的高阶函数和Lambda函数。在这些知识的基础上,这节课我们为大家分享两个和函数相关的内容,一个是装饰器,一个是函数的递归调用。
装饰器
装饰器是Python中用一个函数装饰另外一个函数或类并为其提供额外功能的语法现象。装饰器本身是一个函数,它的参数是被装饰的函数或类,它的返回值是一个带有装饰功能的函数。很显然,装饰器是一个高阶函数,它的参数和返回值都是函数。下面我们先通过一个简单的例子来说明装饰器的写法和作用,假设已经有名为downlaod和upload的两个函数,分别用于文件的上传和下载,下面的代码用休眠一段随机时间的方式模拟了下载和上传需要花费的时间,并没有联网做上传下载。
说明:用Python语言实现联网的上传下载也很简单,继续你的学习,这个环节很快就会来到。
import random
import time
def download(filename):
print(f'开始下载{filename}.')
time.sleep(random.randint(2, 6))
print(f'{filename}下载完成.')
def upload(filename):
print(f'开始上传{filename}.')
time.sleep(random.randint(4, 8))
print(f'{filename}上传完成.')
download('MySQL从删库到跑路.avi')
upload('Python从入门到住院.pdf')
现在我们希望知道调用download和upload函数做文件上传下载到底用了多少时间,这个应该如何实现呢?相信很多小伙伴已经想到了,我们可以在函数开始执行的时候记录一个时间,在函数调用结束后记录一个时间,两个时间相减就可以计算出下载或上传的时间,代码如下所示。
start = time.time()
download('MySQL从删库到跑路.avi')
end = time.time()
print(f'花费时间: {end - start:.3f}秒')
start = time.time()
upload('Python从入门到住院.pdf')
end = time.time()
print(f'花费时间: {end - start:.3f}秒')
通过上面的代码,我们可以得到下载和上传花费的时间,但不知道大家是否注意到,上面记录时间、计算和显示执行时间的代码都是重复代码。有编程经验的人都知道,重复的代码是万恶之源,那么有没有办法在不写重复代码的前提下,用一种简单优雅的方式记录下函数的执行时间呢?在Python中,装饰器就是解决这类问题的最佳选择。我们可以把记录函数执行时间的功能封装到一个装饰器中,在有需要的地方直接使用这个装饰器就可以了,代码如下所示。
import time
# 定义装饰器函数,它的参数是被装饰的函数或类
def record_time(func):
# 定义一个带装饰功能(记录被装饰函数的执行时间)的函数
# 因为不知道被装饰的函数有怎样的参数所以使用*args和**kwargs接收所有参数
# 在Python中函数可以嵌套的定义(函数中可以再定义函数)
def wrapper(*args, **kwargs):
# 在执行被装饰的函数之前记录开始时间
start = time.time()
# 执行被装饰的函数并获取返回值
result = func(*args, **kwargs)
# 在执行被装饰的函数之后记录结束时间
end = time.time()
# 计算和显示被装饰函数的执行时间
print(f'{func.__name__}执行时间: {end - start:.3f}秒')
# 返回被装饰函数的返回值(装饰器通常不会改变被装饰函数的执行结果)
return result
# 返回带装饰功能的wrapper函数
return wrapper
使用上面的装饰器函数有两种方式,第一种方式就是直接调用装饰器函数,传入被装饰的函数并获得返回值,我们可以用这个返回值直接覆盖原来的函数,那么在调用时就已经获得了装饰器提供的额外的功能(记录执行时间),大家可以试试下面的代码就明白了。
download = record_time(download)
upload = record_time(upload)
download('MySQL从删库到跑路.avi')
upload('Python从入门到住院.pdf')
上面的代码中已经没有重复代码了,虽然写装饰器会花费一些心思,但是这是一个一劳永逸的骚操作,如果还有其他的函数也需要记录执行时间,按照上面的代码如法炮制即可。
在Python中,使用装饰器很有更为便捷的语法糖(编程语言中添加的某种语法,这种语法对语言的功能没有影响,但是使用更加方法,代码的可读性也更强,我们将其称之为“语法糖”或“糖衣语法”),可以用@装饰器函数将装饰器函数直接放在被装饰的函数上,效果跟上面的代码相同,下面是完整的代码。
import random
import time
def record_time(func):
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f'{func.__name__}执行时间: {end - start:.3f}秒')
return result
return wrapper
@record_time
def download(filename):
print(f'开始下载{filename}.')
time.sleep(random.randint(2, 6))
print(f'{filename}下载完成.')
@record_time
def upload(filename):
print(f'开始上传{filename}.')
time.sleep(random.randint(4, 8))
print(f'{filename}上传完成.')
download('MySQL从删库到跑路.avi')
upload('Python从入门到住院.pdf')
上面的代码,我们通过装饰器语法糖为download和upload函数添加了装饰器,这样调用download和upload函数时,会记录下函数的执行时间。事实上,被装饰后的download和upload函数是我们在装饰器record_time中返回的wrapper函数,调用它们其实就是在调用wrapper函数,所以拥有了记录函数执行时间的功能。
如果希望取消装饰器的作用,那么在定义装饰器函数的时候,需要做一些额外的工作。Python标准库functools模块的wraps函数也是一个装饰器,我们将它放在wrapper函数上,这个装饰器可以帮我们保留被装饰之前的函数,这样在需要取消装饰器时,可以通过被装饰函数的__wrapped__属性获得被装饰之前的函数。
import random
import time
from functools import wraps
def record_time(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f'{func.__name__}执行时间: {end - start:.3f}秒')
return result
return wrapper
@record_time
def download(filename):
print(f'开始下载{filename}.')
time.sleep(random.randint(2, 6))
print(f'{filename}下载完成.')
@record_time
def upload(filename):
print(f'开始上传{filename}.')
time.sleep(random.randint(4, 8))
print(f'{filename}上传完成.')
download('MySQL从删库到跑路.avi')
upload('Python从入门到住院.pdf')
# 取消装饰器
download.__wrapped__('MySQL必知必会.pdf')
upload = upload.__wrapped__
upload('Python从新手到大师.pdf')
装饰器函数本身也可以参数化,简单的说就是通过我们的装饰器也是可以通过调用者传入的参数来定制的,这个知识点我们在后面用到它的时候再为大家讲解。
递归调用
Python中允许函数嵌套定义,也允许函数之间相互调用,而且一个函数还可以直接或间接的调用自身。函数自己调用自己称为递归调用,那么递归调用有什么用处呢?现实中,有很多问题的定义本身就是一个递归定义,例如我们之前讲到的阶乘,非负整数N的阶乘是N乘以N-1的阶乘,即$ N! = N \times (N-1)! $,定义的左边和右边都出现了阶乘的概念,所以这是一个递归定义。既然如此,我们可以使用递归调用的方式来写一个求阶乘的函数,代码如下所示。
def fac(num):
if num in (0, 1):
return 1
return num * fac(num - 1)
上面的代码中,fac函数中又调用了fac函数,这就是所谓的递归调用。代码第2行的if条件叫做递归的收敛条件,简单的说就是什么时候要结束函数的递归调用,在计算阶乘时,如果计算到0或1的阶乘,就停止递归调用,直接返回1;代码第4行的num * fac(num - 1)是递归公式,也就是阶乘的递归定义。下面,我们简单的分析下,如果用fac(5)计算5的阶乘,整个过程会是怎样的。
# 递归调用函数入栈
# 5 * fac(4)
# 5 * (4 * fac(3))
# 5 * (4 * (3 * fac(2)))
# 5 * (4 * (3 * (2 * fac(1))))
# 停止递归函数出栈
# 5 * (4 * (3 * (2 * 1)))
# 5 * (4 * (3 * 2))
# 5 * (4 * 6)
# 5 * 24
# 120
print(fac(5)) # 120
注意,函数调用会通过内存中称为“栈”(stack)的数据结构来保存当前代码的执行现场,函数调用结束后会通过这个栈结构恢复之前的执行现场。栈是一种先进后出的数据结构,这也就意味着最早入栈的函数最后才会返回,而最后入栈的函数会最先返回。例如调用一个名为a的函数,函数a的执行体中又调用了函数b,函数b的执行体中又调用了函数c,那么最先入栈的函数是a,最先出栈的函数是c。每进入一个函数调用,栈就会增加一层栈帧(stack frame),栈帧就是我们刚才提到的保存当前代码执行现场的结构;每当函数调用结束后,栈就会减少一层栈帧。通常,内存中的栈空间很小,因此递归调用的次数如果太多,会导致栈溢出(stack overflow),所以递归调用一定要确保能够快速收敛。我们可以尝试执行fac(5000),看看是不是会提示RecursionError错误,错误消息为:maximum recursion depth exceeded in comparison(超出最大递归深度),其实就是发生了栈溢出。
我们使用的Python官方解释器,默认将函数调用的栈结构最大深度设置为1000层。如果超出这个深度,就会发生上面说的RecursionError。当然,我们可以使用sys模块的setrecursionlimit函数来改变递归调用的最大深度,例如:sys.setrecursionlimit(10000),这样就可以让上面的fac(5000)顺利执行出结果,但是我们不建议这样做,因为让递归快速收敛才是我们应该做的事情,否则就应该考虑使用循环递推而不是递归。
再举一个之前讲过的生成斐波那契数列的例子,因为斐波那契数列前两个数都是1,从第3个数开始,每个数是前两个数相加的和,可以记为f(n) = f(n - 1) + f(n - 2),很显然这又是一个递归的定义,所以我们可以用下面的递归调用函数来计算第n个斐波那契数。
def fib(n):
if n in (1, 2):
return 1
return fib(n - 1) + fib(n - 2)
# 打印前20个斐波那契数
for i in range(1, 21):
print(fib(i))
需要提醒大家,上面计算斐波那契数的代码虽然看起来非常简单明了,但执行性能是比较糟糕的,原因大家可以自己思考一下,更好的做法还是之前讲过的使用循环递推的方式,代码如下所示。
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
简单的小结
装饰器是Python中的特色语法,可以通过装饰器来增强现有的函数,这是一种非常有用的编程技巧。一些复杂的问题用函数递归调用的方式写起来真的很简单,但是函数的递归调用一定要注意收敛条件和递归公式,找到递归公式才有机会使用递归调用,而收敛条件确定了递归什么时候停下来。函数调用通过内存中的栈空间来保存现场和恢复现场,栈空间通常都很小,所以递归如果不能迅速收敛,很可能会引发栈溢出错误,从而导致程序的崩溃。
面向对象编程入门
面向对象编程是一种非常流行的编程范式(programming paradigm),所谓编程范式就是程序设计的方法论,简单的说就是程序员对程序的认知和理解以及他们编写代码的方式。
在前面的课程中,我们说过“程序是指令的集合”,运行程序时,程序中的语句会变成一条或多条指令,然后由CPU(中央处理器)去执行。为了简化程序的设计,我们又讲到了函数,把相对独立且经常重复使用的代码放置到函数中,在需要使用这些代码的时候调用函数即可。如果一个函数的功能过于复杂和臃肿,我们又可以进一步将函数进一步拆分为多个子函数来降低系统的复杂性。
不知大家是否发现,我们的编程工作其实是写程序的人按照计算机的工作方式通过代码控制机器完成任务。但是,计算机的工作方式与人类正常的思维模式是不同的,如果编程就必须抛弃人类正常的思维方式去迎合计算机,编程的乐趣就少了很多,而“每个人都应该学习编程”的豪言壮语也就只能喊喊口号而已。这里,我想说的并不是我们不能按照计算机的工作方式去编写代码,但是当我们需要开发一个复杂的系统时,这种方式会让代码过于复杂,从而导致开发和维护工作都变得举步维艰。
随着软件复杂性的增加,编写正确可靠的代码会变成了一项极为艰巨的任务,这也是很多人都坚信“软件开发是人类改造世界所有活动中最为复杂的活动”的原因。如何用程序描述复杂系统和解决复杂问题,就成为了所有程序员必须要思考和直面的问题。诞生于上世纪70年代的Smalltalk语言让软件开发者看到了希望,因为它引入了一种新的编程范式叫面向对象编程。在面向对象编程的世界里,程序中的数据和操作数据的函数是一个逻辑上的整体,我们称之为对象,对象可以接收消息,解决问题的方法就是创建对象并向对象发出各种各样的消息;通过消息传递,程序中的多个对象可以协同工作,这样就能构造出复杂的系统并解决现实中的问题。当然,面向对象编程的雏形还可以向前追溯到更早期的Simula语言,但这不是我们现在要讨论的重点。
说明: 今天我们使用的很多高级程序设计语言都支持面向对象编程,但是面向对象编程也不是解决软件开发中所有问题的“银弹”,或者说在软件开发这个行业目前还找不到这种所谓的“银弹”。关于这个问题,大家可以参考IBM360系统之父弗雷德里克·布鲁克斯所发表的论文《没有银弹:软件工程的本质性与附属性工作》或软件工程的经典著作《人月神话》一书。
类和对象
如果要用一句话来概括面向对象编程,我认为下面的说法是相当精辟和准确的。
面向对象编程:把一组数据和处理数据的方法组成对象,把行为相同的对象归纳为类,通过封装隐藏对象的内部细节,通过继承实现类的特化和泛化,通过多态实现基于对象类型的动态分派。
这句话对初学者来说可能不那么容易理解,但是我可以先为大家圈出几个关键词:对象(object)、类(class)、封装(encapsulation)、继承(inheritance)、多态(polymorphism)。
我们先说说类和对象这两个词。在面向对象编程中,类是一个抽象的概念,对象是一个具体的概念。我们把同一类对象的共同特征抽取出来就是一个类,比如我们经常说的人类,这是一个抽象概念,而我们每个人就是人类的这个抽象概念下的实实在在的存在,也就是一个对象。简而言之,类是对象的蓝图和模板,对象是类的实例,是可以接受消息的实体。
在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类。对象的属性是对象的静态特征,对象的行为是对象的动态特征。按照上面的说法,如果我们把拥有共同特征的对象的属性和行为都抽取出来,就可以定义出一个类。
定义类
在Python中,可以使用class关键字加上类名来定义类,通过缩进我们可以确定类的代码块,就如同定义函数那样。在类的代码块中,我们需要写一些函数,我们说过类是一个抽象概念,那么这些函数就是我们对一类对象共同的动态特征的提取。写在类里面的函数我们通常称之为方法,方法就是对象的行为,也就是对象可以接收的消息。方法的第一个参数通常都是self,它代表了接收这个消息的对象本身。
class Student:
def study(self, course_name):
print(f'学生正在学习{course_name}.')
def play(self):
print(f'学生正在玩游戏.')
创建和使用对象
在我们定义好一个类之后,可以使用构造器语法来创建对象,代码如下所示。
stu1 = Student()
stu2 = Student()
print(stu1) # <__main__.Student object at 0x10ad5ac50>
print(stu2) # <__main__.Student object at 0x10ad5acd0>
print(hex(id(stu1)), hex(id(stu2))) # 0x10ad5ac50 0x10ad5acd0
在类的名字后跟上圆括号就是所谓的构造器语法,上面的代码创建了两个学生对象,一个赋值给变量stu1,一个复制给变量stu2。当我们用print函数打印stu1和stu2两个变量时,我们会看到输出了对象在内存中的地址(十六进制形式),跟我们用id函数查看对象标识获得的值是相同的。现在我们可以告诉大家,我们定义的变量其实保存的是一个对象在内存中的逻辑地址(位置),通过这个逻辑地址,我们就可以在内存中找到这个对象。所以stu3 = stu2这样的赋值语句并没有创建新的对象,只是用一个新的变量保存了已有对象的地址。
接下来,我们尝试给对象发消息,即调用对象的方法。刚才的Student类中我们定义了study和play两个方法,两个方法的第一个参数self代表了接收消息的学生对象,study方法的第二个参数是学习的课程名称。Python中,给对象发消息有两种方式,请看下面的代码。
# 通过“类.方法”调用方法,第一个参数是接收消息的对象,第二个参数是学习的课程名称
Student.study(stu1, 'Python程序设计') # 学生正在学习Python程序设计.
# 通过“对象.方法”调用方法,点前面的对象就是接收消息的对象,只需要传入第二个参数
stu1.study('Python程序设计') # 学生正在学习Python程序设计.
Student.play(stu2) # 学生正在玩游戏.
stu2.play() # 学生正在玩游戏.
初始化方法
大家可能已经注意到了,刚才我们创建的学生对象只有行为没有属性,如果要给学生对象定义属性,我们可以修改Student类,为其添加一个名为__init__的方法。在我们调用Student类的构造器创建对象时,首先会在内存中获得保存学生对象所需的内存空间,然后通过自动执行__init__方法,完成对内存的初始化操作,也就是把数据放到内存空间中。所以我们可以通过给Student类添加__init__方法的方式为学生对象指定属性,同时完成对属性赋初始值的操作,正因如此,__init__方法通常也被称为初始化方法。
我们对上面的Student类稍作修改,给学生对象添加name(姓名)和age(年龄)两个属性。
class Student:
"""学生"""
def __init__(self, name, age):
"""初始化方法"""
self.name = name
self.age = age
def study(self, course_name):
"""学习"""
print(f'{self.name}正在学习{course_name}.')
def play(self):
"""玩耍"""
print(f'{self.name}正在玩游戏.')
修改刚才创建对象和给对象发消息的代码,重新执行一次,看看程序的执行结果有什么变化。
# 由于初始化方法除了self之外还有两个参数
# 所以调用Student类的构造器创建对象时要传入这两个参数
stu1 = Student('骆昊', 40)
stu2 = Student('王大锤', 15)
stu1.study('Python程序设计') # 骆昊正在学习Python程序设计.
stu2.play() # 王大锤正在玩游戏.
打印对象
上面我们通过__init__方法在创建对象时为对象绑定了属性并赋予了初始值。在Python中,以两个下划线__(读作“dunder”)开头和结尾的方法通常都是有特殊用途和意义的方法,我们一般称之为魔术方法或魔法方法。如果我们在打印对象的时候不希望看到对象的地址而是看到我们自定义的信息,可以通过在类中放置__repr__魔术方法来做到,该方法返回的字符串就是用print函数打印对象的时候会显示的内容,代码如下所示。
class Student:
"""学生"""
def __init__(self, name, age):
"""初始化方法"""
self.name = name
self.age = age
def study(self, course_name):
"""学习"""
print(f'{self.name}正在学习{course_name}.')
def play(self):
"""玩耍"""
print(f'{self.name}正在玩游戏.')
def __repr__(self):
return f'{self.name}: {self.age}'
stu1 = Student('骆昊', 40)
print(stu1) # 骆昊: 40
students = [stu1, Student('李元芳', 36), Student('王大锤', 25)]
print(students) # [骆昊: 40, 李元芳: 36, 王大锤: 25]
面向对象的支柱
面向对象编程有三大支柱,就是我们之前给大家划重点的时候圈出的三个词:封装、继承和多态。后面两个概念在下一节课中会详细说明,这里我们先说一下什么是封装。我自己对封装的理解是:隐藏一切可以隐藏的实现细节,只向外界暴露简单的调用接口。我们在类中定义的对象方法其实就是一种封装,这种封装可以让我们在创建对象之后,只需要给对象发送一个消息就可以执行方法中的代码,也就是说我们在只知道方法的名字和参数(方法的外部视图),不知道方法内部实现细节(方法的内部视图)的情况下就完成了对方法的使用。
举一个例子,假如要控制一个机器人帮我倒杯水,如果不使用面向对象编程,不做任何的封装,那么就需要向这个机器人发出一系列的指令,如站起来、向左转、向前走5步、拿起面前的水杯、向后转、向前走10步、弯腰、放下水杯、按下出水按钮、等待10秒、松开出水按钮、拿起水杯、向右转、向前走5步、放下水杯等,才能完成这个简单的操作,想想都觉得麻烦。按照面向对象编程的思想,我们可以将倒水的操作封装到机器人的一个方法中,当需要机器人帮我们倒水的时候,只需要向机器人对象发出倒水的消息就可以了,这样做不是更好吗?
在很多场景下,面向对象编程其实就是一个三步走的问题。第一步定义类,第二步创建对象,第三步给对象发消息。当然,有的时候我们是不需要第一步的,因为我们想用的类可能已经存在了。之前我们说过,Python内置的list、set、dict其实都不是函数而是类,如果要创建列表、集合、字典对象,我们就不用自定义类了。当然,有的类并不是Python标准库中直接提供的,它可能来自于第三方的代码,如何安装和使用三方代码在后续课程中会进行讨论。在某些特殊的场景中,我们会用到名为“内置对象”的对象,所谓“内置对象”就是说上面三步走的第一步和第二步都不需要了,因为类已经存在而且对象已然创建过了,直接向对象发消息就可以了,这也就是我们常说的“开箱即用”。
经典案例
案例1:定义一个类描述数字时钟。
import time
# 定义数字时钟类
class Clock(object):
"""数字时钟"""
def __init__(self, hour=0, minute=0, second=0):
"""初始化方法
:param hour: 时
:param minute: 分
:param second: 秒
"""
self.hour = hour
self.min = minute
self.sec = second
def run(self):
"""走字"""
self.sec += 1
if self.sec == 60:
self.sec = 0
self.min += 1
if self.min == 60:
self.min = 0
self.hour += 1
if self.hour == 24:
self.hour = 0
def show(self):
"""显示时间"""
return f'{self.hour:0>2d}:{self.min:0>2d}:{self.sec:0>2d}'
# 创建时钟对象
clock = Clock(23, 59, 58)
while True:
# 给时钟对象发消息读取时间
print(clock.show())
# 休眠1秒钟
time.sleep(1)
# 给时钟对象发消息使其走字
clock.run()
案例2:定义一个类描述平面上的点,要求提供计算到另一个点距离的方法。
class Point(object):
"""屏面上的点"""
def __init__(self, x=0, y=0):
"""初始化方法
:param x: 横坐标
:param y: 纵坐标
"""
self.x, self.y = x, y
def distance_to(self, other):
"""计算与另一个点的距离
:param other: 另一个点
"""
dx = self.x - other.x
dy = self.y - other.y
return (dx * dx + dy * dy) ** 0.5
def __str__(self):
return f'({self.x}, {self.y})'
p1 = Point(3, 5)
p2 = Point(6, 9)
print(p1, p2)
print(p1.distance_to(p2))
简单的小结
面向对象编程是一种非常流行的编程范式,除此之外还有指令式编程、函数式编程等编程范式。由于现实世界是由对象构成的,而对象是可以接收消息的实体,所以面向对象编程更符合人类正常的思维习惯。类是抽象的,对象是具体的,有了类就能创建对象,有了对象就可以接收消息,这就是面向对象编程的基础。定义类的过程是一个抽象的过程,找到对象公共的属性属于数据抽象,找到对象公共的方法属于行为抽象。抽象的过程是一个仁者见仁智者见智的过程,对同一类对象进行抽象可能会得到不同的结果
面向对象编程进阶
上一节课我们讲解了Python面向对象编程的基础知识,这一节课我们继续来讨论面向对象编程相关的内容。
可见性和属性装饰器
在很多面向对象编程语言中,对象的属性通常会被设置为私有(private)或受保护(protected)的成员,简单的说就是不允许直接访问这些属性;对象的方法通常都是公开的(public),因为公开的方法是对象能够接受的消息,也是对象暴露给外界的调用接口,这就是所谓的访问可见性。在Python中,可以通过给对象属性名添加前缀下划线的方式来说明属性的访问可见性,例如,可以用__name表示一个私有属性,_name表示一个受保护属性,代码如下所示。
class Student:
def __init__(self, name, age):
self.__name = name
self.__age = age
def study(self, course_name):
print(f'{self.__name}正在学习{course_name}.')
stu = Student('王大锤', 20)
stu.study('Python程序设计')
print(stu.__name)
上面代码的最后一行会引发AttributeError(属性错误)异常,异常消息为:'Student' object has no attribute '__name'。由此可见,以__开头的属性__name是私有的,在类的外面无法直接访问,但是类里面的study方法中可以通过self.__name访问该属性。
需要提醒大家的是,Python并没有从语法上严格保证私有属性的私密性,它只是给私有的属性和方法换了一个名字来阻挠对它们的访问,事实上如果你知道更换名字的规则仍然可以访问到它们,我们可以对上面的代码稍作修改就可以访问到私有的属性。
class Student:
def __init__(self, name, age):
self.__name = name
self.__age = age
def study(self, course_name):
print(f'{self.__name}正在学习{course_name}.')
stu = Student('王大锤', 20)
stu.study('Python程序设计')
print(stu._Student__name, stu._Student__age)
Python中有一句名言:“We are all consenting adults here”(大家都是成年人)。Python语言的设计者认为程序员要为自己的行为负责,而不是由Python语言本身来严格限制访问可见性,而大多数的程序员都认为开放比封闭要好,把对象的属性私有化并不是编程语言必须的东西,所以Python并没有从语法上做出最严格的限定。
Python中可以通过property装饰器为“私有”属性提供读取和修改的方法,之前我们提到过,装饰器通常会放在类、函数或方法的声明之前,通过一个@符号表示将装饰器应用于类、函数或方法。
class Student:
def __init__(self, name, age):
self.__name = name
self.__age = age
# 属性访问器(getter方法) - 获取__name属性
@property
def name(self):
return self.__name
# 属性修改器(setter方法) - 修改__name属性
@name.setter
def name(self, name):
# 如果name参数不为空就赋值给对象的__name属性
# 否则将__name属性赋值为'无名氏',有两种写法
# self.__name = name if name else '无名氏'
self.__name = name or '无名氏'
@property
def age(self):
return self.__age
stu = Student('王大锤', 20)
print(stu.name, stu.age) # 王大锤 20
stu.name = ''
print(stu.name) # 无名氏
# stu.age = 30 # AttributeError: can't set attribute
在实际项目开发中,我们并不经常使用私有属性,属性装饰器的使用也比较少,所以上面的知识点大家简单了解一下就可以了。
动态属性
Python是一门动态语言,维基百科对动态语言的解释是:“在运行时可以改变其结构的语言,例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言非常灵活,目前流行的Python和JavaScript都是动态语言,除此之外如PHP、Ruby等也都属于动态语言,而C、C++等语言则不属于动态语言”。
在Python中,我们可以动态为对象添加属性,这是Python作为动态类型语言的一项特权,代码如下所示。需要提醒大家的是,对象的方法其实本质上也是对象的属性,如果给对象发送一个无法接收的消息,引发的异常仍然是AttributeError。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
stu = Student('王大锤', 20)
# 为Student对象动态添加sex属性
stu.sex = '男'
如果不希望在使用对象时动态的为对象添加属性,可以使用Python的__slots__魔法。对于Student类来说,可以在类中指定__slots__ = ('name', 'age'),这样Student类的对象只能有name和age属性,如果想动态添加其他属性将会引发异常,代码如下所示。
class Student:
__slots__ = ('name', 'age')
def __init__(self, name, age):
self.name = name
self.age = age
stu = Student('王大锤', 20)
# AttributeError: 'Student' object has no attribute 'sex'
stu.sex = '男'
静态方法和类方法
之前我们在类中定义的方法都是对象方法,换句话说这些方法都是对象可以接收的消息。除了对象方法之外,类中还可以有静态方法和类方法,这两类方法是发给类的消息,二者并没有实质性的区别。在面向对象的世界里,一切皆为对象,我们定义的每一个类其实也是一个对象,而静态方法和类方法就是发送给类对象的消息。那么,什么样的消息会直接发送给类对象呢?
举一个例子,定义一个三角形类,通过传入三条边的长度来构造三角形,并提供计算周长和面积的方法。计算周长和面积肯定是三角形对象的方法,这一点毫无疑问。但是在创建三角形对象时,传入的三条边长未必能构造出三角形,为此我们可以先写一个方法来验证给定的三条边长是否可以构成三角形,这种方法很显然就不是对象方法,因为在调用这个方法时三角形对象还没有创建出来。我们可以把这类方法设计为静态方法或类方法,也就是说这类方法不是发送给三角形对象的消息,而是发送给三角形类的消息,代码如下所示。
class Triangle(object):
"""三角形类"""
def __init__(self, a, b, c):
"""初始化方法"""
self.a = a
self.b = b
self.c = c
@staticmethod
def is_valid(a, b, c):
"""判断三条边长能否构成三角形(静态方法)"""
return a + b > c and b + c > a and a + c > b
# @classmethod
# def is_valid(cls, a, b, c):
# """判断三条边长能否构成三角形(类方法)"""
# return a + b > c and b + c > a and a + c > b
def perimeter(self):
"""计算周长"""
return self.a + self.b + self.c
def area(self):
"""计算面积"""
p = self.perimeter() / 2
return (p * (p - self.a) * (p - self.b) * (p - self.c)) ** 0.5
上面的代码使用staticmethod装饰器声明了is_valid方法是Triangle类的静态方法,如果要声明类方法,可以使用classmethod装饰器。可以直接使用类名.方法名的方式来调用静态方法和类方法,二者的区别在于,类方法的第一个参数是类对象本身,而静态方法则没有这个参数。简单的总结一下,对象方法、类方法、静态方法都可以通过类名.方法名的方式来调用,区别在于方法的第一个参数到底是普通对象还是类对象,还是没有接受消息的对象。静态方法通常也可以直接写成一个独立的函数,因为它并没有跟特定的对象绑定。
继承和多态
面向对象的编程语言支持在已有类的基础上创建新类,从而减少重复代码的编写。提供继承信息的类叫做父类(超类、基类),得到继承信息的类叫做子类(派生类、衍生类)。例如,我们定义一个学生类和一个老师类,我们会发现他们有大量的重复代码,而这些重复代码都是老师和学生作为人的公共属性和行为,所以在这种情况下,我们应该先定义人类,再通过继承,从人类派生出老师类和学生类,代码如下所示。
class Person:
"""人类"""
def __init__(self, name, age):
self.name = name
self.age = age
def eat(self):
print(f'{self.name}正在吃饭.')
def sleep(self):
print(f'{self.name}正在睡觉.')
class Student(Person):
"""学生类"""
def __init__(self, name, age):
# super(Student, self).__init__(name, age)
super().__init__(name, age)
def study(self, course_name):
print(f'{self.name}正在学习{course_name}.')
class Teacher(Person):
"""老师类"""
def __init__(self, name, age, title):
# super(Teacher, self).__init__(name, age)
super().__init__(name, age)
self.title = title
def teach(self, course_name):
print(f'{self.name}{self.title}正在讲授{course_name}.')
stu1 = Student('白元芳', 21)
stu2 = Student('狄仁杰', 22)
teacher = Teacher('武则天', 35, '副教授')
stu1.eat()
stu2.sleep()
teacher.teach('Python程序设计')
stu1.study('Python程序设计')
继承的语法是在定义类的时候,在类名后的圆括号中指定当前类的父类。如果定义一个类的时候没有指定它的父类是谁,那么默认的父类是object类。object类是Python中的顶级类,这也就意味着所有的类都是它的子类,要么直接继承它,要么间接继承它。Python语言允许多重继承,也就是说一个类可以有一个或多个父类,关于多重继承的问题我们在后面会有更为详细的讨论。在子类的初始化方法中,我们可以通过super().__init__()来调用父类初始化方法,super函数是Python内置函数中专门为获取当前对象的父类对象而设计的。从上面的代码可以看出,子类除了可以通过继承得到父类提供的属性和方法外,还可以定义自己特有的属性和方法,所以子类比父类拥有的更多的能力。在实际开发中,我们经常会用子类对象去替换掉一个父类对象,这是面向对象编程中一个常见的行为,也叫做“里氏替换原则”(Liskov Substitution Principle)。
子类继承父类的方法后,还可以对方法进行重写(重新实现该方法),不同的子类可以对父类的同一个方法给出不同的实现版本,这样的方法在程序运行时就会表现出多态行为(调用相同的方法,做了不同的事情)。多态是面向对象编程中最精髓的部分,当然也是对初学者来说最难以理解和灵活运用的部分,我们会在下一节课中用专门的例子来讲解多态这个知识点。
简单的小结
Python是动态语言,Python中的对象可以动态的添加属性。在面向对象的世界中,一切皆为对象,我们定义的类也是对象,所以类也可以接收消息,对应的方法是类方法或静态方法。通过继承,我们可以从已有的类创建新类,实现对已有类代码的复用。## 第19课:面向对象编程应用
面向对象编程对初学者来说不难理解但很难应用,虽然我们为大家总结过面向对象的三步走方法(定义类、创建对象、给对象发消息),但是说起来容易做起来难。大量的编程练习和阅读优质的代码可能是这个阶段最能够帮助到大家的两件事情。接下来我们还是通过经典的案例来剖析面向对象编程的知识,同时也通过这些案例为大家讲解如何运用之前学过的Python知识。
经典案例
案例1:扑克游戏。
说明:简单起见,我们的扑克只有52张牌(没有大小王),游戏需要将52张牌发到4个玩家的手上,每个玩家手上有13张牌,按照黑桃、红心、草花、方块的顺序和点数从小到大排列,暂时不实现其他的功能。
使用面向对象编程方法,首先需要从问题的需求中找到对象并抽象出对应的类,此外还要找到对象的属性和行为。当然,这件事情并不是特别困难,我们可以从需求的描述中找出名词和动词,名词通常就是对象或者是对象的属性,而动词通常是对象的行为。扑克游戏中至少应该有三类对象,分别是牌、扑克和玩家,牌、扑克、玩家三个类也并不是孤立的。类和类之间的关系可以粗略的分为is-a关系(继承)、has-a关系(关联)和use-a关系(依赖)。很显然扑克和牌是has-a关系,因为一副扑克有(has-a)52张牌;玩家和牌之间不仅有关联关系还有依赖关系,因为玩家手上有(has-a)牌而且玩家使用了(use-a)牌。
牌的属性显而易见,有花色和点数。我们可以用0到3的四个数字来代表四种不同的花色,但是这样的代码可读性会非常糟糕,因为我们并不知道黑桃、红心、草花、方块跟0到3的数字的对应关系。如果一个变量的取值只有有限多个选项,我们可以使用枚举。与C、Java等语言不同的是,Python中没有声明枚举类型的关键字,但是可以通过继承enum模块的Enum类来创建枚举类型,代码如下所示。
from enum import Enum
class Suite(Enum):
"""花色(枚举)"""
SPADE, HEART, CLUB, DIAMOND = range(4)
通过上面的代码可以看出,定义枚举类型其实就是定义符号常量,如SPADE、HEART等。每个符号常量都有与之对应的值,这样表示黑桃就可以不用数字0,而是用Suite.SPADE;同理,表示方块可以不用数字3, 而是用Suite.DIAMOND。注意,使用符号常量肯定是优于使用字面常量的,因为能够读懂英文就能理解符号常量的含义,代码的可读性会提升很多。Python中的枚举类型是可迭代类型,简单的说就是可以将枚举类型放到for-in循环中,依次取出每一个符号常量及其对应的值,如下所示。
for suite in Suite:
print(f'{suite}: {suite.value}')
接下来我们可以定义牌类。
class Card:
"""牌"""
def __init__(self, suite, face):
self.suite = suite
self.face = face
def __repr__(self):
suites = '♠♥♣♦'
faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
# 根据牌的花色和点数取到对应的字符
return f'{suites[self.suite.value]}{faces[self.face]}'
可以通过下面的代码来测试下Card类。
card1 = Card(Suite.SPADE, 5)
card2 = Card(Suite.HEART, 13)
print(card1, card2) # ♠5 ♥K
接下来我们定义扑克类。
import random
class Poker:
"""扑克"""
def __init__(self):
# 通过列表的生成式语法创建一个装52张牌的列表
self.cards = [Card(suite, face) for suite in Suite
for face in range(1, 14)]
# current属性表示发牌的位置
self.current = 0
def shuffle(self):
"""洗牌"""
self.current = 0
# 通过random模块的shuffle函数实现列表的随机乱序
random.shuffle(self.cards)
def deal(self):
"""发牌"""
card = self.cards[self.current]
self.current += 1
return card
@property
def has_next(self):
"""还有没有牌可以发"""
return self.current < len(self.cards)
可以通过下面的代码来测试下Poker类。
poker = Poker()
poker.shuffle()
print(poker.cards)
定义玩家类。
class Player:
"""玩家"""
def __init__(self, name):
self.name = name
self.cards = []
def get_one(self, card):
"""摸牌"""
self.cards.append(card)
def arrange(self):
self.cards.sort()
创建四个玩家并将牌发到玩家的手上。
poker = Poker()
poker.shuffle()
players = [Player('东邪'), Player('西毒'), Player('南帝'), Player('北丐')]
for _ in range(13):
for player in players:
player.get_one(poker.deal())
for player in players:
player.arrange()
print(f'{player.name}: ', end='')
print(player.cards)
执行上面的代码会在player.arrange()那里出现异常,因为Player的arrange方法使用了列表的sort对玩家手上的牌进行排序,排序需要比较两个Card对象的大小,而<运算符又不能直接作用于Card类型,所以就出现了TypeError异常,异常消息为:'<' not supported between instances of 'Card' and 'Card'。
为了解决这个问题,我们可以对Card类的代码稍作修改,使得两个Card对象可以直接用<进行大小的比较。这里用到技术叫运算符重载,Python中要实现对<运算符的重载,需要在类中添加一个名为__lt__的魔术方法。很显然,魔术方法__lt__中的lt是英文单词“less than”的缩写,以此类推,魔术方法__gt__对应>运算符,魔术方法__le__对应<=运算符,__ge__对应>=运算符,__eq__对应==运算符,__ne__对应!=运算符。
修改后的Card类代码如下所示。
class Card:
"""牌"""
def __init__(self, suite, face):
self.suite = suite
self.face = face
def __repr__(self):
suites = '♠♥♣♦'
faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
# 根据牌的花色和点数取到对应的字符
return f'{suites[self.suite.value]}{faces[self.face]}'
def __lt__(self, other):
# 花色相同比较点数的大小
if self.suite == other.suite:
return self.face < other.face
# 花色不同比较花色对应的值
return self.suite.value < other.suite.value
说明: 大家可以尝试在上面代码的基础上写一个简单的扑克游戏,如21点游戏(Black Jack),游戏的规则可以自己在网上找一找。
案例2:工资结算系统。
要求:某公司有三种类型的员工,分别是部门经理、程序员和销售员。需要设计一个工资结算系统,根据提供的员工信息来计算员工的月薪。其中,部门经理的月薪是固定15000元;程序员按工作时间(以小时为单位)支付月薪,每小时200元;销售员的月薪由1800元底薪加上销售额5%的提成两部分构成。
通过对上述需求的分析,可以看出部门经理、程序员、销售员都是员工,有相同的属性和行为,那么我们可以先设计一个名为Employee的父类,再通过继承的方式从这个父类派生出部门经理、程序员和销售员三个子类。很显然,后续的代码不会创建Employee 类的对象,因为我们需要的是具体的员工对象,所以这个类可以设计成专门用于继承的抽象类。Python中没有定义抽象类的关键字,但是可以通过abc模块中名为ABCMeta 的元类来定义抽象类。关于元类的知识,后面的课程中会有专门的讲解,这里不用太纠结这个概念,记住用法即可。
from abc import ABCMeta, abstractmethod
class Employee(metaclass=ABCMeta):
"""员工"""
def __init__(self, name):
self.name = name
@abstractmethod
def get_salary(self):
"""结算月薪"""
pass
在上面的员工类中,有一个名为get_salary的方法用于结算月薪,但是由于还没有确定是哪一类员工,所以结算月薪虽然是员工的公共行为但这里却没有办法实现。对于暂时无法实现的方法,我们可以使用abstractmethod装饰器将其声明为抽象方法,所谓抽象方法就是只有声明没有实现的方法,声明这个方法是为了让子类去重写这个方法。接下来的代码展示了如何从员工类派生出部门经理、程序员、销售员这三个子类以及子类如何重写父类的抽象方法。
class Manager(Employee):
"""部门经理"""
def get_salary(self):
return 15000.0
class Programmer(Employee):
"""程序员"""
def __init__(self, name, working_hour=0):
super().__init__(name)
self.working_hour = working_hour
def get_salary(self):
return 200 * self.working_hour
class Salesman(Employee):
"""销售员"""
def __init__(self, name, sales=0):
super().__init__(name)
self.sales = sales
def get_salary(self):
return 1800 + self.sales * 0.05
上面的Manager、Programmer、Salesman三个类都继承自Employee,三个类都分别重写了get_salary方法。重写就是子类对父类已有的方法重新做出实现。相信大家已经注意到了,三个子类中的get_salary各不相同,所以这个方法在程序运行时会产生多态行为,多态简单的说就是调用相同的方法,不同的子类对象做不同的事情。
我们通过下面的代码来完成这个工资结算系统,由于程序员和销售员需要分别录入本月的工作时间和销售额,所以在下面的代码中我们使用了Python内置的isinstance函数来判断员工对象的类型。我们之前讲过的type函数也能识别对象的类型,但是isinstance函数更加强大,因为它可以判断出一个对象是不是某个继承结构下的子类型,你可以简答的理解为type函数是对对象类型的精准匹配,而isinstance函数是对对象类型的模糊匹配。
emps = [
Manager('刘备'), Programmer('诸葛亮'), Manager('曹操'),
Programmer('荀彧'), Salesman('吕布'), Programmer('张辽'),
]
for emp in emps:
if isinstance(emp, Programmer):
emp.working_hour = int(input(f'请输入{emp.name}本月工作时间: '))
elif isinstance(emp, Salesman):
emp.sales = float(input(f'请输入{emp.name}本月销售额: '))
print(f'{emp.name}本月工资为: ¥{emp.get_salary():.2f}元')
简单的小结
面向对象的编程思想非常的好,也符合人类的正常思维习惯,但是要想灵活运用面向对象编程中的抽象、封装、继承、多态需要长时间的积累和沉淀,这件事情无法一蹴而就,属于“路漫漫其修远兮,吾将上下而求索”的东西。## 第21课:文件读写和异常处理
实际开发中常常会遇到对数据进行持久化的场景,所谓持久化是指将数据从无法长久保存数据的存储介质(通常是内存)转移到可以长久保存数据的存储介质(通常是硬盘)中。实现数据持久化最直接简单的方式就是通过文件系统将数据保存到文件中。
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对数据的访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘、光盘、闪存等物理设备的数据块概念,用户使用文件系统来保存数据时,不必关心数据实际保存在硬盘的哪个数据块上,只需要记住这个文件的路径和文件名。在写入新数据之前,用户不必关心硬盘上的哪个数据块没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
打开和关闭文件
有了文件系统,我们可以非常方便的通过文件来读写数据;在Python中要实现文件操作是非常简单的。我们可以使用Python内置的open函数来打开文件,在使用open函数时,我们可以通过函数的参数指定文件名、操作模式和字符编码等信息,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件或二进制文件)以及做什么样的操作(读、写或追加),具体如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' | 读取 (默认) |
'w' | 写入(会先截断之前的内容) |
'x' | 写入,如果文件已经存在会产生异常 |
'a' | 追加,将内容写入到已有文件的末尾 |
'b' | 二进制模式 |
't' | 文本模式(默认) |
'+' | 更新(既可以读又可以写) |
在使用open函数时,如果打开的文件是字符文件(文本文件),可以通过encoding参数来指定读写文件使用的字符编码
使用open函数打开文件成功后会返回一个文件对象,通过这个对象,我们就可以实现对文件的读写操作;如果打开文件失败,open函数会引发异常,稍后会对此加以说明。如果要关闭打开的文件,可以使用文件对象的close方法,这样可以在结束文件操作时释放掉这个文件。
读写文本文件
用open函数打开文本文件时,需要指定文件名并将文件的操作模式设置为'r',如果不指定,默认值也是'r';如果需要指定字符编码,可以传入encoding参数,如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码。需要提醒大家,如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取文件失败。
下面的例子演示了如何读取一个纯文本文件(一般指只有字符原生编码构成的文件,与富文本相比,纯文本不包含字符样式的控制元素,能够被最简单的文本编辑器直接读取)。
file = open('致橡树.txt', 'r', encoding='utf-8')
print(file.read())
file.close()
说明:《致橡树》是舒婷老师在1977年3月创建的爱情诗,也是我最喜欢的现代诗之一。
除了使用文件对象的read方法读取文件之外,还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中,代码如下所示。
file = open('致橡树.txt', 'r', encoding='utf-8')
for line in file:
print(line, end='')
file.close()
file = open('致橡树.txt', 'r', encoding='utf-8')
lines = file.readlines()
for line in lines:
print(line, end='')
file.close()
如果要向文件中写入内容,可以在打开文件时使用w或者a作为操作模式,前者会截断之前的文本内容写入新的内容,后者是在原来内容的尾部追加新的内容。
file = open('致橡树.txt', 'a', encoding='utf-8')
file.write('\n标题:《致橡树》')
file.write('\n作者:舒婷')
file.write('\n时间:1977年3月')
file.close()
异常处理机制
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码具有健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理。Python中和异常相关的关键字有五个,分别是try、except、else、finally和raise,我们先看看下面的代码,再来为大家介绍这些关键字的用法。
file = None
try:
file = open('致橡树.txt', 'r', encoding='utf-8')
print(file.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if file:
file.close()
在Python中,我们可以将运行时会出现状况的代码放在try代码块中,在try后面可以跟上一个或多个except块来捕获异常并进行相应的处理。例如,在上面的代码中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定编码方式解码文件会引发UnicodeDecodeError,所以我们在try后面跟上了三个except分别处理这三种不同的异常状况。在except后面,我们还可以加上else代码块,这是try 中的代码没有出现异常时会执行的代码,而且else中的代码不会再进行异常捕获,也就是说如果遇到异常状况,程序会因异常而终止并报告异常信息。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源。由于finally块的代码不论程序正常还是异常都会执行,甚至是调用了sys模块的exit函数终止Python程序,finally块中的代码仍然会被执行(因为exit函数的本质是引发了SystemExit异常),因此我们把finally代码块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。
Python中内置了大量的异常类型,除了上面代码中用到的异常类型以及之前的课程中遇到过的异常类型外,还有许多的异常类型,其继承结构如下所示。
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
从上面的继承结构可以看出,Python中所有的异常都是BaseException的子类型,它有四个直接的子类,分别是:SystemExit、KeyboardInterrupt、GeneratorExit和Exception。其中,SystemExit表示解释器请求退出,KeyboardInterrupt是用户中断程序执行(按下Ctrl+c),GeneratorExit表示生成器发生异常通知退出,不理解这些异常没有关系,继续学习就好了。值得一提的是Exception类,它是常规异常类型的父类型,很多的异常都是直接或间接的继承自Exception类。如果Python内置的异常类型不能满足应用程序的需要,我们可以自定义异常类型,而自定义的异常类型也应该直接或间接继承自Exception类,当然还可以根据需要重写或添加方法。
在Python中,可以使用raise关键字来引发异常(抛出异常对象),而调用者可以通过try...except...结构来捕获并处理异常。例如在函数中,当函数的执行条件不满足时,可以使用抛出异常的方式来告知调用者问题的所在,而调用者可以通过捕获处理异常来使得代码从异常中恢复,定义异常和抛出异常的代码如下所示。
class InputError(ValueError):
"""自定义异常类型"""
pass
def fac(num):
"""求阶乘"""
if num < 0:
raise InputError('只能计算非负整数的阶乘')
if num in (0, 1):
return 1
return num * fac(num - 1)
调用求阶乘的函数fac,通过try...except...结构捕获输入错误的异常并打印异常对象(显示异常信息),如果输入正确就计算阶乘并结束程序。
flag = True
while flag:
num = int(input('n = '))
try:
print(f'{num}! = {fac(num)}')
flag = False
except InputError as err:
print(err)
上下文语法
对于open函数返回的文件对象,还可以使用with上下文语法在文件操作完成后自动执行文件对象的close方法,这样可以让代码变得更加简单优雅,因为不需要再写finally代码块来执行关闭文件释放资源的操作。需要提醒大家的是,并不是所有的对象都可以放在with上下文语法中,只有符合上下文管理器协议(有__enter__和__exit__魔术方法)的对象才能使用这种语法,Python标准库中的contextlib模块也提供了对with上下文语法的支持,后面再为大家进行讲解。
用with上下文语法改写后的代码如下所示。
try:
with open('致橡树.txt', 'r', encoding='utf-8') as file:
print(file.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
读写二进制文件
读写二进制文件跟读写文本文件的操作类似,但是需要注意,在使用open函数打开文件时,如果要进行读操作,操作模式是'rb',如果要进行写操作,操作模式是'wb'。还有一点,读写文本文件时,read方法的返回值以及write方法的参数是str对象(字符串),而读写二进制文件时,read方法的返回值以及write方法的参数是bytes-like对象(字节串)。下面的代码实现了将当前路径下名为guido.jpg的图片文件复制到吉多.jpg文件中的操作。
try:
with open('guido.jpg', 'rb') as file1:
data = file1.read()
with open('吉多.jpg', 'wb') as file2:
file2.write(data)
except FileNotFoundError:
print('指定的文件无法打开.')
except IOError:
print('读写文件时出现错误.')
print('程序执行结束.')
如果要复制的图片文件很大,一次将文件内容直接读入内存中可能会造成非常大的内存开销,为了减少对内存的占用,可以为read方法传入size参数来指定每次读取的字节数,通过循环读取和写入的方式来完成上面的操作,代码如下所示。
try:
with open('guido.jpg', 'rb') as file1, open('吉多.jpg', 'wb') as file2:
data = file1.read(512)
while data:
file2.write(data)
data = file1.read()
except FileNotFoundError:
print('指定的文件无法打开.')
except IOError:
print('读写文件时出现错误.')
print('程序执行结束.')
简单的小结
通过读写文件的操作,我们可以实现数据持久化。在Python中可以通过open函数来获得文件对象,可以通过文件对象的read和write方法实现文件读写操作。程序在运行时可能遭遇无法预料的异常状况,可以使用Python的异常机制来处理这些状况。Python的异常机制主要包括try、except、else、finally和raise这五个核心关键字。try后面的except语句不是必须的,finally语句也不是必须的,但是二者必须要有一个;except语句可以有一个或多个,多个except会按照书写的顺序依次匹配指定的异常,如果异常已经处理就不会再进入后续的except语句;except语句中还可以通过元组同时指定多个异常类型进行捕获;except语句后面如果不指定异常类型,则默认捕获所有异常;捕获异常后可以使用raise要再次抛出,但是不建议捕获并抛出同一个异常;不建议在不清楚逻辑的情况下捕获所有异常,这可能会掩盖程序中严重的问题。最后强调一点,不要使用异常机制来处理正常业务逻辑或控制程序流程,简单的说就是不要滥用异常机制,这是初学者常犯的错误。## 第23课:用Python读写CSV文件
CSV文件介绍
CSV(Comma Separated Values)全称逗号分隔值文件是一种简单、通用的文件格式,被广泛的应用于应用程序(数据库、电子表格等)数据的导入和导出以及异构系统之间的数据交换。因为CSV是纯文本文件,不管是什么操作系统和编程语言都是可以处理纯文本的,而且很多编程语言中都提供了对读写CSV文件的支持,因此CSV格式在数据处理和数据科学中被广泛应用。
CSV文件有以下特点:
- 纯文本,使用某种字符集(如ASCII、Unicode、GB2312)等);
- 由一条条的记录组成(典型的是每行一条记录);
- 每条记录被分隔符(如逗号、分号、制表符等)分隔为字段(列);
- 每条记录都有同样的字段序列。
CSV文件可以使用文本编辑器或类似于Excel电子表格这类工具打开和编辑,当使用Excel这类电子表格打开CSV文件时,你甚至感觉不到CSV和Excel文件的区别。很多数据库系统都支持将数据导出到CSV文件中,当然也支持从CSV文件中读入数据保存到数据库中,这些内容并不是现在要讨论的重点。
将数据写入CSV文件
现有五个学生三门课程的考试成绩需要保存到一个CSV文件中,要达成这个目标,可以使用Python标准库中的csv模块,该模块的writer函数会返回一个csvwriter对象,通过该对象的writerow或writerows方法就可以将数据写入到CSV文件中,具体的代码如下所示。
import csv
import random
with open('scores.csv', 'w') as file:
writer = csv.writer(file)
writer.writerow(['姓名', '语文', '数学', '英语'])
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
for name in names:
scores = [random.randrange(50, 101) for _ in range(3)]
scores.insert(0, name)
writer.writerow(scores)
生成的CSV文件的内容。
姓名,语文,数学,英语
关羽,98,86,61
张飞,86,58,80
赵云,95,73,70
马超,83,97,55
黄忠,61,54,87
需要说明的是上面的writer函数,除了传入要写入数据的文件对象外,还可以dialect参数,它表示CSV文件的方言,默认值是excel。除此之外,还可以通过delimiter、quotechar、quoting参数来指定分隔符(默认是逗号)、包围值的字符(默认是双引号)以及包围的方式。其中,包围值的字符主要用于当字段中有特殊符号时,通过添加包围值的字符可以避免二义性。大家可以尝试将上面第5行代码修改为下面的代码,然后查看生成的CSV文件。
writer = csv.writer(file, delimiter='|', quoting=csv.QUOTE_ALL)
生成的CSV文件的内容。
"姓名"|"语文"|"数学"|"英语"
"关羽"|"88"|"64"|"65"
"张飞"|"76"|"93"|"79"
"赵云"|"78"|"55"|"76"
"马超"|"72"|"77"|"68"
"黄忠"|"70"|"72"|"51"
从CSV文件读取数据
如果要读取刚才创建的CSV文件,可以使用下面的代码,通过csv模块的reader函数可以创建出csvreader对象,该对象是一个迭代器,可以通过next函数或for-in循环读取到文件中的数据。
import csv
with open('scores.csv', 'r') as file:
reader = csv.reader(file, delimiter='|')
for data_list in reader:
print(reader.line_num, end='\t')
for elem in data_list:
print(elem, end='\t')
print()
注意:上面的代码对
csvreader对象做for循环时,每次会取出一个列表对象,该列表对象包含了一行中所有的字段。
简单的小结
将来如果大家使用Python做数据分析,很有可能会用到名为pandas的三方库,它是Python数据分析的神器之一。pandas中封装了名为read_csv和to_csv的函数用来读写CSV文件,其中read_CSV会将读取到的数据变成一个DataFrame对象,而DataFrame就是pandas库中最重要的类型,它封装了一系列用于数据处理的方法(清洗、转换、聚合等);而to_csv会将DataFrame对象中的数据写入CSV文件,完成数据的持久化。read_csv函数和to_csv函数远远比原生的csvreader和csvwriter强大。## 第26课:用Python操作Word和PowerPoint
在日常工作中,有很多简单重复的劳动其实完全可以交给Python程序,比如根据样板文件(模板文件)批量的生成很多个Word文件或PowerPoint文件。Word是微软公司开发的文字处理程序,相信大家都不陌生,日常办公中很多正式的文档都是用Word进行撰写和编辑的,目前使用的Word文件后缀名一般为.docx。PowerPoint是微软公司开发的演示文稿程序,是微软的Office系列软件中的一员,被商业人士、教师、学生等群体广泛使用,通常也将其称之为“幻灯片”。在Python中,可以使用名为python-docx 的三方库来操作Word,可以使用名为python-pptx的三方库来生成PowerPoint。
操作Word文档
我们可以先通过下面的命令来安装python-docx三方库。
pip install python-docx
按照官方文档的介绍,我们可以使用如下所示的代码来生成一个简单的Word文档。
from docx import Document
from docx.shared import Cm, Pt
from docx.document import Document as Doc
# 创建代表Word文档的Doc对象
document = Document() # type: Doc
# 添加大标题
document.add_heading('快快乐乐学Python', 0)
# 添加段落
p = document.add_paragraph('Python是一门非常流行的编程语言,它')
run = p.add_run('简单')
run.bold = True
run.font.size = Pt(18)
p.add_run('而且')
run = p.add_run('优雅')
run.font.size = Pt(18)
run.underline = True
p.add_run('。')
# 添加一级标题
document.add_heading('Heading, level 1', level=1)
# 添加带样式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
# 添加无序列表
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'second item in ordered list', style='List Bullet'
)
# 添加有序列表
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_paragraph(
'second item in ordered list', style='List Number'
)
# 添加图片(注意路径和图片必须要存在)
document.add_picture('resources/guido.jpg', width=Cm(5.2))
# 添加分节符
document.add_section()
records = (
('骆昊', '男', '1995-5-5'),
('孙美丽', '女', '1992-2-2')
)
# 添加表格
table = document.add_table(rows=1, cols=3)
table.style = 'Dark List'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '姓名'
hdr_cells[1].text = '性别'
hdr_cells[2].text = '出生日期'
# 为表格添加行
for name, sex, birthday in records:
row_cells = table.add_row().cells
row_cells[0].text = name
row_cells[1].text = sex
row_cells[2].text = birthday
# 添加分页符
document.add_page_break()
# 保存文档
document.save('demo.docx')
提示:上面代码第7行中的注释
# type: Doc是为了在PyCharm中获得代码补全提示,因为如果不清楚对象具体的数据类型,PyCharm无法在后续代码中给出Doc对象的代码补全提示。
对于一个已经存在的Word文件,我们可以通过下面的代码去遍历它所有的段落并获取对应的内容。
from docx import Document
from docx.document import Document as Doc
doc = Document('resources/离职证明.docx') # type: Doc
for no, p in enumerate(doc.paragraphs):
print(no, p.text)
提示:如果需要上面代码中的Word文件,可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g 提取码:e7b4。
读取到的内容如下所示。
0
1 离 职 证 明
2
3 兹证明 王大锤 ,身份证号码: 100200199512120001 ,于 2018 年 8 月 7 日至 2020 年 6 月 28 日在我单位 开发部 部门担任 Java开发工程师 职务,在职期间无不良表现。因 个人 原因,于 2020 年 6 月 28 日起终止解除劳动合同。现已结清财务相关费用,办理完解除劳动关系相关手续,双方不存在任何劳动争议。
4
5 特此证明!
6
7
8 公司名称(盖章):成都风车车科技有限公司
9 2020 年 6 月 28 日
讲到这里,相信很多读者已经想到了,我们可以把上面的离职证明制作成一个模板文件,把姓名、身份证号、入职和离职日期等信息用占位符代替,这样通过对占位符的替换,就可以根据实际需要写入对应的信息,这样就可以批量的生成Word文档。
将占位符替换为真实信息,就可以生成一个新的Word文档,如下所示。
from docx import Document
from docx.document import Document as Doc
# 将真实信息用字典的方式保存在列表中
employees = [
{
'name': '骆昊',
'id': '100200198011280001',
'sdate': '2008年3月1日',
'edate': '2012年2月29日',
'department': '产品研发',
'position': '架构师',
'company': '成都华为技术有限公司'
},
{
'name': '王大锤',
'id': '510210199012125566',
'sdate': '2019年1月1日',
'edate': '2021年4月30日',
'department': '产品研发',
'position': 'Python开发工程师',
'company': '成都谷道科技有限公司'
},
{
'name': '李元芳',
'id': '2102101995103221599',
'sdate': '2020年5月10日',
'edate': '2021年3月5日',
'department': '产品研发',
'position': 'Java开发工程师',
'company': '同城企业管理集团有限公司'
},
]
# 对列表进行循环遍历,批量生成Word文档
for emp_dict in employees:
# 读取离职证明模板文件
doc = Document('resources/离职证明模板.docx') # type: Doc
# 循环遍历所有段落寻找占位符
for p in doc.paragraphs:
if '{' not in p.text:
continue
# 不能直接修改段落内容,否则会丢失样式
# 所以需要对段落中的元素进行遍历并进行查找替换
for run in p.runs:
if '{' not in run.text:
continue
# 将占位符换成实际内容
start, end = run.text.find('{'), run.text.find('}')
key, place_holder = run.text[start + 1:end], run.text[start:end + 1]
run.text = run.text.replace(place_holder, emp_dict[key])
# 每个人对应保存一个Word文档
doc.save(f'{emp_dict["name"]}离职证明.docx')
执行上面的代码,会在当前路径下生成三个Word文档
生成PowerPoint
首先我们需要安装名为python-pptx的三方库,命令如下所示。
pip install python-pptx
用Python操作PowerPoint的内容,因为实际应用场景不算很多,我不打算在这里进行赘述,有兴趣的读者可以自行阅读python-pptx的官方文档,下面仅展示一段来自于官方文档的代码。
from pptx import Presentation
# 创建幻灯片对象
pres = Presentation()
# 选择母版添加一页
title_slide_layout = pres.slide_layouts[0]
slide = pres.slides.add_slide(title_slide_layout)
# 获取标题栏和副标题栏
title = slide.shapes.title
subtitle = slide.placeholders[1]
# 编辑标题和副标题
title.text = "Welcome to Python"
subtitle.text = "Life is short, I use Python"
# 选择母版添加一页
bullet_slide_layout = pres.slide_layouts[1]
slide = pres.slides.add_slide(bullet_slide_layout)
# 获取页面上所有形状
shapes = slide.shapes
# 获取标题和主体
title_shape = shapes.title
body_shape = shapes.placeholders[1]
# 编辑标题
title_shape.text = 'Introduction'
# 编辑主体内容
tf = body_shape.text_frame
tf.text = 'History of Python'
# 添加一个一级段落
p = tf.add_paragraph()
p.text = 'X\'max 1989'
p.level = 1
# 添加一个二级段落
p = tf.add_paragraph()
p.text = 'Guido began to write interpreter for Python.'
p.level = 2
# 保存幻灯片
pres.save('test.pptx')
简单的小结
用Python程序解决办公自动化的问题真的非常酷,它可以将我们从繁琐乏味的劳动中解放出来。写这类代码就是去做一件一劳永逸的事情,写代码的过程即便不怎么愉快,使用这些代码的时候应该是非常开心的。## 第27课:用Python操作PDF文件
PDF是Portable Document Format的缩写,这类文件通常使用.pdf作为其扩展名。在日常开发工作中,最容易遇到的就是从PDF中读取文本内容以及用已有的内容生成PDF文档这两个任务。
从PDF中提取文本
在Python中,可以使用名为PyPDF2的三方库来读取PDF文件,可以使用下面的命令来安装它。
pip install PyPDF2
PyPDF2没有办法从PDF文档中提取图像、图表或其他媒体,但它可以提取文本,并将其返回为Python字符串。
import PyPDF2
reader = PyPDF2.PdfFileReader('test.pdf')
page = reader.getPage(0)
print(page.extractText())
提示:上面代码中使用的PDF文件“test.pdf”以及下面的代码中需要用到的PDF文件,也可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g 提取码:e7b4。
当然,PyPDF2并不是什么样的PDF文档都能提取出文字来,这个问题就我所知并没有什么特别好的解决方法,尤其是在提取中文的时候。网上也有很多讲解从PDF中提取文字的文章,推荐大家自行阅读《三大神器助力Python提取pdf文档信息》一文进行了解。
要从PDF文件中提取文本也可以直接使用三方的命令行工具,具体的做法如下所示。
pip install pdfminer.six
pdf2text.py test.pdf
旋转和叠加页面
上面的代码中通过创建PdfFileReader对象的方式来读取PDF文档,该对象的getPage方法可以获得PDF文档的指定页并得到一个PageObject对象,通过PageObject对象的rotateClockwise和rotateCounterClockwise方法可以实现页面的顺时针和逆时针方向旋转,通过PageObject对象的addBlankPage方法可以添加一个新的空白页,代码如下所示。
import PyPDF2
from PyPDF2.pdf import PageObject
# 创建一个读PDF文件的Reader对象
reader = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
# 创建一个写PDF文件的Writer对象
writer = PyPDF2.PdfFileWriter()
# 对PDF文件所有页进行循环遍历
for page_num in range(reader.numPages):
# 获取指定页码的Page对象
current_page = reader.getPage(page_num) # type: PageObject
if page_num % 2 == 0:
# 奇数页顺时针旋转90度
current_page.rotateClockwise(90)
else:
# 偶数页反时针旋转90度
current_page.rotateCounterClockwise(90)
writer.addPage(current_page)
# 最后添加一个空白页并旋转90度
page = writer.addBlankPage() # type: PageObject
page.rotateClockwise(90)
# 通过Writer对象的write方法将PDF写入文件
with open('resources/XGBoost-modified.pdf', 'wb') as file:
writer.write(file)
加密PDF文件
使用PyPDF2中的PdfFileWrite对象可以为PDF文档加密,如果需要给一系列的PDF文档设置统一的访问口令,使用Python程序来处理就会非常的方便。
import PyPDF2
reader = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
writer = PyPDF2.PdfFileWriter()
for page_num in range(reader.numPages):
writer.addPage(reader.getPage(page_num))
# 通过encrypt方法加密PDF文件,方法的参数就是设置的密码
writer.encrypt('foobared')
with open('resources/XGBoost-encrypted.pdf', 'wb') as file:
writer.write(file)
批量添加水印
上面提到的PageObject对象还有一个名为mergePage的方法,可以两个PDF页面进行叠加,通过这个操作,我们很容易实现给PDF文件添加水印的功能。例如要给上面的“XGBoost.pdf”文件添加一个水印,我们可以先准备好一个提供水印页面的PDF文件,然后将包含水印的PageObject读取出来,然后再循环遍历“XGBoost.pdf”文件的每个页,获取到PageObject对象,然后通过mergePage方法实现水印页和原始页的合并,代码如下所示。
import PyPDF2
from PyPDF2.pdf import PageObject
reader1 = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
reader2 = PyPDF2.PdfFileReader('resources/watermark.pdf')
writer = PyPDF2.PdfFileWriter()
# 获取水印页
watermark_page = reader2.getPage(0)
for page_num in range(reader1.numPages):
current_page = reader1.getPage(page_num) # type: PageObject
current_page.mergePage(watermark_page)
# 将原始页和水印页进行合并
writer.addPage(current_page)
# 将PDF写入文件
with open('resources/XGBoost-watermarked.pdf', 'wb') as file:
writer.write(file)
如果愿意,还可以让奇数页和偶数页使用不同的水印,大家可以自己思考下应该怎么做。
创建PDF文件
创建PDF文档需要三方库reportlab的支持,安装的方法如下所示。
pip install reportlab
下面通过一个例子为大家展示reportlab的用法。
from reportlab.lib.pagesizes import A4
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.pdfgen import canvas
pdf_canvas = canvas.Canvas('resources/demo.pdf', pagesize=A4)
width, height = A4
# 绘图
image = canvas.ImageReader('resources/guido.jpg')
pdf_canvas.drawImage(image, 20, height - 395, 250, 375)
# 显示当前页
pdf_canvas.showPage()
# 注册字体文件
pdfmetrics.registerFont(TTFont('Font1', 'resources/fonts/Vera.ttf'))
pdfmetrics.registerFont(TTFont('Font2', 'resources/fonts/青呱石头体.ttf'))
# 写字
pdf_canvas.setFont('Font2', 40)
pdf_canvas.setFillColorRGB(0.9, 0.5, 0.3, 1)
pdf_canvas.drawString(width // 2 - 120, height // 2, '你好,世界!')
pdf_canvas.setFont('Font1', 40)
pdf_canvas.setFillColorRGB(0, 1, 0, 0.5)
pdf_canvas.rotate(18)
pdf_canvas.drawString(250, 250, 'hello, world!')
# 保存
pdf_canvas.save()
上面的代码如果不太理解也没有关系,等真正需要用Python创建PDF文档的时候,再好好研读一下reportlab的官方文档就可以了。
提示:上面代码中用到的图片和字体,也可以通过下面的百度云盘链接获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g 提取码:e7b4。
简单的小结
在学习完上面的内容之后,相信大家已经知道像合并多个PDF文件这样的工作应该如何用Python代码来处理了,赶紧自己动手试一试吧。## 第30课:正则表达式的应用
正则表达式相关知识
在编写处理字符串的程时,经常会遇到在一段文本中查找符合某些规则的字符串的需求,正则表达式就是用于描述这些规则的工具,换句话说,我们可以使用正则表达式来定义字符串的匹配模式,即如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉。
举一个简单的例子,如果你在Windows操作系统中使用过文件查找并且在指定文件名时使用过通配符(*和?),那么正则表达式也是与之类似的用 来进行文本匹配的工具,只不过比起通配符正则表达式更强大,它能更精确地描述你的需求,当然你付出的代价是书写一个正则表达式比使用通配符要复杂得多,因为任何给你带来好处的东西都需要你付出对应的代价。
再举一个例子,我们从某个地方(可能是一个文本文件,也可能是网络上的一则新闻)获得了一个字符串,希望在字符串中找出手机号和座机号。当然我们可以设定手机号是11位的数字(注意并不是随机的11位数字,因为你没有见过“25012345678”这样的手机号),而座机号则是类似于“区号-号码”这样的模式,如果不使用正则表达式要完成这个任务就会比较麻烦。最初计算机是为了做数学运算而诞生的,处理的信息基本上都是数值,而今天我们在日常工作中处理的信息很多都是文本数据,我们希望计算机能够识别和处理符合某些模式的文本,正则表达式就显得非常重要了。今天几乎所有的编程语言都提供了对正则表达式操作的支持,Python通过标准库中的re模块来支持正则表达式操作。
关于正则表达式的相关知识,大家可以阅读一篇非常有名的博文叫《正则表达式30分钟入门教程》,读完这篇文章后你就可以看懂下面的表格,这是我们对正则表达式中的一些基本符号进行的扼要总结。
| 符号 | 解释 | 示例 | 说明 |
|---|---|---|---|
. | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 |
\w | 匹配字母/数字/下划线 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t |
\s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you |
\d | 匹配数字 | \d\d | 可以匹配01 / 23 / 99等 |
\b | 匹配单词的边界 | \bThe\b | |
^ | 匹配字符串的开始 | ^The | 可以匹配The开头的字符串 |
$ | 匹配字符串的结束 | .exe$ | 可以匹配.exe结尾的字符串 |
\W | 匹配非字母/数字/下划线 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 |
\S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you |
\D | 匹配非数字 | \d\D | 可以匹配9a / 3# / 0F等 |
\B | 匹配非单词边界 | \Bio\B | |
[] | 匹配来自字符集的任意单一字符 | [aeiou] | 可以匹配任一元音字母字符 |
[^] | 匹配不在字符集中的任意单一字符 | [^aeiou] | 可以匹配任一非元音字母字符 |
* | 匹配0次或多次 | \w* | |
+ | 匹配1次或多次 | \w+ | |
? | 匹配0次或1次 | \w? | |
{N} | 匹配N次 | \w{3} | |
{M,} | 匹配至少M次 | \w{3,} | |
{M,N} | 匹配至少M次至多N次 | \w{3,6} | |
| ` | ` | 分支 | `foo |
(?#) | 注释 | ||
(exp) | 匹配exp并捕获到自动命名的组中 | ||
(?<name>exp) | 匹配exp并捕获到名为name的组中 | ||
(?:exp) | 匹配exp但是不捕获匹配的文本 | ||
(?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I’m dancing中的danc |
(?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一个ing |
(?!exp) | 匹配后面不是exp的位置 | ||
(?<!exp) | 匹配前面不是exp的位置 | ||
*? | 重复任意次,但尽可能少重复 | a.*ba.*?b | 将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串 |
+? | 重复1次或多次,但尽可能少重复 | ||
?? | 重复0次或1次,但尽可能少重复 | ||
{M,N}? | 重复M到N次,但尽可能少重复 | ||
{M,}? | 重复M次以上,但尽可能少重复 |
说明: 如果需要匹配的字符是正则表达式中的特殊字符,那么可以使用
\进行转义处理,例如想匹配小数点可以写成\.就可以了,因为直接写.会匹配任意字符;同理,想匹配圆括号必须写成\(和\),否则圆括号被视为正则表达式中的分组。
Python对正则表达式的支持
Python提供了re模块来支持正则表达式相关操作,下面是re模块中的核心函数。
| 函数 | 说明 |
|---|---|
compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
purge() | 清除隐式编译的正则表达式的缓存 |
re.I / re.IGNORECASE | 忽略大小写匹配标记 |
re.M / re.MULTILINE | 多行匹配标记 |
说明: 上面提到的
re模块中的这些函数,实际开发中也可以用正则表达式对象(Pattern对象)的方法替代对这些函数的使用,如果一个正则表达式需要重复的使用,那么先通过compile函数编译正则表达式并创建出正则表达式对象无疑是更为明智的选择。
下面我们通过一系列的例子来告诉大家在Python中如何使用正则表达式。
例子1:验证输入用户名和QQ号是否有效并给出对应的提示信息。
"""
要求:用户名必须由字母、数字或下划线构成且长度在6~20个字符之间,QQ号是5~12的数字且首位不能为0
"""
import re
username = input('请输入用户名: ')
qq = input('请输入QQ号: ')
# match函数的第一个参数是正则表达式字符串或正则表达式对象
# match函数的第二个参数是要跟正则表达式做匹配的字符串对象
m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)
if not m1:
print('请输入有效的用户名.')
# fullmatch函数要求字符串和正则表达式完全匹配
# 所以正则表达式没有写起始符和结束符
m2 = re.fullmatch(r'[1-9]\d{4,11}', qq)
if not m2:
print('请输入有效的QQ号.')
if m1 and m2:
print('你输入的信息是有效的!')
提示: 上面在书写正则表达式时使用了“原始字符串”的写法(在字符串前面加上了
r),所谓“原始字符串”就是字符串中的每个字符都是它原始的意义,说得更直接一点就是字符串中没有所谓的转义字符啦。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\\,例如表示数字的\d得书写成\\d,这样不仅写起来不方便,阅读的时候也会很吃力。
例子2:从一段文字中提取出国内手机号码。
import re
# 创建正则表达式对象,使用了前瞻和回顾来保证手机号前后不应该再出现数字
pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')
sentence = '''重要的事情说8130123456789遍,我的手机号是13512346789这个靓号,
不是15600998765,也是110或119,王大锤的手机号才是15600998765。'''
# 方法一:查找所有匹配并保存到一个列表中
tels_list = re.findall(pattern, sentence)
for tel in tels_list:
print(tel)
print('--------华丽的分隔线--------')
# 方法二:通过迭代器取出匹配对象并获得匹配的内容
for temp in pattern.finditer(sentence):
print(temp.group())
print('--------华丽的分隔线--------')
# 方法三:通过search函数指定搜索位置找出所有匹配
m = pattern.search(sentence)
while m:
print(m.group())
m = pattern.search(sentence, m.end())
说明: 上面匹配国内手机号的正则表达式并不够好,因为像14开头的号码只有145或147,而上面的正则表达式并没有考虑这种情况,要匹配国内手机号,更好的正则表达式的写法是:
(?<=\D)(1[38]\d{9}|14[57]\d{8}|15[0-35-9]\d{8}|17[678]\d{8})(?=\D),国内好像已经有19和16开头的手机号了,但是这个暂时不在我们考虑之列。
例子3:替换字符串中的不良内容
import re
sentence = 'Oh, shit! 你是傻逼吗? Fuck you.'
purified = re.sub('fuck|shit|[傻煞沙][比笔逼叉缺吊碉雕]',
'*', sentence, flags=re.IGNORECASE)
print(purified) # Oh, *! 你是*吗? * you.
说明:
re模块的正则表达式相关函数中都有一个flags参数,它代表了正则表达式的匹配标记,可以通过该标记来指定匹配时是否忽略大小写、是否进行多行匹配、是否显示调试信息等。如果需要为flags参数指定多个值,可以使用按位或运算符进行叠加,如flags=re.I | re.M。
例子4:拆分长字符串
import re
poem = '窗前明月光,疑是地上霜。举头望明月,低头思故乡。'
sentences_list = re.split(r'[,。]', poem)
sentences_list = [sentence for sentence in sentences_list if sentence]
for sentence in sentences_list:
print(sentence)
简单的小结
正则表达式在字符串的处理和匹配上真的非常强大,通过上面的例子相信大家已经感受到了正则表达式的魅力,当然写一个正则表达式对新手来说并不是那么容易,但是很多事情都是熟能生巧,大胆的去尝试就行了,有一个在线的正则表达式测试工具相信能够在一定程度上帮到大家。## 第34课:Python中的并发编程-1
现如今,我们使用的计算机早已是多 CPU 或多核的计算机,而我们使用的操作系统基本都支持“多任务”,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务“并行”或“并发”的执行,从而缩短程序的执行时间,同时也让用户获得更好的体验。因此当下,不管用什么编程语言进行开发,实现“并行”或“并发”编程已经成为了程序员的标配技能。为了讲述如何在 Python 程序中实现“并行”或“并发”,我们需要先了解两个重要的概念:进程和线程。
线程和进程
我们通过操作系统运行一个程序会创建出一个或多个进程,进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。简单的说,进程是操作系统分配存储空间的基本单位,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据;操作系统管理所有进程的执行,为它们合理的分配资源。一个进程可以通过 fork 或 spawn 的方式创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此两个进程如果要共享数据,必须通过进程间通信机制来实现,具体的方式包括管道、信号、套接字等。
一个进程还可以拥有多个执行线索,简单的说就是拥有多个可以获得 CPU 调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核 CPU 系统中,多个线程不可能同时执行,因为在某个时刻只有一个线程能够获得 CPU,多个线程通过共享 CPU 执行时间的方式来达到并发的效果。
在程序中使用多线程技术通常都会带来不言而喻的好处,最主要的体现在提升程序的性能和改善用户体验,今天我们使用的软件几乎都用到了多线程技术,这一点可以利用系统自带的进程监控工具(如 macOS 中的“活动监视器”、Windows 中的“任务管理器”)来证实
这里,我们还需要跟大家再次强调两个概念:并发(concurrency)和并行(parallel)。并发通常是指同一时刻只能有一条指令执行,但是多个线程对应的指令被快速轮换地执行。比如一个处理器,它先执行线程 A 的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A 执行一段时间。由于处理器执行指令的速度和切换的速度极快,人们完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行,但微观上其实只有一个线程在执行。并行是指同一时刻,有多条指令在多个处理器上同时执行,并行必须要依赖于多个处理器,不论是从宏观上还是微观上,多个线程可以在同一时刻一起执行的。很多时候,我们并不用严格区分并发和并行两个词,所以我们有时候也把 Python 中的多线程、多进程以及异步 I/O 都视为实现并发编程的手段,但实际上前面两者也可以实现并行编程,当然这里还有一个全局解释器锁(GIL)的问题,我们稍后讨论。
多线程编程
Python 标准库中threading模块的Thread类可以帮助我们非常轻松的实现多线程编程。我们用一个联网下载文件的例子来对比使用多线程和不使用多线程到底有什么区别,代码如下所示。
不使用多线程的下载。
import random
import time
def download(*, filename):
start = time.time()
print(f'开始下载 {filename}.')
time.sleep(random.randint(3, 6))
print(f'{filename} 下载完成.')
end = time.time()
print(f'下载耗时: {end - start:.3f}秒.')
def main():
start = time.time()
download(filename='Python从入门到住院.pdf')
download(filename='MySQL从删库到跑路.avi')
download(filename='Linux从精通到放弃.mp4')
end = time.time()
print(f'总耗时: {end - start:.3f}秒.')
if __name__ == '__main__':
main()
说明:上面的代码并没有真正实现联网下载的功能,而是通过
time.sleep()休眠一段时间来模拟下载文件需要一些时间上的开销,跟实际下载的状况比较类似。
运行上面的代码,可以得到如下所示的运行结果。可以看出,当我们的程序只有一个工作线程时,每个下载任务都需要等待上一个下载任务执行结束才能开始,所以程序执行的总耗时是三个下载任务各自执行时间的总和。
开始下载Python从入门到住院.pdf.
Python从入门到住院.pdf下载完成.
下载耗时: 3.005秒.
开始下载MySQL从删库到跑路.avi.
MySQL从删库到跑路.avi下载完成.
下载耗时: 5.006秒.
开始下载Linux从精通到放弃.mp4.
Linux从精通到放弃.mp3下载完成.
下载耗时: 6.007秒.
总耗时: 14.018秒.
事实上,上面的三个下载任务之间并没有逻辑上的因果关系,三者是可以“并发”的,下一个下载任务没有必要等待上一个下载任务结束,为此,我们可以使用多线程编程来改写上面的代码。
import random
import time
from threading import Thread
def download(*, filename):
start = time.time()
print(f'开始下载 {filename}.')
time.sleep(random.randint(3, 6))
print(f'{filename} 下载完成.')
end = time.time()
print(f'下载耗时: {end - start:.3f}秒.')
def main():
threads = [
Thread(target=download, kwargs={'filename': 'Python从入门到住院.pdf'}),
Thread(target=download, kwargs={'filename': 'MySQL从删库到跑路.avi'}),
Thread(target=download, kwargs={'filename': 'Linux从精通到放弃.mp4'})
]
start = time.time()
# 启动三个线程
for thread in threads:
thread.start()
# 等待线程结束
for thread in threads:
thread.join()
end = time.time()
print(f'总耗时: {end - start:.3f}秒.')
if __name__ == '__main__':
main()
某次的运行结果如下所示。
开始下载 Python从入门到住院.pdf.
开始下载 MySQL从删库到跑路.avi.
开始下载 Linux从精通到放弃.mp4.
MySQL从删库到跑路.avi 下载完成.
下载耗时: 3.005秒.
Python从入门到住院.pdf 下载完成.
下载耗时: 5.006秒.
Linux从精通到放弃.mp4 下载完成.
下载耗时: 6.003秒.
总耗时: 6.004秒.
通过上面的运行结果可以发现,整个程序的执行时间几乎等于耗时最长的一个下载任务的执行时间,这也就意味着,三个下载任务是并发执行的,不存在一个等待另一个的情况,这样做很显然提高了程序的执行效率。简单的说,如果程序中有非常耗时的执行单元,而这些耗时的执行单元之间又没有逻辑上的因果关系,即 B 单元的执行不依赖于 A 单元的执行结果,那么 A 和 B 两个单元就可以放到两个不同的线程中,让他们并发的执行。这样做的好处除了减少程序执行的等待时间,还可以带来更好的用户体验,因为一个单元的阻塞不会造成程序的“假死”,因为程序中还有其他的单元是可以运转的。
使用 Thread 类创建线程对象
通过上面的代码可以看出,直接使用Thread类的构造器就可以创建线程对象,而线程对象的start()方法可以启动一个线程。线程启动后会执行target参数指定的函数,当然前提是获得 CPU 的调度;如果target指定的线程要执行的目标函数有参数,需要通过args参数为其进行指定,对于关键字参数,可以通过kwargs参数进行传入。Thread类的构造器还有很多其他的参数,我们遇到的时候再为大家进行讲解,目前需要大家掌握的,就是target、args和kwargs。
继承 Thread 类自定义线程
除了上面的代码展示的创建线程的方式外,还可以通过继承Thread类并重写run()方法的方式来自定义线程,具体的代码如下所示。
import random
import time
from threading import Thread
class DownloadThread(Thread):
def __init__(self, filename):
self.filename = filename
super().__init__()
def run(self):
start = time.time()
print(f'开始下载 {self.filename}.')
time.sleep(random.randint(3, 6))
print(f'{self.filename} 下载完成.')
end = time.time()
print(f'下载耗时: {end - start:.3f}秒.')
def main():
threads = [
DownloadThread('Python从入门到住院.pdf'),
DownloadThread('MySQL从删库到跑路.avi'),
DownloadThread('Linux从精通到放弃.mp4')
]
start = time.time()
# 启动三个线程
for thread in threads:
thread.start()
# 等待线程结束
for thread in threads:
thread.join()
end = time.time()
print(f'总耗时: {end - start:.3f}秒.')
if __name__ == '__main__':
main()
使用线程池
我们还可以通过线程池的方式将任务放到多个线程中去执行,通过线程池来使用线程应该是多线程编程最理想的选择。事实上,线程的创建和释放都会带来较大的开销,频繁的创建和释放线程通常都不是很好的选择。利用线程池,可以提前准备好若干个线程,在使用的过程中不需要再通过自定义的代码创建和释放线程,而是直接复用线程池中的线程。Python 内置的concurrent.futures模块提供了对线程池的支持,代码如下所示。
import random
import time
from concurrent.futures import ThreadPoolExecutor
from threading import Thread
def download(*, filename):
start = time.time()
print(f'开始下载 {filename}.')
time.sleep(random.randint(3, 6))
print(f'{filename} 下载完成.')
end = time.time()
print(f'下载耗时: {end - start:.3f}秒.')
def main():
with ThreadPoolExecutor(max_workers=4) as pool:
filenames = ['Python从入门到住院.pdf', 'MySQL从删库到跑路.avi', 'Linux从精通到放弃.mp4']
start = time.time()
for filename in filenames:
pool.submit(download, filename=filename)
end = time.time()
print(f'总耗时: {end - start:.3f}秒.')
if __name__ == '__main__':
main()
守护线程
所谓“守护线程”就是在主线程结束的时候,不值得再保留的执行线程。这里的不值得保留指的是守护线程会在其他非守护线程全部运行结束之后被销毁,它守护的是当前进程内所有的非守护线程。简单的说,守护线程会跟随主线程一起挂掉,而主线程的生命周期就是一个进程的生命周期。如果不理解,我们可以看一段简单的代码。
import time
from threading import Thread
def display(content):
while True:
print(content, end='', flush=True)
time.sleep(0.1)
def main():
Thread(target=display, args=('Ping', )).start()
Thread(target=display, args=('Pong', )).start()
if __name__ == '__main__':
main()
说明:上面的代码中,我们将
flush设置为True,这是因为flush参数的值如果为False,而flush参数设置为True,强制每次输出都清空输出缓冲区。
上面的代码运行起来之后是不会停止的,因为两个子线程中都有死循环,除非你手动中断代码的执行。但是,如果在创建线程对象时,将名为daemon的参数设置为True,这两个线程就会变成守护线程,那么在其他线程结束时,即便有死循环,两个守护线程也会挂掉,不会再继续执行下去,代码如下所示。
import time
from threading import Thread
def display(content):
while True:
print(content, end='', flush=True)
time.sleep(0.1)
def main():
Thread(target=display, args=('Ping', ), daemon=True).start()
Thread(target=display, args=('Pong', ), daemon=True).start()
time.sleep(5)
if __name__ == '__main__':
main()
上面的代码,我们在主线程中添加了一行time.sleep(5)让主线程休眠5秒,在这个过程中,输出Ping和Pong的守护线程会持续运转,直到主线程在5秒后结束,这两个守护线程也被销毁,不再继续运行。
思考:如果将上面代码第12行的
daemon=True去掉,代码会怎样执行?有兴趣的读者可以尝试一下,并看看实际执行的结果跟你想象的是否一致。
资源竞争
在编写多线程代码时,不可避免的会遇到多个线程竞争同一个资源(对象)的情况。在这种情况下,如果没有合理的机制来保护被竞争的资源,那么就有可能出现非预期的状况。下面的代码创建了100个线程向同一个银行账户(初始余额为0元)转账,每个线程转账金额为1元。在正常的情况下,我们的银行账户最终的余额应该是100元,但是运行下面的代码我们并不能得到100元这个结果。
import time
from concurrent.futures import ThreadPoolExecutor
class Account(object):
"""银行账户"""
def __init__(self):
self.balance = 0.0
def deposit(self, money):
"""存钱"""
new_balance = self.balance + money
time.sleep(0.01)
self.balance = new_balance
def main():
"""主函数"""
account = Account()
with ThreadPoolExecutor(max_workers=16) as pool:
for _ in range(100):
pool.submit(account.deposit, 1)
print(account.balance)
if __name__ == '__main__':
main()
上面代码中的Account类代表了银行账户,它的deposit方法代表存款行为,参数money代表存入的金额,该方法通过time.sleep函数模拟受理存款需要一段时间。我们通过线程池的方式启动了100个线程向一个账户转账,但是上面的代码并不能运行出100这个我们期望的结果,这就是在多个线程竞争一个资源的时候,可能会遇到的数据不一致的问题。注意上面代码的第14行,当多个线程都执行到这行代码时,它们会在相同的余额上执行加上存入金额的操作,这就会造成“丢失更新”现象,即之前修改数据的成果被后续的修改给覆盖掉了,所以才得不到正确的结果。
要解决上面的问题,可以使用锁机制,通过锁对操作数据的关键代码加以保护。Python 标准库的threading模块提供了Lock和RLock类来支持锁机制,这里我们不去深究二者的区别,建议大家直接使用RLock。接下来,我们给银行账户添加一个锁对象,通过锁对象来解决刚才存款时发生“丢失更新”的问题,代码如下所示。
import time
from concurrent.futures import ThreadPoolExecutor
from threading import RLock
class Account(object):
"""银行账户"""
def __init__(self):
self.balance = 0.0
self.lock = RLock()
def deposit(self, money):
# 获得锁
self.lock.acquire()
try:
new_balance = self.balance + money
time.sleep(0.01)
self.balance = new_balance
finally:
# 释放锁
self.lock.release()
def main():
"""主函数"""
account = Account()
with ThreadPoolExecutor(max_workers=16) as pool:
for _ in range(100):
pool.submit(account.deposit, 1)
print(account.balance)
if __name__ == '__main__':
main()
上面代码中,获得锁和释放锁的操作也可以通过上下文语法来实现,使用上下文语法会让代码更加简单优雅,这也是我们推荐大家使用的方式。
import time
from concurrent.futures import ThreadPoolExecutor
from threading import RLock
class Account(object):
"""银行账户"""
def __init__(self):
self.balance = 0.0
self.lock = RLock()
def deposit(self, money):
# 通过上下文语法获得锁和释放锁
with self.lock:
new_balance = self.balance + money
time.sleep(0.01)
self.balance = new_balance
def main():
"""主函数"""
account = Account()
with ThreadPoolExecutor(max_workers=16) as pool:
for _ in range(100):
pool.submit(account.deposit, 1)
print(account.balance)
if __name__ == '__main__':
main()
思考:将上面的代码修改为5个线程向银行账户存钱,5个线程从银行账户取钱,取钱的线程在银行账户余额不足时,需要停下来等待存钱的线程将钱存入后再尝试取钱。这里需要用到线程调度的知识,大家可以自行研究下
threading模块中的Condition类,看看是否能够完成这个任务。
GIL问题
如果使用官方的 Python 解释器(通常称之为 CPython)运行 Python 程序,我们并不能通过使用多线程的方式将 CPU 的利用率提升到逼近400%(对于4核 CPU)或逼近800%(对于8核 CPU)这样的水平,因为 CPython 在执行代码时,会受到 GIL(全局解释器锁)的限制。具体的说,CPython 在执行任何代码时,都需要对应的线程先获得 GIL,然后每执行100条(字节码)指令,CPython 就会让获得 GIL 的线程主动释放 GIL,这样别的线程才有机会执行。因为 GIL 的存在,无论你的 CPU 有多少个核,我们编写的 Python 代码也没有机会真正并行的执行。
GIL 是官方 Python 解释器在设计上的历史遗留问题,要解决这个问题,让多线程能够发挥 CPU 的多核优势,需要重新实现一个不带 GIL 的 Python 解释器。这个问题按照官方的说法,在 Python 发布4.0版本时会得到解决,就让我们拭目以待吧。当下,对于 CPython 而言,如果希望充分发挥 CPU 的多核优势,可以考虑使用多进程,因为每个进程都对应一个 Python 解释器,因此每个进程都有自己独立的 GIL,这样就可以突破 GIL 的限制。在下一个章节中,我们会为大家介绍关于多进程的相关知识,并对多线程和多进程的代码及其执行效果进行比较。
Python中的并发编程
在上一课中我们说过,由于 GIL 的存在,CPython 中的多线程并不能发挥 CPU 的多核优势,如果希望突破 GIL 的限制,可以考虑使用多进程。对于多进程的程序,每个进程都有一个属于自己的 GIL,所以多进程不会受到 GIL 的影响。那么,我们应该如何在 Python 程序中创建和使用多进程呢?
创建进程
在 Python 中可以基于Process类来创建进程,虽然进程和线程有着本质的差别,但是Process类和Thread类的用法却非常类似。在使用Process类的构造器创建对象时,也是通过target参数传入一个函数来指定进程要执行的代码,而args和kwargs参数可以指定该函数使用的参数值。
from multiprocessing import Process, current_process
from time import sleep
def sub_task(content, nums):
# 通过current_process函数获取当前进程对象
# 通过进程对象的pid和name属性获取进程的ID号和名字
print(f'PID: {current_process().pid}')
print(f'Name: {current_process().name}')
# 通过下面的输出不难发现,每个进程都有自己的nums列表,进程之间本就不共享内存
# 在创建子进程时复制了父进程的数据结构,三个进程从列表中pop(0)得到的值都是20
counter, total = 0, nums.pop(0)
print(f'Loop count: {total}')
sleep(0.5)
while counter < total:
counter += 1
print(f'{counter}: {content}')
sleep(0.01)
def main():
nums = [20, 30, 40]
# 创建并启动进程来执行指定的函数
Process(target=sub_task, args=('Ping', nums)).start()
Process(target=sub_task, args=('Pong', nums)).start()
# 在主进程中执行sub_task函数
sub_task('Good', nums)
if __name__ == '__main__':
main()
说明:上面的代码通过
current_process函数获取当前进程对象,再通过进程对象的pid属性获取进程ID。在 Python 中,使用os模块的getpid函数也可以达到同样的效果。
如果愿意,也可以使用os模块的fork函数来创建进程,调用该函数时,操作系统自动把当前进程(父进程)复制一份(子进程),父进程的fork函数会返回子进程的ID,而子进程中的fork函数会返回0,也就是说这个函数调用一次会在父进程和子进程中得到两个不同的返回值。需要注意的是,Windows 系统并不支持fork函数,如果你使用的是 Linux 或 macOS 系统,可以试试下面的代码。
import os
print(f'PID: {os.getpid()}')
pid = os.fork()
if pid == 0:
print(f'子进程 - PID: {os.getpid()}')
print('Todo: 在子进程中执行的代码')
else:
print(f'父进程 - PID: {os.getpid()}')
print('Todo: 在父进程中执行的代码')
简而言之,我们还是推荐大家通过直接使用Process类、继承Process类和使用进程池(ProcessPoolExecutor)这三种方式来创建和使用多进程,这三种方式不同于上面的fork函数,能够保证代码的兼容性和可移植性。具体的做法跟之前讲过的创建和使用多线程的方式比较接近,此处不再进行赘述。
多进程和多线程的比较
对于爬虫这类 I/O 密集型任务来说,使用多进程并没有什么优势;但是对于计算密集型任务来说,多进程相比多线程,在效率上会有显著的提升,我们可以通过下面的代码来加以证明。下面的代码会通过多线程和多进程两种方式来判断一组大整数是不是质数,很显然这是一个计算密集型任务,我们将任务分别放到多个线程和多个进程中来加速代码的执行,让我们看看多线程和多进程的代码具体表现有何不同。
我们先实现一个多线程的版本,代码如下所示。
import concurrent.futures
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return n != 1
def main():
"""主函数"""
with concurrent.futures.ThreadPoolExecutor(max_workers=16) as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
假设上面的代码保存在名为example.py的文件中,在 Linux 或 macOS 系统上,可以使用time python example.py命令执行程序并获得操作系统关于执行时间的统计,在我的 macOS 上,某次的运行结果的最后一行输出如下所示。
python example09.py 38.69s user 1.01s system 101% cpu 39.213 total
从运行结果可以看出,多线程的代码只能让 CPU 利用率达到100%,这其实已经证明了多线程的代码无法利用 CPU 多核特性来加速代码的执行,我们再看看多进程的版本,我们将上面代码中的线程池(ThreadPoolExecutor)更换为进程池(ProcessPoolExecutor)。
多进程的版本。
import concurrent.futures
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return n != 1
def main():
"""主函数"""
with concurrent.futures.ProcessPoolExecutor(max_workers=16) as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
提示:运行上面的代码时,可以通过操作系统的任务管理器(资源监视器)来查看是否启动了多个 Python 解释器进程。
我们仍然通过time python example.py的方式来执行上述代码,运行结果的最后一行如下所示。
python example09.py 106.63s user 0.57s system 389% cpu 27.497 total
可以看出,多进程的版本在我使用的这台电脑上,让 CPU 的利用率达到了将近400%,而运行代码时用户态耗费的 CPU 的时间(106.63秒)几乎是代码运行总时间(27.497秒)的4倍,从这两点都可以看出,我的电脑使用了一款4核的 CPU。当然,要知道自己的电脑有几个 CPU 或几个核,可以直接使用下面的代码。
import os
print(os.cpu_count())
综上所述,多进程可以突破 GIL 的限制,充分利用 CPU 多核特性,对于计算密集型任务,这一点是相当重要的。常见的计算密集型任务包括科学计算、图像处理、音视频编解码等,如果这些计算密集型任务本身是可以并行的,那么使用多进程应该是更好的选择。
进程间通信
在讲解进程间通信之前,先给大家一个任务:启动两个进程,一个输出“Ping”,一个输出“Pong”,两个进程输出的“Ping”和“Pong”加起来一共有50个时,就结束程序。听起来是不是非常简单,但是实际编写代码时,由于多个进程之间不能够像多个线程之间直接通过共享内存的方式交换数据,所以下面的代码是达不到我们想要的结果的。
from multiprocessing import Process
from time import sleep
counter = 0
def sub_task(string):
global counter
while counter < 50:
print(string, end='', flush=True)
counter += 1
sleep(0.01)
def main():
Process(target=sub_task, args=('Ping', )).start()
Process(target=sub_task, args=('Pong', )).start()
if __name__ == '__main__':
main()
上面的代码看起来没毛病,但是最后的结果是“Ping”和“Pong”各输出了50个。再次提醒大家,当我们在程序中创建进程的时候,子进程会复制父进程及其所有的数据结构,每个子进程有自己独立的内存空间,这也就意味着两个子进程中各有一个counter变量,它们都会从0加到50,所以结果就可想而知了。要解决这个问题比较简单的办法是使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,底层是通过操作系统底层的管道和信号量(semaphore)机制来实现的,代码如下所示。
import time
from multiprocessing import Process, Queue
def sub_task(content, queue):
counter = queue.get()
while counter < 50:
print(content, end='', flush=True)
counter += 1
queue.put(counter)
time.sleep(0.01)
counter = queue.get()
def main():
queue = Queue()
queue.put(0)
p1 = Process(target=sub_task, args=('Ping', queue))
p1.start()
p2 = Process(target=sub_task, args=('Pong', queue))
p2.start()
while p1.is_alive() and p2.is_alive():
pass
queue.put(50)
if __name__ == '__main__':
main()
提示:
multiprocessing.Queue对象的get方法默认在队列为空时是会阻塞的,直到获取到数据才会返回。如果不希望该方法阻塞以及需要指定阻塞的超时时间,可以通过指定block和timeout参数进行设定。
上面的代码通过Queue类的get和put方法让三个进程(p1、p2和主进程)实现了数据的共享,这就是所谓的进程间的通信,通过这种方式,当Queue中取出的值已经大于等于50时,p1和p2就会跳出while循环,从而终止进程的执行。代码第22行的循环是为了等待p1和p2两个进程中的一个结束,这时候主进程还需要向Queue中放置一个大于等于50的值,这样另一个尚未结束的进程也会因为读到这个大于等于50的值而终止。
进程间通信的方式还有很多,比如使用套接字也可以实现两个进程的通信,甚至于这两个进程并不在同一台主机上,有兴趣的读者可以自行了解。
简单的小结
在 Python 中,我们还可以通过subprocess模块的call函数执行其他的命令来创建子进程,相当于就是在我们的程序中调用其他程序,这里我们暂不探讨这些知识,有兴趣的读者可以自行研究。
对于Python开发者来说,以下情况需要考虑使用多线程:
- 程序需要维护许多共享的状态(尤其是可变状态),Python 中的列表、字典、集合都是线程安全的(多个线程同时操作同一个列表、字典或集合,不会引发错误和数据问题),所以使用线程而不是进程维护共享状态的代价相对较小。
- 程序会花费大量时间在 I/O 操作上,没有太多并行计算的需求且不需占用太多的内存。
那么在遇到下列情况时,应该考虑使用多进程:
- 程序执行计算密集型任务(如:音视频编解码、数据压缩、科学计算等)。
- 程序的输入可以并行的分成块,并且可以将运算结果合并。
- 程序在内存使用方面没有任何限制且不强依赖于 I/O 操作(如读写文件、套接字等)。## 第36课:Python中的并发编程-3
爬虫是典型的 I/O 密集型任务,I/O 密集型任务的特点就是程序会经常性的因为 I/O 操作而进入阻塞状态,比如我们之前使用requests获取页面代码或二进制内容,发出一个请求之后,程序必须要等待网站返回响应之后才能继续运行,如果目标网站不是很给力或者网络状况不是很理想,那么等待响应的时间可能会很久,而在这个过程中整个程序是一直阻塞在那里,没有做任何的事情。通过前面的课程,我们已经知道了可以通过多线程的方式为爬虫提速,使用多线程的本质就是,当一个线程阻塞的时候,程序还有其他的线程可以继续运转,因此整个程序就不会在阻塞和等待中浪费了大量的时间。
事实上,还有一种非常适合 I/O 密集型任务的并发编程方式,我们称之为异步编程,你也可以将它称为异步 I/O。这种方式并不需要启动多个线程或多个进程来实现并发,它是通过多个子程序相互协作的方式来提升 CPU 的利用率,解决了 I/O 密集型任务 CPU 利用率很低的问题,我一般将这种方式称为“协作式并发”。这里,我不打算探讨操作系统的各种 I/O 模式,因为这对很多读者来说都太过抽象;但是我们得先抛出两组概念给大家,一组叫做“阻塞”和“非阻塞”,一组叫做“同步”和“异步”。
基本概念
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。阻塞随时都可能发生,最典型的就是 I/O 中断(包括网络 I/O 、磁盘 I/O 、用户输入等)、休眠操作、等待某个线程执行结束,甚至包括在 CPU 切换上下文时,程序都无法真正的执行,这就是所谓的阻塞。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。非阻塞并不是在任何程序级别、任何情况下都可以存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。显然,某个操作的阻塞可能会导程序耗时以及效率低下,所以我们会希望把它变成非阻塞的。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。例如前面讲过的给银行账户存钱的操作,我们在代码中使用了“锁”作为通信信号,让多个存钱操作强制排队顺序执行,这就是所谓的同步。
异步
不同程序单元在执行过程中无需通信协调,也能够完成一个任务,这种方式我们就称之为异步。例如,使用爬虫下载页面时,调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是不相关的,也无需相互通知协调。很显然,异步操作的完成时刻和先后顺序并不能确定。
很多人都不太能准确的把握这几个概念,这里我们简单的总结一下,同步与异步的关注点是消息通信机制,最终表现出来的是“有序”和“无序”的区别;阻塞和非阻塞的关注点是程序在等待消息时状态,最终表现出来的是程序在等待时能不能做点别的。
生成器和协程
前面我们说过,异步编程是一种“协作式并发”,即通过多个子程序相互协作的方式提升 CPU 的利用率,从而减少程序在阻塞和等待中浪费的时间,最终达到并发的效果。我们可以将多个相互协作的子程序称为“协程”,它是实现异步编程的关键。在介绍协程之前,我们先通过下面的代码,看看什么是生成器。
def fib(max_count):
a, b = 0, 1
for _ in range(max_count):
a, b = b, a + b
yield a
上面我们编写了一个生成斐波那契数列的生成器,调用上面的fib函数并不是执行该函数获得返回值,因为fib函数中有一个特殊的关键字yield。这个关键字使得fib函数跟普通的函数有些区别,调用该函数会得到一个生成器对象,我们可以通过下面的代码来验证这一点。
gen_obj = fib(20)
print(gen_obj)
输出:
<generator object fib at 0x106daee40>
我们可以使用内置函数next从生成器对象中获取斐波那契数列的值,也可以通过for-in循环对生成器能够提供的值进行遍历,代码如下所示。
for value in gen_obj:
print(value)
生成器经过预激活,就是一个协程,它可以跟其他子程序协作。
def calc_average():
total, counter = 0, 0
avg_value = None
while True:
curr_value = yield avg_value
total += curr_value
counter += 1
avg_value = total / counter
def main():
obj = calc_average()
# 生成器预激活
obj.send(None)
for _ in range(5):
print(obj.send(float(input())))
if __name__ == '__main__':
main()
上面的main函数首先通过生成器对象的send方法发送一个None值来将其激活为协程,也可以通过next(obj)达到同样的效果。接下来,协程对象会接收main函数发送的数据并产出(yield)数据的平均值。通过上面的例子,不知道大家是否看出两段子程序是怎么“协作”的。
异步函数
Python 3.5版本中,引入了两个非常有意思的元素,一个叫async,一个叫await,它们在Python 3.7版本中成为了正式的关键字。通过这两个关键字,可以简化协程代码的编写,可以用更为简单的方式让多个子程序很好的协作起来。我们通过一个例子来加以说明,请大家先看看下面的代码。
import time
def display(num):
time.sleep(1)
print(num)
def main():
start = time.time()
for i in range(1, 10):
display(i)
end = time.time()
print(f'{end - start:.3f}秒')
if __name__ == '__main__':
main()
上面的代码每次执行都会依次输出1到9的数字,每个间隔1秒钟,整个代码需要执行大概需要9秒多的时间,这一点我相信大家都能看懂。不知道大家是否意识到,这段代码就是以同步和阻塞的方式执行的,同步可以从代码的输出看出来,而阻塞是指在调用display函数发生休眠时,整个代码的其他部分都不能继续执行,必须等待休眠结束。
接下来,我们尝试用异步的方式改写上面的代码,让display函数以异步的方式运转。
import asyncio
import time
async def display(num):
await asyncio.sleep(1)
print(num)
def main():
start = time.time()
objs = [display(i) for i in range(1, 10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(objs))
loop.close()
end = time.time()
print(f'{end - start:.3f}秒')
if __name__ == '__main__':
main()
Python 中的asyncio模块提供了对异步 I/O 的支持。上面的代码中,我们首先在display函数前面加上了async关键字使其变成一个异步函数,调用异步函数不会执行函数体而是获得一个协程对象。我们将display函数中的time.sleep(1)修改为await asyncio.sleep(1),二者的区别在于,后者不会让整个代码陷入阻塞,因为await操作会让其他协作的子程序有获得 CPU 资源而得以运转的机会。为了让这些子程序可以协作起来,我们需要将他们放到一个事件循环(实现消息分派传递的系统)上,因为当协程遭遇 I/O 操作阻塞时,就会到事件循环中监听 I/O 操作是否完成,并注册自身的上下文以及自身的唤醒函数(以便恢复执行),之后该协程就变为阻塞状态。上面的第12行代码创建了9个协程对象并放到一个列表中,第13行代码通过asyncio模块的get_event_loop函数获得了系统的事件循环,第14行通过asyncio模块的run_until_complete函数将协程对象挂载到事件循环上。执行上面的代码会发现,9个分别会阻塞1秒钟的协程总共只阻塞了约1秒种的时间,因为阻塞的协程对象会放弃对 CPU 的占有而不是让 CPU 处于闲置状态,这种方式大大的提升了 CPU 的利用率。而且我们还会注意到,数字并不是按照从1到9的顺序打印输出的,这正是我们想要的结果,说明它们是异步执行的。对于爬虫这样的 I/O 密集型任务来说,这种协作式并发在很多场景下是比使用多线程更好的选择,因为这种做法减少了管理和维护多个线程以及多个线程切换所带来的开销。
aiohttp库
我们之前使用的requests三方库并不支持异步 I/O,如果希望使用异步 I/O 的方式来加速爬虫代码的执行,我们可以安装和使用名为aiohttp的三方库。
安装aiohttp。
pip install aiohttp
下面的代码使用aiohttp抓取了10个网站的首页并解析出它们的标题。
import asyncio
import re
import aiohttp
from aiohttp import ClientSession
TITLE_PATTERN = re.compile(r'<title.*?>(.*?)</title>', re.DOTALL)
async def fetch_page_title(url):
async with aiohttp.ClientSession(headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
}) as session: # type: ClientSession
async with session.get(url, ssl=False) as resp:
if resp.status == 200:
html_code = await resp.text()
matcher = TITLE_PATTERN.search(html_code)
title = matcher.group(1).strip()
print(title)
def main():
urls = [
'https://www.python.org/',
'https://www.jd.com/',
'https://www.baidu.com/',
'https://www.taobao.com/',
'https://git-scm.com/',
'https://www.sohu.com/',
'https://gitee.com/',
'https://www.amazon.com/',
'https://www.usa.gov/',
'https://www.nasa.gov/'
]
objs = [fetch_page_title(url) for url in urls]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(objs))
loop.close()
if __name__ == '__main__':
main()
输出:
京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!
搜狐
淘宝网 - 淘!我喜欢
百度一下,你就知道
Gitee - 基于 Git 的代码托管和研发协作平台
Git
NASA
Official Guide to Government Information and Services | USAGov
Amazon.com. Spend less. Smile more.
Welcome to Python.org
从上面的输出可以看出,网站首页标题的输出顺序跟它们的 URL 在列表中的顺序没有关系。代码的第11行到第13行创建了ClientSession对象,通过它的get方法可以向指定的 URL 发起请求,如第14行所示,跟requests中的Session对象并没有本质区别,唯一的区别是这里使用了异步上下文。代码第16行的await会让因为 I/O 操作阻塞的子程序放弃对 CPU 的占用,这使得其他的子程序可以运转起来去抓取页面。代码的第17行和第18行使用了正则表达式捕获组操作解析网页标题。fetch_page_title是一个被async关键字修饰的异步函数,调用该函数会获得协程对象,如代码第35行所示。后面的代码跟之前的例子没有什么区别,相信大家能够理解。
大家可以尝试将aiohttp换回到requests,看看不使用异步 I/O 也不使用多线程,到底和上面的代码有什么区别,相信通过这样的对比,大家能够更深刻的理解我们之前强调的几个概念:同步和异步,阻塞和非阻塞。## 第40课:关系型数据库和MySQL概述
关系型数据库概述
-
数据持久化 - 将数据保存到能够长久保存数据的存储介质中,在掉电的情况下数据也不会丢失。
-
数据库发展史 - 网状数据库、层次数据库、关系数据库、NoSQL 数据库、NewSQL 数据库。
1970年,IBM的研究员E.F.Codd在Communication of the ACM上发表了名为A Relational Model of Data for Large Shared Data Banks的论文,提出了关系模型的概念,奠定了关系模型的理论基础。后来Codd又陆续发表多篇文章,论述了范式理论和衡量关系系统的12条标准,用数学理论奠定了关系数据库的基础。
-
关系数据库特点。
-
理论基础:关系代数(关系运算、集合论、一阶谓词逻辑)。
-
具体表象:用二维表(有行和列)组织数据。
-
编程语言:结构化查询语言(SQL)。
-
-
ER模型(实体关系模型)和概念模型图。
ER模型,全称为实体关系模型(Entity-Relationship Model),由美籍华裔计算机科学家陈品山先生提出,是概念数据模型的高层描述方式,
- 实体 - 矩形框
- 属性 - 椭圆框
- 关系 - 菱形框
- 重数 - 1:1(一对一) / 1:N(一对多) / M:N(多对多)
实际项目开发中,我们可以利用数据库建模工具(如:PowerDesigner)来绘制概念数据模型(其本质就是 ER 模型),然后再设置好目标数据库系统,将概念模型转换成物理模型,最终生成创建二维表的 SQL(很多工具都可以根据我们设计的物理模型图以及设定的目标数据库来导出 SQL 或直接生成数据表)。
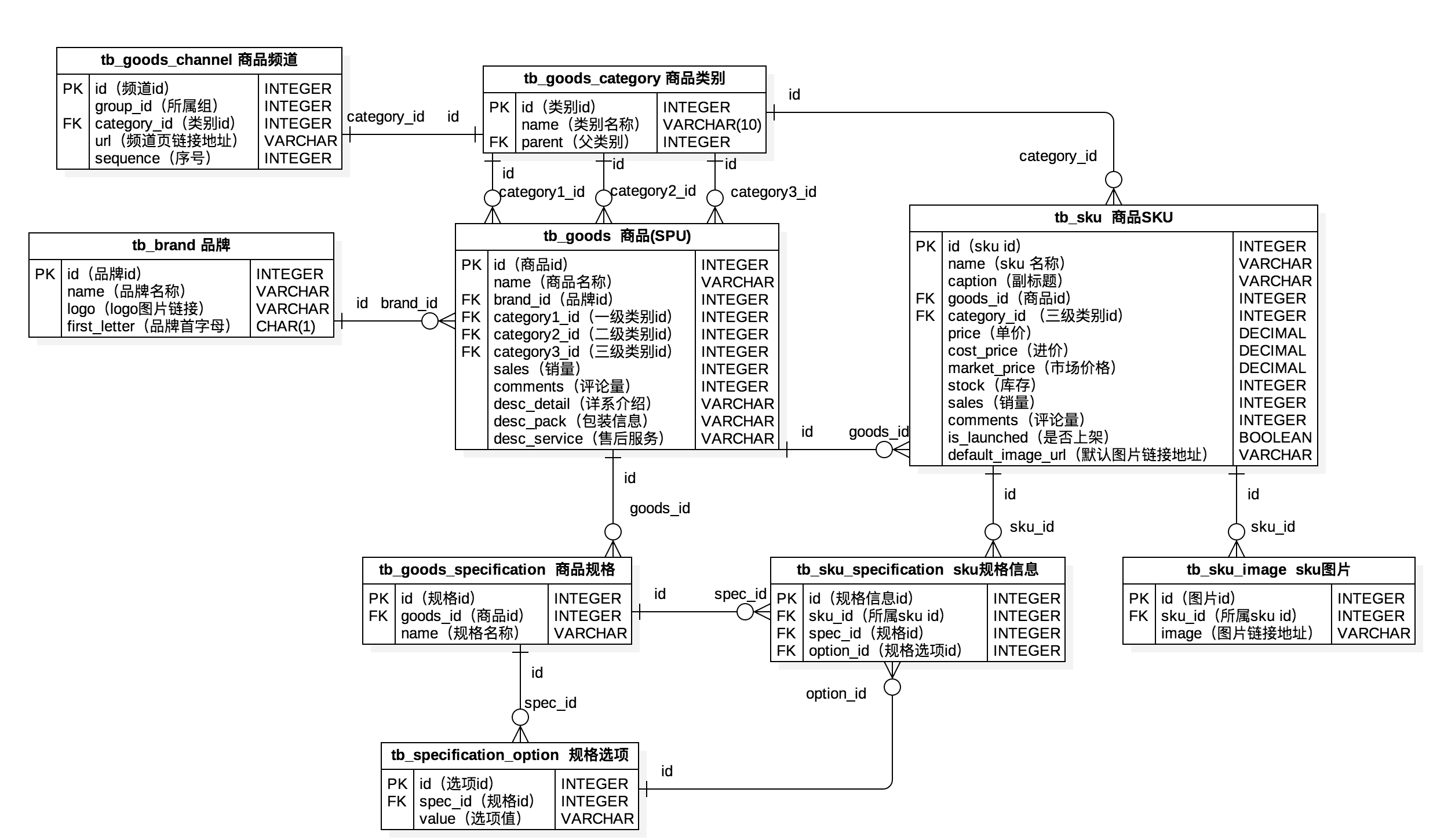
-
关系数据库产品。
- Oracle - 目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库,它实现了分布式处理的功能。在 Oracle 最新的 12c 版本中,还引入了多承租方架构,使用该架构可轻松部署和管理数据库云。
- DB2 - IBM 公司开发的、主要运行于 Unix(包括 IBM 自家的 AIX)、Linux、以及 Windows 服务器版等系统的关系数据库产品。DB2 历史悠久且被认为是最早使用 SQL 的数据库产品,它拥有较为强大的商业智能功能。
- SQL Server - 由 Microsoft 开发和推广的关系型数据库产品,最初适用于中小企业的数据管理,但是近年来它的应用范围有所扩展,部分大企业甚至是跨国公司也开始基于它来构建自己的数据管理系统。
- MySQL - MySQL 是开放源代码的,任何人都可以在 GPL(General Public License)的许可下下载并根据个性化的需要对其进行修改。MySQL 因为其速度、可靠性和适应性而备受关注。
- PostgreSQL - 在 BSD 许可证下发行的开放源代码的关系数据库产品。
MySQL 简介
MySQL 最早是由瑞典的 MySQL AB 公司开发的一个开放源码的关系数据库管理系统,该公司于2008年被昇阳微系统公司(Sun Microsystems)收购。在2009年,甲骨文公司(Oracle)收购昇阳微系统公司,因此 MySQL 目前也是 Oracle 旗下产品。
MySQL 在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用于中小型网站开发。随着 MySQL 的不断成熟,它也逐渐被应用于更多大规模网站和应用,比如维基百科、谷歌(Google)、脸书(Facebook)、淘宝网等网站都使用了 MySQL 来提供数据持久化服务。
甲骨文公司收购后昇阳微系统公司,大幅调涨 MySQL 商业版的售价,且甲骨文公司不再支持另一个自由软件项目 OpenSolaris 的发展,因此导致自由软件社区对于 Oracle 是否还会持续支持 MySQL 社区版(MySQL 的各个发行版本中唯一免费的版本)有所担忧,MySQL 的创始人麦克尔·维德纽斯以 MySQL 为基础,创建了 MariaDB(以他女儿的名字命名的数据库)分支。有许多原来使用 MySQL 数据库的公司(例如:维基百科)已经陆续完成了从 MySQL 数据库到 MariaDB 数据库的迁移。
MySQL 基本命令
查看命令
- 查看所有数据库
show databases;
- 查看所有字符集
show character set;
- 查看所有的排序规则
show collation;
- 查看所有的引擎
show engines;
- 查看所有日志文件
show binary logs;
- 查看数据库下所有表
show tables;
获取帮助
在 MySQL 命令行工具中,可以使用help命令或?来获取帮助,如下所示。
-
查看
show命令的帮助。? show -
查看有哪些帮助内容。
? contents -
获取函数的帮助。
? functions -
获取数据类型的帮助。
? data types
其他命令
-
新建/重建服务器连接 -
connect/resetconnection。 -
清空当前输入 -
\c。在输入错误时,可以及时使用\c清空当前输入并重新开始。 -
修改终止符(定界符)-
delimiter。默认的终止符是;,可以使用该命令修改成其他的字符,例如修改为$符号,可以用delimiter $命令。 -
打开系统默认编辑器 -
edit。编辑完成保存关闭之后,命令行会自动执行编辑的内容。 -
查看服务器状态 -
status。 -
修改默认提示符 -
prompt。 -
执行系统命令 -
system。可以将系统命令跟在system命令的后面执行,system命令也可以缩写为\!。 -
执行 SQL 文件 -
source。source命令后面跟 SQL 文件路径。 -
重定向输出 -
tee/notee。可以将命令的输出重定向到指定的文件中。 -
切换数据库 -
use。 -
显示警告信息 -
warnings。 -
退出命令行 -
quit或exit。
Python程序接入MySQL数据库
在 Python3 中,我们可以使用mysqlclient或者pymysql三方库来接入 MySQL 数据库并实现数据持久化操作。二者的用法完全相同,只是导入的模块名不一样。我们推荐大家使用纯 Python 的三方库pymysql,因为它更容易安装成功。下面我们仍然以之前创建的名为hrs的数据库为例,为大家演示如何通过 Python 程序操作 MySQL 数据库实现数据持久化操作。
接入MySQL
首先,我们可以在命令行或者 PyCharm 的终端中通过下面的命令安装pymysql,如果需要接入 MySQL 8,还需要安装一个名为cryptography的三方库来支持 MySQL 8 的密码认证方式。
pip install pymysql cryptography
使用pymysql操作 MySQL 的步骤如下所示:
- 创建连接。MySQL 服务器启动后,提供了基于 TCP (传输控制协议)的网络服务。我们可以通过
pymysql模块的connect函数连接 MySQL 服务器。在调用connect函数时,需要指定主机(host)、端口(port)、用户名(user)、口令(password)、数据库(database)、字符集(charset)等参数,该函数会返回一个Connection对象。 - 获取游标。连接 MySQL 服务器成功后,接下来要做的就是向数据库服务器发送 SQL 语句,MySQL 会执行接收到的 SQL 并将执行结果通过网络返回。要实现这项操作,需要先通过连接对象的
cursor方法获取游标(Cursor)对象。 - 发出 SQL。通过游标对象的
execute方法,我们可以向数据库发出 SQL 语句。 - 如果执行
insert、delete或update操作,需要根据实际情况提交或回滚事务。因为创建连接时,默认开启了事务环境,在操作完成后,需要使用连接对象的commit或rollback方法,实现事务的提交或回滚,rollback方法通常会放在异常捕获代码块except中。如果执行select操作,需要通过游标对象抓取查询的结果,对应的方法有三个,分别是:fetchone、fetchmany和fetchall。其中fetchone方法会抓取到一条记录,并以元组或字典的方式返回;fetchmany和fetchall方法会抓取到多条记录,以嵌套元组或列表装字典的方式返回。 - 关闭连接。在完成持久化操作后,请不要忘记关闭连接,释放外部资源。我们通常会在
finally代码块中使用连接对象的close方法来关闭连接。
代码实操
下面,我们通过代码实操的方式为大家演示上面说的五个步骤。
插入数据
import pymysql
no = int(input('部门编号: '))
name = input('部门名称: ')
location = input('部门所在地: ')
# 1. 创建连接(Connection)
conn = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4')
try:
# 2. 获取游标对象(Cursor)
with conn.cursor() as cursor:
# 3. 通过游标对象向数据库服务器发出SQL语句
affected_rows = cursor.execute(
'insert into `tb_dept` values (%s, %s, %s)',
(no, name, location)
)
if affected_rows == 1:
print('新增部门成功!!!')
# 4. 提交事务(transaction)
conn.commit()
except pymysql.MySQLError as err:
# 4. 回滚事务
conn.rollback()
print(type(err), err)
finally:
# 5. 关闭连接释放资源
conn.close()
说明:上面的
127.0.0.1称为回环地址,它代表的是本机。下面的guest是我提前创建好的用户,该用户拥有对hrs数据库的insert、delete、update和select权限。我们不建议大家在项目中直接使用root超级管理员账号访问数据库,这样做实在是太危险了。我们可以使用下面的命令创建名为guest的用户并为其授权。create user 'guest'@'%' identified by 'Guest.618'; grant insert, delete, update, select on `hrs`.* to 'guest'@'%';
如果要插入大量数据,建议使用游标对象的executemany方法做批处理(一个insert操作后面跟上多组数据),大家可以尝试向一张表插入10000条记录,然后看看不使用批处理一条条的插入和使用批处理有什么差别。游标对象的executemany方法第一个参数仍然是 SQL 语句,第二个参数可以是包含多组数据的列表或元组。
删除数据
import pymysql
no = int(input('部门编号: '))
# 1. 创建连接(Connection)
conn = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4',
autocommit=True)
try:
# 2. 获取游标对象(Cursor)
with conn.cursor() as cursor:
# 3. 通过游标对象向数据库服务器发出SQL语句
affected_rows = cursor.execute(
'delete from `tb_dept` where `dno`=%s',
(no, )
)
if affected_rows == 1:
print('删除部门成功!!!')
finally:
# 5. 关闭连接释放资源
conn.close()
说明:如果不希望每次 SQL 操作之后手动提交或回滚事务,可以
connect函数中加一个名为autocommit的参数并将它的值设置为True,表示每次执行 SQL 成功后自动提交。但是我们建议大家手动提交或回滚,这样可以根据实际业务需要来构造事务环境。如果不愿意捕获异常并进行处理,可以在try代码块后直接跟finally块,省略except意味着发生异常时,代码会直接崩溃并将异常栈显示在终端中。
更新数据
import pymysql
no = int(input('部门编号: '))
name = input('部门名称: ')
location = input('部门所在地: ')
# 1. 创建连接(Connection)
conn = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4')
try:
# 2. 获取游标对象(Cursor)
with conn.cursor() as cursor:
# 3. 通过游标对象向数据库服务器发出SQL语句
affected_rows = cursor.execute(
'update `tb_dept` set `dname`=%s, `dloc`=%s where `dno`=%s',
(name, location, no)
)
if affected_rows == 1:
print('更新部门信息成功!!!')
# 4. 提交事务
conn.commit()
except pymysql.MySQLError as err:
# 4. 回滚事务
conn.rollback()
print(type(err), err)
finally:
# 5. 关闭连接释放资源
conn.close()
查询数据
- 查询部门表的数据。
import pymysql
# 1. 创建连接(Connection)
conn = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4')
try:
# 2. 获取游标对象(Cursor)
with conn.cursor() as cursor:
# 3. 通过游标对象向数据库服务器发出SQL语句
cursor.execute('select `dno`, `dname`, `dloc` from `tb_dept`')
# 4. 通过游标对象抓取数据
row = cursor.fetchone()
while row:
print(row)
row = cursor.fetchone()
except pymysql.MySQLError as err:
print(type(err), err)
finally:
# 5. 关闭连接释放资源
conn.close()
说明:上面的代码中,我们通过构造一个
while循环实现了逐行抓取查询结果的操作。这种方式特别适合查询结果有非常多行的场景。因为如果使用fetchall一次性将所有记录抓取到一个嵌套元组中,会造成非常大的内存开销,这在很多场景下并不是一个好主意。如果不愿意使用while循环,还可以考虑使用iter函数构造一个迭代器来逐行抓取数据,有兴趣的读者可以自行研究。
- 分页查询员工表的数据。
import pymysql
page = int(input('页码: '))
size = int(input('大小: '))
# 1. 创建连接(Connection)
con = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8')
try:
# 2. 获取游标对象(Cursor)
with con.cursor(pymysql.cursors.DictCursor) as cursor:
# 3. 通过游标对象向数据库服务器发出SQL语句
cursor.execute(
'select `eno`, `ename`, `job`, `sal` from `tb_emp` order by `sal` desc limit %s,%s',
((page - 1) * size, size)
)
# 4. 通过游标对象抓取数据
for emp_dict in cursor.fetchall():
print(emp_dict)
finally:
# 5. 关闭连接释放资源
con.close()
案例讲解
下面我们为大家讲解一个将数据库表数据导出到 Excel 文件的例子,我们需要先安装openpyxl三方库,命令如下所示。
pip install openpyxl
接下来,我们通过下面的代码实现了将数据库hrs中所有员工的编号、姓名、职位、月薪、补贴和部门名称导出到一个 Excel 文件中。
import openpyxl
import pymysql
# 创建工作簿对象
workbook = openpyxl.Workbook()
# 获得默认的工作表
sheet = workbook.active
# 修改工作表的标题
sheet.title = '员工基本信息'
# 给工作表添加表头
sheet.append(('工号', '姓名', '职位', '月薪', '补贴', '部门'))
# 创建连接(Connection)
conn = pymysql.connect(host='127.0.0.1', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4')
try:
# 获取游标对象(Cursor)
with conn.cursor() as cursor:
# 通过游标对象执行SQL语句
cursor.execute(
'select `eno`, `ename`, `job`, `sal`, coalesce(`comm`, 0), `dname` '
'from `tb_emp` natural join `tb_dept`'
)
# 通过游标抓取数据
row = cursor.fetchone()
while row:
# 将数据逐行写入工作表中
sheet.append(row)
row = cursor.fetchone()
# 保存工作簿
workbook.save('hrs.xlsx')
except pymysql.MySQLError as err:
print(err)
finally:
# 关闭连接释放资源
conn.close()
大家可以参考上面的例子,试一试把 Excel 文件的数据导入到指定数据库的指定表中,看看是否可以成功。
至此,Wanyu已经把自己所学的所有关于Python的知识用上十万字的结构、方法、代码呈现了出来,制作不易,希望大家可以点个关注支持下啦~~~。
后续,会对这篇文章内容继续进行优化和删改。
放一张字数的图片:
备注:
5.27 第一次上传
6.6 修改更新

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









