



爬虫是一种自动化程序,用于在互联网上收集信息或数据。它模拟人类用户的行为,访问网页、抓取页面内容,并将所需的数据提取出来。爬虫可以在互联网上搜索、分析和检索大量数据,在很多领域都有应用。
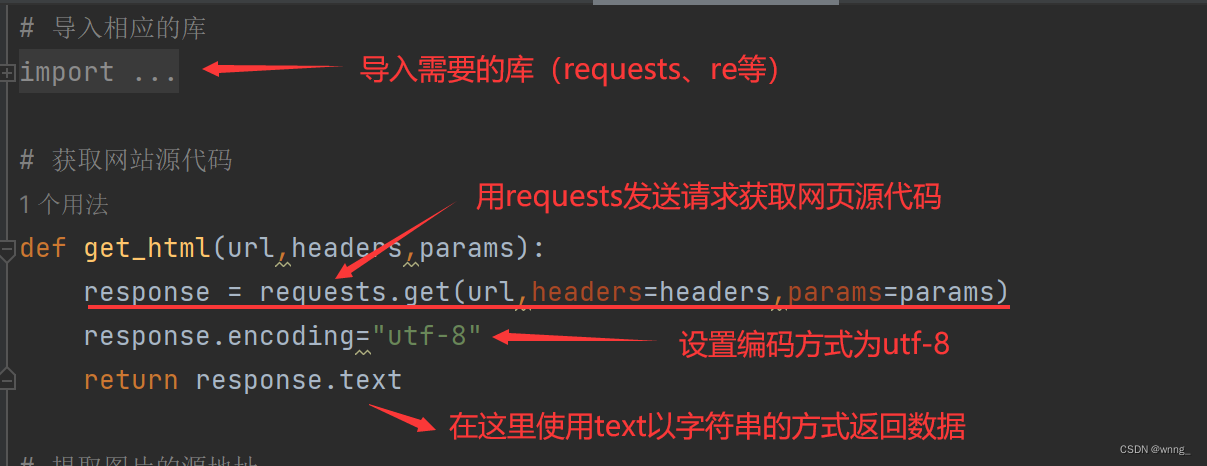
1.我们想要爬取内容首先就需要发送请求获取网站源代码
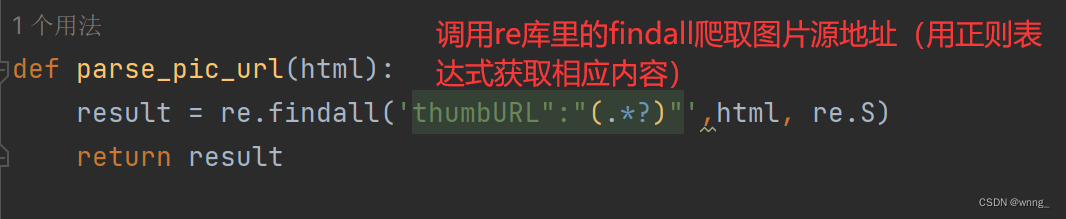
2.提取图片的源地址
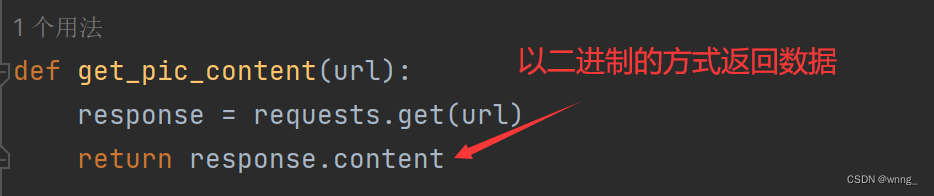
3.获取图片的二进制源码
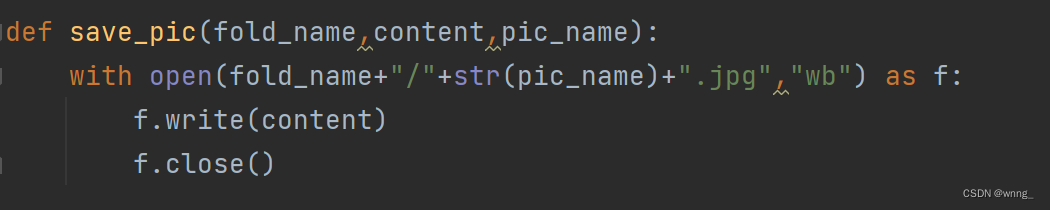
4.保存图片
5.定义mian函数调用get_html函数

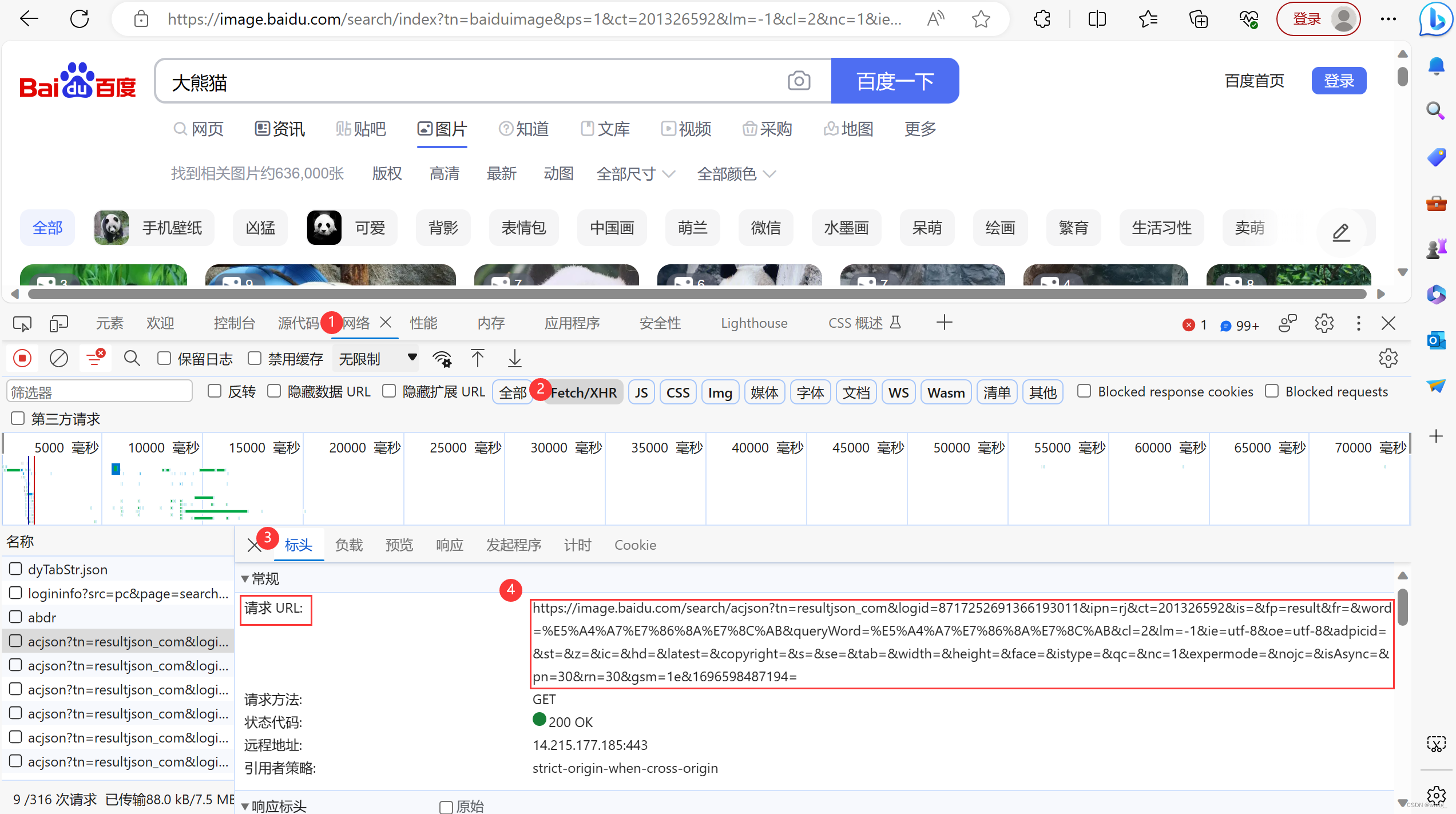
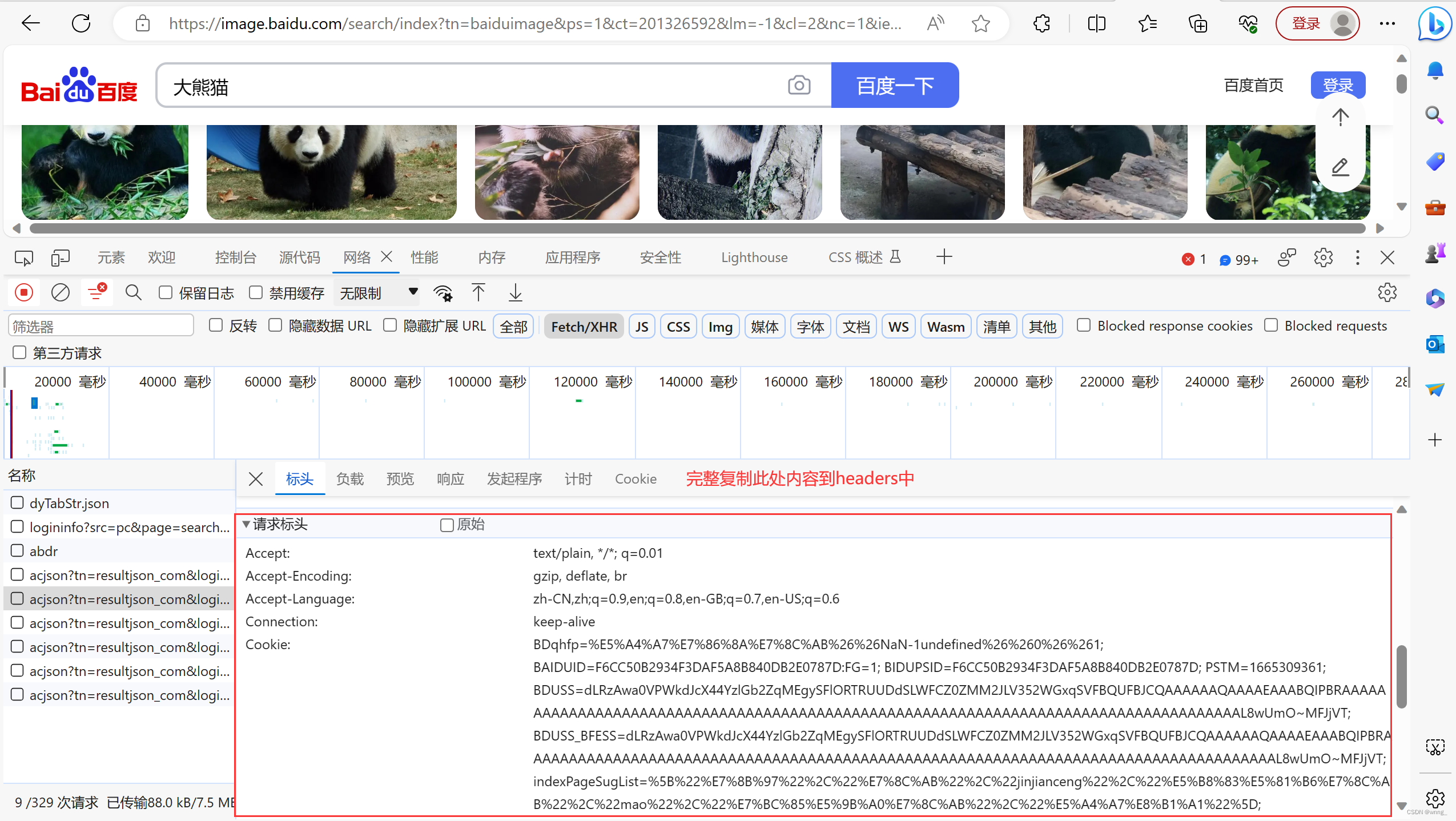
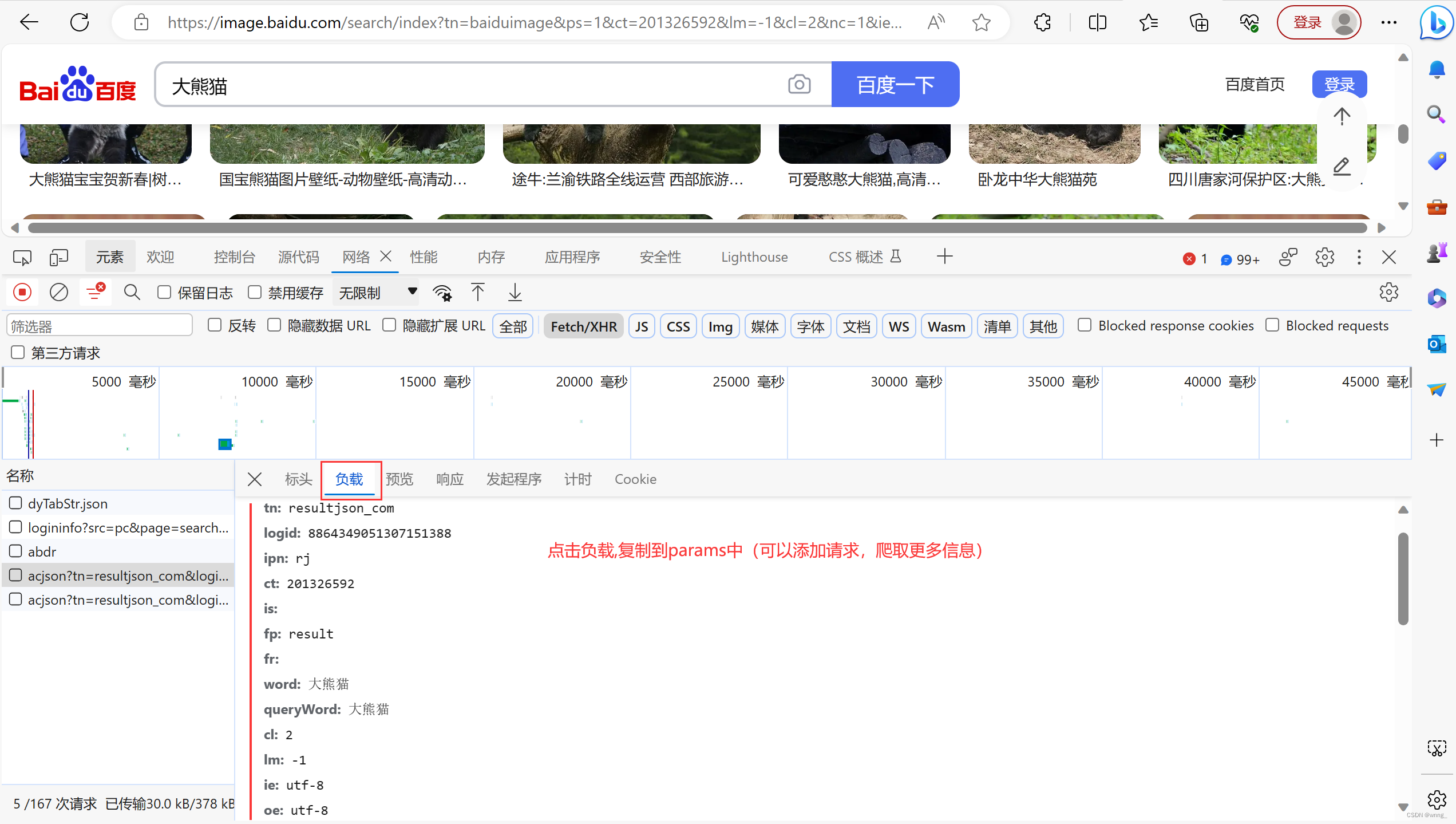
6.查找提取数据,url、headers、params
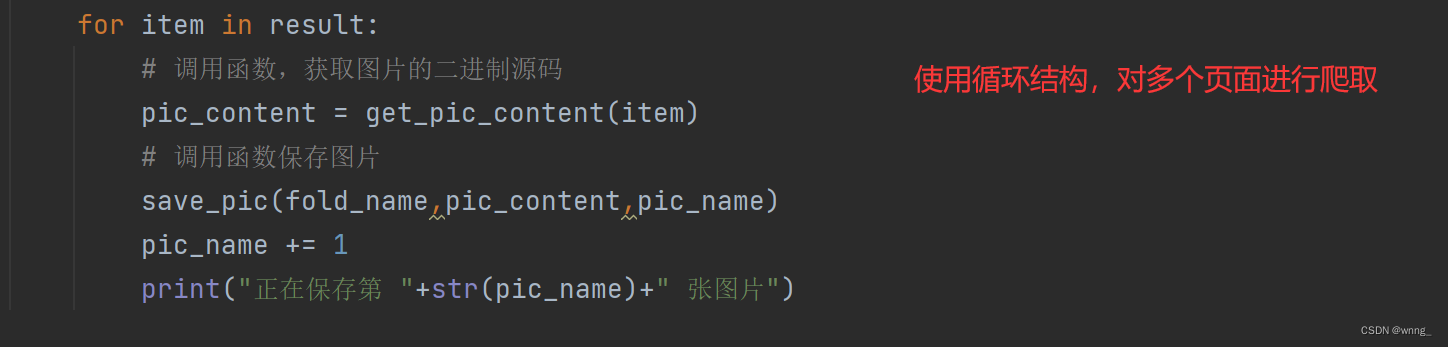
9.使用for循环遍历列表,调用函数,获取图片的二进制源码并保存
 本文介绍了爬虫的基本原理,包括发送请求获取网站源代码、提取图片地址和二进制源码,以及如何定义主函数调用相关函数进行数据抓取和图片保存的过程。
本文介绍了爬虫的基本原理,包括发送请求获取网站源代码、提取图片地址和二进制源码,以及如何定义主函数调用相关函数进行数据抓取和图片保存的过程。
爬虫是一种自动化程序,用于在互联网上收集信息或数据。它模拟人类用户的行为,访问网页、抓取页面内容,并将所需的数据提取出来。爬虫可以在互联网上搜索、分析和检索大量数据,在很多领域都有应用。
1.我们想要爬取内容首先就需要发送请求获取网站源代码
2.提取图片的源地址
3.获取图片的二进制源码
4.保存图片
5.定义mian函数调用get_html函数
6.查找提取数据,url、headers、params
9.使用for循环遍历列表,调用函数,获取图片的二进制源码并保存

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1799
1799





