







一.广义表的一些基本概念:
GL=(d1,d2,d3......dn),在这里di 既可以是单个的元素,也可以是一个表;
d1是表头,其余的部分组成的表就称为广义表的表尾;(广义表的表尾一定是一个表!)
由此其实我们也可以理解:广义表是递归定义的;
D=(),长度为0的表
A=(a,(b,c)),长度为2,第一个元素是单个数据,第二个元素是子表;
B=(A,A,D),长度为3,前两个元素为表A,第三个是空表;(可以看出广义表也可以被其他广义表共享!)
C=(a,C),长度为2的递归定义表,C就是无穷表;(利用这个例子,就可以更好地理解广义表的递归定义)
二.广义表的存储结构
采用链式存储
根据上述给出的一些特殊的广义表的例子:我们可以看出一个广义表中的元素,要么是单个的元素,要么是一个表,而表又可以继续拆分;
因此在链式结构中,我们把单个元素定义为原子结点,把表定义为:表结点
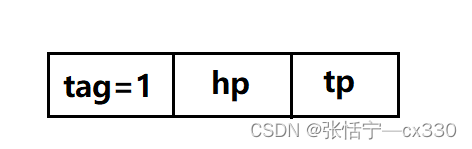 (表结点)
(表结点)
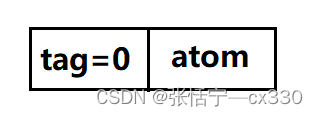 (原子结点)
(原子结点)
tag用来区分原子结点和表结点;hp指向表头的指针域,tp指向表尾的指针域,atom是原子结点的值域;
1.广义表的头尾链表存储结构类型定义:
typedef enum {ATOM, LIST}ElemTag;//C语言枚举类型 ATOM=0,LIST=1;
typedef struct GLNode
{
ElemTag tag;//要么为0,要么为1;
union
{
AtomType atom;
struct
{
struct GLNode* hp, * tp;
}htp;
}atom_htp;//原子结点的值域atom和表结点的指针域htp的联合体体域
}GLNode,*GList;
在这里enum是C语言的枚举:
union是C语言的共用体(联合体):
共用体是一种特殊的数据类型,允许在相同的内存位置存储不同的数据类型。我们可以定义一个带有多成员的共用体,
但是任何时候只能有一个成员带有值,共用体提供了一种使用相同的内存位置的有效方式!
由于所有的成员都在同一个内存块中,所以任何时候只能有一个成员的值有效——那根据这个特点,我们来看上述代码:联合体中的成员一个是原子结点,而另一个则是结构体定义的表结点,那么也就是说,利用联合体的这个特点:我们就实现了:一个结点要么是原子结点,要么是表结点这一特点;
2.广义表的链存储结构:
下面我们以广义表A为例:A=(a,(b,c))
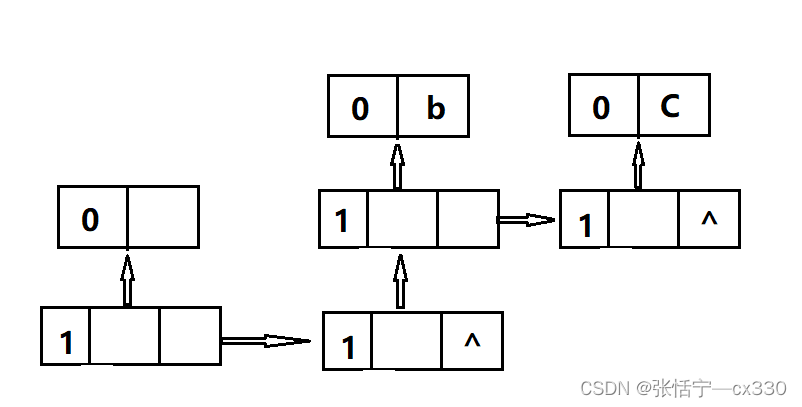
分析如下:

由b,c两个地方的不同之处,其实我们就可以看出:广义表的表尾必须是一个表这一特点;
3.广义表的同层结点链存储结构类型定义:
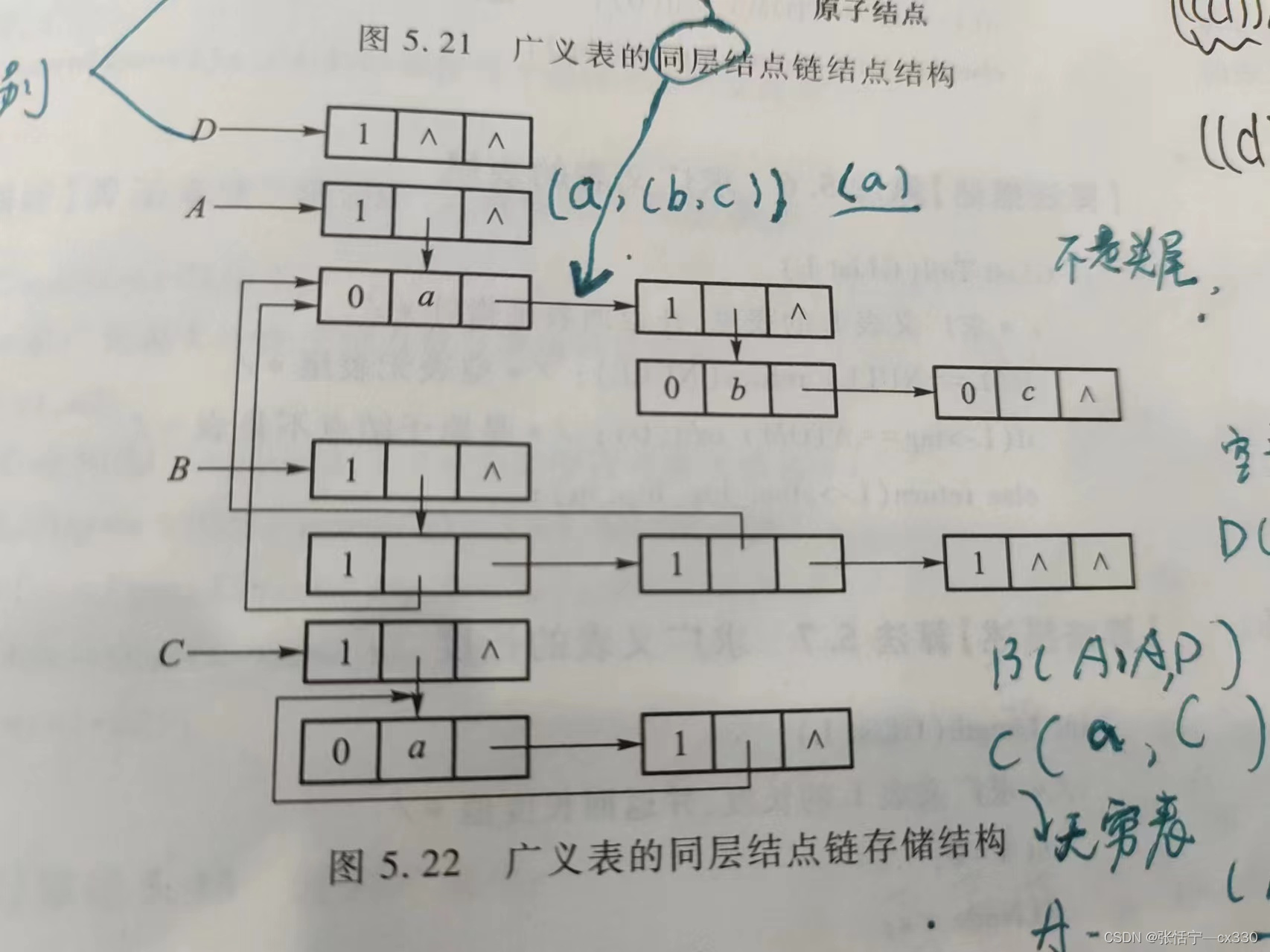
对以上同层结点链的存储进行分析:其实我们可以看出:此时广义表的尾指针指向的并不是表尾结点,而是与之位于同一“层”的结点;
比如:A=(a,(b,c))——没有与自身(整个表)位于同一层的,所以指向NULL,与a位于同一层的是(b,c),与b位于同一层的是c,而没有与c位于同一层的,所以指向NULL;
//广义表的同层结点链存储结构
typedef enum { ATOM, LIST }; ElemTag;
typedef struct GLNode
{
ElemTag tag;
union
{
AtomType atom;
struct GLNode* hp;//表头指针域
};
struct GLNode* tp;//同层下一个结点的指针域;
}GLNode,*GList;
与上面的头尾链不同的就是对于“尾指针”的操作!
4.广义表的操作:(以头尾链为例)
求广义表的表头,表尾,长度,深度,统计广义表中原子结点的数目,复制广义表;
(1)求广义表的表头:
GList Head(GList L)
{
if (L == NULL)
{
return NULL;//是空表
}
if (L->tag == ATOM)
{
exit(0);//是原子结点
}
else
{
return (L->atom_htp.htp.hp);//L->atom_htp.htp是定义的表结点,利用.找到表头
}
}(2)求广义表的表尾:
//求广义表的表尾
GList Tail(GList L)
{
if (L == NULL)
{
return NULL;//是空表
}
if (L->tag == ATOM)
{
exit(0);//是原子结点
}
else
{
return (L->atom_htp.htp.tp);
}
}
(3)求广义表的长度
长度:不是有多少个原子结点,而是一直找表尾,直至表的表尾为空,表的总和
//求广义表的长度
int length(GList L)
{
int k = 0;
GLNode* s;
if (L == NULL)
{
return 0;
}
if (L->tag == ATOM)
{
exit(0);
}
s = L;
while (s != NULL)
{
k++;//表头,长度+1(无论表头是表还是元素,根据广义表递归的定义,表头的长度都为1)
s = s->atom_htp.htp.tp;//指向表尾,表尾不为空,说明能够再剥离出来一个表头,所以长度再+1;
}
return k;
}(4)求广义表的深度:
int Depth(GList L)
{
int d, max;
GLNode* s;
if (L == NULL)
{
return 1;//空表的深度为1
}
if (L->tag == ATOM)
{
return 0;
}
s = L;
while (s != NULL)
{
d = Depth(s->atom_htp.htp.hp);//从表的头指针指向的开始进行递归//先介绍一下子表的定义
if (d > max)
{
max = d;
}
s = s->atom_htp.htp.tp;//往后移
}
return(max + 1);
}我们重点理解一下:求广义表的深度这一过程
a.首先理解:什么是广义表的深度:所谓广义表的深度就是表中所包含的最大括号层数,也被称为括号的重数。空表的深度为1,原子(即不含人格括号的元素)的深度为0;
广义表:LS=((),a,b,(a,b,c),(a,(a,b),c)),在这里LS的深度为3;
而表的深度等于最深子表的深度+1;
什么是最深子表?所谓子表:见广义表的定义,在广义表中(d1,d2,d3,d4,d5.....dn),如果di是广义表,那么di就可以称为广义表的一个子表。而最深子表就是深度最大的子表。
b.逐步理解算法的递归过程:
以LS为例:
·遍历到(),空表,深度为1;
·遍历到a,是一个“在表中的原子结点”,那么进入递归,返回0+1(原子结点的深度为0,但是它是在表中的原子结点,那么已经进入递归循环,返回的是max+1(看代码),所以max=1;
·遍历到(a,b,c)都是原子结点,且遍历到其中的a,d=0,不影响max,而继续遍历到(b,c)同理,那么不会影响max的值;
·遍历到(a,(a,b),c),遍历到其中的a,原子结点d=0,不影响max,遍历到((a,b),c)再遍历到其中的(a,b),原子结点0,返回0+1=1,那么(a,b)的深度就为d=1+1=2,那么更新max的值,max=2,而继续遍历到c,不影响max,所以最终返回max=2,最深子表的深度+1=2+1=3;
(或者直接看括号的重数:从最外层开始:一直往前找,直到遇到左括号,累积的右括号数就是广义表的深度!)
这就是整个的递归过程;那其实在刚开始我是不理解为什么能够在没有初始化的情况下返回一个值(可能就是对递归的理解不清吧!)在递归中的return,跳出一层递归,不是跳出整个函数,而需要接着进行下面的递归/程序,那通过return在整个的depth函数中,返回值,然后通过递归返回子表的深度;(其实看了上述分析的递归过程应该就能理解)
(5)统计广义表中原子结点的数目
分为表头中的原子结点和表尾中的原子结点
//统计广义表中的原子结点的数目
int CountAtom(GList L)
{
int n1, n2;
if (L == NULL)
{
return 0;
}
if (L->tag == ATOM)
{
return 1;
}
//仍然是利用递归,因为有好多个表头表尾,将复杂问题转化为子问题
n1 = CountAtom(L->atom_htp.htp.hp);//表头中的原子结点
n2 = CountAtom(L->atom_htp.htp.tp);
return(n1 + n2);
}
(6)复制广义表:
//复制广义表
int CopyGList(GList S, GList* T)
{
if (S == NULL)
{
*T = NULL;
return 1;
}
*T = (GLNode*)malloc(sizeof(GLNode));
if (*T == NULL)
{
return 0;
}
(*T)->tag = S->tag;
if (S->tag == ATOM)
{
(*T)->atom_htp.atom = S->atom_htp.atom;//那就是全部分解为单个原子才能进行赋值
}
else
{
CopyGList(S->atom_htp.htp.hp, &((*T)->atom_htp.htp.hp));
CopyGList(S->atom_htp.htp.tp, &((*T)->atom_htp.htp.tp));
}
return 1;
}在这里:利用*T,就涉及到C语言的传址与传值问题,在C语言中,函数参数是通过值传递的。当你将一个指针传递给函数时,实际上传递的是指针值的副本,而不是指针本身。因此,在函数内部修改指针的值(即改变它指向的地址)并不会影响函数外部的原始指针。
为了能够在函数内部修改外部的指针,你需要传递一个指向该指针的指针。这就是*T出现的原因。通过解引用T(即使用*T),你能够访问并修改T所指向的GList(即GLNode*)的值。
并且一定要是给(*T)赋值,这样才能通过解引用访问到真正的指针,进行修改指针的值,否则改变的仍然是自身的值,而不是被指向的对象的值!
以上就是个人对于广义表相关内容的理解,如有疑问,欢迎各位读者在评论区交流!















 8147
8147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









