







 本文解析了Spark中的序列化技术(JavaSerializer和KryoSerializer),强调了它们在提升性能中的作用,以及Spark内置的压缩方法(LZ4、LZF、Snappy)。同时提到了面试准备资源,包括面试题解析、学习笔记和视频教程。
本文解析了Spark中的序列化技术(JavaSerializer和KryoSerializer),强调了它们在提升性能中的作用,以及Spark内置的压缩方法(LZ4、LZF、Snappy)。同时提到了面试准备资源,包括面试题解析、学习笔记和视频教程。
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
在分布式计算中,序列化和压缩是提升性能的两个重要手段。Spark通过序列化将链式分布的数据转化为连续分布的数据, 这样就能够进行分布式的进程间数据通信或者在内存进行数据压缩等操作,通过压缩能够减少内存占用以及I/O和网络数据传输开销, 提升Spark整体的应用性能。
在Spark中内置了两个数据序列化类:JavaSerializer和KryoSerializer,这两个继承于抽象类SeriaIizer, 而在Spark SQL中SparkSqlSerializer继承于KryoSerializer, 它们之间关系如下Spark序列化类图所示。
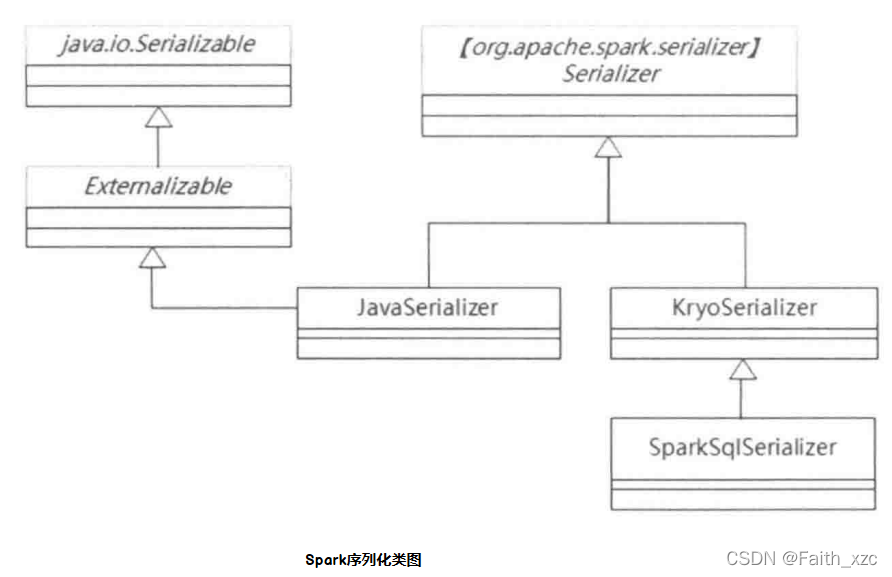
默认情况下Spark默认使用的JavaSerializer 序列方法, 它使用的是Java 的ObjectOutputStream序列化框架。JavaSerializer继承于java.io.Serializable,但性能不佳, 而且生成的序列结果也较大, 因此Spark提供性能更佳的KryoSerializer方法,不过KryoSerializer不支持所有的系列化对象, 而且要求用户注册类。 如果这两种序列化方法不满足要求, 也可以通过集成Scrializer类自定义新的序列化方法。
Spark初始序列化是在SparkEnv类进行创建,在该类中根据spark.serializer配置初始化序列化实例, 然后把该实例作为参数初始化SerializerManager实例, 而SerializerManager作为参数初始化Block.Manager。代码实现如下:
//这里可以序列化的对象是Shuffle数据以及RDD缓存等场合
val serializer = instantiateClassFromConf[Serializer](
“spark.serializer”, “org.apache.spark.serializer.JavaSerializer”)
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
val closureSerializer = new JavaSerializer(conf)
需要注意的是,这里可配的序列化的对象是Shuffle数据以及RDD缓存等场合,对于Spark 任务的序列化是通过spark.closure.serializer米配置, 目前只支待JavaSerializer。
Spark内置提供了三种压缩方法, 分别是:LZ4、LZF和Snappy, 这三个方法均继承于特质类CompressionCodec, 并实现了其压缩和解压两个方法, 它们之间关系如下Spark压缩类图所示。
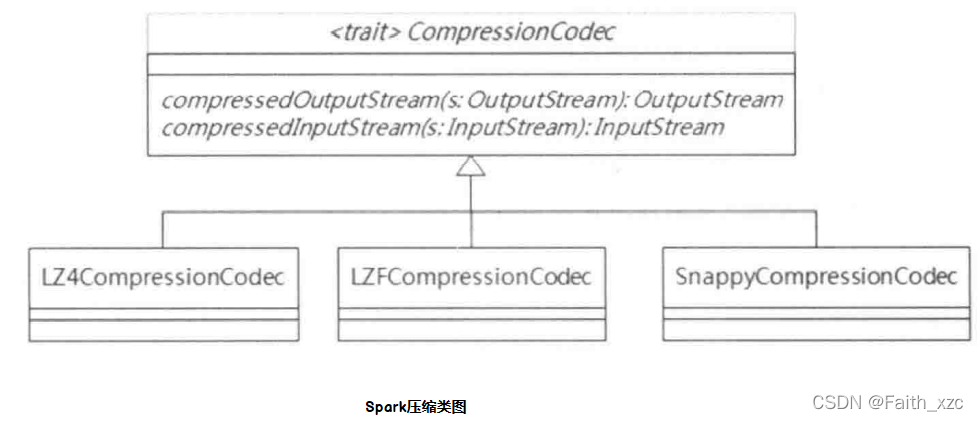
这二个压缩算法采用了第三方库实现的, Snappy提供了更高的压缩速度,LZF提供了更高 的压缩比, LZ4提供了压缩速度和压缩比俱佳的性能:
最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
下面的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)

最新整理电子书

《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!**















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









