






前言
Linux 系统性能指标无非就是这几个方面,CPU、内存、磁盘 I/O、文件系统、网络等相关指标。不同的性能指标都有对应的具体命令工具进行查看与监控,接下来我们将介绍一些常见的 Linux 系统性能指标及其对应的命令工具(通过命令工具找出 Linux 系统性能瓶颈),而要优化 Linux 系统性能,首先就要对 Linux 性能指标的知识点进行整体掌握,否则一切都是空谈。
Linux系统的性能受多个因素的影响。以下是一些常见的影响Linux系统性能的因素:
-
CPU负载:CPU的利用率和负载水平对系统性能有直接影响。高CPU负载可能导致进程响应变慢、延迟增加和系统变得不稳定。
-
内存使用:内存是系统运行的关键资源。当系统内存不足时,可能会导致进程被终止、交换分区使用过多以及系统性能下降。
-
磁盘I/O:磁盘I/O性能是影响系统响应时间和吞吐量的重要因素。高磁盘I/O负载可能导致延迟增加、响应变慢和系统性能下降。
-
网络负载:网络流量的增加和网络延迟会对系统性能产生影响。高网络负载可能导致网络延迟增加、响应变慢和系统资源竞争。
-
进程调度:Linux系统使用进程调度器来管理和分配CPU资源。调度算法的选择和配置会影响进程的优先级和执行顺序,从而影响系统的响应能力和负载均衡。
-
文件系统性能:文件系统的选择和配置对磁盘I/O性能有影响。不同的文件系统可能在性能方面有所差异,适当的文件系统选项和调整可以改善系统性能。
-
内核参数:Linux内核有许多可调整的参数,可以影响系统的性能和行为。例如,TCP/IP参数、内存管理参数、文件系统缓存等。适当的内核参数调整可以改善系统的性能和资源利用率。
-
资源限制和配额:在多用户环境中,资源限制和配额的设置可以控制每个用户或进程可使用的资源量。适当的资源管理可以避免某些进程耗尽系统资源而导致性能问题。
接下来我们用一些常用命令去进行网络、CPU、内存、磁盘的性能分析
一、网络性能分析
1.1 ping命令
ping 命令是一个用于测试网络连接的常见命令行工具,通常用于检查目标主机是否可达以及测量网络往返时间(RTT)。
选项
-c N ping N次后停止ping
-s N 一个ping包的字节数大小
-W N 第一个ping包的响应超时时间,单位S,其余ping包的响应超时时间为1s
-w N 执行PING操作的超时时间,单位S
-f 极限检测,快速连续ping一台主机范例
[root@ubuntu2004 ~]#ping 10.0.0.179
PING 10.0.0.179 (10.0.0.179) 56(84) bytes of data.
64 bytes from 10.0.0.179: icmp_seq=1 ttl=64 time=0.809 ms
64 bytes from 10.0.0.179: icmp_seq=2 ttl=64 time=4.58 ms
64 bytes from 10.0.0.179: icmp_seq=3 ttl=64 time=4.73 ms
64 bytes from 10.0.0.179: icmp_seq=4 ttl=64 time=4.44 ms
64 bytes from 10.0.0.179: icmp_seq=5 ttl=64 time=2.58 ms
^C
--- 10.0.0.179 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4047ms
rtt min/avg/max/mdev = 0.809/3.429/4.733/1.525 ms字段输出解释:
-
PING:这是 ping 命令的第一行,显示正在执行的 ping 命令以及目标主机的 IP 地址或主机名。
-
bytes:每个 ICMP 报文的大小,通常默认为 64 字节。
-
icmp_seq:ICMP 报文的序列号,从 0 开始递增。
-
ttl:生存时间(Time to Live),表示报文在网络上能够存活的跳数(路由器数量)。
-
time:每个 ICMP 报文的往返时间(Round-Trip Time,RTT),以毫秒为单位。这是从发送 ICMP 报文到接收响应所经过的时间。
-
packets transmitted:发送的 ICMP 报文数量,表示发送的次数。
-
packets received:接收的 ICMP 响应报文数量,表示成功收到的次数。
-
packet loss:丢失的 ICMP 报文数量,表示未收到响应的次数,通常以百分比形式显示。
-
time:用于显示 RTT 的统计信息,通常包括最小、最大和平均 RTT 时间。
在进行网络性能分析的时候,我们要重点关注 packet loss 的值,如果该值越大,说明丢包就越严重,表明源与目的之间的网络延时很大,此时就需要检查你的本地网络。
说明:
- ping一个不存在地址出现的提示:Destination Host Unreachable
- 受防火墙规则限制的提示:Destination Port Unreachable
1.2 mtr命令
通常网络出问题我们都会使用 ping 命令,但是该命令只是简单的网络连通性测试,却无法确定网络是在哪里出了问题,此时就会使用 traceroute 来查看数据包途径路由,或使用 nslookup 来查看 DNS 解析状态是否正常。而我们的 mtr 命令正好集成了这三个命令的功能,从而实现了我们的需求。
mtr(My Traceroute)是一个网络诊断工具,结合了 traceroute 和 ping 的功能,用于追踪网络路径和测量网络往返时间(RTT)。mtr 不仅可以显示路由路径,还能实时监控网络路径中每个跳的性能指标。
安装
apt install -y mtr语法和选项
mtr [选项] 目标主机
-n:用于禁用域名解析。
-c:用于指定发送数据包的次数。
-i:用于设置报文发送的时间间隔。范例
[root@ubuntu2004 ~]#mtr www.baidu.com就会如下图所示
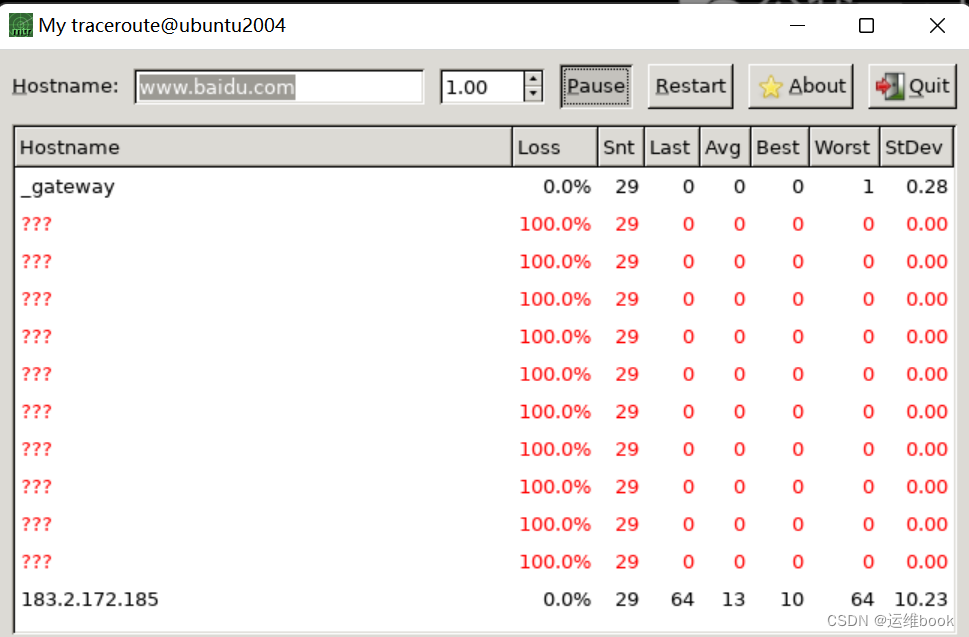
字段输出解释:
-
Host:显示路由路径上每个跳的主机名或 IP 地址,其中最后一行显示了目标主机(在本例中是 14.119.104.254)。
-
Loss%:损失率,表示到达每个跳的数据包丢失的百分比。在这个例子中,192.168.* 跳的损失率都是 0%,这意味着我本地没有数据包丢失,我本地网络正常,而中间网络就存在丢包了,说明中间路由网络是有延迟的。
-
Snt:发送的数据包数量,表示发送给每个跳的数据包总数。
-
Last:最后一个数据包的往返时间(RTT),以毫秒为单位。这是从源主机到达每个跳的最后一个数据包的时间。
-
Avg:平均往返时间,以毫秒为单位。这是从源主机到达每个跳的所有数据包的平均时间。
-
Best:最短往返时间,以毫秒为单位。这是从源主机到达每个跳的最快数据包的时间。
-
Wrst:最长往返时间,以毫秒为单位。这是从源主机到达每个跳的最慢数据包的时间。
-
StDev:往返时间的标准差,以毫秒为单位。它表示 RTT 变化的程度,越小越好。
一般情况下 mtr 前几跳都是本地 ISP(本次案例是我虚拟机的网关),后几跳属于服务商(本次案例的百度),中间跳数则是中间网络互联节点(本次案例是???),如果前几跳异常,需联系本地 ISP,如果后几跳出现问题,则需联系服务商(百度),如果中间几跳出现问题,则两边都无完全解决问题。
二、CPU性能分析
2.1 uptime
用于显示系统的运行时间以及当前系统的平均负载(Load Average)。
[root@rocky8 ~]#uptime
17:56:46 up 6:18, 4 users, load average: 0.15, 0.03, 0.01字段说明
- 17:56:46:系统当前时间
- up 6:18:系统己开机运行时长
- 4 users:当前登录到系统的用户数量
- load average: 0.15, 0.03, 0.01:系统的平均负载,1分钟,5分钟,15分钟
我们需要重点关注三个负载值。那么要怎么看,怎么分析, 我们需要知道几个概念
- CPU时间片:我们现在所使用的Windows、Linux、Mac OS都是“多任务操作系统”,就是说他们可以“同时”运行多个程序,比如一边打开Chrome浏览器浏览网页还能一边听音乐。 但是,实际上一个CPU内核在同一时刻只能干一件事,那操作系统是如何实现“多任务”的呢?大概的方法是让多个进程轮流使用CPU一小段时间,由于这个“一小段时间”很短(在linux上为5ms-800ms之间),用户感觉不到,就好像是几个程序同时在运行了。上面提到的“一小段时间”就是我们所说的CPU时间片,CPU的现代分时多任务操作系统对CPU都是分时间片使用的。
- CPU利用率:就是程序对CPU时间片的占用情况,即CPU使用率 = CPU时间片被程序使用的时间 / 总时间。比如A进程占用10ms,然后B进程占用30ms,然后空闲60ms,再又是A进程占10ms,B进程占30ms,空闲60ms,如果在一段时间内都是如此,那么这段时间内的CPU占用率为40%。CPU利用率显示的是程序在运行期间实时占用的CPU百分比。
- CPU负载:指的是一段时间内正在使用和等待使用CPU的任务数
简单理解,CPU利用率是CPU的实时使用情况,CPU负载是CPU的当前以及未来一段时间的使用情况。举例来说:如果我有一个程序它需要一直使用CPU的运算功能,那么此时CPU的使用率可能达到100%,但是CPU的工作负载则是趋近于“1”,因为CPU仅负责一个工作嘛!如果同时执行这样的程序两个呢?CPU的使用率还是100%,但是工作负载则变成2了。所以也就是说,CPU的工作负载越大,代表CPU必须要在不同的工作之间进行频繁的工作切换。无论CPU的利用率是高是低,跟后面有多少任务在排队(CPU负载)没有必然关系。
CPU核数和load average的关系
我们要知道,load average指的是过去一段时间内,系统中同时处于可运行状态和不可中断睡眠状态的进程的平均数,可以和CPU负载的概念进行近似理解。在CPU中可以理解为CPU可以并行处理的任务数量,就是CPU个数乘以核数。
所以Load Average是与CPU内核数有关的 ,如果单核CPU的话,负载达到1就代表CPU已经达到满负荷的状态了,超过1,后面的进行就需要排队等待处理了。如果是是多核多CPU,假设现在服务器是2个CPU,每个CPU有2个核,那么总负载不超过4都没什么问题。
load average返回三个平均值应该参考哪个值?
以一个单核的机器为例
- 如果只有1分钟的系统负荷大于1.0,其他两个时间段都小于1.0,这表明只是暂时现象,问题不大。
- 如果15分钟内,平均系统负荷大于1.0(调整CPU核心数之后),表明问题持续存在,不是暂时现象。所以应该主要观察"15分钟系统负荷",将它作为服务器正常运行的指标。
2.2 vmstat
用于监控系统性能和虚拟内存统计的命令。它提供了关于CPU、内存、磁盘I/O和系统上下文切换等方面的信息。
语法
vmstat [option] [刷新间隔] [刷新次数]
-a 分开显示活动和非活动内存
-s 显示事件统计
-d 统计磁盘设备相关信息
-D 综合统计磁盘
-p <dev> 统计指定分区
-S <char> 指定显示单位 k|K|m|M
-w 以宽格式显示
-t 显示时间[root@rocky8 ~]#vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1033308 4204 526264 0 0 3 2 41 59 0 0 100 0 0字段说明
procs:显示队列和等待状态
-
r 列:表示运行队列中的进程数,即当前正在运行的进程数。如果这个值长期大于系统 CPU 个数,说明 CPU 紧张,需进行 CPU 升级(即增加系统 CPU)。
-
b 列:表示在等待资源的进程数,即处于不可中断(blocked)状态的进程数,通常是等待 I/O、内存交换完成的进程数。由于硬盘速度特别慢而导致内存同步的时候没成功,那么现在告诉程序,说你先不要产生数据,这就是阻塞 b越大证明硬盘压力很大
memory:显示物理内存状态
-
swpd 列:表示交换(swap)的虚拟内存使用量,表示从实际物理内存已经交换到交换空间的数据量,我这里的值为 0,因为我压根就没有启用 Swap Space。如果你启用了交换空间,发现swpd 列下的值很大,只要 swap 字段下的 si、so 列的值长期为 0,这也不会影响系统性能。
-
free 列:表示当前可用的空闲物理内存。
-
buff 列:Buffers Cache,表示内存缓冲区缓存的数据量,一般对块设备的读写才需要缓冲(即通常用于文件I/O缓存)。
-
cache 列:Page Cache,表示内存的页高速缓存的数据量,一般作为文件系统的缓存(即通常用于文件系统缓存),频繁访问的文件都会被缓存,如果 cache 列的值比较大,说明页缓存的文件数较多,如果此时 io 字段中的 bi 列的值较小,说明文件系统效率较好。
swap:显示交换分区读写情况
-
si 列:表示每秒从磁盘(即交换空间)交换到内存的数据量(swap in)(单位KB/s),内存进,从swap出。
-
so 列:表示每秒从内存交换到磁盘(即交换空间)的数据量(swap out)(单位KB/s),内存出,进到swap里面,腾出内存空间运行应用程序。
说明:如果 si、so 长期不为 0,那我们的 Linux 系统的物理内存资源肯定不足了。为什么呢?你想一想,根据内存的相关机制,我们知道长期不为 0,说明数据频繁地在物理内存和交换空间中交换数据,如:需要使用内存的进程会在内存中运行,然后内存会将不常用的文件数据交换到 Swap Space,这样的话 si、so 值势必是不会为 0 的,而且会存在频繁波动。如果发现si、so里面有数据,说明内存可能不够用了
io:显示磁盘读写情况
-
bi 列:表示每秒从块设备(磁盘)读取的块数量(blocks in)(单位KB/s),从块设备读入数据到系统的速率(kb/s),进内存。
-
bo 列:表示每秒写入块设备(磁盘)的块数量(blocks out)(单位KB/s),保存数据至块设备的速率,出内存
说明:如果 bi + bo 的值大于 1000KB/s,且 wa 值较大,则表示系统磁盘 I/O 有瓶颈,应该提高磁盘的读写性能。
system:显示采集间隔内发生的中断数
-
in 列:每秒中断的数量,包括时钟中断、网络中断等。
-
cs 列:每秒上下文切换的数量,包括进程切换和内核线程切换。
说明:如果这两个值越大,说明内核消耗的 CPU 时间会越多。
cpu:显示 CPU 的使用状态
-
us 列:用户空间占用CPU时间的百分比。如果长期大于 50%,就需要考虑优化程序或算法。
-
sy 列:内核空间占用CPU时间的百分比。如果 us + sy 长期大于 80%,说明 CPU 资源不足。
-
id 列:CPU空闲时间的百分比。
-
wa 列:等待 I/O 完成的CPU时间的百分比。wa 越高说明 IO 等待越严重,一般如果 wa 超过 20%,说明 IO 等待严重(可能是因为磁盘大量的随机读写造成)。
-
st 列:用于虚拟机监控程序(hypervisor)的CPU时间的百分比(仅在虚拟化环境中可见)
我们需要重点关注 procs 字段的 r 列和 CPU 字段的值。
2.3 mpstat
mpstat 是 Multiprocessor Statistics(即多处理器统计),它用于显示多核CPU系统中每个CPU核心的性能统计信息。这个命令可以帮助系统管理员监控和分析系统的CPU使用情况,尤其是在多核 CPU 的环境中。一般地,有些 Linux 发行版默认没有安装次工具,需我们手动安装。来自于sysstat包
该命令与 vmstat 命令类似,mpstat 是通过 /proc/stat 里面的状态信息进行统计的,mpstat 的好处在于,它可以查看多核 CPU 中每个 CPU 计算核的统计数据的情况,而 vmstat 只能查看系统整体 CPU 的情况。
语法
mpstat [option] [刷新次数]
-P N 查看第N号CPU的运行情况,ALL表示查看所有[root@centos ~]#mpstat
Linux 3.10.0-1160.el7.x86_64 (centos) 09/16/2023 _x86_64_ (2 CPU)
04:49:20 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:49:20 PM all 0.03 0.00 0.05 0.00 0.00 0.00 0.00 0.00 0.00 99.92字段输出解释:
-
Linux 3.10.0-1160.el7.x86_64 (centos):显示操作系统版本和主机名。
-
09/16/2023:显示当前日期。
-
x86_64:显示系统架构(在此示例中为x86_64,表示64位系统)。
-
(2 CPU):显示 CPU 核心数量,本例中有 2 个CPU核心。
-
04:49:20 PM:显示统计信息的时间戳。
-
CPU:处理器的 ID 号,采集时不指定则默认为系统整体 CPU 情况(all 表示系统整体 CPU 情况,其他如 CPU 0、CPU 1 等)。
-
%usr:用户空间占用 CPU 时间的百分比。
-
%nice:优先级较高的用户空间占用 CPU 时间的百分比。
-
%sys:内核空间占用 CPU 时间的百分比。
-
%iowait:CPU 等待 I/O 操作完成的百分比。涉及到磁盘的IO或者网络的IO,值过大说明磁盘和网络的性能较差
-
%irq:CPU 处理硬件中断的百分比。
-
%soft:CPU 处理软件中断的百分比。
-
%steal:CPU 被虚拟机监控程序(hypervisor)"偷取"的百分比,即被嵌套虚拟机跑进程所使用的时间
-
%guest:运行虚拟机中的操作系统时,CPU花费在虚拟机中的百分比,即运行虚拟化主机cpu自身时间的占比
-
%gnice:虚拟机中运行的优先级较高的用户空间占用CPU时间的百分比,即运行虚拟cpu上的nice 进程的占比
-
%idle:CPU空闲时间的百分比,值越高,CPU利用率越低
-
Average:平均值,如果指定了采集次数,系统为自动为我们计算出相关字段的平均值。
在实际开发中,可能有些不使用多线程体系结构的应用程序可能会运行在一个多核 CPU 的服务器上(比如 2 个 CPU),从而不使用所有处理器(而只使用其中一个 CPU),最终导致一个 CPU 过载,而另一个 CPU 空闲,此时通过 mpstat 命令就能很好地诊断这类问题(而此时 vmstat 去无法看出是哪个 CPU 过载,哪个 CPU 空闲),因此我们一般会将 vmstat 和 mpstat 配合使用。
三、内存性能分析
3.1 free
free 命令用于显示Linux系统上的内存使用情况。它提供了有关物理内存(RAM)和交换空间(swap)的信息,包括已使用、空闲、缓冲区和缓存内存等。
选项说明
-b 以字节为单位
-m 以MB为单位
-g 以GB为单位
-h 易读格式
-o 不显示-/+buffers/cache行
-t 显示RAM + swap的总和
-s n 刷新间隔为n秒
-c n 刷新n次后即退出[root@ubuntu2004 ~]#free -h
total used free shared buff/cache available
Mem: 3.8Gi 352Mi 425Mi 1.0Mi 3.0Gi 3.2Gi
Swap: 0B 0B 0B字段说明
-
total:物理内存的总量,包括实际可用内存和内核保留的内存
-
used:已使用的物理内存量,包括用于进程和系统的内存
-
free:空闲的物理内存量,尚未分配给任何进程
-
shared:被共享的内存量,通常用于共享内存段的进程(如进程间通信机制),即多个进程共享的内存
-
buff/cache:用于缓冲区和缓存的内存量。这包括Linux内核用于缓存文件系统数据的内存,以及用于文件I/O的内存缓冲区
-
available:可用内存量,表示系统当前可供新进程使用的内存,包括缓冲区和缓存,buffer、cache可以释放大部分,所以这里近似等于 free+buffer/cache的大小
-
Mem:物理内存的相关信息,包括总内存空间、使用、剩余等相关信息。
-
Swap:交换空间的信息,包括总交换空间、已使用的交换空间和空闲交换空间。
通常情况下,total = used + free + buff/cache ,available 是在 buff/cache 基础上减去 shared 和 buffer 内存损耗后剩下的资源,因此查看服务器的内存资源是否充足,看 available 部分即可,一般地 20% < available < 70%,则系统内存资源基本能满足应用需求,暂时不影响系统性能。
在这里另外补充一下缓冲区和缓存的概念和作用
-
缓冲区(buffers)是操作系统用来临时存储I/O数据的内存区域。例如,当读写文件时,内核会将磁盘上的数据暂时存放在缓冲区内,然后再批量写,以减少磁盘碎片和硬盘反复寻道,快速处理后续的I/O请求。这样可以提高系统性能,减少对磁盘的直接访问,主要用于硬盘与内存之间的数据交互,缓存(cached) 是指文件的内容要被多个进程使用的时候,则可以将内容放入缓存区,则后续就可以直接从内存中读,而不用再消耗IO
-
缓存(cache)主要指的是页面缓存或文件缓存。这部分内存用来存储最近访问过的文件内容,使得再次访问同一文件时能更快地从内存而不是硬盘中读取数据。还包括inode缓存等内核用于加速文件系统操作的数据结构,主要作用于CPU和内存之间的数据交互(本来要用IO读硬盘文件,现在变成了读内存)
3.2 smem
smem 是一个用于查看 Linux 系统中进程内存使用情况的工具。它提供了详细的内存统计信息,包括物理内存、虚拟内存、共享内存、缓冲区和缓存等各种内存指标。smem 命令的功能比标准的 ps 或 top 命令更加详细,可以帮助我们更好地了解各个进程占用内存的情况。
安装
#centos
yum install -y epel*
yum install -y smem
#Ubuntu
apt install -y smem语法和选项
smem [选项]
-r:按照内存使用量的逆序(从高到低)排序显示进程列表。
-u:以用户模式显示内存使用情况,按照用户分类显示内存使用情况。
-U:显示虚拟内存(VIRT)的信息。
-P:显示共享内存(SHR)的信息。
-c:显示缓冲区的信息。
-C:显示缓存的信息。
-k:指定按KB显示。
-p:指定按百分比显示。
-P:指定具体的进程。
-s:指定排序规则(如 -s uss,表示对 USS 列进行排序 - 默认为升序)不添加选项,默认情况下,smem 命令以物理内存(RES)的信息排序,并显示前10个进程
[root@ubuntu2004 ~]#smem
PID User Command Swap USS PSS RSS
929 daemon /usr/sbin/atd -f 0 204 279 2464
900 root /usr/sbin/cron -f 0 308 429 3036
909 root /usr/sbin/irqbalance --fore 0 472 646 3616
18940 root /usr/lib/openssh/sftp-serve 0 628 955 4280
946 root /bin/login -p -- 0 908 1299 4400
901 messagebus /usr/bin/dbus-daemon --syst 0 1104 1472 4744
827 systemd-timesync /lib/systemd/systemd-timesy 0 976 1521 7500
926 root /lib/systemd/systemd-logind 0 1184 1739 7660
944 root sshd: /usr/sbin/sshd -D [li 0 932 1804 7408
970 root /usr/lib/policykit-1/polkit 0 972 1848 7272
897 root /usr/lib/accountsservice/ac 0 1176 2045 7476
1287 root -bash 0 1712 2405 5180
18873 root -bash 0 1888 2615 5564
18769 root sshd: root@notty 0 1592 2800 9228
560 root /lib/systemd/systemd-udevd 0 2652 2808 5840
1281 root /lib/systemd/systemd --user 0 1600 2855 9524
18767 root sshd: root@pts/0 0 1776 2987 9372
13997 systemd-network /lib/systemd/systemd-networ 0 2820 3121 7800
1282 root (sd-pam) 0 2500 3173 5132
915 syslog /usr/sbin/rsyslogd -n -iNON 0 3256 3449 6372
839 root /usr/bin/vmtoolsd 0 3156 3647 8036
914 redis /apps/redis/bin/redis-serve 0 3976 4179 7360
838 root /usr/bin/VGAuthService 0 3516 4797 10812
928 root /usr/lib/udisks2/udisksd 0 4340 5405 12392
1 root /sbin/init maybe-ubiquity 0 3656 5464 12992
886 systemd-resolve /lib/systemd/systemd-resolv 0 6736 7309 13188
37633 root /usr/bin/python3 /usr/bin/s 0 7236 8613 13728
37423 root /usr/lib/packagekit/package 0 7636 9580 16032
911 root /usr/bin/python3 /usr/bin/n 0 8132 10387 18520
964 root /usr/bin/python3 /usr/share 0 8212 11608 21308
783 root /sbin/multipathd -d -s 0 14552 14995 19000
917 root /usr/lib/snapd/snapd 0 30756 30827 32624
527 root /lib/systemd/systemd-journa 0 37524 43887 55468
字段输出解释:
-
PID:进程ID。
-
User:进程所属用户。
-
Command:进程的命令行。
-
Swap:进程占用的交换空间。
-
USS:唯一内存使用(Unique Set Size),表示进程独占的内存。只计算进程独自占用的内存大小,不包含任何共享的部分
-
PSS:共享内存使用(Proportional Set Size),表示进程独占内存加上共享内存的平均值。
-
RSS:物理内存使用(Resident Set Size),表示进程当前实际占用的物理内存。
指定字段uss,以KB为内存单位并进行排序
smem -k -s uss指定uss字段以百分比显示并进行排序
smem -p -s uss查看每个用户使用内存的情况
smem -u查看指定dockerd进程使用系统内存的情况
smem -k -P dockerd所以我们使用smem命令,可清楚地获取每个进程占用的内存资源,以此判断这些进程是否异常,内存分配是否合理。
四、磁盘性能分析
4.1 iostat
用于监视 Linux 系统中磁盘和 CPU 使用情况的命令行工具。它可以提供有关系统的磁盘 I/O 和 CPU 使用的详细统计信息。此工具由sysstat包提供
语法及选项
iostat [option] [刷新间隔] [刷新次数]
-c 只显示CPU行
-d 显示设备(磁盘)使用状态
-k 以千字节为为单位显示输出
-t 在输出中包括时间戳
-x 在输出中包括扩展的磁盘指标[root@centos8 ~]#iostat
Linux 4.18.0-80.el8.x86_64 (centos8.localdomain) 01/09/2020 _x86_64_ (4CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.01 0.00 0.06 0.00 0.00 99.93
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.31 2.57 3.52 238227 326708
scd0 0.01 0.14 0.00 13140 0字段说明
-
%usr:用户空间进程占用的CPU
-
%nice:调整优先级占用的CPU
-
%system:内核空间进程占用的CPU
-
%iowait:等待IO,涉及到磁盘的IO或者网络的IO,值过大说明磁盘和网络的性能较差
-
%steal:被嵌套虚拟机跑进程所使用的时间
-
%idle:空闲值,值越高,CPU利用率越低
-
Device:磁盘设备的名称,表示正在监视的磁盘或分区。
-
tps:每秒传输的 I/O 操作次数。这个值表示每秒完成的读取和写入磁盘的总操作数,即该设备每秒的传输次数,"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的
-
kB_read/s:每秒从磁盘读取的数据量。这个值表示每秒从磁盘读取的数据量,以千字节(KB)为单位。
-
kB_wrtn/s:每秒写入磁盘的数据量。这个值表示每秒写入磁盘的数据量,以千字节(KB)为单位。
-
kB_read:自系统启动以来从磁盘读取的总数据量。这个值表示自系统启动以来累积的总读取数据量,以千字节(KB)为单位。
-
kB_wrtn:自系统启动以来写入磁盘的总数据量。这个值表示自系统启动以来累积的总写入数据量,以千字节(KB)为单位。
[root@centos8 ~]#iostat -d sda 1 3 -x
Linux 4.18.0-193.el8.x86_64 (centos8.wangxiaochun.com) 11/24/2020 _x86_64_(2 CPU)
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 12.70 2.93 523.99 183.34 0.05 0.78 0.41 20.93 0.37 0.75 0.00 41.26 62.53 0.50 0.78字段说明
-
r/s: 每秒合并后读的请求数
-
w/s: 每秒合并后写的请求数
-
rsec/s:每秒读取的扇区数
-
wsec/:每秒写入的扇区数
-
rKB/s:每秒向设备发出的读取请求数
-
wKB/s:每秒向设备发出的写入请求数
-
rrqm/s:每秒这个设备相关的读取请求有多少被合并了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同块的数据,FS会将这个请求合并)
-
wrqm/s:每秒这个设备相关的写入请求有多少被合并了
-
%rrqm: 读取请求在发送到设备之前合并在一起的百分比
-
%wrqm: 写入请求在发送到设备之前合并在一起的百分比
-
avgrq-sz:平均请求扇区的大小
-
avgqu-sz:是平均请求队列的长度。毫无疑问,队列长度越短越好
-
await:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
-
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
-
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
我们需要重点关注 kB_read/s、kB_wrtn/s ,通过这两个字段就可判断磁盘读写性能及磁盘读写是否频繁的问题。
- 如果 kB_wrtn/s 很大,说明磁盘写操作很频繁,可考虑磁盘或程序优化。
- 如果 kB_read/s 很大,说明程序对磁盘的读操作较频繁,可考虑将读取的数据放入内存中操作,提高读性能。
4.2 iotop
iotop命令是一个用来监视磁盘I/O使用状况的top类工具,iotop具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息,可查看查看哪些进程正在读取或写入磁盘,可定位哪个进程消耗IO的时间最长。来自于iotop包。
选项说明
-o 只显示正在产生I/O的进程或线程,除了传参,可以在运行过程中按o生效
-b 非交互模式,一般用来记录日志
-n NUM|--iter=NUM 设置监测的次数,默认无限。在非交互模式下很有用
-d SEC|--delay=SEC 设置每次监测的间隔,默认1秒,接受非整形数据例如1.1
-p PID|--pid=PID 指定监测的进程/线程
-u USER|--user=USER 指定监测某个用户产生的I/O
-P 仅显示进程,默认iotop显示所有线程
-a 显示累积的I/O,而不是带宽
-k 使用kB单位,而不是对人友好的单位。在非交互模式下,脚本编程有用
-t 加上时间戳,非交互非模式
-q 禁止头几行,非交互模式,有三种指定方式
-q 只在第一次监测时显示列名
-qq 永远不显示列名
-qqq 永远不显示I/O汇总交互按键
left和right方向键:改变排序
r:反向排序
o:切换至选项--only
p:切换至--processes选项
a:切换至--accumulated选项
q:退出
i:改变线程的优先级[root@centos8 ~]#iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND字段输出解释
第一行:Read和Write速率总计
第二行:实际的Read和Write速率
第三行:
-
TID:线程或进程的唯一标识符(Thread/Task ID),表示正在进行磁盘 I/O 操作的进程或线程的ID。
-
PRIO:进程的优先级(Priority),通常用于指示进程的执行优先级。
-
USER:执行磁盘 I/O 操作的用户的用户名。
-
DISK READ:磁盘读取速率,表示进程正在从磁盘读取数据的速度。以字节/秒(Bytes per Second)为单位显示。
-
DISK WRITE:磁盘写入速率,表示进程正在向磁盘写入数据的速度。以字节/秒为单位显示。
-
SWAPIN:表示进程从交换空间中读取数据的速率,通常用于虚拟内存操作。以字节/秒为单位显示。
-
IO>:磁盘 I/O 操作的总和,包括读取和写入。以百分比形式表示,表示磁盘 I/O 占用的总带宽。
-
COMMAND:正在进行磁盘 I/O 操作的进程或线程的命令名称。
我们重点关注一下磁盘读写
- DISK READ:磁盘读取速率,表示进程正在从磁盘读取数据的速度。以字节/秒(Bytes per Second)为单位显示。
- DISK WRITE:磁盘写入速率,表示进程正在向磁盘写入数据的速度。以字节/秒为单位显示。
五、综合的性能分析命令
5.1 top
top 命令是一个用于实时监视 Linux 系统中进程的命令行工具,它提供了有关系统性能和进程活动的实时信息。top 可以帮助我们监视系统资源的使用情况,识别性能问题,并查看正在运行的进程的相关信息
top 命令没有参数,直接运行它将显示实时的系统性能信息和进程列表。默认情况下,top 会按 CPU 利用率降序排列进程。
[root@ubuntu2004 ~]#top
top - 14:58:07 up 11:35, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 219 total, 3 running, 216 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3888.4 total, 2479.3 free, 339.4 used, 1069.6 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 3277.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
783 root rt 0 346048 18272 8308 S 6.7 0.5 0:45.15 multipathd
1 root 20 0 170384 12992 8496 S 0.0 0.3 0:02.78 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.10 ksoftirqd/0
10 root 20 0 0 0 0 R 0.0 0.0 2:34.03 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.27 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/0
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1
16 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/1
字段输出解释
第一行:uptime格式
- 14:58:07:系统当前时间
- up 11:35:系统己开机运行时长
- 2 users:当前有两个用户登录
- load average: 0.00, 0.00, 0.00:系统的平均负载,1分钟,5分钟,15分钟
第二行:
- 一共219个进程,其中3个在运行,216个在睡觉,0个停止态。0个僵尸态
第三行:
- us:用户空间进程占用的CPU
- sy:内核空间进程占用的CPU
- ni:用户进程以调整优先级方式运行的时间的百分比(nice值)
- id:CPU空闲时间的百分比
- wa:CPU等待I/O完成的时间的百分比
- hi:处理硬件中断的时间的百分比
- si:处理软件中断的时间的百分比
- st:被嵌套虚拟机跑进程所使用的时间
第四行:
- Mem:物理总内存大小,未使用内存大小,已使用物理内存大小,内核缓存占用内存大小
第五行:
- swap:交换区大小,未使用交换区大小,已使用交换区大小
第六行
- PID:进程号
- USER:用户
- PR:优先级
- VIRT:虚拟物理内存,包括所有代码、数据和共享库,以及已交换的页面和已映射但未使用的内存
- RES:实际物理内存,共享的内存比如动态库也会计算在内
- SHR:共享物理内存,并非所有共享的内存都是常驻的
- S:进程状态
- %CPU:CPU占用率
- %MEM:内存占用率
- TIME+:时间片累加值
选项
-d 指定刷新时间间隔,默认为3秒
-b 全部显示所有进程
-n 刷新多少次后退出
-H 线程模式
-p 指定进程号
^%Cpu 过滤以 %CPU 开头的行交互环境下子命令
排序:
- P:以占据的CPU百分比,%CPU
- M:占据内存百分比,%MEM
- T:累积占据CPU时长,TIME+
首部信息显示:
- uptime信息:l命令
- tasks及cpu信息:t命令
- cpu分别显示:1 (数字)
- memory信息:m命令
其他子命令
- 退出命令:q或esc
- 修改刷新时间间隔:s
- 终止指定进程:k
- 保存文件:W
- 帮助:h 或 ?
快捷键
- h:获取帮助。按下h键,top命令将为您展示所有可用的快捷键和功能说明。这是您使用top命令时的得力助手,随时提供帮助和指导。
- k:结束进程。选中要结束的进程,按下k键,然后输入要结束的进程的PID(进程ID),即可终止选定的进程。这是一个强大而危险的功能,可用于关闭不响应或占用过多资源的进程。
- r:修改进程优先级。按下r键,可以修改选定进程的优先级。通过输入要修改的进程的PID和新的优先级值,您可以更好地管理系统资源分配,提高系统性能。
- f:选择显示字段。按下f键,进入字段选择界面,允许您自定义top命令中显示的字段。您可以根据需求选择要显示的字段,如CPU使用率、内存占用等,以便更全面地了解系统性能。
- o:按指定字段排序。按下o键,可以按指定字段对进程列表进行排序。输入要排序的字段名称,top命令将根据该字段的值对进程进行排序,如按CPU使用率排序、按内存占用排序等。
- s:更改刷新间隔。按下s键,可以修改top命令的刷新间隔。输入新的刷新间隔值(以秒为单位),默认为3秒。通过调整刷新频率,您可以更准确地监控系统的实时性能。
- q:退出top命令。按下q键,可以退出top命令,返回到命令行界面。
- 1:切换到单核模式。按下数字键1,可以切换到单核模式,只显示一个CPU核心的性能数据。这对于单核处理器的系统非常有用,可以更清晰地查看单个核心的性能情况。
- i:隐藏空闲和僵尸进程。按下 i 键,可以切换是否显示空闲和僵尸进程。当显示大量进程信息时,隐藏空闲和僵尸进程可以使界面更清晰,专注于关注的活动进程。
- m:切换单位显示。按下m键,可以切换单位显示方式。您可以在字节、千字节、兆字节和吉字节之间进行切换,以适应不同的内存规模。
- t:显示进程和CPU信息摘要。按下 t 键,可以在顶部显示进程和CPU信息的摘要。这个摘要可以帮助您更快速地了解系统的整体性能情况。
- W:保存当前设置为配置文件。按下大写字母W键,可以将当前top命令的设置保存为配置文件。下次启动top命令时,将使用保存的配置,节省您的时间和努力。
- L:切换显示平均负载和启动时间。按下大写字母L键,可以切换top命令的显示模式,显示平均负载和系统的启动时间。这对于监控系统负载和了解系统运行时间非常有用。
- F:跟踪选定进程。按下F键,可以跟踪选定的进程。在进程列表中选中要跟踪的进程,然后按下F键,top命令将仅显示该进程的信息,以便更详细地监控其性能和资源消耗。
- e:切换显示所有进程。按下e键,可以切换显示所有进程。默认情况下,top命令仅显示活动进程,按下e键后,将显示所有进程,包括空闲和僵尸进程。
- n:设置显示进程数量。按下n键,可以设置top命令显示的进程数量。通过输入新的进程数量值,您可以控制显示的进程数量,以适应您的需求。
- #:切换显示进程编号。按下#键,可以切换是否显示进程编号。当处理大量进程时,隐藏进程编号可以使界面更清晰,减少混乱。
- &:设置进程筛选条件。按下&键,可以设置进程筛选条件。您可以输入一个或多个条件,如进程ID、进程名称等,以便于快速筛选和定位特定的进程。
- u:仅显示指定用户的进程。按下u键,可以仅显示指定用户的进程。输入用户名后,top命令将仅显示该用户的进程信息,有助于对特定用户的进程进行监控和管理。
- z:切换颜色/显示模式。按下z键,可以切换top命令的颜色和显示模式。您可以选择不同的配色方案或切换到单色模式,以适应您的偏好和环境。
5.2 htop
可以使用 htop 的交互式命令来对进程列表进行筛选、排序和管理,以及查看更多信息,如线程和性能图表。htop 提供了更多的功能和用户友好的界面,相对于标准的 top 命令,使其成为了一个强大的系统监视和管理工具。
Centos来自EPEL源,Ubuntu 中可以直接安装
选项
-d N: 指定延迟时间;
-u UserName: 仅显示指定用户的进程
-s COLUME: 以指定字段进行排序子命令
s:跟踪选定进程的系统调用
l:显示选定进程打开的文件列表
a:将选定的进程绑定至某指定CPU核心
t:显示进程树[root@ubuntu2004 ~]#htop想要查看那个区的具体指标,鼠标点点点即可
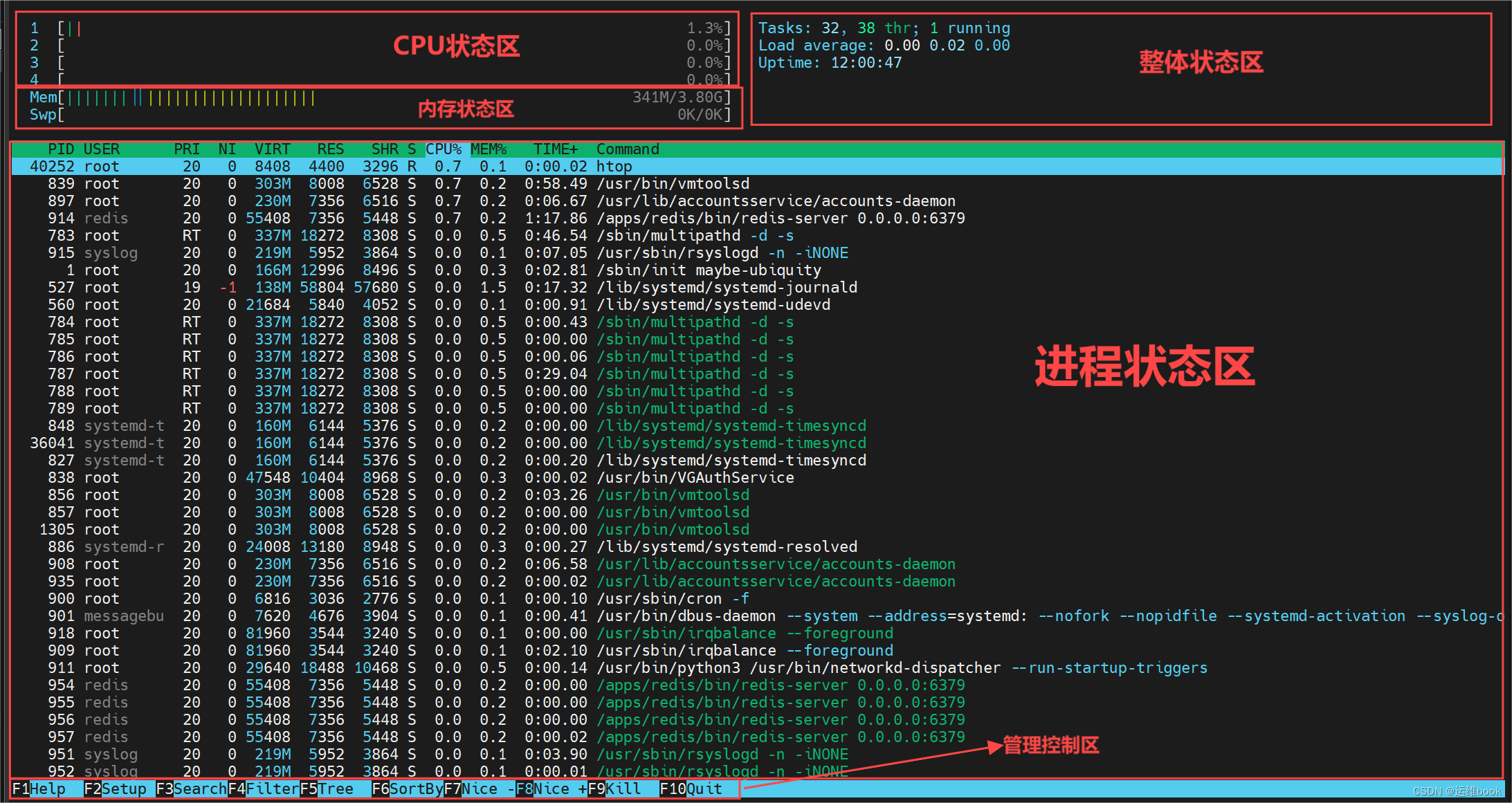
上图可分为 5 大区:
-
CPU 状态区
展示每个每个 CPU 逻辑核的使用百分比,并通过不同颜色条进行区分,蓝色表示 low-prority 使用,绿色表示 normal 使用情况,红色表示 Kernel 使用情况,青色表示 vistualiz 使用情况,上图案例中共有 2 个逻辑核。
-
内存状态区
展示物理内存和 Swap Space 的状态,同样也使用不同的颜色条来区分,其中绿色表示已使用内存情况,蓝色表示用于缓冲的内存情况,黄色表示用于缓存的内存情况。
-
整体状态区
Task 表示当前系统进程总数和当前正在运行的进程数;
Load average 表示过去 1、5、15 分钟的系统平均负载;
Uptime 表示系统运行时长。
-
进程状态区
PID:进程 ID(Process ID),表示每个正在运行的进程的唯一标识符。
USER:进程的所有者(用户),显示启动进程的用户帐户。
PRI:进程的优先级(Priority),通常是一个负整数。较低的数值表示更高的优先级。
NI:进程的 Nice 值(Nice Value),用于调整进程的优先级。负值表示较高的优先级,正值表示较低的优先级。
VIRT:虚拟内存大小(Virtual Memory),表示进程已分配但未必使用的虚拟内存大小,以千字节(KB)为单位。
RES:常驻内存大小(Resident Set Size),表示进程实际占用的物理内存大小,以千字节(KB)为单位。
SHR:共享内存大小(Shared Memory),表示多个进程之间共享的内存大小,以千字节(KB)为单位。
S:进程的状态,可以是以下之一:
-
R:运行中(Running)
-
S:睡眠中(Sleeping)
-
D:不可中断的休眠状态(Uninterruptible Sleep)
-
Z:僵尸进程(Zombie)
-
T:已停止(Stopped)
-
t:跟踪/停止(Tracing/Stopped)
-
W:等待内存交换(Paging)
-
X:死掉(Dead)
-
K:内核线程(Kernel Thread)
%CPU:进程的 CPU 利用率,表示进程使用 CPU 的百分比。
%MEM:进程的内存使用率,表示进程使用系统内存的百分比。
TIME+:进程已运行的累计 CPU 时间,以小时:分钟:秒的格式表示。
COMMAND:进程的命令名称,显示启动进程的完整命令。
如何自定义添加字段?
- 按F2键
- 在Setup列中用鼠标点击选择 Columns 字段
- 接着在Active Columns列中选择你想要的添加字段的添加位置,比如点击选中PID字段
- 接着在Available Columns列中选择你想要添加的字段,比如选择TGID,点击选中后按F5键,那么TGID字段就添加到了PID字段的前面
- 最后按F10键,你就会看到PID字段前有一列的TGID字段
总结
性能分析工具其实还有很多,以上只是一些常用的分析工具,其实会使用一两个工具已经够用了,我们重点是要能够通过数据分析这些性能的瓶颈,而分析的前提就是你得知道这些性能指标能对 Linux 系统产生哪些影响(如 CPU、内存、磁盘 I/O、网络等)。
CPU 性能瓶颈分析
-
若只想查看整体 CPU 的使用情况,可使用 vmstat;
-
若想查看具体 CPU 的使用情况,可使用 mpstat。
-
如果
top或htop显示CPU使用率持续超过80%,可能意味着系统存在性能瓶颈。这时,可以检查是否有CPU密集型进程在运行,或者考虑增加CPU资源。
内存性能分析
-
若只想查看 Linux 系统内存的整体使用情况,可使用 free;
-
若想查看具体进程占用的具体内存情况,可使用 seme。
-
当
free命令显示可用内存很少时,系统可能会变得缓慢。可以考虑关闭一些不必要的进程或增加内存容量。
磁盘性能分析
-
若只想查看 Linux 系统磁盘的整体 I/O 情况,可使用 iostat;
-
若想查看具体进程具体的对磁盘 I/O 情况,可使用 iotop。
-
如果
iostat显示磁盘的等待时间很长,而传输速率很低,可能是磁盘性能瓶颈。可以考虑使用更快的磁盘、增加缓存或优化数据库查询等方式来改善磁盘I/O性能。
网络性能分析
-
若只是简单的网络连通性测试,可使用 ping;
-
若想查看具体的网络性能(如经历的各个路由、延迟等),可使用 mtr。
-
通过
netstat或ss命令,发现大量处于TIME_WAIT状态的连接,这可能意味着系统正在经历大量的短连接请求。您可以考虑调整内核参数来减少TIME_WAIT状态的持续时间。
系统综合分析
-
若想整体掌握系统性能通过 top 即可;
-
若想更深入地查看系统中具体的进程对系统资源的占用,可使用 htop。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









