






在进入本篇前我们先模拟一个场景,在我们日常使用qq这个软件的时候,我们是怎么使用它来传递信息的,为什么我们在自己的手机上输入了一段信息点击发送,你发送的对象在短短几秒内就能收到你的信息呢?这样信息传递的过程是什么?要搞清楚这个过程我们需要从源头说起;
冯诺依曼体系结构
我们常见的计算机基本上都是满足这个结构的;这个结构的出现给我们计算机界带来了设计计算机的一个标准(标准不一定需要被遵守,但他一定是最普遍的)
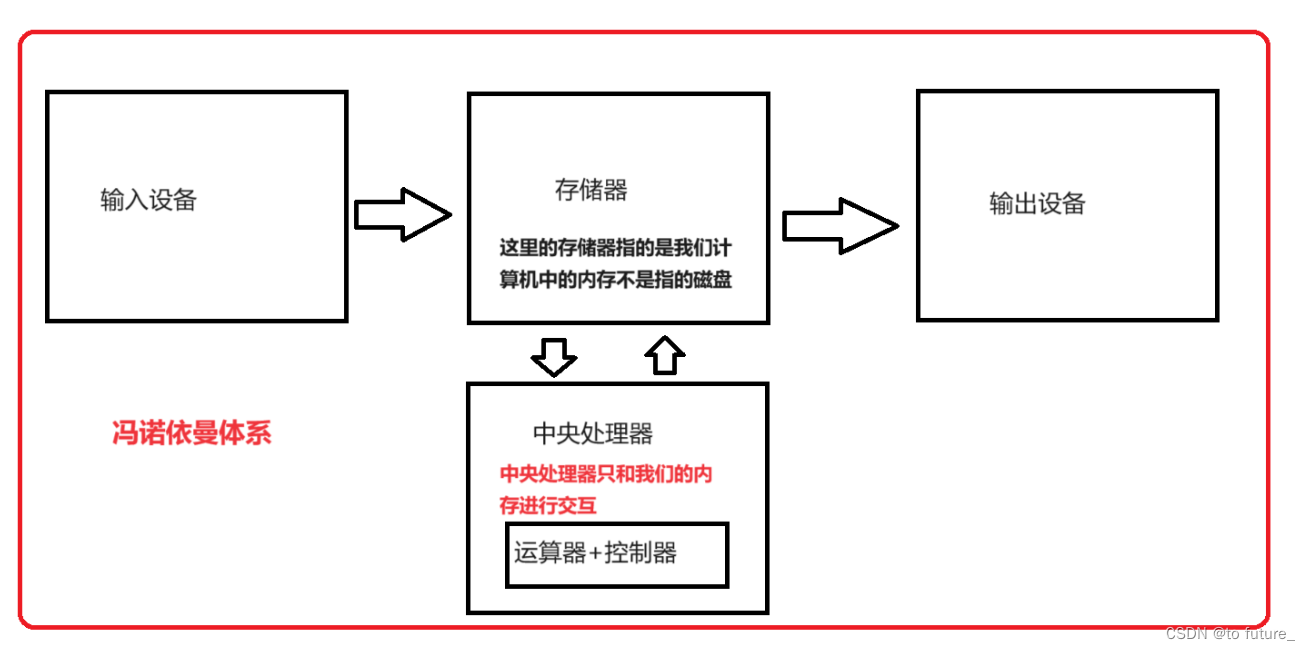
上面就是我们冯诺依曼体系的基本结构,现在我们通过这个结构来解释我们的场景,当我们输入信息到手机的时候,这个时候是通过输入设备将我们的数据输入到计算机上,这个时候我们的数据一定是加载到内存中的,我们的中央处理器对我们的数据进行处理后通过内存将数据传给输出设设备——网卡,网卡将我们的数据发送到了我们qq的服务器上,服务器再将我们的消息找到相应的用户发送给相应的用户,用户的输入设备网卡,接受到了数据后,也是将数据写入内存,我们的中央处理器从内存中读取数据,将数据处理成我们可以读懂的形式后再通过内存加载到我们的输出设备上,这个时候对方就能看到我们的消息了;
我们明白了这个过程之后,我们就大致可以理解计算机运行的过程;我们也可以通过细心的观察可以发现:
1.我们的输入输出设备可以是同一个硬件,比如说我们的网卡,磁盘;我们可以从中读取数据也可以向其中写入数据,而有些设备只能写入比如我们的键盘,还有些设备只能读取数据比如说我们的屏幕,音响;
2.我们的中央处理器只和我们的内存进行读写,我们也是通过对内存中数据的管理来控制我们的硬件的,我们所有的设备也只能和内存交互,其他设备之间是间接交互的;
了解了计算机的基本结构后,就等于一群人联合在了一块,人和人之间会有冲突,机器也一样,所以这个时候需要管理,这个时候我们的操作系统就登场啦;
操作系统
我们上面说到了计算机的结构;现在我们说说管理这个结构的操作系统;操作系统的作用就是管理好硬件,为我们的软件提供安全稳定的运行环境;我们可以通过下面这个图来更好地理解:

我们的操作系统就是这样一款搞管理的软件!
它如何来管理呢?
操作系统管理也和我们人管理一样,它只是一个个体,它需要管理的东西太多太多了,所以一定是无法直接一个一个和我们的硬件直接交互的,它是通过获取我们的硬件的数据,由驱动递交数据,我们操作系统就对我们的这些数据进行管理和操作就好了;就如同我们的大学校长不可能直接管理我们每个学生,我们会由我们的辅导员进行管理,导员将我们的数据交给他的上一级,导员的上一级再交给校长,这样层层递进,校长得到的一定是我们这些学生的数据,比如年龄学号成绩等等,我们的操作系统获得我们硬件的基本数据之后,就可以根据这些数据发出指令了;那么操作系统描述出这些数据之后,为了更好地更有序的进行管理,就可以将这些数据用数据结构的形式来组织好我们的数据;
我们可以这样理解:
我们硬件的各种数据被写成了一个struct结构体,我们描述出了这个结构体后,我们再通过我们数据结构所学习的如链表,顺序表这样的数据结构来组织好我们的数据;这样我们就可以对这些数据进行增删查改的管理了;
操作系统通过先描述再组织来管理。

我们知道操作系统这样管理好硬件之后,对上层,为了让我们用户方便使用,不需要对操作系统进行深层的学习操作,于是它开放了一些系统的调用接口,就如同我们C语言的库函数一样,我们可以直接调用,实现我们需要的功能;可是有时候这样的接口也需要一定的成本学习,为了再次降低成本,我们的大牛们就开发出了如shell外壳和windows图形化界面这样的交互界面;将我们用户使用的成本再次降低,我们的用户就可以对此进行各种app的使用或者是各种管理操作了,也就是我们现在所使用的各种软件;
我们了解了我们计算机的基本结构,以及操作系统如何管理我们的计算机后,我们再次往深层进 发——我们的进程是如何被管理的呢?
进程
进程是什么?
我们使用qq发消息,我们打游戏,我们看视频,我们都在运行程序,这些程序被运行到内存中时,它就叫做进程。
我们们手机上的程序有很多,我们如何运行他们,以及这么多程序怎么一起运行,这些都是操作系统需要处理的问题,
所以操作系统如何进行进程管理呢?
其实这个问题的答案,我们已经再上文回答了,我们操作系统也会把一个个进程的数据描述成一个个结构体,再通过数据结构将这些结构体以链表的形式形成一个队列组织起来;这就是进程管理的操作;先描述再组织;
我们描述进程的结构体叫PCB在Linux下的PCB叫做task_struct;
我们的课执行文件,需要被运行时,它会带着它的代码和它的pcb结构体一起被加载到我们的内存中,我们通过pcb结构中包含的我们进程的各种信息来了解我们进程的状态找到进程的代码等等;
在linux中我们所有进程都是以task_struct链表的形式存在在内核中的,这是我从网上找到的task_struct结构体链表的模拟实现:
struct task_struct {
/* ...其他成员... */
struct list_head tasks; // 任务链表
/* ...其他成员... */
};
// 初始化链表头
struct task_struct init_task;
INIT_LIST_HEAD(&init_task.tasks);
// 添加任务到链表尾部
struct task_struct *new_task;
struct task_struct *prev_task;
list_add_tail(&new_task->tasks, &prev_task->tasks);
// 遍历任务链表
struct task_struct *task;
list_for_each_entry(task, &init_task.tasks, tasks) {
// 对每个任务执行操作
// task->tasks 指向下一个任务的链表节点
}
为了让我们明确的看到进程这个概念,我们可以使用ps和top命令来查看我们的进程;
查看进程
下面是我写的一段代码:
#include<stdio.h>
#include<unistd.h>
int main()
{
int ret=0;
ret=getpid();
while(1)
{
printf("code pid is:%d\n",ret);
printf("#########################\n");
sleep(1);
}
return 0;
} 我们写了一段死循环代码,让我们的代码可以不被中止的运行(getpid这个函数是获取我们当前进程pid的意思,pid可以说就是这个进程的号码一样)
我们使用上面所说的ps命令进行查看
ps axj |grep 'code'这串命令可以用来查看我们的code进程的属性axj是ps命令的选项
axj是三个选项起到了下面的作用:
- “a”选项表示查看所有进程,包括其他用户的进程。
- “x”选项表示查看没有终端控制的进程,也就是后台进程。
- “j”选项表示以child threads(子线程)的格式显示进程,同时会输出进程的用户名、进程ID、CPU占用率、内存占用率、开始运行的时间、进程状态等详细信息。
grep 'code'则是从我们显示的临时文件管道 | 中找到我们的code进程的意思;

我们使用ps axj|head -1 && ps axj|grep 'code'这串命令就可以获得上图的进程信息
下面是我搜索到的这些信息的意思:
在 Linux 中,每个进程都有一个与之关联的进程组 ID (pgid),会话 ID (sid),控制终端(tty)和进程 ID (pid)。
1. 进程组 ID(pgid):在 Linux 中,每个进程都被分配到一个进程组。进程组 ID 是用于识别一个进程组的数字,由进程组的首进程(通常是父进程)分配。进程可以通过 POSIX 系统调用 `setpgid()` 加入或创建一个进程组。
2. 会话 ID(sid):一个或多个进程可以组成一个会话,一个会话通过一个进程组来标识。会话 ID 是唯一标识一个会话的数字,由会话的首进程(通常是 Shell 或 X 窗口管理器)分配。会话 ID 可以通过函数 `getsid()` 来获取。
3. 控制终端(tty):控制终端是指用户与计算机进行交互所使用的终端。在一个会话中只有一个控制终端,它通常是通过 Shell 或 X 窗口管理器分配的。控制终端可以通过 POSIX 系统调用 `tcgetpgrp()` 和 `tcsetpgrp()` 来获取和设置。
4. 前台进程组 ID(tpgid):一个进程组可以拥有一个前台进程组的标识符。前台进程组是当前与控制终端进行交互的进程组。POSIX 系统调用 `tcgetpgrp()` 获取前台进程组 ID。
5. 用户 ID(uid):用户 ID 标识了进程的所有权所属的用户。
这些属性通常用于 Linux 中进行进程管理和控制,例如,可以向特定进程组中的所有进程发送信号,或者将一个进程放入后台。了解这些属性有助于更深入地了解 Linux 上的进程和进程组的工作原理。
上面的图是我还没有运行我写的code代码时的进程信息,它显示的是我们的grep进程的进程属性;下面我们运行我们的code代码让code进程开始运行;

还可以使用循环不断输出我们的进程属性信息
while : ; do ps axj|head -1&&ps axj|grep code ;sleep 1;done;
我们还可以通过top命令看到动态更新的进程表

上图就是我们的top命令展示的进程表
除去ps和top命令之外我们还可以使用我们的ls -l /proc来显示我们proc目录下的文件


fork创建子进程
我们先看一看下面这段代码,我们通过实例来了解我们的fork
#include<stdio.h>
#include<unistd.h>
int main()
{
int ret=fork();
if(ret==0)
while(1)
{
printf("I am child :pid=%d\n",getpid());
sleep(1);
}
else
while(1)
{
printf("I am father :pid=%d\n",getpid());
sleep(1);
}
return 0;
} 我们运行我们的可执行程序code可以发现:

我们的fork函数的作用就是创建子进程;当我们的进程调用了fork后我们的进程会产生一个子进程,这个子进程会和我们的父进程共享代码,代码运行产生的数据则各自开辟空间;
我现在只是了解了fork的用法,明白他可以创建一个子进程,剩下的知识我会慢慢学习在后面的博客中加以补充;
进程状态
我们的进程是我们的可执行程序在运行时将我们的代码加载到内存中形成我们的pcb结构体,这些结构体会被cup进行运算,这些结构体也会通过链表的形式形成队列;
新建:当进程开始加载到内存中形成他的结构体的时候,这个瞬时事件叫做新建
运行:当我们的进程结构体在我们的运行队列中排队时,这就是运行态
阻塞:当我们的进程正在等待非cpu资源就绪的时候,就叫做阻塞状态
挂起:当我们的运行内存不足时,操作系统通过将闲置的进程的代码和数据置换到磁盘上,等内存够了之后再拿回来,这叫做挂起;
上面的这些状态就是我们概念上的进程状态,也就是模板的意思,但是我们不同的操作系统对进程状态的命名是不一样的,他们会对标准进行实例化(这就和媒婆和是媒婆的王婆一样,王婆是媒婆,但媒婆指的是不同的这样的职业的人的统称)操作系统的进程状态也是一样的,我们的linux下的进程状态是下面这样的:
R 运行状态 0 :就和我们的模板的运行状态一样我们的进程处于我们的cpu运行队列中,这个状态就叫运行态;
S 睡眠状态 1 :就和模板中的阻塞态一样,我们的进程正在等待资源,这个状态又叫做可中断睡眠;
D 不可中断睡眠状态 2:这个状态也是类似阻塞态,只不过这个状态一般是我们的进程正在等待我们的磁盘或者某种资源正在处理我们的数据的时候,所以我们的进程没有在cpu状态中,而我们正在等待时如果被中断就会导致数据的丢失,为了防止数据的丢失,我们就会将这种进程状态设置成不可中断睡眠状态;
T 停止状态 4 :我们的进程在运行时我们可以主动发送信号让我们的进程停止运行,当进程停止时这种状态就叫做停止状态;(SIGTOP停止命令,SIGCONT继续运行命名);
t 调试状态 8 : 这种状态就是停止状态的一种在我们调试打断点,我们的程序运行到相应的断点处的时候,程序停止下来,这就是我们的调试状态;
X死亡状态 16:这种状态就是我们的程序的代码运行完了,我们的程序需要从内存中释放的时候,这是一个瞬时过程;
我们使用ps命名可以查看我们的进程状态

Z僵尸状态 32 :这个状态就是我们的进程的代码已经被运行完了,进程需要被释放的时候,需要释放它的进程没有释放它,这个状态就叫做僵尸状态;
一般这种状态是在我们的父进程创建了子进程,当子进程运行完毕之后,父进程没有回收子进程时,子进程所处的状态,这种状态其实就和我们C语言中的内存泄露类似,我们的进程运行完了,可是没有倍释放,所以这个进程的pcb结构体一直存在在内存中,结构体也是需要被维护的所以这就导致了资源的浪费,这就是僵尸进程的危害,所以我们在创建了子进程的时候需要注意回收进程;
小tip:我们进程状态后面跟着的数字,也就是在linux中这些进程状态可以使用这些数字来表示;
还有一种进程叫做孤儿进程:
这是创造出孤儿进程的代码;父进程先退出子进程还存在:
#include<stdlib.h>
#include<stdio.h>
#include<unistd.h>
int main()
{
int ret=fork();
if(ret>0)
{
printf("I am father :pid%d\n",getpid());
sleep(1);
exit(0);
}
else if(ret==0)
{
printf("I am child :pid=%d\n",getpid());
sleep(5);
}
return 0;
} 孤儿进程是指的我们的父进程先运行完了,先退出了,我们的子进程本来要被它的父进程释放的,可是父进程已经释放了,所以子进程无法被父进程释放了,这个时候我们的子进程也被称为孤儿进程,可是孤儿进程运行完也需要被释放,所以孤儿进程会被领养,由领养它的进程来释放它;一般是有1号进程init来领养的;

由图也可以证明这个结论是正确的;
进程优先级
为什么会有优先级这一概念呢?因为我们的资源是有限的,所以资源的分配是需要竞争的有竞争就会有先后;接下来,我们来看看进程的优先级是怎么样的;
我们首先介绍一下我们查看优先级的指标PRI和NI;PRI代表的是我们的优先级,PRI越小我们的优先级越高,PRI的默认值是80;我们的NI是用来调整我们的优先级的,我们的操作系统会自动对我们的优先级进行分配,但是如果我们用户自己相对优先级进行调整也是可以的,我们可以通过修改NI的值来修改优先级,NI的范围是-20到19,因为为了保护我们的操作系统,为了防止有程序恶意修改我们的优先级,所以我们的NI值也设置了范围,我们的优先级PRI=PRI(原本)+NI,可以说我们的NI就是我们优先级的修正值;
我们如何修改NI值
我们可以通过top指令进行top页面再输入r再输入进程的pid再输入nice值来修改我们的进程优先级;
拓展:
cpu是如何读取进程的?
我们的进程的结构体中的数据会被加载到我们cpu中的寄存器当中,寄存器包含了我们的进程中的临时数据,然后cpu对我们寄存器中的数据进行运算;
进程具有竞争性与独立性
我们的进程之间是需要抢占cpu,让cpu进行运算的,所以进程具有竞争性;而我们的进程之间是相互独立的,他们的数据都储存在各自的结构体当中,互不干扰;
并行
当我们的计算机有多个cpu时,那我们的运行队列也会有多个,那么我们的多个进程在不同的运行队列上运行,这种情况叫做并行;
并发
通俗的说这就是我们平时在使用手机的时候我们可以边听歌边打游戏,我们多个进程一起运行;其实看似我们的多个进程在同时运行,其实是多个进程在我们的cpu上交替运行,但是由于我们的cpu的计算速度超级快,所以我们看到的现象就是多个进程一起运行一样;而我们之前又说到了我们cpu读取进程是将进程上的临时数据加载到我们的cpu中的寄存器当中的,我们并发的时候,就是将寄存器中的数据不断拿出与放入我们的寄存器当中,使得数据不被丢失,进程轮流运行;














 6508
6508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









