







基础SQL语句
DDL (Data Definition Language,数据定义语言)
数据库操作
-- 查询所有数据库
show DATABASES;
-- 查询当前选择的数据库
select DATABASE();
-- 创建数据库
create database itcast;
create database if not exists itcast default charset utf8mb4 collate utf8mb4_general_ci;
-- 删除数据库
drop database if exists itcast;
-- 使用数据库
use itcast;
表操作
-- 查询当前数据库所有表
show tables;
-- 创建表
create table user (
id int comment 'id',
name varchar(128) comment '姓名',
age int comment '年龄'
) comment '用户表';
-- 删除表
drop table if exists user;
-- 删除表并重新创建
truncate table user;
-- 查看表结构
desc emp;
-- 查看表创建语句
show create table emp;
-- 添加表字段
alter table user add column sex char(1) comment '性别';
-- 删除表字段
alter table user drop sex;
-- 修改表字段类型
alter table user modify sex varchar(1);
-- 替换表字段
alter table user change sex user_sex char(1) comment '性别';
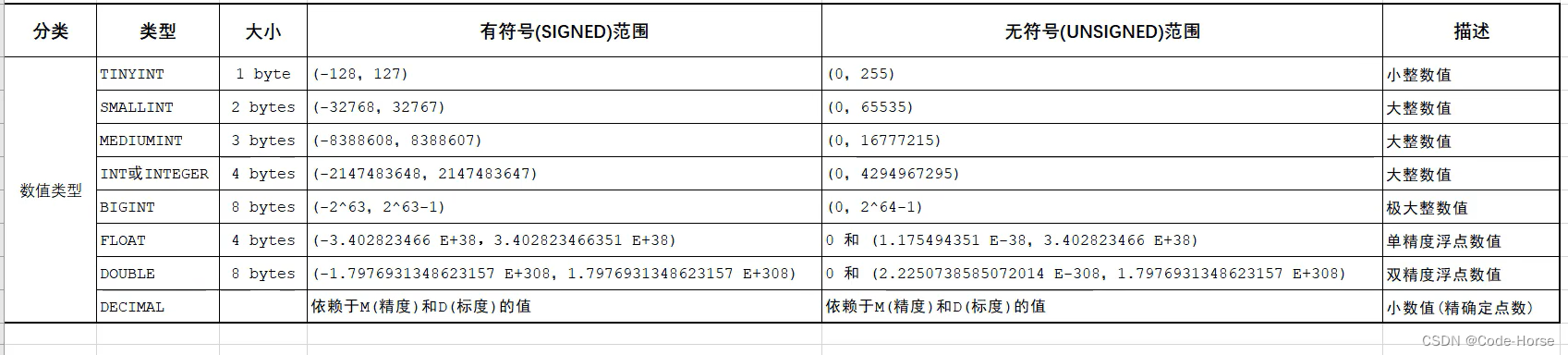
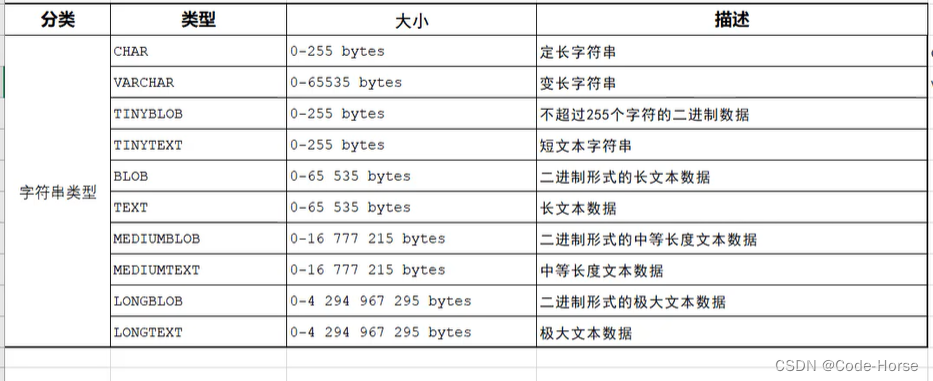
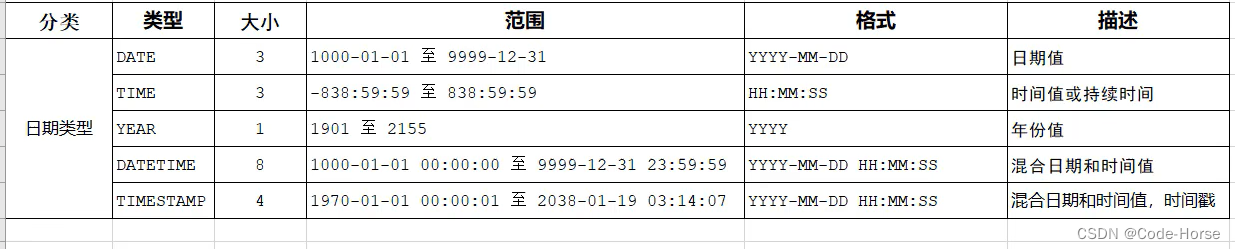
数据类型
DML(Data Manipulation Language,数据操作语言)
-- 插入数据1( 指定字段)
insert into user (id, name, age, sex) values(1, 'm', 18, '1');
-- 插入数据2(全字段插入可以不写指定字段)
insert into user values (2, 'q', 19, '0');
-- 插入数据3(批量插入数据)
insert into user values (3, 'a', 20, '1'), (4, 'b', 21, '0'), (5, 'c', 22, '1');
-- 修改数据
update user set name = 'code' where id = 1; -- 如果没有where条件,则修改整张表数据,慎重
-- 一条数据同时修改多个值
update user set name = 'horse', age = 17, sex = '1' where id = 1;
-- 删除数据
delete from user where id = 5; -- 没有where条件,则删除整张表数据
DQL (Data Query Language,数据查询语言)
select 基本查询
--
select * from user; -- 查询所有数据
select id, name, age, sex from user; -- 查询指定字段
-- 查询到的数据起别名:as 或 空格
select id as user_id, name user_name from user;
-- 去除重复数据
select distinct age from user;
where 条件查询
-- > 大于
select * from user where age > 18
-- >= 大于等于
select * from user where age >= 18;
-- < 小于
select * from user where age < 18;
-- <= 小于等于
select * from user where age <= 18;
-- = 等于
select * from user where age = 18;
-- <> 或 != 不等于
select * from user where age <> 18;
select * from user where age != 18;
-- BETWEEN ... AND ... 在某个范围之内(含最小、最大值)
select * from user where age between 18 and 26;
-- IN(...) 在in之后的列表中的值,多选一
select * from user where age in (18, 20, 22);
-- LIKE 占位符 模糊匹配( _:匹配单个字符, %: 匹配任意个字符)
select * from user where name like '_'; -- 名字为任意一个字母
select * from user where name like '%a%' -- 名字含有a的;
-- 判断是否为null:is null
select * from user where name is null;
-- 判断不是null:is not null
select * from user where name is not null;
-- 多个条件使用 and 和 or 隔开
select * from user where age > 18 and age < 25; -- 18 < age < 25
select * from user where age = 18 or age = 25; -- age只能取到 18 或 25
聚合函数
注意:null值不参与聚合函数的运算。
-- count 统计数量
select count(*) from user;
-- max 最大值
select max(age) from user;
-- min 最小值
select min(age) from user;
-- avg 平均值
select avg(age) from user;
-- sum 求和
select sum(age) from user;
group by 分组查询
-- 根据性别分组 , 统计男性用户 和 女性用户的数量
select sex, count(sex) from user group by sex;
-- 根据性别分组 , 统计男性用户 和 女性用户的平均年龄
select sex, avg(age) from user group by sex;
-- 查询年龄小于30的用户 , 并根据性别分组 , 要求分组后数据量大于等于1才展示出来
select sex, count(*) '数据量' from user where id <= 30 group by sex having count('数据量') >= 1;
order by 排序查询:asc(升序,默认)、desc(降序)
-- 根据年龄升序排序
select * from user order by age asc; -- asc可以省略
select * from user order by age;
-- 根据年龄降序排序
select * from user order by age desc;
-- 根据年龄降序排序,如果相同则按照id升序排序
select * from user order by age desc, id asc;
limit 分页查询
分页查询索引从0开始
起始索引 = (当前页码 - 1)* 每页展示数
-- 查询第1页用户数据, 每页展示10条记录
select * from user limit 0, 10;
select * from user limit 10; -- 第一页的起始索引(0)开始省略
-- 查询第2页用户数据
-- 起始索引 = (当前页码 - 1)* 每页展示数 = (2 - 1) * 10 = 10
select * from user limit 10, 10;
DQL的执行顺序
执行顺序:from -> where -> group by -> having -> select -> order by -> limit
理解如下:
1. 先找到表 (from)
2. 数据条件限定 (where)
3. 将数据进行分组 (group by)
4. 分组后的数据条件限定 (having)
5. 挑选展示字段 (select)
6. 数据排序 (order by)
7. 跳过条数和展示条数 (limit)
-- DQL的基础语法
select
字段列表
from
表名列表
where
条件列表
group by
分组字段列表
having
分组后条件列表
order by
排序字段列表
limit
分页参数
DCL (Data Control Language,数据控制语言)
管理用户
-- 查询用户
select * from mysql.user; -- 当前库的所有用户
-- 创建用户
create user 'myuser'@'localhost' identified by '123456'; -- localhost本地用户登录
create user 'myuser'@'%' identified by '123456'; -- % 远程用户登录
-- 修改用户密码
alter user 'myuser'@'localhost' identified with mysql_native_password by '123';
-- 删除用户
drop user 'myuser'@'localhost';
权限控制
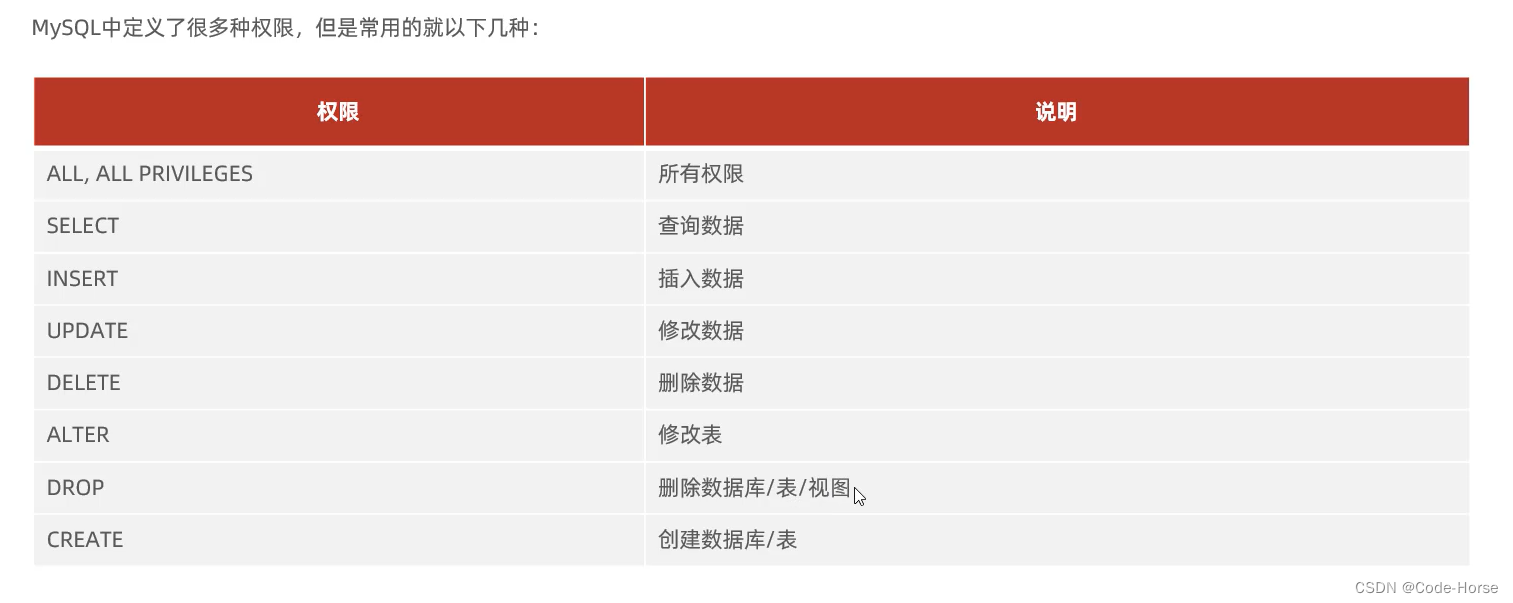
-- 查询用户权限
show grants for 'myuser'@'localhost';
-- 授予用户权限
grant select, update on itcast.* to 'myuser'@'localhost'; -- 授予指定权限
grant all on *.* to 'myuser'@'localhost'; -- 授予用户 所有库和表的所有权限
-- 撤销用户权限
revoke update on itcast.* FROM 'myuser'@'localhost'; -- 撤销指定权限
revoke all on *.* from 'myuser'@'localhost'; -- 撤销所有权限
如报错:Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation。 解决方案:执行 grant system_user on *.* to 'root';
常用函数
字符串函数
-- concat(S1, S2, ..., Sn) 字符串拼接,将S1,S2,... Sn拼接成一个字符串
select concat('a', 'b', 'c'); -- abc
-- lower(str) 将字符串str全部转为小写
select lower('aBC'); -- abc
-- upper(str) 将字符串str全部转为大写
select upper('aBc'); -- ABC
-- lpad(str, n, pad)左填充,用字符串pad对str的左边进行填充,达到n个字符串长度
select lpad('89', 5, '0'); -- 00089
-- rpad(str,n,pad) 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度
select rpad('89', 5, '0'); -- 89000
-- trim(str) 去掉字符串头部和尾部的空格
select trim(' xx '); -- xx;
-- substring(str, start, len) 返回从字符串str从start位置起的len个长度的字符串(索引从1开始)
select substring('abcdefg',3, 3); -- cde
数值函数
-- ceil(x) 向上取整
select ceil(1.1); -- 2
-- floor(x) 向下取整
select floor(1.7); -- 1
-- mod(x,y) 返回x % y
select mod(9, 3); -- 0
-- rand() 返回0~1内的随机数
select rand(); -- 随机数 0.16639879640787728
-- round(x,y) 求x的四舍五入,保留y位小数
select round(1.37, 1); -- 1.4
日期函数
-- CURDATE() 返回当前日期
select curdate(); -- 2023-10-05
-- CURTIME() 返回当前时间
select curtime(); -- 03:45:23
-- NOW() 返回当前日期和时间
select now(); -- 2023-10-05 03:45:55
-- YEAR(date) 获取指定date的年份
select year('2023-10-05'); -- 2023
select year(now()); -- 2023
-- MONTH(date) 获取指定date的月份
select month(now()); -- 10;
-- DAY(date) 获取指定date的日期
select day(now()); -- 5
-- DATE_ADD(date, INTERVAL xx exprtype) 返回一个日期/时间值加上一个时间间隔xx expr后的时间值
-- exprtype = {year, month, day, hour, minute, second}
select date_add('2023-10-05 03:45:55', interval 1 year); -- 2024-10-05 03:45:55
select date_add('2023-10-05 03:45:55', interval 1 minute); -- 2023-10-05 03:46:55
-- DATEDIFF(date1,date2) 返回date1 - date2的天数
select datediff('2023-10-05', '2023-10-01');
流程函数
-- if(value , a , b) 如果value为true,则返回a,否则返回b
select if (true, 'a', 'b'); -- a
select if (false, 'a', 'b'); -- b
-- ifnull(value1 , value2) 如果value1不为空,返回value1,否则返回value2
select ifnull('value1', 'value2'); -- value1
select ifnull(null, 'value2'); -- value2
-- case when then 语句
-- 写法1:
select
name, (case sex when '0' then '女' when '1' then '男' else '未知' end) as '性别'
from user;
-- 写法2:表达式判断
select
name, (case when age < 18 then '未成年' when age > 18 then '成年' else '未知' end) as '是否成年'
from user;
约束
not null:非空约束,限制该字段的数据不能为null。
unique:唯一约束,保证该字段的所有数据都是唯一、不重复的。
primary key:主键约束,主键是一行数据的唯一标识,要求非空且唯一。
default: 默认约束 保存数据时,如果未指定该字段的值,则采用默认值。
check:检查约束(8.0.16版本之后)保证字段值满足某一个条件。
foreign key:外键约束用来让两张表的数据之间建立连接,保证数据的一致性和完整性。同一个数据库中的外键约束名称不能重复,否则会报错
-- 创建表时添加约束
create table user_info(
id int primary key auto_increment comment '主键(非空唯一)id,自增', -- 主键约束
username varchar(255) not null unique comment '用户名,非空唯一', -- 非空约束、唯一约束
status tinyint default 1 comment '用户状态,默认1激活,0禁用', -- 默认约束
age int check (age >= 0 and age <= 200) comment '年龄,必须 >= 0', -- 检查约束
user_id int not null comment '用户外键',
constraint fk_info_user_id foreign key (user_id) references user(id) -- 外键约束
);
-- 删除约束
alter table user_info drop foreign key fk_info_user_id;
-- 添加约束
alter table user_info add constraint fk_info_user_id foreign key (user_id) references user(id);
添加约束前需要注意数据是否已经满足约束,不然会添加失败。:Check constraint 'stu_info_chk_2' is violated.
外键的删除/更新行为

-- 添加外键时设置更新和删除行为
alter table user_info
add constraint fk_info_user_id foreign key (user_id) references user(id)
on update cascade
on delete cascade;
多表查询
笛卡尔积: 笛卡尔乘积是指在数学中,集合A和集合B的所有组合情况(A个数*B个数)。
多表关系
一对一:只需要在任意一方加入外键。
一对多:在多的一方加入外键。
多对多:通过中间表建立双方的外键。
多表查询的分类
分类:内连接、外连接、自连接。

内连接
内连接:两个表的交集部分
-- 隐式内连接
select e.name, d.name from emp e, dept d where e.dept_id = d.id;
-- 显式内连接
select e.name, d.name from emp e join dept d on e.dept_id = d.id;
外连接
左外连接:左表所有数据且包含两个表的交集部分。
右外连接:右表所有数据且包含两个表的交集部分。
-- 左外连接 left outer join
select e.name, d.name from emp e left outer join dept d on e.dept_id = d.id;
-- 右外连接 right outer join
select d.name, e.name from emp e right outer join dept d on e.dept_id = d.id;
自连接
-- 自连接(内连接)
select a.name, b.name from emp a, emp b where a.managerid = b.id; -- a和b的交集
-- 自连接(外连接)
select a.name, b.name from emp a left outer join emp b on a.managerid = b.id; -- a的所有数据且包含a和b的交集
联合查询 union,union all
union all:将两个查询结果直接合并
union:将两个查询结果去重合并
-- union all合并
select * from emp where salary < 5000 -- 注意这里别加分号;这是一条语句
union all
select * from emp where age > 50;
-- union合并去重
select * from emp where salary < 5000
union
select * from emp where age > 50;
注意:对于联合查询的字段列数和类型必须保持一致。
子查询(嵌套查询)




-- 标量子查询:子查询的数据为一个值
-- 查询销售部的所有员工信息
select * from emp e where e.dept_id = (select id from dept where name = '销售部');
-- 列子查询:子查询的数据为一列的
-- 查询销售部和财务部的所有员工信息
select * from emp e where e.dept_id in (select id from dept where name = '销售部' or name = '财务部');
-- 行子查询:子查询的数据为一行的
-- 查询与 "张无忌" 的薪资及直属领导相同的员工信息
select * from emp where (salary, managerid) = (select salary, managerid from emp where name = '张无忌');
-- 表子查询:子查询的数据为多行多列的
-- 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job, salary) in (select job, salary from emp where name = '鹿杖客' or name = '宋远桥');
exists / not exists 相关子查询
exists:查找主集和子集至少存在一个交集
not exists:主集和子集没有交集
-- exists
-- 查找所有至少有一个订单的客户
SELECT * FROM Customers
WHERE EXISTS (SELECT * FROM Orders WHERE orders.customer_id = customers.customer_id);
-- 查询有选修成绩不及格的学生的的学号,姓名,性别,年龄及班级号。
SELECT s_id, s_name, sex, age, class_id
FROM stu_info
WHERE EXISTS (
SELECT *
FROM stu_score
WHERE stu_info.`s_id` = stu_score.`s_id`
AND score < 60 -- 返回当前学生选修课至少存在一门小于60分的集合
)
-- not exists
-- 查找没有下订单的所有客户
SELECT * FROM Customers
WHERE NOT EXISTS (SELECT * FROM Orders WHERE orders.customer_id = customers.customer_id);
-- 查询选修了课程表中所有课程的学生信息
select *
from stu_info
where not exists (
select *
from course
where not exists ( -- 不存在课程没有被选中的情况(空集) = 全选
select *
from stu_score
where course.c_id = stu_score.c_id
and stu_score.s_id = stu_info.s_id
)
);
事务 transaction
事务操作
-- 方法1:查看/设置事务提交方式
select @@autocommit; -- 1为自动提交,0为手动提交
set @@autocommit = 0; -- 设置手动提交事务
-- 方法2:显式开启事务 begin、 start transaction
-- 以下两种显示写法
begin; -- 手动开启事务
start transaction; -- 手动开启事务
-- 提交事务,所有sql顺利完成可以提交事务
commit;
-- 回滚事务,中途如果遇到问题,就需要执行回滚
rollback;
注意:一旦开启了事务,除非提交事务,否则即使数据发生了改变也无法看到数据的变化。
事务的四大特性(ACID)
原子性(Atomicity):事务是不可分割的最小操作单位,要么全部成功,要么全部失败。一致性(Consistency):事务完成时,必须使所有的数据都保持一致的状态(不管提交还是回滚,数据是恒定的,不能说执行完sql后,数据比执行完sql多了或者少了值)。隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(事务A和事务B互不干扰,都是独立的)。持久性(Durability):事务一旦提交事务或回滚,它对数据库中的数据的改变是永久的。
事务的并发问题
脏读:一个事务读取到另外一个事务还没有提交的数据。不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。幻读:一个事务按照条件查询数据时,没有查到对应的数据行,但是在插入数据时,又发现了这行数据已经存在了,就好像出现了"幻觉"一样。
事务的隔离级别
Read uncommitted(读未提交)、Read committed(读已提交)、Repeatable Read(可重复读)、Serializable(串行化)
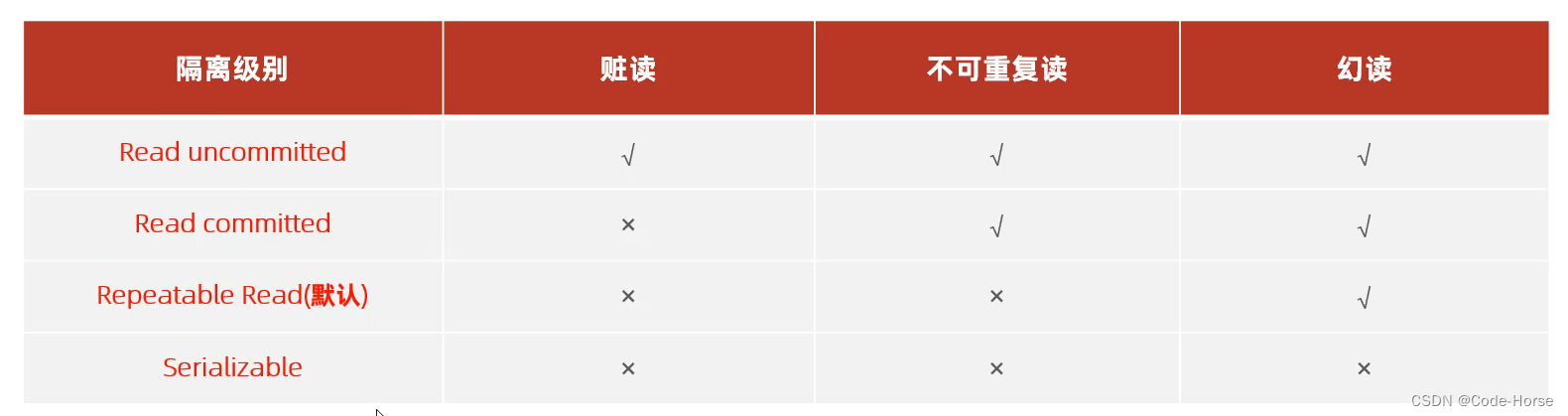
-- 查看事务隔离级别
select @@transaction_isolation;
-- 设置事务隔离级别
set session transaction isolation level read uncommitted; -- 设置当前会话隔离级别
set global transaction isolation level read uncommitted; -- 设置全局隔离级别
隔离级别越高,数据越安全,但是性能就越差。
存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。
存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
我们可以在创建表的时候,来指定选择的存储引擎,如果没有指定将自动选择默认的存储引擎。
-- 显示当前数据库(表)所支持的存储引擎
show engines;
-- 创建表时指定存储引擎
create table xx (
)engine=InnoDb;
InnoDB
介绍:InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在MySQL5.5之后,InnoDB是默认MySQL存储引擎。
特点:(事务,行级锁,外键)
- DML操作遵循ACID模型,支持事务。
- 行级锁,提高并发访问性能。
- 支持外键foreign key约束,保证数据的完整性和正确性。
文件:
每个表基本对应一个 表空间文件.ibd文件(innodb data),存储该表的表结构(frm-早期的 、sdi-新版的)、数据和索引。
-- 查看是否每一张表对应一个表空间文件
show variables like 'innodb_file_per_table'; -- 默认ON开启
可以使用终端执行:ibd2sdi xx.ibd查看存储结构
InnoDB的存储结构: 表空间文件 > 段 > 区 > 页 > 行
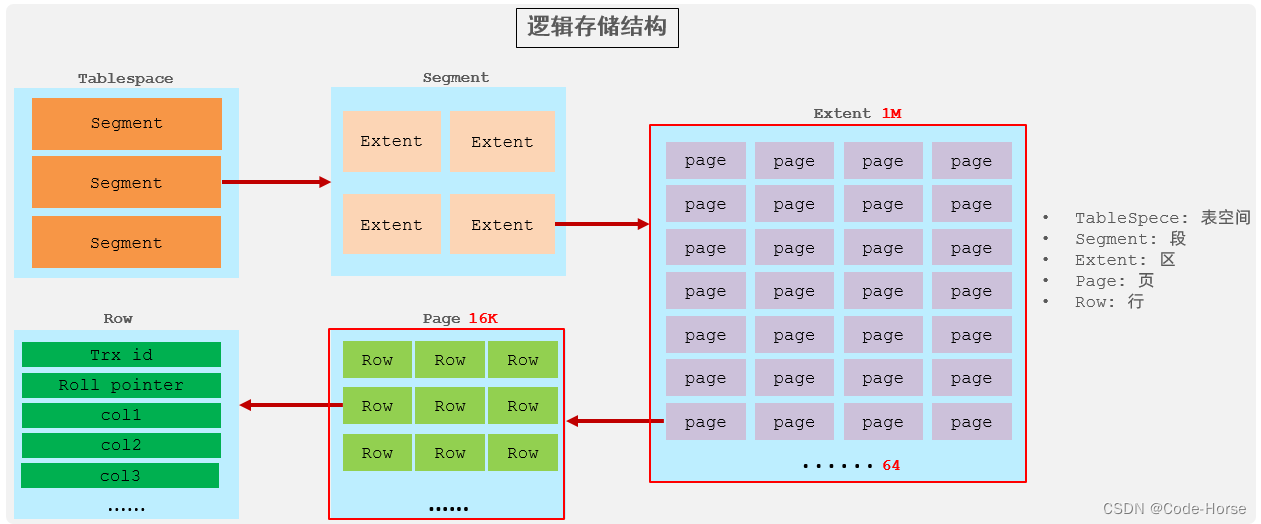
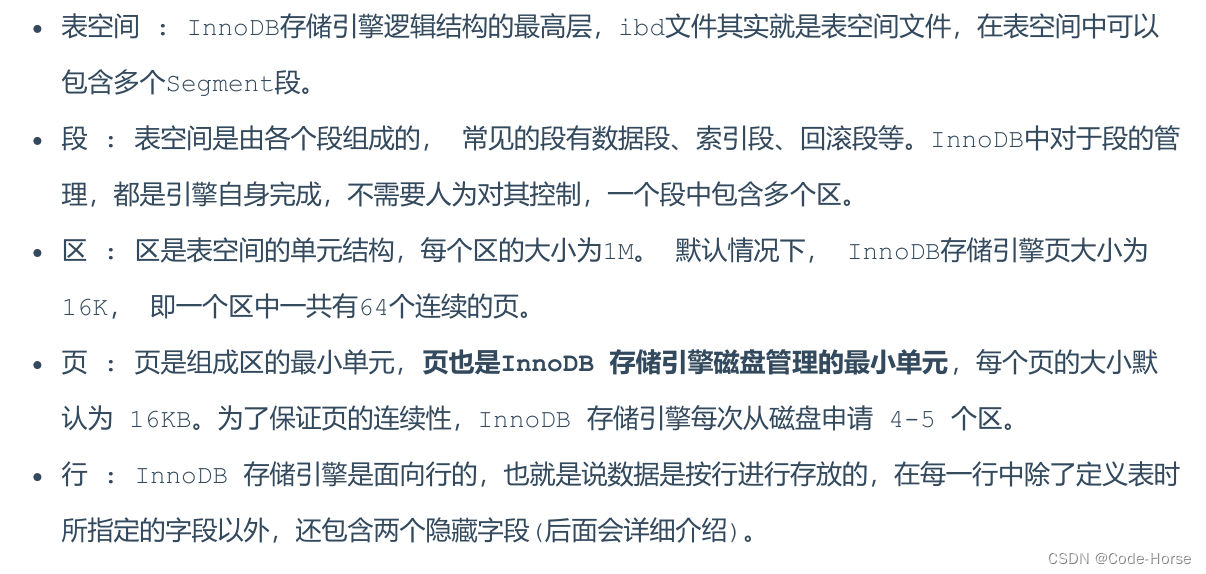
MyISAM
介绍:MyISAM是MySQL早期的默认引擎。
特点:
- 不支持事务,不支持外键。
- 支持表锁,不支持行锁。
- 访问速度快。
文件:
xxx.sdi:存储表结构信息(早期是.frm)
xxx.myd (myisam data):存储数据
xxx.myi (myisam index):存储索引
MEMORY
介绍:Memory引擎的表数据是存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
特点:
- 内存存放
- hash索引(默认)
文件:
xxx.sdi;
区别及特点
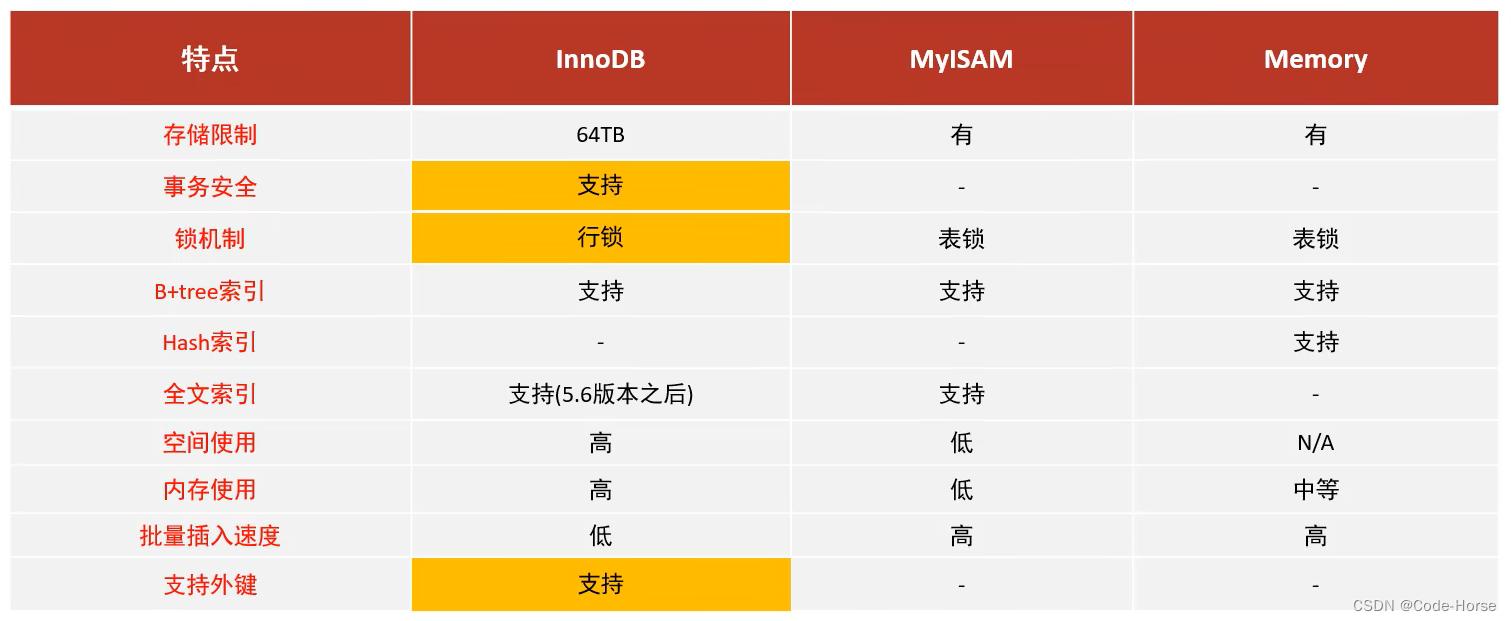
存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择
多种存储引擎进行组合。
-
InnoDB:是MySQL的默认存储引擎,支持事务,外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB是比较合适的选择。(常用) -
MyISAM:如果应用是以读操作和插入操作为住,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。 -
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
MyISAM (对标MongoDB) 和 MEMORY (对标Redis) 将会被NoSql取代。
索引
索引概述
介绍:索引(index)是帮助Mysql高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,
这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低cpu的消耗。
缺点:
- 索引列也是要占用空间的。
- 索引大大提高了查询效率,同时却也降低了更新表的速度,如对表进行insert,update,delete时,效率降低。
索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
-
B+Tree索引:最常见的索引类型,大部分引擎都支持B+树索引。(支持的引擎:InnoDB, MyISAM, Memory)
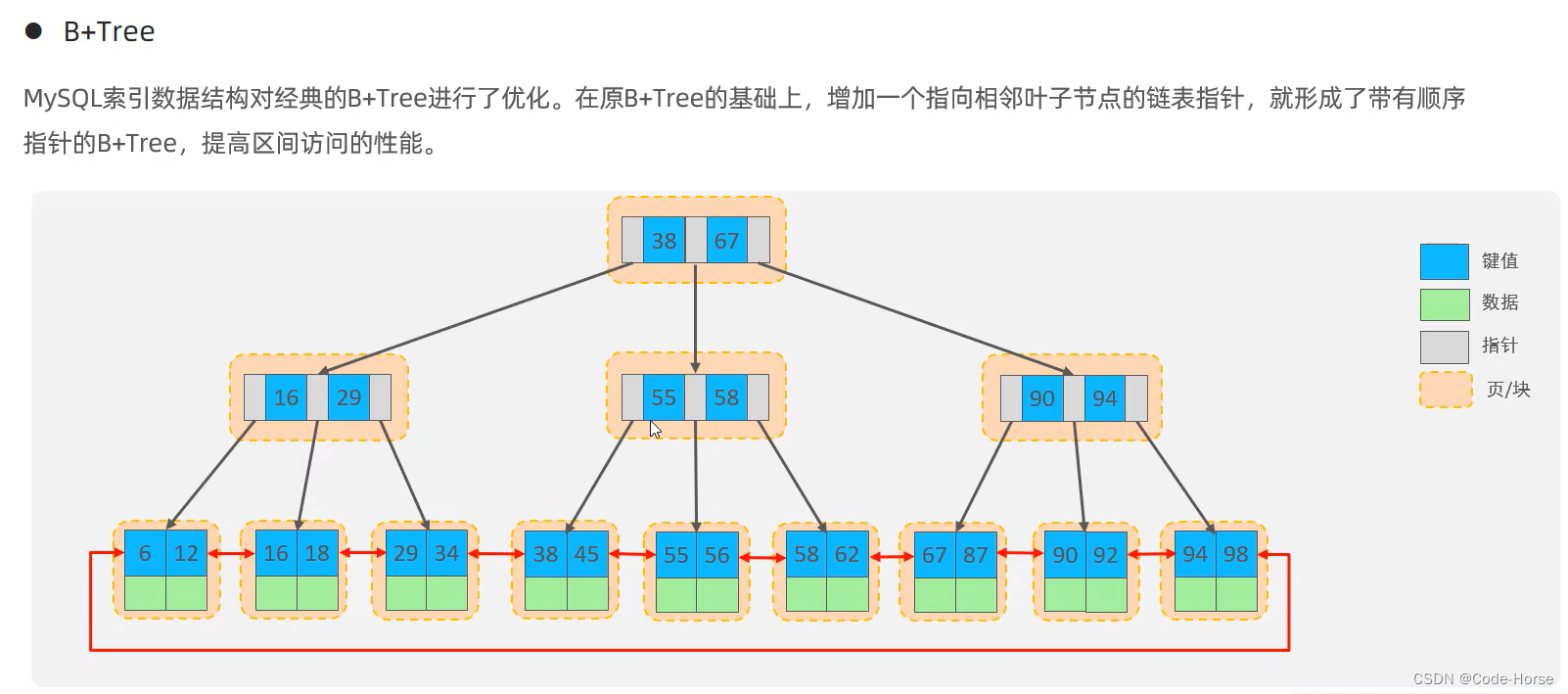
-
Hash索引:底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询。(支持的引擎:Memory)
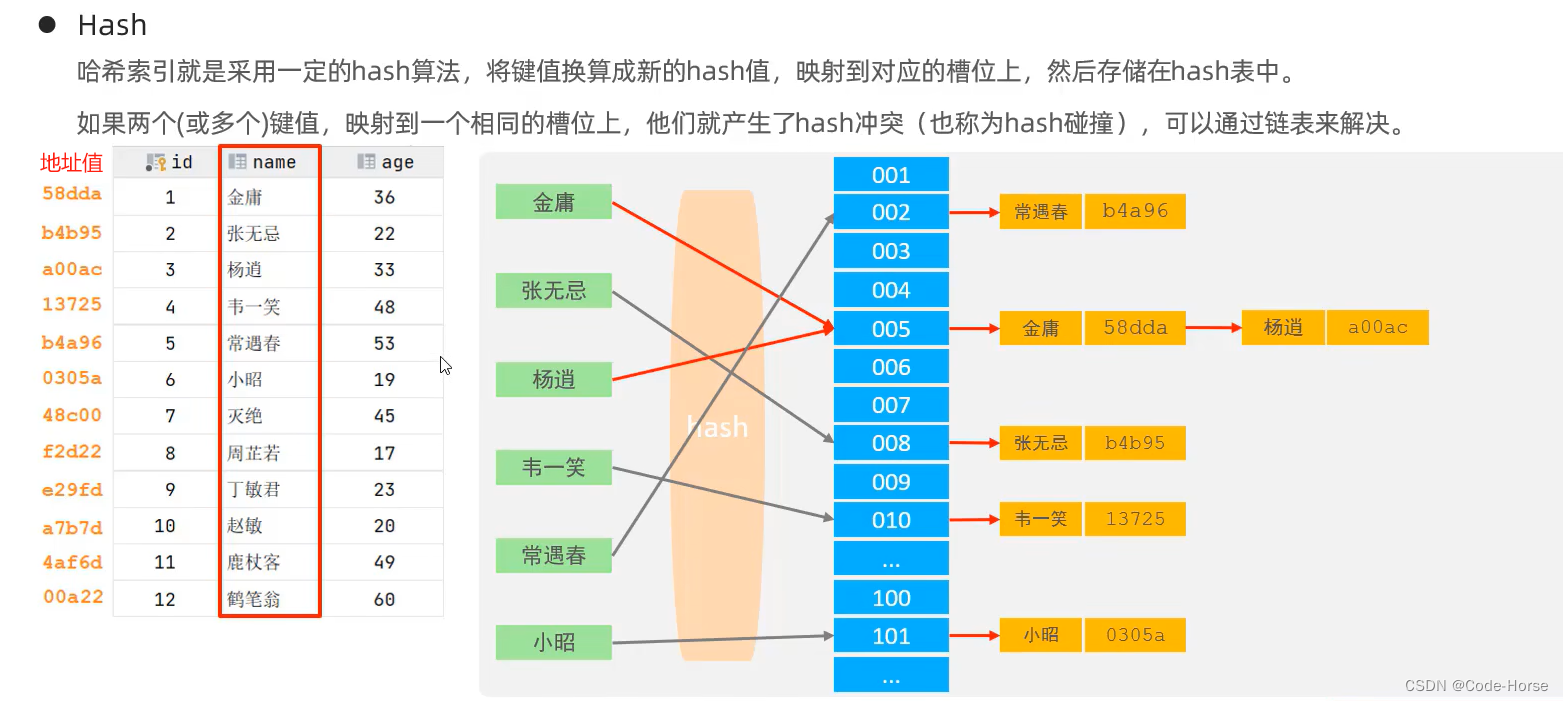

-
R-tree(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。(支持的引擎:MyISAM) -
Full-test(全文索引):是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES。(支持的引擎:5.6以后的InnoDB, MyISAM)
索引分类
主键索引
含义:针对表中主键创建的索引。
特点:默认自动创建,只能有一个。
关键字:primary。唯一索引
含义:避免同一个表中某数据列中的值重复。
特点:可以有多个。
关键字:unique常规索引
含义:快速定位特定数据。
特点:可以有多个。
关键字:全文索引
含义:全文索引查找的是文本中的关键词,而不是比较索引中的值。
特点:可以有多个
关键字:fulltext
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
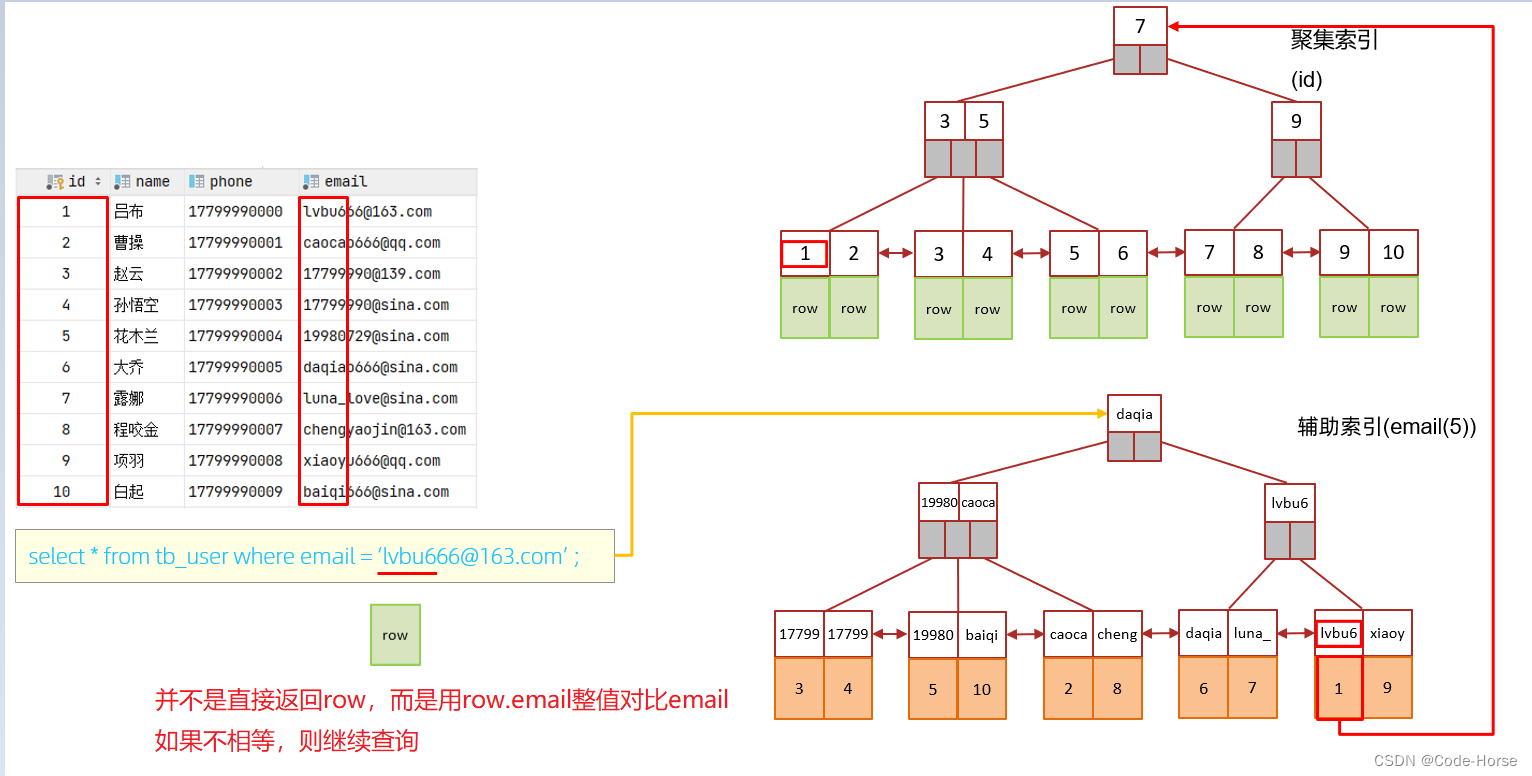
聚集索引(Clustered Index)
含义:将数据存与索引放到了一块,索引结构的叶子节点保存了行数据
特点:必须有,而且只有一个二级索引(Secondary Index)
含义:将数据存与索引分开存储,索引结构的叶子节点关联的是对应的主键值
特点:可以存多个
聚集索引选取的规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(unique)索引作为聚集索引。
- 如果不存在主键或没有合适的唯一索引,则InnoDB将会自动生成一个rowid作为隐藏的聚集索引。
二级索引的使用(回表查询):通过二级索引查找出的主键值,然后使用主键通过聚集索引拿到行数据;这个过程叫做回表查询。
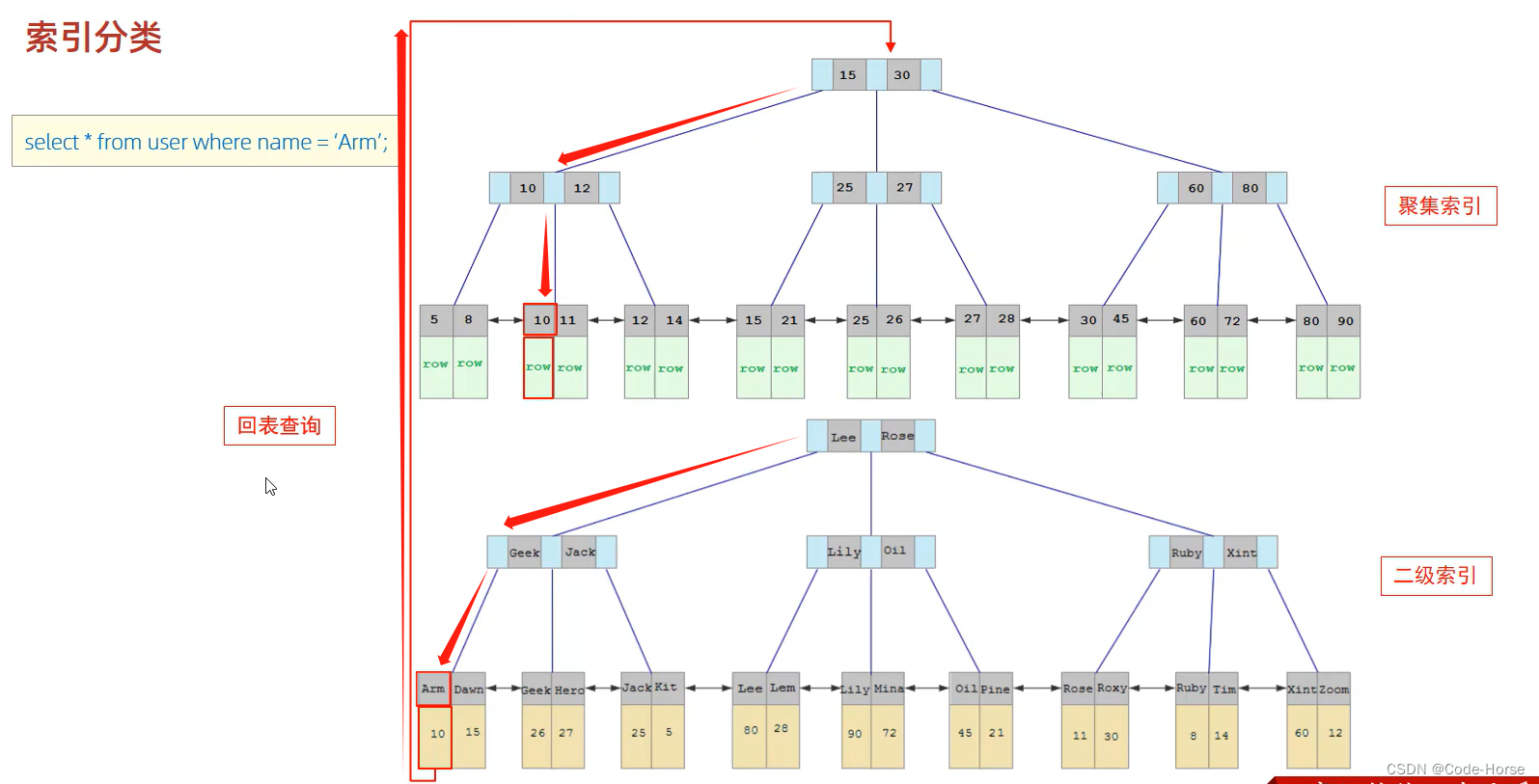
索引语法
-- 查看索引
show index from tb_user;
-- 创建索引
create index idx_name on tb_user(name); -- 常规索引
create unique index idx_phone on tb_user(phone) -- 唯一索引
create index idx_pro_age_sta on tb_user(profession, age, status); -- 联合索引
-- 删除索引
drop index idx_email on tb_user;
SQL性能分析
SQL的执行频率
mysql客户端连接成功后,通过show[session|global] status命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的insert,update,delete,select的访问频次
-- 查看当前服务器增删改查的频率
show global status like 'Com_______';
慢查询日志
-- 查看是否开启了慢查询,还有存储的日志的路径
show variables like 'slow_query%';

开启慢查询需要配置my.cnf文件,一般路径在/etc/mysql/my.cnf,如找不到则百度
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
重启发现报错,可以看看my.cnf文件开头有没有 [mysqld]
profile 执行详情
-- 查看当前mysql是否支持profile操作, YES支持,NO不支持
select @@have_profiling;
-- 设置profile
set global profiling = 1;
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query 138;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query 182;
explain 分析执行计划
-- explain + select语句
explain select * from user where id= 1;

索引的使用原则
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃了某一列,索引将部分失效(后面的索引字段失效)。
-- 查到有联合索引idx_pro_age_sta, 顺序为:profession, age, status
show index from tb_user;
-- 以下情况都经过索引
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0'; -- key_len = 54
explain select * from tb_user where profession = '软件工程' and age = 31; -- key_len = 49
explain select * from tb_user where profession = '软件工程'; -- key_len = 47
-- 由上推出索引长度:profession = 47, age = 2, status = 5
-- 索引失效,由于跳过了profession,不满足最左前缀法则
explain select * from tb_user where age = 31 and status = '0';
explain select * from tb_user where status = '0';
-- 只走了profession的索引,跳过了age索引,status索引失效
explain select * from tb_user where profession = '软件工程' and status = '0'; -- key_len=47
-- 最左前缀法则和where顺序无关,顺序是建立索引时确定的,和条件判断时出现的字段有关。
explain select * from tb_user where age = 31 and status = '0' and profession = '软件工程'; -- 经过索引,key_len=54
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。(>=和<=不会索引失效)
-- 只走了profession索引,age用了>导致索引失效,则status也失效
explain select * from tb_user where profession = '软件工程' and age > 30 and status = '0' -- key_len=49
-- age使用>=时,经过联合索引
explain select * from tb_user where profession = '软件工程' and age >= 30 and status = '0'; -- key_len=57
索引失效情况
-- 1. 索引列运算,导致索引失效
explain select * from tb_user where substring(phone,10,2) = '15'; -- 不走索引
-- 2. 字符串字段不加引号,导致索引失效
explain select * from tb_user where phone = '17799990000'; -- 走索引
explain select * from tb_user where status = 17799990000; -- 不走索引
-- 3. like模糊查询:如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
explain select * from tb_user where profession like '软件%'; -- 走索引
explain select * from tb_user where profession like '%软件'; -- 不走索引
-- 4. or连接条件:如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select * from tb_user where id = 10 or age = 23; -- 由于age没有索引,则整个or都不会走索引
create index idx_age on tb_user(age); -- 建立age索引
explain select * from tb_user where id = 10 or age = 23; -- 走索引,因为age已经建立索引
-- 5. 数据分布情况决定走全表还是走索引:如果Mysql评估使用索引比全表更慢,则不适用索引。
explain select * from tb_user where phone >= '17799990005'; -- 数据占全表大部分,走了all
explain select * from tb_user where phone >= '17799990020'; -- 数据占全表的少量,走索引
SQL提示
-- use index 指定使用索引
explain select * from tb_user use index(idx_pro) where profession = '软件工程'; -- 建议mysql走idx_pro索引
-- ignore index 排除指定索引
explain select * from tb_user ignore index(idx_pro) where profession = '软件工程'; -- 排除idx_pro索引
-- force index 强制走指定索引
explain select * from tb_user force index(idx_pro) where profession = '软件工程'; -- 强制mysql走idx_pro索引
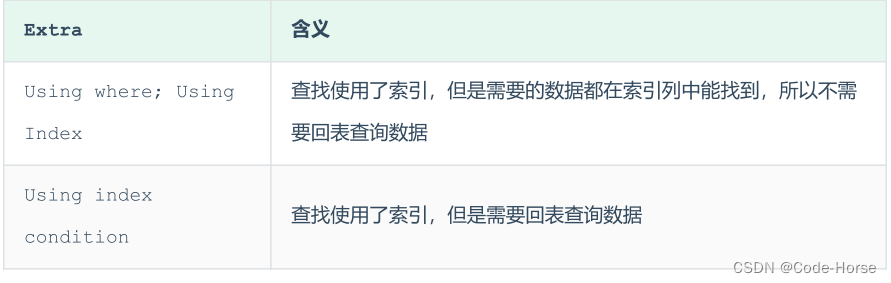
要盖索引 & 避免回表查询
尽量使用覆盖索引,减少select * 查询。
因为在查询使用了索引,并且返回需要的列,在索引叶子节点中或者叶子节点关联值已经全部能够找到。如果没有找到则会回表查询。
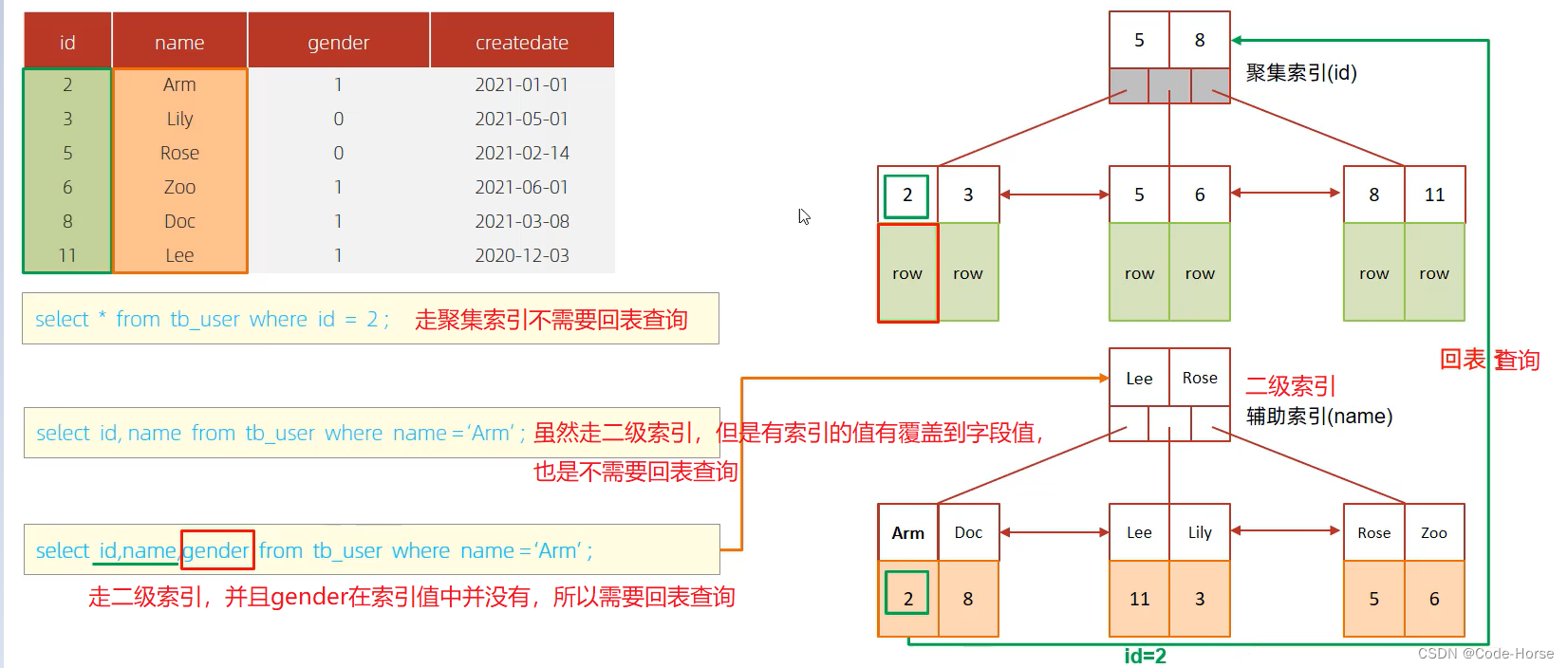
-- 字段值在索引叶子节点中或者叶子节点关联值中,无需回表查询
explain select id, profession,age, status from tb_user where profession = '软件工程' and age = 31 and status = '0' ; -- Using where; Using index
-- 字段值不在索引叶子节点中或者叶子节点关联值中,需要回表查询
explain select id, name from tb_user where profession = '软件工程' and age = 31 and status = '0'; -- Using index condition
前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让
索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建
立索引,这样可以大大节约索引空间,从而提高索引效率。
-- 前缀长度:可以根据索引的选择性来决定
-- 不重复的索引值(基数)/ 数据表的记录总数
select count(distinct substring(email,1,5)) / count(*) from tb_user; -- 0.9583, 越高越好
select count(distinct substring(email,1,4)) / count(*) from tb_user; -- 0.9167
-- 创建前缀长度
create index idx_email_5 on tb_user(email(5));
单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
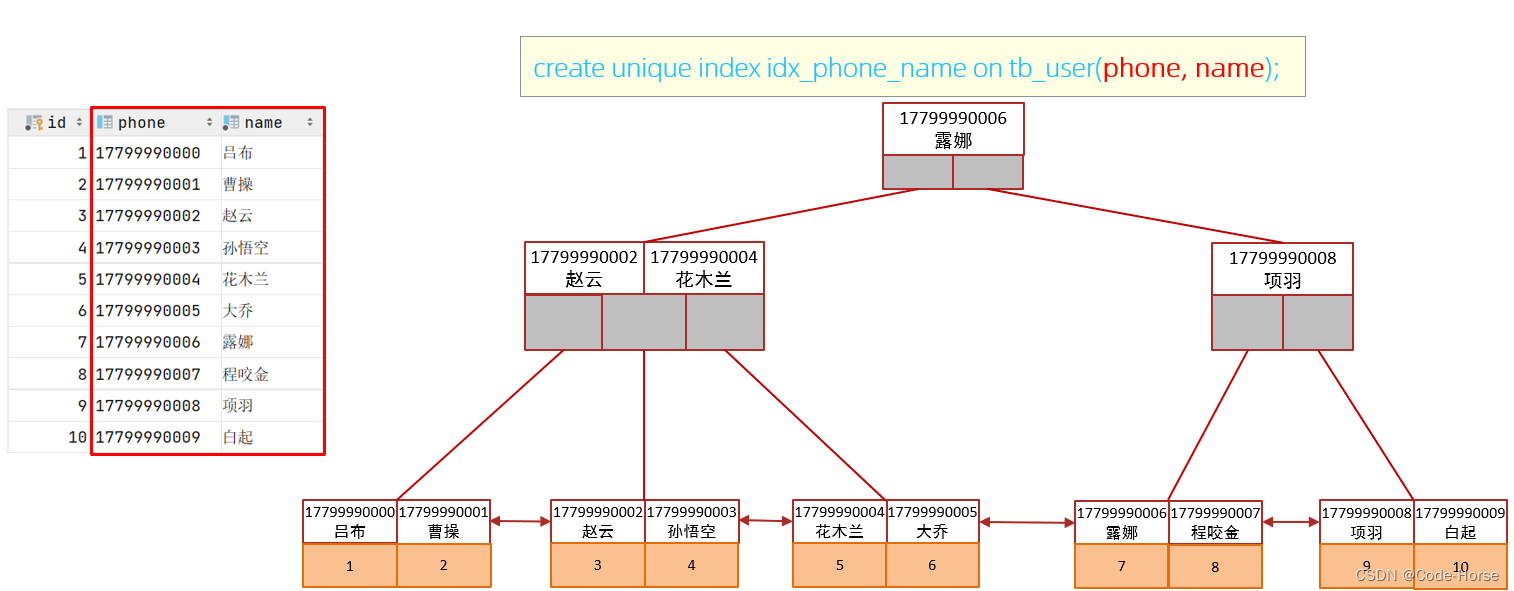
-- possible_keys:idx_phone,idx_name, key:idx_phone,mysql根据查询情况实际走了phone的索引
-- 索引信息不包括name值,所以需要回表查询
explain select id, name, phone from tb_user where phone = '17799990000' and name = '吕布';
-- 建立联合索引
create index idx_phone_name on tb_user(phone, name);
-- 使用联合索引
explain select id, name, phone from tb_user use index (idx_phone_name) where phone = '17799990000' and name = '吕布';
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,
而非单列索引。
索引设计原则
- 针对于数据量比较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- 尽量使用区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度越长,可针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用not null约束它。当优化器知道每列是否包含null值时,它可以更好地确认哪个索引最有效地用于查询。
SQL优化
insert优化
-- 1. 批量插入(推荐一次插入不超过1000条,如果超过可以分割成多条sql)
insert into tb_test values(...),(...),(...);
-- 2. 手动事务提交(不然每次插入后自动提交事务,费时间)
start transaction;
insert into tb_test values(...);
insert into tb_test values(...);
insert into tb_test values(...);
commit;
-- 3. 主键顺序插入:主键顺序插入会比乱序插入快
-- 主键乱序插入: 3 1 2 88 4
-- 主键顺序插入:1 2 3 4 88
-- 4. 大批量插入数据(如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用mysql数据库提供的load data指令进行插入,[假设表结构为id,name,age])新建文件load_user_100w_sort.sql内容如下
/*
1,codehorse,18
2,mjq,19
...此处省略2000w数据
*/
-- 客户端连接服务端时,加上参数 --local-infile。告诉服务端需要加载本地文件
mysql --local-infile -u root -p
-- 查看local_infile是否开启, ON开,OFF关
show variables like 'local_infile';
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中(注意:windows下文本换行符为'\r\n')
load data local infile '/root/load_user_100w_sort.sql'
into table tb_user
fields terminated by ','
lines terminated by '\n';
主键优化
页分裂
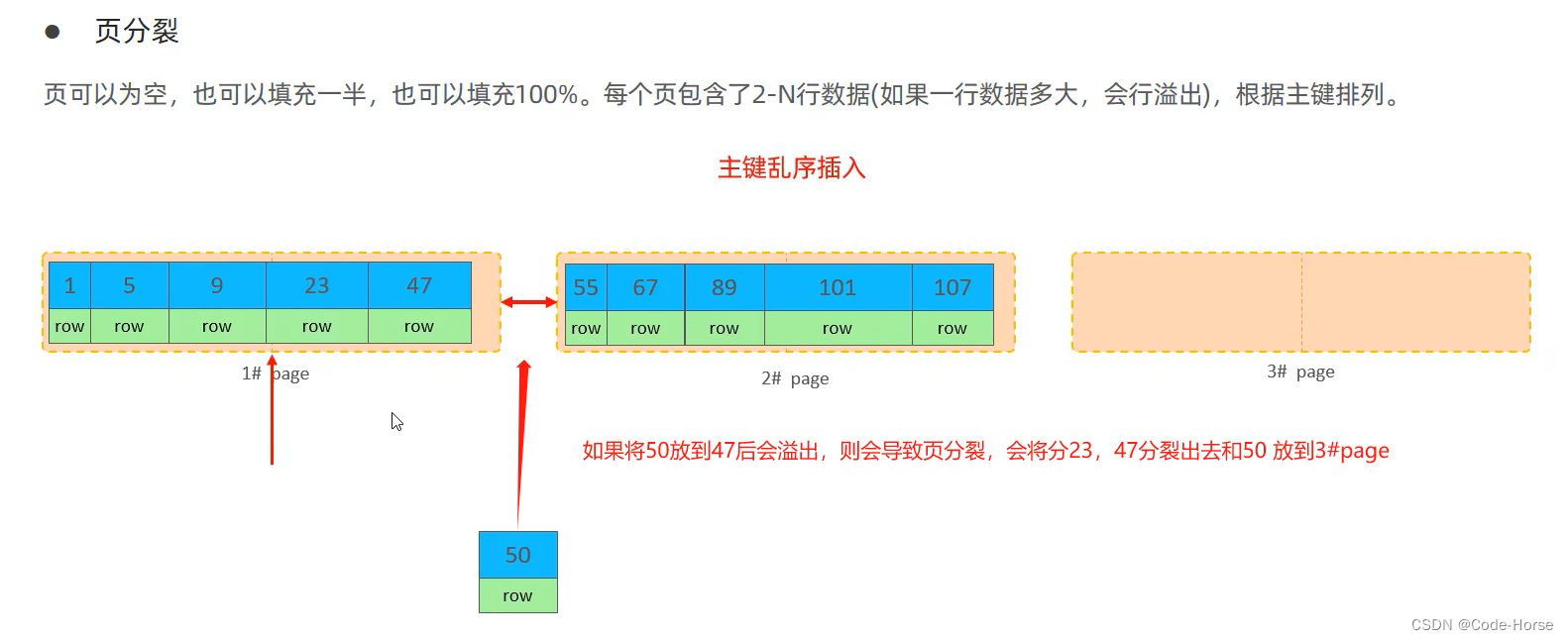

页合并
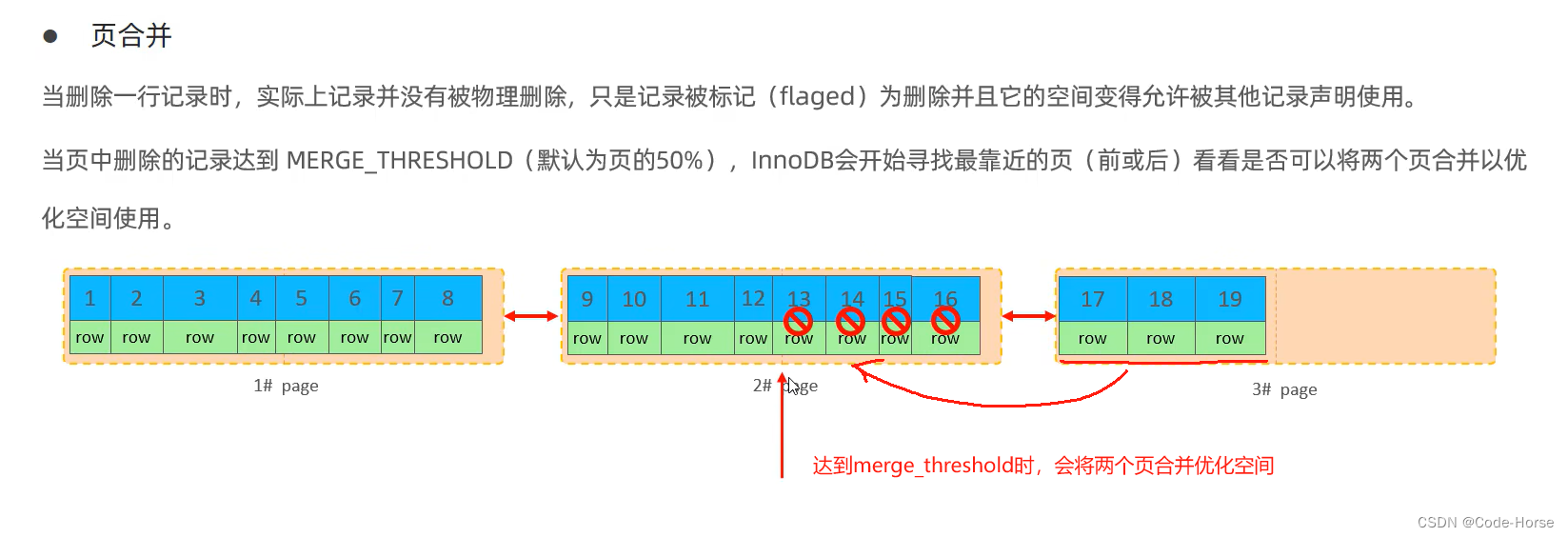

主键设计原则:
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用auto_increment自增主键。
- 尽量不用使用UUID做主键或者是其他自然主键,如身份证。
- 业务操作时,避免对主键的修改。
order by优化
MySQL的排序,有两种方式:
Using filesort :通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要
额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序
操作时,尽量要优化为 Using index。
-- 按照age升序排序,如果age相同则按phone升序排序
explain select id, age, phone from tb_user order by age, phone; -- Using filesort
-- 创建age、phone联合索引(默认asc升序索引)
create index idx_age_phone on tb_user(age, phone);
-- 建立联合索引后,再次按照age升序排序,如果age相同则按phone升序排序
explain select id, age, phone from tb_user order by age, phone; -- Using index
-- 按照age降序排序,如果age相同则按phone降序排序。 Backward index scan:反向索引扫描
explain select id, age, phone from tb_user order by age desc, phone desc; -- Backward index scan; Using index
-- 按照age升序排序,如果age相同则按phone降序排序
explain select id, age, phone from tb_user order by age asc, phone desc; -- Using index; Using filesort
-- 创建age 升序排序、phone降序排序的联合索引
create index idx_age_phone_ad on tb_user(age asc ,phone desc);
-- 建立联合索引后,再次按照age升序排序,如果age相同则按phone降序排序
explain select id, age, phone from tb_user order by age asc, phone desc; -- Using index
-- 无论什么顺序的联合索引,都要注意最左前缀法则
explain select id, age, phone from tb_user order by phone, age; -- Using index; Using filesort
explain select id, age, phone from tb_user order by phone desc, age asc; -- Using index; Using filesort
order by的使用原则
- 尽量根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。(因为出现回表查询,就会出现FileSort排序)。
- 多字段排序,一个升序一个降序的情况,此时需要注意联合索引在创建时指定排序规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
-- 查询排序缓冲区大小
show variables like 'sort_buffer_size'; -- 262144
-- 设置排序缓冲区大小
set global sort_buffer_size = 262144;
group by优化
在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是满足最左前缀法则的。
-- group by字段如果没有索引会出现Using temporary(临时表)
explain select profession, count(*) from tb_user group by profession; -- Using temporary
-- 建立profession、age、status的联合索引
create index idx_pro_age_sta on tb_user(profession, age, status);
-- 再次查询
explain select profession, count(*) from tb_user group by profession; -- Using index
-- 不满足最左前缀法则也会出现Using temporary
explain select age, count(*) from tb_user group by age; -- Using index; Using temporary
explain select age, count(*) from tb_user where profession = '软件工程' group by age; -- Using index
limit 优化
对于limit分页,大数据量的情况下,越往后的页就越卡。
一个常见又非常头疼的问题就是limit 2000000,10,此时需要MySQL排序前200000010记录,仅仅返回2000000~2000010的记录,其他记录丢弃,查询排序的代价非常大。
==优化思路:==一般分页查询时,通过创建覆盖索引能给比较好地提高性能,可以通过覆盖索引 + 子查询形式进行优化。
-- 没优化写法
explain select * from tb_sku limit 20000000, 10; -- 不要expalin执行时15.75 sec
-- 子查询 + 覆盖索引
explain select * from tb_sku s , (select id from tb_sku order by id limit 2000000,10) t where s.id = t.id; -- 2.17 sec
count 优化
效率:count(*) > count(数字) > count(主键) > count(字段)
-- count(*): InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
select count(*) from tb_user;
-- count(数字):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
select count(1) from tb_user;
-- count(主键):InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)
select count(*) from tb_user;
-- count(字段)
-- 没有not null约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。
-- 有not null约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
select count(profession) from tb_user;
update 优化
当表开启事务后对没有索引条件的行进行修改,则触发表级锁。对有索引条件的行进行修改,则触发行级锁。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
update优化:当开启事务修改某行值时,尽量命中索引,否则触发表级锁,影响效率。
-- 当id为索引,只触发行锁
update student set name = 'lisi' where id = 1;
-- 当name不为索引,触发表锁
update student set name = 'lisi' where name = 'zhangsan';
-- 建立name索引
create index idx_name on tb_user(name);
-- name为索引,触发行锁
update student set name = 'lisi' where name = 'zhangsan';
视图 view
-- 创建视图
create view stu_v_1 as select id, name from student where id <= 10;
create or replace view stu_v_1 as select id, name from student where id <= 10; -- or replace:或替换
-- 查看视图创建语句
show create view stu_v_1;
show table status where comment='view'; --查看所有视图
-- 查询视图
select * from stu_v_1;
-- 修改视图
create or replace view stu_v_1 as select name from student where id <= 100; -- 暴力写法,创建或替换
alter view stu_v_1 as select name from student where id <= 100; -- 修改视图
-- 删除视图
drop view if exists stu_v_1;
视图的检查选项
-- cascaded check option 级联检查项:一层叠一层往上检查
create or replace view stu_v_1 as select id, name from student where id >= 10
create or replace view stu_v_2 as select id, name from stu_v_1 where id <= 20 with cascaded check option;
insert into stu_v_1 values(15, 'tom'); -- 满足stu_v_1视图检查项id >= 10
insert into stu_v_2 values(9, 'tom'); -- 满足stu_v_2.id <= 20 但是不满足 stu_v_1.id <= 10,插入失败
-- local check option:往上递归检查,如果没有检查项则不检查
create or replace view stu_v_3 as select id, name from student where id >= 10;
create or replace view stu_v_4 as select id, name from stu_v_3 where id <= 20 with local check option;
insert into stu_v_3 values(15, 'tom'); -- 没有条件,直接插入
insert into stu_v_4 values(9, 'tom'); -- 满足stu_v_2.id <= 20, 由于stu_v_3没有检查项,所以不会检查。 插入成功
存储过程 procedure
-- 创建存储过程
create procedure p1()
begin
select count(*) from student;
end;
-- 调用
call p1();
-- 删除
drop procedure p1;
-- 查看创建存储过程语句
show create procedure p1;
select * from information_schema.ROUTINES where ROUTINE_SCHEMA = '数据库名';
if判断
-- if语句
create procedure p3()
begin
declare score int default 59;
declare res varchar(10);
if score >= 85 then
set res := '优秀';
elseif score >= 60 then
set res := '及格';
else
set res := '不及格';
end if;
select res;
end;
call p3();
存储过程参数
-- 参数: in: 输入 out:输出 inout:输入输出
create procedure p4(in score int, out res varchar(10), inout sum int)
begin
if score >= 85 then
set res := '优秀';
elseif score >= 60 then
set res := '及格';
else
set res := '不及格';
end if;
set sum := sum + sum;
end;
set @sum := 1;
call p4(85, @res, @sum);
select @res, @sum;
存储过程case
-- case用法
create procedure p6(in x int)
begin
declare res varchar(10);
case
when x >= 1 and x <= 10 then
set res := '1~10';
when x >= 11 and x <= 20 then
set res := '11~20';
else
set res := '非法参数';
end case;
select res;
end;
call p6(11);
while循环
-- while循环
create procedure p7(in n int)
begin
declare sum int default 0;
while n > 0 do
set sum := sum + n;
set n := n - 1;
end while;
select sum;
end;
call p7(10);
repeat重复执行
-- repeat: 一直重复直到满足条件才退出
create procedure p8(in n int)
begin
declare sum int default 0;
repeat
set sum := sum + n;
set n := n - 1;
until n <= 0
end repeat;
select sum;
end;
call p8(10);
loop 循环
-- loop 循环
create procedure p9(in n int)
begin
declare res varchar(100);
even:loop
if n <= 0 then
leave even;
end if;
if n % 2 = 1 then
set n := n - 1;
iterate even;
end if;
if isnull(res) then -- 一定要判断null,不然concat有一个null,最终结果就是null
set res := cast(n as char);
else
set res := concat(res, ' ', cast(n as char));
end if;
set n := n - 1;
end loop even;
select res;
end;
call p9(10);
drop PROCEDURE p9;
游标 cursor
-- 游标的基本使用
create procedure p10(in uage int)
begin
declare u_name varchar(100);
declare u_age int;
declare u_cursor cursor for select name, age from student where age <= uage; -- 1. 新建游标
drop table if exists new_user;
create table if not exists new_user(
id int primary key auto_increment,
name varchar(100),
age int
);
open u_cursor; -- 2. 开启游标
while true do
fetch u_cursor into u_name, u_age; -- 3. 遍历游标
insert into new_user values (null, u_name, u_age);
end while;
close u_cursor; -- 4. 关闭游标
end;
call p10(20);
由于while是死循环,导致游标不会停, 最后会报一个错:No data - zero rows fetched, selected, or processedNo data - zero rows fetched, selected, or processed
解决方案:配合条件处理一起使用
条件处理程序 handler
-- 游标 和 条件处理 一起使用
create procedure p10(in uage int)
begin
declare u_name varchar(100);
declare u_age int;
declare u_cursor cursor for select name, age from student where age <= uage; -- 1. 新建游标
declare exit handler for sqlstate '02000' close u_cursor; -- 当SQL执行状态码满足'02000'时exit
-- declare exit handler for not found close u_cursor; -- sql执行状态满足02开头的代码
drop table if exists new_user;
create table if not exists new_user(
id int primary key auto_increment,
name varchar(100),
age int
);
open u_cursor; -- 2. 开启游标
while true do
fetch u_cursor into u_name, u_age; -- 3. 遍历游标
insert into new_user values (null, u_name, u_age);
end while;
close u_cursor; -- 4. 关闭游标
end;
call p10(20);
存储函数
-- 存储函数
create function p12(n int) -- 定义存储函数
returns int deterministic
begin
declare res int default 0;
while n > 0 do
set res := res + n;
set n := n - 1;
end while;
return res;
end;
select p12(10); -- 直接调用函数
变量
系统变量
-- 系统变量
show session variables; -- session,默认
show global variables; -- 全局
show global variables like 'auto%'; -- 模糊匹配查找变量
select @@global.autocommit; -- 查看指定系统变量名
-- 设置系统变量
set global autocommit = 0;
set @@global.autocommit = 1;
用户自定义变量
-- 设置用户自定义变量
set @myName = 'codehorse'; -- 方法1:=
set @myName := 'codehorse2'; -- 方法2::=,推荐
select @myName := 'codehorse3'; -- 方法3:select
select count(*) into @MyCount from student; -- 方法4:select查表赋值
-- 查看用户自定义变量
select @myName, @MyCount;;
局部变量
-- declare 变量名 变量类型 [default ...]
create procedure p2()
begin
declare stu_cnt int default 0; -- declare定义局部变量
declare myName varchar(255); -- declare 变量名 变量类型
select count(*) into stu_cnt from student;
set myName := 'codehorse';
select stu_cnt, myName;
end;
call p2()
触发器 trigger
-- 创建触发器日志表
create table stu_logs(
id int primary key not null auto_increment comment 'id',
op_type varchar(255) comment '操作类型 insert/update/delete',
op_time datetime comment '操作日期',
info varchar(255) comment '日志信息'
)engine=innodb default charset=utf8;
insert插入触发器
-- 创建 插入触发器
create trigger stu_insert_trigger
after insert on student for each row
begin
insert into stu_logs(id, op_type, op_time, info) values(null, 'insert', now(), concat('插入的内容为:', 'id=',new.id, ', age=', new.age, ', name=', new.name));
end;
-- 当studetn插入数据时触发
insert into student(id, age, name) values(null, 18, 'horse');
-- 查看日志
select * from stu_logs;
-- 查看创建的触发器
show triggers;
-- 删除触发器
drop trigger stu_update_trigger;
update更新触发器
-- 更新触发器
create trigger stu_update_trigger
after update on student for each row
begin
insert into stu_logs(id, op_type, op_time, info) values(null, 'update', now(), concat('更新前的数据为:id=', old.id, ', age=', old.age, ', name=', old.name,
' | 更新后的数据为:id=', new.id, ', age=', new.age, ', name=', new.name));
end;
-- 当student更新数据时触发
update student set name = 'horse' where id = 1;
delete删除触发器
-- 删除触发器
create trigger stu_delete_trigger
before delete on student for each row
begin
insert into stu_logs(id, op_type, op_time, info) values(null, 'delete', now(), concat('删除的数据id为:', old.id));
end;
-- 当student删除数据时触发
delete from student where id = 100;
锁
全局锁
-- 开启全局锁
flush tables with read lock;
-- 解除全局锁
unlock tables;
备份语句
-- 备份命令(这条需要加锁,不然备份过程中有可能会产生一致性问题)
mysqldump -h127.0.0.1 -uroot -proot company > G:/db01.sql -- 备份命令不需要进入mysql客户端执行
-- 在InnoDB引擎中,我们可以在备份时加上参数 --single-transaction 参数来完成不加锁的一致性数据备份。
mysqldump --single-transaction -h127.0.0.1 -uroot -proot company > G:/db01.sql
表级锁
表锁 = 整张表的每一行数据都会自动加锁
表锁
-- 开启表共享读锁 (读锁)
lock tables student read;
select * from student; -- 成功
update student set name = 'b' where id = 1; -- 失败
-- 开启表共享写锁(写锁)
lock tables student write;
select * from student; -- 成功
update student set name = 'a' where id = 1; -- 成功,但只限当前客户端,别的客户端会锁住
-- 解除表级锁
unlock tables;
元数据锁 meta data lock (MDL)
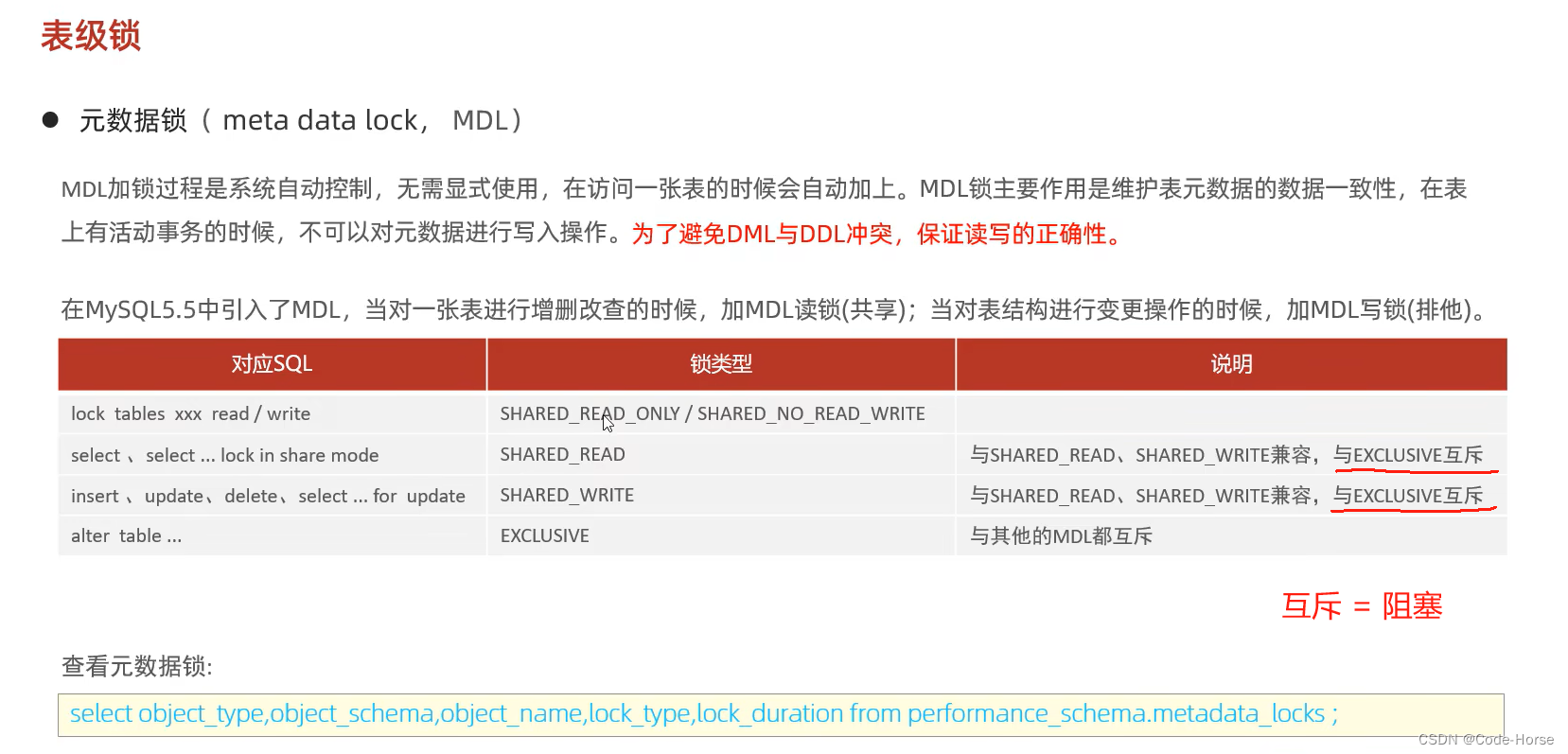
-- 查看当前所有的元数据锁
select object_type, object_schema, object_name, lock_type, lock_duration from performance_schema.metadata_locks;
-- 客户端1
begin;
select id, name from student where id = 1; -- 执行成功,并产生shared_read锁。 可以使用查看元数据锁语句查看
commit;
-- 客户端2
begin;
update student set name = 'a' where id = 1; -- 执行成功(shared_read兼容shared_write锁),并产生shared_write锁
alter table student add column job varchar(255); -- 执行阻塞(exclusive和shared_write互斥,需要等read和write锁释放),并产生exclusive锁
commit;
意向锁

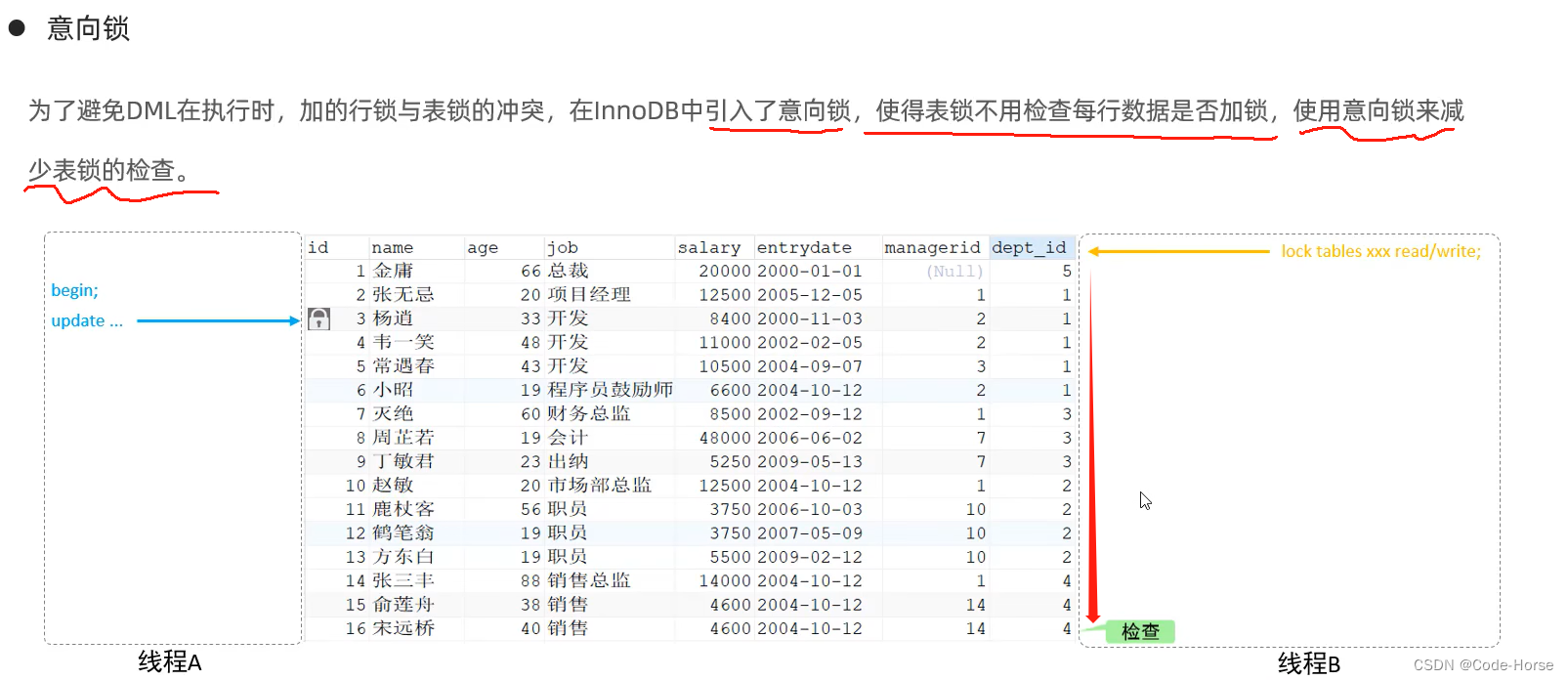

-- 查看当前所有的意向锁和行级锁
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;
begin;
-- 意向共享锁
select id, name from student where id = 1 lock in share mode; -- 给student表加上IS锁(意向共享锁)和id=1的行数据加上S锁(共享锁)
-- 意向排他锁
select id, name from student where id = 1 for update; -- 给student表加上IX锁(意向共享锁)和id=1的行数据加上X锁(共享锁)
commit;
-- 客户端2
lock tables student read; -- 表仅拥有IS锁时执行成功,表拥有IX锁时执行阻塞
unlock tables;
行级锁
注意:找数据的条件如果没有索引,行锁将会上升到表锁!!!
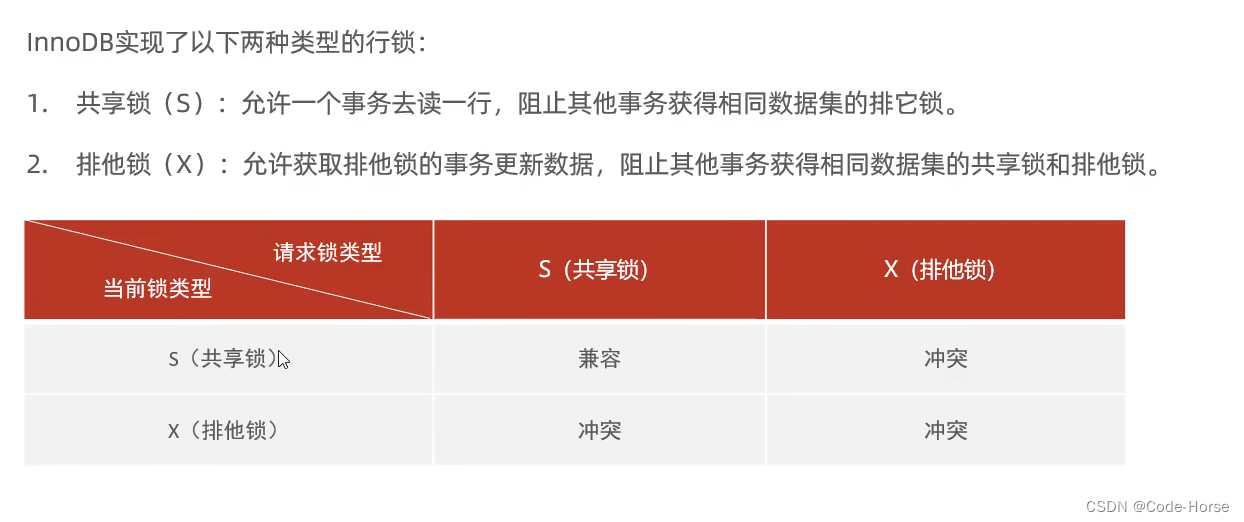
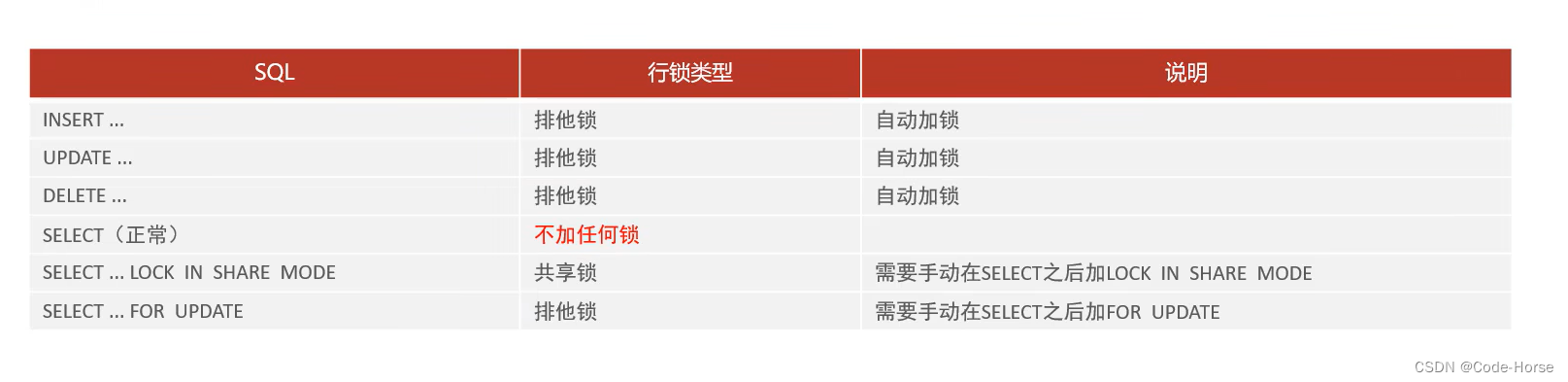

-- 查看当前所有的意向锁和行级锁
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;
begin;
select id, name from student where name = 'a' lock in share mode; -- 当前行数据加上共享锁(S)
select id, name from student where id = 1 for update; -- 当前行数据加上排他锁(X)
update student set name = 'horse' where name = 'a'; -- insert, update, delete 自动加排他锁
commit;
间隙锁(Gap Lock)& 临键锁(Next-Key Lock)

-- 查看当前所有的意向锁和行级锁
select object_schema, object_name, index_name, lock_type, lock_mode, lock_data from performance_schema.data_locks;
begin;
-- 假设id=5这条记录不能存在且a和b是最接近5的。 a(小于5的最大值) < 5 < b(大于5的最小值)
update student set name = 'horse' where id = 5; -- 会给a和b之间的数据加上间隙锁(不包含a和b)
-- 假设现有记录id=[1, 2, 19, 25]
select id, name from student where id >= 15 lock in share mode; -- 触发临键锁,锁住区间[15, 19],(19, 25],(25, +∞]
-- supremum pseudo-record: 相当于正无穷
commit;
InnoDB引擎
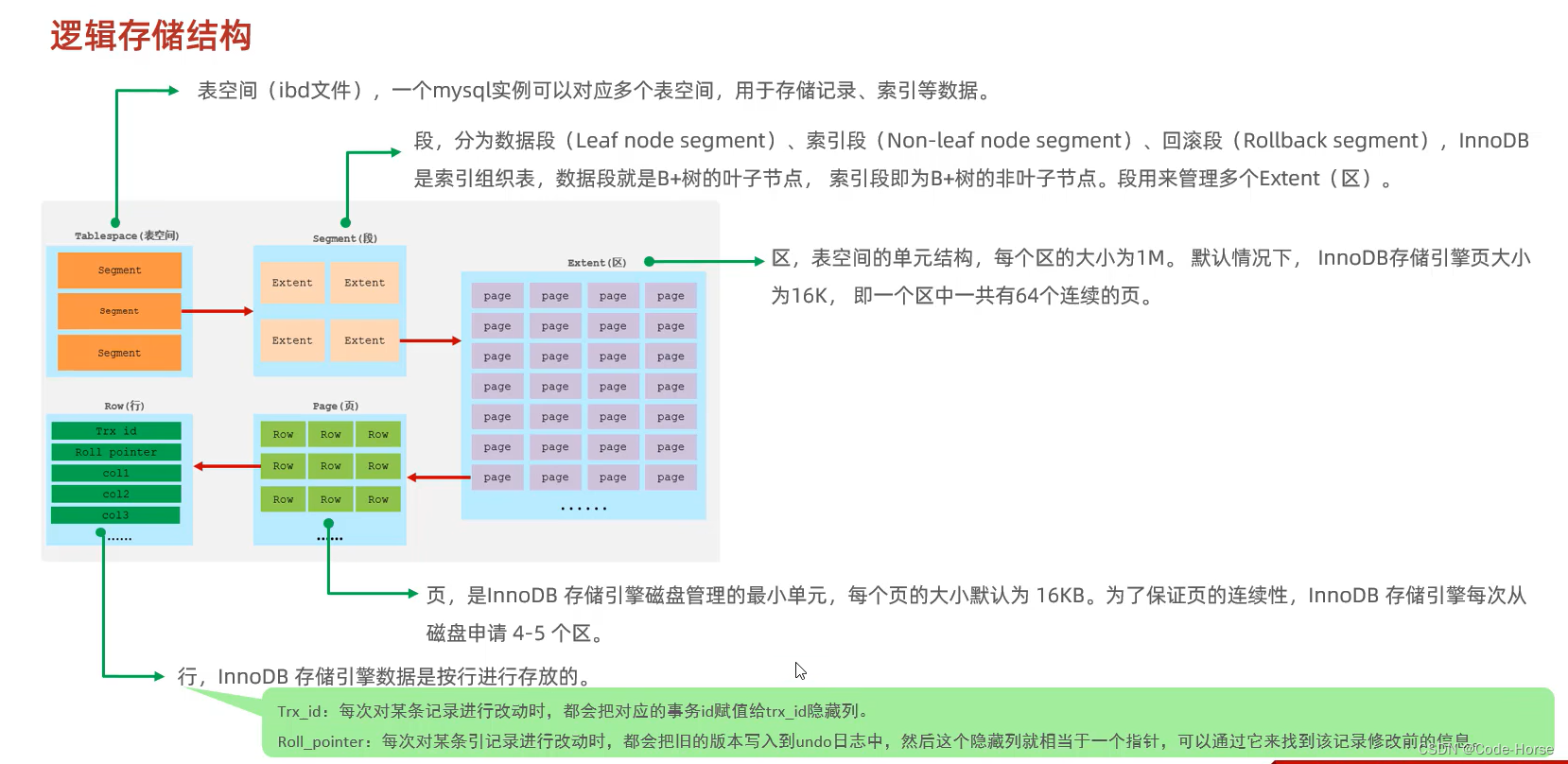
逻辑存储结构
架构
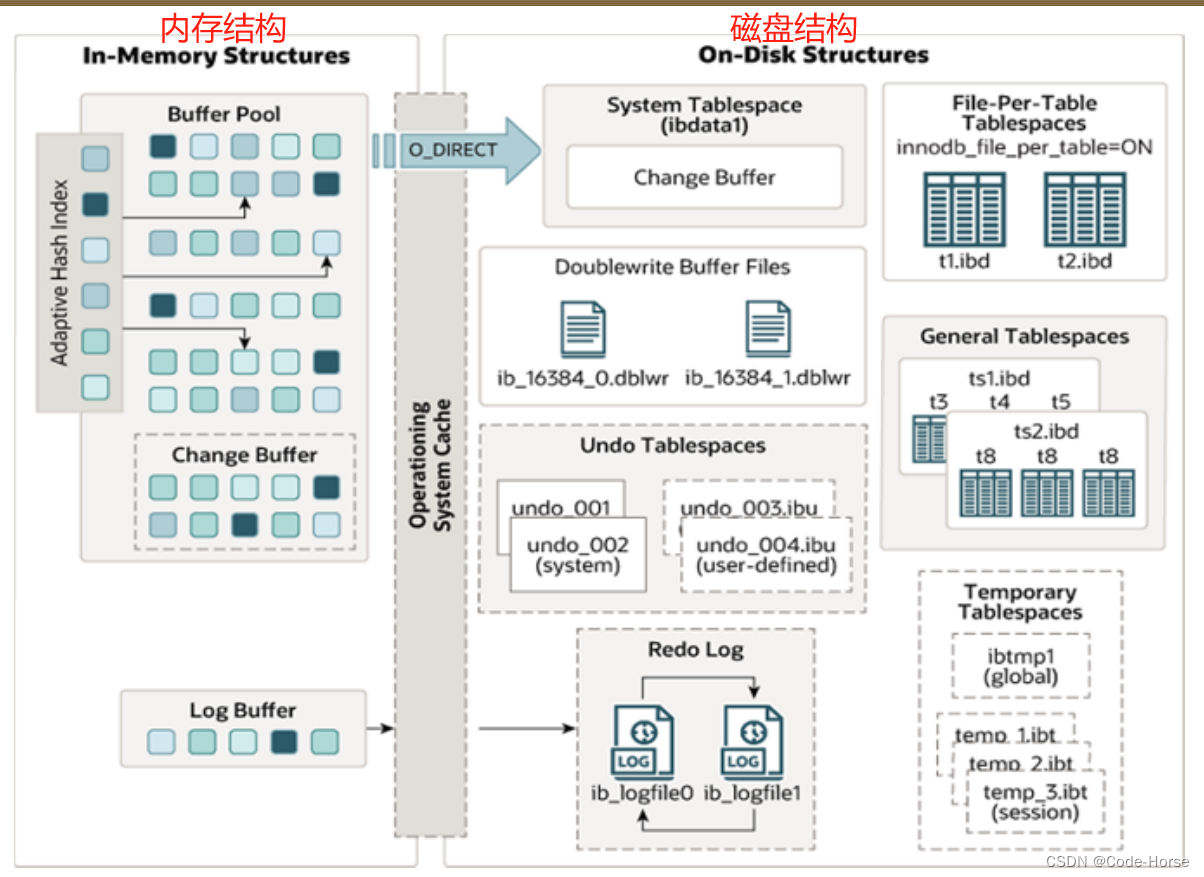
内存结构
磁盘结构
事务原理
MVCC
mysql管理
系统数据库
Mysql数据库安装完成后,一般自带四个数据库,具体作用如下:
information_schema:提供了访问数据库元数据的各种表和视图,包含了数据库、表、字段类型及访问权限等。 如表:engine、character_sets、views、triggers、routines 等
mysql:存储mysql运行过程中所需的各种信息。如表:time_zone(时区) 、user(用户)、salve*(主从相关)、(权限)、slow_log(慢日志) 等
performance_schema:mysql运行过程中的底层监控,用于收集数据库服务器性能参数。 如表:data_locks、error_log、metadata_locks
sys:包含了一系列方便DBA和开发人员利用 performance_schema 性能数据库进行性能调优和诊断的视图。
mysql常用工具命令
mysql 直接执行语句
-- 直接执行mysql语句,不进入客户端
mysql -uroot -proot -P3306 itcast -e "select * from student;"
mysqladmin
-- mysqladmin:执行管理操作的客户端程序。
mysqladmin --help --mysqladmin使用文档
mysqladmin -uroot -proot version -- 查看mysql版本
mysqladmin -uroot -proot variables -- 查看mysql服务器系统变量
mysqlbinlog
-- mysqlbinlog: 用于查看mysql生成的二进制日志文件
mysqlbinlog --help
mysqlbinlog binlog.000020
mysqlbinlog binlog.000020 -v -- 将行事件(数据变更)重构为SQL语句

注意:两个v的参数,不是w
mysqlshow
-- mysqlshow:可以快速便捷的查看MySQL数据库、表、列、索引等信息,
mysqlshow --help
mysqlshow -uroot -proot --count -- 统计所有库中的表、数据的数量
mysqlshow -uroot -proot itcast student id --count
mysqlshow -uroot -proot itcast student-i -- itcast库的student表的状态信息
mysqldump
-- mysqldump: 数据库备份、迁移。
mysqldump --help
mysqldump -uroot -proot itcast > G:/db01.sql -- 备份itcast数据库
mysqldump -uroot -proot itcast > G:/db01.sql -d -- 不包含数据
mysqldump -uroot -proot itcast > G:/db01.sql -t -- 不包含数据表的创建语句
mysqldump -uroot -proot -T /var/lib/mysql-files/ itcast student -- 生成表备份和数据备份两个文件
如果报错:mysqldump: Got error: 1290: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement when executing ‘SELECT INTO OUTFILE’
方案1:查看信任目录
mysql -uroot -proot -e "show variables like '%secure_file_priv%'"
方案2:打开my.ini文件
# 在[mysqld]下添加:
secure_file_priv = '信任目录'
mysqlimport 导入
-- mysqlimport:用于导入mysqldump -T 生成的数据文件
mysqlimport --help
mysqlimport -uroot -proot itcast /var/lib/mysql-files/student.txt -- 向itcast库student表导入数据
```sql
-- source:加载sql脚本(需要在mysql客户端内执行)
source student.sql
日志
错误日志
-- 查看错误日志的存储路径
show variables like '%log_error%'; -- log_error:错误日志路径
二进制日志
作用:①. 灾难时的数据恢复; ②. MySQL的主从复制。
在MySQL8版本中,默认二进制日志是开启的。
-- 查看二进制日志的信息
show variables like '%log_bin%';
-- 查看二进制日志支持的格式
show variables like '%binlog_format%';
删除二进制文件
-- 删除 binlog.000030 编号之前的所有日志(不包括 binlog.000030)
purge master logs to 'binlog.000030';
-- 删除日志为 "2023-09-13 23:59:59" 之前产生的所有日志
purge master logs before '2023-09-13 23:59:59';
-- 删除全部 binlog 日志,删除之后,日志编号,将从 binlog.000001重新开始
reset master;
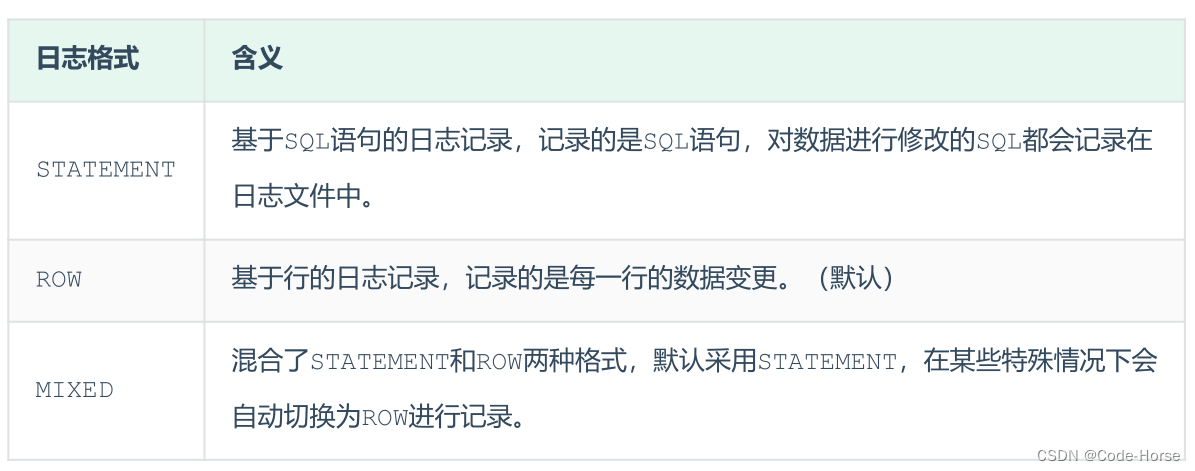
在my.cnf配置文件中修改日志格式
# 将binlog_format设置为statement
binlog_format=statement
查询日志
-- 查询日志信息
show variables like '%general%'; -- 默认OFF
开启查询日志,可以修改MySQL的配置文件 my.cnf 文件,添加如下内容:
#该选项用来开启查询日志 , 0 代表关闭, 1 代表开启
general_log=1
#设置日志的文件名 , 如果没有指定, 在查询日志信息中有这条记录
general_log_file=mysql_query.log
慢查询日志
-- 慢查询日志信息
show variables like '%slow_query%';
-- 慢查询时间
show variables like 'long_query_time';
在my.cnf中配置慢查询信息
#开启慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以修改log_slow_admin_statements和 log_queries_not_using_indexes达到也记录慢查询记录。
#记录执行较慢的管理语句
log_slow_admin_statements=1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes=1
主从复制
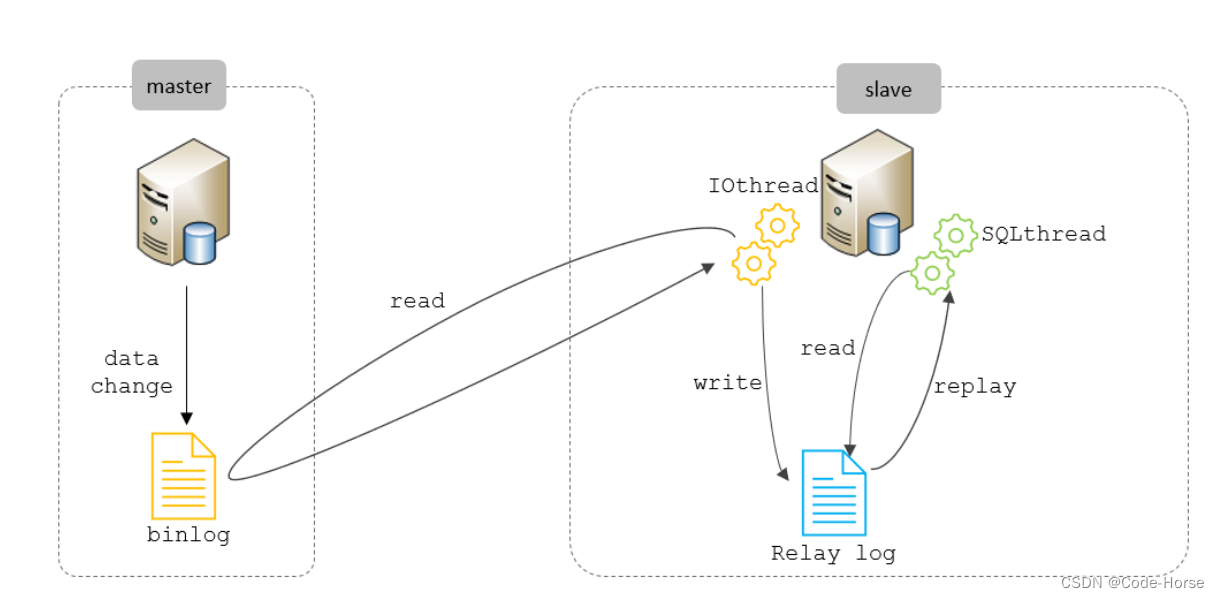
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。(IO线程)
- slave重做中继日志中的事件,将改变反映它自己的数据。(SQL线程)
主库配置
- 在
my.cnf中配置主库信息
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01
- 重启mysql服务
systemctl restart mysql
- 登录mysql,创建远程连接的账号,并授予主从复制权限
-- 创建myuser用户,并设置密码,该用户可在任意主机连接该MySQL服务
create user 'myuser'@'%' identified with mysql_native_password BY 'mypassword';
-- 为 'myuser'@'%' 用户分配主从复制权限
grant replication slave on *.* to 'myuser'@'%';
- 查看二进制日志文件和起始坐标
show master status;
从库配置
- 在
my.cnf中配置从库信息
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1
- 重启mysql服务
systemctl restart mysql
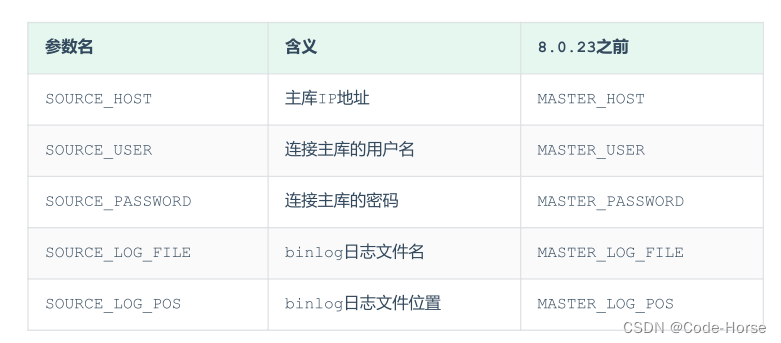
- 登录mysql,配置连接主库mysql二进制文件和坐标
-- 8.0.22之后的写法
change replication source to source_host='192.168.137.139', source_user='myuser',
source_password='mypassword', source_log_file='binlog.000008',source_log_pos=585;
-- 8.0.22之前的写法
change master to master_host='192.168.137.139', master_user='myuser',
master_password='mypassword', master_log_file='binlog.000008',master_log_pos=585;
- 开启同步操作
start replica; -- 8.0.22之后的写法
start slave; -- 8.0.22之前的写法
- 查看主从同步状态
show replica status; -- 8.0.22之后的写法
show replica status\G; -- 格式化显示
show slave status; -- 8.0.22之前的写法
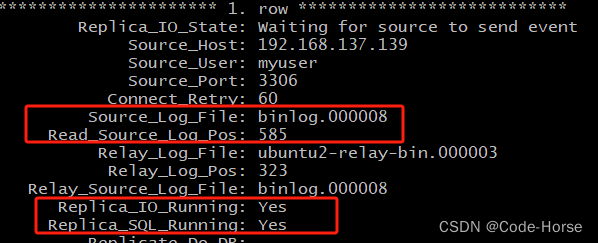
需要确保两个YES:io线程和sql线程都有在跑
停止主从复制
-- 停止从库复制
stop replica; -- 8.0.22之后的写法
stop slave; -- 8.0.22之前的写法
-- 清除从库的同步复制信息
reset replica all; -- 8.0.22之后的写法
reset salve all; -- 8.0.22之前的写法
分库分表
拆分策略
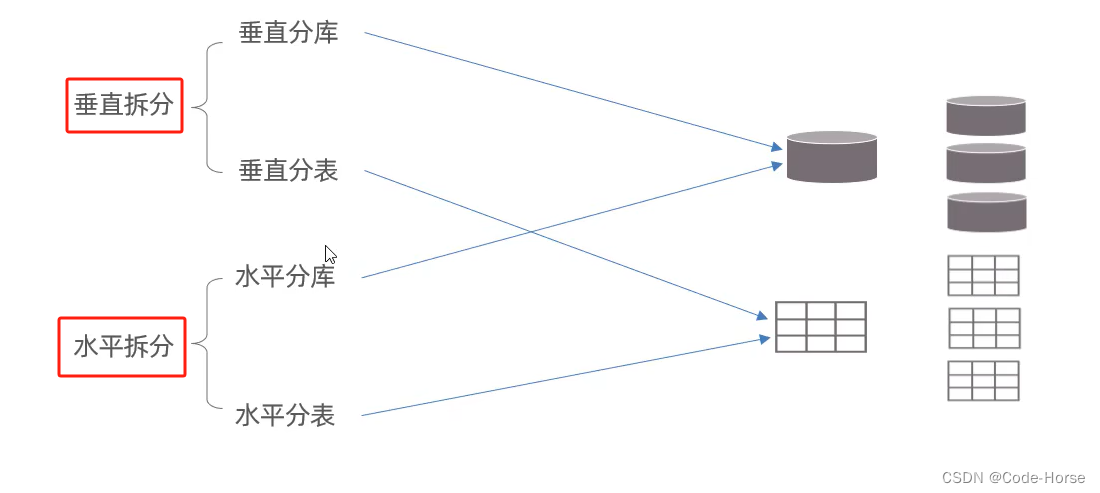
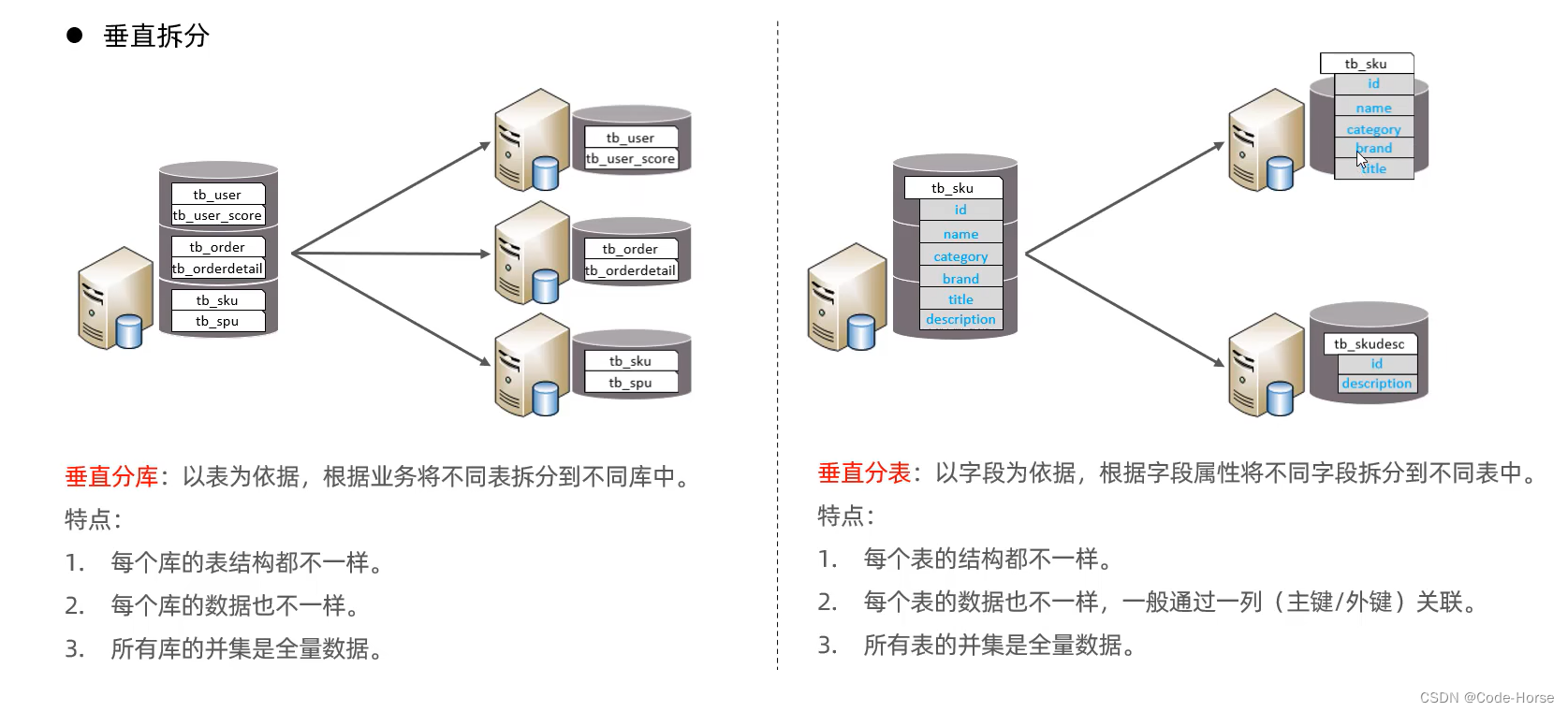
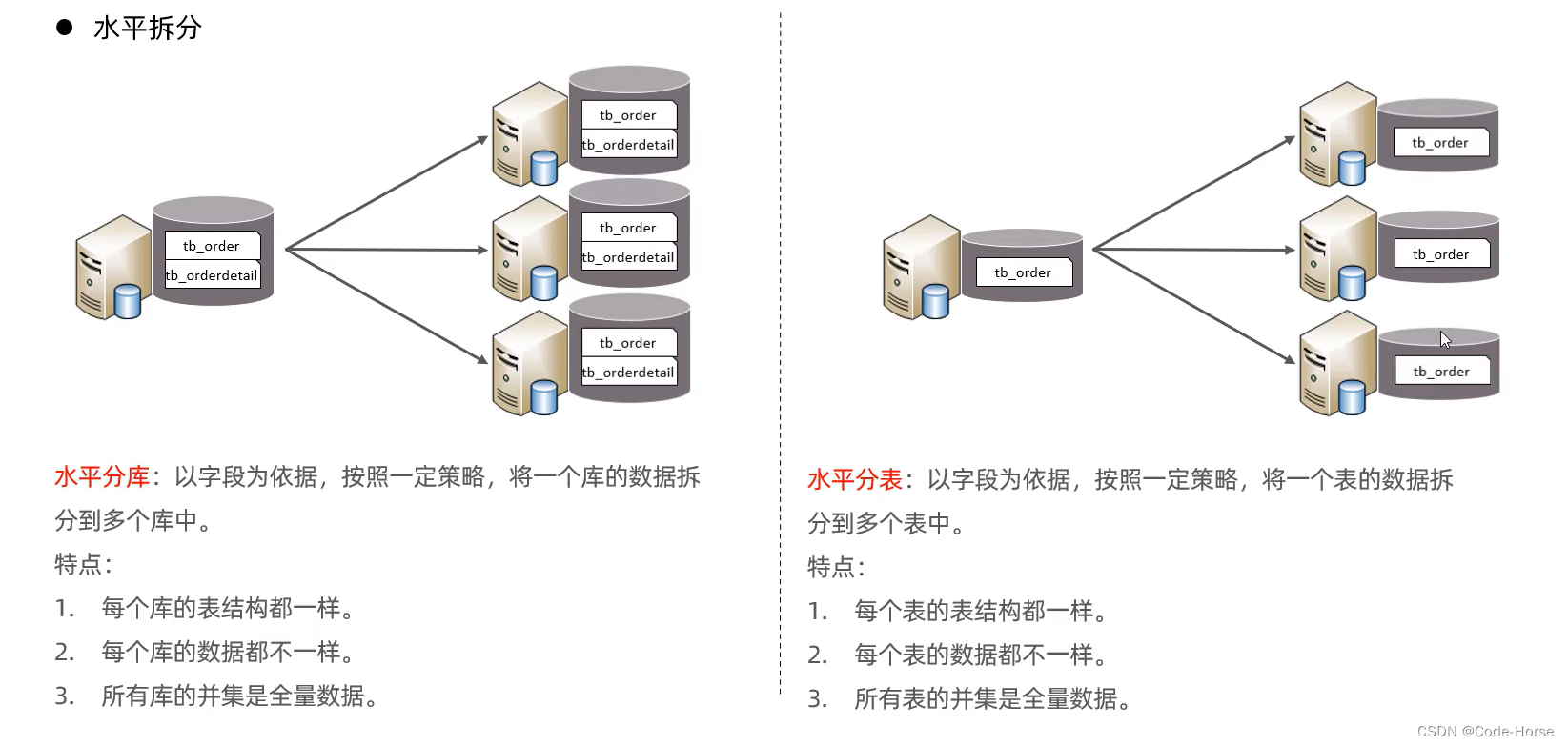
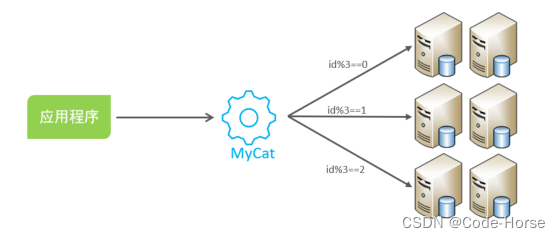
MyCat中间件














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









