







1、在JAVA中如何跳出当前的循环?
2、char型变量中能不能存贮一个中文汉字?为什么?
char类型可以存储一个中文汉字,因为Java中使用的编码是Unicode,一个char类型占2个字节(16比特),所以放一个中文是没问题的。
3、使用 final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?
是引用对象的地址值不能变,引用变量所指向的对象的内容是可以改变。final变量永远指向这个对象,是一个常量指针,而不是指向常量的指针。
4、"=="和equals 方法究竟有什么区别?
双等号:
对于基本类型:比较的的是值是否相等;
对于引用类型:⽐较的是两个引⽤是否指向同⼀个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同⼀个地⽅)
equals:
对于引用类型:(包括包装类型)来说,equals 如果没有被重写,对⽐它们的地址是否相等;
如果 equals()⽅法被重写(例如 String ),则⽐较的是地址⾥的内容。
注意:Object类中的equals方法和双等号是一样的,没有区别,而String类,Integer类等等一些类,是重写了equals方法,才使得equals和“==不同”。对于基础数据类型来说,没有重写equals方法,故两者是一样。
5、构造器Constructor 是否可被override?为什么?
构造器(构造方法)Constructor 不能被继承,因此不能重写 Override,但可以被重载 Overload(不
同参数即可)。
6、面向对象的特征有哪些方面?
7、String s = new String"xyz";创建了几个 String Object? 二者之同有什么区别?
8、如何把一段逗号分割的字符串转换成一个数组?
String 类的split方法可以根据给定正则表达式的匹配拆分字符串,故而可以把字符串分离成单个字符的形式。
//使用String的split 方法
public static String[] convertStrToArray(String str){
String[] strArray = null;
strArray = str.split(","); //拆分字符为"," ,然后把结果交给数组strArray
return strArray;
}
9、下面的程序代码输出的结果是多少?
public class smallT
{
public static void main(String args[])
{
smallT t = new smallT();
int b = t.get();
System.out.printin(b);
}
public int get(){
try
{
return 1;
}
finally
{
return 2 ;
}
}
}
结果:2
try 语句定义所执行的进行错误测试的代码。如果 try 里面没有抛出异常,catch 将被跳过。
catch 语句定义当 try 语句发生错误时,捕获该错误并对错误进行处理。只有当 try 抛出了错误,才会执行。
finally 语句无论前面是否有异常都会执行。
return 、throw 与 try/catch/finally
10、final, finally 的区别。
final:用于修饰类,方法,变量。用final修饰的类,方法,变量都有不可变的特性。
finally:用于异常处理机制。
11、多线程有几种实现方法?同步有几种实现方法?
- 继承Thread类,重写run方法
- 实现Runnable接口,重写run方法,实现Runnable接口的实现类的实例对象作为Thread构造函数的target
- 通过Callable和FutureTask创建线程
- 通过线程池创建线程
- 同步方法
- 同步代码块
- 使用重入锁实现线程同步(ReentrantLock)
- 使用特殊域变量(volatile)实现同步(每次重新计算,安全但并非一致)
- 使用局部变量实现线程同步(ThreadLocal)以空间换时间
- 使用原子变量实现线程同步(AtomicInteger(乐观锁))
- 使用阻塞队列实现线程同步(BlockingQueue (常用)、ArrayBlockingQueue (数组阻塞队列)、DelayQueue (延迟队列)
12、HTTP请求的GET与POST方式的区别?
- post更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中)
- post发送的数据更大(get有url长度限制)
- post能发送更多的数据类型(get只能发送ASCII字符)
- post比get慢
- post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据
13、MVC单词全拼及作用?
Model(模型)、View(视图)和Controller(控制)
Model层实现系统中的业务逻辑,通常可以用JavaBean或EJB来实现。
View层用于与用户的交互,通常用JSP来实现,
Controller层:从用户接收请求, 将模型与视图匹配在一起,共同完成用户的请求。
组成MVC的三个模式分别是组合模式、策咯模式、观察者模式。
14、请写出oracle或mysql 复制表的命令行?
oracle
复制表结构和数据
create table A as select * from B //as不能省
复制表结构
create table A as select * from B where 1=2
复制表数据
insert into A select * from B //全部列
insert into A(id,name) select id,name from B //部分
mysql
复制表结构和数据
create table A like B //有主键
create table A [as] select * from B //as可省略
复制表结构
create table A select * from B where 1=2
复制数据
insert into A select * from B //全部列
insert into A (id,name) select id,name from B //部分
15、数据库中视图和表的区别?
- 视图是已经编译好的sql语句。而表不是
- 视图没有实际的物理记录。而表有。
- 表是内容,视图是窗口。
- 表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时修改,但视图只能有创建的语句来修改
- 表是内模式,视图是外模式
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
- 表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
- 视图的建立和删除只影响视图本身,不影响对应的基本表。
16、group by和order by 在命令行中谁在前谁在后?
group by—having—order by
:select product,sum(price) from orders GROUP BY product HAVING sum(price)>100 ORDER BY sum(price);
order by 和 group by 的区别:
- order by 从英文里理解就是行的排序方式,默认的为升序。 order by 后面必须列出排序的字段名,可以是多个字段名。
- group by 从英文里理解就是分组。必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。
注意:聚合函数是—sum()、count()、avg()等都是“聚合函数”
需要注意having和where的用法区别:
- having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
- where肯定在group by 之前。
- where后的条件表达式里不允许使用聚合函数(聚合函数针对结果集进行的),而having可以。
17、数据库中的内连接和外连接的区别?
在SQL中,内连接和外连接是在联接多个表时常用的操作。内连接仅返回在连接的表之间有匹配的记录,而外连接则返回匹配和不匹配的记录。左外连接和右外连接分别根据左边表和右边表的数据来返回记录,全外连接则返回两个表的所有记录。
内连接(INNER JOIN)是最常用的连接类型之一,它根据两个或多个表之间的共同列值来联接这些表。在内连接中,只有在连接的表之间有匹配的值时,才会返回结果。
左外连接(LEFT OUTER JOIN)返回左边表的所有记录以及右边表中与左边表列相匹配的记录。如果右边表中没有匹配的行,则返回NULL值。
右外连接(RIGHT OUTER JOIN)则相反,它返回右边表的所有记录以及左边表中与右边表列相匹配的记录。如果左边表中没有匹配的行,则返回NULL值。
全外连接(FULL OUTER JOIN)则返回左边表和右边表的所有记录,即使没有匹配的行也不会被过滤掉。如果没有匹配的行,则返回NULL值。
18、jdk1.7&1.8HashMap 区别?
- 最重要的一点是底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构;
- jdk1.7中当哈希表为空时,会先调用inflateTable()初始化一个数组;而1.8则是直接调用resize()扩容;
- 插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插;
- jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,使元素分布更均匀;
- 扩容时1.8会保持原链表的顺序,而1.7会颠倒链表的顺序;而且1.8是在元素插入后检测是否需要扩容,1.7则是在元素插入前;
- jdk1.8是扩容时通过hash&cap==0将链表分散,无需改变hash值,而1.7是通过更新hashSeed来修改hash值达到分散的目的;
- 扩容策略:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容。
19、SpringAop Bean的生命周期?
20、Springboot如何自定义starter,启动流程?
21、Springcloud :Eureka 、 Ribbon、 Feign 、Hystrix、 Zuul 组件作用?
Eureka Server是一个注册中心,里面有一个注册表,保存了各服务所在的机器和端口号。
Feign通过对某个接口定义@FeignClient注解,针对这个接口创建一个动态代理(接着你要调用哪个接口,本质就是会调用 Feign创建的动态代理),这个动态代理会根据接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址最后针对这个地址,发起请求、解析响应。
Ribbon它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上。(Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。)
Hystrix是隔离、熔断以及降级的一个框架。Hystrix会搞很多个小小的线程池,每个线程池里的线程就仅仅用于请求那个服务。当某个服务中断的时候不会影响其他服务。
Zuul组件,一种微服务网关组件,负责网络路由的,类似于路由器的功能。接收所有的请求,根据请求中的一些特征,将请求转发给后端的各个服务。
各组件之间的流程:
订单服务想要调用库存服务、仓储服务,或者是积分服务,怎么调用?-----》使用Eureka提供注册与发现-----》知道每个服务位置和端口号了,但是订单服务要自己写一大堆代码,跟其他服务建立网络连接,然后构造一个复杂的请求,接着发送请求过去,最后对返回的响应结果再写一大堆代码来处理吗?-----》通过Feign的动态代理机制去发起请求-----》如果人家某个服务部署在了3台机器上,人家Feign怎么知道该请求哪台机器呢?-----》Ribbon就派上用场了。通过负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上。-----》万一要是哪台机器的服务挂了,怎么办,服务与服务之间都是紧密联系的,会不会产生连锁反应,导致整个系统崩掉?-----》使用Hystrix组件将每个服务隔离起来,让它们互不影响-----》后台服务部署完了,但是如果有几百个服务,前端发来请求难道要让他一个一个的请求后台服务?-----》使用Zuul组件,接收所有请求并且根据请求中的一些特征,将请求转发给后端的各个服务。
总结:
- Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
- Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
- Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
- Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
- Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
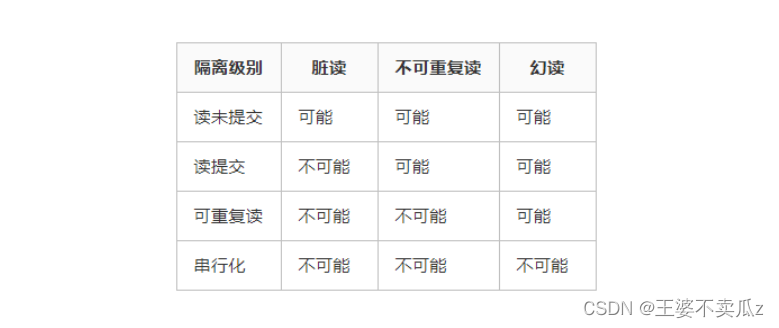
22、数据库隔离级别?
- 读未提交(READ UNCOMMITTED)
- 读提交 (READ COMMITTED)
- 可重复读 (REPEATABLE READ)
- 串行化 (SERIALIZABLE)
从上往下,隔离强度逐渐增强,性能逐渐变差。采用哪种隔离级别要根据系统需求权衡决定,其中,可重复读是 MySQL 的默认级别。
23、redis 有几种数据类型,什么是缓存击穿、缓存穿透?
- String字符串类型
- List列表类型
- Hash数据类型
- Set集合类型
- Zset有序集合
-
缓存雪崩:
解释:当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
分析:第一种可能是Redis宕机。第二种可能是采用了相同的过期时间。
解决方案:- 在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
如果真的发生了缓存雪崩,有没有什么兜底的措施? - 使用熔断机制。当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
- 提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
- 为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
- 在原有的失效时间上加上一个随机值,比如1-5分钟随机。这样就避免了因为采用相同的过期时间导致的缓存雪崩。
-
缓存击穿:
解释:其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
分析:第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
解决方案:- 上面说过了,如果业务允许的话,对于热点的key可以设置永不过期的key。
- 使用互斥锁。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库打死。当然这样会导致系统的性能变差。
-
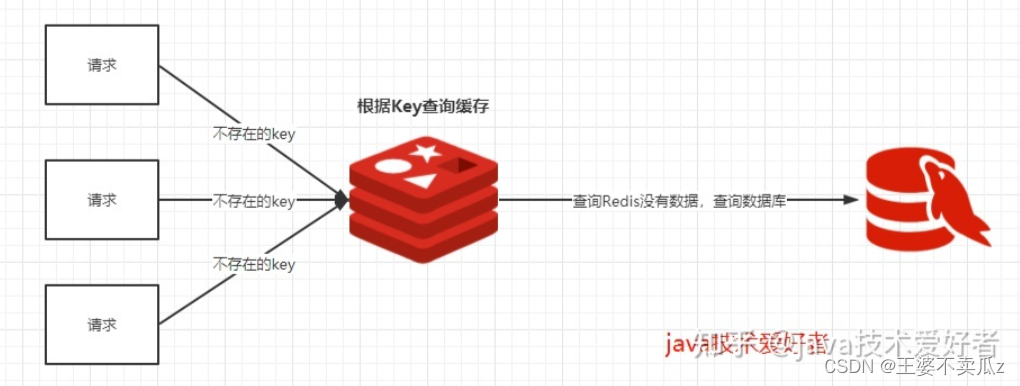
缓存穿透:
解释:我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
分析:关键在于在Redis查不到key值,这和缓存击穿有根本的区别,**区别在于缓存穿透的情况是传进来的key在Redis中是不存在的。**假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示,要对调用方保持这种“不信任”的心态。
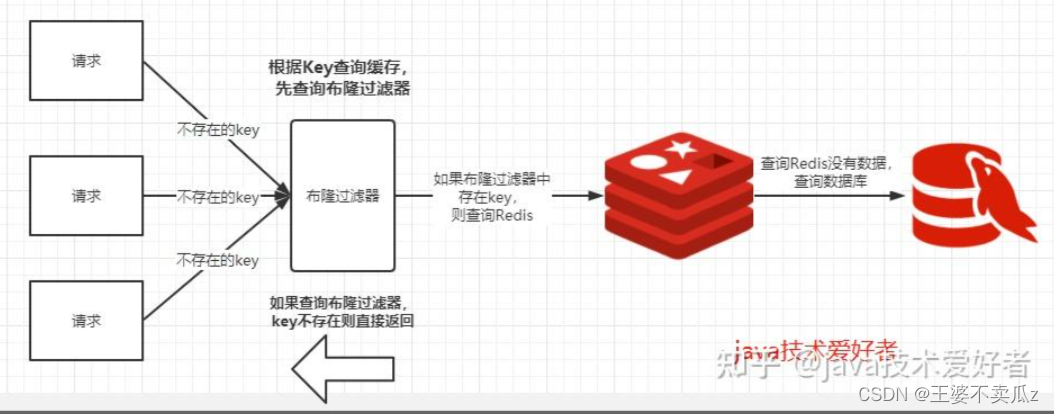
解决方案:- 把无效的Key存进Redis中。
- 使用布隆过滤器。
每次使用Redis时,需要注意的是要做好熔断,一旦出现缓存雪崩,击穿,穿透这种情况,至少还有熔断机制保护数据库不会被打死。
24、项目中用到的消息队列有哪些,什么场景下使用?
- 消息队列是分布式应用间交换信息的重要组件,消息队列可驻留在内存或磁盘上, 队列可以存储消息直到它们被应用程序读走。
- 通过消息队列,应用程序可以在不知道彼此位置的情况下独立处理消息,或者在处理消息前不需要等待接收此消息。
- 所以消息队列可以解决应用解耦、异步消息、流量削锋等问题,是实现高性能、高可用、可伸缩和最终一致性架构中不可以或缺的一环。
- 现在比较常见的消息队列产品主要有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、RocketMQ等。
- 异步处理:串行方式、并行方式。
- 应用解耦
- 流量削锋
- 日志处理
- 消息通讯















 6362
6362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









