







 本文详细介绍了如何使用Python的openpyxl库进行Excel数据的读取与写入操作,包括获取工作表、单元格数据,以及如何修改和创建新的Excel文件。并通过美国各州人口统计和批量更新表格数据的实例,展示了实际应用。
本文详细介绍了如何使用Python的openpyxl库进行Excel数据的读取与写入操作,包括获取工作表、单元格数据,以及如何修改和创建新的Excel文件。并通过美国各州人口统计和批量更新表格数据的实例,展示了实际应用。
目录
1 准备工作
1.1 基础知识
首先简述Excel中的三个基本概念:
- workbook工作簿,即你打开的Excel文件
- worksheet工作表,即sheet1,sheet2,...
- 行,通常使用1,2,3,...
- 列,使用A,B,C...
1.2 软件准备
- 软件准备:自行下载pyCharm继承开发环境
- openpyxl官方帮助:https://openpyxl.readthedocs.io/en/stable/
- 安装openpyxl库:

2 Excel数据信息获取常用函数函数
试验数据:

2.1 打开excel表格
wb = openpyxl.load_workbook('example.xlsx')
#参数字符串为excel文件路径2.2 获取excel各工作表的名称
#一次性获取所有的工作表名称
print(ws.sheetnames)
#遍历工作簿中的sheet,调用title属性获取工作表的名称
for sheet in wb:
print(sheet.title)2.3 获取某个工作表
#方式一:使用get_sheet_by_name函数获取
sheet1 = wb.get_sheet_by_name('Sheet1')
#方式二:使用索引访问
sheet2 = wb['Sheet1']
#方式三:获取当前激活的工作表
sheetActive = wb.active
print(sheet2) #<Worksheet "Sheet1">
2.4 得到某个单元格及其值
print(ws['A1']) #<Cell 'Sheet1'.A1>
print(ws['A1'].value) #夏季水果2.5 输出某一单元格的列和行索引
cell = ws['B1']
#方式一:使用行列属性
print('Row {}, columun {} is {}'.format(cell.row, cell.col, cell.value)) #Row 1, Column 2 is 葡萄
#方式二:使用坐标
print('cell {} is {}'.format(cell.coordinate, cell.value)) #cell B1 is 葡萄
2.6 根据索引获取值
#注意row=1之间不能出现空格
print(ws.cell(row=1, column=2).value)
#打印前两行的第二列数据
for i in range(1,2,1):
print(ws.cell(row=i, column=2).value)2.7 获取整行(列)的数据
colC = ws['C'] #得到表格的第C列
print(col[1].value)
row2 = ws[6] #得到表格第6行
print(row2[1].value)
col_range = ws['B:C'] #获取多列数据
row_range = ws[2:6] #获取多行数据
#按照B1C1, B2C2, B3C3,...的顺序依次输出数据
for col in col_range:
for cell in col:
print(cell.value)
2.8 获取指定区间的数据
#获取前两行前两列的数据
for row in ws.iter_rows(min_col=1, max_row=2, max_col=2):
for cell in row:
print(cell.value)
#获取2到4列前两行的数据
for col in ws.iter_cols(min_col=2, max_col=4, max_row=2):
for cell in col:
print(cell.value, end='\t')
print(end='\n')
cell_range = ws['A1:C2']
for rowOfCellObjects in cell_range:
for cellObj in rowOfCellObjects:
print(cellObj.coordinate, cellObj.value, end='\t')
print('---------next row----------------')2.9 打印表格的全部内容
for row in tuple(ws.rows):
for cell in row:
print(cell.value, end='\t')
print('\n')
#tuple(ws.rows)为嵌套元组,元组的每一个元素为代表一行数据的子元组2.10 获取表格行数和列数
print('{} * {}'.format(ws.max_row, ws.max_column))2.11 列标字符串到数字的相互转化
from openpyxl.utils import get_column_letter, column_index_from_string
print(get_column_letter(2), get_column_letter(47), get_column_letter(900)) #B AU AHP
print(column_index_from_string('AAH')) #710
3 Excel中写入数据函数及代码
3.1 新建文件并修改表单名称
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
print(sheet.title)
sheet.title = 'Happy2019'
print(wb.sheetnames)
wb.create_sheet(index=0, title='First Sheet')
wb.create_sheet(index=1, title='Middle Sheet')
print(wb.sheetnames)
wb.remove_sheet(wb.get_sheet_by_name('Middle Sheet'))
#warning: Call to deprecated function remove_sheet
print(wb.sheetnames)
wb.save('output.xlsx')
wb.close()3.2 不同形式数据写入
wb = openpyxl.Workbook()
sheet = wb.active
sheet['A1'] = 'hello world'
print(sheet['A1'].value)
#写入序列
ws1 = wb.create_sheet('range name')
for row in range(1, 40):
ws1.append(range(17))
#写入列表
ws2 = wb.create_sheet('List')
rows = [
['Number', 'Batch 1', 'Batch 2'],
[2, 40, 30],
[3, 40, 25],
[4, 45, 27],
[5, 89, 29]
]
for row in rows:
ws2.append(row)
#写入列号
ws3 = wb.create_sheet('Data')
for row in range(5, 30):
for col in range(15, 54):
ws3.cell(column=col, row=row, value=get_column_letter(col))
print(ws3['AA10'].value)
wb.save('output.xlsx')
wb.close()4 案例研究
4.1 美国各省各州人口统计的例子
数据来源:美国人口统计表
源代码:
import openpyxl, pprint
'''
{'AL':
{'Autauga':{tract:13, 'pop':人口总数}
}
}
'''
wb = openpyxl.load_workbook('censuspopdata.xlsx')
sheet = wb.active
countryData = {}
#填充每个城市的人口和有几个行政区
for row in range(2, sheet.max_row+1):
state = sheet['B' + str(row)].value
country = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
countryData.setdefault(state, {})
countryData[state].setdefault(country, {'tract': 0, 'pop': 0})
#统计该州所包含的区数
countryData[state][country]['tract'] += 1
#将每个区的数据进行累加
countryData[state][country]['pop'] += int(pop)
#将某个区的人口数目输出
print(countryData['AL']['Covington']['tract'])
#打开txt文本将统计的文本写入到文本文档中
print('Writing results...')
resaultFile = open('resault.py', 'w')
resaultFile.write('allData = ' + pprint.pformat(countryData))
4.2 批量更新表格中的数据
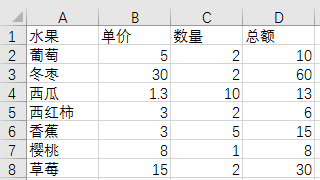
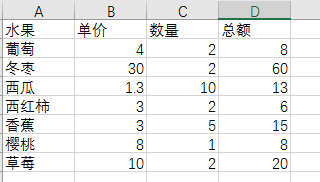
import openpyxl
wb = openpyxl.load_workbook('fruit.xlsx')
updataData = {
'草莓': 10,
'葡萄': 4
}
ws = wb.get_sheet_by_name('Sheet1')
for rowNum in range(2, ws.max_row+1):
productName = ws.cell(row=rowNum, column=1).value
if productName in updataData:
ws.cell(row=rowNum, column=2).value = updataData[productName]
wb.save('modify1.xlsx')
wb.close()


















 3850
3850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











