






目录
5、光标的使用(MySQL中光标只能在存储过程和函数中使用。)
2.使用SHOW CREATE语查看存储过程和函数的定义除了SHOW STATUS之外,
3. 从information_schema.Routines 表中查看存储过程和函数的信息
1、基本存储过程和函数
简单地说,存储过程就是一条或者多条 SQL 语的集合,可视为批文件,
但是其作用不仅限于批处理。本章主要介绍如何创建存储过程和存储函以及变量的使用,
如何调用、查看修改、删除存储过程和存储函数等。
存储程序可以分为存储过程和函数,MySQL中创建存储过程和函数使用的语句分别是
CREATE PROCEDURE和CREATE FUNCTION。
使用CALL语来调用存储过程,只能用输出变量返回值。函数可以从语句外调用(即通过引用函数名),也能返回标量值。
存储过程也可以调用其他存储过程。
1、创建存储过程
创建存储过程,需要使用CREATE PROCEDURE语句,基本语法格式如下:
CREATE PROCEDURE sp_name ( [proc_parameter] )
[characteristics ...] routine_body
CREATE PROCEDURE 为用来创建存储函数的关键字;
sp_name为存储过程的名称
proc_parameter为指定存储过程的参数列表,
列表形式如下:[IN | OUT| INOUT ] param_name type
其中,IN 表示输入参数,OUT 表示输出参数,INOUT 表示既可以输入也可以输出:
param_name表示参数名称 type表示参数的类型,该类型可以是MySQL 数据库中的任意类型
characteristics指定存储过程的特性,有以下取值:
LANGUAGE SQL:说明 routine_body 部分是由 SQL语句组成的,当前系统支持的语言
为SQL,
SQL是LANGUAGE特性的唯一值。
[NOT] DETERMINISTIC:指明存储过程执行的结果是否确定。
DETERMINISTIC表示结果是确定的。每次执行存储过程时,相同的输入会
得到相同的输出。
NOTDETERMINISTIC 表示结果是不确定的,相同的输入可能得到不同的输
出。
如果没有指定任意一个值,默认为NOT DETERMINISTIC。
{CONTAINS SQL | NO SQL | READS SQLDATA | MODIFIES SQL DATA} ;
指明子程序使用 SOL语句的限制。
CONTAINS SQL表明子程序包含SQL语句,但是不包含读写数据的语句:
NOSQL表明子程序不包含 SQL语句:
READS SOL DATA说明子程序包含读数据的语句:
MODIFIES SOLDATA表明子程序包含写数据的语句。默认情况下,系统会指定为
CONTAINSSOL。
SQL SECURITY{DEFINER | INVOKER}:指明谁有权限来执行。
DEFINER表示只有定义者才能执行。
INVOKER 表示拥有权限的调用者可以执行。默认情况下,系统指定为DEFINER COMMENT'string:注释信息,可以用来描述存储过程或函数
routine_body是SQL代码的内容可以用BEGINEND来表示SOL代码的开始和结束.
编写存储过程并不是件简单的事情,可能存储过程中需要复杂的 SQL语句,并且要有创建
存储过程的权限:但是使用存储过程将简化操作,减少冗余的操作步骤,同时,还可以减少
操作过程中的失误,提高效率,因此存储过程是非常有用的,而且应该尽可能地学会使用。
下面的代码演示了存储过程的内容,名称为AvgFruitPrice,返回所有水果的平均价格,
输入代码如下:
create procedure AvgFruitPrice()
begin
select avg(f_price) as avgprice from fruits
end;上述代码中此存储过程名为AvgFruitPrice使用CREATE PROCEDURE AvgFruitPrice()语句定义。
此存储过程没有参数,但是后面的()仍然需要。BEGIN和END语句用来限定存储过程体,过程本身仅是一个简单的 SELECT 语句 (AVG为求字段平均值的函数)。
举例:创建查看fruits表的存储过程,代码如下:
delimiter // --表示将系统默认的sql结束符号 ;修改为 //
create procedure Proc()
begin
select * from fruits;
end //
delimiter ; --表示将系统刚修改的 //结束符修改成原来的 ;调用存储过程
call Proc();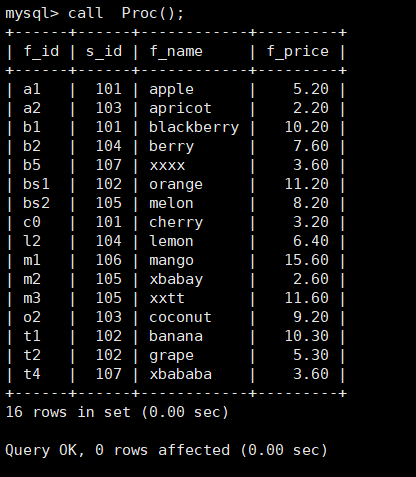
这个存储过程和使用 SELECT 语句查看表的效果得到的结果是一样的,当然存储过程
也可以 是很多语句的复杂组合,其本身也可以调用其他的函数来组成更加复杂的操作。
“DELIMITER//”语的作用是将MySOL的结束符设置为//,
因为MySOL默认的语句结束符号为分号“;’,为了避免与存储过程中 SQL 语句结束符相冲突,需要使用DELIMITER改变存储过程的结束符,并以“END //”结束存储过程。存储过程定义完毕 之后再使用“DELIMITER ;”恢复默认结束符。DELIMITER也可以指定其他符号做为结束符。
举例2:创建名称为CountProc的存储过程,代码如下:
delimiter //
create procedure CountProc(OUT param1 INT)
begin
select count(*) into param1 from fruits;
end //
delimiter ;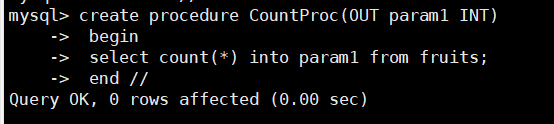
![]()
当使用DELIMITER命令时,应该避免使用反斜杠(’\’)字符,因为反斜线是MySQL的
转义字符。
简单查询是否创建成功:
show PROCEDURE status like '%Proc%' \G;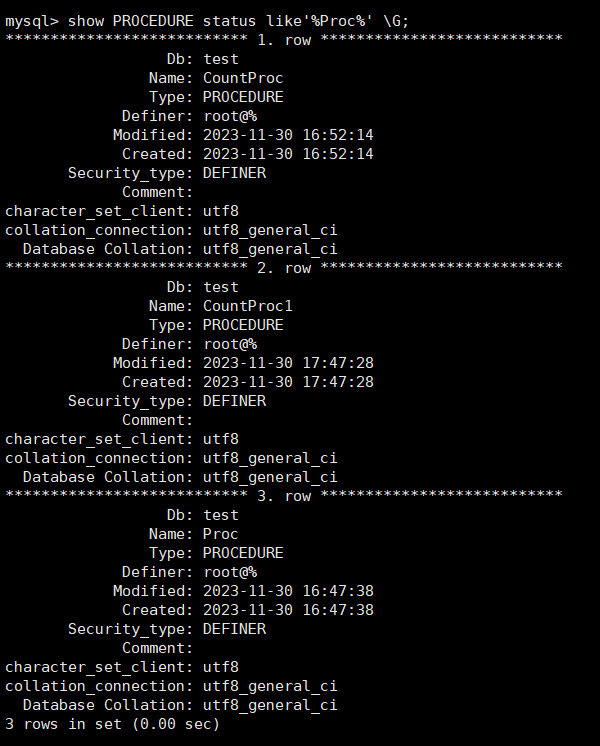
2、调用存储过程
存储过程已经定义好了,接下来需要知道如何调用这些过程和函数。存储过程和函数有多种调用方法。
存储过程必须使用 CALL 语句调用,并且存储过程和数据库相关,如果要执行其他数据库中的存储过程,需要指定数据库名称,例如CALL dbname.procname。
存储函数的调用与MySOL中预定义的函数的调用方式相同。
本节介绍存储过程和存储函数的调用。
调用存储过程
存储过程是通过CALL语句进行调用的,语法如下:
CALL sp_name([parameter[;...]]
CALL语句调用一个先前用CREATE PROCEDURE创建的存储过程,
其中sp_name为存储过程名称,parameter为存储过程的参数。
定义名为CountProc1的存储过程,然后调用这个存储过程,代码执行如下:
定义存储过程:
delimiter //
create procedure CountProc1 (IN sid INT, OUT num INT)
begin
select count(*) into num from fruits where s_id = sid;
end //
delimiter ; 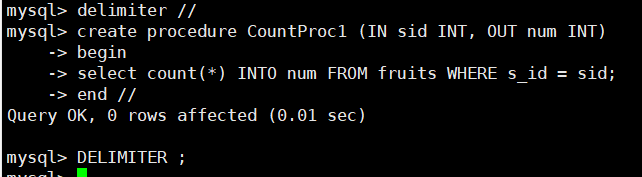
调用存储过程:
call CountProc1 (101, @num); 
查看返回结果:
select @num; 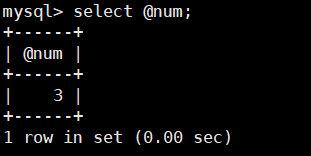
该存储过程返回了指定sd=101的水果商提供的水果种类,返回值存储在num变量中
使用SELECT查看,返回结果为3。
2、创建存储函数
1、创建存储函数
创建存储函数,需要使用CREATE FUNCTION语句,基本语法格式如下
CREATE FUNCTION func_name ( [funcparameter] )
RETURNS type
[characteristic ...] routine_body
CREATE FUNCTION为用来创建存储函数的关键字:
func_name表示存储函数的名称
funcparameter为存储过程的参数列表,参数列表形式如下:
{ IN | OUT | INOUT } param_name type
其中,IN 表示输入参数,OUT 表示输出参数,INOUT表示既可以输入也可以输出:
param name 表示参数名称;type 表示参数的类型,该类型可以是MySOL数据库中的任
意类型。
RETURNS type 语句表示函数返回数据的类型;
characteristic 指定存储函数的特性,取值与创建存储过程时相同,这里不再赘述。
举例:创建存储函数,名称为NameByZip,该函数返回SELECT语句的查询结果,
数值类型为字符串型,代码如下:
delimiter //
create function NameByZip()
returns char(50)
return (select s_name from suppliers where s_call= '48075');
//
delimiter ;
如果在存储函数中的RETURN语句返回一个类型不同于函数的RETURNS子句中指定类型的值,返回值将被强制为恰当的类型。比如,如果一个函数返回一个ENUM或SET值,但是RETURN 语句返回一个整数,对于SET成员集的相应的ENUM成员,从函数返回的值是字符串。
指定参数为IN、OUT或INOUT只对 PROCEDURE是合法的。(FUNCTION 中总是默认为IN参数)。
RETURNS 子只能对FUNCTION做指定,对函数而言这是强制的。它用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句。
2、调用存储函数
在MySOL中,存储函数的使用方法与MySOL内部函数的使用方法是一样的。换言之,
用户自己定义的存储函数与MySOL内部函数是一个性质的。
区别在于,存储函数是用户自己定义的,而内部函数是MySQL的开发者定义的。
举例:
定义存储函数CountProc2,然后调用这个函数,代码如下:
delimiter //
create function CountProc2 (sid int)
returns int
begin
return (select count(*) from fruits where s_id = sid);
end //
delimiter ; create function CountProc2 (sid int) --存储函数的参数默认是IN方向

调用存储函数:
select CountProc2(101);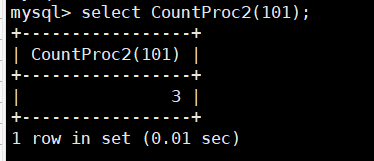
可以看到,该例与上一个例子中返回的结果相同。虽然存储函数和存储过程的定义稍有不
同, 但可以实现相同的功能,读者应该在实际应用中灵活选择。
3、变量的使用
变量可以在子程序中声明并使用,这些变量的作用范围是在 BEGIN..END程序中,
本小节主要介绍如何定义变量和为变量赋值。
1、定义变量
在存储过程中使用DECLARE语句定义变量,语法格式如下:
DECLARE var_name [,var_name] ..... data_type [DEFAULT value] ;
var_name为局部变量的名称。DEFAULT value 子给变量提供一个默认值。
值除了可以被声明为一个常数之外,还可以被指定为一个表达式。
如果没有 DEFAULT 子句,初始值为NULL。
举例:
定义名称为myparam的变量,类型为INT类型,默认值为100,代码如下:
declare myparam int default 100;2、为变量赋值
定义变量之后,为变量赋值可以改变变量的默认值。 MySOL中使用 SET 语为变量赋值
语法格式如下:
SET var_name = expr [, var_nam = eexpr] ... ;
在存储程序中的SET语句是一般SET语的扩展版本。被参考变量可能是子程序内声明的
变量,或者是全局服务器变量,如系统变量或者用户变量。
在存储程序中的SET语作为预先存在的SET 语法的一部分来实现。这允许SET a=x,b=y....
这样的扩展语法。其中不同的变量类型(局域声明变量及全局变量)可以被混合起来.
这也允许把局部变量和一些只对系统变量有意义的选项合并起来。
举例:声明3个变量,分别为var1、var2和var3,数据类型为INT,使用SET为变量赋
值,代码如下:
declare var1, var2, var3 int; --声明三个int类型的变量
set var1 = 10, var2 = 20; --给其中的两个变量赋值数字常量
set var3 = var1 + var2; --用一个表达式给第三个变量赋值MySQL中还可以通过SELECT ... INTO为一个或多个变量赋值,语法如下:
SELECT col_name[,...] INTO var_name[,...] table_expr;
这个SELECT语法把选定的列直接存储到对应位置的变量。
col_name表示字段名称;
var_name表示定义的变量名称;
table_expr表示查询条件表达式,包括表名称和WHERE子句。
举例:声明变量fruitname和fruitprice,通过SELECT ... INTO语句查询指定记录并为变
量赋值,
代码如下:
declare fruitname char(50);
declare fruitprice decimal(8,2);
select f_name,f_price into fruitname, fruitprice
from fruits where f_id ='a1'; 4、定义条件和处理程序
特定条件需要特定处理。这些条件可以联系到错误,以及子程序中的一般流程控制。
定义条件是事先定义程序执行过程中遇到的问题,处理程序定义了在遇到这些问题时应
当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。这样可以增强存储程序处理问题的能力,避免程序异常停止运行。
本节将介绍使用 DECLARE 关键字来定义条件和处理程序。
1.定义条件
定义条件使用DECLARE语句,语法格式如下:
DECLARE condition_name CONDITION FOR [condition_type]
[condition type]:
SQLSTATE [VALUE] sqlstate_value | mysql_error_code
其中,condition_name 参数表示条件的名称;condition_type 参数表示条件的类型
sqlstate_value和mysql_error_code 都可以表示MySOL 的错误,
sqlstate_value 为长度为5的字符串类型错误代码,mysql_error_code 为数值类型错误代码。
例如:ERROR 1142(42000)中,sqlstate_value的值是42000,mysql_error_code的值是1142。
这个语句指定需要特殊处理的条件。它将一个名字和指定的错误条件关联起来。这个名字可以随后被用在定义处理程序的DECLARE HANDLER语句中.
举例:定义"ERROR 1148(42000)"错误,名称为command_not_allowed。
可以用两种不同的方法来定义,代码如下:
//方法一:使用sqlstate_value
declare command_not_allowed condition for sqlstate '42000';//方法二:使用mysql_error_code
declare command_not_allowed condition for 1148 ;2、定义处理程序
定义处理程序时,使用DECLARE语句的语法如下:
DECLARE handler_type HANDLER FOR condition_value [,...] sp_statement
handler type:
CONTINUE | EXIT | UNDO
condition value:
SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT EOUND
| SQLEXCEPTION
| mysql_error_code
其中,
handler type 为错误处理方式,参数取 3个值:CONTINUE、EXIT 和UNDO
CONTINUE 表示遇到错误不处理,继续执行:
EXIT 遇到错误马上出:
UNDO表示遇到错误后撤回之前的操作,MySQL中暂时不支持这样的操作。
condition_value表示错误类型,可以有以下取值:
SQLSTATE [VALUE] sqlstate_value:包含5个字符的字符串错误值;
condition_name:表示DECLARE CONDITION定义的错误条件名称;
SQLWARNING:匹配所有以01开头的SQLSTATE错误代码
NOTFOUND:匹配所有以02开头的SOLSTATE错误代码·
SQLEXCEPTION:匹配所有没有被SOLWARNING或NOTFOUND 捕获的SOLSTATE错误代码。
mysql_error_code:匹配数值类型错误代码
sp_statement参数为程序语句段表示在遇到定义的错误时,需要执行的存储过程或函数
举例:定义处理程序的几种方式,代码如下:
//方法一:捕获sqlstate_value (错误值)
declare continue handler for sqlstate '42002' set @info='NO_SUCH_TABLE'; //方法二:捕获mysql_error_code (错误码)
declare continue handler for 1146 set @info=' NO_SUCH_TABLE '; //方法三:先定义条件,然后调用
declare no_such_table condition for 1146;
declare continue handler for no_such_table set @info='NO_SUCH_TABLE '; //方法四:使用SQLWARNING (警告)
declare exit handler for sqlstate set @info='ERROR'; //方法五:使用NOT FOUND (没有找到)
declare exit handler for not found set @info=' NO_SUCH_TABLE '; //方法六:使用SQLEXCEPTION(其他)
declare exit handler for sqlexception set @info='ERROR'; 上述代码是6种定义异常处理程序的方法
第一种方法是捕获 sqlstate_value 值。如果遇到sqlstate value 值为“42S02”,执行CONTINUE 操作,并且输出“NOSUCHTABLE”信息。
第二种方法是捕获mysql_error_code值。如果遇到MySQL error code值为1146,执行CONTINUE 操作,并且输出“NOSUCH TABLE”信息。
第三种方法是先定义条件,然后再调用条件。这里先定义no such table条件,遇到1146 错误就执行CONTINUE操作。
第四种方法是使用SQLWARNING。SQLWARNING捕获所有以01开头的sqlstate value值,然后执行EXIT操作,并且输出“ERROR”信息。
第五种方法是使用NOT FOUND。NOT FOUND 捕获所有以02开头的sqlstate_value值然后执行EXIT操作,并且输出“NOSUCH TABLE”信息。
第六种方法是使用SQLEXCEPTION。SOLEXCEPTION 捕获所有没有被SOLWARNING或NOTFOUND捕获的sqlstate value值,然后执行EXIT操作,并且输出“ERROR”信息。
举例:
定义条件和处理程序,具体执行的过程如下:
create table t (s1 int,primary key (s1));
delimiter //
create procedure handlerdemo ()
begin
declare continue HANDLER for sqlstate '23000' set @x2 = 1;
set @x = 1;
insert into test.t values (1);
set @x = 2;
insert into test.t values (1);
set @x = 3;
end //
delimiter ; 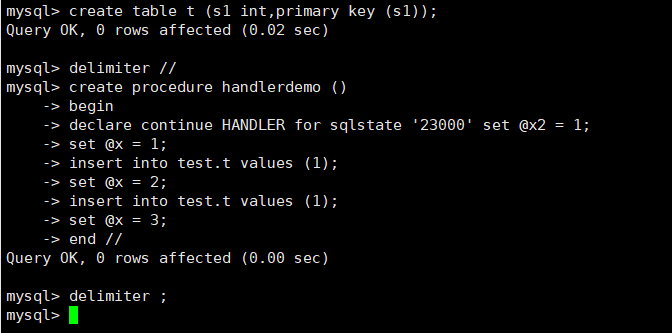
/*调用存储过程*/
call handlerdemo();
/*查看调用过程结果*/
select @x; 
@x是1个用户变量,执行结果@x 等于 3,这表明 MySQL 被执行到程序的末尾。
如果“DECLARE CONTINUE HANDLER FORSQLSTATE23000 SET @x2=1;” 这1行不存在 第2个INSERT因PRIMARYKEY强制而失败之后MySOL可能已经采取默认(EXIT)路径并且 SELECT@x可能已经返回2。
”@var name”表示用户变量,使用 SET 语句为其赋值,用户变量与连接有关,一个客户端 定义的变量不能被其他客户端看到或使用。当客户端退出时,该客户端连接的所有变量将自动释放。
5、光标的使用(MySQL中光标只能在存储过程和函数中使用。)
查询语句可能返回多条记录,如果数据量非常大,需要在存储过程和储存函数中使用
光标 来逐条读取查询结果集中的记录。应用程序可以根据需要滚动或浏览其中的数据。
本节将介绍如何声明、打开、使用和关闭光标。
光标必须在声明处理程序之前被声明,并且变量和条件还必须在声明光标或处理程序之
前被声明。
1.声明光标
MySQL中使用DECLARE关键字来声明光标,其语法的基本形式如下:
DECLARE cursor_name CURSOR FOR select_statement
其中cursor_name参数表示光标的名称;
select_statement参数表示SELECT语句的内容返回一个用于创建光标的结果集。
举例:
声明名称为cursor_fruit的光标,代码如下:
declare cursor_fruit cursor for select f_name, f_price from fruits ; 上面的示例中,
光标的名称为cur_fruit,SELECT语句部分从fruits表中查询出f_name和f_price字
段的值。
2.打开光标
打开光标的语法如下:
OPEN cursorname(光标名称)
这个语句打开先前声明的名称为cursorname的光标。
举例: Open cursor_fruit;
3.使用光标
使用光标的语法如下:
FETCH cursor_name INTO var_name [,var_name] ...{参数名称)
其中cursor_name参数表示光标的名称;
var_name参数表示将光标中的SELECT语句查询出来的信息存入该参数中,
var_name必须在声明光标之前就定义好。
举例:
使用名称为cursor_fruit的光标。将查询出来的数据存入fruit_name和fruit_price这两个变量中,
代码如下:
fetch cursor_fruit into fruit_name, fruit_price ; 上面的示例中,将光标cursor_fruit中SELECT语句查询出来的信息存入fruit_name
和fruit_price中。 fruit_name和fruit_price必须在前面已经定义。
DECLARE fruit_name CHAR(50);
DECLARE fruit_price DECIMAL(8,2);
4.关闭光标
关闭光标的语法如下:
CLOSE cursor_name{光标名称]
这个语句关闭先前打开的光标如果未被明确地关闭,光标在它被声明的复合语句的末尾被关闭。
举例: CLOSE cursor_fruit;
例子:
delimiter //
create procedure get_name_price()
begin
declare fruit_name char(255);
declare fruit_price decimal(8,2);
declare cursor_fruit cursor for select f_name,f_price from fruits;
open cursor_fruit;
read_loop: loop
fetch cursor_fruit into fruit_name,fruit_price;
select fruit_name,fruit_price;
end loop;
close cursor_fruit;
end //
delimiter ;
查看

游标使用案例:
首先创建一个学生表并插入一些数据:
create table students (id int ,name text);
insert into students values (1,'zhangsan'),(2,'lisi'),(3,'wangwu'),(4,'zhaoliu'); 
delimiter //
create procedure get_all_students()
begin
declare done int default false; -- 定义游标是否结束的标志
declare s_id int; -- 存储查询结果中的学生编号
declare s_name varchar(255); -- 存储查询结果中的学生姓名
declare cursor_students cursor for select id, name from students; -- 声明游标,查询表 student 中的所有数据
-- 打开游标
open cursor_students;
-- 遍历游标指向的结果集
read_loop: loop
-- 获取游标指向的当前行
fetch cursor_students into s_id, s_name; ---遍历游标得到的实际数据值
-- 如果游标到达结果集的末尾,则跳出循环
if done then
leave read_loop;
end if;
-- 输出当前行的值
select s_id, s_name;
end loop;
-- 关闭游标
close cursor_students;
end //
delimiter ;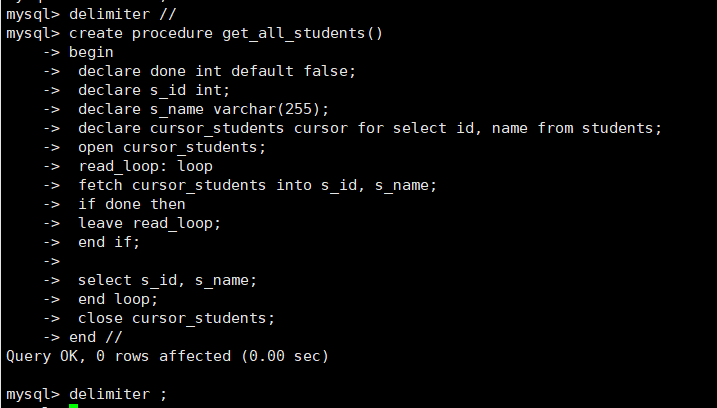
查看
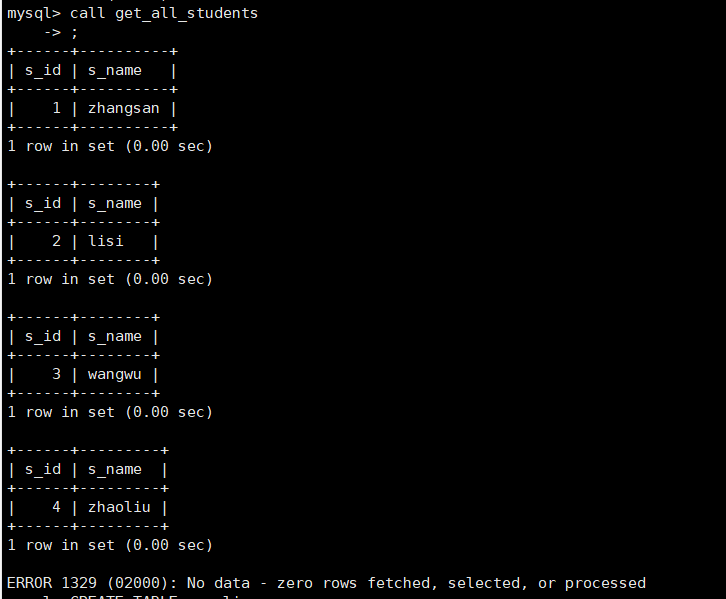
在上面的示例中,声明了一个名为 cursor_students 的游标,用于查询表 students 中的所有数据。打开游标后,使用 read_loop 循环体遍历查询结果集,并使用 FETCH 命令获取当前行的值存储到变量 s_id和 s_name 中,并输出到控制台。如果游标到达结果集的末尾,则跳出循环。当游标使用完毕后,需要使用 CLOSE 命令关闭游标。虽然游标为开发者提供了一种方便的查询结果集的方式,但由于其需要使用额外的内存和资源,
因此在使用时需要格外注意以下几个问题:
1,游标会影响性能,特别是在处理大型数据集时。不建议在大规模或高并发环境中使用游标,应该优先考虑使用其他方式,例如子查询和 JOIN 操作等。
2,游标只能在存储过程中使用,无法直接在 SQL 语句中使用。
3,游标的使用需要谨慎,因为如果没有正确关闭游标,会导致 MySQL 数据库占用大量的内存资源,甚至出现崩溃的情况。
通常情况下,游标适用于以下几个场景:
1,需要在存储过程中实现复杂查询逻辑的情况。
2,需要分批次处理大型数据集的情况。
3,需要对查询结果集进行逐行处理的情况。
6、流程控制的使用:
流程控制语句用来根据条件控制语句的执行。MySQL 中用来构造控制流程的语句
有:IF 语句、 CASE 语句、LOOP 语句、LEAVE 语、ITERATE 语、REPEAT语和WHILE语句。
每个流程中可能包含一个单独语句,或者是使用BEGIN...END构造的复合语句,构造可以被嵌套。
本节将介绍这些控制流程语句。
1.IF语句
IF语句包含多个条件判断,根据判断的结果为 TRUE或FALSE 执行相应的语句,语法格
式如下:
IF expr_condition THEN statement_list
[ ELSEIF expr_condition THEN statement list] ...
[ ELSE statement list]
END IF
IF实现了一个基本的条件构造。如果expr_condition 求值为真(TRUE),相应的SQL语句
列表被执行
如果没有expr_condition 匹配 则ELSE子句里的语列表被执行statement_list可以包括一
个或多个语句。
注意:MySQL中还有一个IF()函数,它不同于这里描述的IF 语句。
举例:IF语句的示例,代码如下:
if val is null then select 'val is NULL';
else select 'val is not NULL';
end if;举例
delimiter //
create procedure doiterate1()
begin
declare val int;
if val is null then select 'val is NULL';
else select 'val is not NULL';
end if;
end //
delimiter ;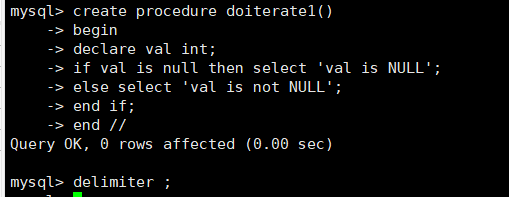
调用
call doiterate1();
该示例判断val值是否为空,如果val值为空,输出字符串“valisNULL”;
否则输出字符串“val is not NULL”。IF语都需要使用ENDIF来结束。
2.CASE语句
CASE是另一个进行条件判断的语句,该语句有2种语句格式,第1种格式如下:
CASE case_expr
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list]
[ELSE statement_list]
END CASE
其中,case_expr 参数表示条件判断的表达式,决定了哪一个 WHEN 子句会被执行:
when_value参数表示表达式可能的值如果某个when_value表达式与case_expr表达式结
果相同,
则执行对应THEN关键字后的 statement_list 中的语句:
statement_list 参数表示不同when_value值的执行语句。
使用CASE流程控制语句的第1种格式,判断val值等于1、等于2,或者两者都不等,语
句如下:
delimiter //
create procedure doiterate3()
begin
declare val int;
case val
when 1 then select 'val is 1';
when 2 then select 'val is 2';
else select 'val is not 1 or 2';
end case;
end //
delimiter ;
调用:
call doiterate3();
CASE语句的第2种格式如下:
case val
when expr_condition then statement_list;
[when expr_condition then statement_list];
else statement_list;
end case;
case val
when expr_condition then statement_list;
[when expr_condition then statement_list];
else statement_list;
end case;其中,expr_condition 参数表示条件判断语句;statement_list 参数表示不同条件的执
行语句。
该语句中,WHEN语句将被逐个执行,直到某个expr_condition表达式为真,
则执行对应THEN关键字后面的statement_list语。如果没有条件匹配,ELSE子里的语
句被执行。
这里介绍的用在存储程序里的CASE语与“控制流程函数”里描述的SQL CASE表达式的
CASE语句
有轻微不同。这里的 CASE 语不能有ELSE NULL字句,并且用END CASE替代END来终
止。
使用CASE流程控制语句的第2种格式,判断val是否为空、小于0、大于0或者等于0,
语句如下:
delimiter //
create procedure doiterate4()
begin
declare val int default 2;
case val
when val < 2 then select 'val is less 2';
when val > 2 then select 'val is greater than 2';
else select 'val is 2 ';
end case;
end //
delimiter ;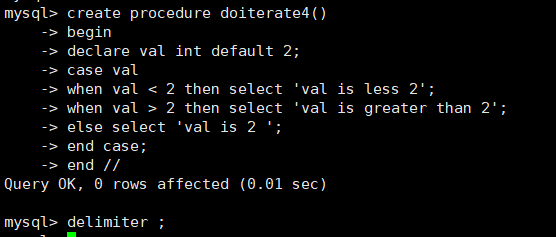
调用
call doiterate4();
3.LOOP语句
LOOP循环语句用来重复执行某些语句,与F和CASE语相比,LOOP 只是创建一个循环
操作的过程,
并不进行条件判断。LOOP 内的语句一直重复执行直到循环被退出,跳出循环过程,使用LEAVE子句,LOOP语句的基本格式如下:
[loop_label:] LOOP
statement_list
END LOOP [loop_label
loop_label表示LOOP 语句的标注名称,该参数可以省略;
statement_list 参数表示需要循环执行的语句。
举例:使用LOOP语句进行循环操作,id值小于等于10之前,将重复执行循环过程,代
码如下:
delimiter //
create procedure testproc4()
begin
declare id int default 0;
add_loop: loop
set id = id + 1;
if id >= 10 THEN LEAVE add_loop;
end if;
end loop add_loop;
select id ;
end //
delimiter ;
该示例循环执行id加1的操作。当id值小于10时,循环重复执行,
当d 值大于或者等于10时,使用LEAVE语句退出循环。
LOOP循环都以END LOOP结束
4、LEAVE语句
LEAVE语句用来退出任何被标注的流程控制构造,LEAVE语句基本格式如下:LEAVE label
其中,label参数表示循环的标志。LEAVE和BEGIN...END或循环一起被使用
举例:使用LEAVE语句退出循环,代码如下:
add_num: LOOP
SET @count=@count+1;
IF @count=50 THEN LEAVE add_num ;
END LOOP add_num ;
该示例循环执行count加1的操作。当count的值等于50时,使用LEAVE语句跳出循环。
5.ITERATE语句
ITERATE语句将执行顺序转到语句段开头处,语句基本格式如下:ITERATE label
ITERATE只可以出现在LOOP、REPEAT和WHILE语内。ITERATE的意思为“再次循环”,
label参数表示循环的标志。ITERATE语句必须跟在循环标志前面。
举例:
ITERATE语句示例,代码如下:
delimiter //
create procedure doiterate2()
begin
declare p1 int default 0;
my_loop: loop
set p1= p1 + 1;
if p1 < 10 then iterate my_loop;
elseif p1 > 20 then LEAVE my_loop;
end if;
select 'p1 is between 10 and 20',p1;
end loop my_loop;
end //
delimiter ;
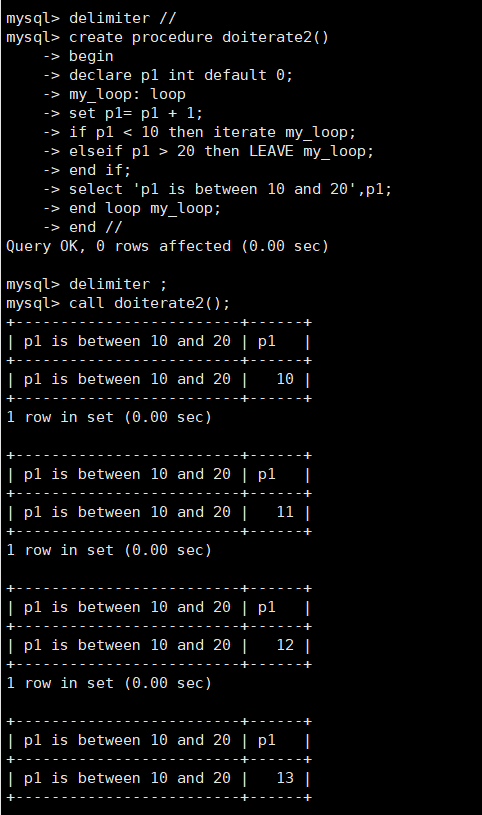
执行过程是:
p1=0,如果p1的值小于10时,重复执行p1加1操作;
当p1大于等于10并且小于20时,打印消息“plis between 10and 20”;
当p1大于20时,退出循环。
6.REPEAT语句
REPEAT语句创建一个带条件判断的循环过程,每次语句执行完毕之后,
会对条件表达式进行判断,如果表达式为真,则循环结束:否则重复执行循环中的语
句。
REPEAT 语句的基本格式如下:
[repeat_label:] repeat
statement_list
UNTIL expr_condition
end repeat [repeat_label] 其中repeat_label为REPEAT语句的标注名称,该参数可以省略;
REPEAT语内的语句或语句群被重复,直至exprcondition为真。
举例:
REPEAT语句示例,id值小于等于10之前,将重复执行循环过程,代码如下:
delimiter //
create procedure doiterate5()
begin
declare id int default 0;
repeat
set id = id +1;
until id >=10
end repeat;
end //
delimiter ;
该示例循环执行id加1的操作。
当id值小于10时,循环重复执行;
当id值大于或者等于10时,使用LEAVE语句退出循环。
REPEAT循环都以END REPEAT结束。
7.WHILE语句
WHILE语句创建一个带条件判断的循环过程与REPEAT不同,WHILE在执行语句时先对
指定的表达式进行判断,如果为真,则执行循环内的语句,否则退出循环。
WHILE 语句的基本格式如下:
[while_label:] WHILE expr_condition DO
statement_list
END WHILE [while_label]
while_label为WHILE语句的标注名称;expr_condition 为进行判断的表达式如果表达式结果为真,
WHILE语句内的语句或语句群被执行,直至expr_condition为假,退出循环。
举例:WHILE语句示例,id值小于等于10之前,将重复执行循环过程,代码如下:
delimiter //
create procedure doiterate6()
begin
declare i int default 0;
while i < 10 do
set i = i + 1;
end while;
end //
delimiter ;
7、查看存储过程和函数
MySQL存储了存储过程和函数的状态信息用户可以使用SHOW STATUS语或SHOW CREATE
语句来查看,也可直接从系统的information schema数据库中查询。本节将通过实例来介绍这3种方法。
1、使用SHOW STATUS 语查看存储过程和函数的状态
SHOW STATUS 语句可以查看存储过程和函数的状态,其基本语法结构如下:
SHOW { PROCEDURE | FUNCTION } STATUS [ LIKE 'pattern']
这个语句是一个MySOL的扩展。它返回子程序的特征,如数据库、名字、类型、创建
者及创建和修改日期。如果没有指定样式,根据使用的语句,所有存储程序或存储函数的信息
都被列出。
PROCEDURE和FUNCTION分别表示查看存储过程和函数;LIKE语句表示匹配存储过程或函数的名称。
举例:SHOW STATUS语句示例,代码如下:
show procedure status like 'C%'\G 
“SHOW PROCEDURE STATUS LIKE C%\G”语取数据库中所有名称以字母“C“开头
的存储过程的信息。通过上面的语句可以看到:这个存储函数所在的数据库为 test、存储函数的名
称为CountProc等一些相关信息。
2.使用SHOW CREATE语查看存储过程和函数的定义除了SHOW STATUS之外,
MySQL还可以使用SHOWCREATE 语句查看存储过程和函数的状态。
SHOW CREATE { PROCEDURE | FUNCTION} sp_name
这个语句是一个MySOL的扩展。类似于SHOW CREATE TABLE,它返回一个可用来重
新创建已命名子程序的确切字符串。PROCEDURE和FUNCTION分别表示查看存储过程和函数;
sp_name参数表示匹配存储过程或函数的名称。
举例:SHOW CREATE语句示例,代码如下:
show create function test.CountProc2 \G ;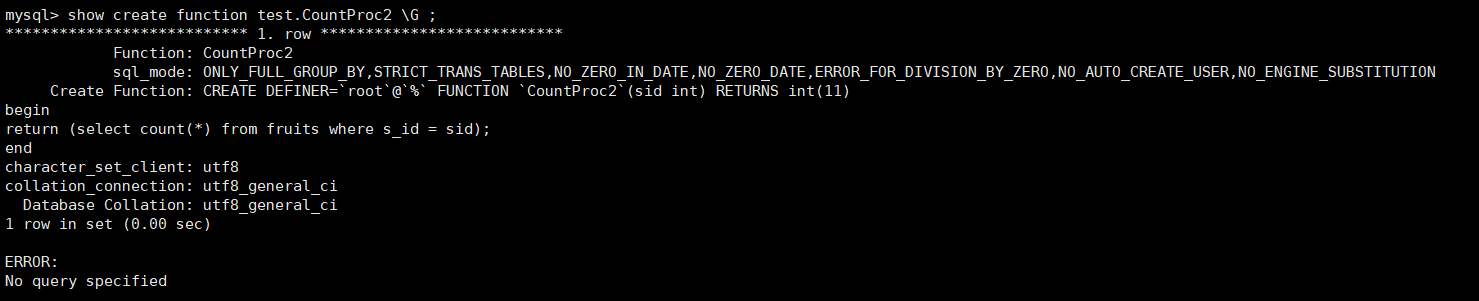
执行上面的语句可以得到存储函数的名称为CountProc2,sqlmode为SQL的模式,
CreateFunction为存储函数的具体定义语句,还有数据库设置的一些信息。
3. 从information_schema.Routines 表中查看存储过程和函数的信息
MySOL中存储过程和函数的信息存储在information_schema数据库下的Routines表中
可以通过查询该表的记录来查询存储过程和函数的信息。其基本语法形式如下:
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='sp_name'
其中,ROUTINENAME字段中存储的是存储过程和函数的名称;
sp_name参数表示存储过程或函数的名称。
查询所有存储过程:
select * from information_schema.Routines
where ROUTINE_TYPE = 'procedure' \G查询所有的存储函数:
select * from information_schema.Routines
where ROUTINE_TYPE = 'FUNCTION' \G举例:从Routines表中查询名称为CountProc的存储函数的信息,代码如下:
select * from information_schema.Routines
where ROUTINE_NAME='CountProc2' and ROUTINE_TYPE = 'FUNCTION' \G ;
在information schema数据库下的 Routines 表中,存储所有存储过程和函数的定义。
使用SELECT语句查询 Routines 表中的存储过程和函数的定义时,一定要使用ROUTINE_NAME 字段指定存储过程或函数的名称。否则,将查询出所有的存储过程或函数的定义。
如果有存储过程和存储函数名称相同则需要同时指定ROUTINE_TYPE字段表明查询的是哪种类型的存储程序。
8、修改删除过程和函数
使用ALTER语句可以修改存储过程或函数的特性,
ALTER {PROCEDURE | FUNCTION) sp_name [characteristic ...]
其中,sp_name参数表示存储过程或函数的名称
characteristic 参数指定存储函数的特性可能的取值有:
CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句。
NOSQL 表示子程序中不包含 SQL语句。
READS SQL DATA 表示子程序中包含读数据的语句
MODIFIES SQL DATA表示子程序中包含写数据的语句
SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行
DEFINER表示只有定义者自己才能够执行。
INVOKER表示调用者可以执行
COMMENT ‘string’表示注释信息
修改存储过程使用ALTER PROCEDURE 语句,修改存储函数使用ALTER FUNCTION语句。
但是,这两个语句的结构是一样的,语句中的所有参数也是一样的。而且,它们与创建存储过程或函数的语句中的参数也是基本一样的。
加注释:
ALTER PROCEDURE test_proc COMMENT '这是一个测试存储过程';
ALTER PROCEDURE testProc4 COMMENT '这是一个测试存储过程';
修改安全性:
将读写权限改为MODIFIES SQL DATA,并指明调用者可以执行,代码如下:
ALTER PROCEDURE testProc4
MODIFIES SQL DATA
SQL SECURITY INVOKER ;
举例:修改存储过程CountProc的定义。将读写权限改为MODIFIES SQL DATA,
并指明调用者可以执行,代码如下:
alter procedure CountProc
modifies sql data
sql SECURITY INVOKER ; 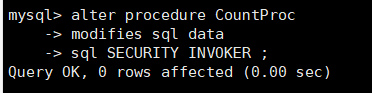
执行代码,并查看修改后的信息。结果显示如下:
//查询修改后的CountProc表信息
select SPECIFIC_NAME,SQL_DATA_ACCESS,SECURITY_TYPE
from information_schema.Routines
where ROUTINE_NAME='CountProc' and ROUTINE_TYPE='PROCEDURE'; 
结果显示,存储过程修改成功。从查询的结果可以看出,
访问数据的权限(SQL DATAACCESS)已经变成MODIFIES SQL DATA,
安全类型(SECURITY TYPE)已经变成了INVOKER。
举例2:修改存储函数CountProc的定义。将读写权限改为READS SQL DATA,
并加上注释信息“FIND NAME”,代码如下:
alter function CountProc2
reads sql data
comment 'FIND NAME' ; 
执行代码,并查看修改后的信息。结果显示如下:
//查询修改后f表的信息
select SPECIFIC_NAME,SQL_DATA_ACCESS,ROUTINE_COMMENT
from information_schema.Routines
where ROUTINE_NAME='CountProc2' and ROUTINE_TYPE = 'FUNCTION' ; 
存储函数修改成功。从查询的结果可以看出,
访问数据的权限 (SQL DATA ACCESS)已经变成READS SQLDATA,
函数注释(ROUTINE COMMENT)已经变成了FIND NAME
删除存储过程和函数,可以使用 DROP 语句,其语法结构如下
DROP (PROCEDURE | FUNCTION ) [ IF EXISTS ] sp_name
这个语句被用来移除一个存储过程或函数。sp_name为要移除的存储过程或函数的名称 IF EXISTS 子句是一个MYSQL 的扩展。如果程序或函数不存储,它可以防止发生错误产 生一个用SHOW WARNINGS 查看的警告。
举例:
删除存储过程和存储函数,代码如下:
drop procedure CountProc;
drop function CountProc2; 语句的执行结果如下:
上面语句的作用就是删除存储过程CountProc和存储函数CountProc2。
9、练习题
注意事项:
疑问1:MySQL存储过程和函数有什么区别?
在本质上它们都是存储程序。函数只能通过return语句返回单个值或者表对象;
而存储过程不允许执行 return 语句,但是可以通过 out 参数返回多个值。
函数限制比较多,不能用临时表,只能用表变量,还有一些函数都不可用等等;
而存储过程的限制相对就比较少。函数可以嵌入在SQL语句中使用,
可以在SELECT语句中作为查询语句的一个部分调用;
而存储过程一般是作为一个独立的部分来执行。
疑问2:存储过程中的代码可以改变吗?
目前,MvSOL 还不提供对已存在的存储过程代码的修改,如果必须要修改存储过程,必须使用DROP语句删除之后,再重新编写代码,或者创建一个新的存储过程。
疑问3:存储过程中可以调用其他存储过程吗?
存储过程包含用户定义的SQL语句集合,可以使用CALL 语句调用存储过程,当然在存储过程中也可以使用 CALL 语句调用其他存储过程,但是不能使用 DROP 语删除其他存储过程。
疑问4:存储过程的参数不要与数据表中的字段名相同
在定义存储过程参数列表时,应注意把参数名与数据库表中的字段名区别开来,否则将出现无法预期的结果。
疑问5:存储过程的参数可以使用中文吗?
一般情况下,可能会出现存储过程中传入中文参数的情况,例如某个存储过程根据用
户的名字查找该用户的信息,传入的参数值可能是中文。这时需要在定义存储过程的时候,在后面加上character set gbk 不然调用存储过程使用中文参数会出错比如定义userInfo存储过程代码如下:
CREATE PROCEDURE useInfo(IN u_name VARCHAR(50) character set gbk, OUT
u_age INT);
练习题:
(1)写个HelloWord的存储过程和函数
存储过程
delimiter //
create procedure helloword(out h char(50))
begin
declare h1 char(50);
set h1 = 'helloword';
select h1 into h;
end //
delimiter ;
call helloword(@h);
select @h;存储函数
delimiter //
create function hw()
returns char(50)
return ('helloword');
//
delimiter ;
select hw();(2)写一个完整的包括参数、变量、变量赋值、条件判断、UPDATE语句、SELECT返回结果
集的存储过程。
delimiter //
create procedure p2(out h char(50))
begin
declare h1 int(50);
set h1 = 1;
if h1 = 1 then select 'h1 is 1';
else select 'h1 is not 1';
end if;
select h1 into h;
end //
delimiter ;
call p2(@a);
select @a;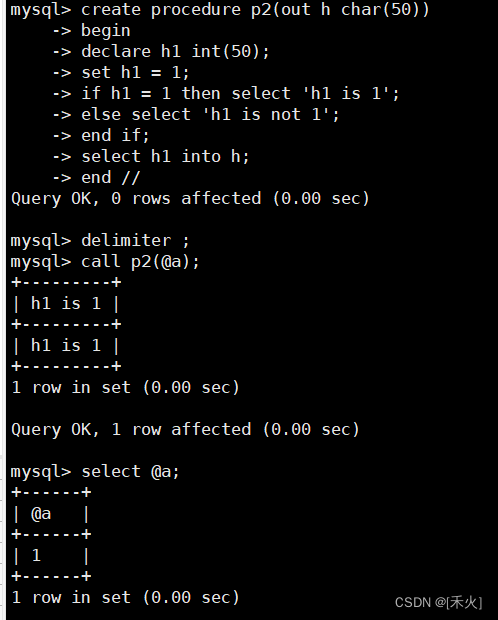
(3)创建一个执行动态SOL的存储过程。
delimiter //
create procedure pp(in sid int,out num int)
begin
select count(*) into num from fruits where s_id = sid;
end //
delimiter ;
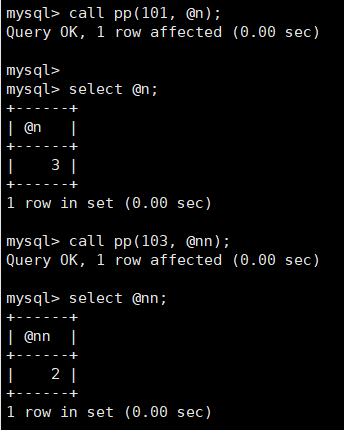
call pp(101, @n);
select @n;
call pp(103, @nn);
select @nn; 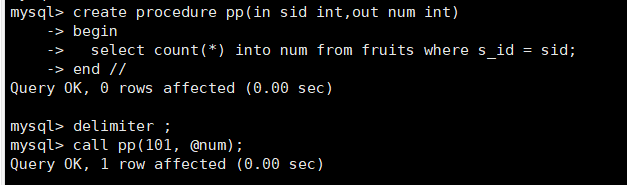
(4)创建实现功能相同的存储函数,比较他们之间的不同点在什么地方?
delimiter //
create function p1(n int)
returns int
begin
declare var int;
set var = 0;
while n>0 do
set var = var + n;
set n = n -1;
end while;
return var;
end //
delimiter ;
select p1(5);
select p1(6);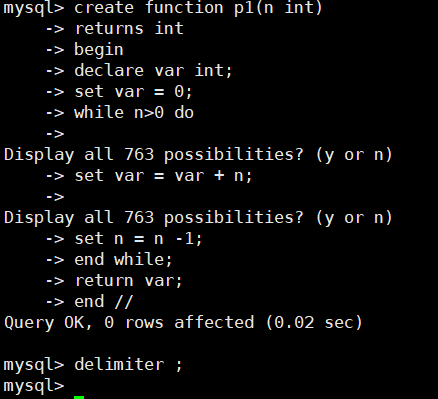

delimiter //
create function p4(n int)
returns int
begin
declare var int;
set var = 0;
if n>0 then set
var = var + n;
set n = n -1;
end if;
return var;
end //
delimiter ;
select p4(5);
select p4(6);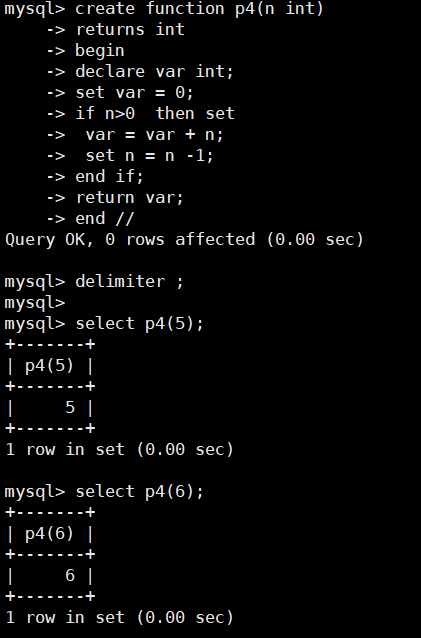















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









