






1. 概念
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。 在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合进行合并。在此过程中要反复用到查询某一个元素归属于具体集合的运算。
2.原理
下面通过一个具体的场景描述一下并查集的原理
总公司组织下属子公司员工进行团建,其中A公司4人,B公司3人,C公司3人,10个人分别来自不同的组,起先互不相识,每个员工都是一个独立的小队,现给这些员工进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};每个子公司的员工自发组织成小队一起到达目的地,于是:A公司小队s1={0,3,5,7},B公司小队s2={1,2,8},C公司小队s3={4,6,9}就相互认识了,10个人形成了三个小团队。
按照概念将三组小队用树表示,以编号最小的员工作为根节点
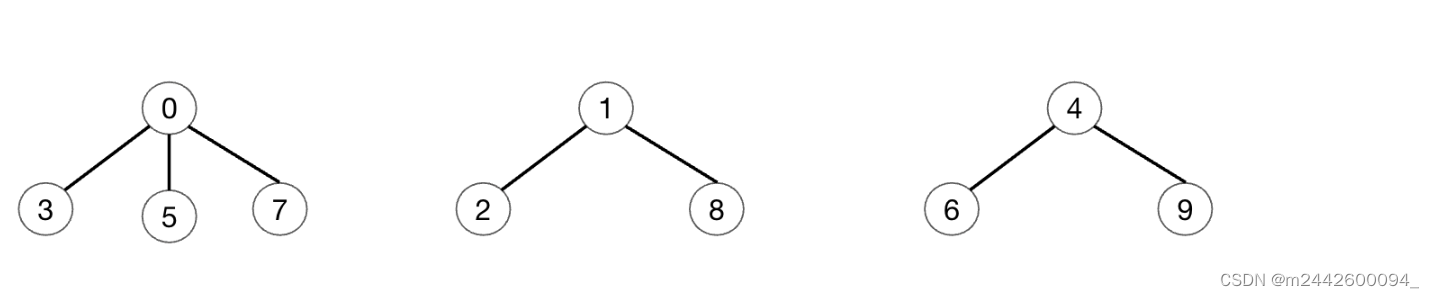
使用数组进行后续存储,将元素的初始化为对应的下标,初始化的数据如下图所示:

2.1合并节点
现有分组:
A公司小队s1={0,3,5,7},B公司小队s2={1,2,8},C公司小队s3={4,6,9},
合并策略
将子节点的下标调整为最上层的根节点下标,根节点的下标保持不变,此时的数组会变成下图所示
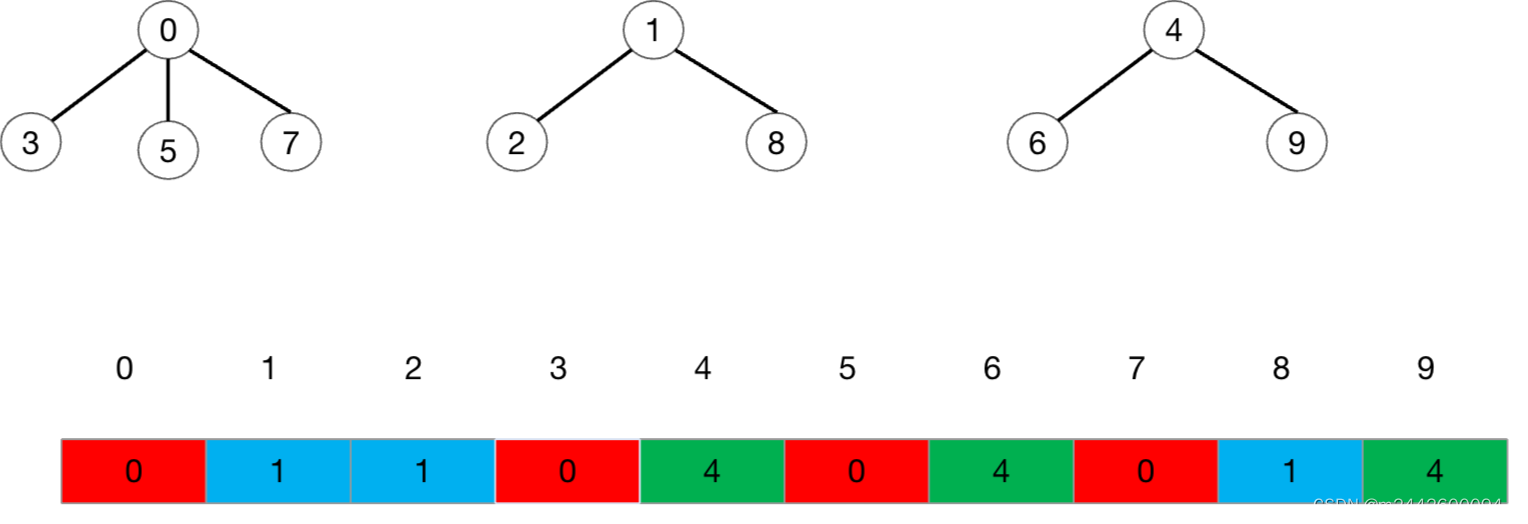
此时数组数组存在以下特点:
1. 数组的下标对应集合中元素的编号
2. 对于每个位置来说,如果它存的值是其下标,那它就是根,如果不是其下标,那它存的就是它的父结点的下标。
情景继续:
团建了一段时间后,A公司3号员工与B公司2号员工慢慢熟悉起来了,两个小队的其他员工也经过相互介绍,最后融合成了一个小队
那上面这种情况对应到数组中该怎么做呢?
是否可以和上述操作一样,直接将3号元素的坐标修改2?

目前看这样显然不行,这样等于把3从原先的小队中脱离,然后加到2这棵树里面。 但是目的是要把这两个小队进行合并啊。
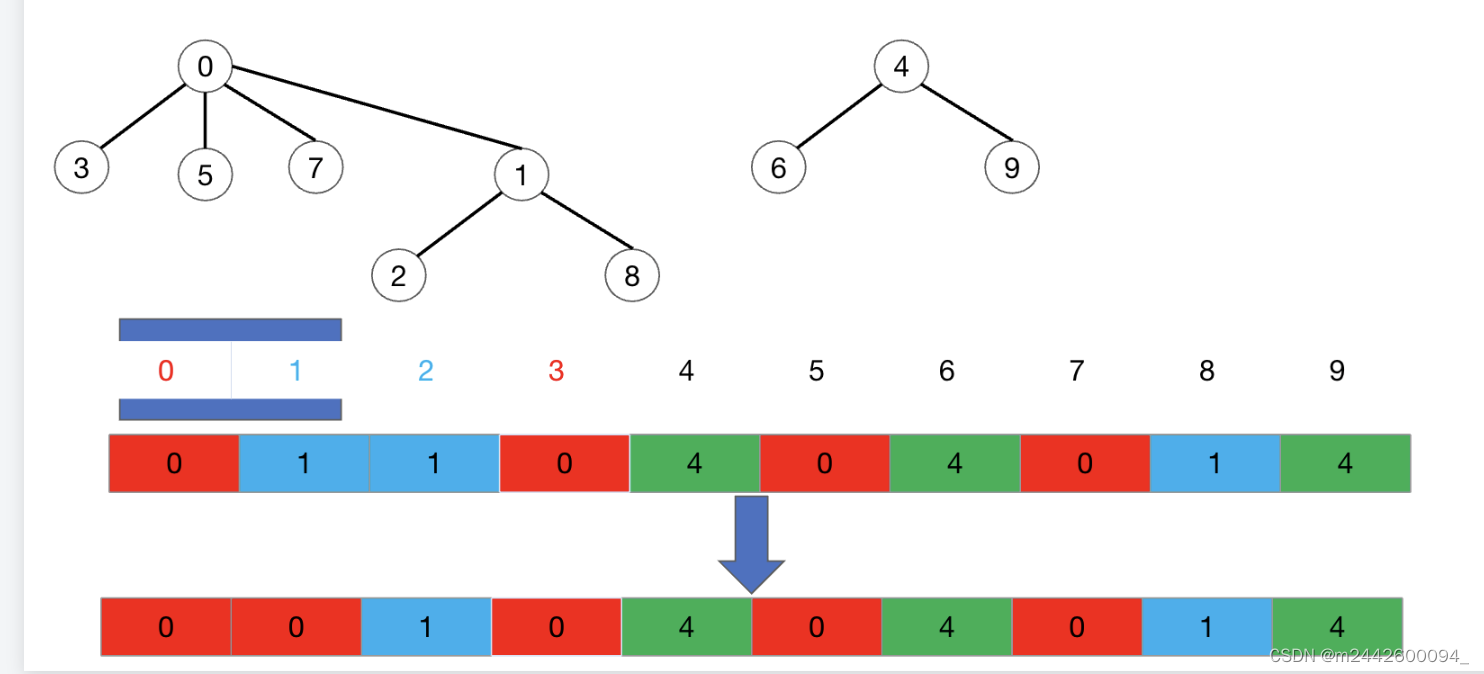
那正确的应该这样搞: 要找着两棵树的根节点,把它们的两个根合并了,这两棵树不就合并了嘛!

2.2找根节点
如何找根节点:
那很简单,看这个位置存的值是不是对应的下标,是对应下标的话就是根了;不是对应下标的话,存的就是其父节点的下标,那就顺着父结点往上找,直到值为对应下标就是最上面的根了

3找到根是0,2找到根是1然后让这两个根合并就行了,如图所示
3.并查集
3.1简单代码
public class UnionFind {
int[] cache ;
public UnionFind(int n){
cache = new int[n];
for(int i = 0 ; i < n ; i++){
cache[i] = i;
}
}
public int find(int x){
int root = x;
while (cache[root] != root){
root = cache[root];
}
return root;
}
public void union(int x,int y){
int rootX = find(x);
int rootY = find(y);
if(rootX != rootY){
if (rootX > rootY){
cache[rootX] = rootY;
}else {
cache[rootY] = rootX;
}
}
}
public static void main(String[] args) {
// 构建并查集
int[][] m = {{0,3},{0,5},{0,7},{1,2},{1,8},{4,6},{4,9}};
UnionFind uf = new UnionFind(10);
for(int[] edge : m){
uf.union(edge[0],edge[1]);
}
//结果打印
//0 1 1 0 4 0 4 0 1 4
for (int i = 0 ; i < 10 ; i++){
System.out.print(uf.find(i)+"\t");
}
System.out.println();
//3,2合并
uf.union(3,2);
//结果打印
//0 0 0 0 4 0 4 0 0 4
for (int i = 0 ; i < 10 ; i++){
System.out.print(uf.find(i)+"\t");
}
}
}
3.2 常用场景
1. 查找元素属于哪个集合(找根) 沿着数组表示的树形关系往上一直找到根(即:树中中元素为其下标的位置)
2. 查看两个元素是否属于同一个集合 沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在
3. 将两个集合归并成一个集合
4. 集合的个数 遍历数组,数组中元素为其下标的个数即为集合的个数
3.3 例题
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c直接相连,那么城市a与城市c间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。返回矩阵中 省份 的数量。
示例 1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2

整体思路:
1.初始化长度为n的数组,每个元素的值为其下标
2.依次遍历每个城市与其他城市连接情况
3.将连接的城市构建一个并查集
4.查找数组中元素为其下标的个数
代码:
class Solution {
int[] cache ;
public int find(int x){
int root = x;
while (cache[root] != root){
root = cache[root];
}
return root;
}
public void union(int x,int y){
int rootX = find(x);
int rootY = find(y);
if(rootX != rootY){
if (rootX > rootY){
cache[rootX] = rootY;
}else {
cache[rootY] = rootX;
}
}
}
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
cache = new int[n];
for (int i = 0 ; i < n ; i++){
cache[i] = i;
}
for(int i = 0 ; i < n ; i++){
for(int j = i + 1 ; j < n ; j++){
if (isConnected[i][j] == 1){
union(i,j);
}
}
}
int res = 0;
for(int i = 0 ; i < n ; i++){
if(cache[i] == i){
res++;
}
}
return res;
}
}3.4压缩优化
数据量特别大的时候,可能有些路径会比较长,导致效率变慢,这时候可以考虑进行一下压缩。
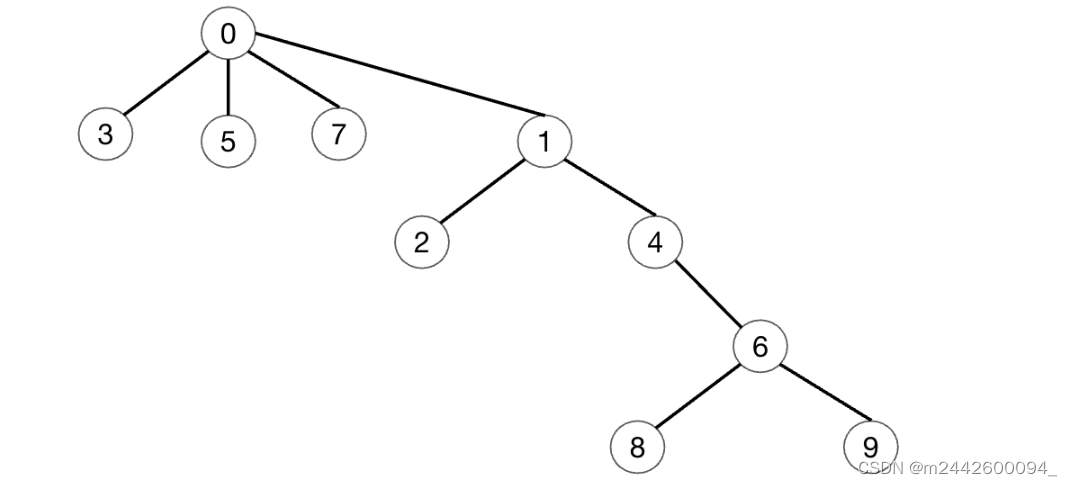
那压缩的话就是查找谁就去压缩哪条路径。 比如Find3的话,那里面判断一下,3的父亲直接就是0,就一层,那就不需要压缩。
再比如,查找9那最后发现它返回的root是0,但是9直接的上一层的父亲并不是0, 那说明它们之间有间隔层,那就可以对这条路径压缩一下。 可以直接把9变成0的孩子,那后续再查找9的话就快了。 然后也可以直接把9的上一层父亲,6直接变成0的孩子,依次上传,直到0-9这条路径上的元素的父节点都变成0
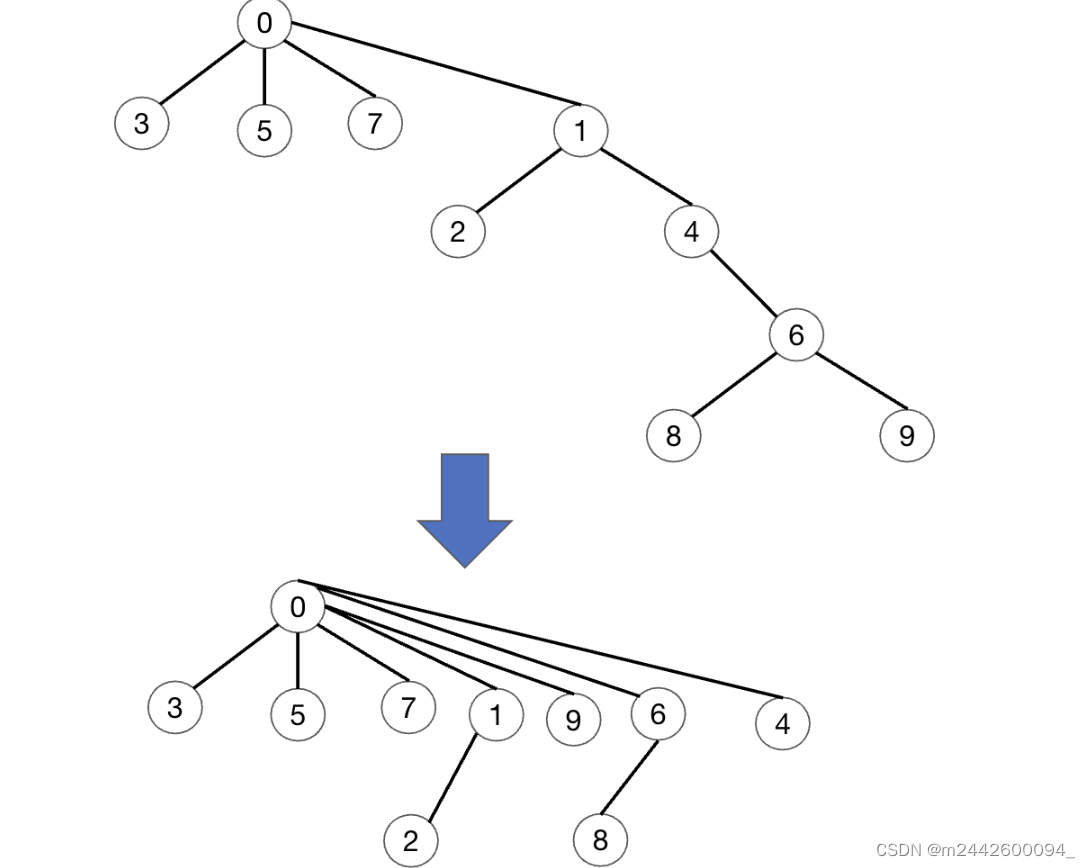
需要在find方法再加一个压缩路径的代码,其实就是先找到根结点,然后把这条查找路径上所有的结点都直接链接到根结点上。
代码改造如下:
public int find(int x){
int root = x;
while (cache[root] != root){
root = cache[root];
}
while (x != root){
//记录父节点
int parent = cache[x];
//父节点存放的下标等于根节点
cache[x] = root;
//调整当前值
x = parent;
}
return root;
}














 2857
2857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









