







今天参加了学校合作公司的笔试,记录下模糊的概念和编程题目,
1. 编程题目: 将一个正整数转换为4进制的字符串的函数
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*void SwapNum(int &a, int &b) //C语言中没有引用。。。。错误原因:::
{
if(a != b)
{
int temp;
temp = a;
a = b;
b = temp;
}
}*/
void SwapNum(char *a, char *b)
{
if(*a != *b)
{
char temp;
temp = *a;
*a = *b;
*b = temp;
}
}
void revert(long int a, char * str4)//整数转换为4进制的数
{
int A,B,i = 0,j;
char * p = str4;
while(a != 0)
{
A = a / 4;
B = a % 4;
*p = B + '0';
p++;
a = A;
i++;
}
for( j = 0; j < i / 2; j++)
{
SwapNum(&str4[j],&str4[i - j -1]);
}
str4[i] = '\0';
printf("%s\n",str4);
}
int main()
{
char s[1000];
long int input;
while(1)
{
printf("input a num:\n");
scanf("%ld",&input);
revert(input,s);
}
return 0;
}
来测试一下:
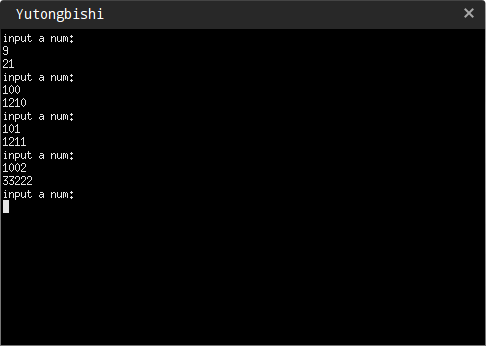
2.修改数据库表的结构使用的命令:
如果要实现MYSQL修改表结构,应该怎么做呢?使用ALTER,就可以实现MYSQL修改表结构,下面就为您介绍详细的方法,供您参考。
MYSQL修改表结构ALTER用法
项目实例:
ALTER TABLE TestResult ADD xinlinDoc longblob;
ALTER TABLE TestResult ADD xinlinDocName varchar(50);
其它实例:
CREATE TABLE t1 (a INTEGER,b CHAR(10)); // 创建的表t1开始
ALTER TABLE t1 RENAME t2; // 重命名表,从t1到t2
ALTER TABLE t2 MODIFY a TINYINT NOT NULL, CHANGE b c CHAR(20); // 为了改变列a,从INTEGER改为TINYINT NOT NULL(名字一样),并且改变列b,从CHAR(10)改为CHAR(20),同时重命名它,从b改为c:
ALTER TABLE t2 ADD d TIMESTAMP; // 增加一个新TIMESTAMP列,名为d
ALTER TABLE t2 ADD INDEX (d), ADD PRIMARY KEY (a); // 在列d上增加一个索引,并且使列a为主键
ALTER TABLE t2 DROP COLUMN c; // 删出列c
ALTER TABLE t2 ADD c INT UNSIGNED NOT NULL AUTO_INCREMENT, ADD INDEX (c); // 增加一个新的AUTO_INCREMENT整数列,命名为c。注意,我们索引了c,因为AUTO_INCREMENT柱必须被索引,并且另外我们声明c为NOT NULL,因为索引了的列不能是NULL。当你增加一个AUTO_INCREMENT列时,自动地用顺序数字填入列值。
以上就是使用ALTER实现MYSQL修改表结构的方法介绍。
3NoSQL数据库的优点(非关系型数据库)
特点:
优点:
易扩展
灵活的数据模型
高可用
缺点:
4.sizeof是在编译的时候确定的。
C语言中判断数据类型或者表达式长度符;不是一个函数,字节数的计算在程序编译时进行,而不是在程序执行的过程中才计算出来。5.主机序&网络序、入栈地址高低问题。大端模式&小端模式、
网络字节序与主机字节序是经常导致混淆的两个概念,网络字节序是确定的,而主机字节序的多样性往往是混淆的原因。
主机字节序 - 最常见的有两种
2. Big endian:将高序字节存储在起始地址
大端模式&小端模式
所谓的“大端模式”,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
所谓的“小端模式”,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,
LE little-endian
地址低位存储值的低位
地址高位存储值的高位
怎么讲是最符合人的思维的字节序,是因为从人的第一观感来说
低位值小,就应该放在内存地址小的地方,也即内存地址低位
反之,高位值就应该放在内存地址大的地方,也即内存地址高位
BE big-endian
最直观的字节序
地址低位存储值的高位
地址高位存储值的低位
为什么说直观,不要考虑对应关系
只需要把内存地址从左到右按照由低到高的顺序写出
把值按照通常的高位到低位的顺序写出
两者对照,一个字节一个字节的填充进去
4000 4001 4002 4003
LE 04 03 02 01 (值的高位存储在内存的高位,符合人们的思维)
BE 01 02 03 04 (值的高位 存储在内存的低位,打印输出方便)
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
bool am_little_endian ()
{
unsigned short i=1;
return (int)*((char *)(&i)) ? true : false;
}
int main()
{
//short int 是2个字节
printf("sizeof(short)= %d\n",sizeof(short int));
if(am_little_endian())
{
printf("LE!\n");
}else
{
printf("BE!\n");
}
return 0;
}
2.网络字节序
为了进行转换 bsd socket提供了转换的函数 有下面四个:
htons 把unsigned short类型从主机序转换到网络序
htonl 把unsigned long类型从主机序转换到网络序
ntohs 把unsigned short类型从网络序转换到主机序
ntohl 把unsigned long类型从网络序转换到主机序
在使用little endian的系统中,这些函数会把字节序进行转换
在使用big endian类型的系统中,这些函数会定义成空宏
同样,在网络程序开发时,或是跨平台开发时,也应该注意保证只用一种字节序,不然两方的解释不一样就会产生BUG。















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









