






阅读本文需要3分钟
鸣谢
在我开通公众号的第25天,腾讯邀请了我开通 “原创声明” 和文章的 “评论功能 ”。
因此在这里感谢下我的公众号用户,感谢你们一直以来的支持,我马超会一直将技术分享下去。
同时,希望各位对于我写的文章有疑问的,可以统统在文章末尾 ‘写回复’ 来描述你们的疑问。 我将第一时间回复。
扯淡
Python爬虫玩多了之后,大家应该都会发现它们有个共性:就是只能爬取单纯的html代码。那么如果页面是JS渲染的该怎么办?
如果我们单纯的去分析每一个后台的请求,手动去摸索JS渲染的一些结果,那么简直是醉了。所以,我们用一些好用的工具来帮助我们抓到像浏览器一样渲染JS处理后的页面。
这时候,NB的工具就出现了。
PhantomJS
官网地址: http://phantomjs.org
Full web stack No browser required
PhantomJS is a headless WebKit scriptable with a JavaScript API. It has fast and native support for various web standards: DOM handling, CSS selector, JSON, Canvas, and SVG.
PhantomJS是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web标准:DOM操作、CSS选择器、JSON、Canvas以及SVG。
具体的安装方法我们就不讲了。这里给个链接 http://www.tuicool.com/articles/MjUfayI
小实验
接下来我们通过一个有意思的小实验来演示下 《抓取 Github 某个仓库渲染之后的主页》
原理大概是这样的:
1、我通过Web.py搭了一个简单的WebApi,并暴露了一个通过Get请求来获取Git仓库截图的接口。
2、Get请求地址:http://127.0.0.1:9988/capture/[用户]/[仓库]。
3、通过PhantomJS来截取整个仓库打开后的页面。
4、返回仓库的截图。
超哥给大家上个效果:
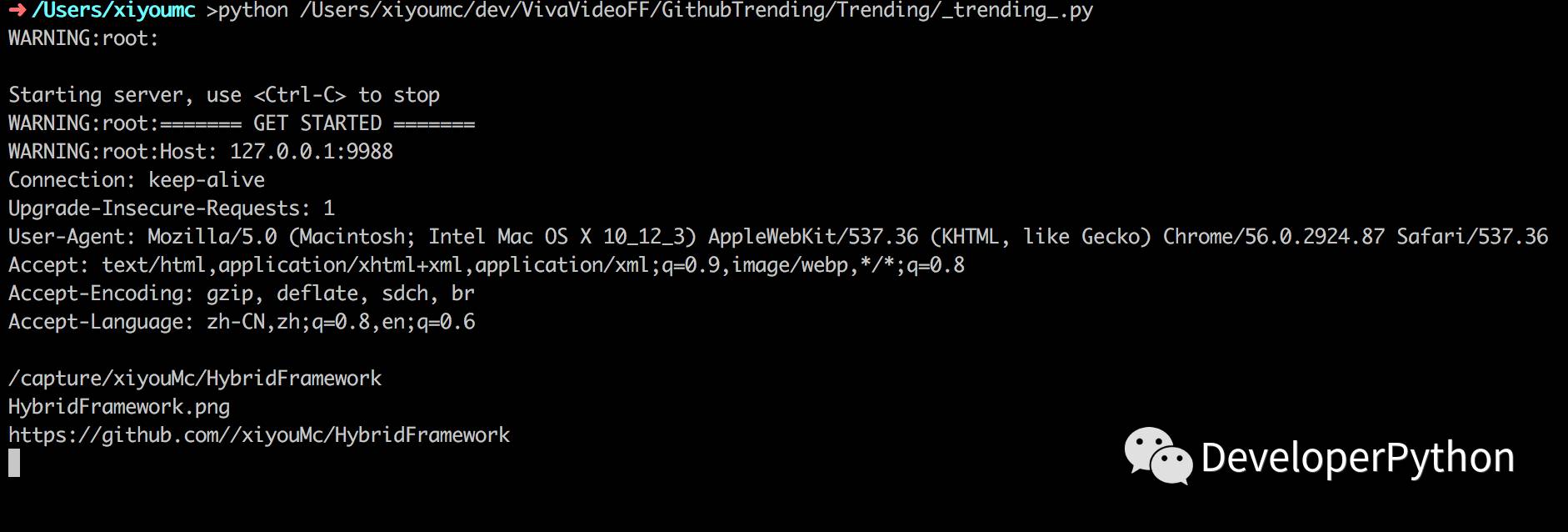
(Server.py执行后监听9988端口)
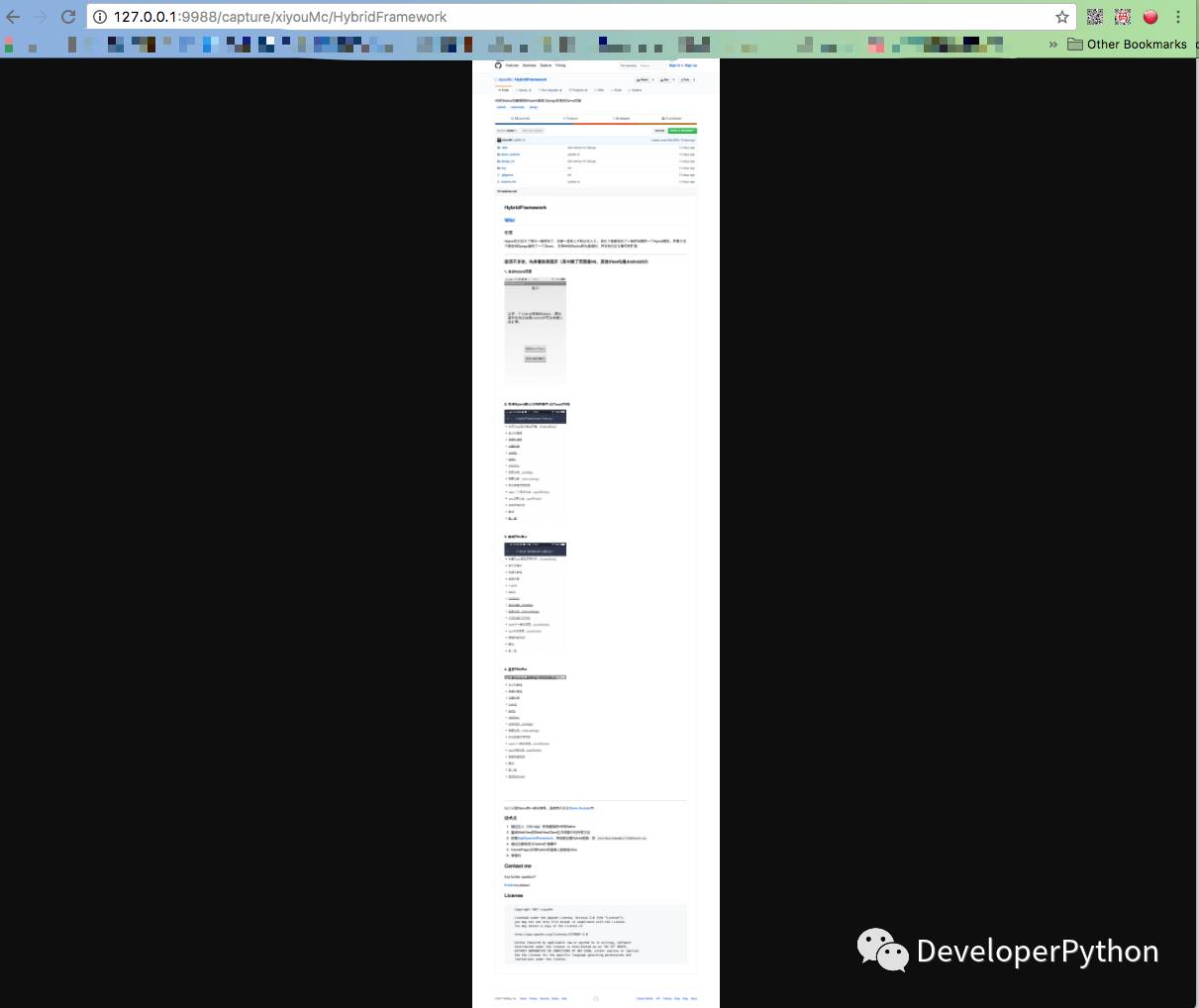
(请求结果是一个长图)
放大之后的页面是这样的。是不是很逼真呢?
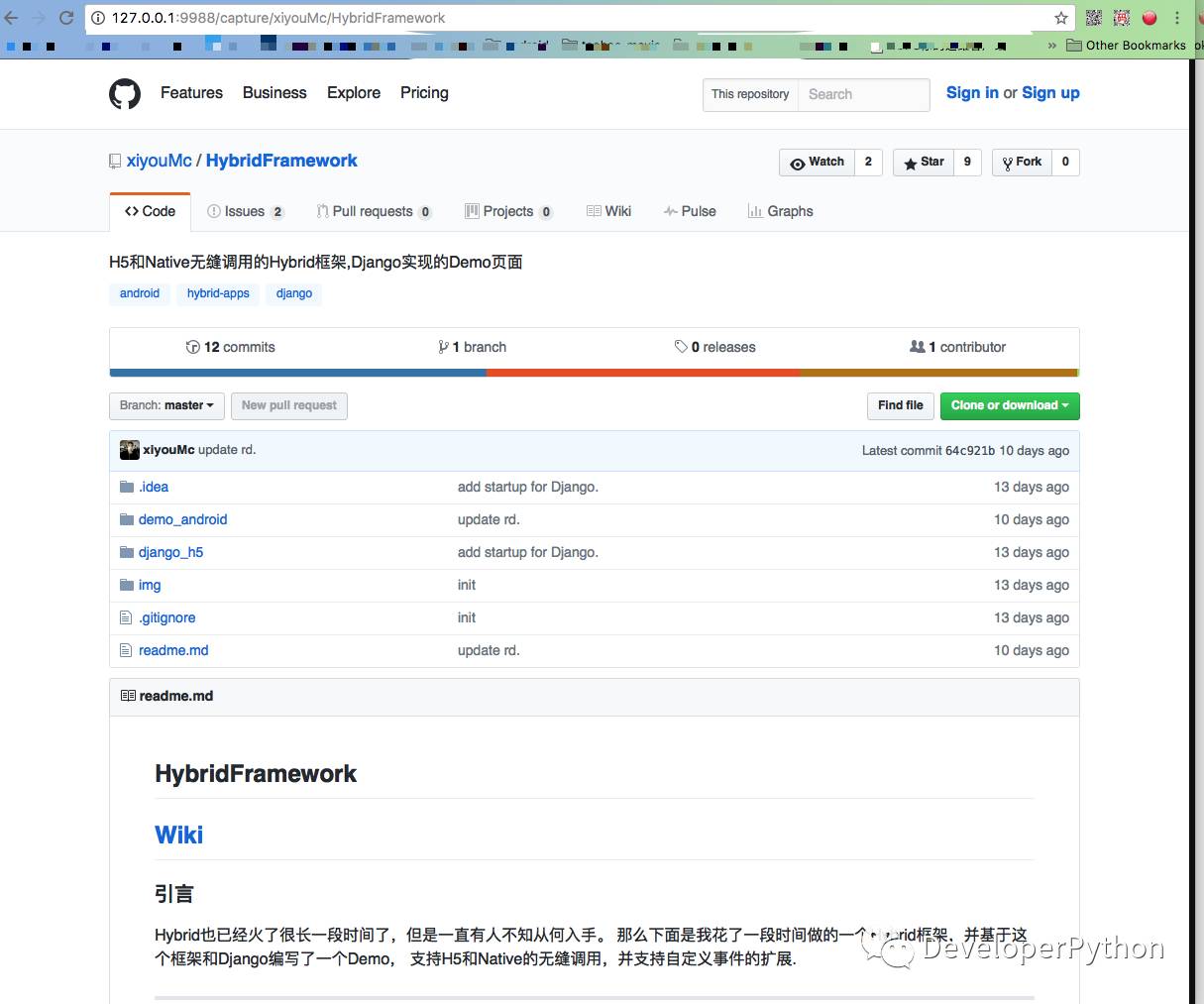
具体的代码就只有不到10行,当然这一直是Python的风格。
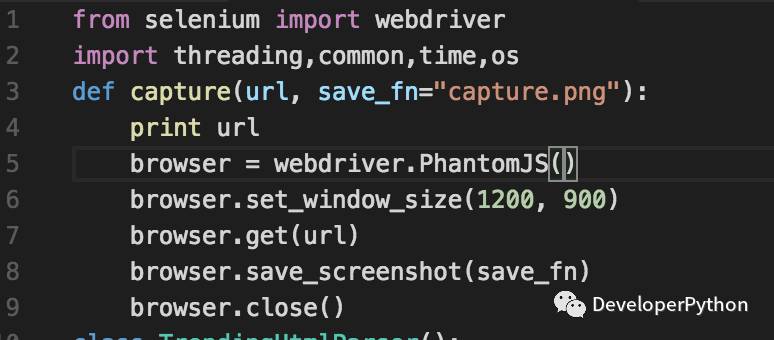
点击 阅读原文 ,获取Demo代码。
当然,“截图” 只是PhantomJS的一个功能。更重要的是它可以基于页面的 id 、class、tag等等进行类似手动的操作。如点击、填写文字。这里就不做演示了。
又是扯淡
附加 PhantomJS 额外的接口:
find_element_by_tag_name("div")find_element_by_csss_selector("#content")find_element_by_id("content")...
其次,之所以用Github来举例,是因为最近超哥在课余时间正在开发一款 关于 Github 的 小程序。 并且后台是通过 Python 搭建,Redis来做数据缓存的。
福利来了!!!
剧透下个人的小程序,《 Github开源社区 》 是一款关于 Github 的微信小程序。
旨在将 Github 每日开源趋势进行同步,并将其嵌入到公众号的菜单页。
同时在公众号的文章中,将不时讲解自己感兴趣且实用的开源项目。当然将不局限于Python,同时包括Android(Java)、Shell、JS、SQL等等的技术,毕竟本人也是Android出身,同时也正在往全栈工程师发展。
以下是《Github开源社区》小程序的截图。
体验资格获取方式:评论区留下你们的微信号,我将在第一时间邀请你们体验。
长摁‘识别二维码’,将自动执行代码

生活不止眼前的苟且,还有手下的代码、
和嘴上的扯淡
——
个人博客: https://www.alision.com
Github:https://www.github.com/xiyouMc















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









