









〔更多精彩AI内容,尽在 「魔方AI空间」 公众号,引领AIGC科技时代〕
本文作者:猫先生
写在前面
【魔方AI新视界】 专栏致力于梳理和探索AIGC领域内的创新技术与有影响力的实际应用案例。我们计划以月刊的形式定期发布内容,目的是让读者站在AI时代的最前沿,紧跟时代发展的步伐,自信而坚定地跟随AI技术的最新趋势。
此外,猫先生也会根据读者的反馈,持续对专栏内容和版面设计进行更新和改进。我们非常欢迎读者提出宝贵的建议,一起交流和学习,共同推动专栏的完善和成长!💪
文章首发公众号 「魔方AI空间」,欢迎关注!!
大家好,我是猫先生,AI技术爱好者与深耕者!!
阅读猫先生整理的《魔方AI新视界》专栏,您将获得以下宝贵收获:
- 前沿技术洞察:深入了解AIGC行业的核心技术动向,涵盖AI绘画、AI视频、大型模型、多模态技术以及数字人等领域的最新进展,让您始终站在技术发展的最前沿。
- 职业发展助力:在专栏中发现那些能够激发创新灵感的关键技术和应用案例,这些内容对您的职业发展具有重要意义,帮助您在专业领域中取得突破。
- 紧跟时代潮流:通过专栏,您将能够准确把握时代的脉搏,自信而坚定地跟随AI技术的最新趋势,确保您在快速发展的AI时代中保持竞争力。
《魔方AI新视界》不仅是一个信息的汇聚地,更是一个促进思考、激发创新的平台,猫先生期待与您一起探索AI的无限可能。
本文是《魔方AI新视界》专栏的第二期,周期为2024年 6月1日-2024年6月30日。在本期中,猫先生将采用精炼而扼要的语言,对AI领域的前沿技术进行介绍,并提供详情链接,以便于您能够进一步探索和学习。
本文整理自《AIGCmagic社区飞书知识库》的每周AI大事件板块,飞书主页地址:AIGCmagic社区,欢迎大家点赞评论!!
正文开始
1. AI视频进入有声时代|V2A:轻松给AI视频配音
- 谷歌DeepMind发布 **V2A,全称是 “video-to-audio”,就是根据视频生成音频。**这项技术能够根据视频内容以及一段简短的描述(例如"水母在水中游动,海洋生物,海洋"),自动生成与视频同步的音乐和音效,甚至还能创造出人物对话。整个过程无需人工进行音频的调整和剪辑,直接将无声视频转换为有声内容。
- 这标志着谷歌DeepMind正引领视频内容进入一个全新的有声时代。
- 项目主页:https://deepmind.google/discover/blog/generating-audio-for-video/

2. NVIDIA Broadcast:以 AI 助力语音和视频
- 一款利用 AI提升音频和视频质量的应用,适用于RTX GPU用户。它能够去除背景噪音、提供虚拟背景、自动对焦、动态跟踪、减少视频噪点等功能,从而简化直播和远程工作中的设置和操作。
- 官方地址:https://www.nvidia.cn/geforce/broadcasting/broadcast-app/

3. Alter 3:利用 GPT-4 驱动的人形机器人
- 东京大学和Alternative Machine的研究人员开发了一种名为Alter3的仿人机器人系统,该系统可以直接将自然语言命令映射到机器人动作。
- 通过利用大型语言模型(LLMs)如GPT-4,Alter3能够执行复杂的任务,如自拍或模仿幽灵。
- 项目主页:https://tnoinkwms.github.io/ALTER-LLM/
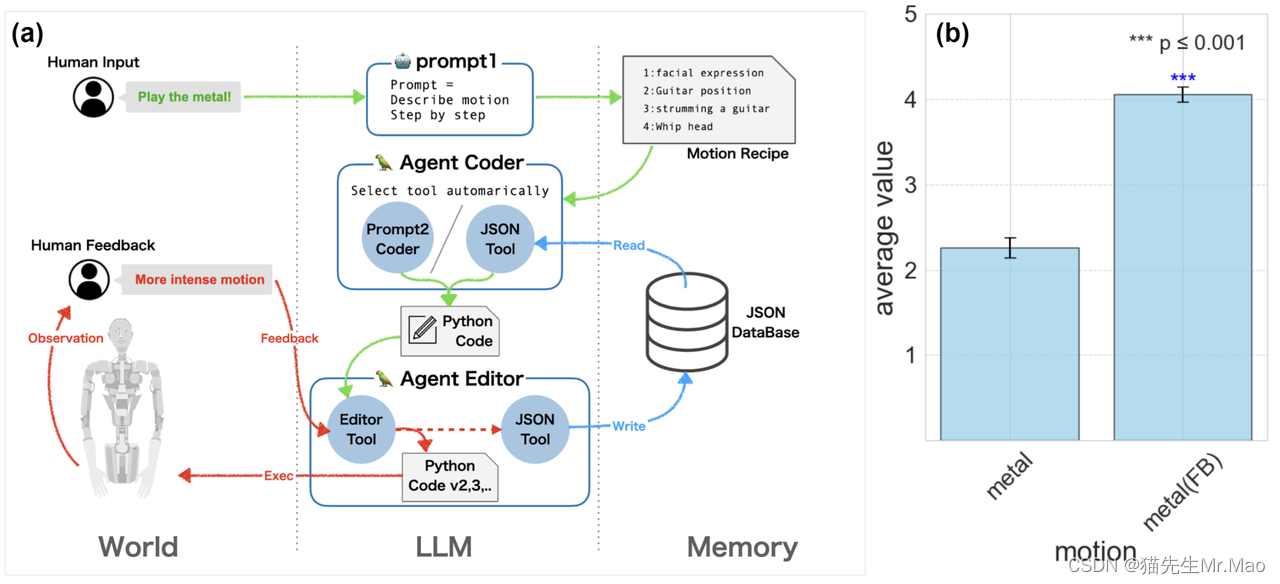
4. 中科大发布EvTexture:解决视频细节模糊和抖动问题
- 一种提升视频清晰度的新方法,专门利用事件信号进行纹理增强;
- EvTexture特别关注于利用事件相机捕获的高频动态细节来改善视频的纹理质量;
- 专门利用 “事件相机” 捕捉到的快速变化信息来增强视频中的纹理细节。
- 项目主页:https://dachunkai.github.io/evtexture.github.io/

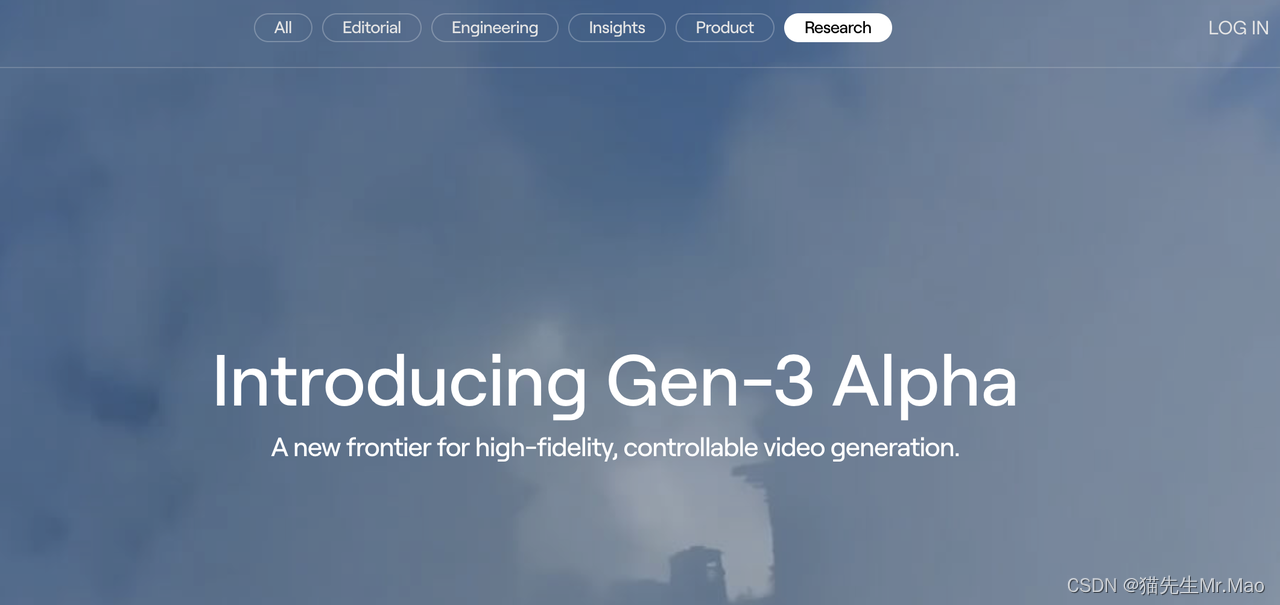
5. Runway最新发布Gen-3 Alpha:重回AI视频领域宝座
- Gen-3 Alpha 是 Runway 即将在为大规模多模式训练而构建的新基础设施上训练的一系列模型中的第一个。与 Gen-2 相比,它在保真度、一致性和运动方面有了重大改进,也是朝着构建通用世界模型迈出的一步。
- 官方地址:https://runwayml.com/blog/introducing-gen-3-alpha/
6. Open-Sora 1.2 版本正式发布!视频质量大幅提升!可在线体验
- Open-Sora,是一项致力于高效制作高质量视频的计划。 该项目希望让所有人都能使用模型、工具和所有细节。
- 项目地址:https://github.com/hpcaitech/Open-Sora
- 在线体验:https://huggingface.co/spaces/hpcai-tech/open-sora

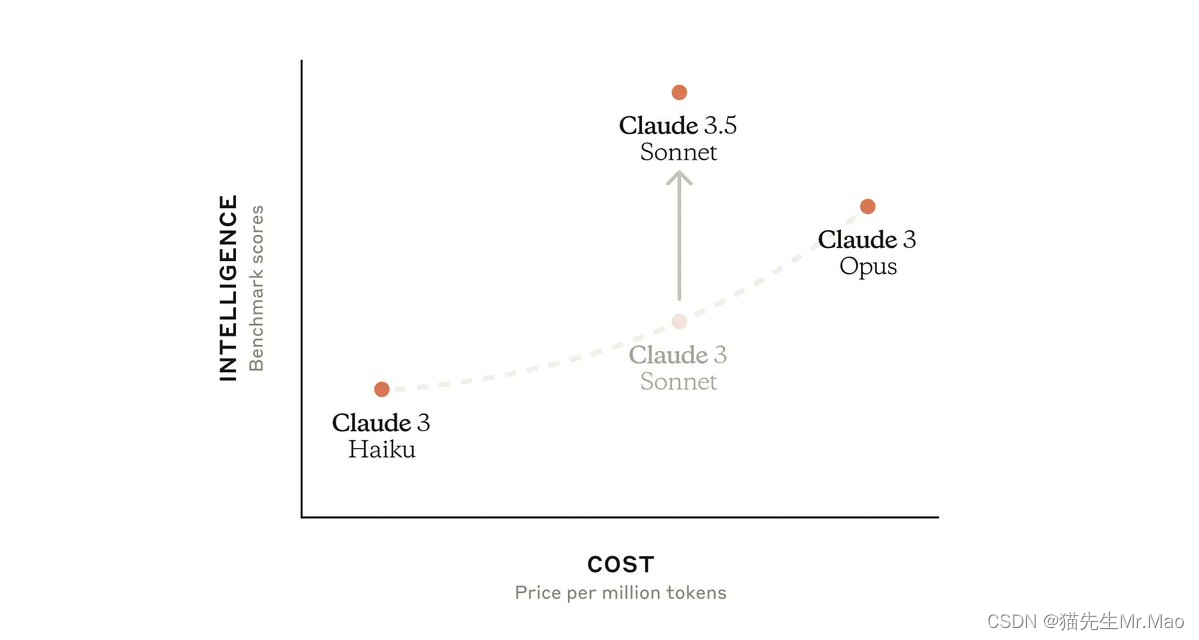
7. Anthropic 发布Claude 3.5 Sonnet最新模型
- 在推理、知识和编码能力方面超越了以前的版本和竞争对手。
- 运行速度是Claude 3 Opus的两倍。
- 官方地址:http://Claude.ai
8. Flash Diffusion: 加速 SD3 生图
- Flash Diffusion 是一种加速扩散模型的技术,昨天发布的 Flash SD3, 在 2 H100 上训练了 50 个小时,只需 4 步即可出图。
- 体验地址:https://huggingface.co/spaces/jasperai/flash-sd3

9. Luma 发布视频生成模型 Dream Machine,直逼电影级效果
- Dream Machine 是一种 AI 模型,可以快速将文本和图像制作成高质量、逼真的视频。
- 它是一个高度可扩展且高效的 transformer 模型,直接在视频上进行训练,使其能够生成物理上准确、一致且多变的镜头,生成效果直逼电影级!
- Dream Machine 是构建通用想象力引擎的第一步,现在每个人都可以使用它!
- 体验地址:https://lumalabs.ai/dream-machine/creations

10. Stable Diffusion 3 Medium模型开源
- SD3 Medium 是一个基于多模态扩散(MM-DiT)架构的文本到图像生成模型,是目前AI绘画领域开源的最强模型;
- 具有照片写实主义、理解复杂提示、高效文本排版、资源利用高效、Fine-Tuning定制化等优势;
- SD3 Medium的参数量为2B,适合消费级GPU运行,支持多种模型文件和工作流程示例。
- 官方地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main

11. MARS5 TTS:开源高拟真语音合成
- 摘要: MARS5 TTS 是一款开源语音合成模型,能以2-3秒音频为参考,在140多种语言中复制高难度场景,如体育解说、电影和动漫等。
- 项目地址:https://github.com/Camb-ai/MARS5-TTS

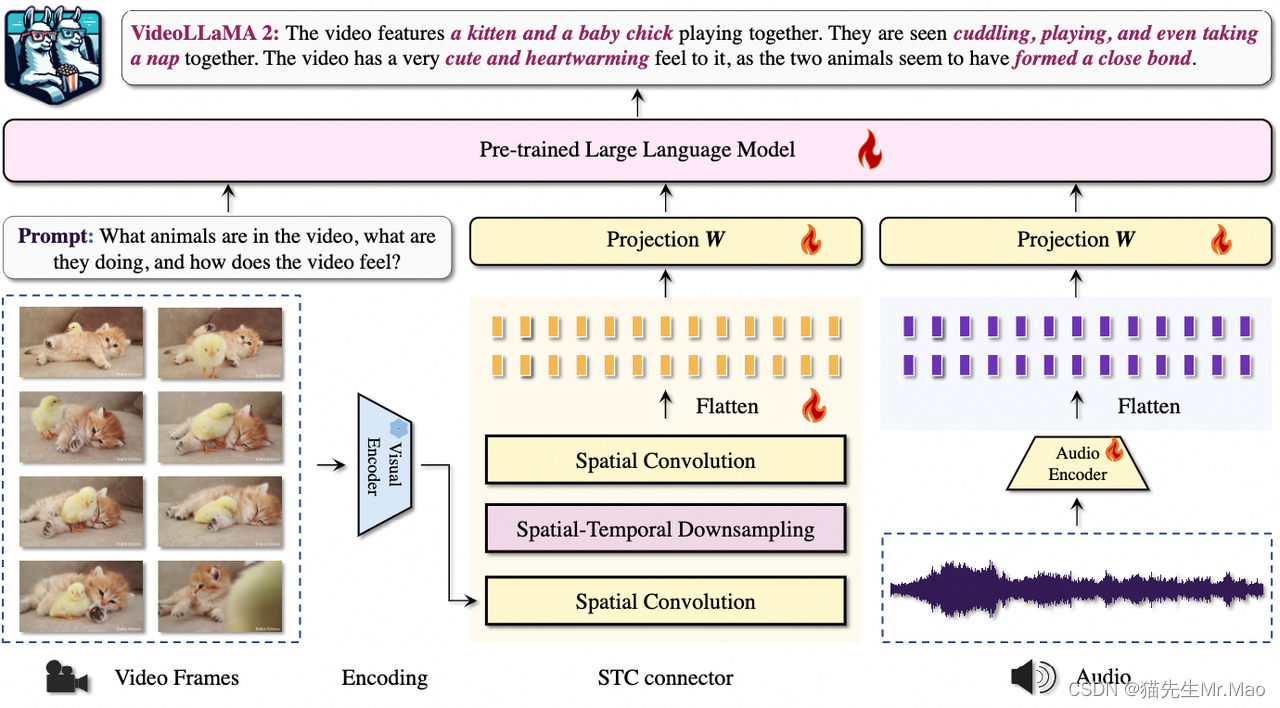
12. 阿里云发布VideoLLaMA2:上传视频可根据指令实时识别解读视频内容
- 摘要: VideoLLaMA2是一个旨在提升视频大语言模型(Video-LLM)时空建模和音频理解能力的项目。 该模型集成了一个专门设计的时空卷积(Spatial-Temporal Convolution,STC)连接器,有效捕捉视频数据中的复杂时空动态。此外,通过联合训练,模型还集成了音频分支,增强了多模态理解能力。
- 项目地址:https://github.com/DAMO-NLP-SG/VideoLLaMA2
13. 腾讯联合东京大学发布MOFA-Video:图像到视频的可控生成框架
- 一种新颖的统一框架,用于稳定视频扩散(SVD)中的可控图像动画;
- 设计一种新颖的网络结构,即MOFA-Adapter,它利用显式稀疏运动提示进行变形和生成;
- 支持运动画笔,可快速本地部署。
- 项目主页:https://myniuuu.github.io/MOFA_Video/

14. 腾讯发布V-Express:音频驱动图片生成讲话视频,数字人免费平替
- 旨在通过一系列渐进式的控制信号衰减操作,实现由单张图片生成讲话头像视频;
- 通过参考图像、音频和V-Kps图像序列生成可控的说话人视频;
- 能够有效生成音频同步的高质量人像视频,保持人脸身份和姿势的一致性。
- 项目主页:https://tenvence.github.io/p/v-express/

15. 字节发布Seed-TTS:几乎完美接近人类的文本到语音(TTS)模型
- 一个大规模自回归文本转语音 (TTS) 模型系列,能够生成与人类语音几乎没有区别的语音;
- 对各种语音属性(如情感)具有卓越的可控性,并且能够为野外的说话者生成高度富有表现力和多样化的语音。
- 项目主页:https://bytedancespeech.github.io/seedtts_tech_report/

16. 快手发布“可灵”视频生成大模型
- 生成超过120秒1080P视频,画面连贯,动作流畅,细节真实;
- 类Sora的DiT结构,用Transformer代替卷积网络;
- 模拟真实物理特性,准确建模复杂运动场景(高速奔跑的动物、月球行走的宇航员等)
- 官网主页:https://kling.kuaishou.com/

技术交流
加入 「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在 「魔方AI空间」,关注了解全栈式 AIGC内容!!
推荐阅读
• 万字长文 | AIGC时代算法工程师的面试秘籍(2024.5.13-5.26第十四式)
• AIGC | 「视频生成」系列之Suno制作MV视频工作流分享(保姆级)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









