






〔更多精彩AI内容,尽在 「魔方AI空间」,引领AIGC科技时代〕
本文作者:猫先生
写在前面
【魔方AI新视界】专栏致力于梳理和探索AIGC领域内的创新技术与有影响力的实际应用案例。我们计划以月刊的形式定期发布内容,目的是让读者站在AI时代的最前沿,紧跟时代发展的步伐,自信而坚定地跟随AI技术的最新趋势。
此外,猫先生也会根据读者的反馈,持续对专栏内容和版面设计进行更新和改进。我们非常欢迎读者提出宝贵的建议,一起交流和学习,共同推动专栏的完善和成长!💪
大家好,我是猫先生,AI技术爱好者与深耕者!!
阅读猫先生整理的《魔方AI新视界》专栏,您将获得以下宝贵收获:
-
前沿技术洞察:深入了解AIGC行业的核心技术动向,涵盖AI绘画、AI视频、大型模型、多模态技术以及数字人等领域的最新进展,让您始终站在技术发展的最前沿。
-
职业发展助力:在专栏中发现那些能够激发创新灵感的关键技术和应用案例,这些内容对您的职业发展具有重要意义,帮助您在专业领域中取得突破。
-
紧跟时代潮流:通过专栏,您将能够准确把握时代的脉搏,自信而坚定地跟随AI技术的最新趋势,确保您在快速发展的AI时代中保持竞争力。
《魔方AI新视界》不仅是一个信息的汇聚地,更是一个促进思考、激发创新的平台,猫先生期待与您一起探索AI的无限可能。
本文是《魔方AI新视界》专栏的第七期,周期为2024年10月1日-2024年10月31日。在本期中,猫先生将采用精炼而扼要的语言,对AI领域的前沿技术进行介绍,并提供详情链接,以便于您能够进一步探索和学习。
本文整理自《AIGCmagic社区飞书知识库》的每周AI大事件板块,飞书主页地址:AIGCmagic社区,欢迎大家点赞评论!!
往期回顾
正文开始
Sana:使用线性扩散Transformer进行高效高分辨率图像合成
Sana,一个文本到图像框架,可以有效生成高达 4096 × 4096 分辨率的图像。
Sana 可以以极快的速度合成具有强大文本图像对齐功能的高分辨率、高质量图像,可部署在笔记本电脑 GPU 上。
项目地址:https://github.com/NVlabs/Sana

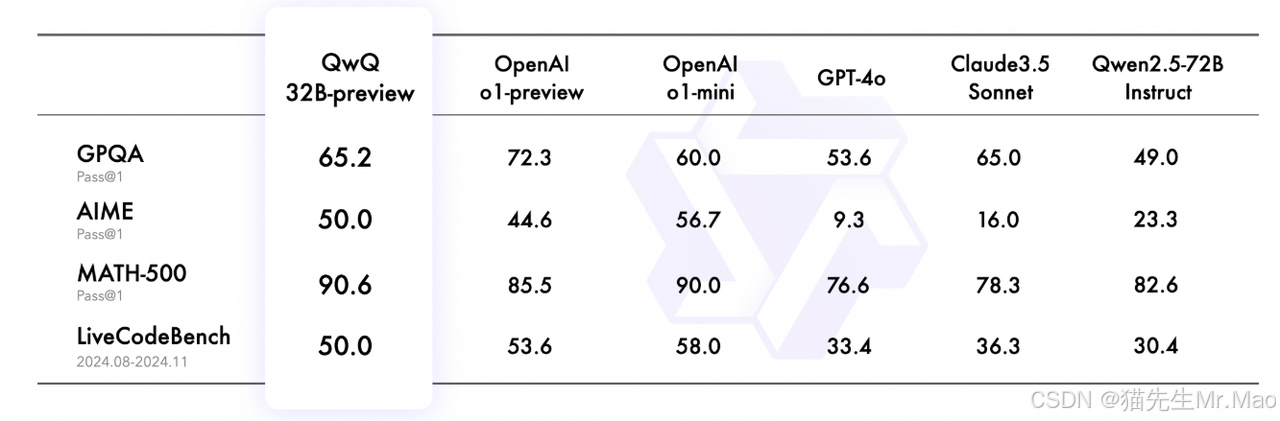
阿里开源qwq-32b-preview:最强国产推理模型
QwQ-32B-Preview 是由 Qwen 团队开发的实验性研究模型,专注于增强 AI 推理能力。作为预览版本,它展现了令人期待的分析能力。
GPQA:65.2%,展示了研究生水平的科学推理能力;
AIME:50.0%,证明了强大的数学问题解决技能;
MATH-500:90.6%,体现了在各类数学主题上的全面理解;
LiveCodeBench:50.0%,验证了在实际编程场景中的出色表现。
这些成果充分体现了QwQ在分析和问题解决能力方面的显著进步,尤其是在需要深度推理的技术领域。
项目地址:https://github.com/QwenLM/Qwen2.5
项目介绍:https://qwenlm.github.io/zh/blog/qwq-32b-preview/
OneDiffusion:多功能生图模型即将开源
- OneDiffusion 是一种多功能的大规模扩散模型,可无缝支持跨不同任务的双向图像合成和理解。
- 可以实现类似 ControlNet 的条件生成(如深度、姿势、布局、语义等),同时也能将图片预处理为这些条件。
- 项目地址:https://github.com/lehduong/OneDiffusion

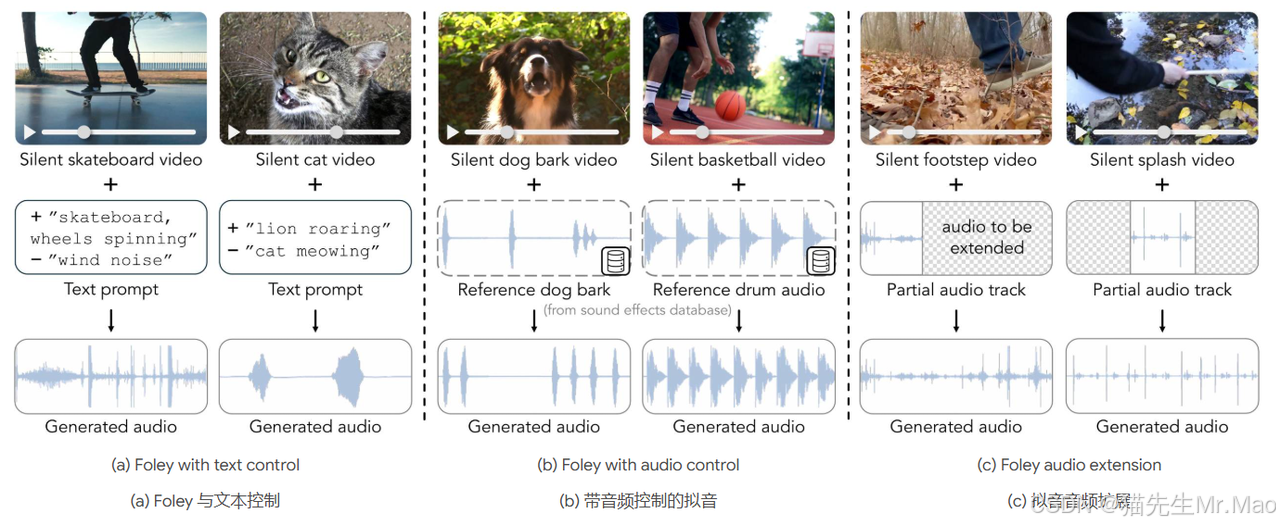
MultiFoley:具有多模态控制的视频引导音频生成
MultiFoley ,一个专为视频引导声音生成而设计的模型 支持通过文本、音频和视频进行多模态调节。
给定无声视频和文字提示,MultiFoley 允许用户创建干净的声音(例如,滑板轮旋转而没有风噪声)或更异想天开的声音 声音(例如,使狮子的吼声听起来像猫的喵喵声)。
项目地址:https://ificl.github.io/MultiFoley/
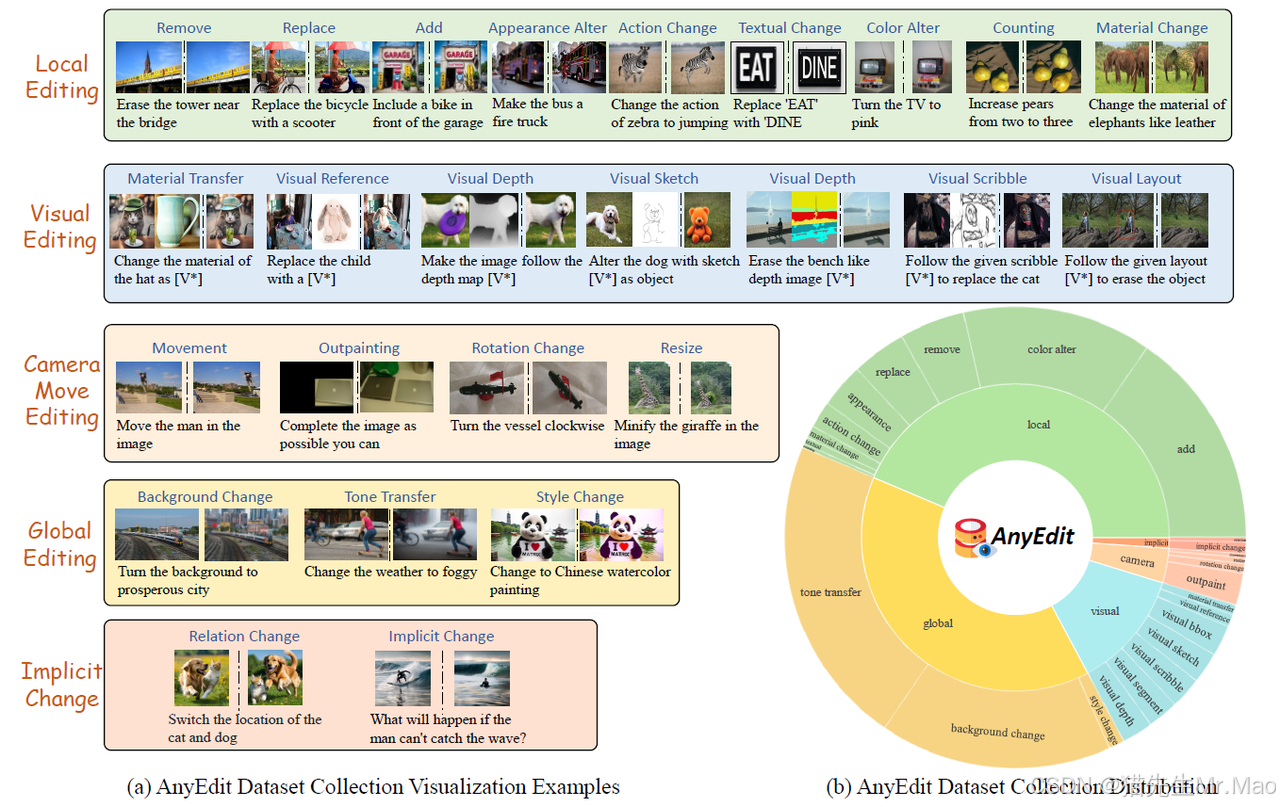
AnyEdit:掌握适用于任何想法的统一高质量图像编辑
一个全面的多模态指令编辑数据集,包含 250 万个高质量编辑对,涵盖 20 多种编辑类型和 5 个领域。
使用该数据集,进一步训练一种新颖的 AnyEdit Stable Diffusion,具有任务感知路由和可学习任务嵌入,以实现统一图像编辑。
项目主页:https://dcd-anyedit.github.io/
Qwen2vl-Flux:最先进的多模态图像生成模型
Qwen2vl-Flux 是一种最先进的多模态图像生成模型,通过 Qwen2VL 的视觉语言理解能力增强 FLUX。
该模型擅长根据文本提示和视觉参考生成高质量图像,提供卓越的多模式理解和控制。
项目主页:https://huggingface.co/Djrango/Qwen2vl-Flux

DanceFusion:基于AI音频驱动舞蹈动作重建
一种利用时空骨架扩散变压器重建和生成与音乐同步的舞蹈动作的新颖框架。
将基于 Transformer 的分层变分自动编码器 (VAE) 与扩散模型相结合,显着增强了运动的真实感和准确性。
该框架的潜在应用扩展到内容创建、虚拟现实和互动娱乐,有望在自动化舞蹈生成方面取得重大进展。
项目主页:https://th-mlab.github.io/DanceFusion/
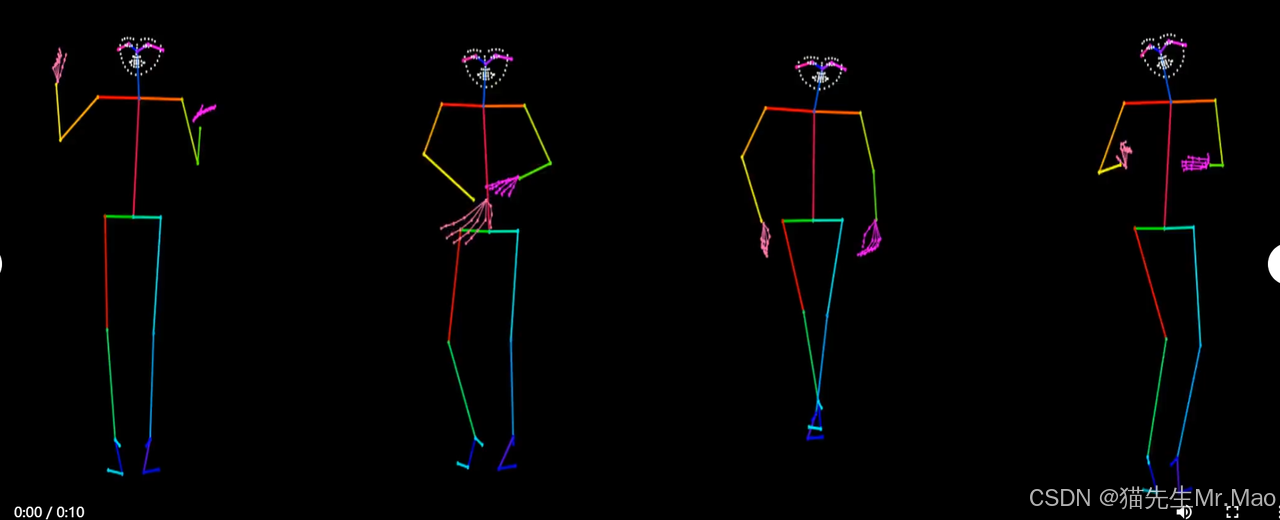
EchoMimicV2:迈向引人注目、简化和半人体动画
利用参考图像、音频剪辑和一系列手势来生成高质量的动画视频,确保音频内容和半身动作之间的连贯性。
该方法利用新颖的音频姿势动态协调策略(包括姿势采样和音频扩散)来增强半身细节、面部和手势表现力,同时减少条件冗余。
项目主页:https://antgroup.github.io/ai/echomimic_v2/

Janus 系列:统一多模态理解和生成模型
Janus是一种新颖的自回归框架,统一了多模态理解和生成。
它通过将视觉编码解耦到单独的路径中来解决以前方法的局限性,同时仍然利用单个统一的变压器架构进行处理。
Janus超越了之前的统一模型,并且匹配或超过了特定任务模型的性能。
Janus 的简单性、高度灵活性和有效性使其成为下一代统一多模式模型的有力候选者。
项目主页:https://github.com/deepseek-ai/Janus

MikuDance:二次元角色动画生成技术
基于扩散模型,结合了混合运动动力学来动画化风格化的角色艺术。
MikuDance 包含两项关键技术:混合运动建模和混合控制扩散,以解决角色艺术动画中高动态运动和参考引导错位的挑战。
MikuDance 在各种角色艺术和动作指导中具有很好的有效性和通用性。
项目主页:https://kebii.github.io/MikuDance/
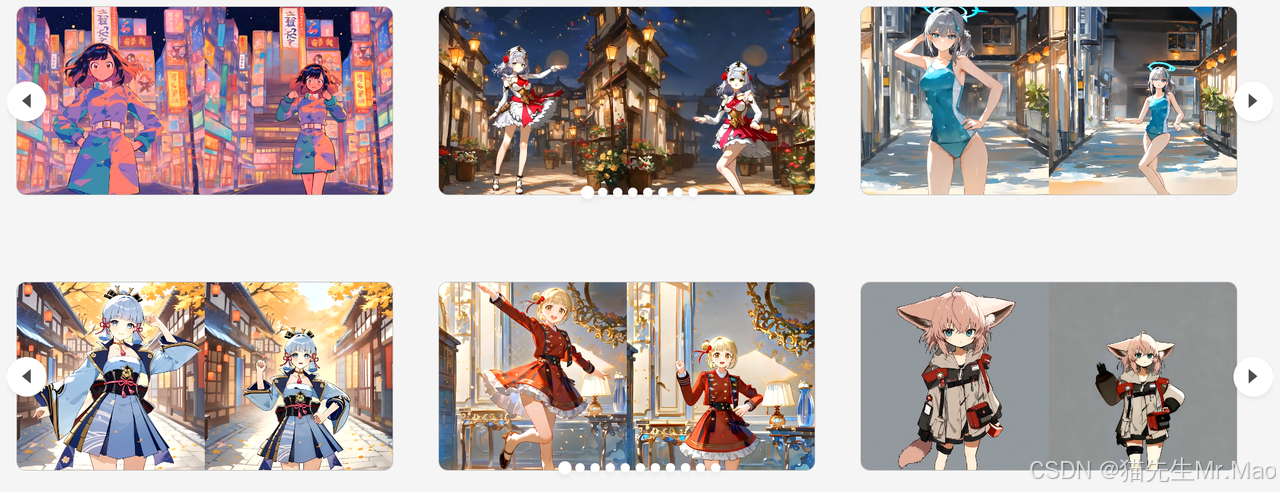
SG-I2V:超强图生视频技术,精确控制运动轨迹
一种无需微调或外部知识即可实现图像到视频生成中对象和相机运动控制的框架。
该框架建立在Stable Video Diffusion之上,这是一种公开可用的图像到视频扩散模型。
项目主页:https://kmcode1.github.io/Projects/SG-I2V/
技术解读:https://mp.weixin.qq.com/s/5v0oZH0P5FJpksdh5F6BWg
X-Portrait 2::极具表现力的肖像动画
人像动画技术提供了一种超低成本、高效的方式来创建富有表现力、逼真的角色动画和视频片段。
用户只需提供静态人像图像和驾驶表演视频,模型就可以使用这些输入来生成视频将驾驶表情转移到肖像中的拍摄对象上。
这可以大大降低现有动作捕捉、角色动画和内容创建管道的复杂性。
项目主页:https://byteaigc.github.io/X-Portrait2/

HART:高效自回归图像生成模型,速度提升4.5-7.7 倍
一种自回归(AR)视觉生成模型,能够直接生成 1024x1024 图像,在图像生成质量方面可与扩散模型相媲美。
提出混合标记器,它将来自自动编码器的连续潜在特征分解为两个部分:代表全局的离散标记和代表离散标记无法表示的残差分量的连续标记。
其生成速度比扩散模型快 4.5 至 7.7 倍。
项目主页:https://hanlab.mit.edu/projects/hart
在线试用地址:https://hart.mit.edu/

InstantIR:基于 SDXL 的高清修复模型
这是一种基于扩散的新型 BIR(盲图像修复) 方法,可在推理过程中动态调整生成条件。
InstantIR 主动将条件编码与生成先验进行对齐。这是通过一种新颖的预览机制实现的,该机制具有三个关键模块:(1)用于紧凑 LQ 图像表示编码的 DCP; (2) 用于将其解码为生成先验的预览器; (3) 聚合器,用于将生成参考和 LQ 输入集成到采样条件中。
项目主页:https://jy-joy.github.io/InstantIR/

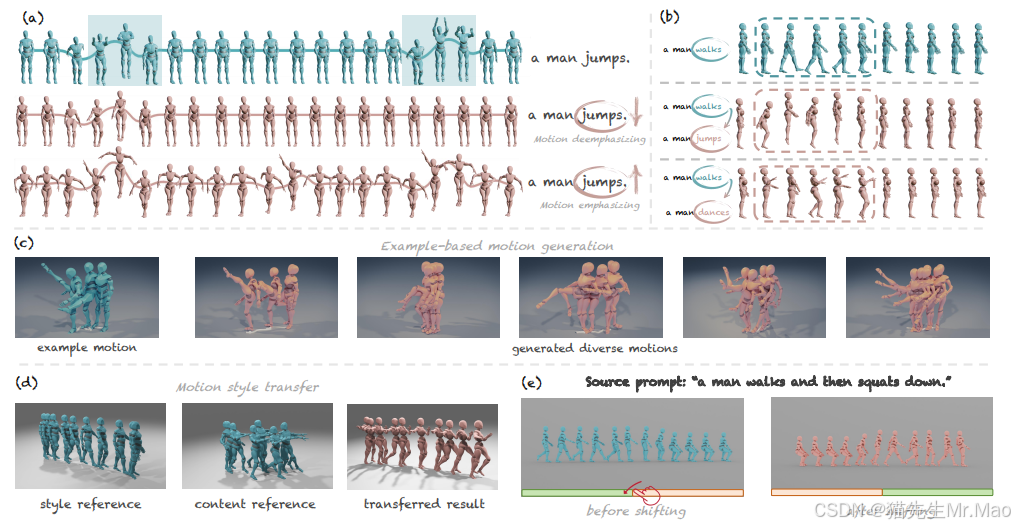
MotionCLR:一款能够理解和编辑人类动作的模型
该工作深入探讨了人体动作生成的交互式编辑问题。
MotionCLR 分别用自注意和交叉注意力对模态和跨模态交互进行建模。
项目主页:https://lhchen.top/MotionCLR/
Mochi:最强开源视频生成模型
一个开源的、最先进的视频生成模型,具有高保真运动和初步评估中的强烈提示依从性。
此模型极大地缩小了封闭和开源视频生成系统之间的差距。
项目主页:https://www.genmo.ai/play
代码地址:https://github.com/genmoai/models
技术解读:https://mp.weixin.qq.com/s/8S9EuUldDfb8e0Y0bMkSrA
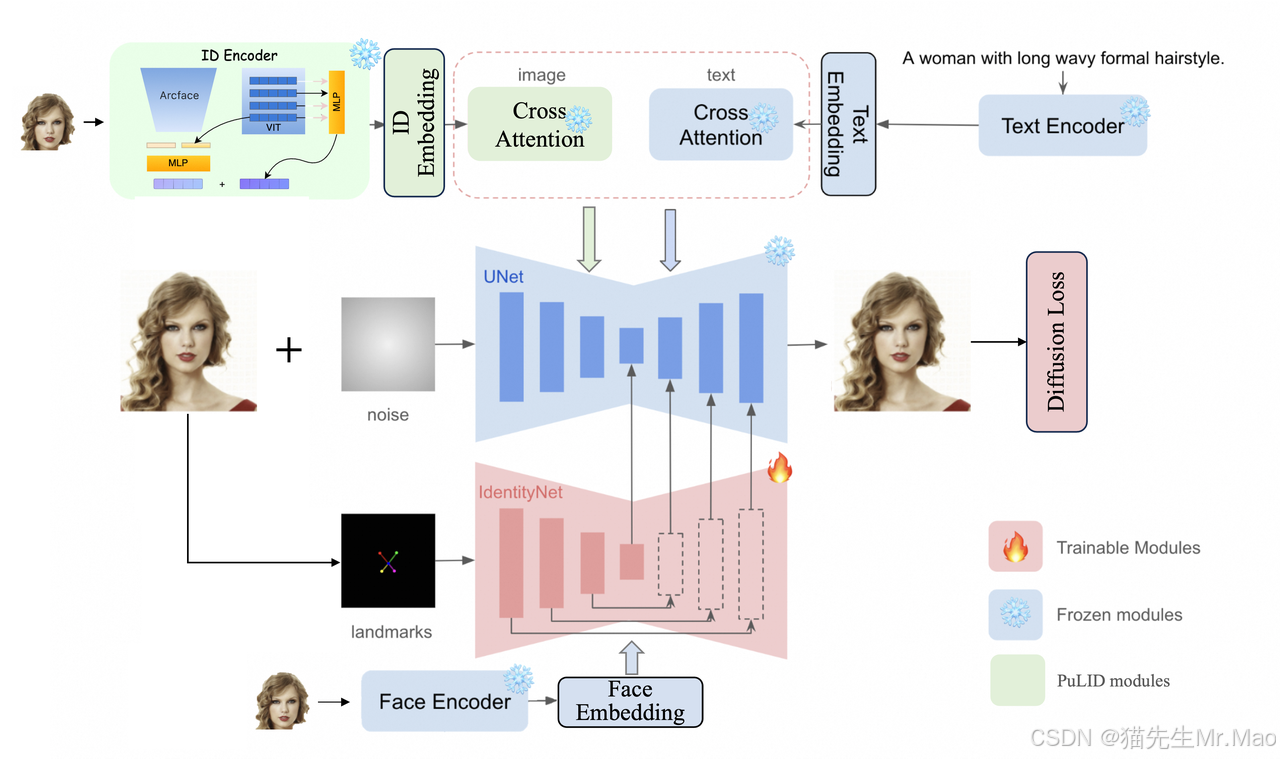
阿里发布SDXL-EcomID:更好的角色一致性
EcomID 借鉴 PuLID 的 ID-Encoder 和交叉注意力组件,其使用对齐损失训练而成。
EcomID 保留了背景生成能力,同时最大限度地减少了风格化,从而大大增强了真实感。
EcomID 使用关键点作为训练的条件输入,允许精确调整面部位置、大小和方向。
项目主页:https://huggingface.co/alimama-creative/SDXL-EcomID/blob/main/README_ZH.md
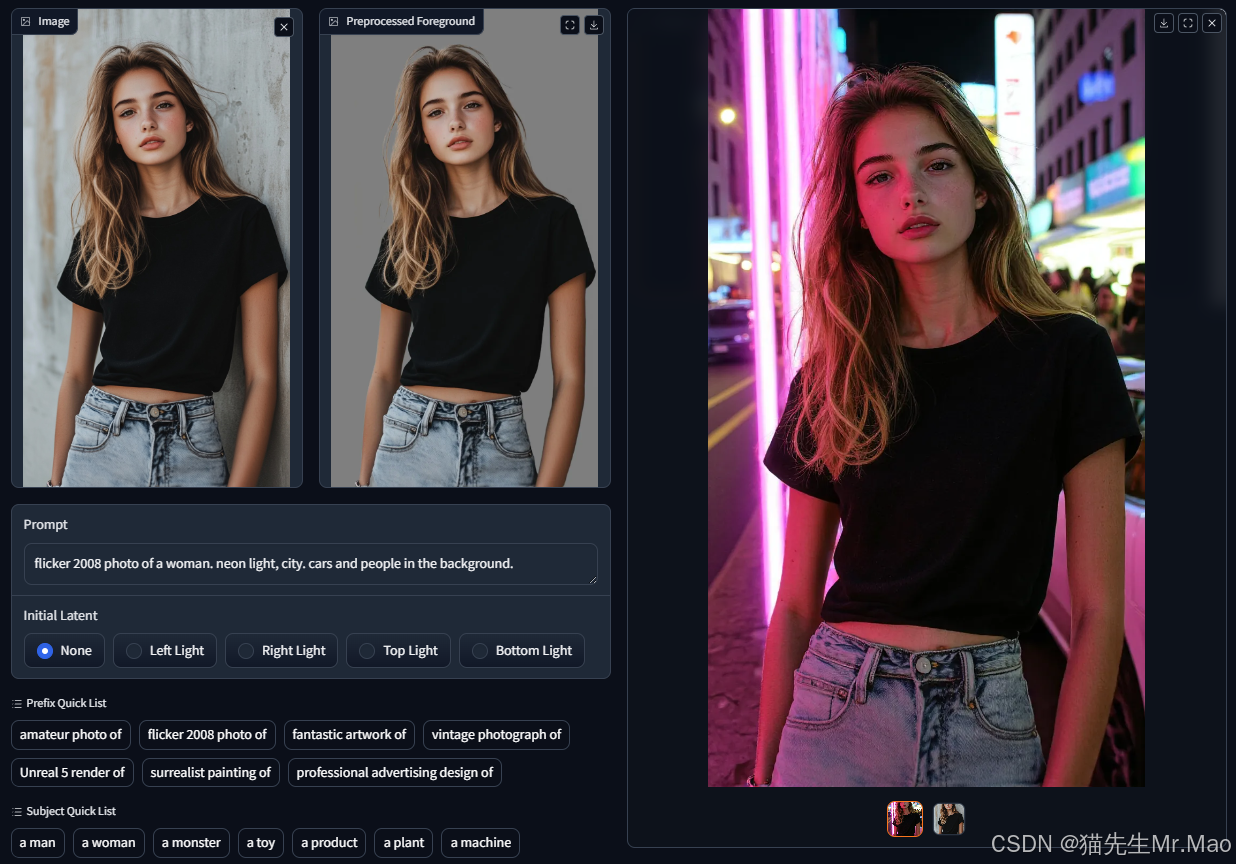
IC-Light V2: 基于 Flux 的图像重打光模型
IC-Light V2 是一系列基于 Flux 的 IC-Light 型号,具有 16 通道 VAE 和原生高分辨率,专门用于操作图像中的打光效果。
该模型仍然由 ControlNet 的作者开发,目前正处于 WIP(工作进行中)阶段,仅发布了前景条件模型。
项目地址:https://github.com/lllyasviel/IC-Light
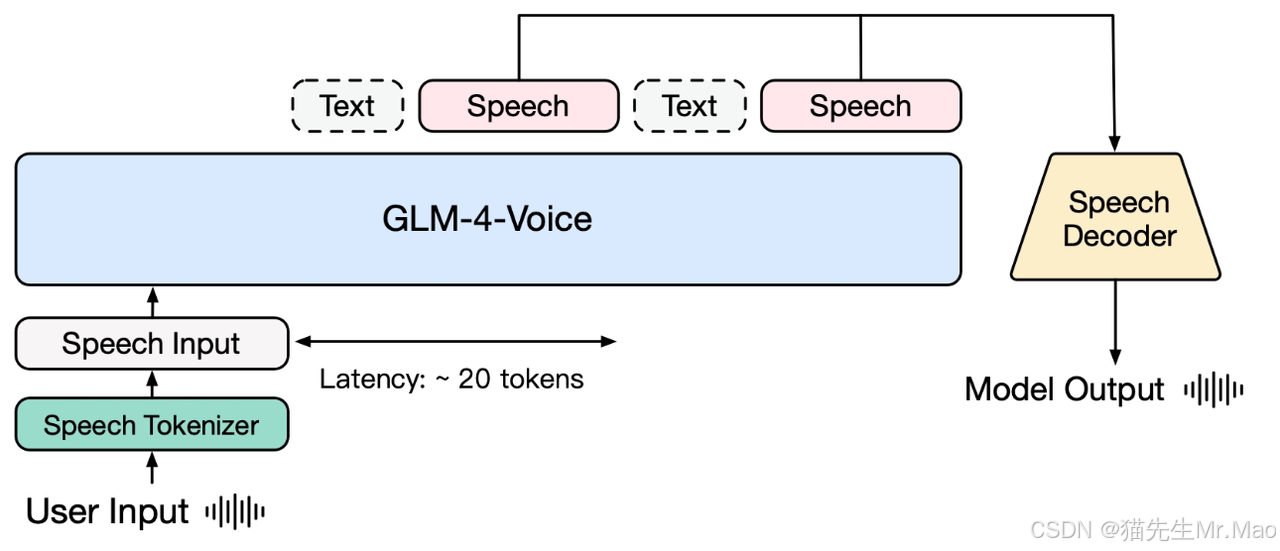
智谱 GLM-4.Voice:开源语音模型支持多语言实时对话
GLM-4-Voice 是智谱 AI 推出的端到端语音模型。GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。
GLM-4-Voice-Tokenizer: 通过在 Whisper 的 Encoder 部分增加 Vector Quantization 并在 ASR 数据上有监督训练,将连续的语音输入转化为离散的 token。每秒音频平均只需要用 12.5 个离散 token 表示。
GLM-4-Voice-Decoder: 基于 CosyVoice 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个语音 token 即可开始生成,降低端到端对话延迟。
GLM-4-Voice-9B: 在 GLM-4-9B 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音 token。
项目主页:https://github.com/THUDM/GLM-4-Voice
MarDini:专为基于图片生成视频而设计
MarDini,将连续空间中掩蔽自回归 (MAR) 的灵活性与扩散模型 (DM) 的稳健生成能力相结合。
MarDini模型将视频生成分解为两个子任务——时间建模和空间建模。
MAR 处理长距离时间建模,而 DM 专注于详细的空间建模。
MAR 以较低的分辨率运行较多的参数,而 DM 以较高的分辨率使用较少的参数运行。
项目主页:https://mardini-vidgen.github.io/

技术交流
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在「魔方AI空间」,关注了解全栈式 AIGC内容!!
推荐阅读
技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
技术资讯: 魔方AI新视界
技术综述: 一文掌握Video Diffusion Model视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









