









〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
写在前面
【魔方AI新视界】专栏致力于梳理和探索AIGC领域内的创新技术与有影响力的实际应用案例。我们计划以月刊的形式定期发布内容,目的是让读者站在AI时代的最前沿,紧跟时代发展的步伐,自信而坚定地跟随AI技术的最新趋势。
此外,猫先生也会根据读者的反馈,持续对专栏内容和版面设计进行更新和改进。我们非常欢迎读者提出宝贵的建议,一起交流和学习,共同推动专栏的完善和成长!💪
大家好,我是猫先生,AI技术爱好者与深耕者!!
阅读猫先生整理的《魔方AI新视界》专栏,您将获得以下宝贵收获:
-
前沿技术洞察:深入了解AIGC行业的核心技术动向,涵盖AI绘画、AI视频、大型模型、多模态技术以及数字人等领域的最新进展,让您始终站在技术发展的最前沿。
-
职业发展助力:在专栏中发现那些能够激发创新灵感的关键技术和应用案例,这些内容对您的职业发展具有重要意义,帮助您在专业领域中取得突破。
-
紧跟时代潮流:通过专栏,您将能够准确把握时代的脉搏,自信而坚定地跟随AI技术的最新趋势,确保您在快速发展的AI时代中保持竞争力。
《魔方AI新视界》不仅是一个信息的汇聚地,更是一个促进思考、激发创新的平台,猫先生期待与您一起探索AI的无限可能。
本文是《魔方AI新视界》专栏的第五期,周期为2024年9月1日-2024年9月30日。在本期中,猫先生将采用精炼而扼要的语言,对AI领域的前沿技术进行介绍,并提供详情链接,以便于您能够进一步探索和学习。
本文整理自《AIGCmagic社区飞书知识库》的每周AI大事件板块,飞书主页地址:AIGCmagic社区,欢迎大家点赞评论!!
往期回顾
正文开始
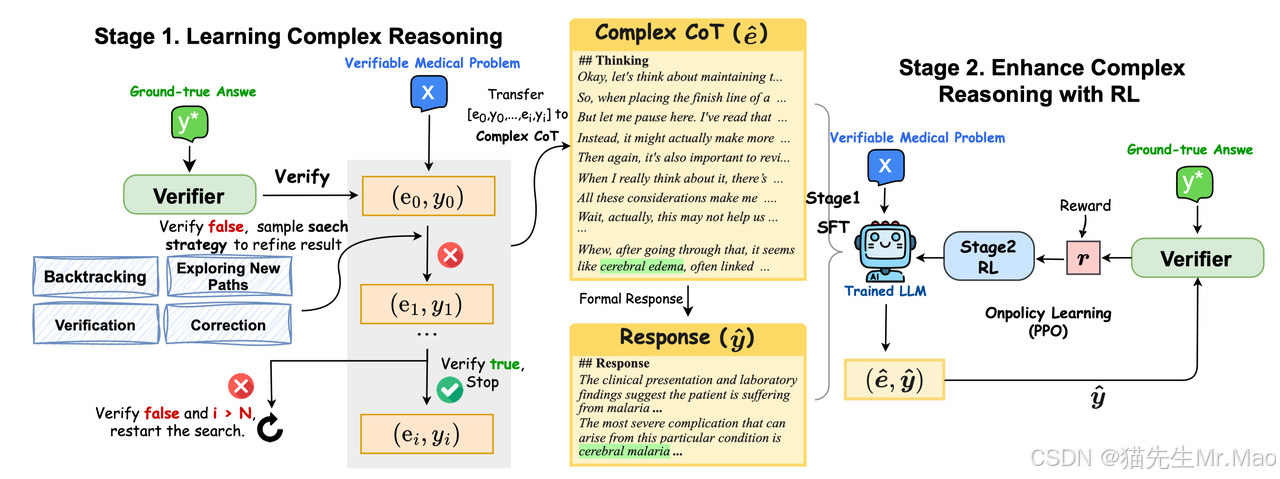
华佗GPT-o1,面向医学复杂推理 LLMs
HuatuoGPT-o1 是一个医学LLM,专为高级医学推理而设计。它可以识别错误、探索替代策略并完善其答案。通过利用可验证的医疗问题和专业的医疗验证器,它通过以下方式推进推理:
使用验证器指导搜索用于微调 LLMs.
应用强化学习 (PPO) 和基于验证奖励,以进一步增强复杂推理。
项目主页:https://github.com/FreedomIntelligence/HuatuoGPT-o1
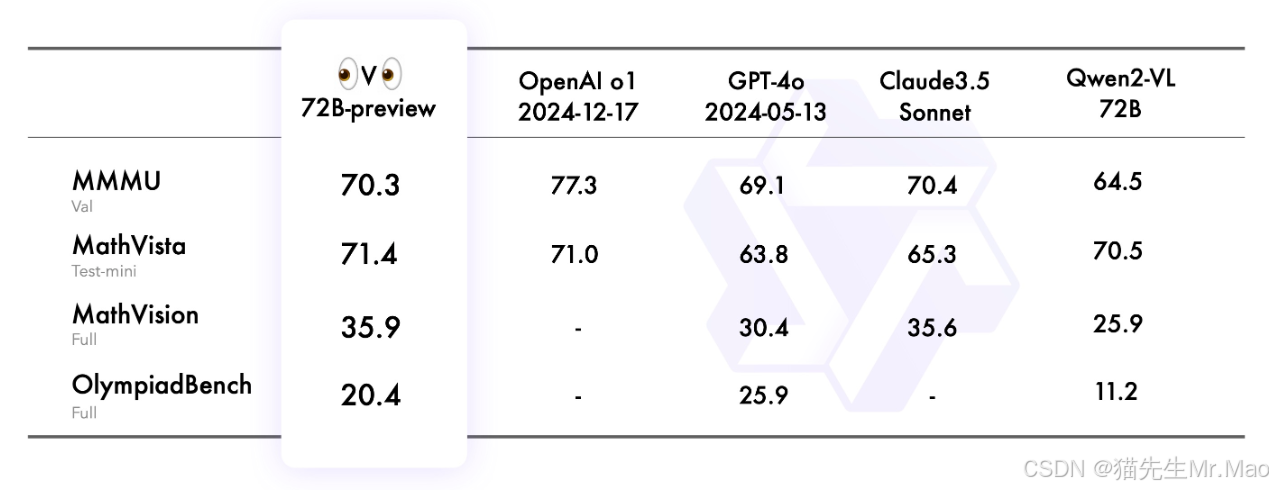
QVQ-72B-Preview:开源多模态推理模型
QVQ-72B-Preview 是由 Qwen 团队开发的实验性研究模型,专注于增强视觉推理能力。
在 MMMU 评测中,QVQ 取得了 70.3 的优异成绩,并且在各项数学相关基准测试中相比 Qwen2-VL-72B-Instruct 都有显著提升。
通过细致的逐步推理,QVQ 在视觉推理任务中展现出增强的能力,尤其在需要复杂分析思维的领域表现出色。
项目主页:https://qwenlm.github.io/zh/blog/qvq-72b-preview/
Switti:速度超快的文生图模型
一种用于文本到图像生成的比例transformer,其性能优于现有的自回归模型,媲美现有的扩散模型,同时生成速度最高快7倍。
项目主页:https://yandex-research.github.io/switti/

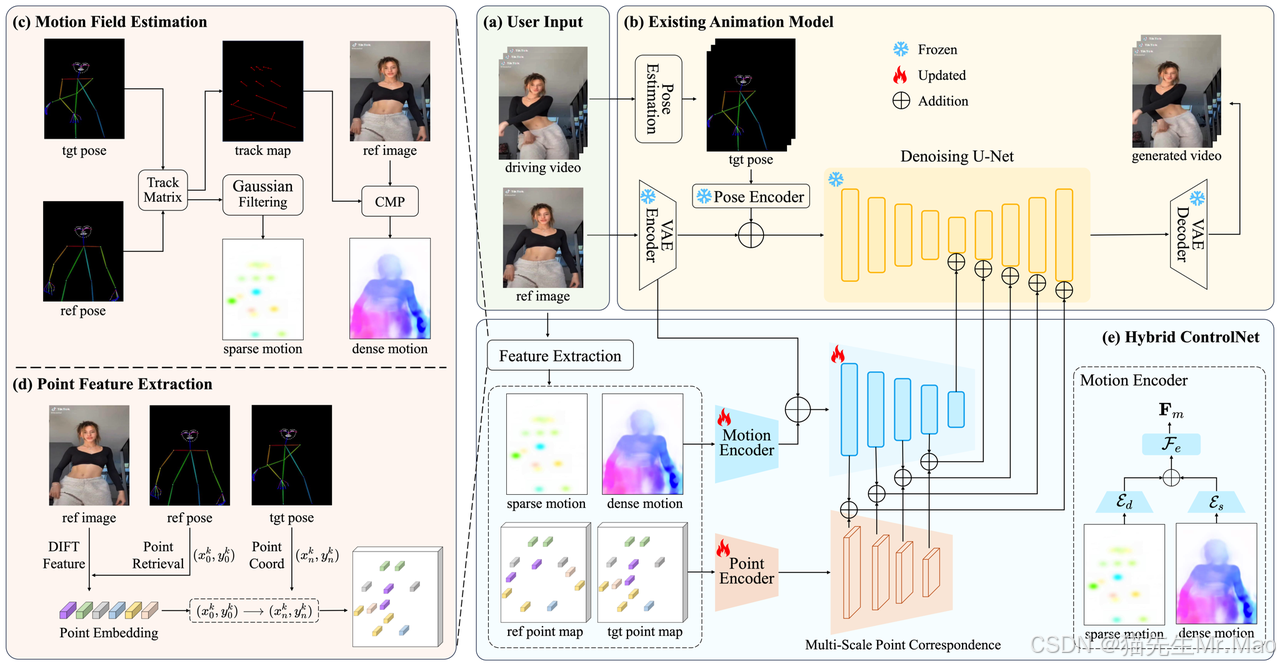
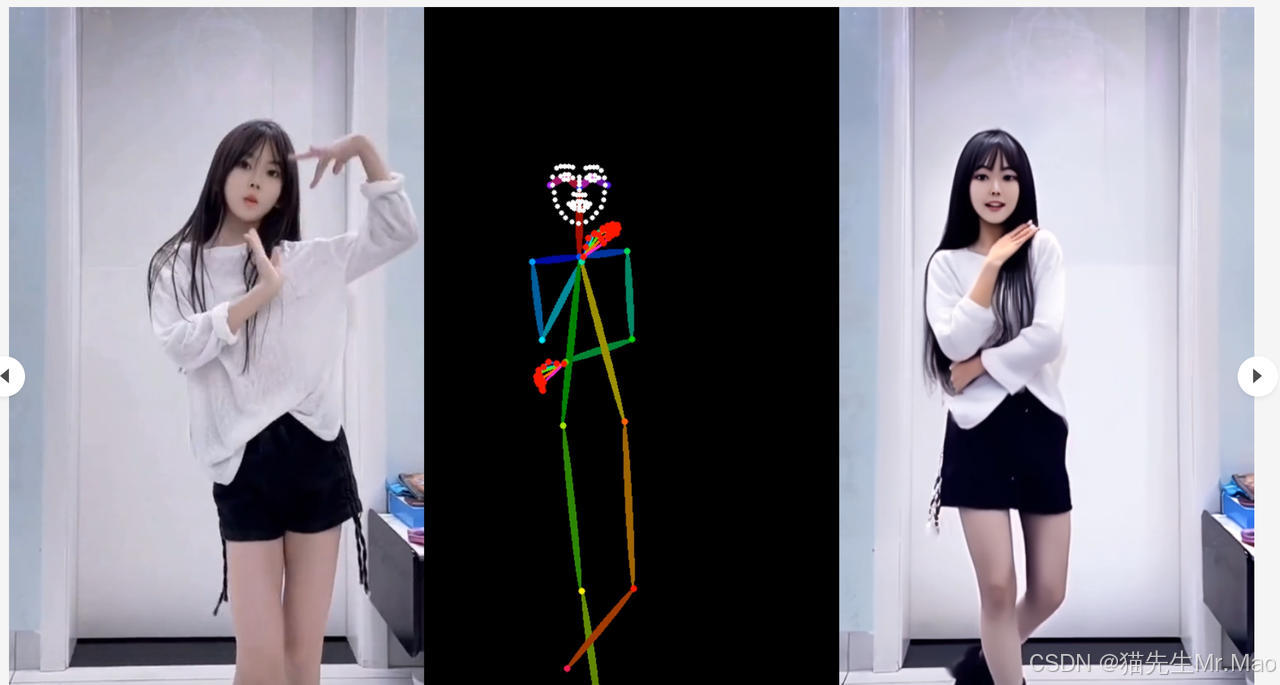
DisPose:用于可控人体图像动画的视频生成技术
一种可控制的人体图像动画方法,它使用运动场改进视频生成 指导和关键点对应。
一个即插即用的指导模块,用于解开纠缠的姿势指导,它提取了健壮的 仅来自骨架姿势图(Skeleton Pose Map)和参考图像(Reference Image)的控制信号,无需额外的密集输入。
项目主页:https://lihxxx.github.io/DisPose/
FlowEdit:开源图像文本图像编辑技术
一种无需反转、无需优化且与模型无关的文本编辑方法,它通过构建ODE直接映射源和目标分布,降低了传输成本。
该方法将反转过程重新解释为源分布和目标分布之间的直接路径,通过计算编辑方向来驱动直接路径的演变,实现无噪声的图像编辑。
项目主页:https://matankleiner.github.io/flowedit/

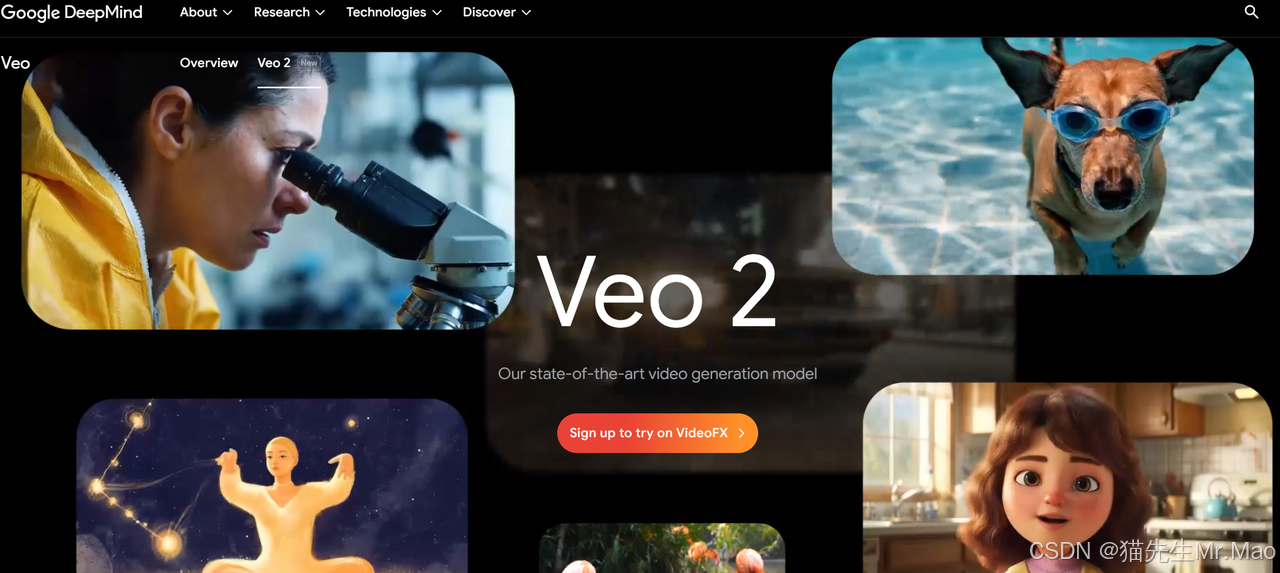
谷歌发布 Veo2 视频模型,支持文生视频和图生视频
Veo 创建的视频具有逼真的动作和高达 4K 的高质量输出。探索不同的风格,并通过广泛的相机控制找到自己的风格。
Veo 2 能够忠实地遵循简单和复杂的指令,并令人信服地模拟现实世界的物理效果以及各种视觉风格。
增强的真实感和保真度:与其他 AI 视频模型相比,在细节、真实感和伪影减少方面有了显著改进。
高级运动功能:Veo对物理学的理解和遵循详细指示的能力,可以高度准确地表示运动。
更多摄像机控制选项:精确解释说明,以创建各种击球风格、角度、动作以及所有这些的组合。
项目地址:https://deepmind.google/technologies/veo/veo-2/
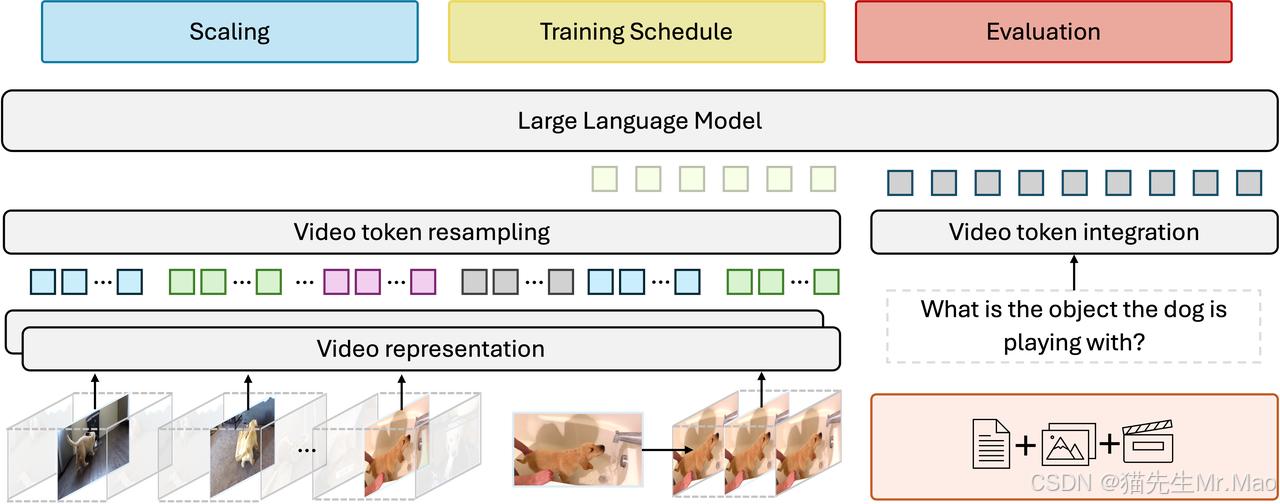
DeepSeek-VL2:面向高级多模态理解的专家混合视觉-语言模型
一系列先进的大型专家混合 (MoE) 视觉语言模型,在其前身 DeepSeek-VL 的基础上进行了显著改进。
DeepSeek-VL2 在各种任务中展示了卓越的能力,包括但不限于视觉问答、光学字符识别、文档/表格/图表理解和视觉接地。
由三个变体组成:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small 和 DeepSeek-VL2,分别具有 1.0B、2.8B 和 4.5B 激活参数。
项目地址:https://github.com/deepseek-ai/deepseek-vl2

Apollo:多模态大模型中视频理解的探索
最先进的视频 LMM 的新系列。在开发 Apollo 的过程中,作者发现了扩展一致性,能够在较小的模型和数据集上可靠地做出设计决策,从而大大降低计算成本。
Apollo 在高效、高性能的视频语言建模方面树立了新的标杆。
项目主页:https://apollo-lmms.github.io/
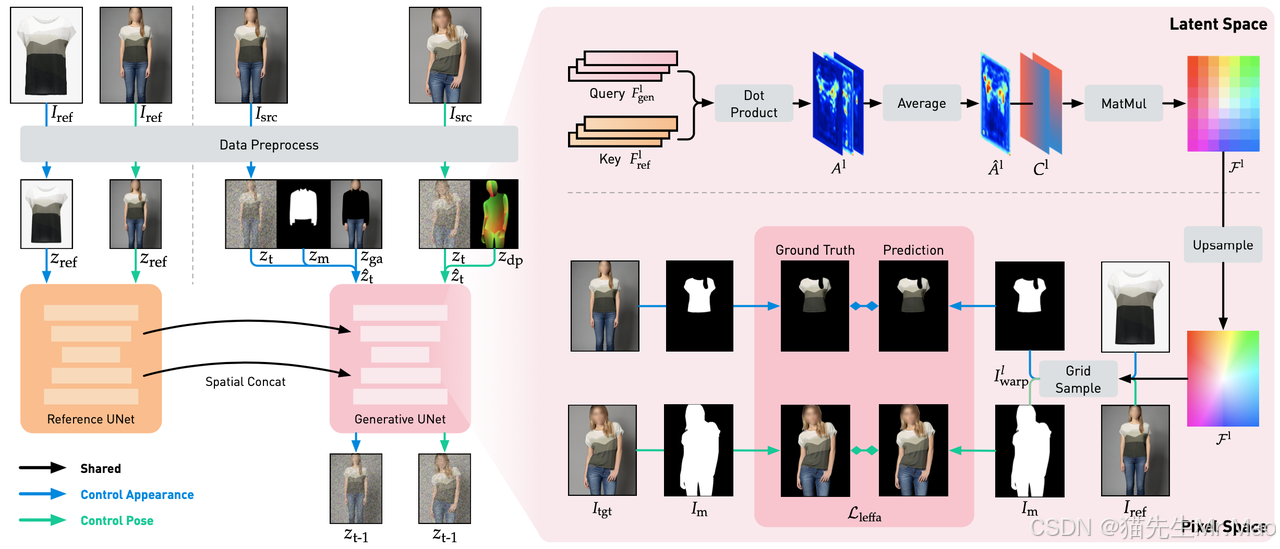
Leffa:开源的可控人物虚拟试穿技术
一个用于生成可控人物图像的统一框架,可以精确处理外观(即虚拟试戴)和姿势(即姿势传输)。
在控制外观(虚拟试戴)和姿势(姿势传输)方面实现了最先进的性能,在保持高图像质量的同时显着减少了细粒度的细节失真。
项目地址:https://github.com/franciszzj/Leffa
OpenAI Sora终于正式发布
支持生成最高1080p分辨率、长达20秒的视频
提供给ChatGPT Plus和Pro订阅用户使用
包含"探索"页面展示社区创作、"故事板"功能等新特性
官方地址:https://openai.com/sora/

StableAnimator:开源的单图跳舞视频生成技术
第一个端到端 ID 保留视频扩散框架,它以参考图像和一系列姿势为条件,无需任何后处理即可合成高质量视频。
基于视频扩散模型构建,包含精心设计的模块,用于训练和推理,以实现身份一致性。
引入了一种新颖的分布式感知 ID 适配器,它可以防止时间层引起的干扰,同时通过对齐保留 ID。
项目主页:https://francis-rings.github.io/StableAnimator/
Worldlabs:单图生成可交互 3D 世界 AI 系统
大多数 GenAI 工具都制作图像或视频等 2D 内容。相反,以 3D 形式生成可以提高控制和一致性。这将改变我们制作电影、游戏、模拟器和物理世界的其他数字表现形式的方式。
只需输入一张图片即可生成一个可探索的 3D 世界。
生成的场景支持景深、变焦等相机效果,官方博客展示了非常多的可交互效果,值得一试。
项目主页:https://www.worldlabs.ai/blog

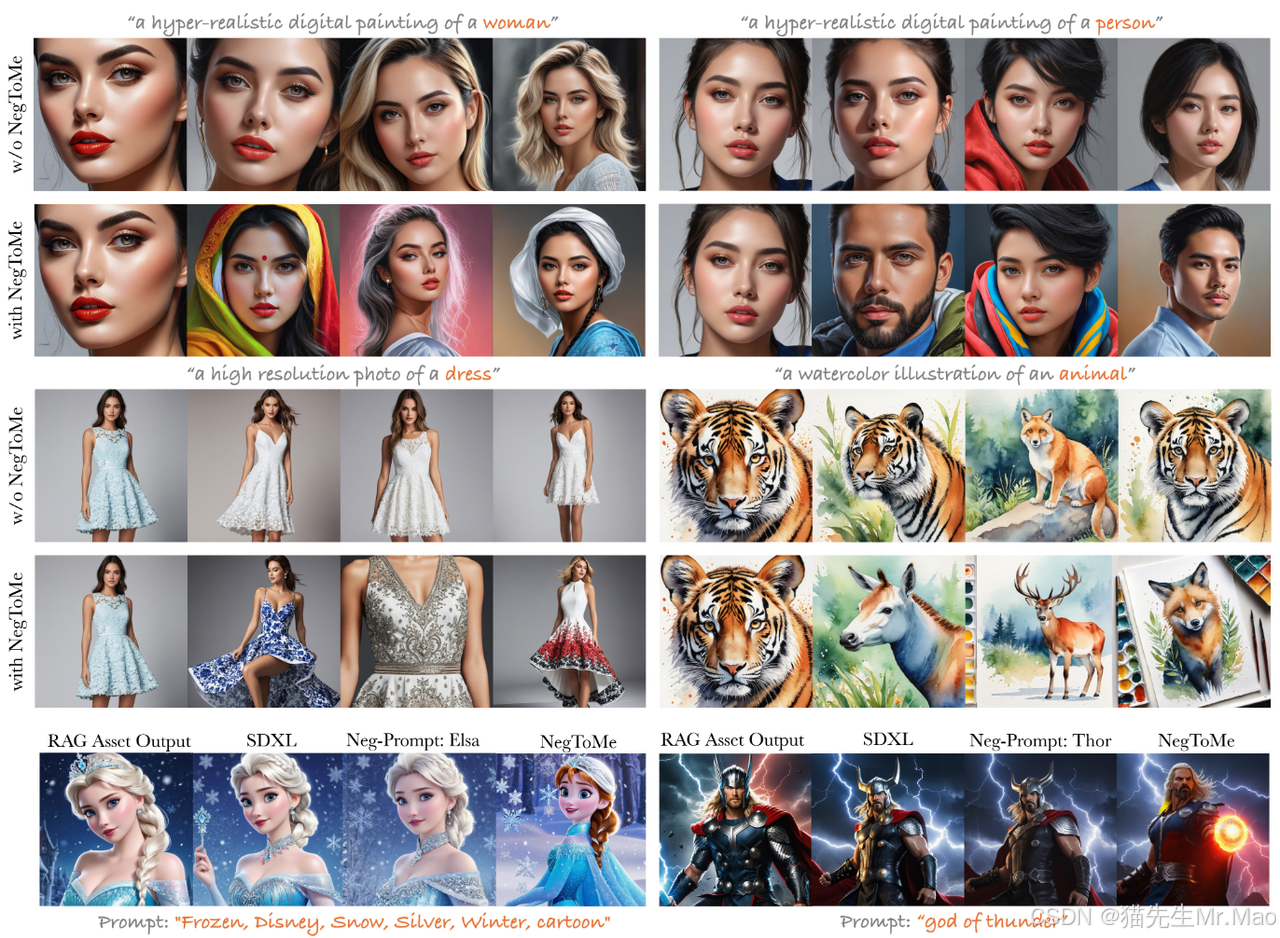
NegToMe:提升生图多样性与版权规避
增加输出多样性:在不同输出中使用 NegToMe 可以提高输出多样性。
版权缓解:当使用受版权保护的检索数据库 (RAG) 作为参考时,NegToMe 可以更好地减少与 cpyrighted 图像的视觉相似性。
提高输出的美感和细节:只需使用模糊/质量差的参考即可改善输出的美感和细节,而无需任何微调。
对抗式指导:将 NegToMe w.r.t 用于样式参考图像有助于排除某些艺术元素,同时仍能获得所需的输出内容。
项目主页:https://negtome.github.io/
Meta 发布 Llama 3.3 70B:支持 128K 上下文与多语言增强
Llama 3.3 是一种使用优化的 transformer 架构的自回归语言模型。调整版本使用监督式微调 (SFT) 和基于人类反馈的强化学习(RLHF),以符合人类对有用性和安全性的偏好。
Meta Llama 3.3 是 70B (文本输入/文本输出) 的预训练和指令调整生成模型。
Llama 3.3 指令调整的纯文本模型针对多语言对话使用案例进行了优化,在常见的行业基准上优于许多可用的开源和封闭式聊天模型。
项目地址:https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct

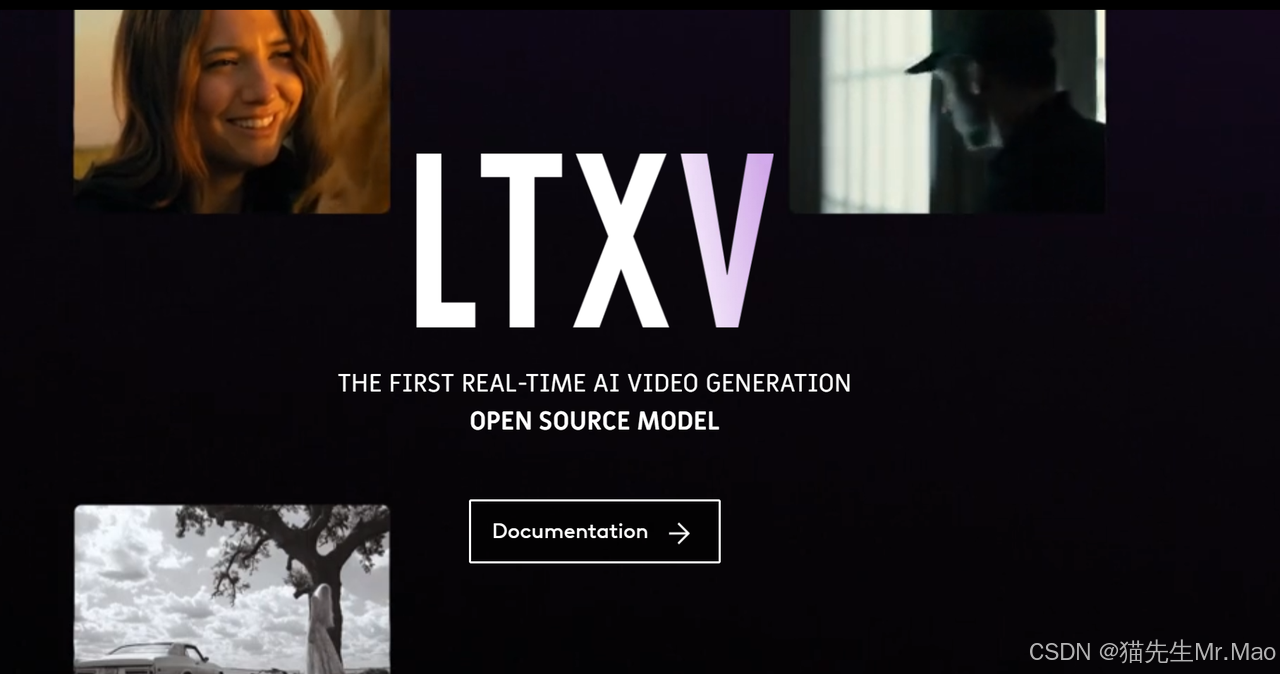
LTX-Video:首个开源实时的视频生成模型
可扩展的长视频制作:能够生成具有可扩展性一致性的扩展高质量视频,从而提供更大的灵活性和控制力。
更快的处理和渲染时间:TXV 针对 GPU 和 TPU 系统进行了优化,可大幅缩短视频生成时间,同时保持高视觉质量。
无与伦比的运动和结构一致性:LTXV 独特的帧到帧学习可确保帧之间的连贯过渡,从而消除场景中的闪烁和不一致等问题。
项目主页:https://www.lightricks.com/
代码地址:https://github.com/Lightricks/LTX-Video
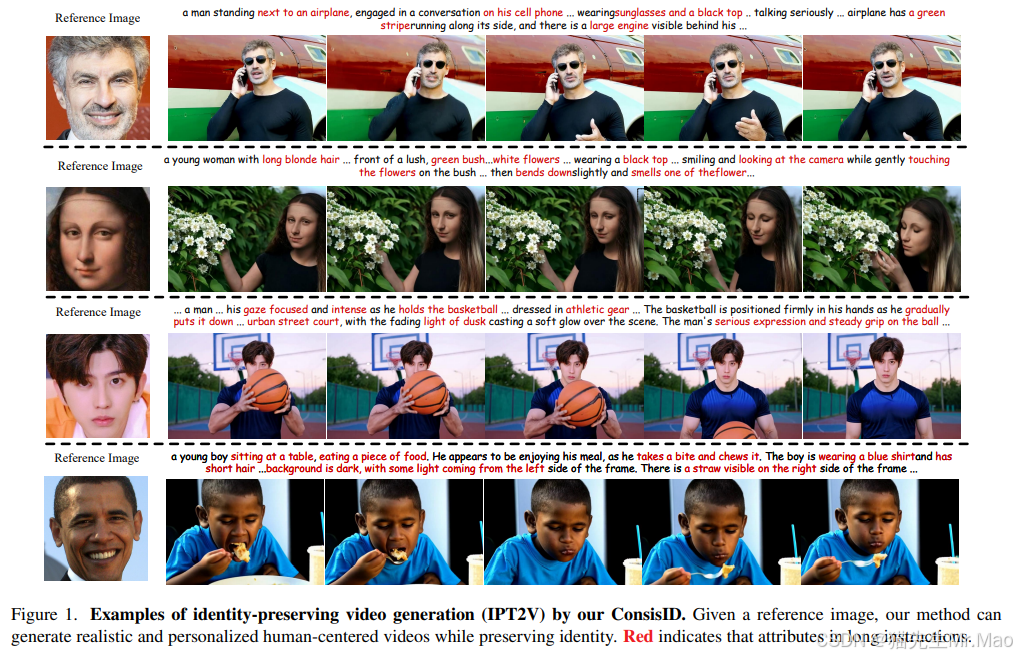
ConsisID:保持角色一致性的文生视频模型
一种免调整的基于 DiT 的可控 IPT2V 模型,可在生成的视频中保持人类身份的一致性。
角色一致文本到视频 (IPT2V) 生成旨在创建具有一致人类身份的高保真视频。这是视频生成中的一项重要任务,但对于生成模型来说仍然是一个悬而未决的问题。
项目主页:https://pku-yuangroup.github.io/ConsisID/
更多精彩内容,尽在「魔方AI空间」,关注了解全栈式 AIGC内容!!
推荐阅读
技术专栏: 多模态大模型最新技术解读专栏 | AI视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向AGI系列
技术资讯: 魔方AI新视界
技术综述: 一文掌握Video Diffusion Model视频扩散模型 | YOLO系列的十年全面综述 | 人体视频生成技术:挑战、方法和见解



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









