



目录
引言
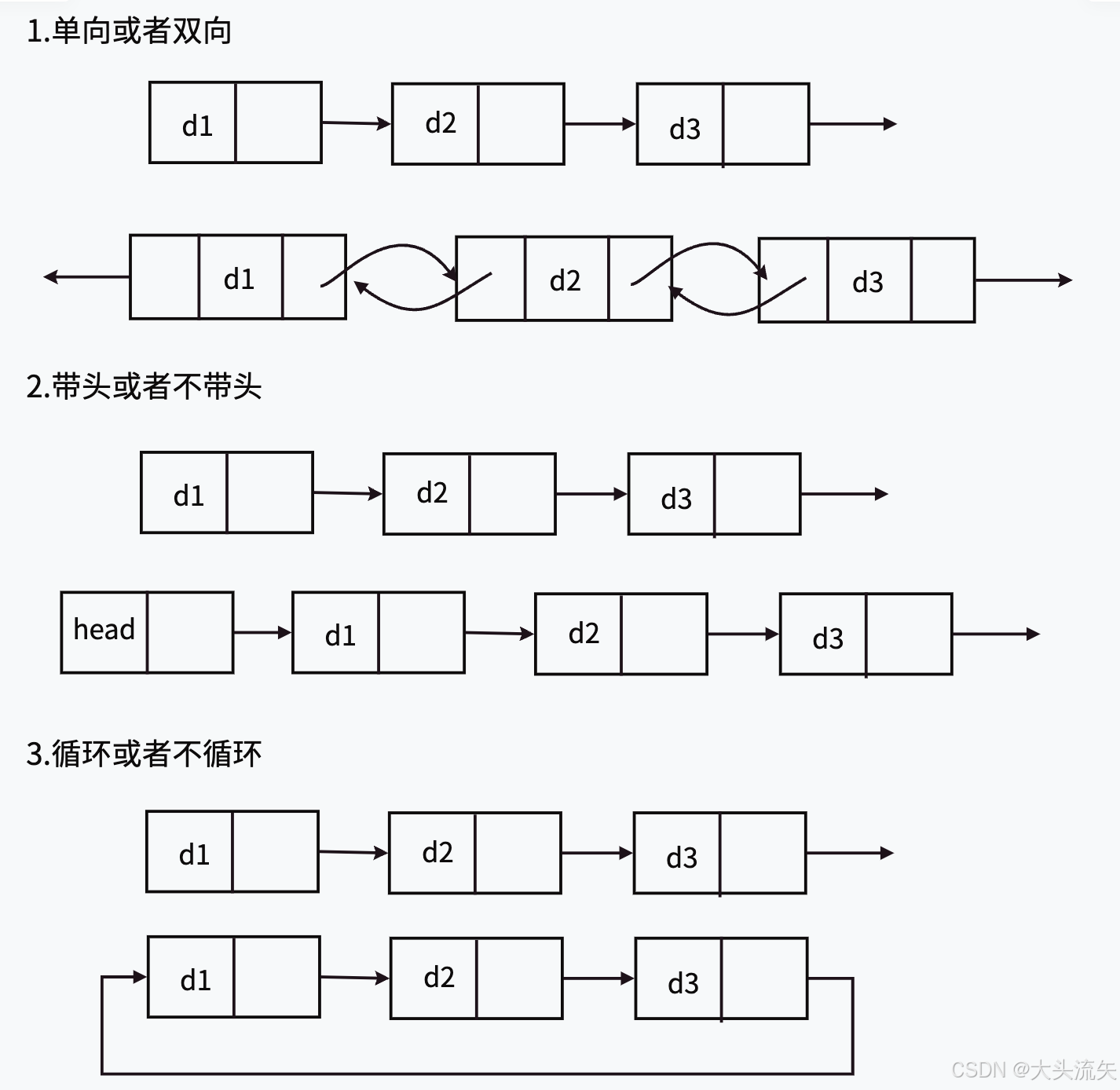
首先我们先看一下链表的家族成员
链表家族树:
├── 单链表
│ ├── 不带头单链表
│ ├── 带头单链表
│ ├── 不带头单循环链表
│ └── 带头单循环链表
│
└── 双链表
├── 不带头双链表
├── 不带头双向循环链表
├── 带头双向循环链表
└── 带头双向链表整个链表大致有8个成员,但是其实他们之间是有很多共同点的,所以我们这次主要以
什么是头?
不带头单链表
带头单链表
带头双向循环链表
来讲解
什么是链表
链表是一种线性数据结构,它通过一系列节点(Node)组成,每个节点包含两部分:
数据域:存储数据元素
指针域:存储指向下一个节点的引用(地址)
核心特点
动态结构:不需要连续的内存空间,节点可以分散在内存各处
顺序访问:只能从头部开始按顺序访问,不能像数组那样随机访问
灵活大小:长度可以动态增长或缩减
基本结构示例
节点结构: 链表图示:
[数据|地址] plist → [10|•] → [20|•] → [30|null]
↑数据 ↑指针 ↑尾节点指针为null在C/C++中链表的每一个节点(Node)都是一个结构体,并且该结构体必须要一个存储数据的变量和存储下一个节点地址的结构体指针
plist存储的是第一个节点的地址,最后一个节点的next存储的就是NULL

链表的基本功能
以下是单链表的实现功能:
// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos);
//销毁链表
void SLTDestroy(SListNode** pphead);结构体的设计:
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;//存储数据
struct SListNode* next;//存储下一个节点地址
}SListNode;申请动态节点
// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x)
{
//创建一个节点来存储新增的数据
SListNode* tmp = (SListNode*)malloc(sizeof(SListNode));
if (NULL == tmp)
{
perror("tmp malloc");
exit(-1);
}
tmp->data = x;
tmp->next = NULL;
return tmp;
}单链表打印
// 单链表打印
void SListPrint(SListNode* plist)
{
//我们一般不会直接去修改传过来的头指针,也是为了数据的安全性
SListNode* tmp = plist;
//当tmp为NULL的时候说明已经遍历完了链表
while (tmp)
{
printf("%d->", tmp->data);
tmp = tmp->next;
}
printf("NULL\n");
}单链表尾插
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
//头指针的地址
SListNode** tmp = pplist;
//头指针指向的地址
SListNode* plist = *pplist;
SListNode* flag = BuySListNode(x);
if ( plist == NULL)
{
*tmp = flag;
return;
}
//先遍历到尾节点
while (plist->next)
{
plist = plist->next;
}
plist->next = flag;
}这里我pplist使用了二级指针,原因是应为外面传入的是一个指针变量的地址
因为函数的参数是传入变量的临时拷贝,函数执行结束以后,函数的参数和函数内的局部变量都会销毁
如果我只是把plist整个指针传入该函数,得到的只是整个变量的一份拷贝元素,然后你把一个地址赋值给该变量,函数运行结束后,该变量就销毁了,原本的plist根本没有变化
所以,我们这里的解决办法是传入plist这个头指针的地址,然后在函数内通过它的地址修改他内存中存储的头指针地址
为什么尾插会使用到头指针呢?
应为如果链表为空的话,那么尾插入节点,这个头指针就要指向这个尾插入的节点,所以我在后面代码里面也做了处理这两种情况
单链表尾删
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{
//头指针的地址
SListNode** tmp = pplist;
//头指针指向的地址
SListNode* plist = *pplist;
//头指针指向的地址为空就报错
//说明该链表为空
assert(plist);
//如果链表只有一个节点
if ((*pplist)->next == NULL)
{
free(*pplist);
*pplist = NULL;
return;
}
//查找倒数第二个节点
SListNode* prev = NULL;
SListNode* current = *pplist;
//prev每次都会记录current当前位置后,current才会往后走
while (current->next != NULL)
{
prev = current;
current = current->next;
}
//删除尾节点并更新前一个节点的next指针
free(current);
prev->next = NULL;
}如果看不懂这个while循环条件,没关系,我们先分析一下链表尾删是怎么删的
- 链表不为空(plist != NULL)
- 链表是连续的,每一个节点的next都存储着下一个节点的地址,所以直接删除尾节点,会导致前一个节点存储的next地址为野指针,但是想修改前一个节点的next首先得知道前一个节点的地址
- 所以这里我们current每往后走之前,prev都会保存他的地址
单链表的头插
//单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
//头指针的地址
SListNode** tmp = pplist;
//头文件指向的地址
SListNode* plist = *pplist;
//创建新节点
SListNode* flag = BuySListNode(x);
//如果链表为空
if (plist == NULL)
{
*tmp = flag;
return;
}
//链表不为空
flag->next = plist;
*tmp = flag;
}这里还是一样要考虑一下链表为空的情况,如果为空那么头指针就要单独赋值
单链表头删
// 单链表头删
void SListPopFront(SListNode** pplist)
{
//头文件地址
SListNode** tmp = pplist;
//头文件指向的地址
SListNode* plist = *pplist;
//空
assert(tmp);
//如果头指针为空那就直接返回
if (plist == NULL)
{
return;
}
//先存储头指针的地址
SListNode* del = plist;
*tmp = plist->next;
free(del);
del = NULL;
}这里注意接收plist->next的地址时,一定要用*tmp去接收,不然外面的头指针就不会被修改
单链表查询
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x)
{
if (plist == NULL)
return;
while (plist->data != x)
{
plist = plist->next;
}
return plist;
}单链表删除pos位置节点
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos)
{
SListNode** tmp = pphead;
SListNode* plist = *pphead;
//头部
if (plist == pos)
{
*tmp = pos->next;
free(pos);
}
else
{
while (plist->next != pos)
{
plist = plist->next;
}
SListNode* flag = plist->next;
plist->next = plist->next->next;
free(flag);
}
}这边的pos是上面查询函数的返回值
删除一个节点就需要将它后一个节点的地址赋值给要删除节点的前一个节点的next
所以代码中用plist->next来判断是否等于pos,如果等于,那么此次plist还在要删除节点的前一个节点
销毁链表
//销毁链表
void SLTDestroy(SListNode** pphead)
{
assert(pphead);
while (*pphead)
{
SListNode* del = *pphead;
*pphead = (*pphead)->next;
free(del);
}
}带头单链表
带头单链表,也叫带哨兵位的单链表,什么是哨兵位,就是拿一个结构体的next来存储当头节点的地址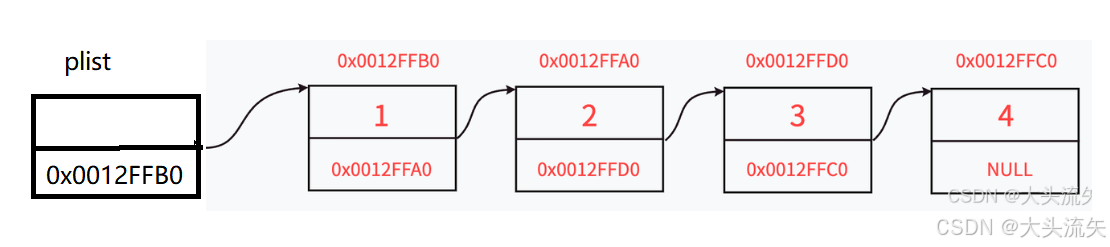
那这样有什么好处呢?和原先那种头指针有什么区别呢
- 就是可以不用再去关注头指针是否为空,原本我们创建的头指针初始值赋NULL,我们在使用时还得考虑空指针不能访问的问题。但是如果你的头指针是哨兵位的话,那么你就需要考虑这个问题,因为哨兵位的地址不可能为空,除非不存在,要空也是哨兵位->next为空
- 我们在空链表头插和尾插、头删、尾删的时候都要用二级指针来接受头指针的地址,不然我们都无法更新头指针。但是现在有哨兵位的话,我们就可以直接通过哨兵位->next来修改,无需在传头指针的地址(你可能在想参数不是临时拷贝嘛,是这样没错,但是我们通过临时拷贝来的指针参数,来访他的next,修改它的值,哪怕最后函数结束,但是我们的值已经修改好了)
带头双向循环链表
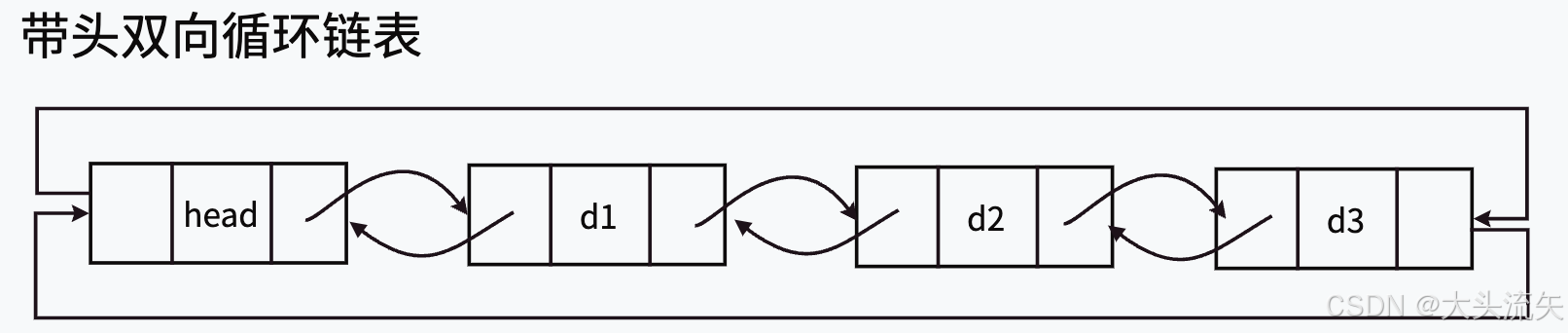
前面我们刚刚讲了哨兵位,所以,我们这边主要讲一下双向循环链表的概念
- 顾名思义,双向循环链表就是每个节点有一个指向上一个节点的指针(prev)和下一个节点的指针(next)
- 循环就是头节点的prev指向尾节点的地址,尾节点的next指向头节点的地址
带头双向循环链表很好的解决了,数据中插、任意插、尾删、的问题,如果直接根据地址来删除节点,那么时间复杂度可以从O(n)直接变为O(1)
带头双向链表相对于带头双向循环链表,在尾插、尾删等涉及到尾部操作的时候时间复杂度还是O(n)
时间复杂度对比(n为链表长度)
| 操作类型 | 普通单链表 | 带头单链表 | 单循环链表 | 普通双链表 | 带头双链表 | 双循环链表 | 带头双向循环链表 | 静态链表 |
|---|---|---|---|---|---|---|---|---|
| 访问头节点 | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) |
| 访问尾节点 | O(n) | O(n) | O(n) | O(n) | O(n) | O(1) | O(1) | O(n) |
| 随机访问 | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) |
| 头部插入 | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) |
| 尾部插入 | O(n) | O(n) | O(n) | O(n)* | O(n)* | O(1) | O(1) | O(n) |
| 指定位置插入 | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) |
| 头部删除 | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(1) |
| 尾部删除 | O(n) | O(n) | O(n) | O(n)* | O(n)* | O(1) | O(1) | O(n) |
| 删除已知节点 | O(n) | O(n) | O(n) | O(1) | O(1) | O(1) | O(1) | O(n) |
| 查找元素 | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) |
| 前向遍历 | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) | O(n) |
| 后向遍历 | 不支持 | 不支持 | 不支持 | O(n) | O(n) | O(n) | O(n) | 不支持 |
注: *普通双链表需要维护尾指针才能实现O(1)尾插尾删,否则为O(n)
适用场景推荐
1. 普通单链表
-
适用:教学演示、简单栈实现、内存受限环境
-
不适用:频繁尾部操作、需要反向遍历
2. 带头单链表
-
适用:需要统一操作逻辑的场景、实现队列
-
不适用:频繁尾部操作、需要高性能
3. 单循环链表
-
适用:约瑟夫环问题、轮询调度、循环缓冲区
-
不适用:需要随机访问、内存敏感
4. 普通双链表
-
适用:需要双向遍历、文本编辑器(撤销/重做)
-
不适用:代码简洁性要求高、新手使用
5. 带头双链表
-
适用:需要双向遍历且代码简洁的场景
-
不适用:频繁尾部操作(仍需遍历)
6. 双循环链表
-
适用:需要双向循环遍历的场景
-
不适用:需要处理空链表特例
7. 带头双向循环链表(推荐)
-
适用:高性能应用、LRU缓存、数据库缓冲池、操作系统内核
-
不适用:内存极度受限、明确不需要循环特性
8. 静态链表
-
适用:嵌入式系统、无动态内存环境、内存池管理
-
不适用:数据量变化大、需要频繁插入删除

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









