






1.安装下载
下载路径:solr-7.5.0下载
2.安装配置
-
7.5的solr是自带jetty容器的,不需要通过tomcat,解压后通过cmd来启动,默认端口为8983
solr 启动、停止、重启命令
solr start -p 端口号
solr stop -all
solr restart -p 端口号
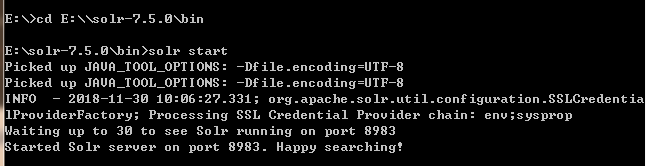
-
启动成功,登录管理页http://127.0.0.1:8983/solr/#/
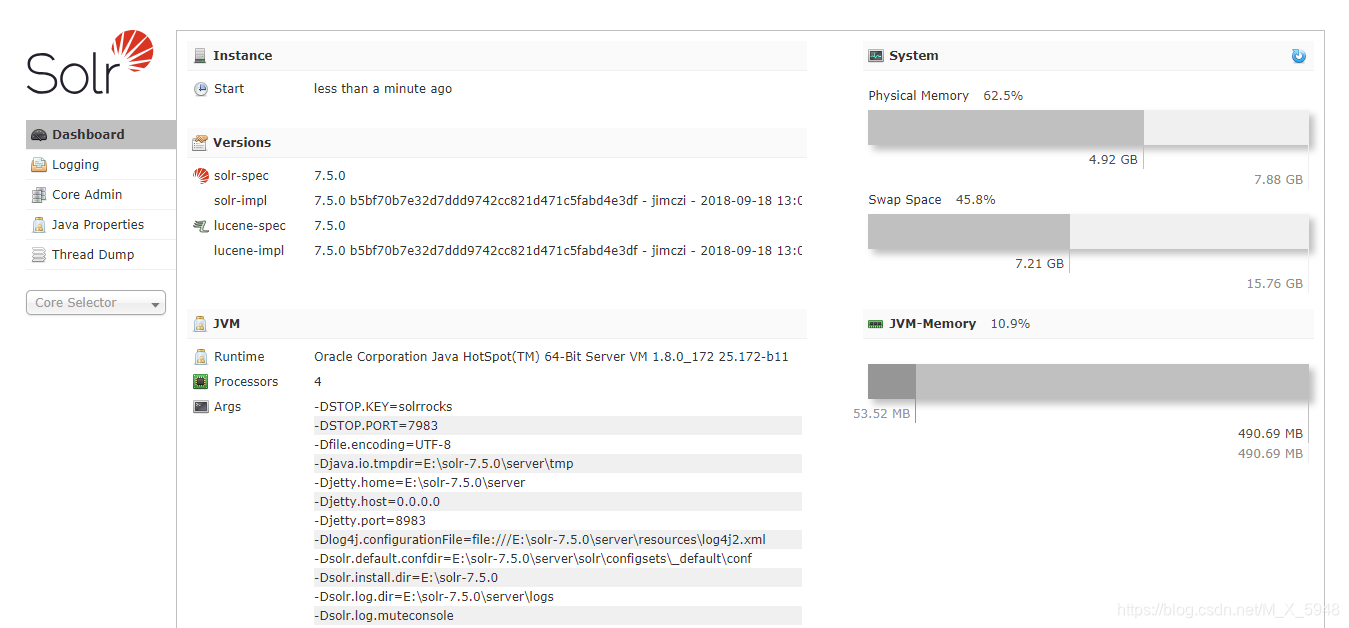
-
配置code
初始化是没有core的,需要新建
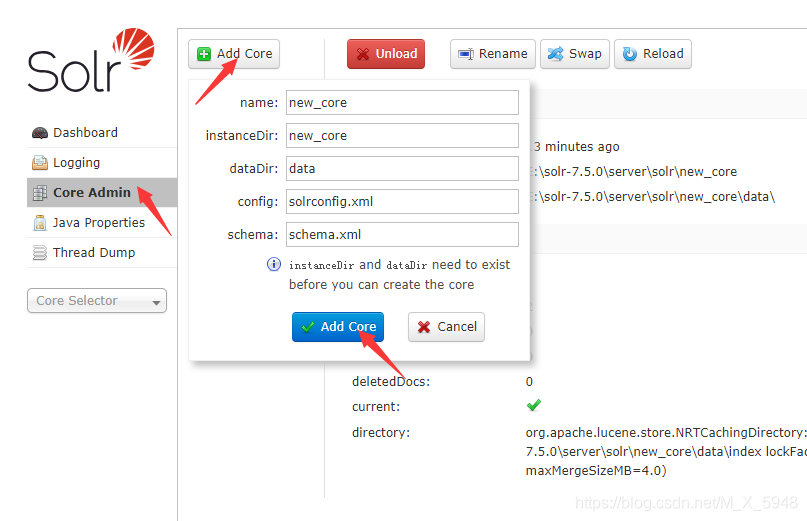
点击Add core之后页面会出现报错,这时我们可以在\solr-7.5.0\server\solr 看到新建了一个对应name的文件夹,以下new_core文件夹皆为本次建的core

报错是因为配置文件不存在,可以把solr-7.5.0\example\example-DIH\solr\db 目录下的conf文件夹复制过来,然后再执行Add core。也可以通过cmd命令来创建core,然后重启solr
cmd命令:solr.cmd create -c mycore ,mycore是自定义core名称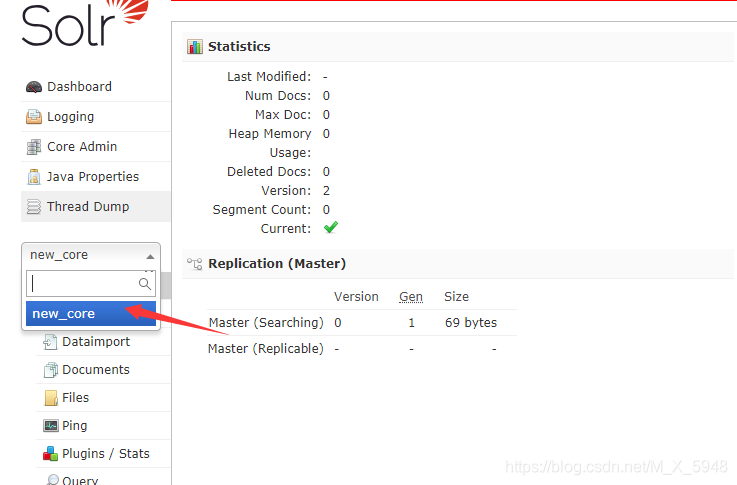
选择我们创建的core进入管理页可以进行测试分词
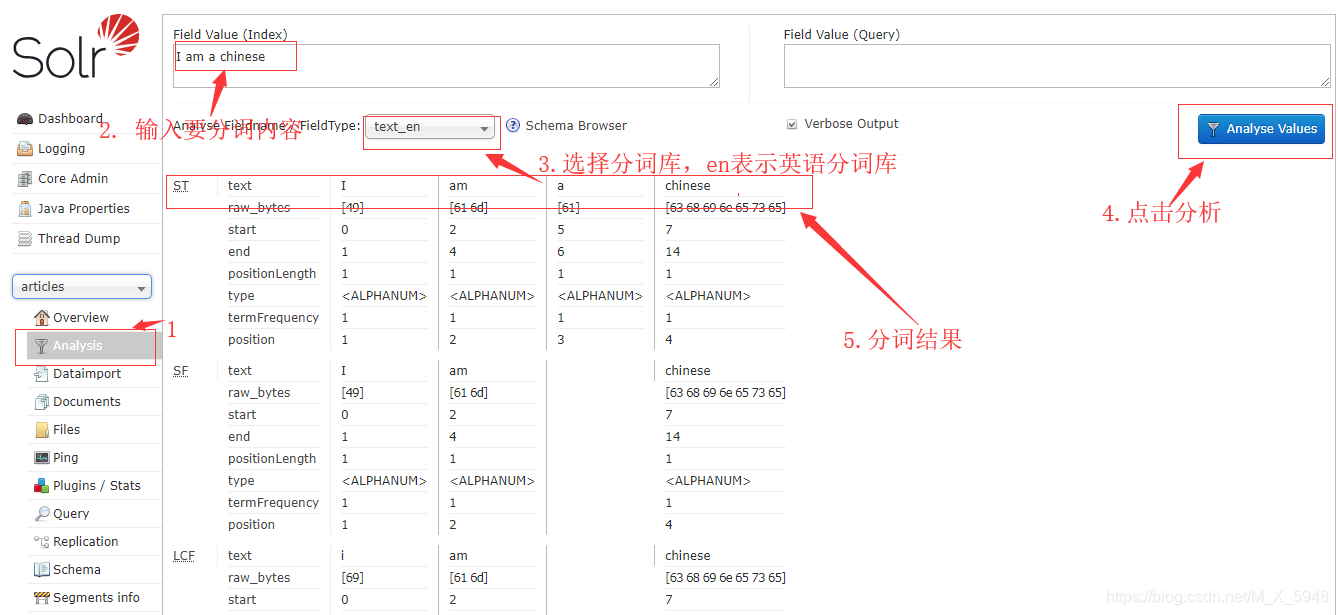
-
solr是默认不支持中文的,所以要进行中文分词插件配置
solr 7.5自带中文分词配置
添加中文分词插件:
将solr-7.5.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.3.1.jar 复制到 solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib目录中配置中文分词
在创建的core文件夹里找到\conf\managed-schema文件,搜索Italian,在Italian下添加我们的中文配置
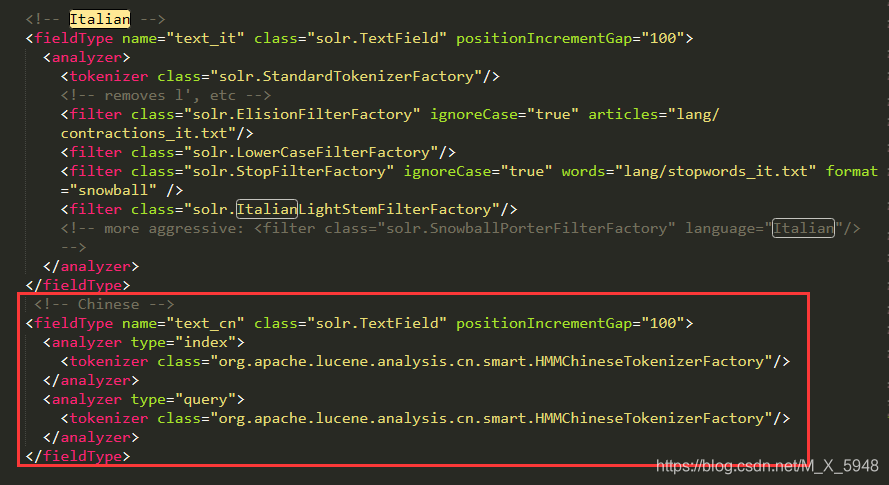
配置代码
<!-- Chinese -->
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
配置ik中文分词
下载:ik分词jar包
同样将下好的 jar 包拷贝到solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib目录中,并在managed-schema文件添加配置
<!-- 我添加的IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
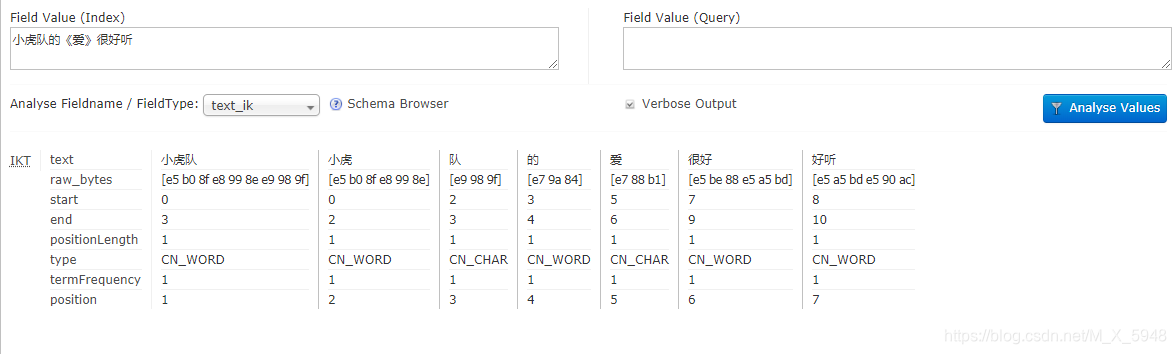
重启solr测试中文分词,选择text_cn/text_ik(中文分词配置代码中的name)分析
自带分词分析结果
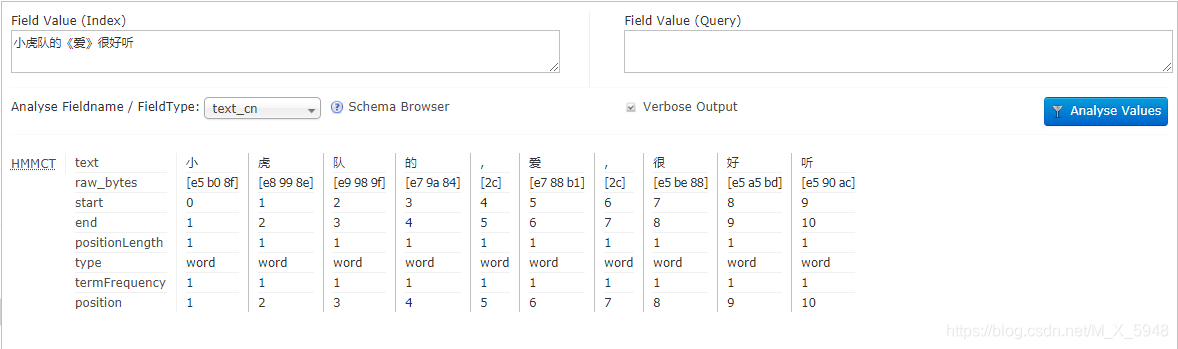
IK分词结果
3.导入数据库
- 在\solr-7.5.0\server\solr\new_core\conf 创建数据库配置文件 mydata-config.xml,配置数据库
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<!-- 配置数据库 -->
<dataSource driver="oracle.jdbc.OracleDriver" url="jdbc:oracle:thin:@localhost:1521:orcl" user="OSN" password="ORCL" />
<document>
<!-- 配置实体 -->
<entity name="PRODUCT" query="SELECT * FROM PRODUCT" pk="PRO_ID">
<!-- column:字段名; name:name对应之后managed-schema文件配置的name -->
<field column="PRO_ID" name="id" />
<field column="PRO_TITLE" name="proTitle" />
<field column="PRO_DETAIL" name="proDetail" />
</entity>
</document>
</dataConfig>
- 之后在\solr-7.5.0\server\solr\new_core\conf\managed-schema文件配置索引字段
例:
<!-- type表示类型,如果需要分词查询则写对应分词库名,比如我用的上文配置的ik分词库,不需要查询的就用相对应类型;
indexed表示需不需要建立索引,以便之后对这个field进行查询;
stored表示需不需要存储这个field本身的内容,以便查询时直接从结果中获取该内容(数据量大时一般不建议存储或全部存储);
multiValued表示一个field是否允许多个值,例一个用户的购买商品列表;
required表示是否拒绝空值的字段-->
<!-- 结果需要的字段都需要写field -->
<field name="proTitle" type="text_ik" indexed="true" stored="true" required="true" multiValued="true"/>
<field name="proDetail" type="text_ik" indexed="true" stored="true" required="true" multiValued="true"/>
因为配置文件本身存在一些索引,所以已经存在的索引不需要重复添加,比如id字段
如果数据库用的自增ID,多个实体查询会导致出现相同ID,后面出现的会覆盖前面ID的索引,网上推荐是在插入数据时,使用UUID(通用唯一识别码)来生成ID储存
- 将mydata-config.xml文件添加至solr-7.5.0\server\solr\new_core\conf\solrconfig.xml配置
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">mydata-config.xml</str>
</lst>
</requestHandler>
<!-- 在以下这句之前添加 -->
<requestHandler name="/select" class="solr.SearchHandler">
- 将solr-7.5.0\dist目录下的solr-dataimporthandler-7.5.0.jar和数据库驱动复制到\solr-7.5.0\server\solr-webapp\webapp\WEB-INF\lib目录下。
- 重启solr服务。
- 打开solr页面,进行下面操作。
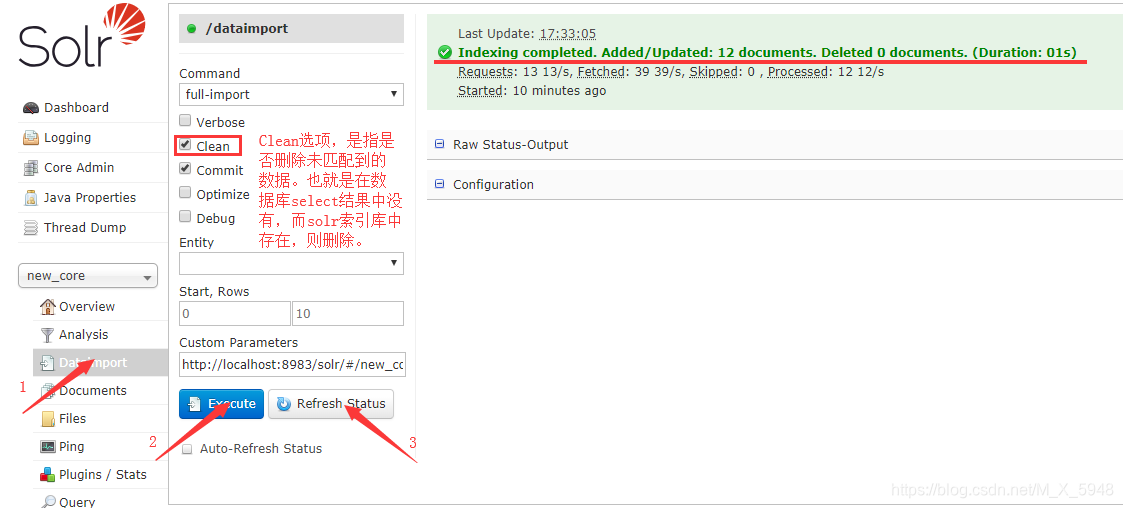
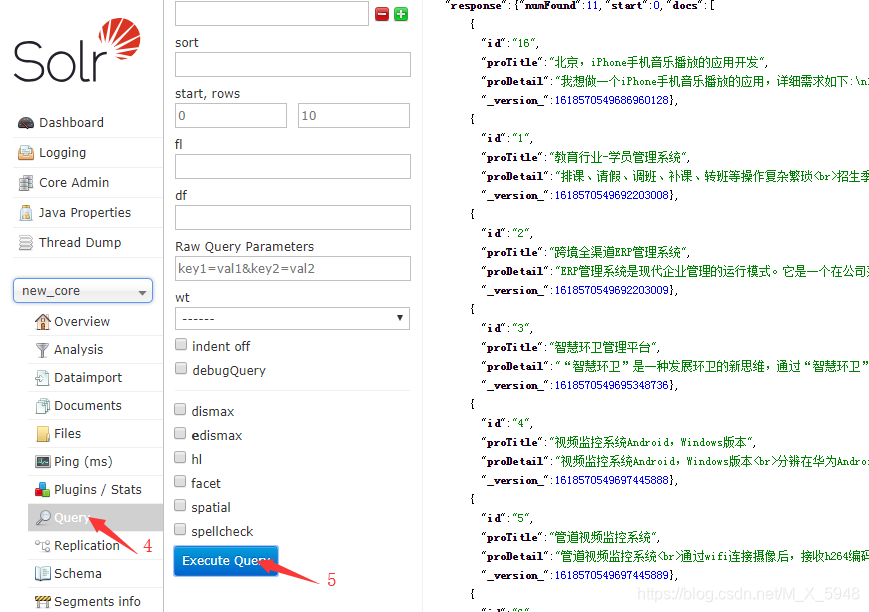
到此数据库导入完毕,下面说solr连表查询
主要是在mydata-config.xml对要多表联查的主表entity内再加附表的实体

注意两个entity的嵌套关系以及两表关联字段
之后与上文一样,在managed-schema文件配置字段类型
重启solr,重新导入数据查询(导入数据库第6步骤)

4.solr的定时增量更新
所需jar包:百度云
提取码:1lei
CSDN下载:传送门
将jar包放置在\solr-7.5.0server\solr-webapp\webapp\WEB-INF\lib里,
在web.xml添加监听
<listener>
<listener-class>
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
</listener-class>
</listener>
之后要手动创建个 dataimport.properties 配置文件,在\solr-7.5.0\server\solr文件夹里,即new_core文件同级,创建一个conf文件夹,在文件夹里创建dataimport.properties
编辑dataimport.properties文件
内容如下(内容来自参考文章)
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
# 修改成你所使用的core
syncCores=new_core
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
# 安装solr的端口
port=8983
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
# 这里改成下面的形式,solr同步数据时请求的链接
params=/dataimport?command=delta-import&clean=false&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
#这里是设置定时任务的,单位是分钟,也就是多长时间你检测一次数据同步,根据项目需求修改
# 开始测试的时候为了方便看到效果,时间可以设置短一点
interval=1
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=7200
# 重做索引的参数
reBuildIndexParams=/select?qt=/dataimport&command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 01:00:00 或者 01:00:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=01:00:00
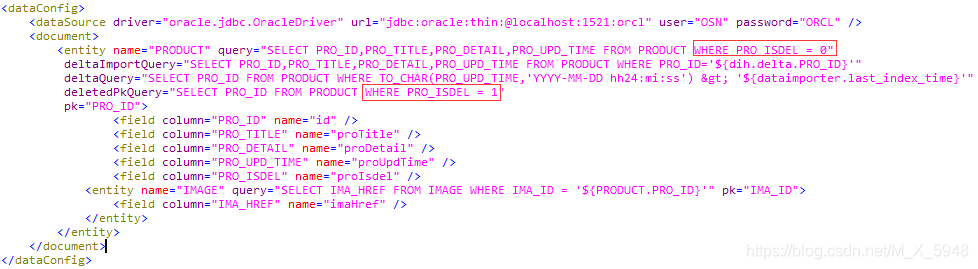
接下来修改mydata-config.xml文件的实体
deltaQuery:增量索引查询ID(只返回ID),需要数据库有个update_time(即更新时间)字段做对比,字段需要设置field类型
deltaImportQuery:根据deltaQuery查询的ID去更新索引
示例代码:
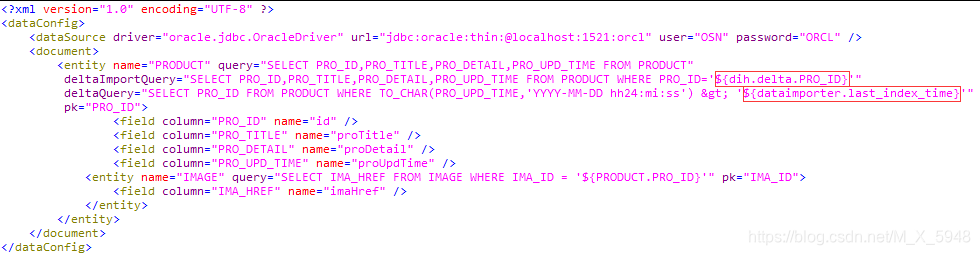
deltaQuery查询的条件${dataimporter.last_index_time}是固定写法,就是拿solr最后一次的更新索引的时间与数据库的update_time做对比,返回的ID给deltaImportQuery做更新用。
solr的更新索引时间来源于core下的conf文件夹的dataimport.properties,即\solr-7.5.0\server\solr\new_core\conf\dataimport.properties ,与上文自己创建的文件不是同一个

因为时区关系,它的时间比我的时间少了8个小时,不过经小测似乎不影响更新
另外,如果数据删除需要删除对应索引,可以在以上两个query下新增一个deletedPkQuery,这里的数据删除是指假删除,与deltaQuery一样,数据库需要个字段去区分删除,也只返回ID,所需字段也要设置field类型。
例如
最后就是重启solr测试了
solr的日志文件是在\solr-7.5.0\server\logs下的solr.log文件,可以查看有没报错。
4.solrj的使用
添加依赖
<!-- solr分词 -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.5.0</version>
</dependency>
创建工具类与方法
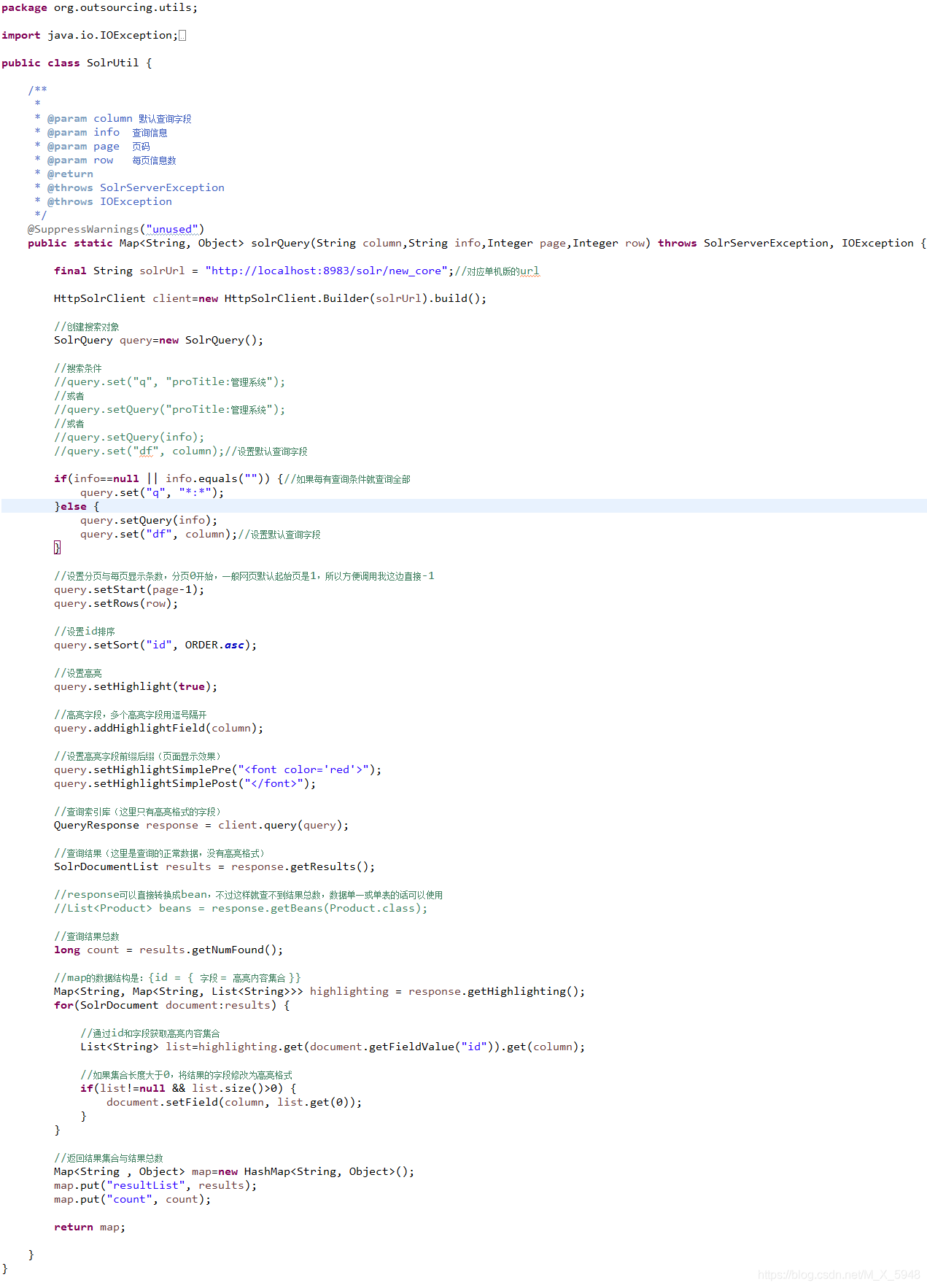
这里我只做了查询,增删改网上也有,下面有两篇solrj文章有提到增删改,就不多做了。
参考文章:
若有误解,还请评论指出。














 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









