






面试这个领域最近环境不行,所以卷起来流量挺大
搭建:
总体来说 比较简单,主要是配置文件,命令的话分开了producer /consumer/ topic 大概这么个意思。具体可以看里面的博客
#host配置
#安装包
wget https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
#压缩 配置系统变量
#zk集群搭建 当然kafka自带zk 这都行,集群中zk的配置是都需要改的
#3.x kafka提供了kraft取代zk
https://blog.csdn.net/qq_41865652/article/details/126588263
点对点:生产者 发送 消息 到队列,消费者从队列 取出 并 消费(消费后不再储存)
一条消息 只会被一个消费者消费,想发给多个消费者 多次发送
发布/订阅:一对多,多个订阅者消费 消息,数据保留指定期限,默认7天
同一个消费组 中消费者 不能消费同一个partition中的数据
一个消费者一个分区(消费组)
0.9 偏移量储存在kafka的topic中
0.9将offset保存在zk中,0.9及后保存在Kafka“__consumer_offsets”主题
生产者
生产消息追加到log文件,采用分片/索引机制,将每个partition 分为多个segment,每个segment对应2个文件 index log,同一文件夹(topic名称+分区序号)。
同步
同步:ISR列表(同步副本 里面的follow与leader同步,选择从这个里面选 H W/LEO)
HW:消费者能看到的offset,isr队列min的LED ,hw-led待同步的消息
选leader (epoch,offset)二位数组,前面是任期 后面是标识大小谁最新
follower故障,从isr剔除,恢复后读取上一次HW高于的截取掉 从hw开始向leader同步 加入isr
- ack-1 数据不丢但会重,生产者pid消息seqnumber 如pid partion seqnumber一样,重复数据
- 0不重复 丢失
消费者
拉取pull,无消息 死循环,消费者 消费数据时传递timeout参数,当时无数据 等待一段时间再返回
topic多个partion
- 轮询rountRobin对topic组生效,一个消费组内all消费者订阅主题是一样的
- rang单个topic生效,数据不均衡
消费者不能同时消费 同组的 同一个分区
分区策略:消费者组 消费者个数 发生变化
offset维护
断电 宕机,消费者恢复后 记录的offset(zk/kafka)
消费者/topic/partion 确定offset
流程
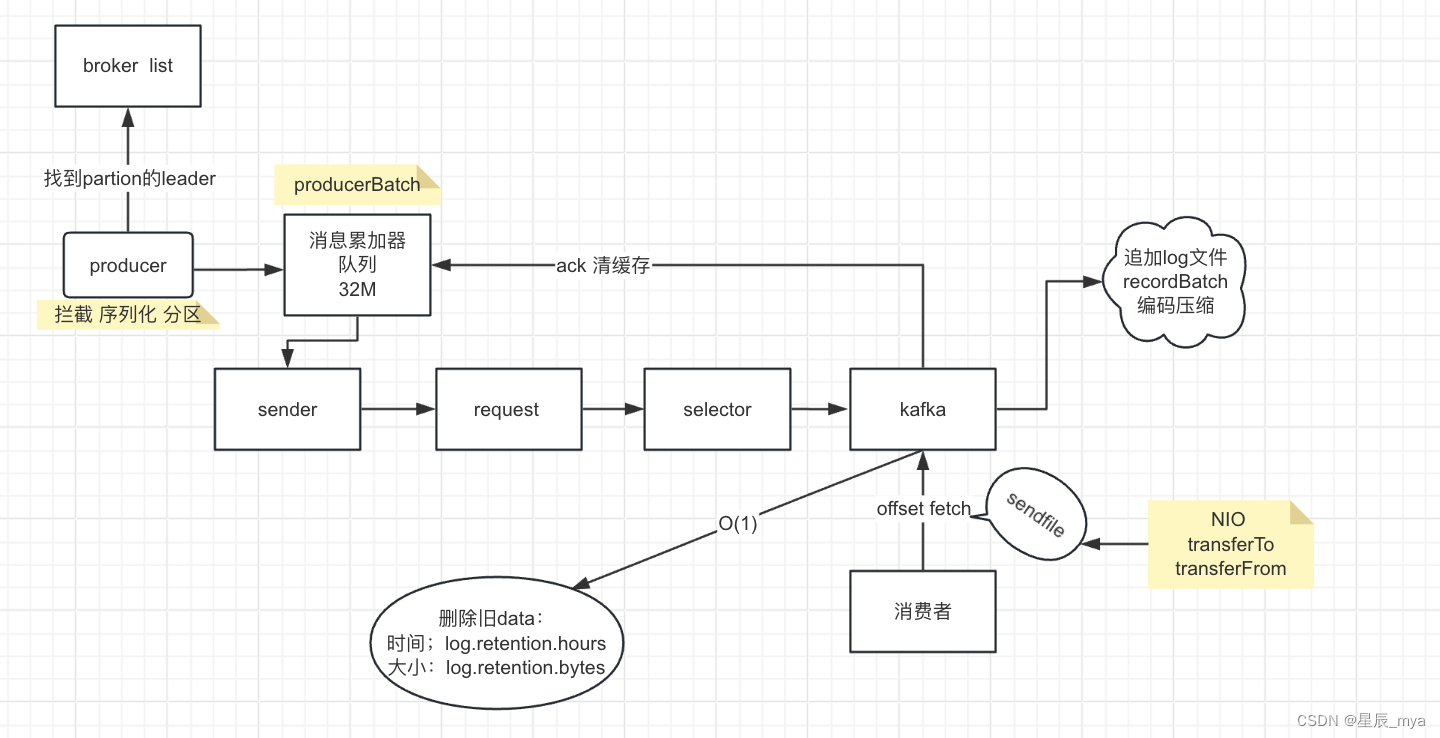
producer两个线程,主线程 拦截/序列化/分区==》处理消息 到 消息累加器(32M / 队列) producerBatch批量发送到sender线程,批量组织request 给selector 送到kafka
kafka 数据 存储在 pageCache 异步刷盘 flusher 追加到日志文件
partition . segment:
log 存储数据 位置:offset
index索引,相对位移:物理位置;稀疏索引 msg设置指针 mmap进行内存操作
被消费ack 清缓存
消费者带着offset,去fetch 利用sendfile底层NIO(transferTo/transferFrom)
消费者能力不足:
原因:
- 大量数据流 consumer崩溃 rebalance 消费速率下降
- 洪峰时consumer从broker取出大量数据,在session.timeout.ms内没有消费完 consumer coordinator没有接受到心跳 挂断,自动提交offset失败(重新分配partition重新消费超时死循环),触发rebalance
- kafka限速
rebalance本质是协议,consumer group下all消费者如何达成一致分配订阅topic每个分区
coordinator执行consumer group管理
- 组成员变更,新consumer入组 consumer离开/崩溃
- 主题变更,使用正则进行订阅,新建正则匹配到topic触发rebalance
- 订阅主题分区数变化
partition分配的高效率
- consumer都要和coordinator连接
- coordinator选出一个consumer作为leader分配partition
- leader分配完后通知coordinator,由coordinator通知其他consumer
- 如一个consumer不能工作(心跳 session_timeout),coordinator触发rebalance重新分配partition
delayed_task
取出一批数据/执行delayed_task/循环yield这批数据/重复执行上述过程
consumer的offset提交机制定时向delayed_task加入autoCommitTask,衡量数据/时间 是否提交
offset提交失败
topicPartition提交单元,consumer消费 发送rebalance,当前消费分配到的partition>1,这个partition分配给其他consumer,如已经被消费再提交offset commitOffsetError,因为partition不属于自己
producer带上create_time字段
https://zhuanlan.zhihu.com/p/33238750
消费者挂了之后重启 直接消费最新的数据,历史数据另起线程补漏
或者从上一次提交offset开始,积压量大 增加任务处理能力
分区少了,数据量大增加分区数
优化/解决
分区数量不能太小/生产者key要均匀(增加随机后缀 均衡分布)
增加消费者数量,或者每次拉取的(合理)数量
主题增加分区,消费者并行处理能力
优化消费逻辑,多线程
max.poll.interval.msrang消费者更长时间处理消息
监控 报警 /及时调整
kafka内置指标
kafka stream:内置了自适应调节机制
数据清理策略:及时清理
数据量太大 生成很多文件 占磁盘空间
设置cleanup.policy清理特定大小日志文件,时间点清理
压缩操作对topic每个键处理,清理重复项,保留最后一个值
启动kafka压缩
compression.type,none不压缩/lz4压缩 加大cpu开销
升级版本
命令
topic的./bin/kafka-topics.sh
生产者./bin/kafka-console-producer.sh
消费者./bin/kafka-console-consumer.sh
https://zhuanlan.zhihu.com/p/347822019
















 2195
2195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









