








问题描述:
两个节点的k8s集群环境,master 和 node
在添加calico服务的时候,master节点正常,node节点上的calico的pod一直异常,10.233.64.1:443 timeout,启动不起来。

问题分析:
calico-node服务需要连接Master节点的kube-apiserver服务,由于网络不通导致连接失败,服务也就启动失败,问题转化成K8S网络问题排查。
解决方案:
查看日志如下:
# kubectl logs -f calico-node-jv2qv -n kube-system
2022-06-18 04:55:45.609 [INFO][9] startup/startup.go 396: Early log level set to info
2022-06-18 04:55:45.609 [INFO][9] startup/utils.go 126: Using NODENAME environment for node name node1
2022-06-18 04:55:45.609 [INFO][9] startup/utils.go 138: Determined node name: node1
2022-06-18 04:55:45.609 [INFO][9] startup/startup.go 98: Starting node node1 with version v3.20.0
2022-06-18 04:55:45.611 [INFO][9] startup/startup.go 401: Checking datastore connection
2022-06-18 04:56:15.613 [INFO][9] startup/startup.go 416: Hit error connecting to datastore - retry error=Get "https://10.233.64.1:443/api/v1/nodes/foo": dial tcp 10.233.64.1:443: i/o timeout其中10.233.64.1是一个clusterIP
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.64.1 <none> 443/TCP 45h进入node节点上,进行telnet命令。结果是,可以ping通,telnet端口不通。
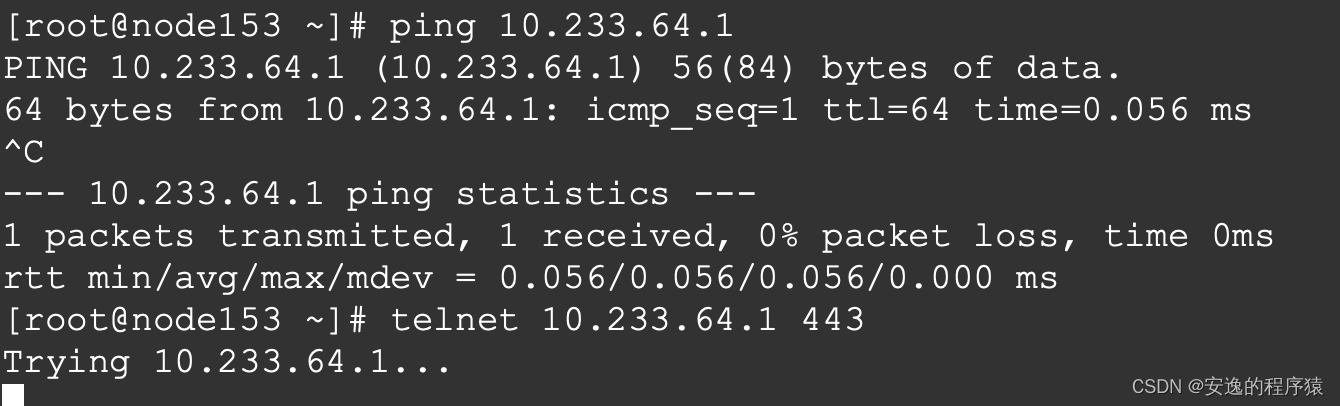
继续查看IPVS的转发规则
# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.233.64.1:443 rr
-> 180.64.10.127:6443 Masq 1 2 0
TCP 10.233.64.3:53 rr
TCP 10.233.64.3:9153 rr
UDP 10.233.64.3:53 rr可以看到10.233.64.1:443 通过 rr轮询 转发到180.64.10.127:6443(这是master节点的apiserver)
尝试一下直接telnet 180.64.10.127 6443,
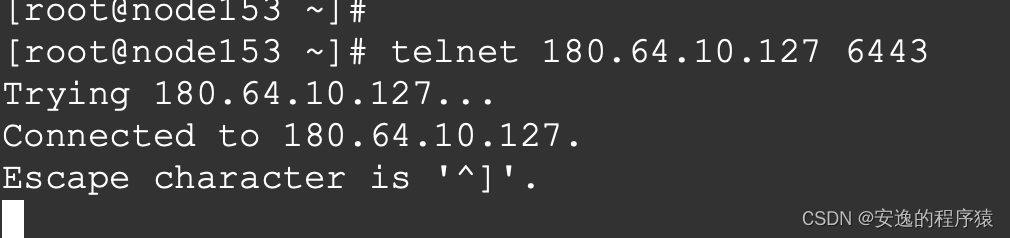
发现这个端口是通的,那就说明,node之间的网络是没问题的。
那问题不会不会是IPVS在转发的时候有问题呢?
查看一下IPVS连接状态
# ipvsadm -lnc
IPVS connection entries
pro expire state source virtual destination
TCP 00:51 SYN_RECV 10.233.64.1:35336 10.233.64.1:443 180.64.10.127:6443结果是 state状态是SYS_RECV
熟悉TCP连接的都知道,TCP需要三次握手建立连接
kubectl edit cm kube-proxy -n kube-system
mode: ipvs 修改为 mode:""
然后删除pod,重启kube-proxy(这里最好把主机都重启一下,不然IPVS规则还存在主机上)
重启后,查看服务,全部RUNING了。
然后对ClusterIP进行测试,ping是不通,telnet是通的。

那这里为什么会PING不通呢?
其实ClusterIP本身就是
kube-proxy有一个dummy虚拟网卡,当启用ipvs的模式,会创建个kube-ipvs0,然后把所有的Service Cluster IP添加到kube-ipvs0中,如下 :
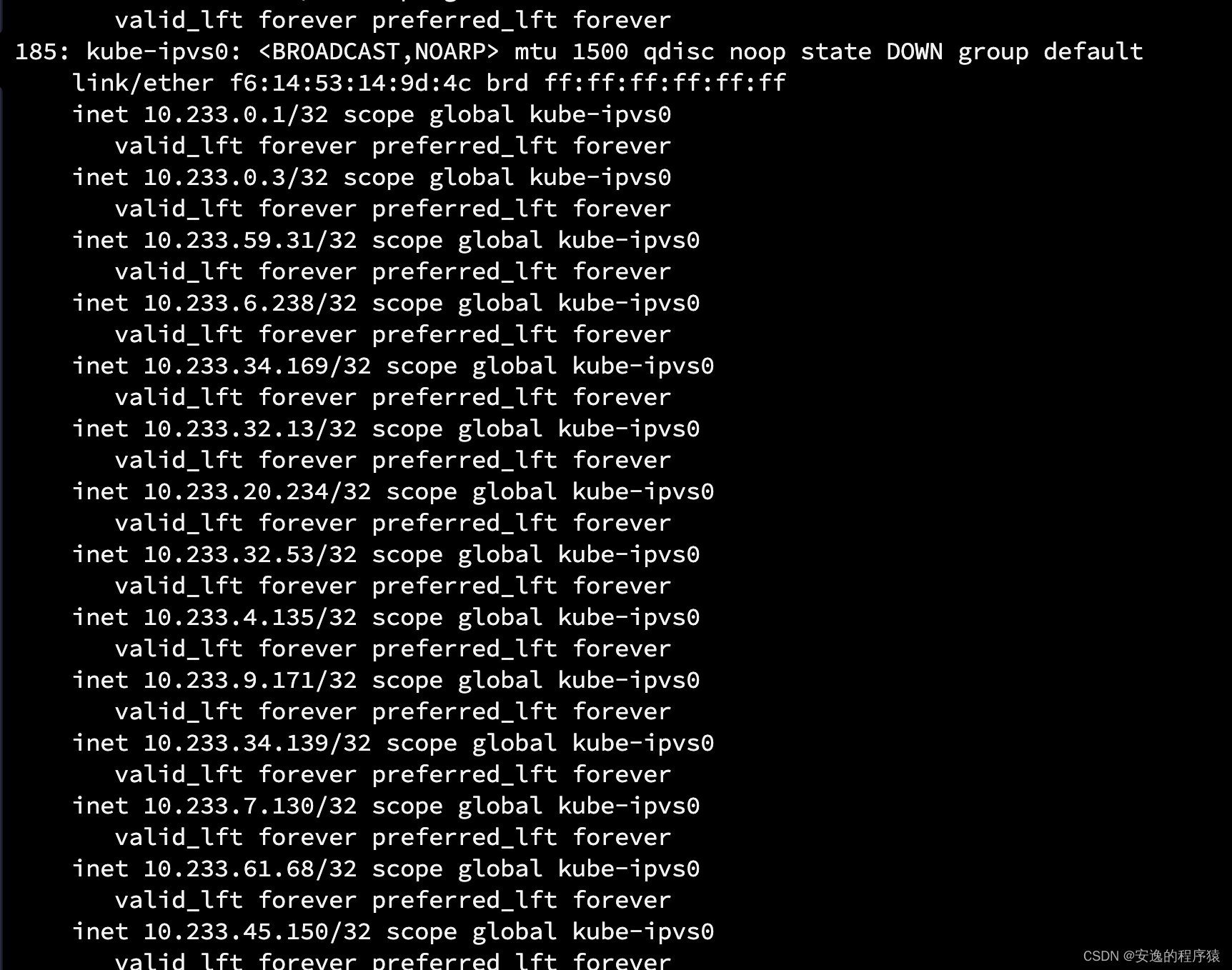
就相当于这些IP在你的主机上是存在的,当你去访问的时候,会根据ipvs规则转发到对应的服务上。相反,如果使用iptables模式的话,是没有这些ip的,也就不能ping通,但是iptables的规则是有的,可以通过clusterIP去访问到服务。
问题总结:
本次出现的问题是因为节点中容器连接k8s的clusterIP失败,然后了解一下访问过程,每个过程进行排查,找出是IPVS的问题,最后改换成Iptables解决了问题。但IPVS出了什么问题还没有搞明白,等哪天查出原因,会在下面继续更新。















 5494
5494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











