






导读:hulk是短视频研发部研发的基于GDP2的go服务开发框架。它是⼀款⾯向业务的Web开发框架,提供了诸多开箱即⽤的组件和功能,可以⽤来快速开发Web服务。同时,依托于hulk框架并结合⼚内/业界优秀的开发实践,初步构建了⼀个符合业务应⽤场景的go⽣态体系。
1. 产生背景
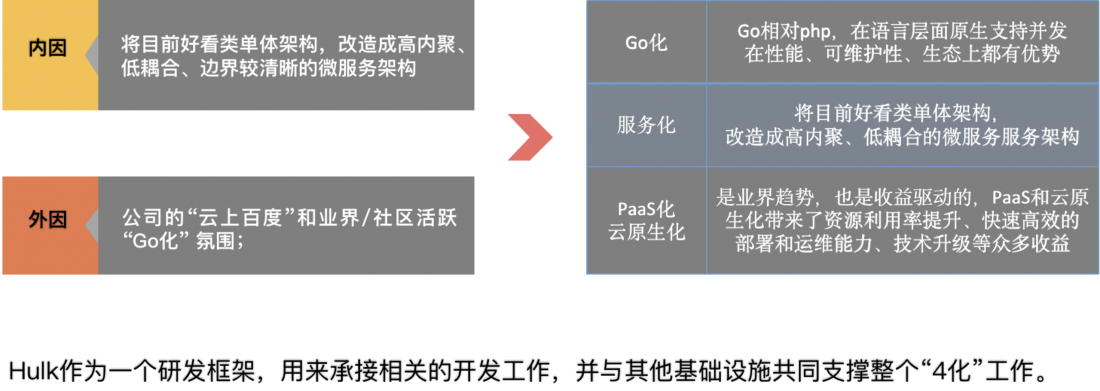
hulk框架是在“好看视频”服务端的go服务化架构升级背景下产生的。
1.1 为什么要做架构升级?当前架构面临哪些问题?
好看视频初期因业务需要快速、灵活的开发迭代,采⽤PHP作为开发语⾔实现后端服务,前期取得了⽐较好的开发迭代效果。但随着好看业务快速发展,服务端的项⽬(接⼝、代码等)急速膨胀,类单体的PHP架构在多个⽅⾯遇到了瓶颈和问题,主要体现在以下⼏个⽅⾯:
- 开发效率:对于主代码库,所有服务端同学都会在这同一个代码空间开发,此外还有依赖的第三方团队也会修改,频繁的修改/合并降低了开发效率,同时也加大了代码的维护成本和难度;
- 上线效率:多用户开发同一代码库的另一个弊端就是上线等待,由于同一个时刻只能有一个分支上线(分级上线),导致相连的上线需求要排队等待。这也导致我们的同学摸索出“搭车上线”的模式,虽然加快的上线效率,但也加大的上线的风险,没有从根本上解决问题;
- 运行效率:PHP在开发效率和灵活度方面确实有一定优势,但当所支撑的业务达到几千万DAU及以上时,我们必须要考虑服务的运行效率和资源成本等问题。PHP语言在多线程/多协程的支持上,弱于Java、C/C++、Go等语言,基于物理机部署的类单体服务部署架构,在资源利用率和服务扩缩容等方面也很难满足需求;
- SRE效率:在出现稳定性问题时,我们期望能够做到快速感知、快速定位、快速止损。目前基于sia的监控/报警,基于日志的问题定位方式距离理想目标还有一定的距离:一是同学要奔波于各个平台/系统获取问题线索,二是获取到的线索及信息维度很多时候也无法满足快速、精确定位问题的需求;
这些问题需要通过“4化”,从总体业务架构、部署架构、基础设施等多方面去解决:
1.2 为什么不直接基于GDP2 ?
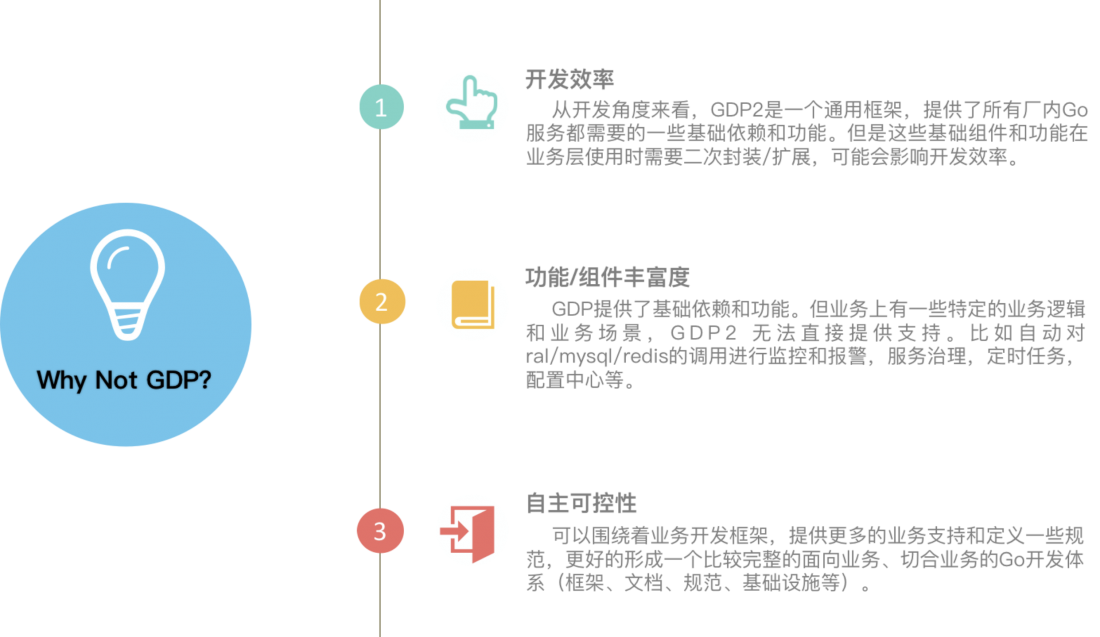
好看的go服务化升级工作开展时,GDP2还未正式发布,这也是其中一个因素。
1.3 hulk与gdp2能⼒对照
1.3.1 web server能⼒
| 功能middleware | GDP2 | hulk |
|---|---|---|
|
logger_middleware
(⽇志)
| 记录服务请求和执⾏⽇志 |
在基本输出外,还⽀持对打印字段控制,如过滤bduss等; ⽀持⽇志打印策略,如按idc/ip/百分⽐/cuid等维度动态控制打印;
|
|
b2logger_middleware
(pb⽇志)
| 未集成 | 将服务请求和执⾏⽇志以pb格式打印 |
|
recover_middleware
(panic recover)
| ⽀持panic捕获及⽇志记录 |
在panic捕捉和记录之外,还与sentry和如流做了集成,可以秒级感知panic并快速定位
|
|
timer_middleware
(监控)
| 未集成 |
⽤于http请求的监控埋点,可以输出可⽤性、tp99、流量、平响、错 误码等metrics,维度包括service/idc/instance等
|
|
timeout_middleware
(超时)
| ⽀持,控制接⼝的超时时间 | ⽀持动态控制接⼝超时间,并可以按idc维度分别设置超时时间 |
|
flow_control_middleware
(限流)
| 未集成 |
接⼝限流组件,可以通过配置中⼼或管理接⼝,对接⼝qps按 idc/instance维度进⾏限流
|
|
thirdpart_auth_middleware
(鉴权)
| 未集成 |
⽀持接⼝维度的第三⽅访问的鉴权,⽀持ak、sk、⾃定义校验字段、 ⾃定义验签算法等
|
| 管理接⼝ | 未集成 |
提供了:健康检查,服务治理-熔断、限流、降级,metrics,线上实例性能调试等管理接⼝
|
1.3.2 功能/组件
| 功能/组件 | GDP2 | hulk |
|---|---|---|
| ral | 支持 |
基于gdp2 ral做了增强实现:
1. 增加了通过字符串⽽⾮⽂件来进⾏ral初始化和ral懒加载功能;
2. 集成了prometheus的监控信息采集、熔断、降级等hook能⼒;
|
| redis | ⽀持 |
基于gdp2 redis做了增强实现,集成了多个hook能⼒:
1. metrics,对所有cmd进⾏prometheus打点;
2. sentry,⽀持将redis错误保存到⽇志的同时发送sentry事件;
3. 降级hook,⽀持按集群/实例/百分⽐维度降级redis访问;
4. 熔断hook,⽀持按集群/实例/错误率/慢请求率进⾏熔断设置;
|
| mysql/gorm | ⽀持 |
基于gdp2 mysql和gorm_adapter的封装和增强:
1. metrics,对所有请求进⾏prometheus打点;
2. sentry,⽀持将mysql错误在记错误⽇志的同时发送到sentry;
|
| 定时任务 | 未集成 |
⽀持两种定时任务模式
1. 带分布式锁的运⾏⽅式;
2. 不带分布式锁的运⾏⽅式:
|
| 分布式锁 | 未集成 | 基于redis的分布式锁实现 |
| 协程池/协程编排 |
⽆协程池
有GTask
|
1. 有基于开源库ants的协程池实现HulkPool;
2. 有基于协程池的类Gtask协程编排⽀持HulkTask;
3. 有兼容PHP phaster使⽤⽅式的hulk phaster组件;
|
| sentry | 未集成 | 借助sentry,对于⼀些故障,我们可以快速感知、快速定位 |
| 如流 | 未集成 | 配置token后,直接使⽤ruliu组件向指定的如流群发送报警/通告 |
| prometheus | ⽀持 | 与hulk框架深度集成,可以对所有inbound/outbound流量做监控 |
| 配置中⼼ | 未集成 | ⽀持开源的Apollo和⾃研的iConf配置中⼼ |
| 服务治理 | 未集成 |
基于Sentinel的服务治理能⼒,以流量为切⼊点,可以从限流、流量整形、熔断、降级等多个维度来协助保障服务稳定性
|
| opentracing/jaeger | 未集成 | 集成了对jaeger分布式调⽤链的⽀持 |
| 热加载 | 未集成 | 主要⽤于开发阶段,可以⾃动加载修改的⽂件,⽆需⼿动重启服务 |
1.3.3 框架周边及基础设施
| 周边/基础设施 | GDP2 | hulk |
|---|---|---|
| ⽀持的应⽤类型 |
http server
rpc server
| ⽬前只⽀持http server |
| ⽬录规范 | 有 | hulk的⽬录规范定义更偏向http应⽤场景 |
| ⽂档与示例 | 有,⽐较完善和丰富 | 有较完整成体系的⽂档,但丰富度和规范度还有待向gdp看⻬ |
| 代码⽣成器 | 有 | hulk包括标准项⽬结构的代码⽣成和数据库model/dao层代码⽣成 |
| prometheus+grafana集群 | 无 | 通过k8s部署在百度云上,⽬前为1500+实例和500+报表提供服务,支持第三方接入 |
| sentry集群 | 无 | 通过k8s部署在百度云上,⽬前接⼊服务50+,支持第三方接入 |
| 配置中⼼集群 | 无 | 云主机⽅式部署,⽬前接⼊服务30+,支持第三方接入 |
| 故障智能定位 | 无 | 基于hulk的故障智能定位系统,⽬前接⼊服务10+,支持基于hulk框架的第三方接入 |
NOTE:1. 好看在做go化时,也调研了开源社区⾥⽐较优秀的⼀些⼯具系统和⽅案并引⼊, hulk中默认添加了对这些基础设施的集成;
1.3.4 对照总结
本节主要站在hulk能力角度与GDP2做了一些方面的参考对照。以上对照,可以概括为4点:
- 很多基础能⼒,hulk是复⽤gdp的,如:bns、net、codec等;
- ⼀些通⽤/扩展组件,hulk按照业务需求场景,进⾏⼆次封装和增强,如:httpserver、ral、redis、mysql等;
- 对于gdp⽬前没有⽀持的⼀些业务需求,进⾏开发集成,如:定时任务、配置中⼼、服务治理等;
- 参考业界开源实践,引入了一些新的基础设施:如prometheus+grafana集群、sentry集群、故障定位系统等;
GDP2由几十个模块共同构成,由于时间有限,可能个别功能点的对照有偏差。
2. 了解hulk
2.1 设计思路

2.2 框架结构
从功能上来看,hulk的整体能力可以划分为四层:
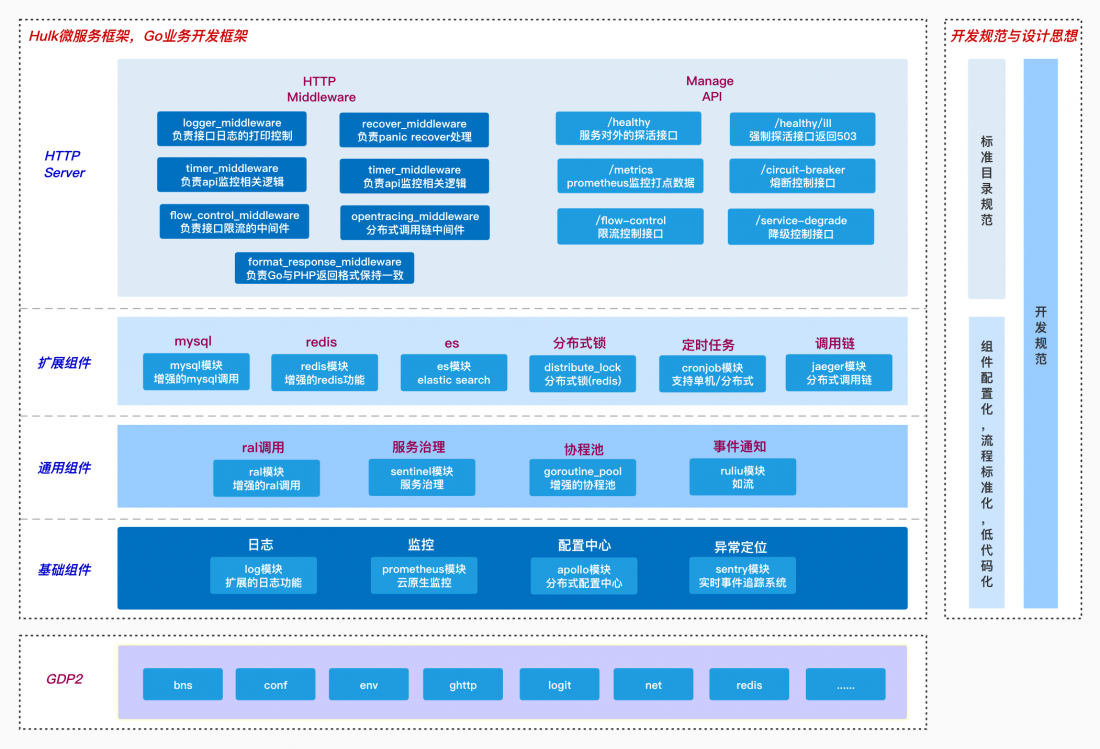
2.2.1 基础组件
提供了绝大部分项目都应该需要的基础能力,也是其他上层功能组件很可能依赖的组件。hulk框架通过这些基础组件,使上层应用可以无感的与基础设施进行集成:
- 日志组件:默认支持与PHP兼容的打印格式(用于配置sia监控和报警),同时也兼容ftrace接入的格式(日志查询和问题定位);
- 云原生监控:默认支持prometheus,对所有接口请求、redis、ral等远程调用进行多维度的metrics采集,并通过grafana展示;
- 配置中心:通过配置中心,可以实时下发并生效配置。目前支持Apollo/iConf,支持功能包括-版本管理、热发布、灰度发布、权限管理、审核与审计等;
- 事件追踪/定位:借助sentry,对于一些故障,我们可以秒级感知。hulk在异常信息中保存了比较完整的现场信息-如调用栈、request、集群和实例信息等,通过这些信息,可以直接定位问题的原因;
2.2.2 通用组件
这一层的组件能力是通用的,提供了一些管理控制和切面能力:
- ral组件:hulk的ral模块封装了GDP2的ral主体功能,同时,对ral进行了增强- a) 提供了通过字符串而非文件来进行ral初始化和ral懒加载功能;b) 提供了多个hook能力,如prometheus的监控信息采集,熔断、降级等;
- 服务治理:框架的服务治理能力是基于Sentinel (阿里开源的高可用流量防护组件)和配置中心来构建的,主要以流量为切入点,从限流、流量整形、熔断、降级等多个维度来协助保障微服务的稳定性,并提供动态控制能力;
- 协程池:a) 可以自动调度海量协程,复用goroutines,减少gc,b) 可以优雅处理 panic,防止程序崩溃 c) 提供了:任务提交、获取运行中的 goroutine 数量、封装了WaitGroup支持协程任务编排等功能;
- 事件通知:框架与如流做了集成。用户将robot token配置在项目里,就可以直接使用ruliu组件向指定的如流群发送报警/通告。如流组件结合sentry,可以让我们第一时间知道程序出了问题并快速定位到问题;
2.2.3 扩展组件
前两层功能对直接的业务处理逻辑参与较少,这一层的组件其能力多是为了处理某一类特定业务逻辑和场景,如redis/mysql/定时任务等:
- redis组件:基于GDP2 redis模块的封装并作了功能增,提供了:
- a) metrics hook,对所有的redis请求进行监控(prometheus)打点(latency/p99/qps/错误码分布等)
- b) sentry hook,支持将redis错误在记错误日志同时发送到sentry
- c) 降级hook,支持按集群/实例/百分比维度降级redis访问
- d) 熔断hook,支持按集群/实例/错误率/慢请求率对依赖的服务进行熔断设置
- mysql组件:mysql组件是基于GDP2 mysql和 gorm_adapter的封装,在已有能力之上,进行了以下功能扩展:
- a) 提供了metrics hook,对所有的mysql请求进行监控(prometheus)打点(latency/p99/qps/错误码分布等)
- b) 提供了sentry hook,支持将mysql错误在记错误日志的同时发送到sentry;
- 分布式锁:hulk提供了基于redis的分布式锁实现。其中redis连接是基于GDP2的redis模块的改造,分布式锁功能是封装了开源项目redsync;
- 定时任务:支持两种定时任务模式
- a) 带分布式锁的运行方式:对于多实例部署的定时任务,如果任务不是幂等的,则需要使用分布式锁对任务的调度运行进行控制;
- b) 不带分布式锁的运行方式:此模式下,如果部署了多实例,则所有实例上同一时刻的定时任务,会同时执行;
2.2.4 http server
hulk(目前只提供了http server能力)提供了很多通用且高效的http middleware,并对外暴露了一些管理控制接口,在一些特殊情况下,可以通过这些管理接口,在运行时干预服务的运行:
- logger_middleware:用于记录http的请求、响应、耗时等信息,同时支持实时修改日志打印策略-如按idc/ip/百分比/uid/cuid等维度打印;
- timer_middleware:用于http请求的监控埋点,可以输出可用性、tp99、流量、平响、错误码等metrics,维度包括服务级/idc/instance等;
- recover_middleware:用于捕获http 请求链路中的painc事件,并可自定义panic handler逻辑,如通过结合sentry和如流,可以实时感知并定位panic事件;
- flow_control_middleware:接口限流组件,可以通过配置中心或管理接口,对接口按idc/instance维度进行限流;
- timeout_middleware:通过该middleware或与配置中心结合使用,可以对接口按idc维度进行超时控制;
- 其他middleware可以查看hulk文档(如-internal_user_middleware、jager_opentracing_middleware、thirdparty_auth_middleware、b2logger_middleware等)
- 管理控制接口:如健康检查接口,服务治理-熔断、限流、降级接口,metrics接口,线上实例性能调试接口等;
2.3 框架生态
通过近一年的建设,我们初步构建了一个以hulk框架为中心的、符合好看业务场景的go生态体系,包括:
- 标准目录规范:避免各个项目结构不统一,减少项目维护难度和工作量;
- 代码生成器:基于hulk框架、标准目录规范、组件使用规范的代码生成器,目的是减少通用模块/组件使用不规范,解决通用流程编码、处理不一致的问题;
- hklib:好看的通用lib库,提供了一些的通用功能(也包含了很多PHP转go过程中的一些orp通用/基础的函数/功能),也提供了50+对中台服务的调用client,减少重复代码,提升研发效率,提升可维护性;
- 基础设施:prometheus+thanos集群、sentry服务、apollo集群、pyroscope性能分析平台等;
- iconf:好看自研配置中心,能力在对齐开源的Apollo之外,还增加/增强了一些功能,如-key维度的发布、更安全的配置获取、更简洁的操作页面、类分级发布等;
- artemis:服务可视化与故障智能定位系统,可以在该系统中看到服务的部署架构、服务内部调用链、多维度细粒度的近实时监控和关键日志。在发生可用性故障时,一些故障问题可以秒级的定位到原因和具体代码;
2.4 框架应用情况
目前短视频所有go服务都是基于hulk构建的,在资源、接口性能和可用性等方面都有一些阶段性产出和收益。
| 服务模块总数 | 40+ | 涵盖好看视频、度小视、度咔、短视频B端等多个服务端 |
|---|---|---|
| 服务实例总数 | 1200+ | 单模块最大实例数 200+ |
| 服务总QPS | 60K+ | 单模块最大QPS 21K+ |
| 资源 |
| 1. 由于Go高并发的特性,能更好的利用多核; 2. Go本身不吃内存,协程栈也很小; | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 接口性能 | 部分接口go化前后对比:
| 1. 从目前已go化的近40+个接口来看,接口性能好于PHP的比例是~ 90%; 2. 耗时高于PHP的一些接口是有预期可以优于或与PHP持平(可能是编码逻辑不一致、下游依赖变更、打点、日志或其他非业务功能引起); |
资源和性能收益,很大一部分要归属于PHP->Go的技术栈切换;而框架为服务应用相应技术栈特性提供了便捷和高效的方式。
2.4 hulk服务架构
下图描述了一个微服务(基于hulk)的架构全景图:
- 框架中个各功能组件都是围绕业务各个场景和需求的,在业务逻辑中能够比较便捷的使用相关功能组件;
- 这些组件在启用后,也会与相应的基础设施进行交互融合,共同支撑服务的高效、可控和稳定的运行;
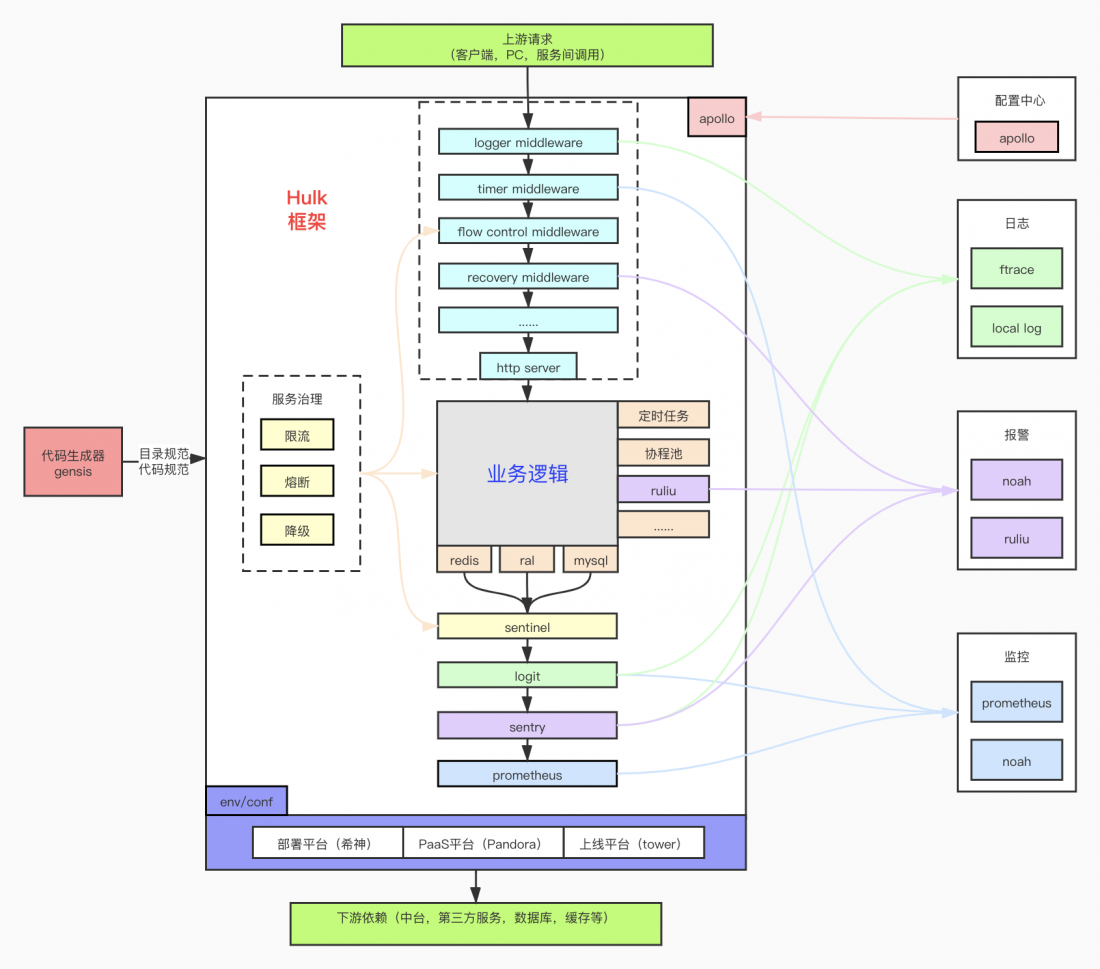
hulk组件初始化及与周边基础设施的集成,基本都可以通过环境变量/配置文件来完成。
3. 框架能力与应用
下面我们从日常开发遇到的一些痛点,来介绍框架的能力,并配以示例来说明这些能力是如何减少或解决痛点的。
3.1 如何提升代码质量?
代码质量会直接或间接的产生以下影响:
- 代码质量会直接影响代码维护成本;
- 代码质量会影响程序出bug的概率;
- 代码质量会影响程序运行效率;
hulk框架从一下三方面分别来提升代码质量。
3.1.1 规范代码组织结构
降低项目维护成本,提升研发效率。
- 通过标准目录规范,定义通用(http服务)的项目layout,避免出现每人一种或多种layout,最终项目结构“百花齐放”的现象;
- 通过代码生成器,帮助开发者生成项目模板,对初始化流程,各目录/文件的使用进行潜在约定;
3.1.2 编码规范和静态检查
提升代码可读性,减少低级代码bug
- 遵循百度Go编码规范+业务编码补充规范;
- 使用GDP的代码检查工具:go_fmt、goc;
3.1.3 配套的压测和性能分析平台
确定服务的压力边界,发现潜在的性能问题。
- 压测和性能测试平台(测试环境):nGrinder
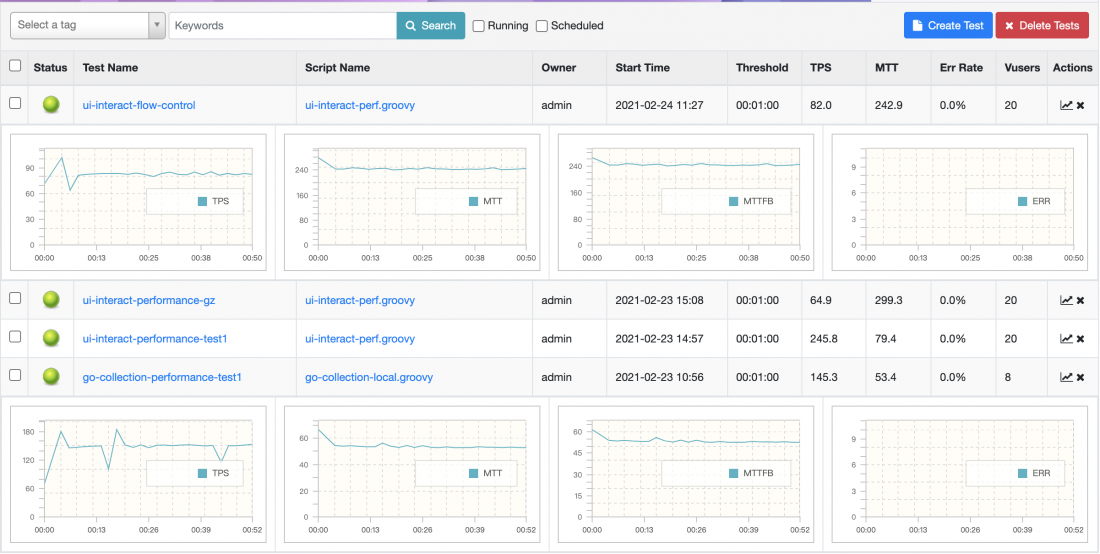
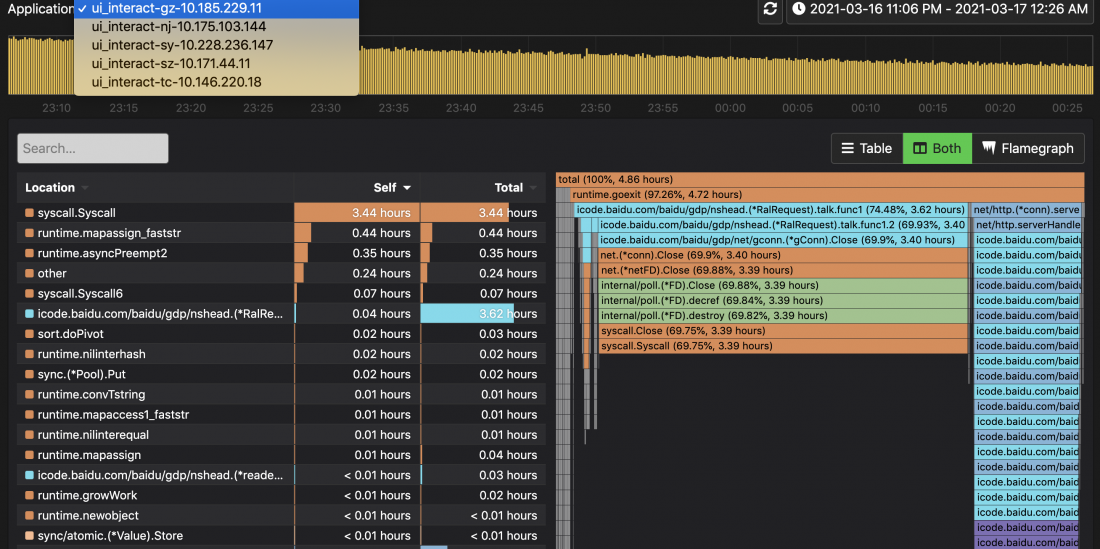
- 程序性能分析平台:pyroscope。可以通过hulk自集成的管理接口,实时打开或关闭线上实例的“continuous-prof”功能,定位线上性能问题:
3.2 如何提升开发迭代速度?
- 如何让开发者专注于业务逻辑与实现?
- 如何让开发者快速响应并完成产品需求?
hulk框架为提升迭代速度,提供了以下支持。
3.2.1 丰富的实用组件/功能
提升研发效率,避免试错,减少出错。
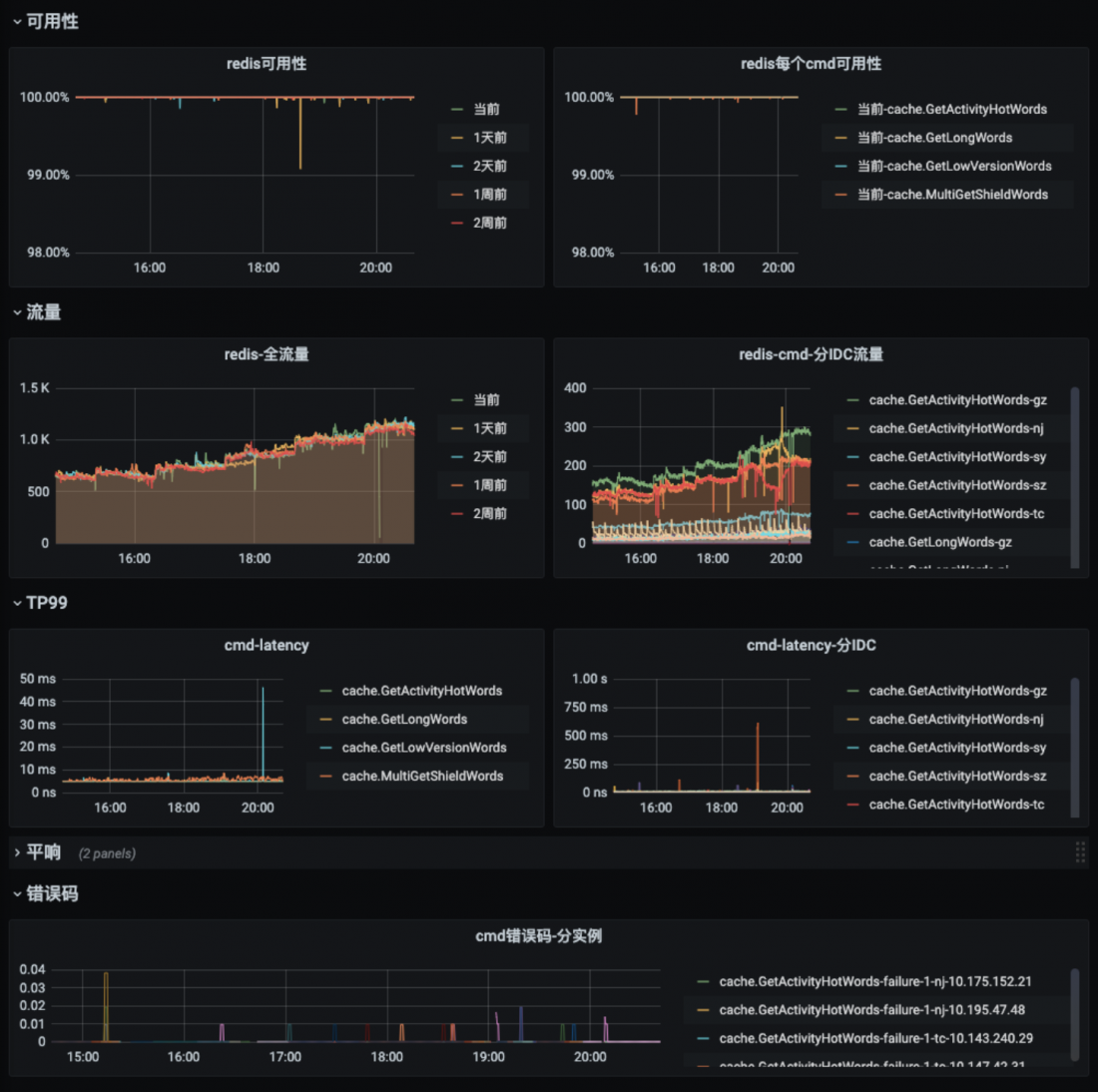
- 程序增强组件:增强的redis/mysql功能,增强的ral调用等。例-下图中的redis监控,其监控指标是由hulk redis组件自动采集计算的:
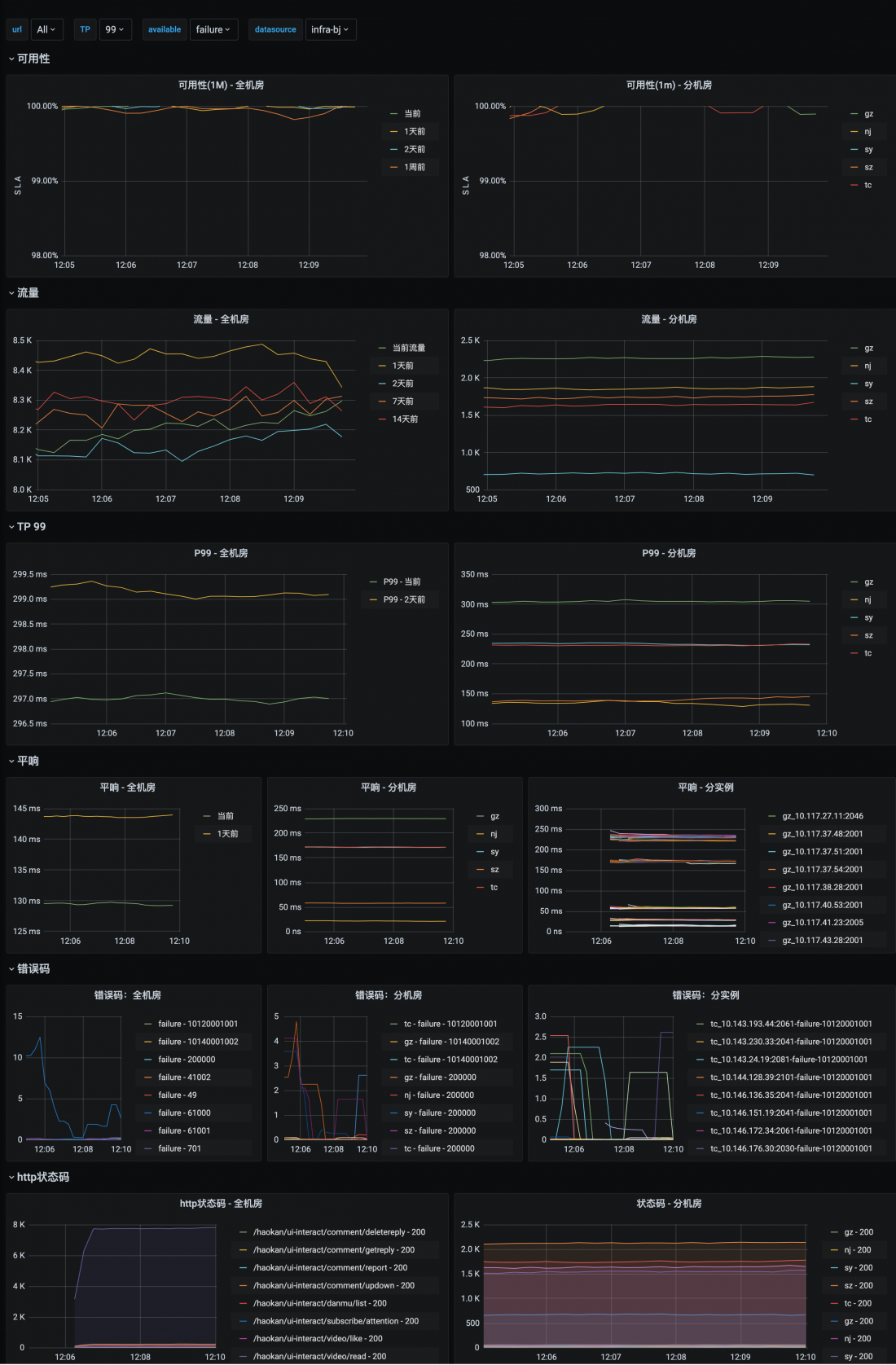
- 优秀的开源组件:sentry、prometheus+grafana、apollo、协程池等。例-prometheus+grafana:hulk框架默认支持prometheus,可以对服务的可用性、QPS、耗时、错误码等metrics自动计算收集:
- 丰富的http middleware
3.2.2 配置化、低代码支持
减少代码的修改和上线,提升需求的响应和完成速度。
- hulk框架中大部分组件可以通过环境变量/配置文件来初始化;
- 业务逻辑中的可变数据与配置,可以通过apollo/iconf实时下发和生效,无需代码修改和长流程上线。例-可以通过开箱即用的配置中心功能,实时下发并生效配置:
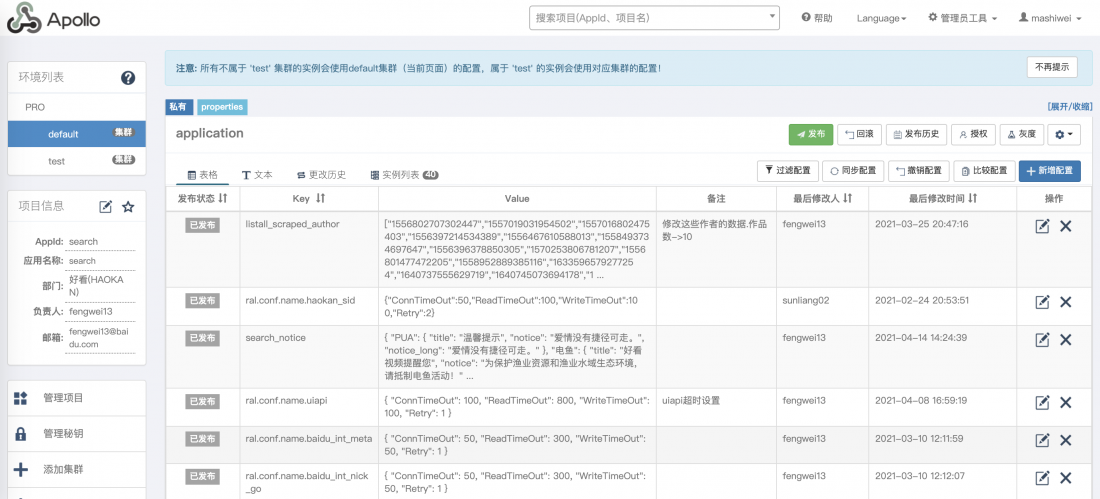
3.3 如何快速感知并定位问题?
- 开发者如何快速感知服务中的问题,严重问题如何实时感知?
- 开发者如何能从监控、日志、报警中获得详细的问题信息,以快速定位问题?
hulk为提升SRE效率,从以下几个方面提供支持。
3.3.1 完善的事件追踪定位与通告能力
能够实时追踪开发者自定义的错误并通告
- 实时事件追踪组件:sentry。hulk提供了开箱即用的sentry组件功能,可以像打印日志一样使用,sentry中的信息包含代码调用栈、上下文、自定义关键信息等:
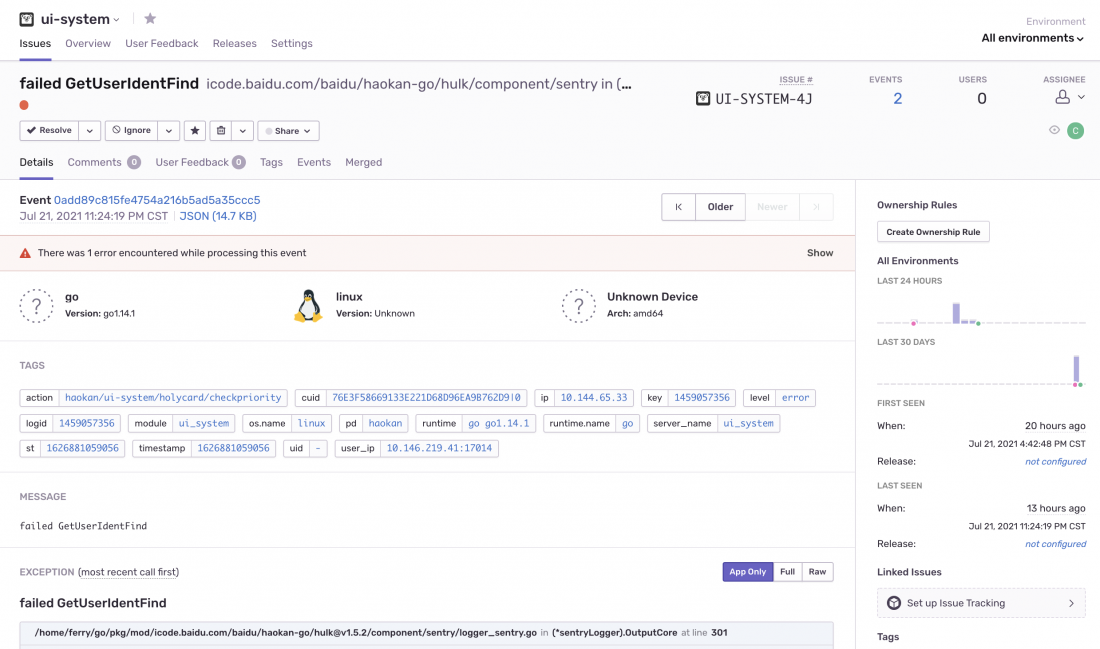
- 通告组件:ruliu。一行token配置就可以开启如流功能,可以将一些需要立即关注的信息实时打到如流群里,同时还可以和sentry结合,实现异常问题实时感知和定位:
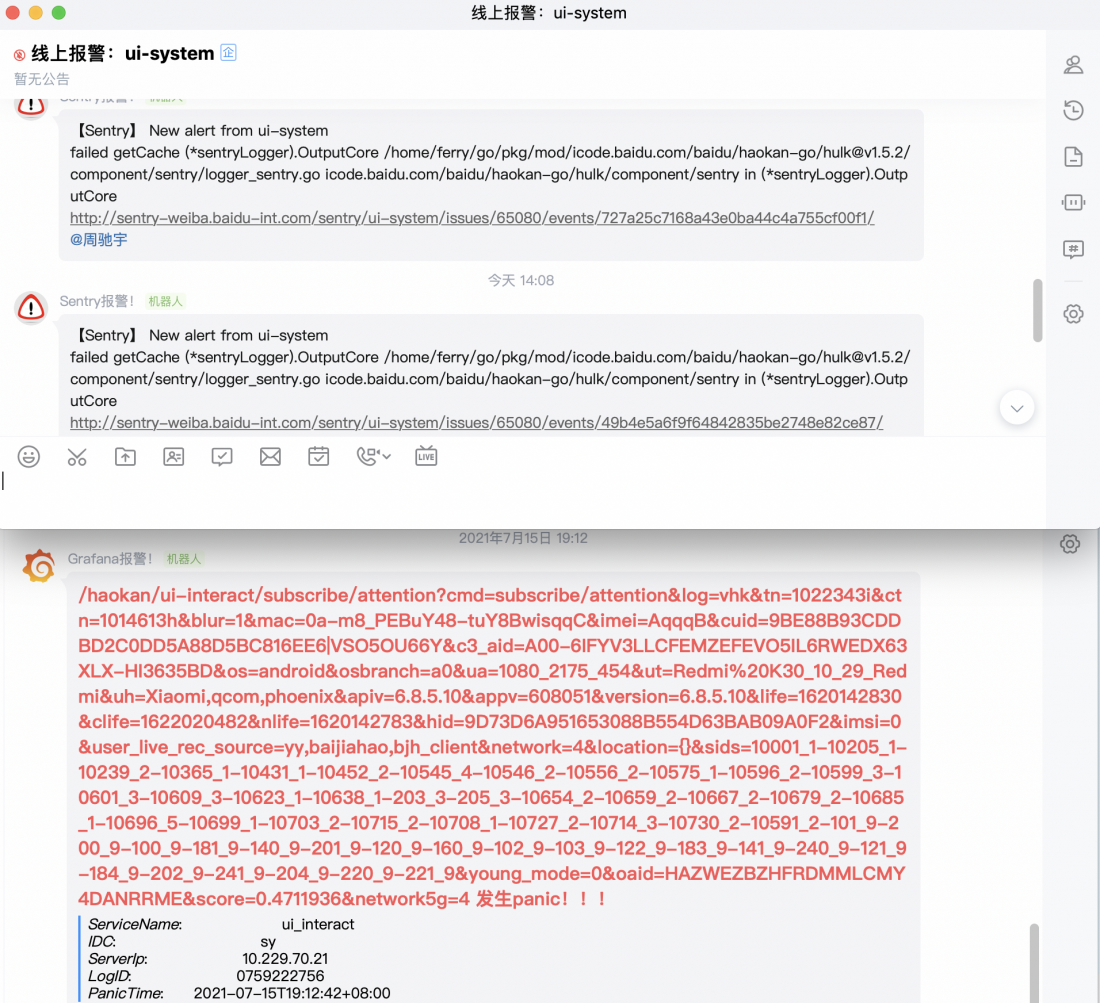
3.3.2 prometheus+sia监控支持
通过prometheus与noah的互补,支持多维度全方位监控,能够获得更多的服务稳定性相关信息
- prometheus为开发者提供灵活的多维度的业务监控信息;
- sia可以为开发者提供基于日志的采集的服务稳定指标和容器、网络等资源维度监控信息;
3.3.3 ftrace日志查询与分析功能
hulk默认支持ftrace平台的日志格式
- 通过ftrace,可以便捷高效的查询用户维度的日志信息;
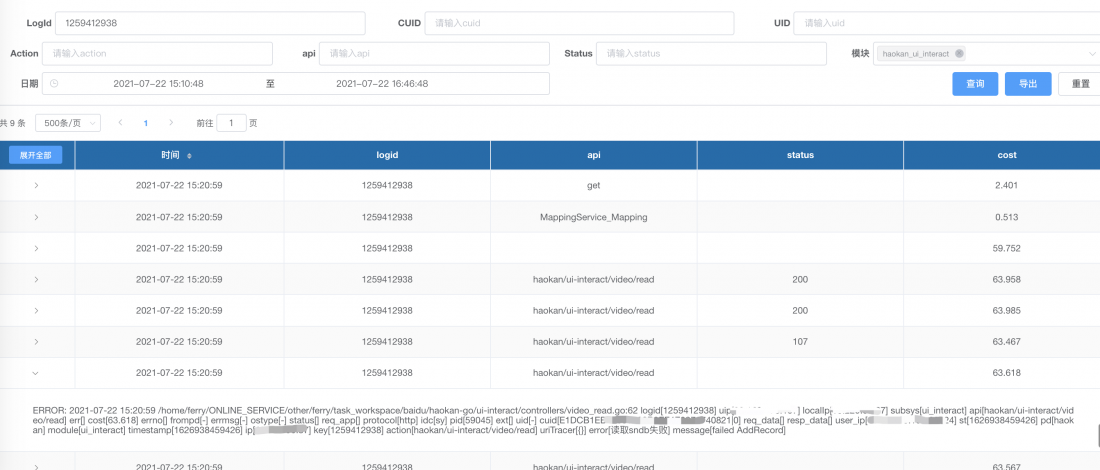
- 通过pdo2命令,可以检索查询自定义规则的日志信息;
3.4 基于hulk的服务可视化和故障智能定位系统
artemis是我们基于hulk研发的一款服务可视化与故障智能定位追踪系统,它集服务部署架构可视化、近实时多维度监控、关键日志、服务调用链等多方面信息,可以快速、高效、精准的发现和定位稳定性问题。
该系统目前已接入好看/全民/度咔等多个后端服务,极大加速了故障定位效率。在一些故障场景,可以秒级定位问题,给出问题的代码行。
3.4.1 服务部署架构
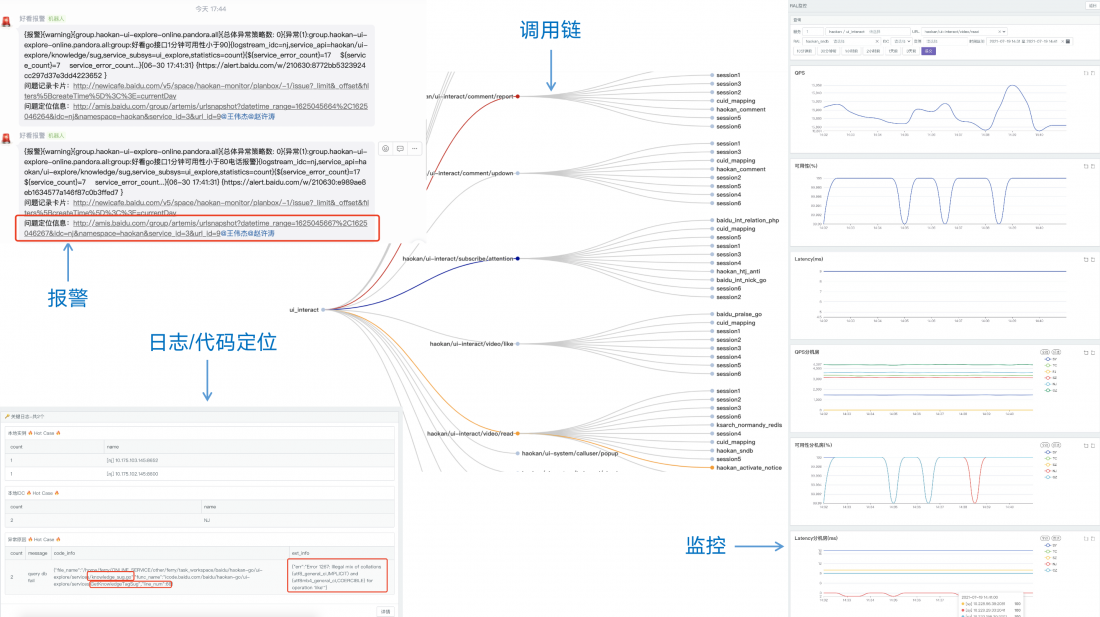
通过实例列表,可以获取服务的idc列表、instance列表和详情,并提供了便捷高效的调试入口和登录指令:

3.4.2 近实时多维度监控
artemis提供的近实时监控,能够提供更多维度信息,这些维度是sia和prometheus无法提供的,如:
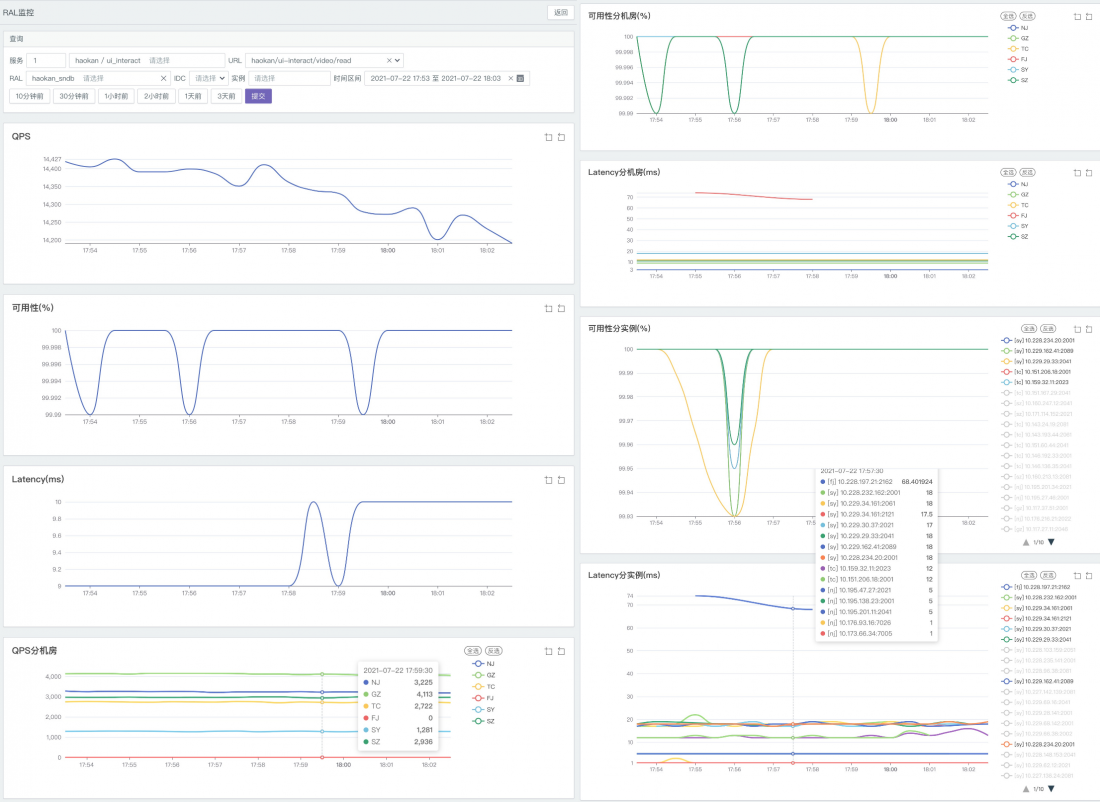
- 某个URI下面的某个下游(或下游实例)RAL的QPS、耗时、可用性;
- 某个服务实例实例的URI或RAL的监控信息;
3.4.3 关键日志
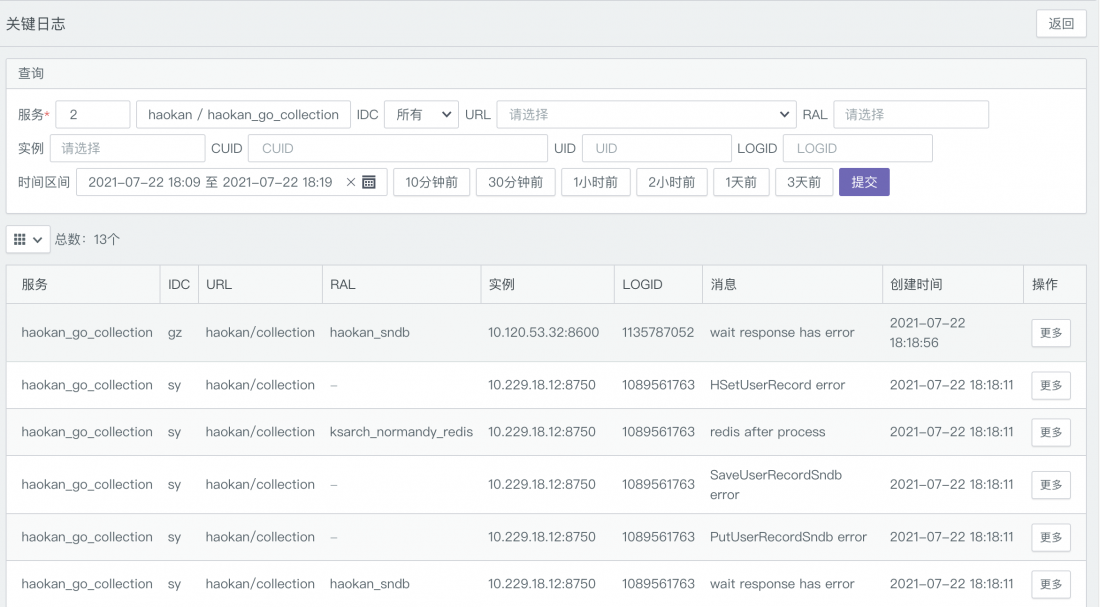
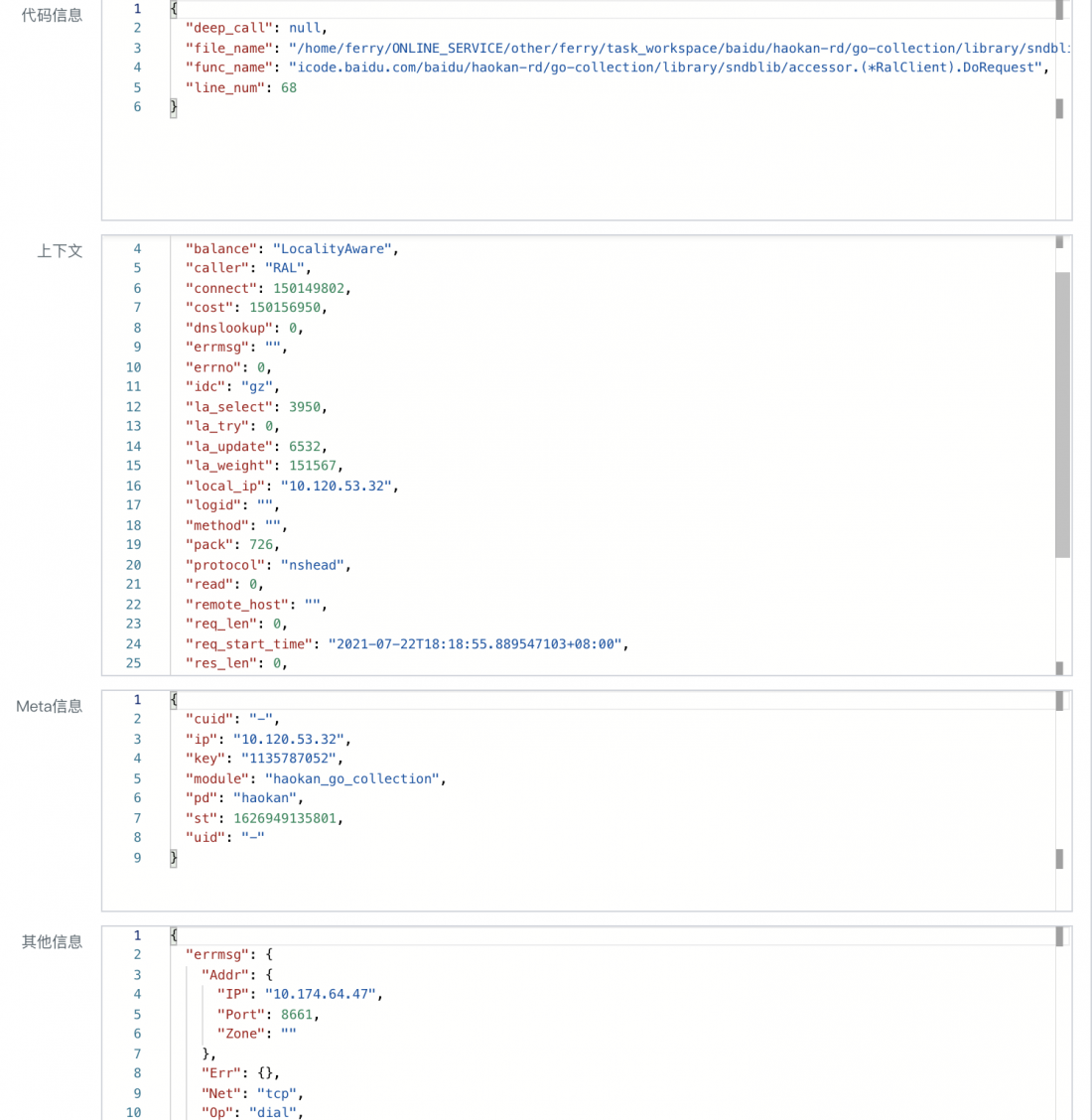
由于与hulk的深度集成,在业务代码中打印warning级别以上的日志时,artemis能拿到更多的日志信息,如-各维度信息、调用栈、上下文等:
3.4.4 服务调用链
在hulk框架的协助下,artemis还可以获取到URI及URI所依赖的RAL调用信息,由此可以构建出请求调用链,并实时展示调用链上的相关metrics信息:
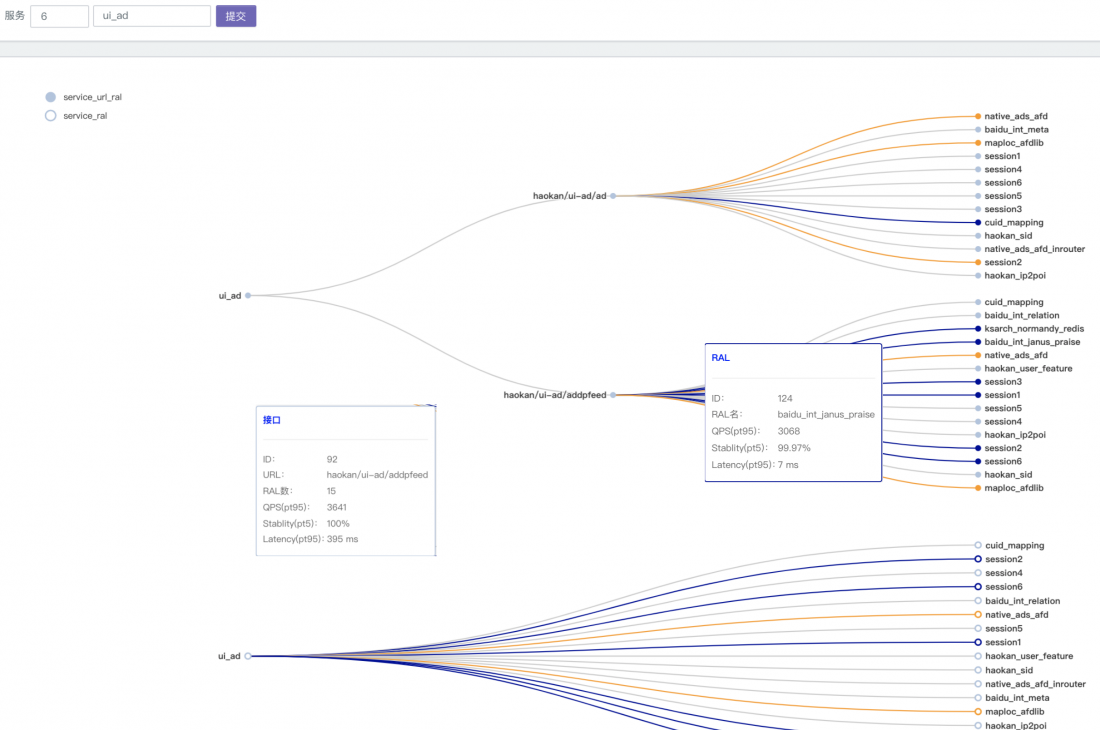
不同颜色的链路代表不同的可用性:红色-1个9及以下,黄色-2个9,蓝色-3个9,灰色-4个9。通过服务调用链,可以非常直观的看到服务里,哪个接口有问题,还可以看到哪些下游影响了这个接口的可用性。
3.4.5 使用案例
通过与报警系统的联动,可以在发生报警的第一时间,在artemis系统中找到受影响的服务及URI,确定是否是下游引起,错误是什么,哪一行代码报了错等,以下是一个artemis的实际应用示例。
4. 总结
hulk虽然是⼀个新的go语⾔web框架,但不是重复造轮,⽽是站在⼚内和开源软件的基础上,结合业务实际开发、部 署、运⾏、运维环境,对这些开源框架和⼯具进⾏取⻓补短、⼆次开发,最终切合实际的业务使⽤场景。同时,围绕hulk初步构建起的go生态,为服务在开发、部署、运行、运维等各个阶段都提供了有力支持。
最后,希望短视频研发部在go服务化架构升级/研发框架上的⼀些实践、⽅案和经验,能够给有相同架构升级需求、 在go项⽬实践中遇到问题的其他业务线同学⼀些帮助和参考。
5. 附录
1. 如果您有任何想交流的问题或意⻅,欢迎随时联系我们(接⼝⼈:mashiwei),如流群:4457629
2. 框架及使⽤⽂档:http://hulk-go.baidu-int.com/
3. hulk底层是基于GDP2的,了解gdp也更有助于了解hulk:http://gdp.baidu-int.com/
4. 团队介绍:⽬前2⼈专职/⾼优投⼊,5⼈按需投⼊
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









