






BigInteger
Java提供了合适的类去解决这个溢出问题:java.math.BigInteger。一个BigInteger对象可以容纳任意大小的有符号整数,这个类定义了所有的基本数学运算(除了一些不那么常见的运算)。Listing 1-6给出了计算Fibonacci序列的BigInteger版本的computeIterativelyFaster。
TIP:除了BigInteger,java.math包同样定义了BigDecimal,java.lang.Math提供了数学常量和操作。如果你的应用不需要双精度,为了性能可以使用安卓的FloatMath代替Math(不同平台的性能改进幅度可能不同)。
Listing 1-6 Fibonacci的computeIterativelyFaster的BigInteger实现
public class Fibonacci {
public static BigInteger computeIterativelyFasterUsingBigInteger(int n) {
if (n>1) {
BigInteger a, b = BigInteger.ONE;
n--;
a = BigInteger.valueOf(n & 1);
n /= 2;
while (n-- > 0) {
a = a.add(b);
b = b.add(a);
}
return b;
}
return (n == 0) ? BigInteger.ZERO : BigInteger.ONE;
}
}这个实现保证了结果的正确因为不会出现溢出。然而,它并不是没有问题的,因为它非常慢:computeIterativelyFasterUsingBigInteger(50000)需要大约1.3秒。这样糟糕的性能可以从三个方面解释:
(1) BigInteger是不可变的
(2) BigInteger通过BigInt和native代码实现
(3) 数值越大,把他们加到一块所花费的时间越长
既然BigInteger是不可变的,我们需要去写a = a.add(b)而不是简单的a.add(b)。许多人可能会假设a.add(b)相当于a += b,这个想法是错误的,它实际上等同于a+b。因此我们需要写成 a = a.add(b)进行赋值。一个细节是极其明显的,a.add(b)创建了一个新的BigInteger对象去容纳相加的结果。
因为BigInteger当前的内部实现,每个分配的BigInteger对象都会创建一个额外的BigInt对象。这个结果会导致在computeIterativelyFasterUsingBigInteger执行过程中,会产生两倍的对象:调用computeIterativeFasterUsingBigInteger(50000)大约创建了100000个对象(所有这些对象,除了一个,会被立即GC清理掉)。另外,BigInt通过native代码实现,而Java调用native代码(通过JNI)会有一定的开销。
第三个原因是非常大的数不能通过单个64位表示,比如,第50000个Fibonacci序列值需要34, 7111位表示。
NOTE:BigInteger的内部实现(BigInteger.java)可能会在将来的Android版本中改变。实际上,任何类的内部实现都有可能改变。
因为性能原因,应尽可能避免在代码中的关键路径分配内存。不幸的是,有些情况内存分配是必须的,比如当用到像BigInteger(String也是)不可变对象的时候。下一个优化聚焦于通过一个不同的算法减少分配的数量。基于Fibonacci Q-matrix,我们有:
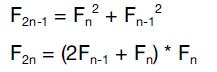
这同样可以使用BitInteger实现(保证结果的正确),如Listing 1-7所示。
Listing 1-7 Fibonacci序列的更快递归实现,使用BigInteger
public class Fibonacci {
public static BigInteger computeRecursivelyFasterUsingBigInteger(int n) {
if (n>1) {
int m = (n/2) + (n&1); // 开始不明显
BigInteger fM = computeRecursivelyFasterUsingBigInteger(m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigInteger(m-1);
if((n&1) == 1) {
// F(m)^2 + F(m-1)^2
return fM.pow(2).add(fM_1.pow(2)); // 创建了3个BigInteger对象
} else {
// (2*F(m-1) + F(m)) * F(m)
return fM_1.shiftLeft(1).add(fM).multiply(fM); // 创建了3个BigInteger对象
}
}
return (n==0) ? BigInteger.ZERO : BigInteger.ONE; // 没有创建BigInteger对象
}
public static long computeRecursivelyFasterUsingBigIntegerAllocations(int n) {
long allocations = 0;
if (n>1) {
int m = (n/2) + (n&1);
allocations += computeRecursivelyFasterUsingBigIntegerAllocations(m);
allocations += computeRecursivelyFasterUsingBigIntegerAllocations(m-1);
// 3个额外的对象分配
allocations += 3;
}
return allocations; // 当调用computeRecursivelyFasterUsingBigInteger(n)的时候的
// BigInteger对象的大概数量
}
}computeRecursivelyFasterUsingBigInteger(50000)的调用需要大约1.6秒。这表示最新的实现比我们当前最快的迭代实现要慢的多。再次,对象分配的数量是罪魁祸首,大约200,000个对象被创建(几乎立即被标记为GC可清除的)。
NOTE:实际的分配数量少于computeRecursivelyFasterUsingBigIntegerAllocations将返回的数量。因为BigInteger的实现使用了预分配对象,比如BigInteger.ZERO, BigInteger.ONE或者BigInteger.TEN,有些操作可能不需要分配一个新的对象。为了知道确切分配了多少对象,你可能需要去看Android的BigInteger实现。
这个实现更慢一些,然而它是正确方向的一个步骤。需要注意到一个主要的事情是,尽管我们需要使用BigInteger去保证值的正确,但是不需要为所有的n使用BigInteger。既然我们知道原子类型long可以容纳n小于等于92的结果,我们可以简单的修改算法,使它混合BigInteger和基本类型实现。如Listing 1-8所示。
Listing 1-8 更快的Fibonacci序列的递归实现,使用BigInteger和基本类型
public class Fibonacci {
public static BigInteger computeRecursivelyFasterUsingBigIntegerAndPrimitive(int n) {
if(n>92) {
int m = (n/2) + (n&1);
BigInteger fM = computeRecursivelyFasterUsingBigIntegerAndPrimitive(m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigIntegerAndPrimitive(m-1);
if((n&1) == 1) {
return fM.pow(2).add(fM_1.pow(2));
} else {
return fM_1.shiftLeft(1).add(fM).multiply(fM); // shiftLeft(1)实现乘以2
}
}
return BigInteger.valueOf(computeIterativelyFaster(n));
}
private static long computeIterativelyFaster(int n) {
// 实现同Listing 1-5
}
}computeRecursivelyFasterUsingBigIntegerAndPrimitive(50000)的调用需要大约73毫秒,大约11000个对象被分配:算法中一个小的修改使运算速度快了大约20倍,对象分配减少到了20分之一。相当令人印象深刻!可以通过减少对象分配数量来进一步的提升性能,如Listing 1-9所示。当Fibonacci类被加载,预计算结果可以被快速产生,这些结果可以在后面被直接使用。
Listing 1-9 更快的Fibonacci序列的递归实现,使用BigInteger和预计算结果
public class Fibonacci {
static final int PRECOMPUTED_SIZE = 512;
static BigInteger PRECOMPUTED[] = new BigInteger[PRECOMPUTED_SIZE];
static {
PRECOMPUTED[0] = BigInteger.ZERO;
PRECOMPUTED[1] = BigInteger.ONE;
for(int i=2;i < PRECOMPUTED_SIZE; i++) {
PRECOMPUTED[i] = PRECOMPUTED[i-1].add(PRECOMPUTED[i-2]);
}
}
public static BigInteger computeRecursivelyFasterUsingBigIntegerAndTable(int n) {
if(n > PRECOMPUTED_SIZE - 1) {
int m = (n/2) + (n&1);
BigInteger fM = computeRecursivelyFasterUsingBigIntegerAndTable(m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigIntegerAndTable(m-1);
if((n&1) == 1) {
return fM.pow(2).add(fM_1.pow(2));
} else {
return fM_1.shiftLeft(1).add(fM).multiply(fM);
}
}
return PRECOMPUTED[n];
}
}这个实现的性能依赖于PRECOMPUTED_SIZE:越大越快。然而,内存使用可能成为一个问题,因为许多BigInteger对像将被创建,然后在Fibonacci类被加载到JVM一直存在内存中。我们可以把Listing 1-8和Listing 1-9的代码合并起来,即混合预计算的结果和基本类型计算。比如,0到92的序列值可以通过computeIterativelyFaster计算,93到127的序列值通过预计算结果,其他值通过递归实现。作为开发者,你有责任选择最好的实现,通常不总是最快的。你的选择基于不同的元素,包括:
(1) 应用程序的目标是在什么样的设备和安卓版本
(2) 你的资源(人力和时间)
你可能已经注意到了,优化倾向于使源代码更难阅读,理解和维护,有时候会到这样一个程度:几周或者数月后你可能已经不认识你自己的代码。基于这个原因,仔细的思考什么样的优化是你确实需要的,它们将从短期和长期影响你的应用开发。建议你在思考优化之前首先实现一个方案(保证保存了一个工程副本)。毕竟,你可能发现根本不需要优化,这将节省你很多的时间。同样的,确保在你的代码中在任何一个对普通开发者不太熟悉的地方包含注释。你的合作者将会感谢你,当你在回顾老的代码不顺利的时候可以给你帮助。我的一点注释在Listing 1-7是个证明。
NOTE:所有的实现忽略了n可能为负值的事实。这里是故意忽略这一点的,不过你的代码,至少在public的API里面,合适的地方应该抛出一个不合法参数异常。















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









