







“斐波那契数列”的发明者,是意大利数学家列昂纳多·斐波那契(Leonardo Fibonacci,生于公元1170年,籍贯大概是比萨,卒于1240年后)。他还被人称作“比萨的列昂纳多”。1202年,他撰写了《珠算原理》(Liber Abaci)一书。他是第一个研究了印度和阿拉伯数学理论的欧洲人。他的父亲被比萨的一家商业团体聘任为外交领事,派驻地点相当于今日的阿尔及利亚地区,列昂纳多因此得以在一个阿拉伯老师的指导下研究数学。他还曾在埃及、叙利亚、希腊、西西里和普罗旺斯研究数学。
菲波那契数列指的是这样一个数列:
1,1,2,3,5,8,13,21……
这个数列从第三项开始,每一项都等于前两项之和。
它的通项公式为:[(1+√5)/2]^n /√5 - [(1-√5)/2]^n /√5 【√5表示根号5】。
很有趣的是:这样一个完全是自然数的数列,通项公式居然是用无理数来表达的。
根据斐波那契数列的数学描述,这个问题很容易用递归来实现,python代码如下:
- def fibonacci2(n):
- if n == 1 or n == 2:
- return 1
- else:
- return fibonacci2(n-1) + fibonacci2(n-2)
- if __name__ == "__main__":
- import profile
- profile.run("fibonacci2(30)")
用递归来描述程序确实简单,但是效率真是不敢恭维啊,算到30,就等了半天了,结果如下(我的配置奔腾双核T23330,内存2G):
1664082 function calls (4 primitive calls) in 11.376 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 11.376 11.376 <string>:1(<module>)
1664079/1 11.376 0.000 11.376 11.376 fibonacci2.py:1(fibonacci2)
1 0.000 0.000 11.376 11.376 profile:0(fibonacci2(30))
0 0.000 0.000 profile:0(profiler)
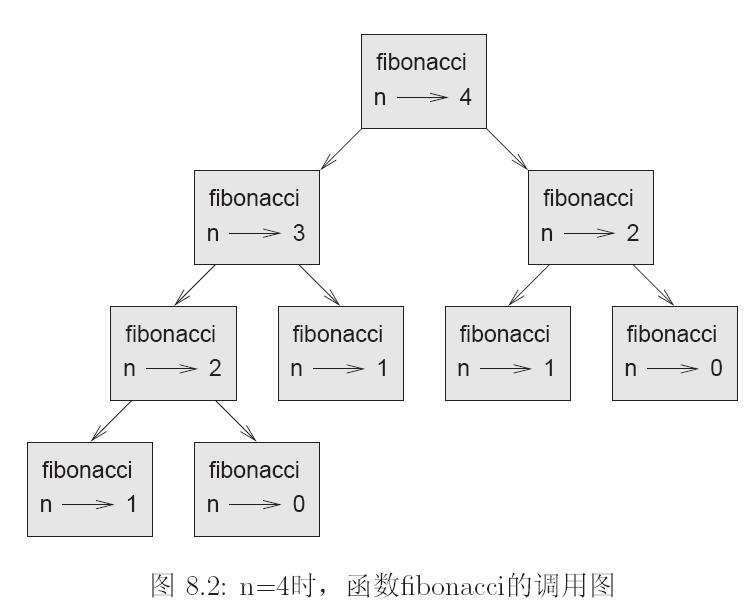
花费了11多的CPU时间,递归效率低下的根本原因是因为重复计算,看那张图就知道了,计算4的时候,1算了3次,2算了2次,这还是数很小的时候,随着N的增长,重复计算基本上是指数级别的增长,效率低下也就可想而知了,算50的时候,这个程序慢的几乎就没有用了。
怎样可以避免重复计算了,我们知道python里面有个字典类型(其他语言也可以模拟类似的数据结构来实现,譬如STL里面的MAP),我们可以把已经算出来的结果存在字典里面,下次算的时候,如果字典里面有了,直接返回就可以了,程序如下:
- previous = {1:1L, 2:1L}
- def fibonacci(n):
- if previous.has_key(n):
- return previous[n]
- else:
- newValue = fibonacci(n-1) + fibonacci(n-2)
- previous[n] = newValue
- return newValue
- if __name__ == "__main__":
- import profile
- print fibonacci1(3)
- profile.run("fibonacci1(30)")
输出结果:
113 function calls (61 primitive calls) in 0.002 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
55 0.000 0.000 0.000 0.000 :0(has_key)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
54/2 0.001 0.000 0.001 0.001 fibonacci1.py:4(fibonacci)
1 0.000 0.000 0.001 0.001 fibonacci1.py:4(fibonacci1)
1 0.000 0.000 0.002 0.002 profile:0(fibonacci1(30))
0 0.000 0.000 profile:0(profiler)
看到没,效率马上有了几个数量级的提升。
不过凡是递归程序都有个致命伤,那就是递归的深度达到一定数量,肯定会堆栈溢出,上面这个程序在计算n=986的时候,输出结果如下:
3937 function calls (1973 primitive calls) in 0.032 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1967 0.007 0.000 0.007 0.000 :0(has_key)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.031 0.031 <string>:1(<module>)
1966/2 0.025 0.000 0.031 0.016 fibonacci1.py:4(fibonacci)
1 0.000 0.000 0.031 0.031 fibonacci1.py:4(fibonacci1)
1 0.000 0.000 0.032 0.032 profile:0(fibonacci1(986))
0 0.000 0.000 profile:0(profiler)
还是很快的,但是在计算987的时候,程序就挂了:
主要错误:RuntimeError: maximum recursion depth exceeded in cmp
呵呵,堆栈溢出了,那我要算一个更大的斐波那契数列怎么办啊,别急,方法还是有的,那就是迭代,从理论上说,所有的递归都可以改写成迭代,只不过有些好改,有些不好改,最好改成迭代的就是尾部递归,尾部递归是指在程序的最后进行递归的,像上面的函数就是在最后调用了自己,改写成迭代的程序如下:
- def fibonacci3(n):
- if n == 1 or n == 2:
- return 1
- # 用迭代进行计算
- nPre = 1
- nLast = 1
- nResult = 0
- i = 2
- while i < n:
- nResult = nPre + nLast
- nPre = nLast
- nLast = nResult
- i += 1
- return nResult
- def funfi():
- fibonacci3(5000)
- if __name__ == "__main__":
- import profile
- profile.run("fibonacci3(30)")
用它计算30的时候输出如下:
4 function calls in 0.003 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.003 0.003 0.003 0.003 :0(setprofile)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 fibonacci3.py:3(fibonacci3)
1 0.000 0.000 0.003 0.003 profile:0(fibonacci3(30))
0 0.000 0.000 profile:0(profiler)
和第二个递归的时间差不多,计算986的输入如下:
4 function calls in 0.001 CPU seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1 0.001 0.001 0.001 0.001 fibonacci3.py:3(fibonacci3)
1 0.000 0.000 0.001 0.001 profile:0(fibonacci3(986))
0 0.000 0.000 profile:0(profiler)
效率拉开了第二个递归花的时间是迭代的32倍,如果数量更大,效率差距更明显,可惜没法进行对比了,因为更大的时候,递归程序溢出了,至于第一个暴力递归的就不用参加对比了,像这种教材程序也就适合讲讲递归的原理了。















 4755
4755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









