






一、Python 的特点和优点是什么?
Python 是一门动态解释性的强类型定义语言:编写时无需定义变量类型;运行时变量类型强制固定;无需编译,在解释器环境直接运行。
优点:
1、解释性: Python 语言写的程序,不需要编译成二进制代码,可以直接从源代码运行程序。
2、动态性:在运行时可以改变其结构的语言 。Python是一个动态语言,除此之外如 PHP 、 Ruby 、 JavaScript 等也都属于动态语言 。
3、面向对象:面向对象编程简单来说就是基于对 类 和 对象 的使用,所有的代码都是通过类和对象来实现的编程就是面向对象编程!面向对象的三大特性:封装、继承、多态
4、语法简洁:Python 是一种代表简单注意思想的语言,阅读一个良好的 Python 程序,即使是在 Python 语法要求非常严格的大环境下,给人的感觉也像是在读英语段落一样。
5、可扩展性:Python 的可扩展性体现为它的模块,Python 具有脚本语言中最丰富和强大的类库,这些类库覆盖了文件 I/O、GUI、网络编程、数据库访问、文本操作等绝大部分应用场景。
二、什么是 PEP8?
PEP是 Python Enhancement Proposal 的缩写,翻译过来就是 Python增强建议书
简单说就是一种编码规范,是为了让代码“更好看”,更容易被阅读。
三、Python解释器种类以及特点?
Python是一门解释器语言,须通过解释器执行,Python存在多种解释器,分别基于不同语言开发,每个解释器有不同的特点,但都能正常运行Python代码。
Python解释器主要有以下几个:
1、CPython:官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。CPython是使用最广泛。
2、IPython:IPython是基于CPython之上的一个交互式解释器
3、PyPy:PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译,所以可以显著提高Python代码的执行速度。
4、Jython:Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
5、IronPython:IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
四、Python面向对象三大特性?
1、封装隐藏对象的属性和实现细节,仅对外提供公共访问方式。在python中用双下划线开头的方式将属性设置成私有的 。好处:1. 将变化隔离;2. 便于使用;3. 提高复用性;4. 提高安全性。
2、继承继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类,新建的类称为派生类或子类。即一个派生类继承基类的字段和方法。
3、多态一种事物的多种体现形式,函数的重写其实就是多态的一种体现 。Python中,多态指的是父类的引用指向子类的对象 。
五、Python 中有几种数据类型?
Python 中主要有8种数据类型:
number(数字)、string(字符串)、list(列表)、tuple(元组)、dict(字典)、set(集合)、Boolean(布尔值)、None(空值)。
六、Python变量、函数、类的命名规则?
1、不能以数字开头,不能出现中文。
2、命名以字母开头,包含数字,字母(区分大小写),下划线。
3、不能包含关键字,见名知意。
七、Python可变与不可变数据类型的区别?
答:Python中看可变与不可变数据类型,主要是看变量所指向的内存地址处的值是否会改变 。 Python 的六种标准数据类型:数字、字符串、列表、元组、字典、集合。
不可变数据(3个):Number(数字)、String(字符串)、Tuple(元组)。
可变数据(3个):List(列表)、Dictionary(字典)、Set(集合)。
八、列举几个Python中的标准异常类?



九、Python中迭代器和生成器的区别?
Python中生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析,同时节省内存。除了创建和保持程序状态的自动生成,当发生器终结时,还会自动跑出StopIterration异常。
列表、元组、字典、字符串都是可迭代对象。
数字、布尔值都是不可迭代的。
十、Python字典以及基本操作
字典是 Python 提供的一种常用的数据结构,主要用于存放具有映射关系的数据 。
字典是一种可变的容器模型,它是通过一组键(key)值(value)对组成,这种结构类型通常也被称为映射,或者叫关联数组,也有叫哈希表的。每个key-value之间用“:”隔开,每组用“,”分割,整个字典用“{}”括起来 ,格式如下所示:
dictionary = {key1 : value1, key2 : value2 }
定义字典时,键前值后,键必须唯一性,值可以不唯一,如果键有相同,值则取最后一个;值可以是任何的数据类型,但是键必须是不可变的数据类型(数字、字符串、元组)。想要访问字典中的值,只需要将键放入方括号里,如果用字典里没有的键访问数据,会输出错误 。
十一、说说Python多线程与多进程的区别?
1、多线程可以共享全局变量,多进程不能
2、多线程中,所有子线程的进程号相同;多进程中,不同的子进程进程号不同
3、线程共享内存空间;进程的内存是独立的
4、同一个进程的线程之间可以直接交流;两个进程想通信,必须通过一个中间代理来实现
5、创建新线程很简单;创建新进程需要对其父进程进行一次克隆
6、一个线程可以控制和操作同一进程里的其他线程;但是进程只能操作子进程
两者最大的不同在于:在多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响;而多线程中,所有变量都由所有线程共享 。
十二、说说Python中HTTP常见响应状态码?
答:http协议是超文本传输协议,是用于从万维网服务器传输文本到本地浏览器的传送协议,是基于tcp/ip通信协议来传输数据的。
HTTP状态码(HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。它由 RFC 2616 规范定义的,并得到 RFC 2518、RFC 2817、RFC 2295、RFC 2774 与 RFC 4918 等规范扩展。所有状态码的第一个数字代表了响应的五种状态之一。
十三、Python中猴子补丁是什么?
在Ruby、Python等动态编程语言中,猴子补丁仅指在运行时动态改变类或模块,为的是将第三方代码打补丁在不按预期运行的bug或者feature上 。
在运行时动态修改模块、类或函数,通常是添加功能或修正缺陷。
猴子补丁在代码运行时内存中发挥作用,不会修改源码,因此只对当前运行的程序实例有效。
十四、Python中的垃圾回收机制?
垃圾回收机制(Garbage Collection:GC)基本是所有高级语言的标准配置之一了,在一定程度上,能优化编程语言的数据处理效率和提高编程软件开发软件的安全性能 。
在python中的垃圾回收机制主要是以引用计数为主要手段以标记清除和隔代回收机制为辅的手段 。可以对内存中无效数据的自动管理!
十五、Python中的6种位运算符?
在Python中,按位运算符有左移运算符(<<)、右移运算符(>>)、按位与运算(&)、按位或运算(|)、按位取反运算(~)、异或运算符,其中按位取反运算符为单目运算符 。
十六、Python中实现二分查找的2种方法?
答:在Python实现二分查找法有两种方法,分别用循环和递归方式。
二分查找法:搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。注意如果要想使用二分查找,前提必须是元素有序排列 。
循环方式
def binary_search_2(alist,item):
"""二分查找---循环版本"""
n = len(alist)
first = 0
last = n-1
while first <= last:
mid = (first + last)//2
if alist[mid] ==item:
return True
elif item < alist[mid]:
last = mid - 1
else:
first = mid + 1
return False
if __name__ == "__main__":
a = [1,5,6,10,11,13,18,37,99]
sorted_list_21 = binary_search_2(a, 18)
print(sorted_list_21) //True
sorted_list_22 = binary_search_2(a, 77)
print(sorted_list_22) //False
递归方式
def binary_search(alist,item):
"""二分查找---递归实现"""
n = len(alist)
if n > 0:
mid = n//2 #数组长度的一半中间下标
if item == alist[mid] :
return True #查找成功
elif item < alist[mid]:
return binary_search(alist[:mid],item)
else:
return binary_search(alist[mid+1:], item)
else :
return False #失败
if __name__ == "__main__":
a = [1,5,6,10,11,13,18,37,99]
# print(a)
sorted_list_11 = binary_search(a,37)
print(sorted_list_11)//True
sorted_list_12= binary_search(a, 88)
print(sorted_list_12)//False
十七、Python中的lambda表达式?
在Python中lambda表达式也叫匿名函数,即函数没有具体的名称。lambda表达式是Python中一类特殊的定义函数的形式,使用它可以定义一个匿名函数。与其它语言不同,Python的lambda表达式的函数体只能有单独的一条语句,也就是返回值表达式语句。
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用 。lambda所表示的匿名函数的内容应该是很简单的,如果复杂的话,就重新定义一个函数了。lambda 表达式允许在一行代码中创建一个函数并传递。
十八、Python中的反射?
在反射机制就是在运行时,动态的确定对象的类型,并可以通过字符串调用对象属性、方法、导入模块,是一种基于字符串的事件驱动。通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员。
Python是一门解释型语言,因此对于反射机制支持很好。在Python中支持反射机制的函数有getattr()、setattr()、delattr()、exec()、eval()、import,这些函数都可以执行字符串。
十九、Python删除list里的重复元素有几种方法?
使用set函数:set是定义集合的,无序,非重复
numList = [1,1,2,3,4,5,4]
print(list(set(numList)))
#[1, 2, 3, 4, 5]
先把list重新排序,然后从list的最后开始扫描
a = [1, 2, 4, 2, 4, 5,]
a.sort()
last = a[-1]
for i in range(len(a) - 2, -1, -1):
if last == a[i]:
del a[i]
else:
last = a[i]
print(a) #[1, 2, 4, 5]
使用字典函数
a=[1,2,4,2,4,]
b={}
b=b.fromkeys(a)
c=list(b.keys())
print(c) #[1, 2, 4]
append方式
def delList(L):
L1 = []
for i in L:
if i not in L1:
L1.append(i)
return L1
print(delList([1, 2, 2, 3, 3, 4, 5])) #[1, 2, 3, 4, 5]
count + remove方式
def delList(L):
for i in L:
if L.count(i) != 1:
for x in range((L.count(i) - 1)):
L.remove(i)
return L
print(delList([1, 2, 2, 3, 3, 4]))#[1, 2, 3, 4]
二十、Python中的__new__和__init__的区别?
1、__new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例对象,是个静态方法。
2、__init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候。是一个实例方法。
主要区别在于:__new__是用来创造一个类的实例的,而__init__是用来初始化一个实例的。
二十一、Python中的help()和dir()函数?
在Python中help()和dir()这两个函数都可以从Python解释器直接访问,并用于查看内置函数的合并转储。
1、help()函数:用于显示文档字符串,还可以查看与模块,关键字,属性等相关的使用信息。
2、dir()函数:可以列出指定类或模块包含的全部内容(包括函数、方法、类、变量等)
二十二、如何提高Python运行效率的技巧?
1、使用局部变量
2、使用较新的Python版本。
3、先编译后调用
4、采用生成器表达式替代列表解析
5、关键代码使用外部功能包
6、在排序时使用键
7、优化算法时间
8、循环优化
9、交叉编译你的应用:Nuitka交叉编译器,将Python代码转化成C++代码。
二十三、Python中的单例模式有几种实现方式?
1、用__new__特殊方法实现
class Singleton:
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
cls._instance = super(Singleton, cls).__new__(cls)
return cls._instance
def __init__(self, name):
self.name = name
s1 = Singleton('IT圈')
s2= Singleton('程序IT圈')
print(s1 == s2) # True
2、使用装饰器实现
def singleton(cls):
_instance = {}
def inner(*args, **kwargs):
if cls not in _instance:
_instance[cls] = cls(*args, **kwargs)
return _instance[cls]
return inner
@singleton
class Singleton:
def __init__(self, name):
self.name = name
s1 = Singleton('IT圈')
s2= Singleton('程序IT圈')
print(s1 == s2) # True
3、类装饰器实现
class Singleton:
def __init__(self, cls):
self._cls = cls
self._instance = {}
def __call__(self, *args):
if self._cls not in self._instance:
self._instance[self._cls] = self._cls(*args)
return self._instance[self._cls]
@Singleton
class Singleton:
def __init__(self, name):
self.name = name
s1 = Singleton('IT圈')
s2= Singleton('程序IT圈')
print(s1 == s2) # True
4、使用元类实现方式
class Singleton1(type):
def __init__(self, *args, **kwargs):
self.__instance = None
super(Singleton1, self).__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
if self.__instance is None:
self.__instance = super(Singleton1, self).__call__(*args, **kwargs)
return self.__instance
class Singleton(metaclass=Singleton1):
def __init__(self, name):
self.name = name
s1 = Singleton('IT圈')
s2= Singleton('程序IT圈')
print(s1 == s2) # True
二十四、Python实现自省的方法有哪些?
1、type(),判断对象类型
2、dir(), 带参数时获得该对象的所有属性和方法;不带参数时,返回当前范围内的变量、方法和定义的类型列表
3、help() , 用于查看函数或模块用途的详细说明
4、isinstance(),判断对象是否是已知类型
5、issubclass(),判断一个类是不是另一个类的子类
6、hasattr(),判断对象是否包含对应属性
7、getattr(),获取对象属性
8、setattr(), 设置对象属性
9、id(): 用于获取对象的内存地址
10、callable():判断对象是否可以被调用。
二十五、爬虫的基本步骤?
1、确定需求;
2、确定资源;
3、通过url获取网站的返回数据;
4、定位数据;
5、存储数据。
二十六、遇到的反爬虫策略以及解决方法?
1、通过headers反爬虫:自定义headers,添加网页中的headers数据。
2、基于用户行为的反爬虫(封IP):可以使用多个代理IP爬取或者将爬取的频率降低。
3、动态网页反爬虫(JS或者Ajax请求数据):动态网页可以使用 selenium + phantomjs 抓取。
4、对部分数据加密处理(数据乱码):找到加密方法进行逆向推理。
常见的反爬虫和应对方法有:
1、基于用户行为,同一个ip段时间多次访问同一页面 利用代理ip,构建ip池
2、请求头里的user-agent 构建user-agent池(操作系统、浏览器不同,模拟不同用户)
3、动态加载(抓到的数据和浏览器显示的不一样),js渲染 模拟ajax请求,返回json形式的数据
4、selenium / webdriver 模拟浏览器加载
5、对抓到的数据进行分析
6、加密参数字段 会话跟踪【cookie】 防盗链设置【Referer】
二七、Python 里面如何实现 tuple 和 list 的转换?
tuple(list) # tuple转list
list(tuple) # list 转tuple
二十八、魔法函数 __call__怎么使用?
class Bar:
def __call__(self, *args, **kwargs):
print('i am instance method')
b = Bar() # 实例化
b() # 实例对象b 可以作为函数调用 等同于b.__call__ 使用
# OUT: i am instance method
# 带参数的类装饰器
class Bar:
def __init__(self, p1):
self.p1 = p1
def __call__(self, func):
def wrapper():
print("Starting", func.__name__)
print("p1=", self.p1)
func()
print("Ending", func.__name__)
return wrapper
@Bar("foo bar")
def hello():
print("Hello")
二十九、Python 如何获取当前日期?
import datetime
print(datetime.datetime.now())
三十、函数装饰器的作用?
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
学习资源推荐
除了上述分享,如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
这里给大家展示一下我进的最近接单的截图
😝朋友们如果有需要的话,可以点击下方链接领取或者V扫描下方二维码联系领取,也可以内推兼职群哦~
🎁 CSDN大礼包,二维码失效时,点击这里领取👉:【学习资料合集&相关工具&PyCharm永久使用版获取方式】
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!

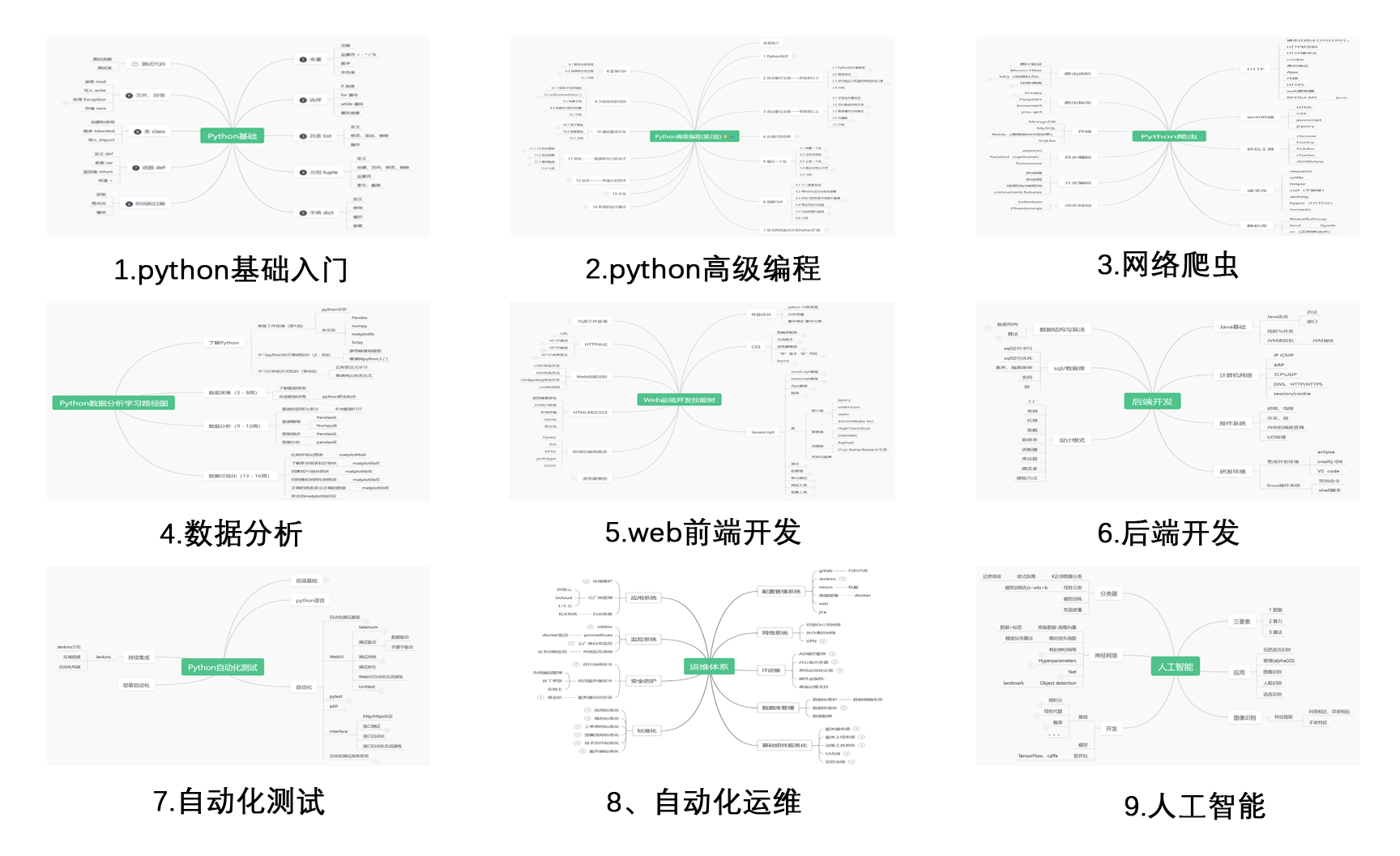
1.Python学习路线

2.Python基础学习
01.开发工具

02.学习笔记
03.学习视频
3.Python小白必备手册

4.数据分析全套资源

5.Python面试集锦
01.面试资料
02.简历模板
🎁 CSDN大礼包,二维码失效时,点击这里领取👉:【学习资料合集&相关工具&PyCharm永久使用版获取方式】















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









