







参考资料:活用pandas库
1、字符串格式化
(1)格式化字符串
要格式化字符串,需要编写一个带有特殊占位符的字符串,并在字符串上调用format方法向占位符插入值。
# 案例1
var='flesh wound'
s="It's just a {}"
print(s.format(var))
# 案例2,通过索引多次使用变量
s="""Black Knight: 'Tis but a {0}.
King Arthor: A {0}? Your arm's off!"""
print(s.format('scratch'))
# 案例3,也可以给占位符一个变量
s='Hayden Planetarium Coordinates:{lat},{lon}'
print(s.format(lat='40.7815°N',lon='73.9733°W')) 
(2)格式化数字
# 案例1
s='Some digits of pi:{}'
print(s.format(3.1415926))
# 案例2,使用千分位符
s='In 2005, Lu Chao of China recited {:,} digits of pi'
print(s.format(67890))
# 案例3
# {0:.4}和{0:.4%}中的0表示索引值,4表示保留多少小数位
# 如果添加上%,则会把小数格式化为百分数
s="I remember {0:.4} or {0:.4%} of What Lu Chao recited"
print(s.format(7/67890))
# 案例4
# 在{0:05d}中,第一个0为索引值
# 第二个0是要填充的字符
# 5表示总共有多少个字符
# d表示要使用数字
# 整体表示总共有5个字符,前面使用0进行填充
s="My ID number is {0:05d}"
print(s.format(42))
(3)C printf格式化风格
在python中,格式化字符串的另一种方法是使用运算符“%”。这遵循的是C printf格式化风格。
# d表示整数
s='I only know %d digits of pi'%7
print(s)
# s代表字符串
# 请注意,字符串模式使用圆括号代替了花括号
# 传入的是一个python字典,使用花括号
s='Some digits of %(cont)s: %(value).2f'%{"cont":'e','value':2.718}
print(s)![]()
(4)python3.6+中的格式化字符串
格式化字符串(f-strings)的语法,最明显的是字符串必须以字符f开头,这就告诉python此处有格式化字符换,然后,可以直接在占位符{}中使用变量而无须调用format方法。
使用f-strings的最主要的好处是:可读性更好,执行速度更快,性能也更高。
var='flesh wound'
s=f"It's just a {var}"
print(s)
lat='40.7815°N'
lon='73.9733°W'
s=f'Hayden Planetarium Coordinates:{lat},{lon}'
print(s)![]()
2、正则表达式
做模式搜索时,如果基本的python字符串方法不够用,可以使用正则表达式。正则表达式功能及其强大,它提供了一种重要的方法来查找和匹配字符串中的模式。其缺点是,复杂的正则表达式难以理解。基础语法如下:
. 匹配所有字符
^ 从字符串开头匹配
$ 从字符串末尾匹配
* 匹配前一个字符任意次
+ 匹配前一个字符一次或多次
? 匹配前一个字符零次或一次
{m} 匹配前一个字符m次
{m,n} 匹配前一个字符,最少匹配m次且最多匹配n次
\ 转义字符
[] 一组字符(比如[a-z],表示匹配从a到z之间的左右字符)
| 或。A|B表示匹配A或B
() 精确匹配括号中指定的模式
\d 匹配一个数字字符
\D 匹配一个非数字字符(与\d相反)
\s 匹配任何不可见字符
\S 匹配任何可见字符(与\s相反)
\w 匹配单词字符
\W 匹配任何非单词字符(与\w相反)
re模块中有很多函数可以用于处理各种需求,常见函数如下:
search 在字符串中进行搜索,成功则返回匹配目标,失败则返回None
match 从字符串开头进行匹配,成功则返回匹配目标,失败则返回None
fullmatch 匹配正则字符串
split 根据模式分割字符串
findall 查找字符串中所有非重叠匹配
finditer 类似于findall,但返回python迭代器
sub 用提供的字符串代替匹配模式
(1)匹配模式
# 导入库
import re
tele_num='1234567890'
m=re.match(pattern='\d{10}',string=tele_num)
print(type(m))
print(m)
print(bool(m))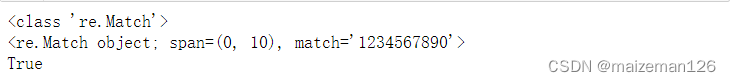
查看输出的match对象,如果存在匹配,span会给出匹配字符串的索引,match会给出精确匹配到的字符串。很多时候,当以某个模式匹配字符串时,只需要一个True或False值,用于指出是否存在匹配。
正则表达式常在if语句中用作条件,在这种情况下,无须进行bool类型转换。
# 正则表达式常在if语句中用作条件,在这种情况下,无须进行bool类型转换。
if m:
print('match')
else:
print('no match')
# 如果想获取匹配对象的某些值,可以使用match对象的一些方法
# 获取第一个匹配字符串的索引
print(m.start())
# 获取最后一个匹配字符的索引
print(m.end())
# 获取第一个和最后一个匹配字符的索引
print(m.span())
# 获取与指定模式相匹配的字符串
print(m.group())
假设新字符串有3个数字、1个空格、另外3个数字、另外一个空格、然后跟着4个数字。空格可以匹配0次或1次。代码如下:
# 可以把RegEx模型看作单独的变量
# 因为它有可能变得更长,让对实际匹配函数的调用难以阅读
tele_num_spaces='123 456 7890'
p='\d{3}\s?\d{3}\s?\d{4}'
m=re.match(pattern=p,string=tele_num_spaces)
print(m)
tele_num_space_paren_dash='(123) 456-7890'
p='\(?\d{3}\)?\s?\d{3}-?\d{4}'
m=re.match(pattern=p,string=tele_num_space_paren_dash)
print(m)(2)查找模式
可是使用findall函数来查找模式中的所有匹配项。
p='\d+'
# python连接两个班次靠近的字符串
s='13 Jodie Whittaker, war John Hurt, 12 Peter Capaldi,'\
'11 Matt Smith, 10 David Tennant, 9 Christopher Eccleston'
m=re.findall(pattern=p,string=s)
print(m)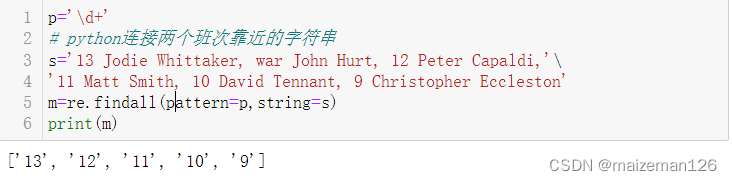
(3)模式替代
multi_str="""Guard: What? Ridden on a horse?
King Arthor: Yes!
Guard: You're using coconuts!
King Arthor: What?
Guard: You've got ... coconuts.
"""
p='\w+\s?\w+:\s?'
s=re.sub(pattern=p,string=multi_str,repl='')
print(s)
(4)编译模式
python的re模块支持对模式进行编译,以便复用它。这可以提升性能,特别是当数据集很大时,性能提升会更明显。语法和前面的几乎相同。首先编写好正则表达式模式,但这次不把它直接保存在变量中,而是把模式字符串传递到compile函数中并保存结果。然后就可以在这个编译好的模式上调用其他re函数了。而且,由于模式已经编译好了,无须再在方法中指定模式参数了。
p=re.compile('\d{10}')
s='1234567890'
m=p.match(s)
print(m)
p=re.compile('\d+')
s='13 Jodie Whittaker, war John Hurt, 12 Peter Capaldi,'\
'11 Matt Smith, 10 David Tennant, 9 Christopher Eccleston'
m=p.findall(s)
print(m)
(5)regex库
re库是python应用广泛的正则表达式库,是python内置和默认的正则表达式引擎。不过,正则表达式的重度用户可能会觉得regex库比re库更好,功能也更全面。regex库和re库是向互兼容的。感兴趣的同学可以自行测试。















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









