







前言
相信大家在平时工作中,或多或少遇到过些棘手的问题,如CPU负载过高、内存溢出、频繁Full GC等。对刚接触工作的同学来说的确是不知道从哪入手,所以这里我简单介绍一下上面三种问题该如何去定位以及解决,当然解决的方式是不一的,可以根据具体环境的问题灵活使用。
TOP 命令解析
Linux中top命令是排查问题最有效的利器,但是很多人对top认识不深刻,而且网上很多博客有些错误的阐述,所以这里先来讨论一下在top命令中需要注意的三个信息:load average、CPU使用占用比、CPU占用率高的线程。清楚的话可以跳过这一节。
load average
下面是top命令的结果:
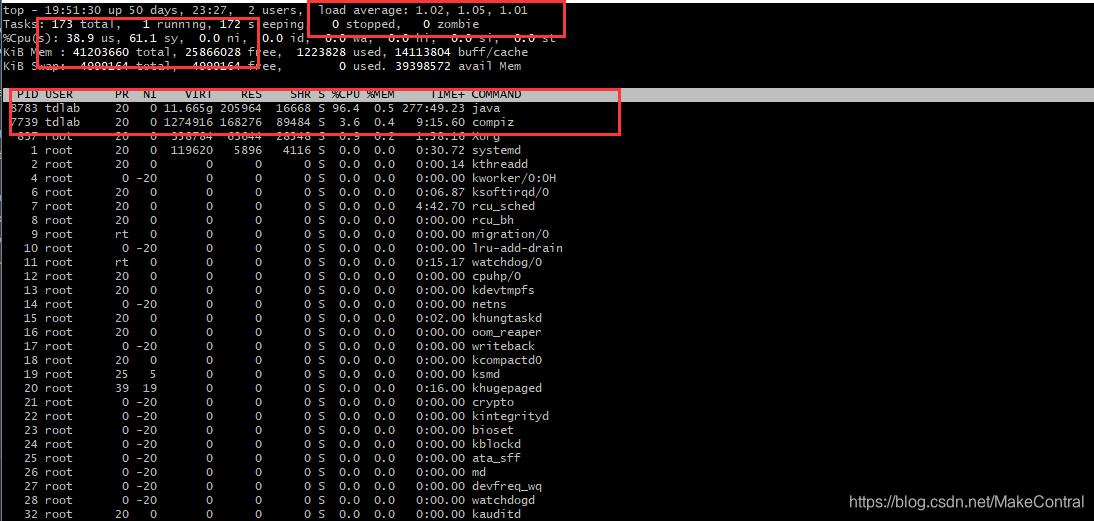
先来看load average。其中1.02 、1.05 、1.01分别为1分钟、5分钟、15分钟CPU负载的情况。在很多博客上看到说load average大于5的时候就是超负荷的情况了,但是load average值是否超标是要根据你CPU的核数来判断的。
一般来说,Load Average是与机器内核数有关的。以一个单核的机器为例,load=0.5表示CPU还有一半的资源可以处理其他的线程请求,load=1表示CPU所有的资源都在处理请求,没有剩余的资源可以利用了,而load=2则表示CPU已经超负荷运作,另外还有一倍的线程正在等待处理。所以,对于单核机器来说,理想状态下,Load Average要小于1。同理,对于双核处理器来说,Load Average要小于2。结论是:多核处理器中,你的Load Average不应该高于处理器核心的总数量。
简单来说,但你的CPU核数为单核时,load average为0-1是一个正常的情况,如果是1.5那说明要一半的工作在等待中。如果你的CPU核数为4核十,load average为0-4是一个正常的情况。
那么如何查看你当前CPU的核数呢?你可以在top命令情况下按下1,就可以看到。
CPU使用占用比
接着来看CPU的使用占用比情况。在上图 %CPU 那行可以看到一系列占用CPU的百分比情况,其中:
us #用户空间占用CPU百分比
sy #内核空间占用CPU百分比
ni #用户进程空间内改变过优先级的进程占用CPU百分比
id #空闲CPU百分比
wa #等待输入输出的CPU时间百分比
hi #硬中断
si #软中断
首先需要明白的就是 Cpu(s) 和下面进程占用CPU情况的区别。可能有人会觉得奇怪:为什么PID为8783的进程明明占用了96.4%的CPU情况,但是为什么 us 用户空间占用只有38.9%呢?us 和 进程占用CPU的百分比有什么联系呢?
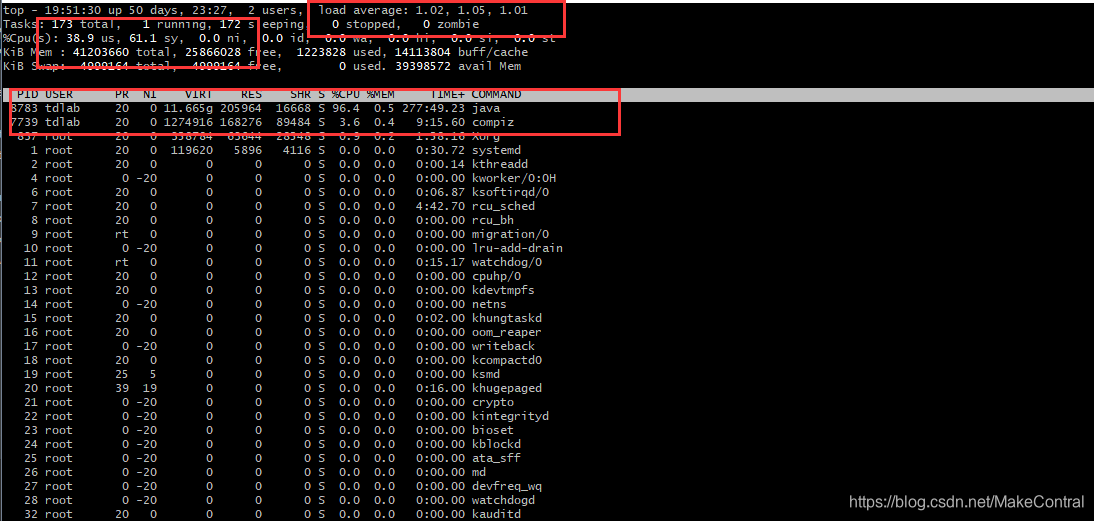
这是因为进程执行过程是分为内核态和用户态的。比如你在执行一个IO过程,因为IO必须要由内核程序亲自调用,那么调用IO的这段时间就是内核 sy 的时间了,其他时间则为用户 us 执行时间。所以虽然这个线程占用了CPU的96%的时间,但是实际上这个时间是分为了内核态和用户态的时间的。
CPU占用率高的线程
有些人看到一个进程占用100%的情况就觉得自己的节点要爆炸了,当然这么说是夸张了。但是如果你的CPU是多核的,那么就算你的某个进程占用了100%的情况也是没关系的,因为Cpu(s) 显示的所有核数的平均情况。
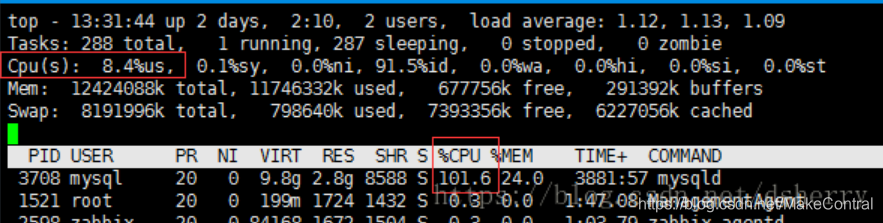
在top情况下按1,查看CPU的所有核的情况:可以知道一个用户进程只是针对某一核的,如果你的CPU有12核,那么就意味着你最高可以有12个100%占用CPU的进程同时运行。
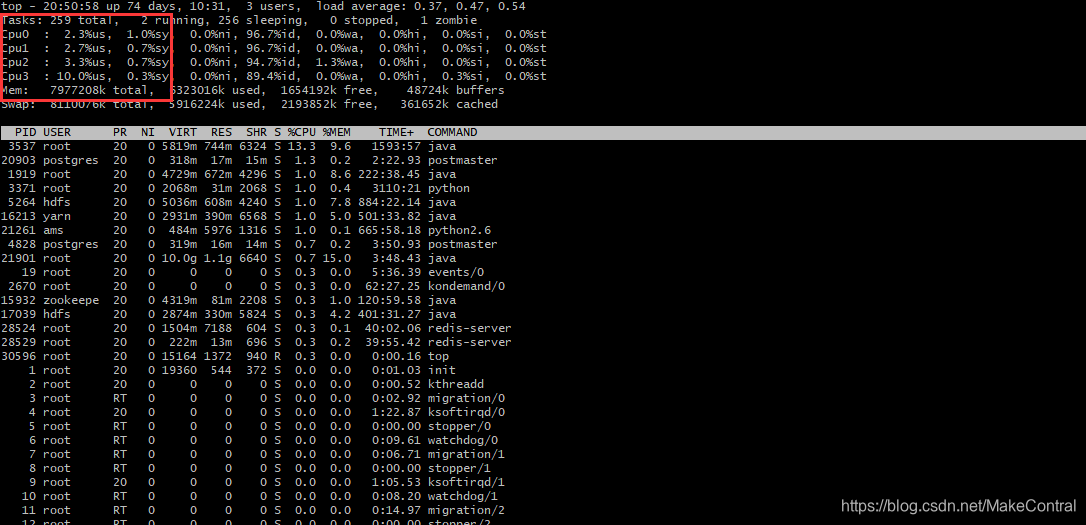
CPU负载过高
上面简单的说明了一下top命令该注意的地方,那么现在再应用一下。实验环境:Linux + 单核CPU。
为了重现问题,在Linux运行了以下脚本:
public class Test {
public static void say(){
System.out.println("abc");
System.out.println("123");
}
public static void main(String args[]){
say();
while(true) {
System.out.println("1");
}
}
}
使用top命令查看:
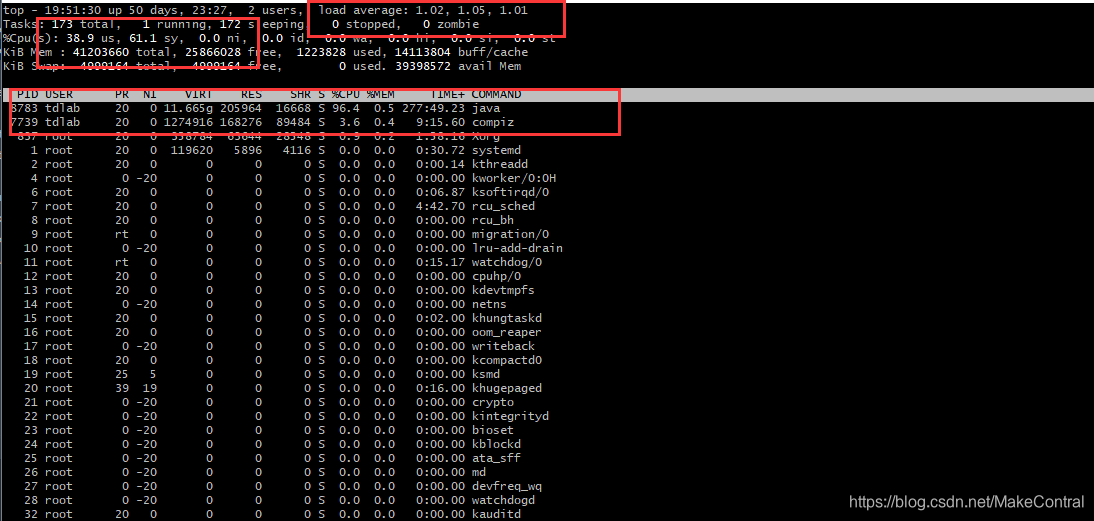
因为是CPU是单核的原因,所以从load average上看出来,CPU已经是负载运行了。这个时候,可以去看一下PID为8783的进程中有有哪些线程,使用一下命令:
top -Hp 8783 # -H 可以查看由某个进程启动的所有线程 ,p指定要看的进程
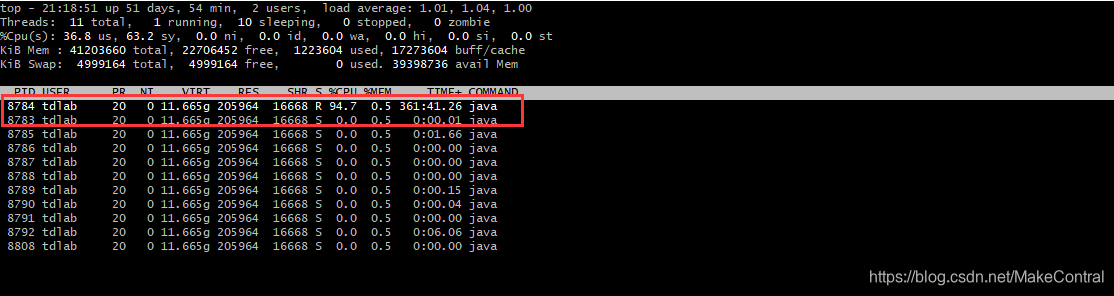
可以看到8783进程中8784线程占用了CPU的时间比最高。这个时候可以使用jstack命令查看,8783线程在运行什么代码,在使用jstack命令之前,需要将8784转为16进制,使用以下命令:
printf '%x\n' 8784 # 得到2250
使用jstack命令查看线程为8784的情况:
jstack 8783 | grep '2250' -A 100 # -A 表示在grep匹配到之后再输出100行
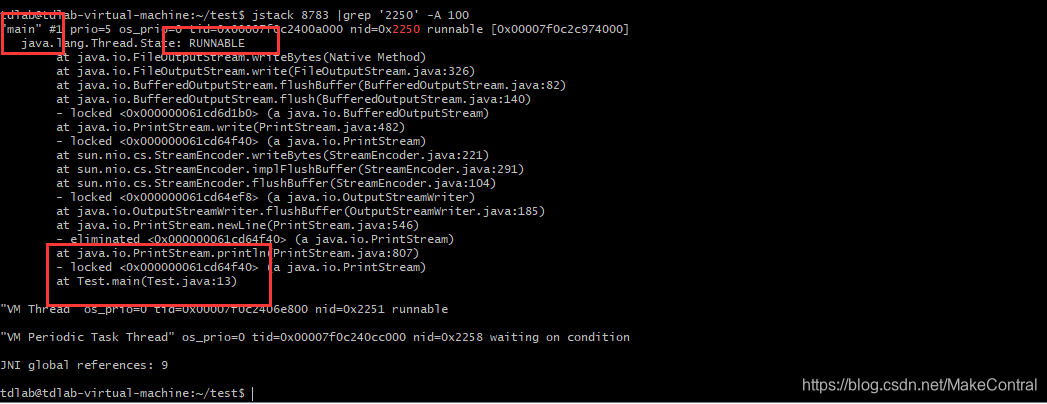
可以看到当前线程执行代码块位置,这个时候就可以去根据你的代码逻辑去排查问题了。
内存溢出
内存溢出的解决办法可以查看我之前的博客:JVM 之 性能监控与故障处理
频繁Full GC
首先你可以使用jstat -gcutil查看一下堆回收的基本情况。
jstat -gcutil <pid> 1000 # 每1000毫秒输出<pid>堆的使用情况
通常来说触发Full GC有以下几点原因:
显示调用System.gc() 。只是建议系统进行GC,并不一定触发
长期存活的对象将进入老年代。
大对象直接进入老年代。
Minor GC晋升到旧生代的平均大小大于老年代的剩余空间 。比如你第一次Minor GC有2M晋升到老年代中,那么下次执行Minor GC时会先判断老年代的空间是否大于2M。
通过jstat的结果可能可以排除掉一些原因,但是最好是结合GC日志来查看。GC的日志文件可以在JVM启动时,添加-XX:+PrintGCDetails,或者你想在不停掉服务的情况,使用jinfo的命令去动态的调整虚拟机的各项参数:
jinfo -flag +PrintGCDetails <pid>
下面就是GC日志,你可以知道当前GC的类型(如果是System.gc,会在后面给出提示)、堆使用的垃圾收集器,回收时间等信息:
[GC (System.gc()) [PSYoungGen: 3686K->664K(38400K)] 3686K->672K(125952K), 0.0016607 secs][Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 664K->0K(38400K)] [ParOldGen: 8K->537K(87552K)] 672K->537K(125952K), [Metaspace: 2754K->2754K(1056768K)], 0.0059024 secs][Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 38400K, used 333K [0x00000000d5c00000, 0x00000000d8680000, 0x0000000100000000)
eden space 33280K, 1% used [0x00000000d5c00000,0x00000000d5c534a8,0x00000000d7c80000)
from space 5120K, 0% used [0x00000000d7c80000,0x00000000d7c80000,0x00000000d8180000)
to space 5120K, 0% used [0x00000000d8180000,0x00000000d8180000,0x00000000d8680000)
ParOldGen total 87552K, used 537K [0x0000000081400000, 0x0000000086980000, 0x00000000d5c00000)
object space 87552K, 0% used [0x0000000081400000,0x00000000814864a0,0x0000000086980000)
Metaspace used 2761K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 299K, capacity 386K, committed 512K, reserved 1048576K
日志分析:
1.GC日志开头的”[GC”和”[Full GC”说明了这次垃圾收集的停顿类型,如果有”Full”,说明这次GC发生了”Stop-The-World”。因为是调用了System.gc()方法触发的收集,所以会显示”[Full GC (System.gc())”,不然是没有后面的(System.gc())的。
2.“[PSYoungGen”和”[ParOldGen”是指GC发生的区域,分别代表使用Parallel Scavenge垃圾收集器的新生代和使用Parallel old垃圾收集器的老生代。为什么是这两个垃圾收集器组合呢?因为我的jvm开启的模式是Server,而Server模式的默认垃圾收集器组合便是这个,在命令行输入java -version就可以看到自己的jvm默认开启模式。还有一种是client模式,默认组合是Serial收集器和Serial Old收集器组合。
3.在方括号中”PSYoungGen:”后面的”3686K->664K(38400K)”代表的是”GC前该内存区域已使用的容量->GC后该内存区域已使用的容量(该内存区域总容量)”
4.在方括号之外的”3686K->672K(125952K)”代表的是”GC前Java堆已使用容量->GC后Java堆已使用容量(Java堆总容量)”
5.再往后的”0.0016607 sec”代表该内存区域GC所占用的时间,单位是秒。
6.再后面的”[Times: user=0.00 sys=0.00, real=0.00 secs]”,user代表进程在用户态消耗的CPU时间,sys代表代表进程在内核态消耗的CPU时间、real代表程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待 I/O 完成)。
7.至于后面的”eden”代表的是Eden空间,还有”from”和”to”代表的是Survivor空间。
上面的操作算是排除问题的一种思路,但是你需要定位到代码,还是要把当前堆dump出来,然后使用MAT或者其他工具进行分析:
jmap -dump:[live,]format=b,file=<filename> <pid> # 把堆的对象情况dump到一个文件中
如何使用MAT在 JVM 之 性能监控与故障处理 已经描述过了。














 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









