







由Facebook开源用于解决海量结构化日志的数据统计,后称为Apache Hive为一个开源项目
-->结构化数据:数据类型,字段,value---》hive
-->非结构化数据:比如文本、图片、音频、视频---》会有非关系型数据库存储,或者转换为结构化
-->结构化日志数据:服务器生成的日志数据,会以空格或者制表符分割的数据,比如:apache、nginx等等- Hive 是一个基于 Hadoop 文件系统之上的数据仓库架构,存储用hdfs,计算用mapreduce
- Hive 可以理解为一个工具,不存在主从架构,不需要安装在每台服务器上,只需要安装几台就行了
- hive还支持类sql语言,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能(披着sql外衣的MapReduce)
- hive有个默认数据库:derby,默认存储元数据---》后期转换成关系型数据库存储mysql
-->https://github.com/apache/ 主要查看版本的依赖
下载地址:
-->apache的版本:http://archive.apache.org/dist/hive/
-->cdh的版本:http://archive.cloudera.com/cdh5/cdh/5/
2、hive的安装
tar -zxf apache-hive-1.2.1-bin.tar.gz -C /opt/module/apache/
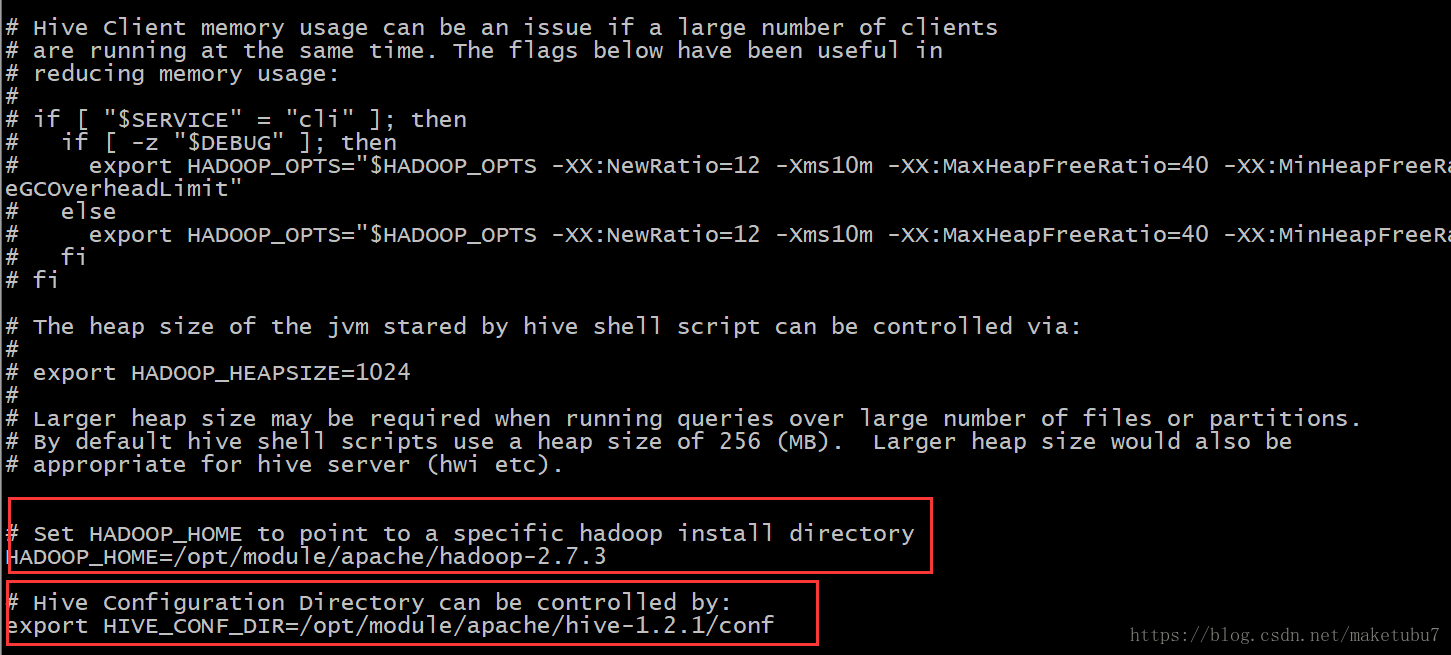
配置环境:修改名称:mv hive-env.sh.template hive-env.sh、截图保留配置
--># Set HADOOP_HOME to point to a specific hadoop install directory--> HADOOP_HOME=/opt/module/apache/hadoop-2.7.3
--># Hive Configuration Directory can be controlled by:
-->export HIVE_CONF_DIR=/opt/module/apache/hive-1.2.1/conf
2.1、在hdfs上创建目录,如下
- bin/hdfs dfs -mkdir /tmp
- bin/hdfs dfs -mkdir -p /user/hive/warehouse
- bin/hdfs dfs -chmod g+w /tmp
- bin/hdfs dfs -chmod g+w /user/hive/warehouse
在启动hive之前,一定要保证启动hadoop(hdfs,yarn),因为hive的数据仓库是建立在hdfs的文件系统之上的然后启动hive 在hive目录下 bin/hive 则可以启动hive
-->查看有哪些数据库:show databases;
-->创建数据库:create database hadoop;
-->查看表:show tables;
-->使用数据库:use hadoop;
2.2、安装MySQL
2.3、修改hive的原始Derby数据库,改为使用关系型数据库MySQL,配置如下
创建一个 hive-site.xml 从hive-defaule.xml 复制头部信息,修改具体内容如下
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
jasbdaksbdaskbdoajsbdasbu
<name>javax.jdo.option.ConnectionURL</name>
<!--指定连接的hostname及端口,和创建一张关于hive的元数据表-->
<value>jdbc:mysql://make.hadoop.com:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<!--指定连接的驱动名称-->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<!--在hive客户端显示当前所在数据库-->
</property>
<property>
<!--显示数据表的头部信息,也就是字段名称-->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>-->这里用的是 mysql-connector-java-5.1.27-bin.jar

重启hive之后,我们可以看到在我们的MySQL中生成了一个名为hive的数据库,里面有三张表,表名区分大小写
- DBS 存放hive的所有的数据库的信息及location
- TBLS 存放hive的所有的表的的信息
- PARTITIONS 存放hive的分区表的所有的分区的信息
3、hive的基础认识
3.1、hive数据类型:
-->数值型:tinyint、smallint、int、bigint --》常用的int
-->字符型:varchar、char、string --》常用string
-->时间型:date、timestamp
-->其他类型:boolean
-->复杂类型:arrays(下标是从0开始)、map(key,value)、structs
tips userlist map(int、string) userlist['1']取出value
user structs<name:string,age:int> user.name user.age
-->官网可以查看更多信息:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
3.2、如何创建表
-->如果数据的分割符与表的分割符不一致,就会解析数据异常
-->默认分割符:默认的分隔符是\001(^A),(\002为^B)默认的分隔符是以ctrl+v、ctrl+A
-->分隔符:"\t"、","、" "、^A、^B
-->指定:ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
create table test3(
id int,
name string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
加载数据
-->load data local inpath '/opt/datas/test' into table test;
查询数据
-->select * from test;
hdfs的目录结构:hive的默认存放 数据库 表 加载的数据
-->/user/hive/warehouse/ hadoop.db/ test/ test
warehouse.dir database table data
3.3、hive的操作命令
描述表
-->desc table_name;
-->desc extended table_name;
-->desc formatted table_name; --》推荐使用,如下图所示,每个信息,都有所描述

-->alter table old_table_name rename to new_table_name;
给表新添加一个列
-->alter table table_name add columns (age int);
-->alter table table_name add columns (sex int comment 'this is age'); //注释
修改列的名字或类型或顺序
-->ALTER TABLE table_name CHANGE col_old_name col_new_name column_type
创建一个测试表:
-->create table test_change (a int,b int, c int);
修改列的名称:a ---> a1
-->alter table test_change CHANGE a a1 int;
将a1改为a2,并且类型string,并放在b的后面
-->alter table test_change CHANGE a1 a2 string after b;
将c改为c1,并且放在第一列
-->alter table test_change CHANGE c c2 int first;
替换列(不能够指定替换,是全表替换)
-->ALTER TABLE table_name REPLACE COLUMNS (col_name data_type)
--> alter table test_change replace columns (d int, f string);
清空表数据
-->TRUNCATE TABLE table_name [PARTITION partition_spec];
只清空数据,表和表的结构还存在
-->truncate table test;
删除数据表drop
删除表:同时将表的元数据信息删除
-->drop table table_name;
删除数据库drop (CASCADE)
-->drop database dabase_name;
-->drop database dabase_name cascade;
查看hive自带的函数方法
-->show functions;
描述函数的信息:
-->desc function count;
-->desc function extended count; 推荐使用这个
3.4、hive的常用配置以及linux命令选项
设定hive的log存放目录,修改hive-log4j.properties
-->hive.log.dir=/opt/apps/hive-1.2.1/logs
指定登录到某个数据库
-->bin/hive --database hadoop
指定一个sql语句,去执行,sql语句必须用引号包裹
-->bin/hive -e 'select * from hadoop.test'
指定一个包含sql语句的文件,去执行
-->bin/hive -f /opt/datas/test.sql
使用重定向将结果保存到某个文件
-->bin/hive -f /opt/datas/test.sql >> /opt/datas/hive.txt
临时修改配置信息参数的值,属于临时生效
-->bin/hive --hiveconf hive.cli.print.current.db=false
在hive客户端里去修改参数信息
-->set hive.cli.print.current.db; --》查看
-->set hive.cli.print.current.db=false; --》修改
自定义数据仓库的位置localtion
-->CREATE DATABASE database_name [LOCATION hdfs_path]
-->create database hive_db location "/hive_test"
-->show tables in hadoop22; 查看其他数据库下的所有表
常用的shell:! 和 dfs
-->! 表示可以访问linux本地文件系统:比如:! ls /opt/apps;
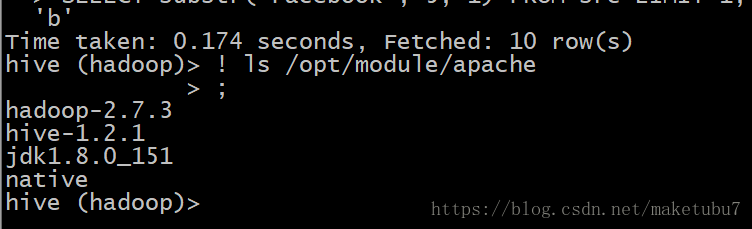
-->dfs 表示可以访问hdfs文件系统:
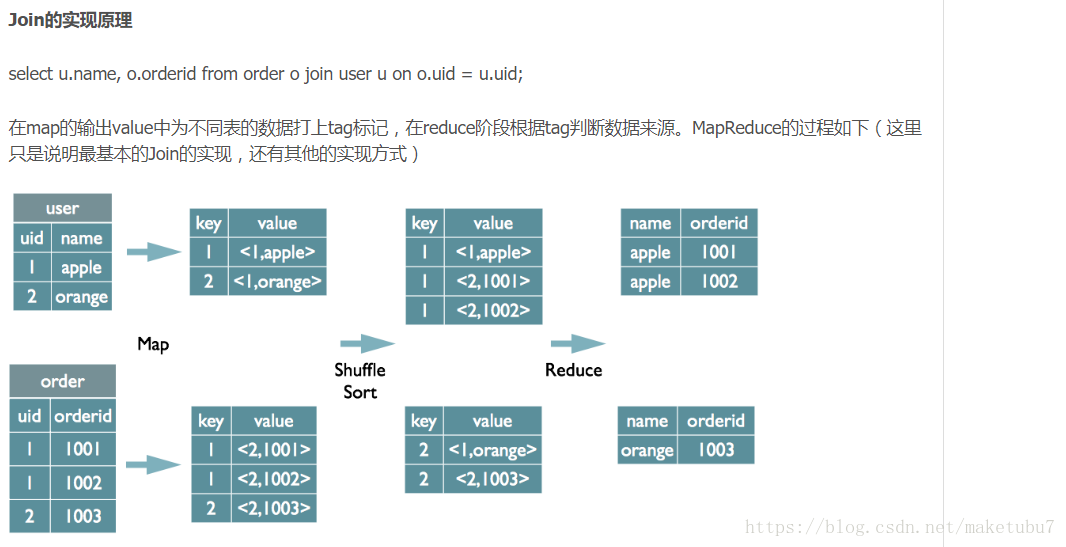
4、对于如何将sql语句转化为课执行的任务的?
1、Antlr自定义规则,识别hive的sql,(写sql的时候,语法错误,可以直接被识别,不会运行到一半才报错)(跟mysql很类似的,但是会有一些自己的东西。rownumber,over X partition(XXX)range 30 between 30 XXX)
2、抽象语法树AST tree sql根据 select ,from,filter(where)XXX---》生成像一个树节点状的逻辑,查询分块(spark,dsl语法的时候)
3、逻辑操作operator 每一块的输入是哪些字段,输出是哪些字段(as 别名)
4、逻辑优化 谓词前置,前推 判断是否能在map直接聚合(mapjoinXX)
-->select X ,X from (select u.name,u.orderid from user u where XXX)where XXX
5、遍历逻辑生成mr任务
6、物理层面的优化器,在优化mr任务,生成最终执行的计划
下面从其他博客截了几张图,应该会更好的理解,方便我自己后面可查看啦
两张标的join的实现
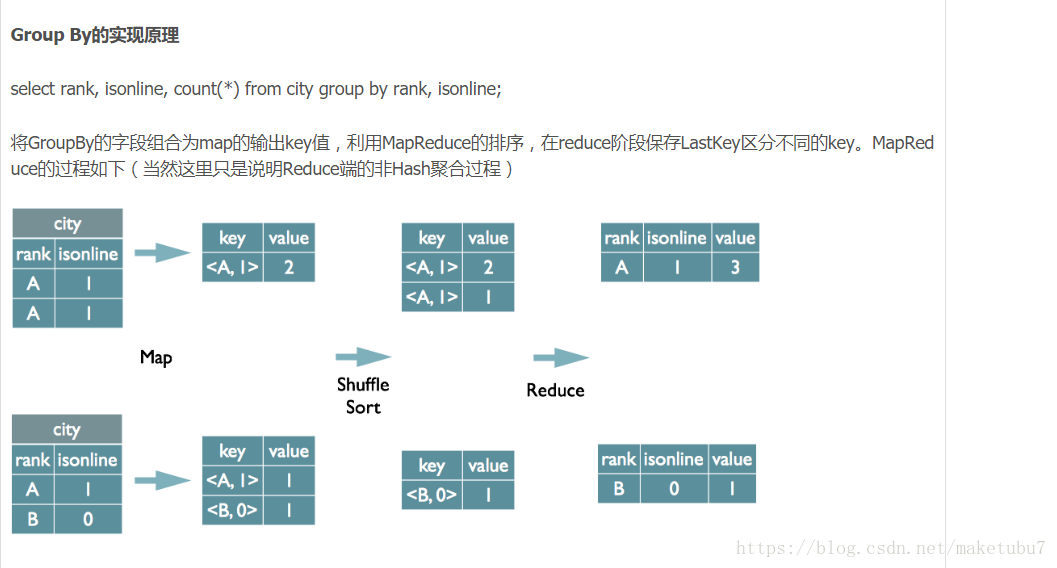
group by 的实现
distinct 的实现
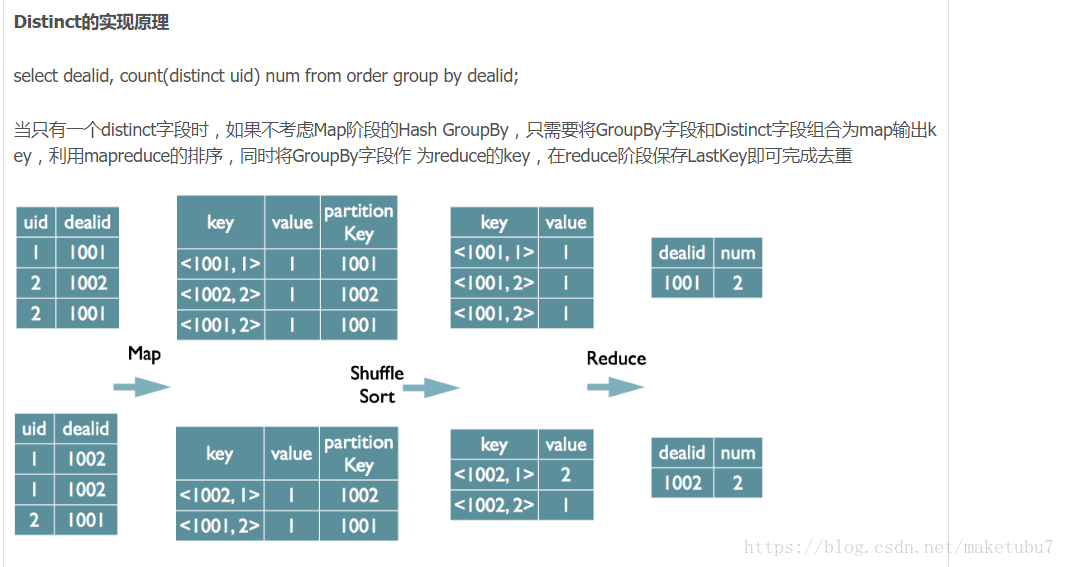
更多的请参考此地址:https://blog.csdn.net/u010738184/article/details/70893161
5、hive的四大表数据的类型
表类型说明table内部表 Partition分区表 External Table外部表 Bucket Table桶表
5.1、内部表就相当于我们前面创建的表,建好内部表后,通过load的方式加载本地数据,和通过hdfs文件系统-put一份数据到表下面的效果是一样的,
也就是说load的本质,就是把本地文件put上去,并不会修改相关表的元数据。
外部表与内部表的区别
- 创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。
- 删除表时:在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据
分区表:[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
普通的表:select * from logs where date = '20171209'
-->执行流程:对全表的数据进行查询,然后才过滤操作
分区表:select * from logs where date = '20171209'
-->执行流程:直接加载对应文件路径下的数据
分区表的直接加载方式,以及对分区的修复
直接在hdfs上创建分区文件夹
-->dfs -mkdir /user/hive/warehouse/emp_part/day=20180627
-->dfs -put /opt/datas/emp.txt /user/hive/warehouse/emp_part/day=20180627
但是这样创建day=20180627的分区表之后,直接查看,表中是没有数据的,因为我们的元数据库里面,根本没有day这个分区,所以我们要对这个表进行修复才可以有以下两种方式
1、=>msck repair table emp_part
2、=>alter table emp_part add partition(day = '20180627')
这样就可以把分区的信息,更新到元数据信息里面,也就可以查出对应的数据
分区的字段是逻辑性的,体现在hdfs上形成一个文件夹存在,并不在数据中,必须不能是数据中已包含的字段
创建一级分区,并加载数据
create table emp_part(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)partitioned by (`date` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='20171209');
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='20171208');select * from emp_part;
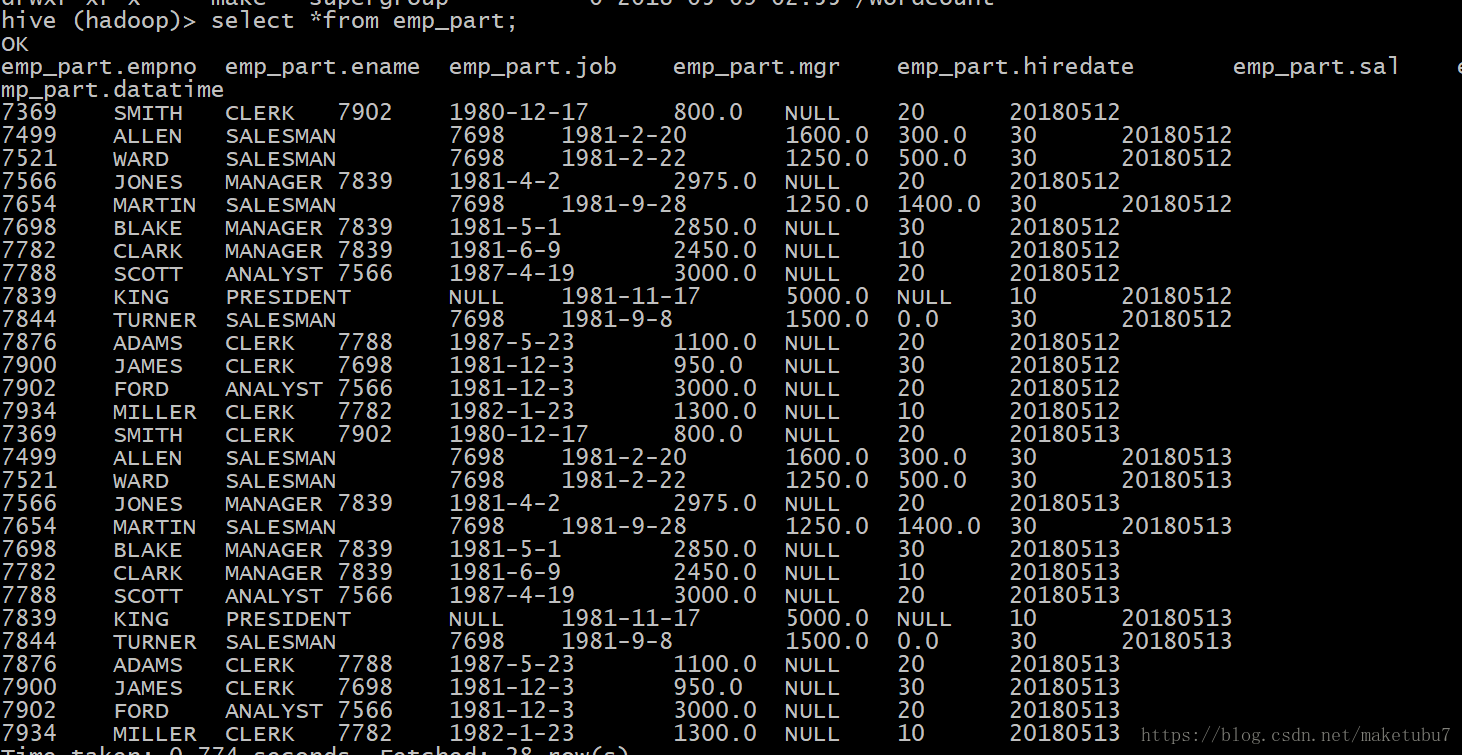
创建二级分区,并加载数据
create table emp_part2(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)partitioned by (`date` string,hour string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='20171209',hour='01');
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='20171209',hour='02');select * from emp_part2 where datatime = '20180518' and hour = '2';
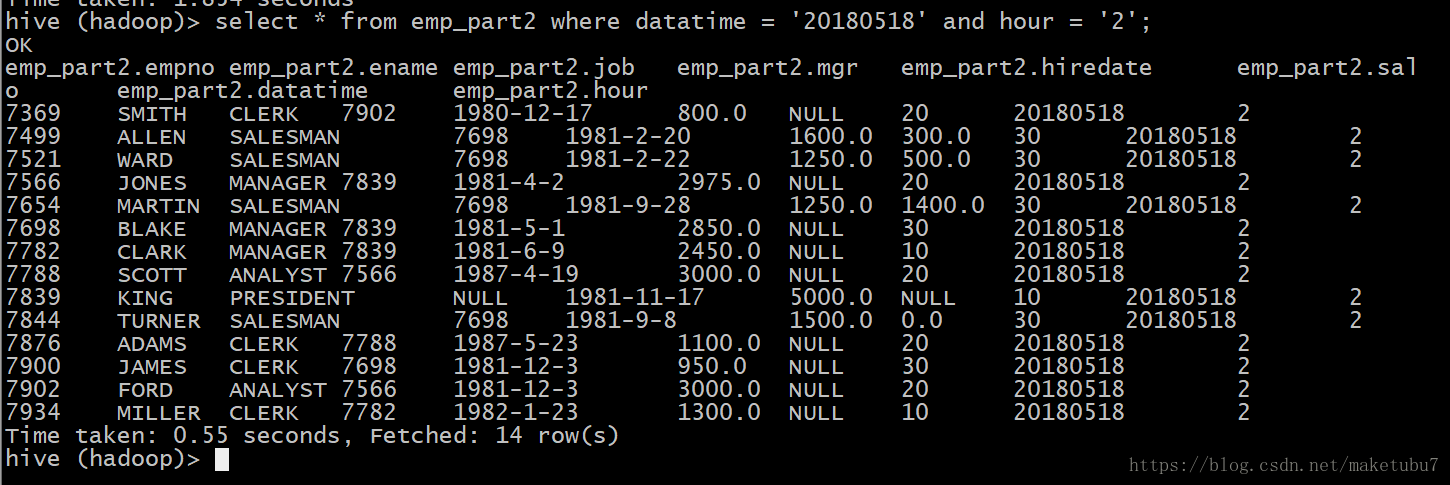
老师给的小技巧啦
关于分区字段的设置:
报错一:
FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns
原因:分区字段不能和原有字段冲突,比如有个叫day的字段,分区就不能用这个字段名
FAILED: ParseException line 11:15 Failed to recognize predicate 'date'. Failed rule: 'identifier' in column specification
因为这个是在1.2.0版本之后增加的一个新特性 hive.support.sql11.reserved.keywords
支持了sql2011,就是保留了一些关键字
解决方法:date上面加反引号 `date`
或者hive.support.sql11.reserved.keywords这个参数改成false
但是建议还是避开关键字,不然你把sql写在shell中的时候,`date`,shell会识别成一个脚本(推荐避开关键字)
FAILED: SemanticException [Error 10062]: Need to specify partition columns because the destination table is partitioned
解决:指定分区就好了。。
桶表:获得更高的查询处理效率、join、抽样数据,但是在做join的时候的两张表必须都是桶表,桶表其实就是根据一个字段的hash值来对表进行分区的感觉,自己这样认为,除非真的这个业务通过桶表能大大提神效率,负责分区表应该就足够了。
桶表的应用场景
比如我数据有严重的数据倾斜,分布不均匀、相对来说每个桶中的数据量会比较平均、桶于桶之间做join等查询的时候,会有优化
6、hive数据导入的多种方式
1、本地 load data local inpath '' XXXX --》cp
2、hdfs load data local inpath '' XXXX --》mv
3、加载一份临时的数据
load data local inpath '路径' overwrite into table emp
4、子查询
insert into table XXX select * from XXXX
like(不复制数据,只复制表机构)
5、location
数据本身已经存在,建表的时候指定hdfs上的路径
6、通过hdfs命令,将文件put到对应的位置
(如果分区表,要记得alter XXXX add/drop partition(XXXX))
7、通过其他工具(sqoop,spaark这类型的工具,从数据库等其他地方将数据加载到hdfs或者hive的表中)
暂时写到这里,我开始理思路了,毕竟太菜啦!!!!!
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
普通的表:select * from logs where date = '20171209'
执行流程:对全表的数据进行查询,然后才过滤操作
分区表:select * from logs where date = '20171209'
执行流程:直接加载对应文件路径下的数据
分区的字段是逻辑性的,体现在hdfs上形成一个文件夹存在,并不在数据中,必须不能是数据中已包含的字段


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









