







一.引言
在高性能计算,实时系统或资源受限的嵌入式场景中,合理分配和管理CPU资源是优化系统性能的关键。本文围绕绑核(CPU Affinity),cgroups(Control Groups)和 cpulimit三大工具,详细介绍其原理,使用方法及适用场景,希望对你的系统优化工作有所增益。
二.绑核(CPU Affinity)
2.1 核心原理
绑核通过将进程或线程固定到特定的 CPU 核心上运行,减少 上下文切换(Context Switch) 的开销,提升 缓存命中率(Cache Locality)。例如,在 4 核的 J3 芯片上,将高频计算任务绑定到 CPU3,可避免其他进程干扰。为了示例展示的方便性,观复君选择在Ubuntu22.04,24核CPU上进行演示。
2.2 Demo代码
为了方便展示,我写了一个大概会占用5个核的demo C++程序cpu_test.cpp(下文提到的cpu_test带指该程序)。
#include <iostream>
#include <thread>
#include <unistd.h>
#include <atomic>
#include <chrono>
#include <cstring>
#include <vector>
#include <cmath> // 添加复杂数学函数
#include <random> // 添加随机数生成
// 生成随机数填充数据
void fill_random_data(std::vector<double>& data) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<> dis(1.0, 100.0);
for (auto& val : data) {
val = dis(gen);
}
}
// 增强的复杂运算(完全占用CPU)
void complex_logic(int id) {
constexpr size_t data_size = 1000000; // 增大数据量至1M
std::vector<double> large_data(data_size);
fill_random_data(large_data); // 填充随机数据增加计算多样性
volatile double sink = 0; // 防止编译器优化
while (true) {
// ========== 增强的数学运算 ==========
double sum = 0.0;
double product = 1.0;
double sum_squares = 0.0;
// 循环展开(每次处理4个元素)
for (size_t i = 0; i < large_data.size(); i += 4) {
// 批量计算加法/乘法/平方
const double d1 = large_data[i];
const double d2 = (i+1 < large_data.size()) ? large_data[i+1] : 1.0;
const double d3 = (i+2 < large_data.size()) ? large_data[i+2] : 1.0;
const double d4 = (i+3 < large_data.size()) ? large_data[i+3] : 1.0;
sum += d1 + d2 + d3 + d4;
product *= d1 * d2 * d3 * d4;
sum_squares += d1*d1 + d2*d2 + d3*d3 + d4*d4;
}
// ========== 复杂数学函数 ==========
double avg = sum / large_data.size();
double root_mean_square = std::sqrt(sum_squares / large_data.size());
double harmonic_mean = large_data.size() / sum;
// ========== 增强的内存操作 ==========
std::vector<double> copied_data(large_data.size());
// 双向复制增加内存压力
memcpy(copied_data.data(), large_data.data(), large_data.size() * sizeof(double));
memcpy(large_data.data(), copied_data.data(), large_data.size() * sizeof(double));
// ========== 强制结果输出 ==========
sink = avg + root_mean_square + harmonic_mean;
std::cout << "Thread " << id << " | RMS: " << root_mean_square
<< " | Product: " << product << "\n"; // 简化输出减少IO压力
}
}
// 高强度计算线程(无sleep)
void busy_thread(int id) {
volatile double sink = 0; // 防止优化
std::vector<double> matrix(1000, 1.618); // 预置数据
while (true) {
// 矩阵运算模拟
for (size_t i = 0; i < matrix.size(); ++i) {
matrix[i] = std::sin(matrix[i]) + std::log(matrix[i] + 1.0);
}
// 累加结果
double sum = 0.0;
for (const auto& val : matrix) {
sum += val;
}
sink = sum;
}
}
int main() {
constexpr int NUM_THREADS = 4;
std::thread threads[NUM_THREADS];
// 启动4个高强度计算线程
for (int i = 0; i < NUM_THREADS; ++i) {
if (i % 2 == 0) {
threads[i] = std::thread(complex_logic, i);
} else {
threads[i] = std::thread(busy_thread, i);
}
}
std::cout << "CPU压力测试已启动(按Ctrl+C终止)\n";
// 主线程也参与计算
complex_logic(NUM_THREADS); // 主线程加入计算
// 实际不会执行到这里(因无限循环)
for (auto& t : threads) {
t.join();
}
return 0;
}2.3 绑核操作方法
2.3.1 命令行工具“taskset”
# 启动进程时绑定到 CPU0 和 CPU1(掩码 0x3)
taskset -c 0,1 ./my_program
# 修改已运行进程(PID=1234)的绑核为 CPU2
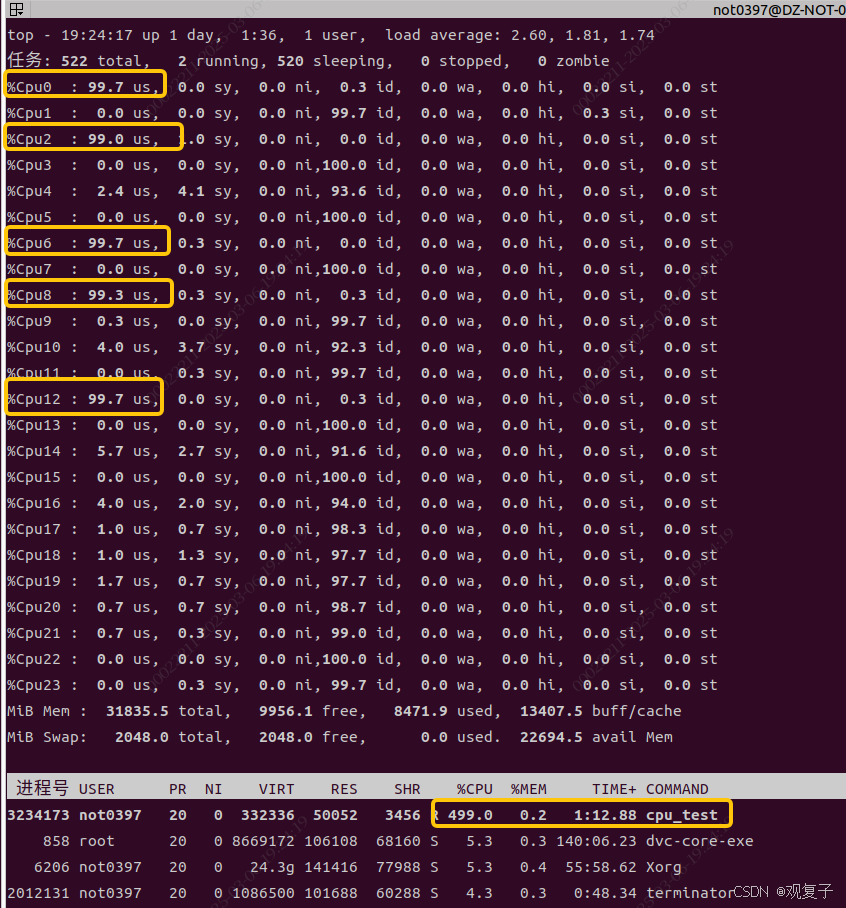
taskset -pc 2 1234先不进行绑核操作,运行cpu_test看一下它的cpu load和会在哪些核上运行。当然。没有绑核操作,它所占用的核是动态的。
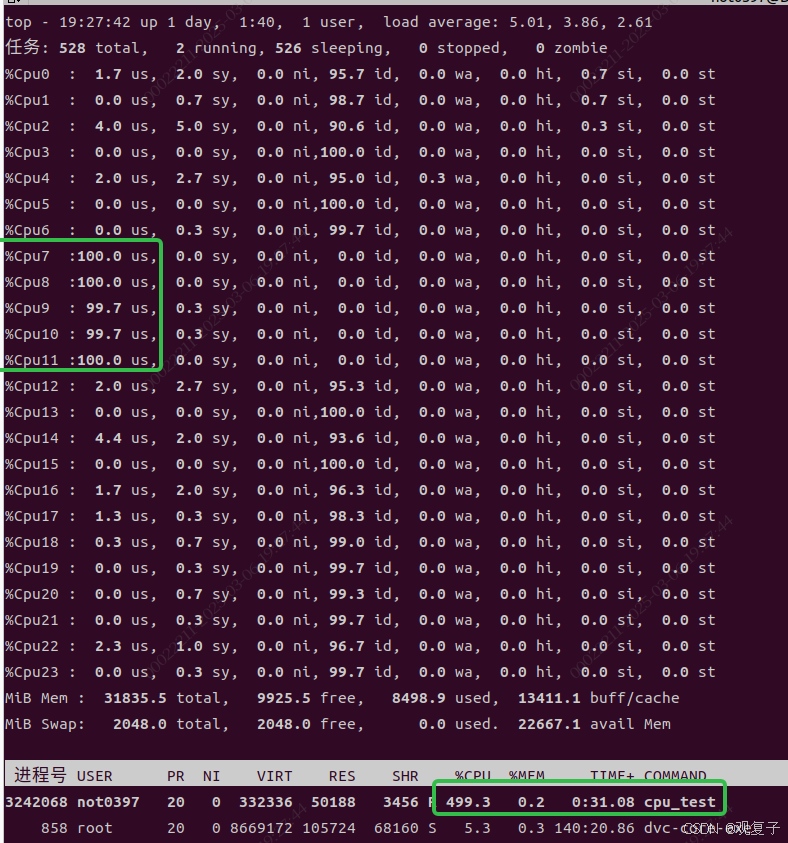
接下来我们用指令"taskset -c 7,8,9,10,11 ./cpu_test"把它绑定到核【7-11】上运行,运行结果如下。
2.3.2 编程接口
#include <sched.h>
...
int main() {
cpu_set_t mask;
CPU_ZERO(&mask); // 清空掩码,确保初始无绑定核心
// 设置要绑定的 CPU 核心(7、8、9)
CPU_SET(7, &mask); // 绑定到 CPU7
CPU_SET(8, &mask); // 绑定到 CPU8
CPU_SET(9, &mask); // 绑定到 CPU9
CPU_SET(11, &mask); // 绑定到 CPU9
CPU_SET(12, &mask); // 绑定到 CPU9
// 调用 sched_setaffinity 设置 CPU 亲和性
if (sched_setaffinity(0, sizeof(mask), &mask) == -1) {
perror("sched_setaffinity 失败");
exit(EXIT_FAILURE);
}
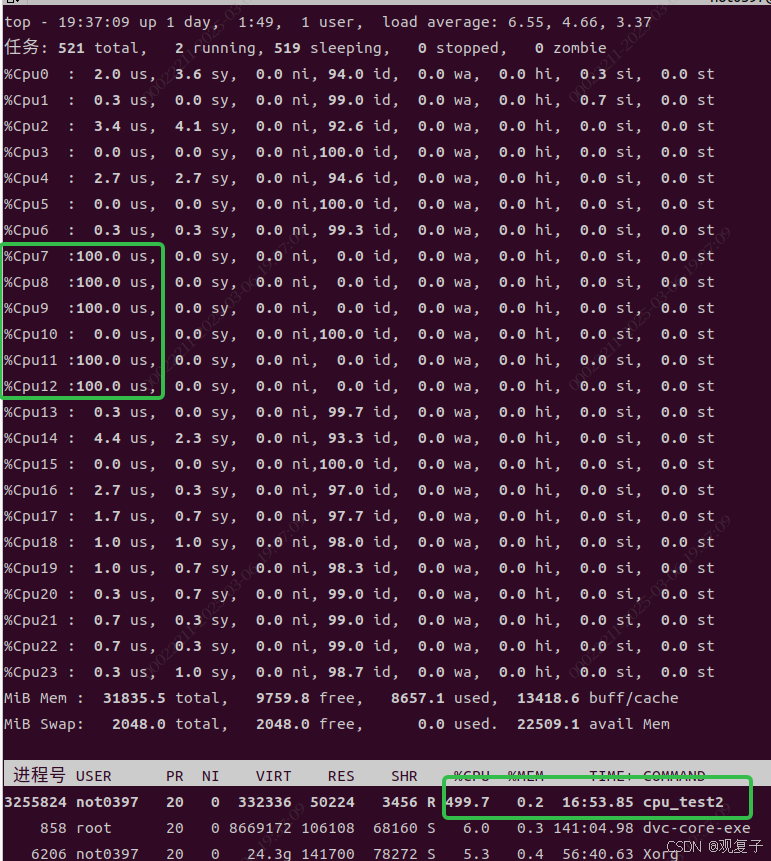
为了便于观察代码层级修改的效果,在原有代码基础上新增如上设置,让新编译的cpu_test2程序运行在【7,8,9,11,12】这5个核上。实际效果如下。
代码释义如下:
-
清空掩码
CPU_ZERO(&mask):将cpu_set_t类型的掩码变量mask所有位初始化为 0,确保无残留绑定。 -
设置目标 CPU 核心
-
CPU_SET(7, &mask):将掩码的第 7 位设为 1(对应 CPU7)。 -
CPU_SET(8, &mask):将掩码的第 8 位设为 1(对应 CPU8)。 -
CPU_SET(9, &mask):将掩码的第 9 位设为 1(对应 CPU9)。
-
-
应用 CPU 绑定
sched_setaffinity(0, sizeof(mask), &mask):-
第一个参数
0表示当前线程(若需绑定其他线程或进程,需替换为 PID)。 -
第二个参数
sizeof(mask)指定掩码大小。 -
第三个参数
&mask传递设置好的位掩码。
-
-
错误处理
检查函数返回值是否为-1,若失败则通过perror输出错误信息。
注意事项
-
CPU 核心有效性
-
确保系统中存在 CPU7、8、9(可通过
lscpu或/proc/cpuinfo确认)。 -
若系统核心数不足(如仅 8 个核心),绑定 CPU9 会失败并触发错误。
-
-
多核绑定的性能影响
-
优势:跨多个核心运行可提升并行计算能力。
-
劣势:若任务无法并行化,可能因上下文切换增加开销。
-
-
动态绑定调整
-
可通过
sched_getaffinity获取当前绑定状态,动态修改掩码后重新设置。
-
2.3.3 查看进程的CPU亲和性
username:~/test/size$ taskset -cp 3255824
pid 3255824 的当前亲和力列表:7-9,11,12
三.cgroups:内核级资源隔离
3.1 什么是cgroups
1. 定义
cgroups(Control Groups)是 Linux 内核提供的一种 资源隔离机制,用于对进程组(一组进程)进行 资源分配、限制和监控。它通过将进程划分到不同的控制组(cgroup),实现对以下资源的精细化管控:
-
CPU:限制 CPU 时间配额或绑定核心。
-
内存:限制内存使用量(包括物理内存和交换分区)。
-
I/O:控制磁盘和网络带宽。
-
设备访问:限制对特定设备的操作权限。
2. cgroups 的核心组件
-
层级(Hierarchy):树状结构的控制组,每个层级可关联一个或多个子系统。
-
子系统(Subsystem):资源控制器(如
cpu、memory),负责具体资源的管理。 -
控制组(cgroup):层级中的节点,包含一组进程和资源限制规则。
3. cgroups 的工作原理
-
资源分配:每个 cgroup 可设置资源使用上限(如 CPU 配额、内存上限)。
-
进程绑定:将进程加入某个 cgroup 后,其资源使用受该组的规则约束。
-
层级继承:子 cgroup 继承父组的限制规则,并可添加更严格的规则。
3.2 cgroups与进程的关系
1. 进程如何归属到 cgroup?
-
静态分配:通过将进程 PID 写入 cgroup 的
tasks或cgroup.procs文件。 -
动态继承:进程创建的子进程默认继承父进程的 cgroup 归属。
2. 进程的资源限制生效方式
-
子系统生效范围:每个子系统(如
cpu、memory)独立管理资源。-
例如,一个进程可以同时属于
cpu子系统的/groupA和memory子系统的/groupB。
-
-
资源竞争规则:同一父 cgroup 下的子组按权重(如
cpu.shares)分配资源。
3. 进程的可见性
-
虚拟文件系统:cgroups 通过
/sys/fs/cgroup目录暴露接口,管理员可直接读写文件配置规则。 -
实时生效:修改 cgroup 文件后,规则立即作用于组内所有进程。
3.3 补充说明 - cgroup v2
由于观复君是用ubuntu22.04演示的,它支持的是cgroup v2,其配置方式与传统的 cgroups v1 有所不同。
-
统一层级结构:所有资源控制器(CPU、内存、IO 等)在同一层级下管理,不再有单独的
cpu、memory子目录。 -
关键配置文件:
-
cpu.max:限制 CPU 使用时间。 -
memory.max:限制内存使用量。 -
cgroup.procs:将进程加入当前 cgroup。
-
-
路径示例:
-
用户自定义 cgroup 通常位于
/sys/fs/cgroup/<自定义组名>。 -
系统服务 cgroup 位于
/sys/fs/cgroup/system.slice/(由 systemd 管理)。
-
3.4 配置参数详解与操作示例
3.3.1 创建自定义 cgroup 目录
# 创建名为 mygroup 的 cgroup 目录
sudo mkdir /sys/fs/cgroup/mygroup3.3.2 启用资源控制器
默认情况下,Ubuntu 22.04 已启用 cpu 和 memory 控制器。若需手动启用:
# 挂载 cgroups v2(通常已自动挂载)
sudo mount -t cgroup2 none /sys/fs/cgroup
# 启用 CPU 和内存控制器(如果未启用)
echo "+cpu +memory" | sudo tee /sys/fs/cgroup/cgroup.subtree_control3.3.3 配置CPU限制
# 进入自定义 cgroup 目录
cd /sys/fs/cgroup/mygroup
# 设置 CPU 配额(格式:quota period)
# 示例:限制为 50% CPU(周期 100000μs,配额 50000μs)
echo "50000 100000" | sudo tee cpu.max
# 可选:设置 CPU 权重(默认 100,范围 1-10000)
echo 500 | sudo tee cpu.weight3.3.4 配置内存限制
# 限制内存为 512MB
echo "536870912" | sudo tee memory.max
# 可选:设置内存软限制(允许短暂超限)
echo "402653184" | sudo tee memory.high| 特性 | memory.max(硬限制) | memory.high(软限制) |
|---|---|---|
| 作用 | 内存使用的绝对上限 | 内存使用的建议性上限 |
| 超限后果 | 立即触发 OOM Killer,终止进程 | 异步回收内存,限流进程的内存分配 |
| 适用场景 | 强制防止内存耗尽(如关键服务隔离) | 容忍临时超限,但需抑制内存增长(如批处理任务) |
| 优先级 | 高于 memory.high | 低于 memory.max |
-
内存使用量 <
memory.high-
进程正常分配内存,无限制。
-
-
内存使用量 ≥
memory.high-
内核开始 异步回收内存(释放缓存、交换到 Swap)。
-
进程的后续内存分配会被 限流(分配速度降低,可能伴随延迟增加)。
-
-
内存使用量 ≥
memory.max-
内核触发 同步回收(强制释放内存)。
-
若回收失败,立即触发 OOM Killer,终止进程。
-
3.3.5 将进程加入 cgroup
# 启动测试进程(示例:启动一个死循环)
./cpu_test
# 将进程 PID 写入 cgroup.procs
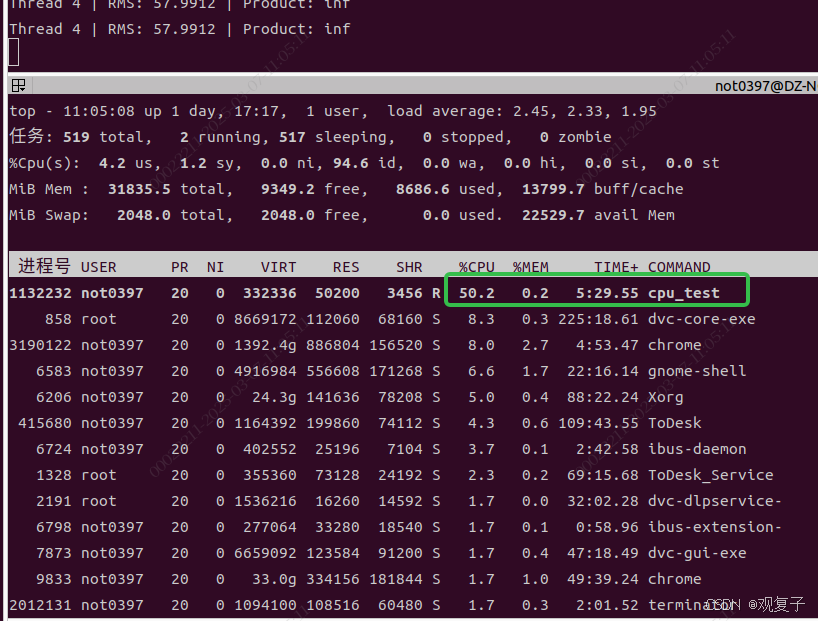
echo $PID | sudo tee /sys/fs/cgroup/mygroup/cgroup.procs配置后cpu_test的cpu load被限制到了50%以内(原)。
为了便于观察进程是否OOM,观复君把进程组的物理内存占用设置为最大100M,修改代码让其占用110M,观察是否crash。
echo "104857600" | sudo tee /sys/fs/cgroup/mygroup/memory.max温馨提升:通过如下指令可以观察进程组内存实时使用情况
watch -n 1 "cat /sys/fs/cgroup/mygroup/memory.current"
调整代码:
// 增强的复杂运算(完全占用CPU)
void complex_logic(int id) {
constexpr size_t data_size = 115343360 / sizeof(double); // 增大数据量至110M
std::vector<double> large_data(data_size);
fill_random_data(large_data); // 填充随机数据增加计算多样性
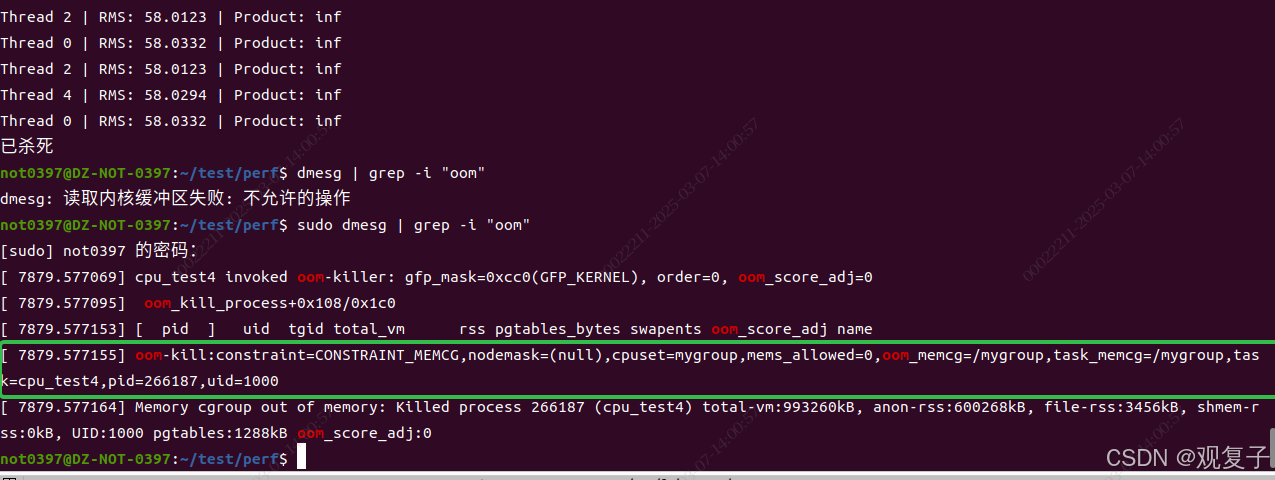
volatile double sink = 0; // 防止编译器优化把进程PID加入进程组后迟迟不见crash,感觉有点奇怪,后来才意识到可能部分内存被交换到磁盘,所以物理内存占用未超限制。临时关闭swap,再次配置程序。
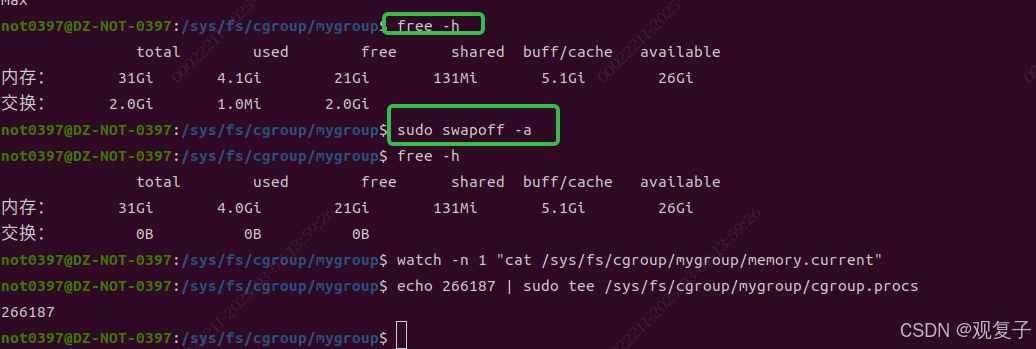
效果立竿见影
四.cpulimit:用户态CPU限制
4.1 核心原理
cpulimit 通过周期性地暂停和恢复进程(通过发送 SIGSTOP 和 SIGCONT 信号),间接限制其 CPU 使用率。适用于临时性资源控制。
4.2 操作方法
限制现有进程:
# 限制 PID=1234 的进程使用 30% CPU
cpulimit -p 1234 -l 30启动新进程时限制:
cpulimit -e ./my_program -l 504.3 适用场景
-
临时限速:开发调试时防止进程占用过高 CPU。
-
用户态进程管理:无需内核权限的快速限制。
4.4 优缺点
-
优点:简单易用,无需 root 权限。
-
缺点:精度低,可能引入延迟,不适用于实时任务。
五. 对比与选则指南
| 工具 | 精度 | 权限要求 | 适用场景 | 性能开销 |
|---|---|---|---|---|
| 绑核 | 高 | 普通用户 | 实时任务、缓存敏感型任务 | 低 |
| cgroups | 高 | Root | 容器、多租户、长期资源隔离 | 低 |
| cpulimit | 中 | 普通用户 | 临时限制、快速干预 | 中 |
选型建议:
-
实时性要求高:绑核 + cgroups(
cpuset)。 -
长期资源隔离:cgroups(
cpu+cpuset)。 -
快速临时限制:cpulimit。

















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









