







文章目录
概述
说到Clickhouse 的索引原理需要提到表引擎,Clickhouse 有很多特性和表引擎密切相关。这里只介绍索引相关的部分,关于表引擎的分类后续介绍。
建表语句,例如
CREATE TABLE if not exists audit.http_stripped_event(
`primary` String,
`reqContentType` LowCardinality(String),
`rspContentLength` UInt32,
INDEX refererIndex referer TYPE tokenbf_v1(2560, 2, 0) GRANULARITY 1,
INDEX rspContentLengthIndex rspContentLength TYPE minmax GRANULARITY 1,
INDEX fileNameIndex file_fileName TYPE bloom_filter() GRANULARITY 5,
INDEX rspStatusBfIndex rspStatus TYPE set(0) GRANULARITY 1
) ENGINE = ReplacingMergeTree() PARTITION BY date ORDER BY (primary) SETTINGS index_granularity = 8192
这里介绍几个和索引密切相关的几个参数,其他参数后续介绍。
1、PARTITION BY [选填]:分区键;用于指定表数据以何种标准进行分区。分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围
如下图所示,按照分区划分目录,所以在条件里加上分区字段可以过滤大量的目录和文件。

2、ORDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序键既可以是单个列字段,例如ORDER BY CounterID,也可以通过元组的形式使用多个列字段,例如ORDER BY(CounterID,EventDate)。当使用多个列字段排序时,以ORDER BY(CounterID,EventDate)为例,在单个数据片段内,数据首先会以CounterID排序,相同CounterID的数据再按EventDate排序。
这也就解释了 为什么根据主键排序很快。
3、PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主键字段生成一级索引,用于加速表查询。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键,无须刻意通过PRIMARY KEY声明。所以在一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数据(ReplacingMergeTree可以去重)。
我们实际业务场景还要支持去重,实现入库的幂等性,同时还要能够排序。所以主键用timestamp:id 构建主键字段。
4、SETTINGS:index_granularity [选填]:index_granularity对于MergeTree而言是一项非常重要的参数,它表示索引的粒度,默认值为8192。也就是说,MergeTree的索引在默认情况下,每间隔8192行数据才生成一条索引。
8192是一个神奇的数字,在ClickHouse中大量数值参数都有它的影子,可以被其整除(例如最小压缩块大小min_compress_block_size:65536)。通常情况下并不需要修改此参数,但理解它的工作原理有助于我们更好地使用MergeTree。
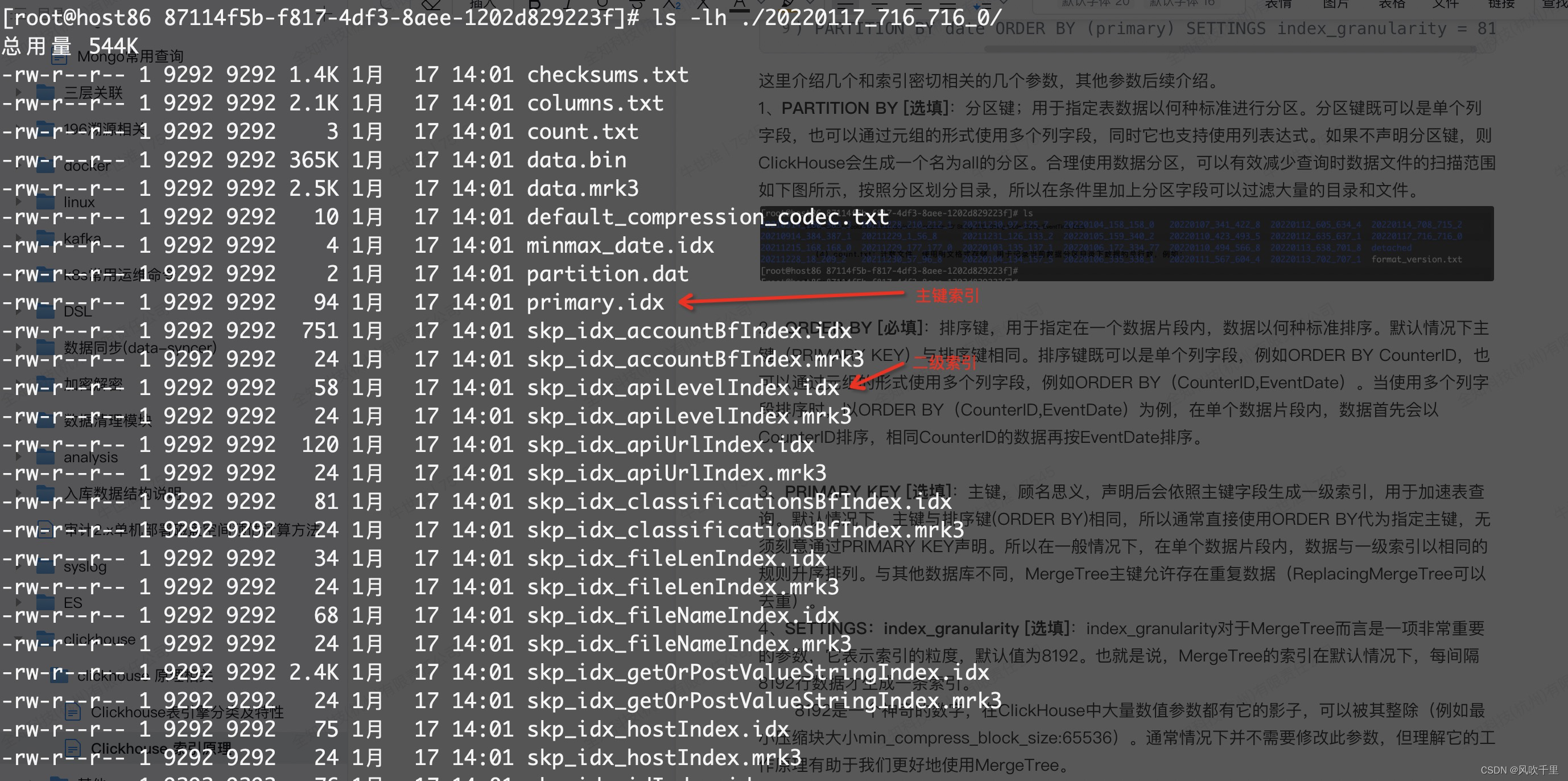
一级索引
稀疏索引
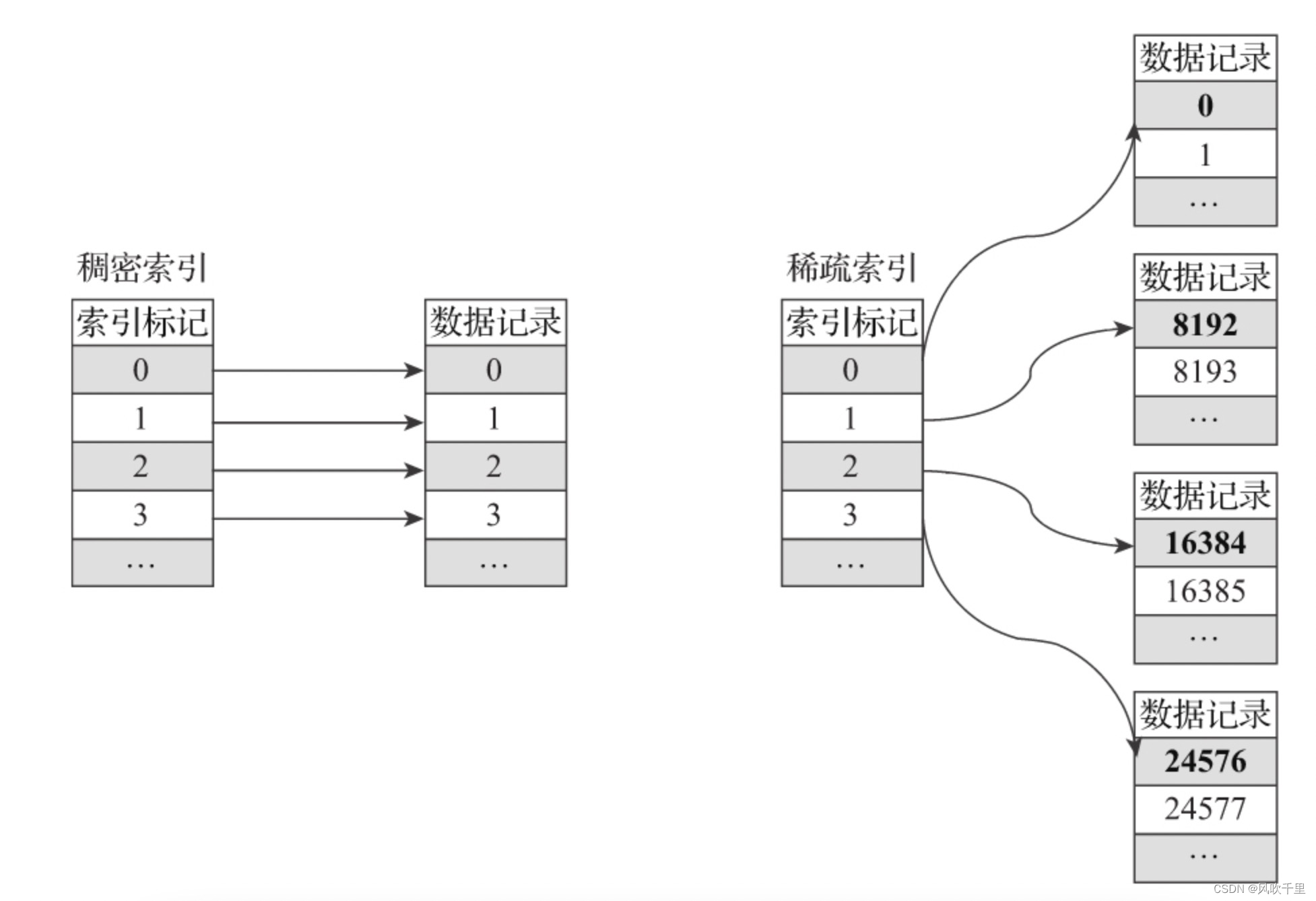
简单来说,在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。用一个形象的例子来说明:如果把MergeTree比作一本书,那么稀疏索引就好比是这本书的一级章节目录。一级章节目录不会具体对应到每个字的位置,只会记录每个章节的起始页码。
稀疏索引的优势是显而易见的,它仅需使用少量的索引标记就能够记录大量数据的区间位置信息,且数据量越大优势越为明显。以默认的索引粒度(8192)为例,MergeTree只需要12208行索引标记就能为1亿行数据记录提供索引。由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存,取用速度自然极快。
索引粒度
前面多次提到 index_granularity, 那么index_granularity 参数用什么作用呢?他其实是索引粒度,前面说到,Clickhouse的索引是稀疏索引。那么多少数据我需要建立一个标记,建立一个索引?index_granularity参数就是控制这个粒度的。
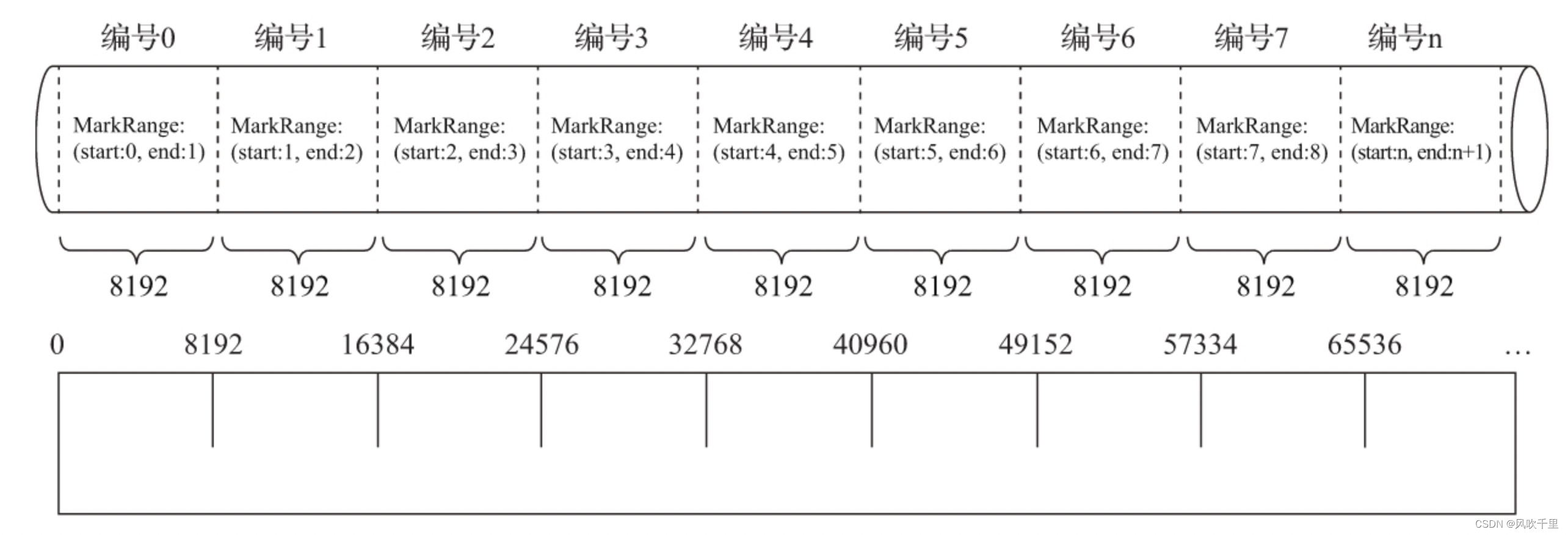
数据以index_granularity的粒度(默认8192)被标记成多个小的区间,其中每个区间最多8192行数据。MergeTree使用MarkRange表示一个具体的区间,并通过start和end表示其具体的范围。index_granularity的命名虽然取了索引二字,但它不单只作用于一级索引(.idx),同时也会影响数据标记(.mrk)和数据文件(.bin)。因为仅有一级索引自身是无法完成查询工作的,它需要借助数据标记才能定位数据,所以一级索引和数据标记的间隔粒度相同(同为index_granularity行),彼此对齐。而数据文件也会依照index_granularity的间隔粒度生成压缩数据块。
索引的查询过程
索引是如何工作的呢?首先,我们需要了解什么是MarkRange。MarkRange在ClickHouse中是用于定义标记区间的对象。通过先前的介绍已知,MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段即是一个MarkRange。MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。通过与start及end对应的索引编号的取值,即能够得到它所对应的数值区间。而数值区间表示了此MarkRange包含的数据范围。
假如现在有一份测试数据,共192行记录。其中,主键ID为String类型,ID的取值从A000开始,后面依次为A001、A002……直至A192为止。MergeTree的索引粒度index_granularity=3

根据索引数据,MergeTree会将此数据片段划分成192/3=64个小的MarkRange,两个相邻MarkRange相距的步长为1。其中,所有MarkRange(整个数据片段)的最大数值区间为[A000,+inf),其完整的示意如图所示。
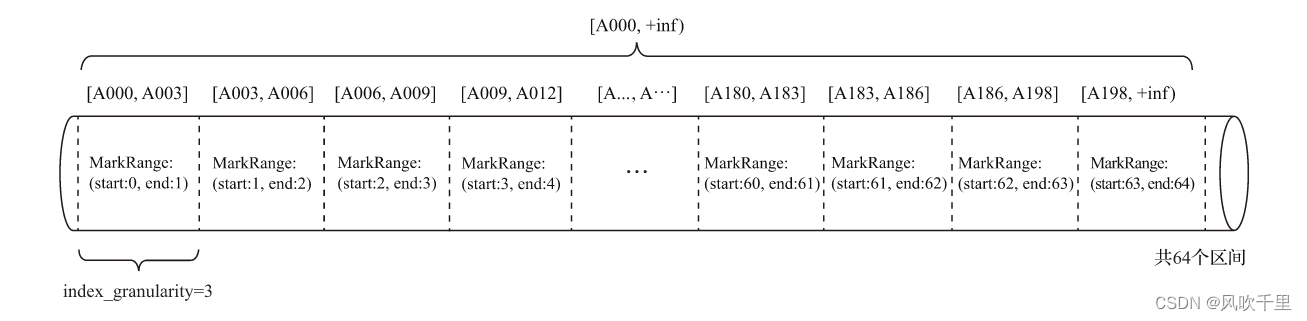
在引出了数值区间的概念之后,对于索引的查询过程就很好解释了。索引查询其实就是两个数值区间的交集判断。其中,一个区间是由基于主键的查询条件转换而来的条件区间;而另一个区间是刚才所讲述的与MarkRange对应的数值区间。
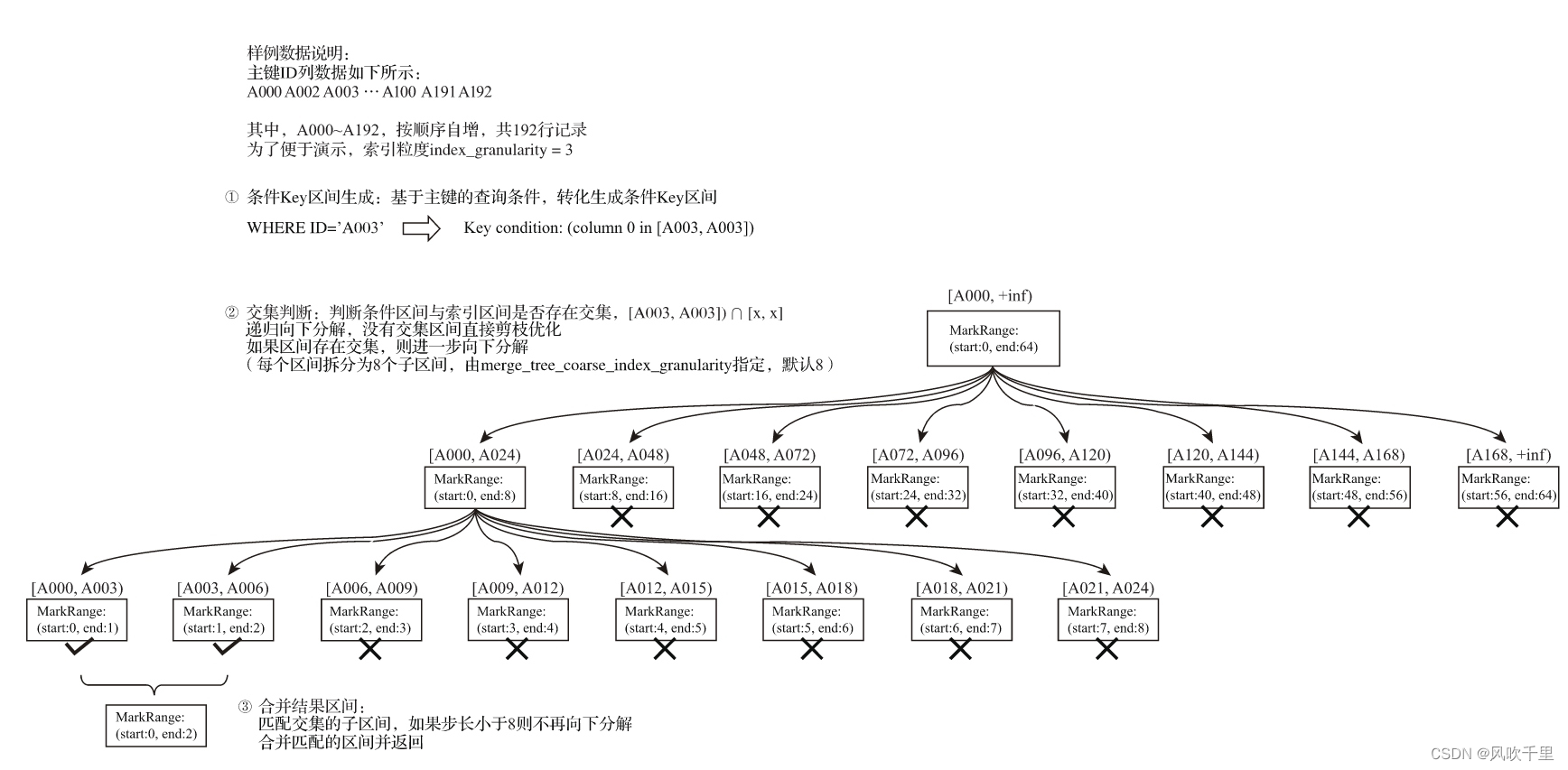
整个索引查询过程可以大致分为3个步骤。
(1)生成查询条件区间:首先,将查询条件转换为条件区间。即便是单个值的查询条件,也会被转换成区间的形式,例如下面的例子。
WHERE ID = 'A003' ['A003', 'A003'] WHERE ID > 'A000' ('A000', +inf) WHERE ID < 'A188' (-inf, 'A188') WHERE ID LIKE 'A006%' ['A006', 'A007')
(2)递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000,+inf)开始:
·如果不存在交集,则直接通过剪枝算法优化此整段MarkRange。
·如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断。
·如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
(3)合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
二级索引/跳数索引
granularity与index_granularity的关系
从上面的例子可以看到,不同的二级索引,都有一个共同的参数 granularity。那么,granularity 与 index_granularity 的关系是什么呢?
对于跳数索引而言,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度。换言之,granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
以minmax 为例:
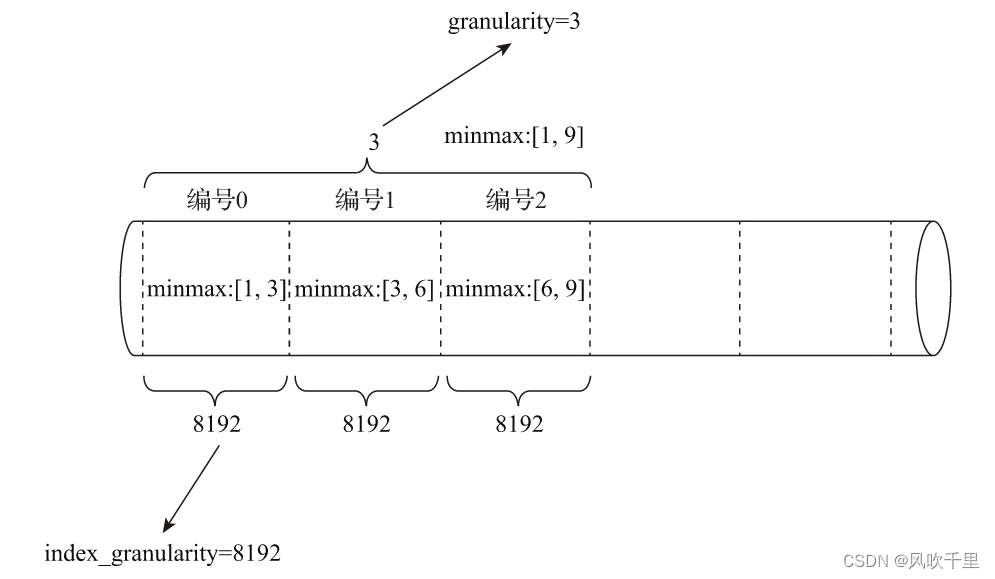
这里可以看到 minmax 索引只记录了最大值和最小值,所以minmax 适合以范围查询但是不适合排序。
这也就是解释了为什么对与timestamp 字段建立了索引后排序为什么还是慢。对于即需要排序又需要范围查询的字段,只能从主键上下功夫。
跳数索引的类型
minmax 索引
参照上一节
set 索引
set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制。
例如
INDEX apiType TYPE set(100) GRANULARITY 5
记录数据中apiType的值,每个index_granularity 中最多记录100个值,每5个index_granularity 构建一个索引记录。
适用于值的重复度很高,接近枚举值的的字段。但是同时又不是枚举值。例如apiType。
ngrambf_v1 / tokenbf_v1索引
这两个索引很像使用起来只有一个参数的差异。但是工作方式确实差异很大,所以放到一起类比的说明
这两个都是数据短语的布隆过滤器。支持String 类型。
ngrambf_v1 索引
ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_functions,random_seed)
● n:token长度,依据n的长度将数据切割为token短语。
● size_of_bloom_filter_in_bytes:布隆过滤器的大小。
● number_of_hash_functions:布隆过滤器中使用Hash函数的个数。
● random_seed:Hash函数的随机种子。
tokenbf_v1 索引
tokenbf_v1(size_of_bloom_filter_in_bytes,number_of_hash_functions,random_seed)
- tokenbf_v1 除了短语的处理方式和 ngrambf_v1 不一样,其他都一样的。
- ngrambf_v1 是按照指定的长度进行切割短语,所以切出来的短语可能是无意义的短语。
- tokenbf_v1 会自动按照非字符的、数字的字符串分割token。
这两个有什么不同?
CREATE TABLE audit.tokenTest
(
`id` String,
`a` String,
`b` String,
INDEX aindex a TYPE ngrambf_v1(3, 256, 3, 1) GRANULARITY 1,
INDEX bindex b TYPE tokenbf_v1(256, 3, 1) GRANULARITY 1
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 8192
a 字段建立 ngrambf_v1 索引,b字段建立tokenbf_v1 索引
插入两条数据
insert into tokenTest (`id`,`a`,`b`) values('123','Conditions in the WHERE clause contains calls of the functions that operate with columns. If the column is a part of an index, ClickHouse tries to use this index when performing the functions. ClickHouse supports different subsets of functions for using indexes.','Conditions in the WHERE clause contains calls of the functions that operate with columns. If the column is a part of an index, ClickHouse tries to use this index when performing the functions. ClickHouse supports different subsets of functions for using indexes.')
insert into tokenTest (`id`,`a`,`b`) values('124','此前已经多次提过,在MergeTree中数据是按列存储的。但是前面的介绍都较为抽象,具体到存储的细节、MergeTree是如何工作的,读者心中难免会有疑问。','此前已经多次提过,在MergeTree中数据是按列存储的。但是前面的介绍都较为抽象,具体到存储的细节、MergeTree是如何工作的,读者心中难免会有疑问。')
select id from tokenTest where b like '%calls of%' 根据b 字段查询当查询的短语很短时,索引没有起到过滤的作用
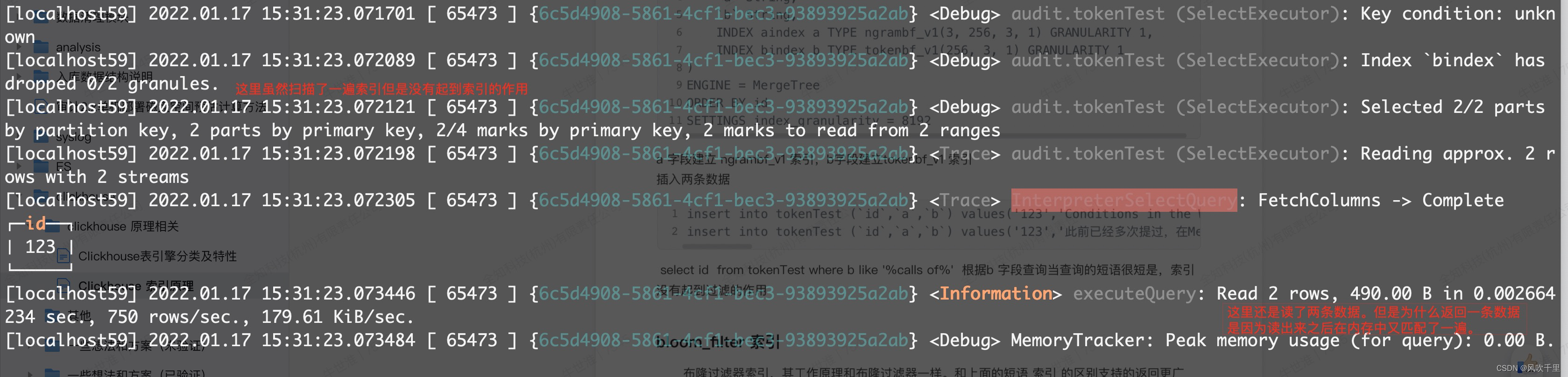
select id from tokenTest where a like '%ins calls of the functions that op%' 如果查询条件的短语很长时,索引过了一条数据
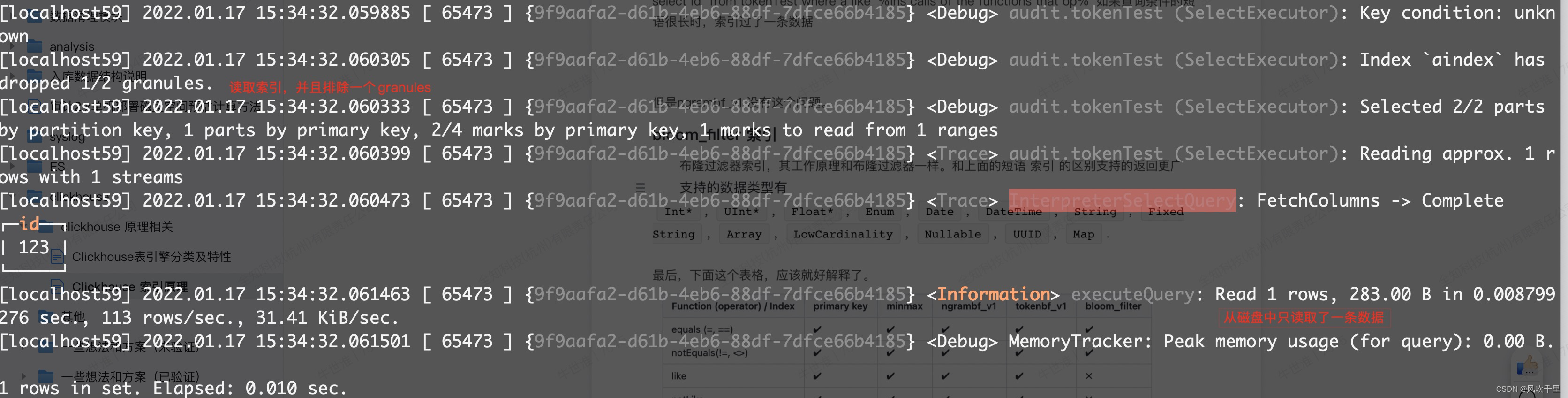
但是ngrambf_v1 没有这个问题。
bloom_filter 索引
布隆过滤器索引,其工作原理和布隆过滤器一样。和上面的短语 索引 的区别支持的返回更广
支持的数据类型有Int*, UInt*, Float*, Enum, Date, DateTime, String, FixedString, Array, LowCardinality, Nullable, UUID, Map.
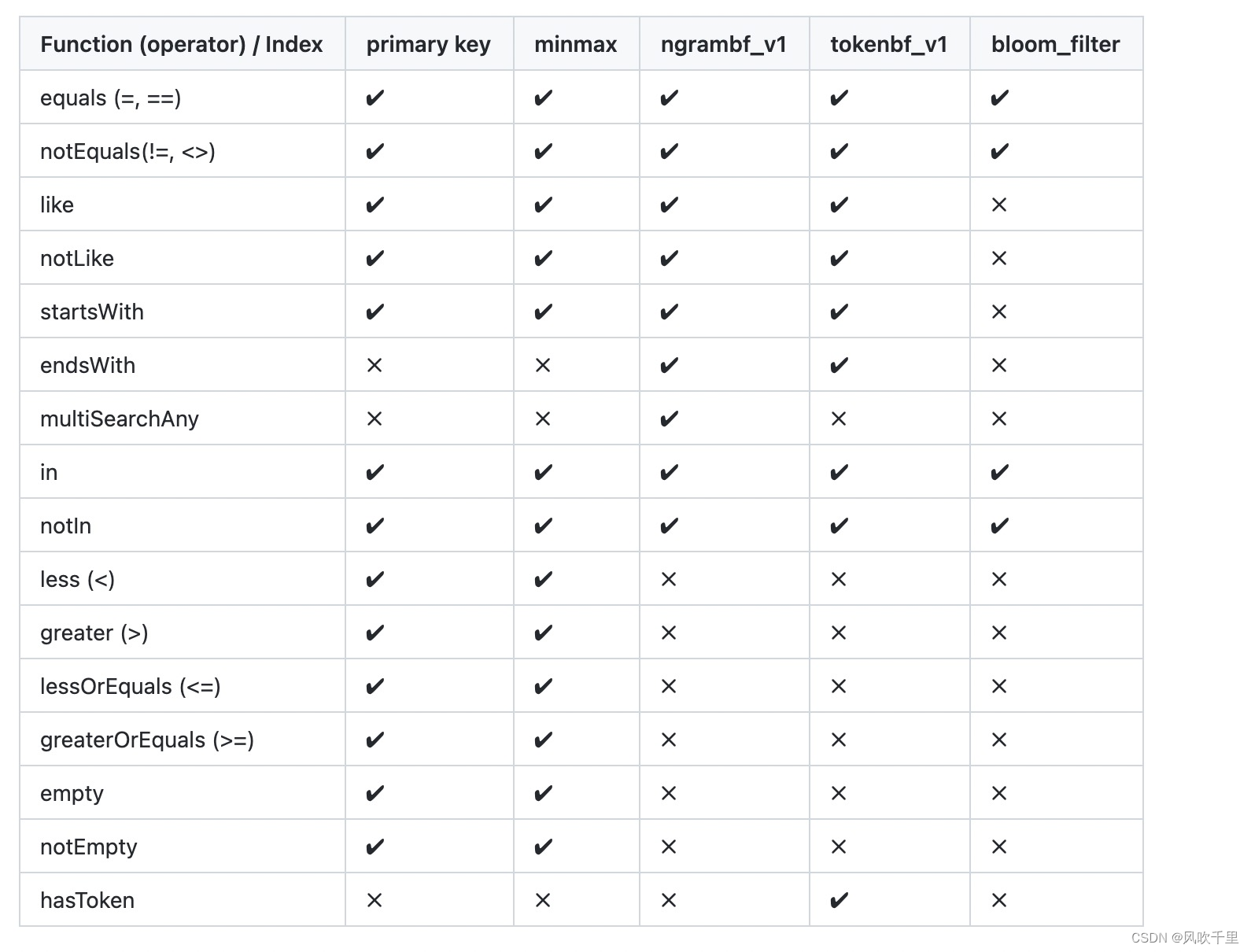
最后,根据常见的场景,索引的使用总计如下。















 5096
5096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









