







Shin W, Song S, Park K, et al. Cardinality Estimation of Subgraph Matching: A Filtering-Sampling Approach[J]. arXiv preprint arXiv:2309.15433, 2023.
文章目录
ABSTRACT
子图计数是理解和分析图结构化数据的一个基本问题,但在计算上具有挑战性。这就需要一种精确而有效的子图基数估计算法,即估计数据图中查询图的所有同构嵌入的数量。我们提出了一种新的FaSTest,一种新的算法,结合(1)强大的滤波技术来显著减少样本空间,(2)自适应树采样算法的准确和有效的估计,(3)最坏的情况最优分层图采样算法。在真实数据集上进行的大量实验表明,FaSTest在精度方面比最先进的基于采样的方法高出两个数量级和基于gnn的方法高出三个数量级。
1 INTRODUCTION
子图匹配是理解和分析图结构化数据[42]的基本问题。给定一个数据图和一个查询图,子图匹配是在数据图中找到查询图的所有同构嵌入的问题。识别特定子图模式的出现对于各种应用程序至关重要,如分析蛋白质-蛋白质相互作用网络[6,36],揭示社交网络[18]中用户交互的模式和趋势,以及优化关系数据库[28]中的查询。子图计数,即嵌入数量的计数问题,在各种应用中也非常重要,如设计图核[43]和理解生物网络[41,56]。
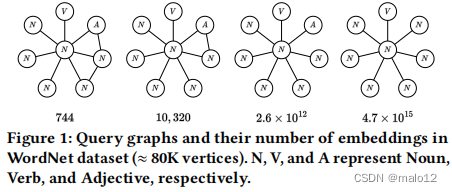
子图匹配和子图计数在计算上都具有挑战性,因为它们是np困难问题[21]。可能的嵌入物的指数级数量进一步放大了这一挑战。例如,图1显示了一些具有8个顶点的查询图,以及WordNet图[49]中每个查询图的嵌入数。嵌入的数量从744到4.7×1015不等,在查询图中只有很小的变化。因此,许多子图匹配算法[5,22-24,27],主要是为了计算嵌入的数量,而不是找到实际的嵌入,通常最多计算𝑘(通常是103到105)的嵌入,而不是计算所有的嵌入。因此,迫切需要一种精确、有效的子图基数估计算法,即估计所有同构嵌入的数量。
现有的方法和限制。子图基数估计由于其在现实世界中的广泛应用而得到了广泛的研究。特别是,小子图(也称为图形或图案)的计数已经得到了广泛的研究。IMPR [11]提出了一种基于随机游走的图形计数方法,而MOTIVO [8]则开发了一种利用颜色编码技术的自适应图形采样算法。然而,这类工作主要集中在小子图上。
近年来,利用图神经网络(GNN)进行子图基数估计引起了人们的关注。LSS [54]和NeurSC [51]已经探索了用于子图基数估计的gnn。然而,它们对于具有大查询的困难实例的准确性仍然不能令人满意。
同态嵌入的近似计数和连接基数的估计也是与子图基数估计密切相关的问题。这些领域的现有工作主要利用基于总结或抽样的方法。一项综合调查[39]表明,采用随机游动进行采样的WonderJoin[30]在计算同态嵌入方面优于其他总结和采样方法。Alley [29]通过提出带有交集的随机漫步来扩展漫步者的加入,以提高精度。尽管这些方法取得了成功,但它们经常遇到采样失败,特别是对于具有复杂标签分布和大型查询[54]的实例。
贡献。在本文中,我们提出了一种新的算法FaSTest(子图基数估计的滤波和采样技术),解决了现有方法的局限性。
我们提出了一种新的基数估计的滤波-采样方法,如下所示。为了逼近一个元素难以枚举或计数的集合的基数,抽样是一种广泛使用的方法。对于查询图𝑞和数据图𝐺,设M表示𝐺中𝑞的所有同构嵌入的集合。采样算法首先定义了一个样本空间Ω,它是M的超集,旨在近似𝜌= |M |/|Ω|的比值。假设(1)获得Ω的基数比M的基数容易,(2) Ω易于随机抽样,(3)可以有效地验证随机样本𝑥∈Ω是否在M中。通过从Ω中获得均匀随机样本,并使用经验比𝜌ˆ,即M中随机样本的比例作为对𝜌的估计量,估计量|Ω|𝜌ˆ是|M |的无偏一致估计量[10]。
我们的方法大大减少了样本空间Ω的大小,同时保留了所有的嵌入(即保持|M |不变)。也就是说,我们通过降低|Ω|来增加𝜌= |M |/|Ω|的比率,这使得采样更准确、更有效。(以往的方法从整个样本空间Ω中提取样本,因此比率𝜌在很多情况下非常小,从而导致采样失败。)
我们建立了一个辅助数据结构候选空间(CS),其中包含顶点映射和边映射的候选空间。通过采用新的安全条件——三角形安全、四循环安全和边二部安全——以及被称为承诺第一候选过滤的细化顺序,与最先进的子图匹配算法[27,46]相比,我们将候选边减少了80%,从而得到一个紧凑的CS。
我们开发了一种候选树采样算法,该算法在紧凑的CS中对查询图的生成树进行均匀采样。我们的树抽样采用自适应策略来确定样本大小使用克洛珀-皮尔逊置信区间,从而实现高效和准确的估计与严格的概率保证。
我们设计了一种分层图采样算法,从样本空间的不同区域获取样本,在小样本量的困难实例上获得了突出的精度。我们的图采样算法为查询图𝑞获得了最坏情况最优时间复杂度𝑂(𝐴𝐺𝑀(𝑞)),这是阿塞拉斯、Grohe和Marx [2,3]提出的|M |的紧上界,保证了即使采样比为100%也具有相同的时间复杂度。
通过在著名的真实数据集上进行的大量实验,我们证明了FaSTest在子图基数估计的精度和效率方面都有了显著的提高。具体来说,FaSTest在精度方面比最先进的基于采样的方法高出两个数量级和基于gnn的方法高出三个数量级。
组织本文的其余部分组织如下。第2节介绍了定义和问题陈述。第3节概述了FaSTest的概述。第4节讨论了候选过滤算法。第5节描述了候选树采样算法。第6节解释了分层图抽样算法。第7节给出了实验结果,第8节总结了论文。
2 PRELIMINARIES
2.1 Problem Statement
在本文中,我们主要考虑带有顶点标记的无向图和连通图,而我们提出的技术可以扩展到有向、不连通图和边标记的图。我们将图𝑔=(𝑉𝑔,𝐸𝑔,𝐿𝑔)定义为一组顶点𝑉𝑔、一组边𝐸𝑔和标记函数𝐿𝑔:𝑉𝑔→Σ的三重联体,其中Σ是一组可能的标签。给定查询图𝑞=(𝑉𝑞,𝐸𝑞,𝐿𝑞)和数据图𝐺=(𝑉𝐺,𝐸𝐺,𝐿𝐺),,当满足三个条件时,一个顶点映射函数𝑀:𝑉𝑞→𝑉𝐺被称为(同构)嵌入: (1)𝑀是内射的,即𝑢=𝑢′∈𝑉𝑞.的.,𝑀(𝑢)=𝑀(𝑢′)(2)𝑀保留了所有邻接关系,即(𝑀(𝑢)∈𝐸𝐺(𝑀(𝑢))∈𝐸𝐺,(3)𝑀保留了所有顶点标签,即每个𝑢∈𝑉𝑞的𝐿𝐺(𝑀(𝑢))=𝐿𝑞(𝑢)。当存在这样的嵌入时,我们说𝑞是与𝐺同构的子图。当一个顶点映射函数只满足(2)和(3)时,我们称之为同态嵌入。
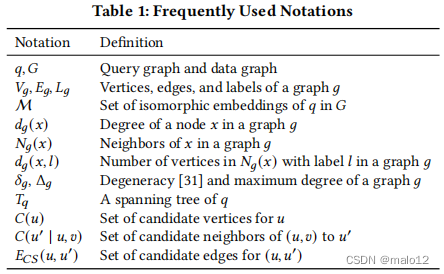
表1列出了本文中经常使用的符号。
子图匹配和计数。对于查询图𝑞和数据图𝐺,设M表示𝐺中𝑞的所有嵌入的集合。子图匹配问题是精确地找到M,而子图计数问题是找到|M |。很明显,所有的子图匹配算法也可以用于计数。子图匹配和子图计数都是np困难问题。
问题声明。给定一个查询图𝑞和一个数据图𝐺,子图基数估计问题是近似|M |,即𝐺中𝑞所有同构嵌入集合的基数。
2.2 Related Works
子图匹配和计数。近十年来,人们提出了许多精确和近似子图匹配和子图计数的解。
基于乌尔曼的回溯框架[48],建立了大量的子图匹配[5,7,16,22,23,27,46]的结果。最近的工作,如[5,22,27,46],共享了过滤器回溯的方法。这些工作首先构建了一个辅助数据结构,如紧凑路径索引(CPI)[5],Bigraph索引(BI)[46]和候选空间(CS)[22,27],利用不同的过滤策略,如使用邻居安全[27]的扩展格图DP。这些算法利用这种数据结构来减少回溯的搜索空间,通过策略选择匹配顺序,进一步加快回溯速度。有兴趣的读者可以参考上述算法[45]的详细调查。
近似的解决方案被分为三个子类:基于摘要、基于抽样的和基于机器学习的方法。摘要方法,如SumRDF [44]和特征集[37],构建了数据图的摘要数据结构。然后,通过查询汇总结构来有效地处理查询图𝑞的估计值,通常是通过将𝑞分解为更小的子结构,如星形,并聚合为每个子结构计算的结果。然而,这些方法可能会产生高度不准确的结果[39]。
采样算法也被广泛应用于子图计数。WanderJoon[30]对关系进行随机游走,并使用霍维茨-汤普森估计,计算每次游走的权重。JSub [55]通过计算中间连接大小的上界,从连接结果中得到独立的均匀样本。Alley [29]提出了带相交的随机游走,并使用了缠结模式指数(TPI),这是一种通过挖掘困难模式获得的摘要结构。
基于机器学习的解决方案,特别是那些利用图神经网络(GNN)的解决方案,最近已经开始出现。像LSS [54]和NeurSC [51]这样的工作已经探索了gnn在子图基数估计方面的潜力。虽然机器学习能够实现高效的查询处理,但这些解决方案并不提供无偏不倚的估计。
计算子图的特殊类。对特殊类的子图基数估计进行了广泛的研究。TETRIS [4]开发了一种在随机游走访问模型下计算三角形的次线性近似算法。图阴影[26]是一种基于图兰定理估计团计数的随机抽样算法。DP颜色路径[53]提出了一种结合贪婪着色的均匀采样算法,该算法也估计了团系的数量。
AGM的界限和最坏情况下的最优性。AGM绑定的[3]是查询图𝑞在数据图𝐺中的嵌入数量的一个紧上界。一种子图匹配或基数估计的算法如果保证了𝑂(𝐴𝐺𝑀(𝑞))时间复杂度[29,34],则称为最坏情况最优算法。SSTE [2]开发了一种边采样算法,用于估计˜𝑂(𝐴𝐺𝑀(𝑞)/𝑂𝑈𝑇(𝑞))时间内任意大小的子图计数,其中𝑂𝑈𝑇(𝑞)指的是嵌入的数量。虽然它提供了强大的理论保证,但它在真实世界的图上的性能并不是令人印象深刻的[12]。
3 OVERVIEW OF ALGORITHM
过滤采样方法。由于决定𝑞是否与𝐺同构的问题是np困难的,精确的枚举或计数在计算上通常是不可行的。为了逼近元素难以枚举或计数的集合M的基数,抽样是一种广泛使用的方法。采样算法首先定义了一个样本空间Ω,它是M的超集,旨在近似𝜌= |M |/|Ω|的比值。
我们的方法大大减少了样本空间Ω的大小,同时保留了所有的嵌入。我们开发了一种过滤算法,通过在寻找所有嵌入时去除不必要的顶点和边来减少样本空间。
过滤。我们建立了一个包含顶点和边的候选空间的辅助数据结构候选空间(CS)。为了构建一个紧凑的CS,我们对每个顶点的𝑢∈𝑉𝑞进行了迭代细化。细化步骤包括检查候选者必须满足的一组必要的安全条件,这使我们能够删除无效的候选者。
通用框架。我们提出了候选过滤的广义框架,其中可以实现不同的条件和细化策略。(第4.1节)
安全条件。我们提出了新的安全条件:三角形安全、四循环安全和边二部安全。这些条件通过更好地利用局部子结构,有效地降低了CS。(第4.2节)
细化顺序。我们建议将承诺的第一候选过滤作为细化顺序,即在每次迭代中,选择一个最有可能被减少的候选集来进行细化。(第4.3节)
我们开发的组合滤波算法在滤波能力方面比[22,27,46]中的要强得多,从而产生了一个紧凑的CS。
取样。我们开发了一种采样算法,利用紧凑的CS来精确和有效的子图基数估计。
候选树采样。我们选择了𝑞的生成tree𝑇𝑞,并将样本空间Ω定义为紧CS中𝑇𝑞的同态集(称为候选树)。我们计算候选树的数量,并随机地对它们进行均匀抽样。(第五节)
分层图采样。我们开发了一种图采样算法来处理在合理的时间内通过树采样获得准确结果的困难情况。我们提出了一种新的抽样方法,灵感来自分层从样本空间的不同区域采样,实现最坏情况最优性。(第6节)
我们的算法FaSTest的大纲如算法1所示。

4 CANDIDATE FILTERING
候选空间(CS)是一种基于高效子图匹配的辅助数据结构,由DAF [22]提出,并由VEQ [27]进行扩展。在这里,我们通过显式地维护候选边来扩展CS的定义,这对于更好的过滤是必要的。
4.1 Candidate Space
定义4.1(候选空间)。对于一个顶点𝑢∈𝑉𝑞及其邻居𝑢‘∈𝑁𝑞(𝑢),我们定义以下术语。
候选集𝐶(𝑢):𝑉𝐺的一个子集,如果在𝐺中存在一个嵌入的𝑞𝑀,将𝑢映射到𝑣,则𝑣必须包含在𝐶(𝑢)中。
候选边𝐸𝐶𝑆(𝑢,𝑢‘):𝐸𝐺的一个子集,如果在𝐺中存在一个嵌入𝑞的𝑀映射𝑢到𝑣,𝑢’到𝑣‘,(𝑣,𝑣’)必须包含在𝐸𝐶𝑆(𝑢,𝑢‘)中。
候选空间是查询图𝑞和数据图𝐺的候选集和候选边的集合。
通过显式地维护候选边,我们可以从候选边中删除一条边(𝑣,𝑣‘),如果它不属于任何嵌入,即使顶点𝑣和𝑣’仍然保留在候选空间中。
对于𝑣∈𝐶(𝑢)和𝑢‘∈𝑁𝑞(𝑢),我们将(𝑢,𝑣)到𝑢’的候选邻居定义为𝑢映射到𝑣时𝑢‘的候选顶点,即𝐶(𝑢’|𝑢,𝑣)={𝑣‘|(𝑣,𝑣’)∈𝐸𝐶𝑆(𝑢,𝑢‘)}。
我们构建初始CS如下。对于每个顶点𝑢,初始候选集𝐶𝑖𝑛𝑖𝑡(𝑢)被定义为具有以下两个条件的顶点𝑣∈𝑉𝐺集: (1)𝑣与𝑢具有相同的标签;(2)对于每个标签𝑙∈Σ,𝑑𝐺(𝑣,𝑙)≥𝑑𝑞(𝑢,𝑙).我们将候选边初始化为𝐸𝐶𝑆(𝑢,𝑢‘)={(𝑣,𝑣’)∈𝐸𝐺|𝑣∈𝐶(𝑢)和𝑣‘∈𝐶(𝑢’)}。初始候选空间可以在𝑂(|𝐸𝑞||𝐸𝐺|)时间内构造。
例子4.2。图2描述了初始CS给定的查询图𝑞和数据图𝐺的一个示例。在具有匹配标签的顶点对中,𝑣6不属于𝐶(𝑢1),因为𝑑𝐺(𝑣6,𝐶)<𝑑𝑞(𝑢1,𝐶)。其他的缺席也可以类似地看到。在CS中,𝐶(𝑢4|𝑢1,𝑣1),𝑢4的(𝑢1,𝑣1)的候选邻居,是{𝑣2,𝑣7},因为它们是𝐶(𝑢4)中的𝑣1的邻居。
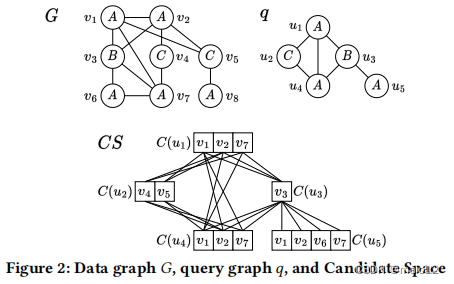
根据定义,𝐺中𝑞的所有嵌入都保留在CS中,因为构成嵌入的所有可能的顶点和边都存在。我们称CS的这个属性为完整的。在我们稍后将要描述的采样算法中,减小候选空间的大小将转化为更小的样本空间。因此,关键是在保持完整性的同时尽可能多地细化候选空间。请注意,在最坏的情况下,CS可以包含𝑂(|𝑉𝑞||𝑉𝐺|)顶点和𝑂(|𝐸𝑞||𝐸𝐺|)边。
通用过滤框架。我们从初始的CS开始进行细化。对于预定义的安全条件集,通用过滤框架可以定义为算法2。该框架由几个设计选择组成;一组确定候选顶点或边的有效性的安全条件,一种确定细化顺序的方法,即细化候选集的查询顶点的顺序,以及我们完成细化的停止标准。

4.2 Safety Conditions
𝐶(𝑢‘|𝑢,𝑣)是非空的,因此𝑣必须成为𝑢的每个邻居𝑢’的𝑢候选对象。结合此条件,VEQ [27]建议使用安全条件,可以进一步过滤无效的候选人。对于任何必要条件ℎ(𝑢,𝑣)必须满足的𝑀(𝑢)=𝑣,在任何步骤中,当ℎ(𝑢,𝑣)为错误时,我们可以从𝐶(𝑢)中删除候选顶点𝑣。VEQ考虑了ℎ的邻居安全,如果它缺少足够的候选邻居,它可以过滤候选顶点。GQL [25]和VC [46]采用了一个较强的二部匹配条件。
由于我们显式地保持候选边,对于嵌入𝑀的𝑀(𝑢)=𝑣和𝑀(𝑢‘)=𝑣’,必须满足的任何必要条件𝑔(𝑢,𝑢‘),(𝑣,𝑣’)都可以用来去除无效的候选边。
在本文中,我们提出了新的安全条件,以实现更强的过滤。我们提出了考虑循环子结构的三角安全和四循环安全。我们将VC [46]提出的ESIC条件扩展到边二部安全,在保持相同时间复杂度的同时增加了滤波能力。
三角安全。[5,22,27]中的细化方法完全忽略了循环子结构,尽管我们经常在子图匹配或计数问题的实际用例中对具有多个循环的密集的查询感兴趣。虽然寻找所有周期本身就是一个np困难问题,但使用小循环可以大大提高滤波能力。
定义4.3。对于一条边(𝑎,𝑏)∈𝐸𝑔,我们将𝐿𝑔3(𝑎,𝑏)定义为顶点𝑐∈𝑉𝑔的集合,这样(𝑎,𝑏),(𝑏,𝑐),(𝑐,𝑎)∈𝐸𝑔,也就是说,它们用给定的边形成一个三角形。
我们将条件三角形安全定义如下。
定义4.4。一个查询边(𝑢,𝑢‘)的数据边(𝑣,𝑣’)是三角形安全时
- |𝐿3𝑞(𝑢,𝑢‘)|≤|𝐿3𝐺(𝑣,𝑣’)|,和
- 对于每个𝑢∗∈𝐿3𝑞(𝑢,𝑢′),,存在由有效顶点和边组成的𝑣∗∈𝐿3𝐺(𝑣,𝑣′),即对于每个𝑢∗,,存在𝑣∗∈𝐶(𝑢∗|𝑢,𝑣)∩𝐶(𝑢∗|𝑢′,𝑣′).
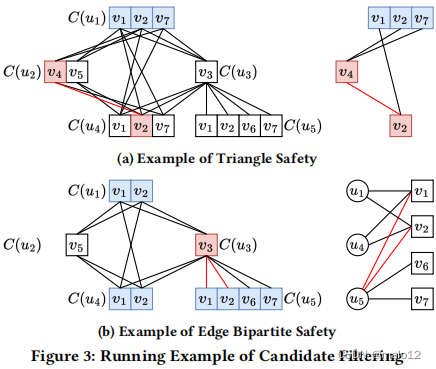
例子4.5。图3a显示了三角形安全细化的示例。考虑到查询边(𝑢2,𝑢4)和数据边(𝑣4,𝑣2),三角形安全评估边安全条件,其中查询三角形(𝑢2,𝑢4,𝑢1)可以与CS中的有效三角形匹配的条件。由于𝐶(𝑢1|𝑢2,𝑣4)∩𝐶(𝑢1|𝑢4,𝑣2)为空,因此通过定义4.4删除了(𝑢2,𝑢4)的候选边(𝑣4,𝑣2)。由于(𝑣4,𝑣7)for(𝑢2,𝑢4)也被三角形安全删除,𝐶(𝑢4|𝑢2,𝑣4)变为空,因此𝑣4可以从𝐶(𝑢2)中删除。
四环的安全。我们进一步将𝐿𝑔4(𝑎,𝑏)定义为边集(𝑐,𝑑)∈𝐸𝑔,这样(𝑎,𝑏),(𝑏,𝑐),(𝑐,𝑑),(𝑑,𝑎)∈𝐸𝑔,即,它们与给定的边形成一个4个循环。使用𝐿𝑔4(𝑎,𝑏),我们引入了类似于三角形安全的条件“四循环安全”,为困难的实例提供了额外的过滤。
为了计算三角形安全和四循环安全,我们提前对所有三角形和四循环进行了索引。当数据图中的三角形和4个周期的数量非常可观时,对它们进行索引可能会导致显著的开销。因此,如果三角形和4个循环的数量分别超过一些常数𝑘1和𝑘2,我们将禁用各自的安全条件,以避免过多的计算成本。在实验中,我们使用了𝑘1=𝑘2=1010。
边二部安全。为了开发一个更强的安全条件,GQL [25]和VC [46]提出对𝑣∈𝐶(𝑢,𝑣)的候选邻居使用二部图𝐵,𝑢,𝑢∈𝑉𝑞。𝐵(𝑢,𝑣)由左顶点𝑉𝐿=𝑁𝑞(𝑢)和右顶点𝑉𝑅=𝑁𝐺(𝑣)组成。中的“边”当且仅当𝑣‘∈𝐶(𝑢’|𝑢,𝑣),即,在𝑣∈𝐶(𝑢)和𝑣‘∈𝐶(𝑢’)之间连接𝑢‘和𝑣’。
例子4.6。图3b描述了𝐶(𝑢3)细化过程中的𝐵(𝑢3,𝑣3),给出了图2中的查询图和数据图,以及左侧的CS。查询图中𝑢3的邻域𝑢1,𝑢4,𝑢5成为𝐵(𝑢3,𝑣3),的左顶点𝑉𝐿,数据图中𝑣3的邻域𝑣1,𝑣2,𝑣6,𝑣7成为右顶点𝑉𝑅。
然后可以很容易地观察到,对于𝑣是𝑢的有效候选对象,𝐵(𝑢,𝑣)应该有一个二部匹配,其大小等于左顶点的集合。我们可以利用𝐵(𝑢,𝑣)[20]算法确定𝑂(𝑑𝑞(𝑢)2𝑑𝐺(𝑣)时间(𝑣)是否有这样的二部匹配,因为最多有𝑑𝑞(𝑢)𝑑𝐺(𝑣)边,最大匹配的大小最多为𝑑𝑞(𝑢)。
我们进一步将二部图的应用扩展到候选边的细粒度滤波。给定二部图𝐵(𝑢,𝑣),大小为𝑑𝑞(𝑢)的最大二部匹配的存在并不能保证对于每条边都存在一个包含该边的最大匹配。
定义4.7。如果一条边包含在某个最大匹配中,那么它就被称为最大匹配的边。
当一条边(𝑢‘,𝑣’)∈𝐸𝐵(𝑢,𝑣)不能最大匹配时,𝑣‘应该从𝐶(𝑢’|𝑢,𝑣)中删除。对于二部图,当最大匹配为[47]时,可以在线性时间内找到所有最大匹配的边。因此,在我们找到𝐵(𝑢,𝑣)上的最大双部分匹配后,我们验证了每条边是否具有最大的匹配性。这需要𝑂(𝑑𝑞(𝑢)𝑑𝐺(𝑣))时间,与找到最大二部匹配相比是可以忽略的。
例子4.8。在图3b中所示的𝐵(𝑢3,𝑣3)中,可以找到一个大小为3的最大匹配值{(𝑢1,𝑣1),(𝑢4,𝑣2),(𝑢5,𝑣6)},因此𝑣3是𝑢3的有效候选对象。然而,由于没有包括边(𝑢5,𝑣1)或(𝑢5,𝑣2)在内的最大匹配,因此这些边并不是最大匹配的。因此,𝑣1和𝑣2被从𝐶(𝑢5|𝑢3,𝑣3)中删除。
4.3 Promising-First Candidate Filtering
细化优先级。在每个细化步骤中,我们选择一个要进行细化的查询顶点(算法2,第2行)。设𝐶𝑡(𝑢)为第𝑡个细化步骤完成后的𝑢的候选集,其中𝐶0(𝑢)表示初始CS中的候选集。让𝑢1,𝑢2,……,𝑢𝑡是已经被细化的顶点序列,当前的细化步骤是𝑡+1。
作为𝑢𝑡+1,我们选择查询顶点𝑢,使𝑢具有最低的𝑝𝑒𝑛𝑎𝑙𝑡𝑦𝑡(𝑢)(即最有希望的),定义为
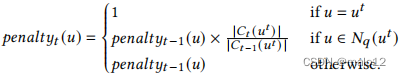
对于[0,1]中的某个常数𝜙,我们给所有顶点分配一个𝑝𝑒𝑛𝑎𝑙𝑡𝑦0(𝑢)=𝜙的初始惩罚。在精炼𝑢𝑡后,𝑝𝑒𝑛𝑎𝑙𝑡𝑦𝑡(𝑢𝑡)增加到1。对于𝑢∈𝑁𝑞(𝑢𝑡),我们通过乘以|𝐶𝑡(𝑢𝑡)|/|𝐶𝑡−1(𝑢𝑡)|(𝐶(𝑢𝑡)减少的比率)来减少𝑝𝑒𝑛𝑎𝑙𝑡𝑦𝑡(𝑢),因为当𝐶(𝑢𝑡)的大小减小时,𝐶(𝑢)的大小也可能减小。如果𝑢既不是𝑢𝑡本身,也不是𝑢𝑡的邻居,那么它的惩罚将保持不变。请注意,惩罚总是在[0,1]的范围内。
例子4.9。对于给定的𝑞和初始的CS(图2),图3描述了过滤过程。𝑉𝑞中的每个顶点的初始惩罚为2/3。在顶点中,我们任意地打破联系。在图3a中,我们选择了𝑢2来进行细化。随着三角形安全过滤能力的增强,𝑣4从𝐶(𝑢2)中删除,将𝑢1和𝑢4的惩罚减少到1/3(乘以1/2,𝐶(𝑢2)减少的比率),并将𝑢2的惩罚重置为1。𝑢3和𝑢5的处罚保持不变,因为它们不在𝑁𝑞(𝑢2)中。
停止标准。我们根据经验观察到,改进的效果在经过一些迭代后就会停滞。因此,我们为细化定义了两个停止标准,并在这两个条件中的任何一个触发时停止。
(1)当查询顶点之间的最小惩罚高于某些预定义的常量𝜏时。这明确地指导算法在进一步改进的效果很小且不值得开销时停止。
(2)对于某些预定义的常数𝑅,当被细化选择的顶点的度之和,包括重复选择,高于𝑅|𝐸𝑞|。该准则对于约束最坏情况的复杂度是必要的,并实际指导算法在细化时间过长时停止。
定理4.10。根据规定的停止标准,各种安全条件会导致过滤的以下时间复杂度界限。
•边二部安全:𝑂(|𝐸𝑞||𝐸𝐺|Δ𝑞)时间
•三角安全:𝑂(|𝐸𝑞||𝐸𝐺|Δ𝑞𝛿𝐺)时间
•四环安全:𝑂(|𝐸𝑞||𝐸𝐺|Δ 2𝑞Δ𝐺𝛿𝐺)时间
证明。让选择要细化的查询顶点序列为𝑠=(𝑢𝑘),𝑢𝑘∈𝑉𝑞。第二个停止标准确保了I𝑢∈𝑠𝑑𝑞(𝑢)≤𝑅|𝐸𝑞|。对于每个𝑢∈𝑉𝑞,候选集𝐶(𝑢)是𝑉𝐺的一个子集。因此,为了边缘二部图的安全,我们有:𝑢∑∈𝑠𝑣∈∑𝐶(𝑢)𝑑𝑞(𝑢)2𝑑𝐺(𝑣)≤Δ𝑞𝑢∑∈𝑠𝑑𝑞(𝑢)|𝐸𝐺|≤𝑅|𝐸𝑞||𝐸𝐺|Δ𝑞.
由于𝑅是一个常数,因此其简化为𝑂(|𝐸𝑞||𝐸𝐺|Δ𝑞)。三角形和四环安全的结果见附录。□根据经验,我们选择了𝜏= 0.9和𝑅=5进行实验。我们观察到,大多数的运行都被第一个标准(惩罚)停止了。
5 CANDIDATE TREE SAMPLING
我们提出了一种采样算法来选择候选空间内的树。虽然已经有针对类似问题的相关工作使用树采样,如连接基数估计[55],但这些算法可能面临准确性和效率方面的挑战,因为树的数量比实际嵌入的数量大得多。相比之下,我们的算法极大地受益于高效的候选空间,它使我们能够过滤出许多不能扩展到嵌入的树。
我们的算法会策略性地选择查询图的生成树来最小化样本空间。我们证明了我们的方法在一个附加的假设下是最优的,并且即使在不满足该假设的情况下,它在实践中也表现得非常好。此外,我们在采样过程中自适应地确定样本量,以提供一个概率界。在大多数情况下,我们的算法以相当小的样本量实现了边界,确保了在实践中的准确性和效率。
5.1 Candidate Trees
定义5.1(候选树)。设𝑇是𝑞的一个子图,它是一个有根于𝑢𝑟∈𝑉𝑇的树。我们将𝑇的候选树定义为一个顶点映射𝑠:𝑉𝑇→𝑉𝐺,
这样对于𝑇,𝑠(𝑢𝑟)∈𝐶(𝑢𝑟),的根节点𝑢𝑟和一个节点𝑥及其父节点𝑝∈𝑉𝑇,𝑠(𝑥)∈𝐶(𝑥|𝑝,𝑠(𝑝)).我们注意到一个候选树可以看作是紧CS中𝑇的同态。
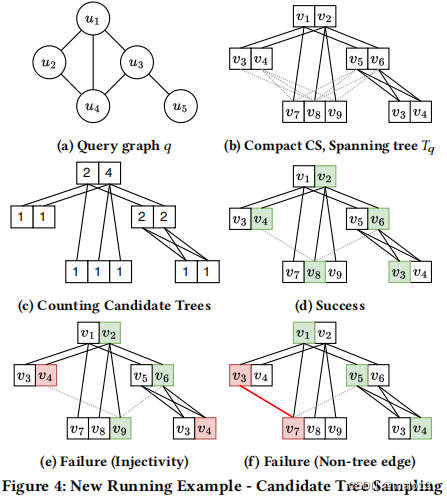
例子5.2。在图4中,对于给定的𝑞和紧凑的CS,我们首先通过删除(𝑢2,𝑢4)和(𝑢3,𝑢4)边来构建𝑞的生成树𝑇𝑞。映射{(𝑢1,𝑣1),(𝑢2,𝑣3),(𝑢3,𝑣5),(𝑢4,𝑣7),(𝑢5,𝑣3})是一个候选树for𝑇𝑞。请注意,候选树并不一定是一个内射映射。
设𝑇𝑞为𝑞的任意生成树。当需要时,我们把𝑇𝑞看作是一个有向图,边的方向从根分配到叶。如果𝑡的顶点映射与嵌入的顶点映射𝑀相同,那么我们假设候选树𝑡是嵌入的对应物。由于CS是完整的,𝑇𝑞的候选树集包含了𝑞嵌入的对应物。因此,我们选择一个生成树𝑇𝑞,并使用紧凑CS中𝑇𝑞的候选树集作为样本空间Ω。我们开发了一种算法来执行使用动态规划的精确计数,并从Ω均匀随机抽样候选树。
我们注意到,如果将候选树的定义扩展到只允许内射映射,那么样本空间可以进一步减少。然而,这种扩展是不可行的,因为同构嵌入的精确计数对于树查询[33]是np困难的。
5.2 Sampling Candidate Trees
选择生成树。最好选择生成树𝑇𝑞,最小的候选树数量减少样本空间的大小。然而,通过生成所有可能的生成树和计算候选树的数量来精确的最小化是不可行的,因为𝑞的生成树的数量可以超指数地很大。
因此,我们引入了一种密度启发式方法来寻找具有少量候选树的生成树,而不是精确的最小化。由于候选树的数量通常会随着候选边数量的增加而增加,因此使用具有密集候选边的查询边是不可取的。为了避免这种情况,我们将边(𝑢,𝑢‘)∈𝐸𝑞的权重分配为
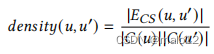
并通过Prim算法[40]找到一个使密度对数的和最小化的生成树,它相当于最小化所选边的密度的乘积。
这种策略最小化密度的产品密度是最优的假设:对于所有(𝑣𝑣)∈𝐶(𝑢)×𝐶(𝑢),事件边缘(𝑣𝑣)是一个候选人(𝑢𝑢)概率𝑑𝑒𝑛𝑠𝑖𝑡𝑦(𝑢𝑢),它是独立于事件,其他顶点对候选人的边缘。
定理5.3。在上述假设下,通过密度启发式使候选树的期望数量最小化。我们在第7.4节中演示,我们的策略优于其他直观上吸引人的替代方案。
正在计数候选树。我们开发了一个动态规划算法来获得一个给定的𝑇𝑞的候选树的精确计数。设𝑇𝑢是𝑇𝑞基于𝑢∈𝑉𝑞的子树,而𝐷(𝑢,𝑣)是𝑢映射到𝑣的𝑇𝑢候选树的数量。候选树的总数for𝑇𝑢可以被计算为I𝑣∈𝐶(𝑢)𝐷(𝑢,𝑣)。
对于一个叶节点𝑢∈𝑉𝑞and𝑣∈𝐶(𝑢),很明显,𝐷(𝑢,𝑣)=1。对于非叶节点𝑢∈𝑉𝑞and𝑣∈𝐶(𝑢),𝑇𝑢的候选树由𝑢的每个子𝑢𝑐的𝑇𝑢𝑐候选树组成,每个𝑢𝑐的候选树从𝐶(𝑢𝑐|𝑢,𝑣)中选择。因此,我们有了
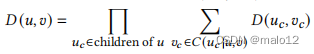
它可以用𝑂(|𝐸𝑞||𝐸𝐺|)时间来计算,采用一种类似于JSub [55]和DAF [22]的自底而上的动态规划方法。
候选树的均匀抽样。基于上述计算的候选树计数,我们开发了一个采样算法,均匀随机返回每个候选树。设𝑠表示𝑇𝑞的样本候选树。回想一下,候选树被定义为一个顶点映射。对于根顶点𝑢𝑟,我们从𝐶(𝑢𝑟)中采样𝑣,其权重与𝐷(𝑢𝑟,𝑣)成正比。对于𝑢=𝑢𝑟,让𝑢𝑝是𝑇𝑞中的𝑢的父级。给定𝑣𝑝=𝑠(𝑢𝑝),我们用BFS遍历𝑇𝑞迭代采样𝑢的𝑠(𝑢)。我们从候选邻居𝐶(𝑢|𝑢𝑝,𝑣𝑝)中选择𝑠(𝑢),其权重与𝐷(𝑢,𝑣)成正比。算法的详细实现见算法4。

例子5.4。图4展示了候选树的计数和采样过程。对于查询图𝑞,紧凑的CS构建如图4b所示。边缘(𝑢2,𝑢4)和(𝑢3,𝑢4)不包括在获得𝑇𝑞之中,因为它们的密度较大,为2/3。图4c显示了在计数候选树后得到的𝐷(𝑢,𝑣)的值。
对于抽样,我们首先为𝑣1和𝑣2分别选择一个权重为2: 4的根。例如,在图4d中,当选择𝑣2时,𝑣4和𝑣6分别是𝑢2和𝑢3的(𝑢1,𝑣2)的唯一候选邻居,因此它们的采样概率为1。对于𝑢4,我们从𝐶(𝑢4|𝑢1,𝑣2)中抽取一个随机样本。类似地,𝑠(𝑢5)是在𝐶(𝑢5|𝑢3,𝑣6)中被选择。由于图4d中的结果映射是内射的,所以我们检查非树形边(𝑢2,𝑢4)和(𝑢3,𝑢4)是否有效。由于(𝑣4,𝑣8)和(𝑣6,𝑣8)都在候选边缘中,所以图4d是成功的。
当为𝑢2和𝑢5选择𝑣4时(图4e),得到的示例是一个失败的实例,因为映射不是内射的。如果𝑠(𝑢2)=𝑣3 and𝑠(𝑢4)=𝑣7,则查询边的候选对象(𝑢2,𝑢4)为(𝑣3,𝑣7)。然而,𝑣7∈𝐶(𝑢4|𝑢2,𝑣3),因此图4f中的实例也是一个失败的例子。由于在3棵树中发现了一个成功,并且有6个候选树,所以我们返回2个作为估计值。实际上有两个嵌入体(𝑣2,𝑣4,𝑣6,𝑣8,𝑣3)和(𝑣2,𝑣4,𝑣6,𝑣9,𝑣3)。
定理5.5(均匀抽样)。算法4返回𝑇𝑞的每个候选树的概率是一致的。样本大小。如果我们进行#𝑡试验并获得#𝑠成功,则样本成功率𝜌ˆ=#𝑠/#𝑡是对真实比例𝜌的估计。设𝛼表示可接受的失效概率,𝑐表示可容忍的相对误差。为了实现概率保证P𝑐−1𝜌≤𝜌ˆ≤𝑐𝜌≥1−𝛼,,我们使用了克珀-皮尔逊区间[9,15],即区间(𝐿𝛼(#𝑡,#𝑠),𝑈𝛼(#𝑡,#𝑠))
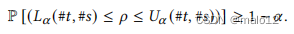
我们通过抽样来自适应地确定样本量,直到满足𝑐−1𝜌ˆ≤𝐿𝛼(#𝑡,#𝑠)和𝑈𝛼(#𝑡,#𝑠)≤𝑐ˆ𝜌为止,这导致我们能够:
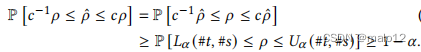
附录中提供了选择克隆皮尔逊区间而不是标准区间、威尔逊评分区间和切尔诺夫界[9,12,13,52]的详细比较和基本原理。在我们的实验中,我们有1000-1000,000次试验,我们发现,无论试验次数如何,88次成功足以满足𝛼= 0.05和𝑐= 1.25的克隆皮尔逊区间(公式4)所述的条件。
对于实现该条件可能需要不合理的计算量的困难情况,我们立即终止树采样,并使用第6节中描述的图采样。对于实验,如果5万次试验的成功不超过10次,我们就停止。由于需要88次成功才能满足规定的条件,并且只有在前5万次试验中至少有11次成功时,我们才会继续进行树抽样,因此我们预计树抽样的试验次数不会超过40万。定理5.6。算法4是子图基数的一个无偏的、一致的估计量。
6 STRATIFIED GRAPH SAMPLING
虽然所提出的树采样算法在大多数情况下给出了准确和有效的估计,但也有一些困难的情况下,即使在过滤后,采样空间仍然比嵌入的数量很大。这是由于候选树的数量可以渐近大于𝐴𝐺𝑀(𝑞),这是嵌入数量[2]的一个紧上界。
为了解决这一问题,我们开发了一个包含以下成分的分层图采样算法。(1)在采样阶段,我们同时考虑非树边,这确保了样本空间的大小受到𝑂(𝐴𝐺𝑀(𝑞))的限制。(2)我们提出分层抽样,从样本空间内的不同区域选择样本。通过结合这两个组件,我们的算法实现了较高的精度和效率,特别是在困难的情况下。
6.1 Extendable Candidates
当顶点映射𝑀嵌入为𝑞到𝐺时,我们将其诱导子图𝑞‘定义为部分嵌入。给定部分嵌入𝑀,如果存在𝑢‘∈𝑁𝑞(𝑢),则𝑢’∈𝑉𝑞(𝑉𝑞‘,则𝑢’∈𝑉𝑞‘是一个可扩展的顶点𝑢’∈𝑉𝑞‘。我们定义关于部分嵌入𝑀的可扩展候选集合如下:
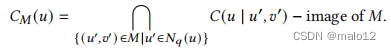
其中,𝑀的图像是由𝑀映射的数据图的顶点,即{𝑣∈𝑉𝐺|∃𝑢∈𝑉𝑞‘,即𝑀(𝑢)=𝑣}。当𝑀=∅时,𝐶𝑀(𝑢)被设置为𝐶(𝑢)。𝐶𝑀(𝑢)是由𝑢的每个邻域𝑢‘的候选邻域集的多路集交集计算的。为了保持注入性,已经被𝑀映射的候选顶点将被删除,即from𝐶𝑀(𝑢)。For𝑣∈𝐶𝑀(𝑢),𝑀∪{(𝑢,𝑣)}形成了一个部分嵌入,因为𝑀∪{(𝑢,𝑣)}是一个具有顶点集𝑉𝑞′∪{𝑢}的𝑞诱导子图到𝐺的嵌入。
例如,在图4b中,当𝑀={(𝑢1,𝑣2),(𝑢2,𝑣4)},𝑢4是一个可扩展顶点,可扩展候选顶点𝐶𝑀(𝑢4)={𝑣8,𝑣9},因为它们是𝐶(𝑢4)中的顶点,是(𝑢1,𝑣2)和(𝑢2,𝑣4)的候选邻居。
6.2 Stratified Graph Sampling
如果部分嵌入包含𝑀作为子集,我们说部分嵌入扩展了𝑀。设𝑤𝑀表示𝑞到𝐺的嵌入数,扩展了部分嵌入𝑀。很明显,当|𝑀|=|𝑉𝑞|时,𝑤𝑀=1,当𝐶𝑀(𝑢)=∅时,𝑤𝑀=0。对于其他情况,我们采用分层抽样的方法来获得𝑤𝑀的无偏一致估计量。
分层采样分层是一种在抽样前将种群划分为多个互斥且共同详尽的亚种群的策略,即地层,以确保结果样本[32]的多样性。在我们的例子中,为了估计𝑤𝑀,总体是扩展𝑀的部分嵌入的集合。对于𝑀的可扩展顶点𝑢和𝑀的候选𝐶𝑀(𝑢),可以将种群分层为部分嵌入的亚种群(称为组),为每个𝑣∈𝐶𝑀(𝑢)扩展𝑀∪{(𝑢,𝑣)}。设ˆ𝑤𝑀为𝑤𝑀的估计值。根据定义,
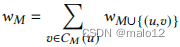
因此,通过从𝐶𝑀(𝑢)中选取一个候选对象的随机子集𝑆,并估计𝑣∈𝑆的𝑤𝑀∪{(𝑢,𝑣)}的值,我们得到了𝑤𝑀的一个无偏估计量。形式上,考虑𝐶𝑀(𝑢)的一个随机子集𝑆,其中每个𝑣∈𝐶𝑀(𝑢)被包含在𝑆中的概率是一致的,即|𝑆|/|𝐶𝑀(𝑢)|。我们将ˆ𝑤𝑀定义为
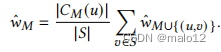
如果是|𝑀|=|𝑉𝑞|,则ˆ𝑤𝑀设置为1,如果是𝐶𝑀(𝑢)=∅,则ˆ𝑤𝑀设置为0。每个ˆ𝑤𝑀∪(𝑢,𝑣)都是递归计算的。在算法5中给出了该算法的伪代码。

取样顺序。在每一步中,我们选择一个可扩展顶点𝑢∈𝑉𝑞,并给定部分嵌入𝑀计算可扩展候选𝐶𝑀(𝑢)。为了选择可扩展候选顶点数量尽可能少的可扩展顶点,我们选择了在每一步中不在𝑀中且在𝑀中邻居数量最多的顶点𝑢。首先,我们选择|𝐶(𝑢)|最小的顶点。我们注意到,对于给定的𝑞和紧的CS,可扩展顶点的顺序是确定性的。
自适应分配。通过对某些常数𝑘进行|𝑆|=|𝐶𝑀(𝑢)|/𝑘来检查每个递归步骤中固定比例的可扩展候选对象,可能会得到指数级大量的样本。为了避免这个问题,我们限制了用于估计每个𝑀的𝑤𝑀的最大样本数量为𝑢𝑏𝑀。我们选择子集𝑆是一个大小为最小的随机子集(|𝐶𝑀(𝑢)|/𝑘,𝑢𝑏𝑀)(算法5,第10行)。𝑢𝑏∅的值是根据查询的难度来确定的,进一步的细节将在后面讨论。然后,我们为每个𝑣∈𝑆设置上界𝑢𝑏𝑀∪{(𝑢,𝑣)},使上界的和不超过𝑢𝑏𝑀。
对于第一个𝑣∈𝑆,我们分配了𝑢𝑏𝑀∪{(𝑢,𝑣)}=𝑢𝑏𝑀|𝑆|。对𝑀∪{(𝑢,𝑣)}的递归调用返回𝑤𝑀∪{(𝑢,𝑣)}的估计值以及整个递归过程中获取的实际样本数量。𝑀上的递归可能在样本数量达到𝑢𝑏𝑀之前终止(例如,如果|𝑀|=|𝑉𝑞|或𝐶𝑀(𝑢)=∅,无论𝑢𝑏𝑀有多大,都只遇到一个样本)。在这种情况下,我们可以自适应地增加后续调用的样本量,以提高总体准确性。的上限第𝑖-𝑣∈𝑆被确定为剩余的上界(即,𝑢𝑏𝑀减去从第一个到(𝑖−1)-th)的样本数)除以剩余的调用数(|𝑆|−𝑖+ 1),如第15行所示。由于这只能增加𝑢𝑏𝑀/|𝑆|的上界,我们确保每个𝑀∪{(𝑢,𝑣)}至少接收到𝑢𝑏𝑀/|𝑆|的上界,从而即使在样本量有限的情况下也能获得不同的样本。
例子6.1。图5描述了一个使用𝑢𝑏𝑀= 300的示例。For𝐶𝑀(𝑢2)={𝑣2,𝑣3,𝑣4},假定𝑆={𝑣2,𝑣3}是随机选择的子集。对于带有𝑣2的组,上限𝑢𝑏𝑀∪{(𝑢2,𝑣2)}被设置为150,因为𝑢𝑏𝑀预计将分为两组。假设第一组返回的估计数为12,使用了120个样本。第二组的上界被确定为180,因为只使用了120个样本。假设该组返回了20个样本,其中使用了150个样本。汇总结果,𝑣1的初始调用返回16(两个子调用返回的估计的平均值),并报告实际使用了270个样本。
定理6.2。算法5是子图基数的无偏一致估计量,最坏情况下的时间复杂度以𝑂(𝐴𝐺𝑀(𝑞))为界。
样本大小。为了准确性,在困难的实例上使用更多的样本,在更容易的实例上使用小样本来有效估计。然而,测量困难本身是具有挑战性的,因为它取决于嵌入的数量和样本空间的大小之间的比率。
查询大小在以前的图同态计数工作中经常使用,因为在一般的[29,39]中,一个更大的查询需要更多的样本。根据经验,虽然实例的难度随着查询大小的增加而增加,但数据图的大小似乎并没有很强的相关性。由于我们只在树抽样经过一定数量的样本后没有找到足够的成功时进行图抽样,因此树抽样的成功数量可以作为实例难度的代理度量。因此,当从树的抽样中获得的成功的次数较小时,我们取较大的𝑢𝑏∅。然而,这种关联在经验上不是线性的,因此我们取成功次数的平方根,将𝑢𝑏∅设为
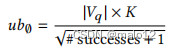
对于一些常数的𝐾。使用𝐾= 100,000,我们在不同统计数据的数据集上实现了合理的准确性。
7 PERFORMANCE EVALUATION
7.1 Experimental Setup
通过回答以下问题,我们进行了实验来评估我们的算法FaSTest的性能。
精度与最先进的竞争对手相比,FaSTest在各种真实世界的数据集和具有不同特征的困难查询实例上有多准确?(第7.2节)
效率。与最先进的竞争对手相比,FaSTest的效率如何?(第7.3节)
技术评估(第7.4节)
筛选方法。我们提出的滤波方法在减少样本空间方面的有效性和效率如何?
密度启发式启发式找到一个生成树。鉴于紧凑的CS,我们的密度𝑇𝑞可以与更少的候选树吗?
我们主要将我们的算法与Alley [29]进行比较,因为它显著优于基于提要的算法和基于采样的算法,如特征集[37]、SumRDF [44]、相关采样[50]、JSub [55]和WanderJoin [30]。由于Alley最初是用于估计同态嵌入的数量,所以我们将其修改为同构嵌入。我们列出了Alley的变体,我们比较如下。
Alley:我们修改了Alley,以便对于每个随机游走抽样,额外检查游走是否是内射的。
Alley+:我们修改了Alley,在每次随机游走中不选择已经访问过的数据顶点两次,确保只对内射行走采样。
Alley+TPI:我们修改了缠结模式索引(TPI)[29],并将其建立在Alley+之上。由于索引需要指数时间和空间,因此最大模式大小设置为4。
为了比较我们的算法与基于gnn的方法,我们考虑了两个最近的最先进的作品,LSS [54]和NeurSC [51]作为两个额外的基线。
环境。FaSTest是用C-++语言实现的。Alley和LSS的源代码是公开的,NeurSC由作者获得。超参数被设置为它们建议的默认值。实验在一台拥有两台英特尔至强银4114 2.20 GHz cpu、一个NVIDIA RTX 3090 Ti GPU和256GB内存的机器上进行。
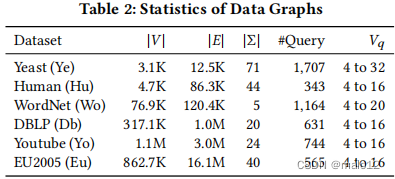
数据集。我们在之前[22,27,29,45,51]中使用的真实大规模图数据集上进行实验。为了进行公平的比较,我们通过对子图匹配算法[45]的比较研究,得到了查询图。我们使用精确子图匹配算法DAF [22]来获得地面真实结果。由于精确计数的计算成本非常高,所以我们只使用了可以在2小时内计算出精确计数的查询图。数据图如表2所示。
性能度量精度由q-误差[35]测量,定义为最大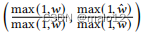
是嵌入的真实数,正如在之前的工作[29,39,51,54]中所做的那样。效率是通过每个查询的平均运行时间来衡量的。对于LSS和NeurSC,我们采用了5倍交叉验证进行了评估。
对于树形采样,我们将可接受的失败概率设置为𝛼= 0.05,将可容忍的相对误差设置为𝑐= 1.25。使用这些工具参数时,树采样的样本量由Clopper-皮尔逊区间(公式4)自适应地决定。
7.2 Accuracy
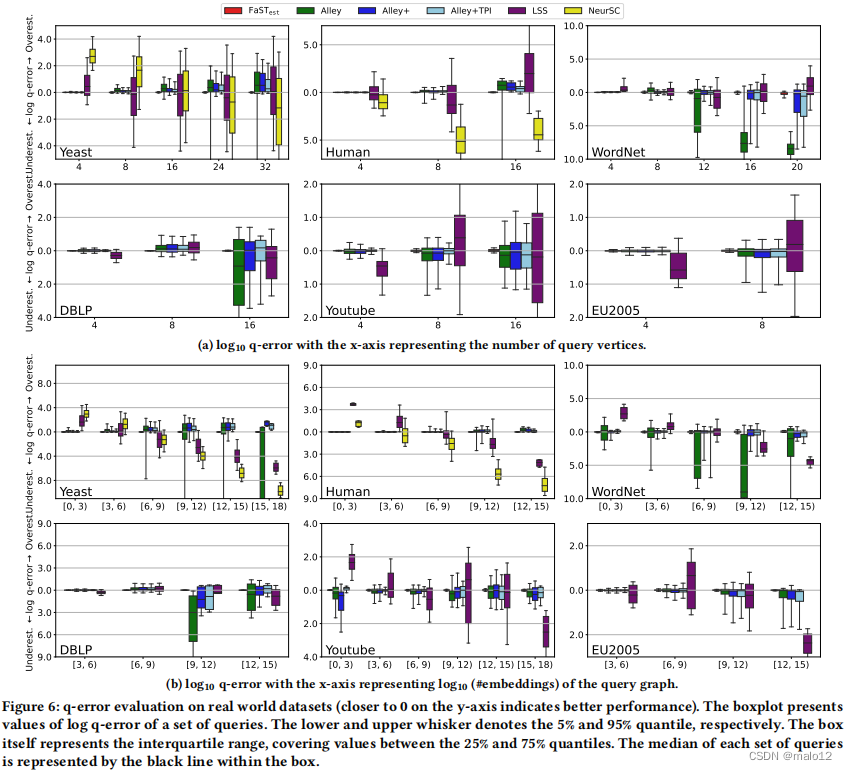
图6显示了FaSTest在真实世界的图形数据集上与最先进的竞争对手相比的准确性。为了区分高估和低估,如果ˆ𝑤≥𝑤,则𝑦=log10 1 )(1,1,𝑤);如果ˆ𝑤<𝑤,则log10 max(1,𝑤)max(1,ˆ𝑤)显示在𝑦=0下面,如[29,39,51,54]所示。为了确保公平的比较,我们使用𝐾=100,000(方程7)进行图形采样,并选择Alley的样本量,使其总体执行时间不小于我们的。对于大型数据集(DBLP,EU2005,Youtube,WordNet),由于时间和内存的限制,我们无法训练NeurSC,因此我们省略了这些数据集的结果。在具有不同统计属性和查询大小从小(4)到大(32)的数据图中,FaSTest在准确性方面显著优于采样方法和GNN方法。请注意,对数q误差为1表示10倍的高估/低估。
图6a显示,gnn的q-误差随着查询图的大小的增长而增加。例如,在人类数据集上大小为16的查询上,FaSTest显示的平均q-误差为1.09,其中LSS和NeurSC分别显示为2.5×103和1.4×104。这代表了一个超过三个数量级的改进。此外,当真实基数很小时,gnn倾向于高估,而当真实基数很大时,gnn则会低估,如图6b所示。虽然基于gnn的方法可以对每个查询进行快速推断,但在困难实例上的准确性明显低于基于采样的算法。因此,为了进一步评估,我们将重点与最先进的采样算法Alley进行比较。
抽样算法往往容易出现抽样失败,没有找到成功的样本,因此算法报告零作为估计。在标签分布复杂或查询图较大的困难实例下,Alley还显示了采样失败,如在DBLP和WordNet数据集上的大型查询中。然而,FaSTest通过强滤波显著减少了样本空间,从而在此类实例上实现了较高的精度。特别是,在WordNet数据集上大小为20的查询情况下,FaSTest显示平均q误差为1.81,其中Alley+TPI的平均q误差为418.5,这代表了超过两个数量级的改进。
随着真实基数的增加,采样算法的精度往往会下降。然而,如图6b所示,即使在真实基数异常大的情况下,FaSTest也显示出了令人印象深刻的准确性。对于酵母数据集,对于有超过1015个嵌入的查询(由[15,18)表示),FaSTest展示了平均q误差为1.10,对应于相对误差约为10%。
图形采样的必要性。虽然大多数情况下可以处理候选树抽样,但图采样算法对于困难的情况是必要的。图7显示了在WordNet数据集上的640个困难查询的有和没有图采样的日志q-误差,其中在50,000次树采样试验中观察到的成功不超过10次。x轴表示从高估的树采样到被低估的树采样的查询。每个查询都用一个红点和一个绿点表示,分别表示有和没有图采样的对数q-误差。
结果表明,当发生一到两个极不可能的成功时,树的抽样会导致严重的高估,或者当没有成功时,会导致严重的低估。即使在这些困难的情况下,图抽样也提供了合理准确的估计。
7.3 Efficiency
采样算法在精度和效率之间有一个自然的权衡,因为通过取一个更大的样本量,估计可以更准确。因此,我们进行了一个不同样本量的实验,以证明我们的算法在这种权衡中的性能。对于图采样,我们将方程7中的𝐾值从5×103变化到3×105。我们确定Alley的样本量为𝐾×|𝑉𝑞|,使用相同范围的𝐾值。
图8突出显示了与Alley相比,FaSTest令人印象深刻的准确性到效率的权衡,每个标记代表了不同样本量下的平均运行时间和平均logq-误差。对于我们的方法,在除WordNet外的5个数据集中,结果几乎是一个单个点。这是因为大多数查询都是由树采样来处理的,树采样的样本大小由公式4决定,独立于𝐾。在这些数据集中,树采样显示了突出的准确性和效率。图采样的效率在WordNet数据集中变得很明显。通过取更大的样本量,FaSTest将q-误差从1.33提高到1.20,而经过的时间从530毫秒增加到650毫秒。
对于WordNet和EU2005数据集,尽管FaSTest由于过滤而产生了一些开销,但在达到特定精度水平所需的执行时间方面,它仍然显著地更有效率。在WordNet数据集中,最大的竞争对手Alley+TPI,每次查询大约需要6秒才能达到平均logq误差为0.3(q误差约为2)。另一方面,FaSTest达到平均logq误差为0.1(q误差约为1.26),每个查询只有大约半秒。
FaSTest的效率是通过我们的三个关键组件的协同作用来实现的。首先,我们的强滤波大大减少了采样前的样本空间,从而减少了所需的样本数量。过滤还降低了获取采样的成本。其次,树采样可以产生准确的结果,而不需要昂贵的交集,从而高效地解决了大多数情况。最后,图抽样处理了剩余的困难情况。
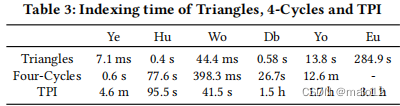
关于索引的效率,表3显示了与来自Alley [29]的TPI(缠结模式索引)相比,我们的数据集的索引三角形和4个周期的开销。在我们的实验中,所有的实验中6个数据集使用三角安全,除欧盟2005数据集外,所有数据集都使用四环安全。与需要指数时间和空间的TPI相比,我们的索引阶段可以更有效地完成。我们注意到,由于每个数据图只需要一次这种预处理,因此可以预先建立这些索引,以处理许多查询。
7.4 Evaluation of Techniques
安全条件。我们将我们的安全条件与两种最先进的子图匹配算法的滤波技术进行了比较:VEQ[27]提出的NS(邻居安全)和VC [46]提出的ESIC。图9显示了最具挑战性的数据集WordNet和酵母的CS的大小(通过CS中的边的数量来衡量)和总体效率(通过运行时间来衡量)。我们的更强的过滤条件大大减少了候选边的数量和执行时间。具体来说,我们的滤波技术与NS相比,使WordNet中的候选边数减少了80%,与ESIC相比减少了75%。尽管它的复杂性更高,但我们的安全条件在实践中仍然是有效的,因为更强的滤波通过减少采样空间而提高了采样的效率。
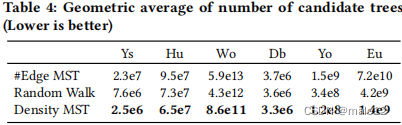
密度启发式的有效性。为了减少候选树的数量,可以考虑最小化剩余候选边数的乘积(#Edge MST),而密度启发式则试图最小化密度的乘积。此外,我们将我们的策略与基于随机游走的生成树生成(随机游走)进行比较。证明了利用随机游动,可以生成一个具有均匀概率[1]的随机生成树。
表4比较了每种策略的候选树数量的几何平均值。我们观察到,#Edge MST产生了显著更高数量的候选树,而密度启发式(密度MST)始终产生更好的结果。当候选树的数量较大时,策略之间的差异较大。与随机漫步相比,密度MST显著减少了高达80%的样本空间,与#Edge MST相比,密度MST显著减少了高达98.5%,这直接转化为所需样本数量的类似减少。
8 CONCLUSION
本文提出了子图基数估计的FaSTest方法。我们的新滤波采样方法协同结合了(1)大幅减少样本空间的强滤波方法,(2)候选树采样的高效和准确估计,(3)最坏情况最优分层图采样,在困难情况下具有突出的精度。在真实数据集上的大量实验表明,FaSTest的性能优于最先进的算法。















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









