









| 分区方法概述 Oracle 提供了一下几种分区方法:
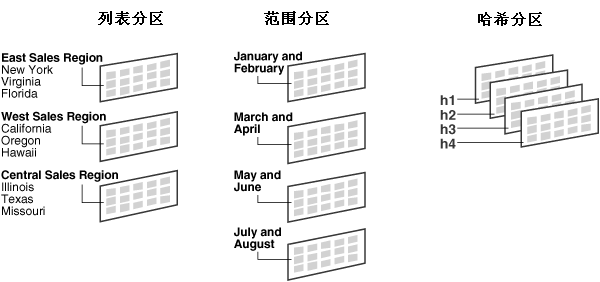
图 18-2 列表分区,范围分区,及哈系分区
图 18-2 显示了依据销售区域进行列表分区,以两个月为一区间进行范围分区,以及按哈希组(h1,h2,h3,h4)进行哈希分区。
用户还可以将多种分区方法组合进行复合分区(composite partitioning)。Oracle 支持范围-哈希(range-hash)复合分区及范围-列表(range-list)复合分区。图 18-3 展示了这两种复合分区。 图 18-3 复合分区 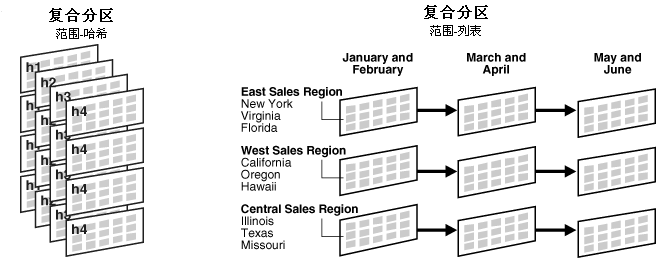
图 18-3 显示了使用哈希组(h1,h2,h3,h4)的范围-哈希复合分区,以及范围-列表复合分区(时间区间(January 到 February,March 到 April,May 到 June)及地理区域列表)。
范围分区 范围分区(range partitioning)依据用户创建分区时设定的分区键值(partition key value)范围将数据映射到不同分区。范围分区是较常用的分区方式,通常针对日期数据使用。例如,用户可以将销售数据按月存储到相应的分区中。 在采用范围分区时,应注意以下规则:
下面的语句给出一个典型的范围例子。此语句创建了依据 sales_date 字段进行范围分区的表 sales_range。
CREATE TABLE sales_range ( salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date)( PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','MM/DD/YYYY')), PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','MM/DD/YYYY')), PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','MM/DD/YYYY')), PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','MM/DD/YYYY')) );
列表分区 用户可以采用列表分区(list partitioning)显示地控制如何将数据行映射到各个分区。用户在各分区的定义中指定一个分区键(partitioning key)离散值的列表,从而实现列表分区。列表分区与范围分区(range partitioning)有所不同,在范围分区中是为每个分区设定一个分区键值的范围;列表分区与哈希分区也有区别,哈希分区是通过一个哈希函数(hash function)控制数据行与分区间的映射关系。用户可以采用列表分区,将无序(unordered)或互不相关(unrelated)的数据进行分组整理。 下面是一个列表分区的示例。在此例子中,用户需要按区域对销售数据进行分区。即把地理位置接近的州归为一组。
CREATE TABLE sales_list( salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_state VARCHAR2(20), sales_amount NUMBER(10), sales_date DATE) PARTITION BY LIST(sales_state)( PARTITION sales_west VALUES('California', 'Hawaii'), PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'), PARTITION sales_central VALUES('Texas', 'Illinois'), PARTITION sales_other VALUES(DEFAULT) );
在将数据行映射到分区的过程中,Oracle 检查数据行的分区键值是否包含于某分区定义的值列中。以下面的数据为例:
与范围分区(range partitioning)及哈希分区(hash partitioning)有所区别,列表分区不支持分区键中包含多列。如果一个表采用列表分区方式,那么分区键只能由此表的一个数据列构成。 用户可以定义一个 DEFAULT 分区,在定义了此分区后,定义列表分区表时不必列出所有可能的分区键值,Oracle 在处理数据时也不会出现无法映射的情况. 哈希分区 用户可以采用哈希分区(hash partitioning)将不适于采用范围分区(range partitioning)或列表分区(list partitioning)的数据进行分区。哈希分区的语法(syntax)简单且易于实现。在以下情况时哈希分区比范围分区更适用:
分割(splitting),移除(dropping ),及融合(merging)等操作不适用于哈希分区。但对哈希分区可以进行添加(add)及接合(coalesce)操作。 CREATE TABLE sales_hash( salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION BY HASH(salesman_id) PARTITIONS 4 STORE IN (ts1, ts2, ts3, ts4);
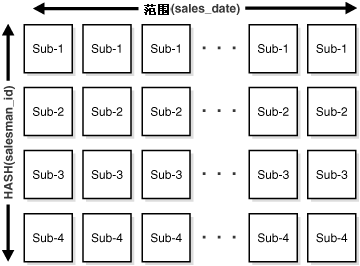
复合分区 复合分区(composite partitioning)首先根据范围(range)进行分区,再使用哈希或列表方式创建子分区。复合范围-哈希分区既能够发挥范围分区的可管理性优势,也能够发挥哈希分区的数据分布(data placement),条带化(striping),及并行化(parallelism)优势。复合范围-列表分区能够发挥范围分区的可管理性优势,也能利用列表分区的显示控制能力。 复合分区(composite partitioning)便于用户进行与时间相关的维护操作(historical operation),例如添加新的范围分区等。同时复合分区还能够利用子分区(subpartitioning)实现高度的并行 DML 操作,并对数据分布进行精细的控制。 CREATE TABLE sales_composite ( salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) SUBPARTITION BY HASH(salesman_id) SUBPARTITION TEMPLATE( SUBPARTITION sp1 TABLESPACE ts1, SUBPARTITION sp2 TABLESPACE ts2, SUBPARTITION sp3 TABLESPACE ts3, SUBPARTITION sp4 TABLESPACE ts4) (PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE('02/01/2000','MM/DD/YYYY')) PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE('03/01/2000','MM/DD/YYYY')) PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE('04/01/2000','MM/DD/YYYY')) PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE('05/01/2000','MM/DD/YYYY')) PARTITION sales_may2000 VALUES LESS THAN(TO_DATE('06/01/2000','MM/DD/YYYY'))); 上述语句创建了 sales_composite 表,首先依据 sales_date 字段创建范围分区(range partitioned),再依据 salesman_id 字段创建哈希子分区。如果用户在语句中使用了模板(template),Oracle 命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区 sales_jan2000_sp1 存储在表空间 ts1 中,而子分区 sales_jan2000_sp4 存储在表空间 ts4 中。同样,子分区 sales_apr2000_sp1 存储在表空间 ts1 中,而子分区 sales_apr2000_sp4 存储在表空间 ts4 中。图 18-4 为上述语句的图形化描述。 图 18-4 复合范围-哈希分区
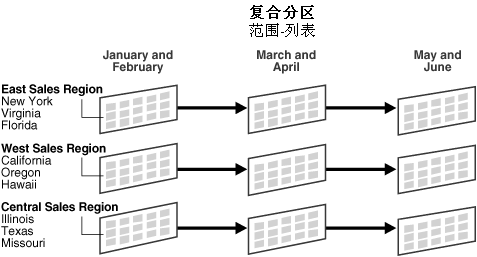
复合范围-列表分区示例
CREATE TABLE bimonthly_regional_sales( deptno NUMBER, item_no VARCHAR2(20), txn_date DATE, txn_amount NUMBER, state VARCHAR2(2)) PARTITION BY RANGE (txn_date) SUBPARTITION BY LIST (state) SUBPARTITION TEMPLATE( SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE ts1, SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE ts2, SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE ts3) ( PARTITION janfeb_2000 VALUES LESS THAN (TO_DATE('1-MAR-2000','DD-MON-YYYY')), PARTITION marapr_2000 VALUES LESS THAN (TO_DATE('1-MAY-2000','DD-MON-YYYY')), PARTITION mayjun_2000 VALUES LESS THAN (TO_DATE('1-JUL-2000','DD-MON-YYYY')) ); 上述语句创建了 bimonthly_regional_sales 表,首先依据 txn_date 字段创建范围分区(range partitioned),再依据 state 字段创建子分区。如果用户在语句中使用了模板(template),Oracle 命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区 janfeb_2000_east 存储在表空间 ts1 中,而子分区 janfeb_2000_central 存储在表空间 ts3 中。同样,子分区 mayjun_2000_east 存储在表空间 ts1 中,而子分区 mayjun_2000_central 存储在表空间 ts3 中。图 18-5 显示了表 bimonthly_regional_sales 的 9 个子分区。 图 18-5 复合范围-列表分区
何时应该对表进行分区 以下是关于何时应该对表进行分区的一些建议:
例子: 3.2. 分区表操作 以上了解了三种分区表的建表方法,下面将使用实际的数据并针对按日期的范围分区来测试分区表的数据记录的操作。 3.2.1. 插入记录 SQL> insert into dinya_test values(1,12,’BOOKS’,sysdate); 1 row created. SQL> insert into dinya_test values(2,12, ’BOOKS’,sysdate+30); 1 row created. SQL> insert into dinya_test values(3,12, ’BOOKS’,to_date(’2006-05-30’,’yyyy-mm-dd’)); 1 row created. SQL> insert into dinya_test values(4,12, ’BOOKS’,to_date(’2007-06-23’,’yyyy-mm-dd’)); 1 row created. SQL> insert into dinya_test values(5,12, ’BOOKS’,to_date(’2011-02-26’,’yyyy-mm-dd’)); 1 row created. SQL> commit; 按上面的建表结果,2006年前的数据将存储在第一个分区part_01上,而2006年到2010年的交易数据将存储在第二个分区part_02上,2010年以后的记录存储在第三个分区part_03上。 3.2.2. 查询分区表记录 SQL> select * from dinya_test partition(part_01); 插入的数据已经根据交易时间范围存储在不同的分区中。这里是指定了分区的查询,当然也可以不指定分区,直接执行select * from dinya_test查询全部记录。检索的数据量很大的时候,指定分区会大大提高检索速度。 3.2.3. 更新分区表的记录 SQL> update dinya_test partition(part_01) t set t.item_description='DESK' where t.transaction_id=1; 1 row updated. SQL> commit; 这里将第一个分区中的交易ID=1的记录中的item_description字段更新为“DESK”,可以看到已经成功更新了一条记录。但是当更新的时候指定了分区,而根据查询的记录不在该分区中时,将不会更新数据,请看下面的例子: SQL> update dinya_test partition(part_01) t set t.item_description='DESK' where t.transaction_id=6; 0 rows updated. SQL> commit; 指定了在第一个分区中更新记录,但是条件中限制交易ID为6,而查询全表,交易ID为6的记录在第三个分区中,这样该条语句将不会更新记录。 3.2.4. 删除分区表记录 SQL> delete from dinya_test partition(part_02) t where t.transaction_id=4; 1 row deleted. SQL> commit; Commit complete. SQL> 上面例子删除了第二个分区part_02中的交易记录ID为4的一条记录,和更新数据相同,如果指定了分区,而条件中的数据又不在该分区中时,将不会删除任何数据。
--------------------------------------------------------------------------------------------------- 表分区示例
oracle 分区表的作用就是为了使用户的大量的数据在读写操作和查询中速度更快,Oracle提供了对表和索引进行分区的技术,以改善大型应用系统的性能。 具体的优点包括: ·增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; ·维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; ·均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能; ·改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 Oracle数据库提供对表或索引的分区方法有三种: ·范围分区 ·Hash分区(散列分区) ·复合分区 实例介绍 1、准备工作首先建立三个表空间 create tablespace demotbsp01 datafile 'C:/oracle/product/10.2.0/oradata/stone/demo01.dbf' size 50M create tablespace demotbsp02 datafile 'C:/oracle/product/10.2.0/oradata/stone/demo02.dbf' size 50M create tablespace demotbsp03 datafile 'C:/oracle/product/10.2.0/oradata/stone/demo03.dbf' size 50M 2、建立不同类型的分区表 2.1.1. 范围分区 范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据业务记录的创建日期进行分区等。 需求描述:有一个物料交易表,表名:material_transactions。该表将来可能有千万级的数据记录数。要求在建该表的时候使用分区表。这时候我们可以使用序号分区三个区,每个区中预计存储三千万的数据,也可以使用日期分区,如每五年的数据存储在一个分区上。 根据交易记录的序号分区建表: SQL> create table dinya_test ( transaction_id number primary key, item_id number(8) not null, item_description varchar2(300), transaction_date date not null ) partition by range (transaction_id) ( partition part_01 values less than(30000000) tablespace demotbsp01, partition part_02 values less than(60000000) tablespace demotbsp02, partition part_03 values less than(maxvalue) tablespace demotbsp03 ); 建表成功,根据交易的序号,交易ID在三千万以下的记录将存储在第一个表空间dinya_space01中,分区名为:par_01,在三千万到六千万之间的记录存储在第二个表空间: demotbsp02中,分区名为:part_02,而交易ID在六千万以上的记录存储在第三个表空间demotbsp03中,分区名为part_03. 根据交易日期分区建表: SQL> create table dinya_test ( transaction_id number primary key, item_id number(8) not null, item_description varchar2(300), transaction_date date not null ) partition by range (transaction_date) ( partition part_01 values less than(to_date('2006-01-01','yyyy-mm-dd')) tablespace demotbsp01, partition part_02 values less than(to_date('2010-01-01','yyyy-mm-dd')) tablespace demotbsp02, partition part_03 values less than(maxvalue) tablespace demotbsp03 ); 这样我们就分别建了以交易序号和交易日期来分区的分区表。每次插入数据的时候,系统将根据指定的字段的值来自动将记录存储到制定的分区(表空间)中。 当然,我们还可以根据需求,使用两个字段的范围分布来分区,如partition by range ( transaction_id ,transaction_date), 分区条件中的值也做相应的改变,请读者自行测试。 2.1.2. Hash分区(散列分区) 散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。如将物料交易表的数据根据交易ID散列地存放在指定的三个表空间中: SQL> create table dinya_test ( transaction_id number primary key, item_id number(8) not null, item_description varchar2(300), transaction_date date ) partition by hash(transaction_id) ( partition part_01 tablespace demotbsp01, partition part_02 tablespace demotbsp02, partition part_03 tablespace demotbsp03 ); 建表成功,此时插入数据,系统将按transaction_id将记录散列地插入三个分区中,这里也就是三个不同的表空间中。 2.1.3. 复合分区 有时候我们需要根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。复合分区是先使用范围分区,然后在每个分区内再使用散列分区的一种分区方法,如将物料交易的记录按时间分区,然后每个分区中的数据分三个子分区,将数据散列地存储在三个指定的表空间中: SQL> create table dinya_test ( transaction_id number primary key, item_id number(8) not null, item_description varchar2(300), transaction_date date ) partition by range(transaction_date)subpartition by hash(transaction_id) subpartitions 3 store in (demotbsp01,demotbsp02,demotbsp03) ( partition part_01 values less than(to_date('2006-01-01','yyyy-mm-dd')), partition part_02 values less than(to_date('2010-01-01','yyyy-mm-dd')), partition part_03 values less than(maxvalue) ); Table created. 该例中,先是根据交易日期进行范围分区,然后根据交易的ID将记录散列地存储在三个表空间中。 3.2. 分区表操作 以上了解了三种分区表的建表方法,下面将使用实际的数据并针对按日期的范围分区来测试分区表的数据记录的操作。 3.2.1. 插入记录 SQL> insert into dinya_test values(1,12,’BOOKS’,sysdate); 1 row created. SQL> insert into dinya_test values(2,12, ’BOOKS’,sysdate+30); 1 row created. SQL> insert into dinya_test values(3,12, ’BOOKS’,to_date(’2006-05-30’,’yyyy-mm-dd’)); 1 row created. SQL> insert into dinya_test values(4,12, ’BOOKS’,to_date(’2007-06-23’,’yyyy-mm-dd’)); 1 row created. SQL> insert into dinya_test values(5,12, ’BOOKS’,to_date(’2011-02-26’,’yyyy-mm-dd’)); 1 row created. SQL> commit; 按上面的建表结果,2006年前的数据将存储在第一个分区part_01上,而2006年到2010年的交易数据将存储在第二个分区part_02上,2010年以后的记录存储在第三个分区part_03上。 3.2.2. 查询分区表记录 SQL> select * from dinya_test partition(part_01); 插入的数据已经根据交易时间范围存储在不同的分区中。这里是指定了分区的查询,当然也可以不指定分区,直接执行select * from dinya_test查询全部记录。检索的数据量很大的时候,指定分区会大大提高检索速度。 3.2.3. 更新分区表的记录 SQL> update dinya_test partition(part_01) t set t.item_description='DESK' where t.transaction_id=1; 1 row updated. SQL> commit; 这里将第一个分区中的交易ID=1的记录中的item_description字段更新为“DESK”,可以看到已经成功更新了一条记录。但是当更新的时候指定了分区,而根据查询的记录不在该分区中时,将不会更新数据,请看下面的例子: SQL> update dinya_test partition(part_01) t set t.item_description='DESK' where t.transaction_id=6; 0 rows updated. SQL> commit; 指定了在第一个分区中更新记录,但是条件中限制交易ID为6,而查询全表,交易ID为6的记录在第三个分区中,这样该条语句将不会更新记录。 3.2.4. 删除分区表记录 SQL> delete from dinya_test partition(part_02) t where t.transaction_id=4; 1 row deleted. SQL> commit; Commit complete. SQL> 上面例子删除了第二个分区part_02中的交易记录ID为4的一条记录,和更新数据相同,如果指定了分区,而条件中的数据又不在该分区中时,将不会删除任何数据。 4.分区表的维护 了解了分区表的建立、索引的建立、表和索引的使用后,在应用的还要经常对分区进行维护和管理。日常维护和管理的内容包括:增加一个分区,合并一个分区及删除分区等等。下面以范围分区为例说明增加、合并、删除分区的一般操作: 4.1. 增加一个分区 SQL> alter table dinya_test 2 add partition part_04 values less than(to_date(’2012-01-01’,’yyyy-mm-dd’)) tablespace dinya_spa ce03; Table altered. SQL> 增加一个分区的时候,增加的分区的条件必须大于现有分区的最大值,否则系统将提示ORA-14074 partition bound must collate higher than that of the last partition 错误。 4.2. 合并一个分区 SQL> alter table dinya_test merge partitions part_01,part_02 into partition part_02; Table altered. SQL> 在本例中将原有的表的part_01分区和part_02分区进行了合并,合并后的分区为part_02,如果在合并的时候把合并后的分区定为part_01的时候,系统将提示ORA-14275 cannot reuse lower-bound partition as resulting partition 错误。 4.3. 删除分区 SQL> alter table dinya_test drop partition part_01; Table altered. SQL> 删除分区表的一个分区后,查询该表的数据时显示,该分区中的数据已全部丢失,所以执行删除分区动作时要慎重,确保先备份数据后再执行,或将分区合并。 需要说明的是,本文在举例说名分区表事务操作的时候,都指定了分区,因为指定了分区,系统在执行的时候则只操作该分区的记录,提高了数据处理的速度。不要指定分区直接操作数据也是可以的。在分区表上建索引及多索引的使用和非分区表一样。此外,因为在维护分区的时候可能对分区的索引会产生一定的影响,可能需要在维护之后重建索引,相关内容请参考分区表索引部分的文档。
| |||||||||||||||||||||||||





















 2233
2233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









