







Yarn组件
Hadoop组件之间的关系
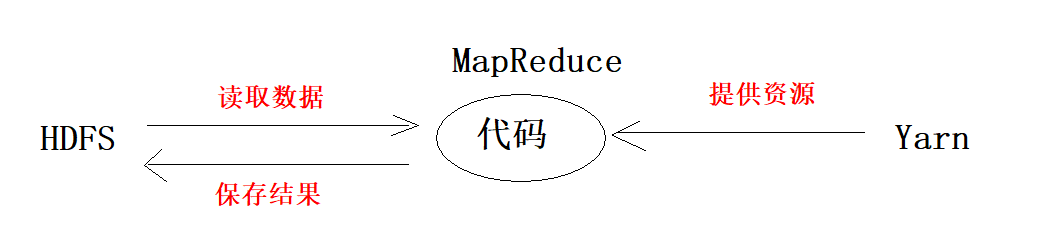
Yarn的介绍
1、Yarn是Hadoop2.x版本引入的一个新组件
2、Yarn本身没有资源,是来管理集群资源,为分布式计算提供合理的资源分配方案
3、Yarn可以让集群的资源能够统一,高效率给分配
4、Yarn本身也是一个集群:
主节点:ResourceManager
从节点:NodeManager
Yarn的集群架构
架构图
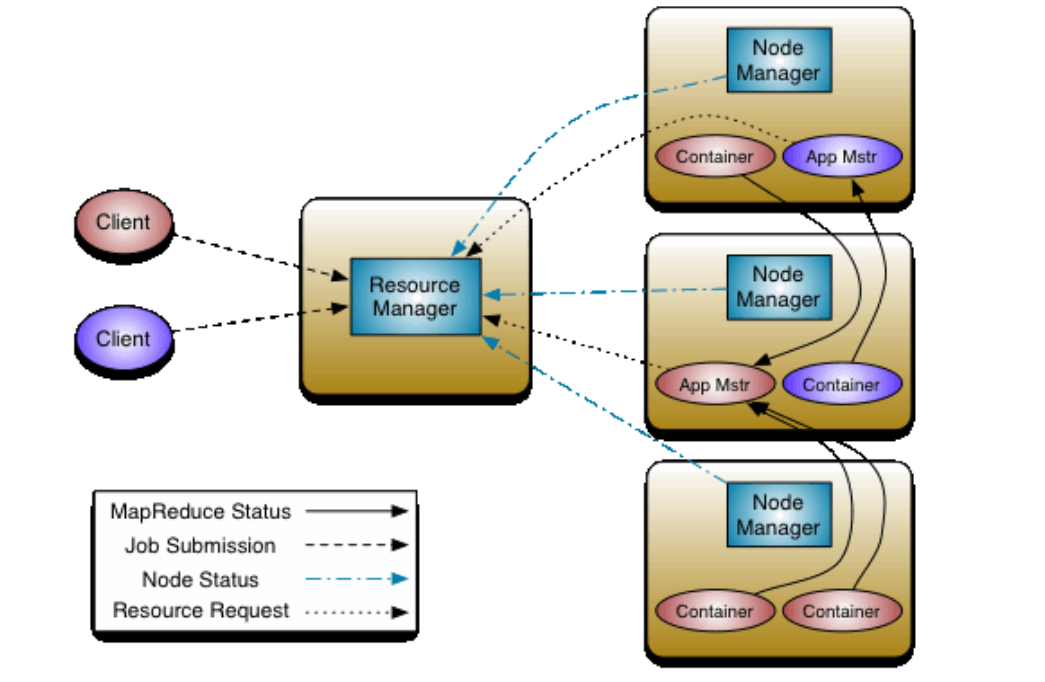
角色
-
Client
客户端: 1、作用就是提交任务 2、既可以提交MapReduce任务,也可以提交Spark任务 -
ResourceManager
1、ResourceManager负责整个集群的资源管理和分配,是一个全局的资源管理系统。 2、NodeManager以心跳的方式向ResourceManager汇报资源使用情况(目前主要是CPU和内存的使用情况)。 3、ResourceManager会根据任务的请求为其分配资源,但是不负责具体任务的监控、追踪、运行状态等工作。 任务的状态由App Master进程来监控 -
NodeManager
1、NodeManager是每个节点上的资源和任务管理器,它来监控每台机器的资源使用情况 2、NodeManager定时向ResourceManager汇报本节点资源(CPU、内存)的使用情况和Container的运行状态。 3、NodeManager接收并处理来自ApplicationMaster的Container启动、停止等各种请求。 -
Container
0、该组件只有在执行任务的时候才会启动,jps是看不到的 1、Container是一个资源容器 2、Container可以理解为一个类,用来封装资源信息,相当于批条或者银票 class Container{ int 内存; int cpu核数; String host; } -- 批条或者银票 ArrayList { new Container(1G, 2核cpu,node1); new Container(1G, 2核cpu,node2); new Container(1G,1核cpu,node3); } -
ApplicationMaster ( App Master)
1、该组件只有在执行任务时,才会启动 2、客户端每提交一个任务,Yarn会自动的启动一个App Master 3、App Master就相当于一个任务的监工,或者包工头,负责整个Job任务执行状态的监控
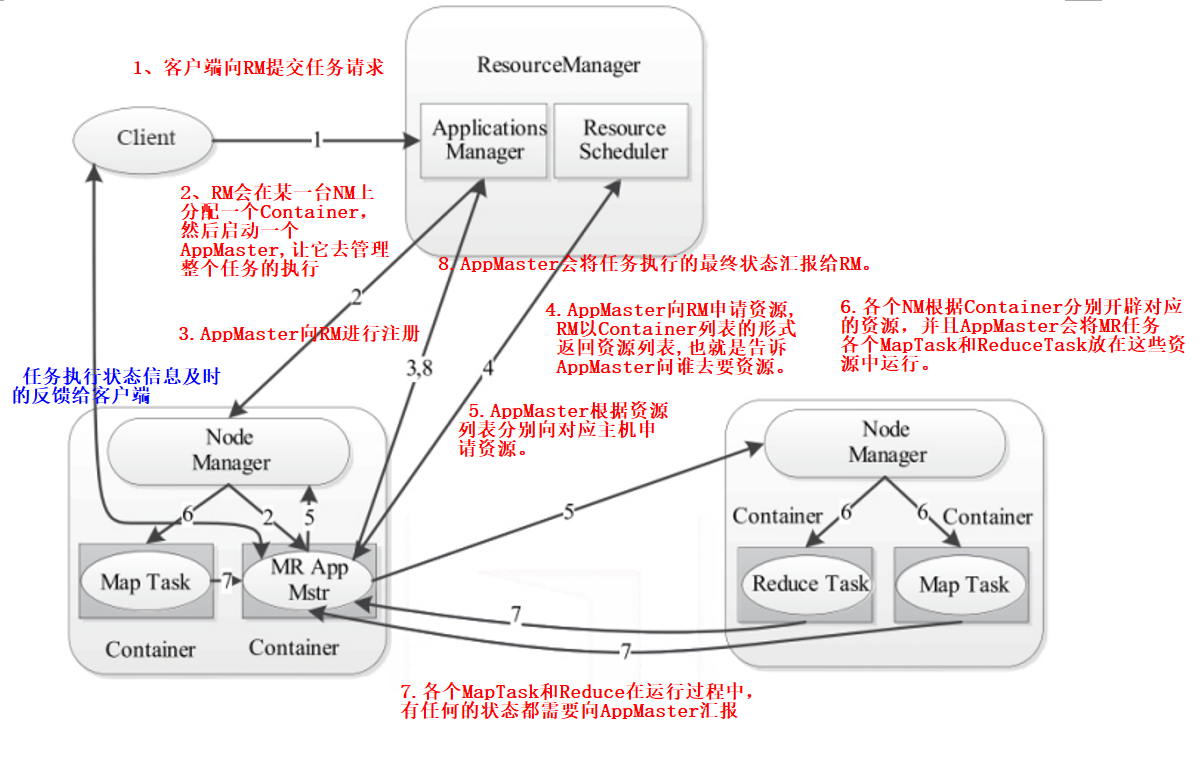
(面试题)Yarn执行任务的流程
(面试题)Yarn的调度策略
介绍
1、当同时向Yarn集群多个Job任务时,Yarn如何对资源进行系统的管理,这种管理策略就是Yarn的调度策略
调度策略
-
队列调度器(FIFO Scheduler)
1、特点:哪个任务先来,先分配其所有需要的资源 2、缺点是大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。 3、该调度方式基本不用 -
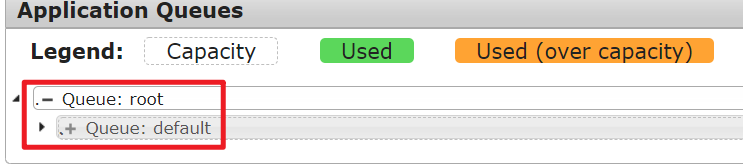
容量调度器(Capacity Scheduler) -Apache默认的调度策略
- 概念
1、该调度器会将整个集群资源分成几个队列 2、不同的开发组只需要使用自己的资源队列即可,可以实现资源隔离 3、这个调度器是Hadoop默认的调度器 4、容量调度器默认有一个root根队列,下边有一个default子队列 5、调度器的使用是通过yarn-site.xml配置文件中的 yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器。 <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulere> </property> 6、我们可以通过定义队列来实现资源隔离
-
配置
1、先备份原来的调度配置文件
cd /export/server/hadoop-3.3.0/etc/hadoop cp capacity-scheduler.xml capacity-scheduler.xml_bak2、打开/export/server/hadoop-3.3.0/etc/hadoop/capacity-scheduler.xml文件,配置以下内容
=方案1:没有default队列=
<?xml version="1.0"?> <configuration> <!-- 分为两个队列,分别为prod和dev --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> <!-- 设置prod队列40% --> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>40</value> </property> <!-- 设置dev队列60% --> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>60</value> </property> <!-- 设置dev队列可使用的资源上限为75% --> <property> <name>yarn.scheduler.capacity.root.dev.maximum-capacity</name> <value>75</value> </property> <!-- dev继续分为两个队列,分别为eng和science --> <property> <name>yarn.scheduler.capacity.root.dev.queues</name> <value>eng,science</value> </property> <!-- 设置eng队列50% --> <property> <name>yarn.scheduler.capacity.root.dev.eng.capacity</name> <value>50</value> </property> <!-- 设置science队列50% --> <property> <name>yarn.scheduler.capacity.root.dev.science.capacity</name> <value>50</value> </property> </configuration>

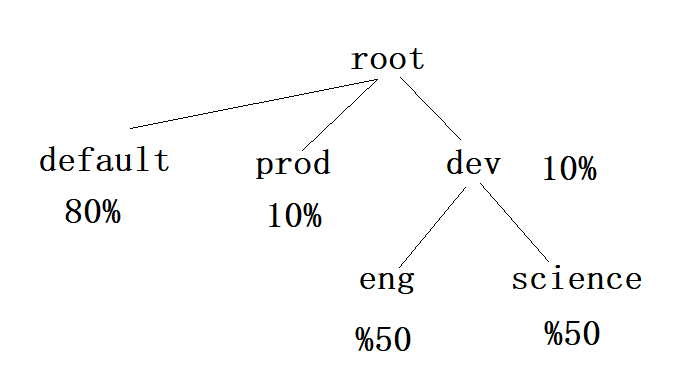
===方案2:有Default队列===
```xml
<?xml version="1.0"?>
<configuration>
<!-- 分为两个队列,分别为prod和dev -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,prod,dev</value>
</property>
<!-- 设置default队列80% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>80</value>
</property>
<!-- 设置prod队列10% -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>10</value>
</property>
<!-- 设置prod队列可使用的资源上限为80% -->
<property>
<name>yarn.scheduler.capacity.root.prod.maximum-capacity</name>
<value>80</value>
</property>
<!-- 设置dev队列10% -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>10</value>
</property>
<!-- 设置dev队列可使用的资源上限为75% -->
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<!-- dev继续分为两个队列,分别为eng和science -->
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<!-- 设置eng队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<!-- 设置science队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>
```
3、重启Yarn
```shell
stop-yarn.sh
start-yarn.sh
```
4、执行测试程序
```shell
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi -Dmapreduce.job.queuename=eng 2 10
```
5、通过8088页面的Scheduler菜单查看资源使用情况
-
公平调度器(Fair Scheduler)
该调度器会将整个资源平均分配给job,所有执行的Job一视同仁
Yarn的关键参数
#以下参数都是在yarn-site.xml中配置
设置container分配最小内存
yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存
设置container分配最大内存
yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存
设置每个container的最小虚拟内核个数
yarn.scheduler.minimum-allocation-vcores 1 每个container默认给分配的最小的虚拟内核个数
设置每个container的最大虚拟内核个数
yarn.scheduler.maximum-allocation-vcores 32 每个container可以分配的最大的虚拟内核的个数
设置NodeManager可以分配的内存大小
yarn.nodemanager.resource.memory-mb 8192 nodemanager 可以分配的最大内存大小,默认8192Mb
定义每台机器的内存使用大小
yarn.nodemanager.resource.memory-mb 8192
定义交换区空间可以使用的大小
交换区空间就是讲一块硬盘拿出来做内存使用,这里指定的是nodemanager的2.1倍
yarn.nodemanager.vmem-pmem-ratio 2.1
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











