







 短链接通过缩短长链接来节省空间,尤其在字符限制的平台如微博中更为实用。其工作原理涉及301和302重定向,前者用于减少服务器压力但无法统计点击次数,后者能统计点击但增加服务器负担。实现方法通常包括哈希函数转化链接为短码。本文介绍了使用MurmurHash将链接转化为62进制数字,并提供了短链接生成的代码实现。
短链接通过缩短长链接来节省空间,尤其在字符限制的平台如微博中更为实用。其工作原理涉及301和302重定向,前者用于减少服务器压力但无法统计点击次数,后者能统计点击但增加服务器负担。实现方法通常包括哈希函数转化链接为短码。本文介绍了使用MurmurHash将链接转化为62进制数字,并提供了短链接生成的代码实现。
一、为什么要设计短链接,短链接有什么好处?
1、链接变短,在对内容长度有限制的平台发文,可编辑的文字就变多了。
比如:微博,限定了只能发 140 个字,如果一串长链直接怼上去,其他可编辑的内容就所剩无几了,用短链的话,链接长度大大减少,自然可编辑的文字多了不少。
2、我们经常需要将链接转成二维码的形式分享给他人,如果是长链的话二维码密集难识别,短链就不存在这个问题了。
3、链接太长在有些平台上无法自动识别为超链接。
二、短链接实现的原理。
1、请求流程:
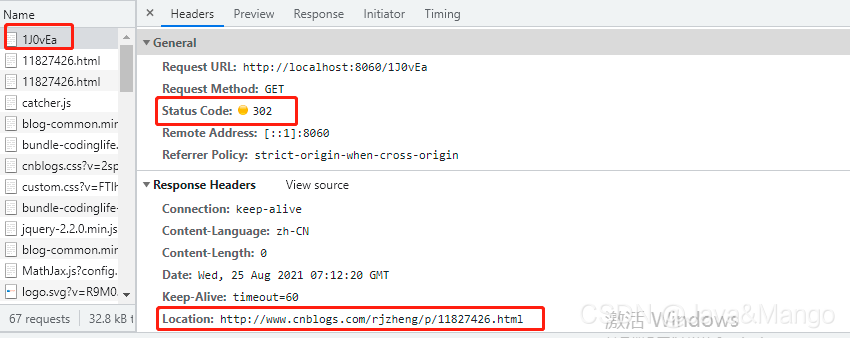
首先,我们先看看当当的短链接http://localhost:8060/1J0vEa
它是由两个部分组成http://localhost:8060短链接系统的域名地址或者IP+端口
1J0vEa:请求参数
请求 http://localhost:8060/1J0vEa 地址后,返回状态如下所示
2、请求短链接后,浏览器发生了什么?
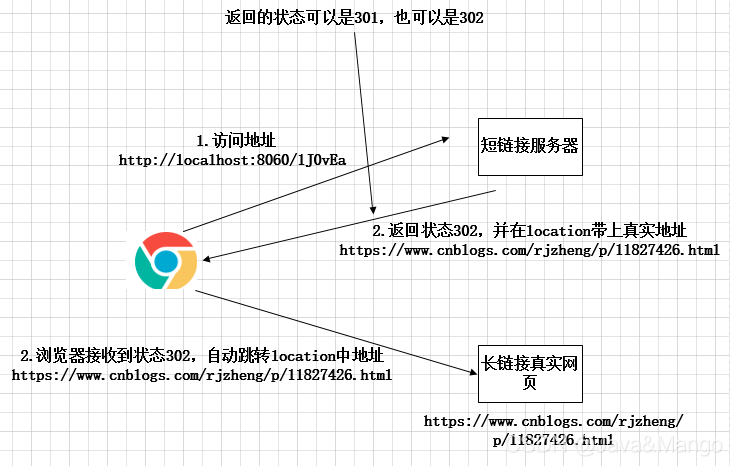
上图所示短链接系统,返回的状态可以为301或者302。
301代表什么?
301代表的是永久重定向。什么意思呢?
对于GET请求, 301跳转会默认被浏览器cache。也就是说,用户第一次访问某个短链接后,如果服务器返回301状态码,则这个用户在后续多次访问同一短链接地址,浏览器会直接请求跳转地址,而不会再去短链接系统上取!
这么做优点很明显,降低了服务器压力,但是无法统计到短链接地址的点击次数。
302代表什么?
302代表的是临时定向。什么意思呢?
对于GET请求, 302跳转默认不会被浏览器缓存,除非在HTTP响应中通过 Cache-Control 或 Expires 暗示浏览器缓存。因此,用户每次访问同一短链接地址,浏览器都会去短链接系统上取。
这么做的优点是,能够统计到短地址被点击的次数了。但是服务器的压力变大了。
三、短链接实现的方法。
1、MurmurHash 非加密型哈希函数 把链接转成一串数字。
public static String hashToBase62(String str) {
int i = MurmurHash.hash32(str);
long num = i < 0 ? Integer.MAX_VALUE - (long) i : i;
return convertDecToBase62(num);
}2、由于我们的短链接是由 a-z、A-Z 和 0-9 共 62 个字符可以选择。因此,我们可以由长链接经过hashToBase62方法转成的十进制的数字,转换为一个62进制的数,例如:http://www.cnblogs.com/rjzheng/p/11827426.html 转成 1J0vEa
private static char[] CHARS = new char[]{
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'
};
private static int SIZE = CHARS.length;
private static String convertDecToBase62(long num) {
StringBuilder sb = new StringBuilder();
while (num > 0) {
int i = (int) (num % SIZE);
sb.append(CHARS[i]);
num /= SIZE;
}
return sb.reverse().toString();
}3、短链接生成方法。
@Override
public String saveUrlMap(String shortURL, String longURL, String originalURL) {
//保留长度为1的短链接
if (shortURL.length() == 1) {
longURL += DUPLICATE;
shortURL = saveUrlMap(HashUtils.hashToBase62(longURL), longURL, originalURL);
}
//在布隆过滤器中查找是否存在
else if (FILTER.contains(shortURL)) {
//存在,从Redis中查找是否有缓存
String redisLongURL = redisTemplate.opsForValue().get(shortURL);
if (redisLongURL != null && originalURL.equals(redisLongURL)) {
//Redis有缓存,重置过期时间
redisTemplate.expire(shortURL, TIMEOUT, TimeUnit.MINUTES);
return shortURL;
}
//没有缓存,在长链接后加上指定字符串,重新hash
longURL += DUPLICATE;
shortURL = saveUrlMap(HashUtils.hashToBase62(longURL), longURL, originalURL);
} else {
//不存在,直接存入数据库
try {
urlMapper.saveUrlMap(new UrlMap(shortURL, originalURL));
FILTER.add(shortURL);
//添加缓存
redisTemplate.opsForValue().set(shortURL, originalURL, TIMEOUT, TimeUnit.MINUTES);
} catch (Exception e) {
if (e instanceof DuplicateKeyException) {
//数据库已经存在此短链接,则可能是布隆过滤器误判,在长链接后加上指定字符串,重新hash
longURL += DUPLICATE;
shortURL = saveUrlMap(HashUtils.hashToBase62(longURL), longURL, originalURL);
} else {
throw e;
}
}
}
return shortURL;
}四、代码。
实现的代码在github:https://github.com/526606178/shortUrl
本文参考了:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









