






TTiki-Taka: Attacking and Defending Deep Learning-based Intrusion Detection Systems 论文分析
摘要
神经网络在网络入侵检测系统(NIDS)的发展中越来越重要,因为它们具有实现高检测精度的潜力,同时需要有限的特征工程。然而,基于深度学习的检测器在对抗的例子中可能是脆弱的,通过这些例子,攻击者可能对目标NIDS的精确机制一无所知,对恶意流量特征添加微妙的扰动,以一种成本效益高的方式逃避检测和扰乱关键系统。因此,防范这种对抗性攻击非常重要,但也需要解决令人生畏的挑战。
在本文中,我们介绍了Tiki - Taka,一个通用框架(i)评估最先进的基于深度学习的NIDS对对抗性操作的鲁棒性,并(ii)纳入我们提出的防御机制,以增加NIDS对使用这种规避技术的攻击的抵抗力。具体来说,我们选择五种不同的尖端对抗性攻击机制来颠覆三种流行的利用神经网络的恶意流量检测器。我们使用一个公开可用的数据集进行实验,并考虑一对全部和一对一的分类场景,即区分非法流量和良性流量,并在许多观察到的流量中分别识别特定类型的异常流量。结果表明,在现实约束下,攻击者仅通过改变生成流量的基于时间的特征,就可以规避NIDS,成功率高达35.7%。为了克服这些缺点,我们提出了三种防御机制:模型投票集成、集成对抗训练和查询检测。据我们所知,我们的工作是第一次提出针对NID的对抗性攻击的防御措施。我们能证明,当采用所提出的方法时,针对大多数类型的恶意流量,入侵检测率可以提高到近100%,并且具有潜在灾难性后果的攻击(例如僵尸网络)可以被挫败。这证实了我们的解决方案的有效性,并使其成为设计可靠可靠的深层异常探测器时采用的理由。
CCS的概念
•安全与隐私→人工免疫系统;•计算方法→神经网络。
关键词
对抗攻击,网络入侵检测系统,深度学习
1 INTRODUCTION
网络入侵检测(Network Intrusion Detection, NID)的目的是识别恶意流量,以保护计算机、网络、服务器和数据免受攻击、未经授权的访问、修改或破坏。考虑到传输有线和无线基础设施的数据流量的空前增长,NID在确保系统/服务可用性和保护个人在线安全和隐私方面变得越来越重要。随着新的网络攻击的激增,传统的入侵检测方法依赖模式匹配(如IP地址和端口号)和分类的有效性正在下降[61]。在这种背景下,基于机器学习的解决方案正在获得关注,因为它们越来越少地依赖深度包检查(因此引起较少的隐私担忧),而且可能具有更好的泛化能力。
由于最近在图像分类、所涉及的特征工程的有限范围以及并行处理硬件成本的降低等领域取得的成功,深度学习——机器学习的一个子集——也在网络领域[58]中取得了进展。这包括NID,其中基于深度神经网络(DNNs)的解决方案明显具有更高的检测精度(参见[25,47])。然而,由于其复杂的结构,DNN的可解释性也受到限制,这不可避免地提出了重要的问题:深度学习是NID真正可靠的选择吗?基于神经网络的NID模型预期的高检测精度是否存在“阿喀琉斯之踵”?解决这些问题对保证网络入侵检测系统的可靠性至关重要。
不幸的是,在一些应用中,DNN已被证明容易受到对抗性例子[36]或后门攻击[52]的攻击[13,21],因此它们可以被输入[54]中引入的微小扰动所欺骗,这些扰动会干扰所作推论的正确性。由于这种对抗性操作通常非常难以检测,基于深度学习的NIDS也面临风险。
 图1:构建和防御针对网络入侵检测系统(NIDS)的对抗性攻击的tiki - takframework
图1:构建和防御针对网络入侵检测系统(NIDS)的对抗性攻击的tiki - takframework
攻击者可能不知道NIDS(即黑箱系统)的属性,他们可以通过反复改变流量特征的小子集来生成对抗性样本,并向NIDS进行“查询”。在每个查询之后,攻击者会收到一些反馈(例如,确认或缺少任何响应),这表明攻击尝试的成功或失败。基于这种反馈,攻击者可以在不改变其本质的情况下,调整对流量所选特征(如连续数据包之间的间隔)的扰动,或者引入新的扰动,直到成功绕过NIDS[23,46]。通过这种方法,恶意流可以伪装成良性流量并危及其目标[28],而即使被认为高度精确的NIDS也不会检测到。网络战正在迅猛发展,这种对抗策略提供了成本效益高的手段,危害医疗保健系统、电子投票、银行、工业自动化以及无数其他系统。
在本文中,我们解决了在对抗性攻击下分类器面临的严重入侵检测问题。我们第一次审查的健壮性最先进的模型对不同深度学习国家免疫日对抗机制,考虑在实际攻击决定设置(例如,攻击者只能推断如果l流量生成分为良性的或恶意的,没有知识的具体类流量映射)。我们在两种检测场景中测试每种攻击的有效性和效率:一对一和一对一,即旨在区分恶意流量和良性流量,并分别识别精确的攻击类型。在此基础上,我们提出了三种方法来防御这类新的威胁,有效地降低了每次攻击的成功率。这使得NID更加健壮和可靠。简而言之,我们做出了以下主要贡献:
[C1]我们基于最先进的NID模型实现了三种类型的DNN架构,即多层感知器(Multilayer Perceptron, MLP)、卷积神经网络(Convolutional Neural Network, CNN)和长短期记忆(Long - short - Memory, LSTM),并在现实的网络防御数据集cesic - ids2018[42]上执行NID。基于有限的特征集,实现的NID模型实现了超过98.7%的检测准确率,这与之前报道的NIDS实现的性能相匹配(详细信息见第5节)。
[C2]为了证明所考虑的NID是可以规避的,我们采用了五种最先进的攻击策略来生成对抗性样本(即NES、Boundary、HopSkipJumpAttack、Pointwise和Opt攻击),将流量特征操纵绑定到真实的域约束(即,保留那些可能改变流语义的功能不变)。我们对每种对抗性攻击的有效性进行全面评估,并对其特征进行深入分析(见第6节)。
[C3]我们提出了三种防御机制来加强基于深度学习的NIDS对对抗性攻击的防御,即:模型投票集成、集成对抗训练和查询检测。每种防御方法既可以单独操作,也可以与其他方法联合操作。实验表明,这些方法大大降低了攻击成功率,显著提高了NIDS的鲁棒性,因为我们使检测率接近100%(第7节)。
我们将我们的通用攻击-防御框架命名为TIKI-TAKA1,并在图1中说明了我们方法的工作流程。据我们所知,我们是第一个引入防御机制来对抗针对NID的对抗性攻击的公司。
2 RELATED WORK
DNN越来越多地用于NID目的,因为它们有助于最小化特征工程工作,并以高检测精度运行[6]。然而,最近的研究表明,存在可能会降低神经网络入侵检测系统性能的漏洞,因为对其输入的扰动可能会触发流量错误分类[20,58]。因此,从对抗性样本中防御基于深度学习的方法成为网络安全的关键问题。
2.1 Deep Learning-based NID
Niyazet等人使用稀疏自动编码器进行自学,并从交通流中提取重要特征[25]。他们在NSL-KDD数据集[44]上进行NID,并达到98。84%的F1成绩。Faker和Dogdu设计了一个MLP来区分CIC-IDS2017数据集中的恶意流量[16]。虽然模型结构简单,但MLP的检测率明显高于随机森林(RF)、梯度提升树(GPT)和支持向量机(SVM)结构。在[47]中也得出了类似的结论,Vinayakumaret等人将MLP与NID的大量传统机器学习方法进行了比较,表明深度学习产生了更好的性能。
NID也采用了基于CNN的方法[48]。Zhang等人设计了一个双分支CNN并采用特征融合,以解决所用数据集的类不平衡问题[59]。他们的方案能够以更高的准确度检测一小类异常,同时在执行时间方面更有效。递归神经网络(rnn)是提取交通流时间特征的热门候选方法。Zhang等人对原始数据包级流量执行NID[60]。它们结合CNN和LSTM来提取重要的空间和时间特征,实现了比单独使用这些组件时更高的检测率。
在我们的研究中,我们选择MLP、CNN和LSTM作为执行NID的代表性模型,然后对它们进行对抗性攻击的测试,并随后使用我们提出的一组增强其鲁棒性的防御机制来增强这些模型。
2.2 Attacking Deep Learning-based NIDS
大多数使用对抗性样本来破坏分类器的现有方法都以图像应用为目标(例如[19,30,35])。关于规避基于深度学习的网络入侵检测的研究很少。Wang等人采用了四套为图像分类而设计的白盒攻击算法,以绕过在NSL-KDD数据集上训练的基于MLP的入侵检测器[49]。他们的实验表明,这些攻击算法可以转移到NID域,MLP检测器容易受到敌对样本的攻击。然而,攻击者可能无法访问支持目标NID的神经模型,这使得此类设置对于NID设计者评估其系统的鲁棒性更为有用[28]。
Yanget al.使用三种方法,即代理模型[8]、零阶优化(ZOO)[10]和生成性对抗网络(GANs)[3],在黑盒设置中生成对抗样本[51]。这些方法会降低基于MLP的分类器的性能,从而对NIDS构成威胁。Kuppaet al。考虑一个更现实的情况,在基于决策和查询受限的设置中执行针对不同的基于深度学习的检测器的黑盒攻击[28 ]。通过学习和逼近良性和异常样本的分布,这些方法能够以较高的成功率避开NIDS。
2.3 Defending from Adversarial Samples
存在一系列的策略来保护深度学习模型不受对抗性例子的影响。常用的方法包括网络蒸馏[37]、对抗训练[45]、对抗检测[31]、输入重构[40]、分类器鲁棒化[2]、网络验证[26],以及它们的集合[33,54],这些方法可以是被动的,也可以是主动的。网络蒸馏方法使用一个学生神经网络从一个更复杂的教师网络学习知识。采用这种方法,学生网络泛化得更好,对敌对样本的鲁棒性更强。对抗训练通过在原始训练集上增加对抗样本来对神经网络进行再训练,这样神经网络就能更好地抵御那些具有微妙特征扰动的输入。输入重构通过恢复原始输入来降低扰动的有效性。分类器鲁棒化采用多种方法(如模型集成)来提高原分类器的鲁棒性。网络验证使用额外的分类器来识别对抗样本。
虽然这些方法在计算机视觉和自然语言处理领域是有效的,(i) carlinet的工作证明了针对成像中的对抗性例子的防御机制可以通过构建新的损失函数[7]来击败,而(ii)这些都不是针对NIDS中对抗样本的防御,这是本文要解决的问题。
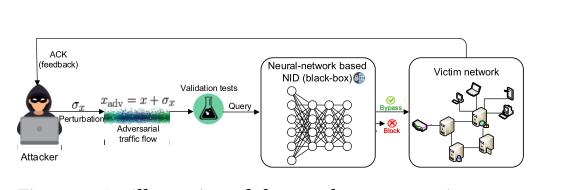 图2:对基于机器学习的NID模型的攻击过程示意图
图2:对基于机器学习的NID模型的攻击过程示意图
3 THREAT MODEL
我们关注的场景是,攻击者通过向NIDS输入添加小扰动来生成对抗样本,从而导致错误分类并逃避对其恶意流量的检测。在[24]中,我们用x表示分类器的输入(即从流中提取的特征),一个对抗性的样本xadv =x + σx,目标类是 yadv 。对抗性攻击的目的可以表述为寻找xadv,例如||xadv - x||∞<ε,同时xadv属于类yadv。这里,σx是添加到输入的扰动,ε限制扰动规模
3.1 Adversarial Settings
针对机器学习模型的典型攻击可分为三类:(i)白盒攻击,(ii)灰盒攻击,(iii)黑盒攻击。白盒和灰盒攻击假定恶意行为者能够访问训练数据或/和模型结构。这种假设适用于系统设计人员试图提高其NIDS的稳健性的情况,但很少适用于有外部对手的情况。在最好的情况下,恶意行为者可以对自己的模型进行白盒攻击,然后寻求将这些攻击转移到受害者NIDS上。更常见的情况是,潜在的黑客被迫将NIDS视为一个黑盒子,因为受害者系统的内部工作细节仍然隐藏着,而了解NIDS行为的唯一方式是通过一系列查询和接收到的反馈。这也是我们在这项工作中考虑的主要实际威胁模型,而我们提出的防御机制也可以抵御来自白盒方法的对抗性样本,正如我们所揭示的。
一般情况下,攻击者可以向目标网络发送流量流,该流量流首先由NID模型进行检查。这被称为查询过程。随后,攻击者将从模型中得到隐式/显式的反馈,如ACK报文,反映流量是否属于异常流。基于这种反馈,攻击者可以对恶意流量进行调整并施加微妙的扰动,从而产生对抗样本,最终可能会损害入侵检测系统的有效性,最终将恶意流量分类为良性流量。另一方面,攻击者可能对NIDS决定的精确决策类没有信心,但可能对流量被认为是恶意的还是良性的(基于决策的攻击)。我们在图2中演示了针对NID模型的攻击过程。
3.2 Domain Constraints
与针对图像分类器的对抗性攻击不同,针对NID的对抗性样本必须遵守某些域约束[28],以便在引入扰动σx时保持样本的功能性和完整性. 这意味着(i)只有一部分功能是可以修改的;(ii)对抗样本的特征不违反原始样本固有的属性。为了满足这些需求,这里我们将考虑限制在22个基于时间的特性上,正如[28]中建议的那样,我们在这些特性上添加了扰动。这些包括这些包括(a)前向到达间时间–在前向方向上发送的两个数据包之间的时间(平均值、最小值、最大值、标准值)(b) 反向到达时间–反向发送的两个数据包之间的时间(平均值、最小值、最大值、标准值);(c) 活动空闲时间–流在变为活动之前处于空闲状态的时间量,反之亦然(平均值、最小值、最大值、标准值)(d)在初始窗口或/和子流中向前和向后方向发送的平均字节数和包数。可以想象,攻击者也可能试图模仿良性流的时间特性,并在有效负载中隐藏恶意内容(例如SQL注入、跨站点脚本等)。在这种情况下,我们的Tiki-Taka框架也可以用于基于有效载荷的特征提取,例如通过单词嵌入或Text-CNNs[34]。在攻击过程中,可能改变流语义的子集之外的特征保持不变,这与最近的研究一致,即只要扰动输入特征[43]的一小部分就可以有效地构建对抗样本。
此外,我们期望(i)每个特征 k 的平均绝对百分比误差(MAPE)不超过20%,即100· |(x(k) - x(k)adv) / x(k)| ≤20%;(ii)扰动特征保持平均特性(例如,平均前向到达间隔时间)+ / - std特征不超过其相应的最大值和最小值特征;(iii)每个扰动样本的符号与原样本的符号保持一致;(iv)当std特征为零时,对应的均值、最大值、最小值和std特征在对抗样本中保持不变。违反这些限制的样品将被视为不成功的试验,因为它们改变了流的最初预期功能。在为我们的研究制作对抗性攻击时,我们还将基于这些约束条件执行验证测试。
4 DATASET
我们使用公开可用的CSE-CIC-IDS2018数据集[42]进行所有实验(例如,NID、黑箱对抗攻击,以及使用所提议的防御增强的针对NIDS的攻击)。这包括14种类型的网络入侵流量和良性流量。网络攻击可分为暴力破解、心脏出血、僵尸网络、DoS (Denial of Service)、DDoS (Distributed Denial of Service)、Web和渗透等7类。表1总结了每种流量的流行程度。使用的基础设施包括50台机器,它们试图入侵一个由420台终端主机和30台服务器组成的受害者网络。
我们总共提取了80个流量特征来进行入侵检测,我们在工作中过滤了其中65个。选择的特征可以分为8类,具体如下:
(a)Forward Inter Arrival Time -两个包在Forward方向上发送的时间间隔(mean, min, max, std);
(b)Backward Inter Arrival Time -两个数据包反向发送的时间(mean, min, max, std);
©Flow Inter Arrival Time –两个数据包在任意方向发送之间的时间(mean, min, max, std);
(d)Active - idle Time -一个流在变为活动之前处于空闲状态的时间量(平均值,最小值,最大值,std)和一个流在变为空闲状态之前处于活动状态的时间量(平均值,最小值,最大值,std);
(e)Flags based features –URG, PSH标志被设置的次数,包括向前和向后的次数;
(f)Flow characteristics –每秒字节数,每秒包数,流长度(平均,最小,最大,std)和下行和上行发送的字节数的比率;
(g)带有FIN、SYN、RST、PUSH、ACK、URG、CWE和ECE标志的包计数;
(h)初始窗口中向前/向后方向发送的平均字节数和包数、bulk rate和子流计数。我们的框架很容易扩展到其他类型的特性,例如,从有效负载[34]提取。

我们训练所有的深度学习模型,使用选定的特征实现和防御对抗性攻击。
5 TRAINING INTRUSION DETECTORS
训练精确的深度网络入侵检测器是我们研究的第一个重要步骤,asTiki Takaki建立在预先训练好的NID模型之上。为此,我们采用了三种众所周知的深度学习架构,即多层感知器(MLP)[16]、卷积神经网络(CNN)[59]和具有长短时记忆(LSTM)层的CNN,即C-LSTM[60]。


这些模型经常用于NID目的,并取得了显著的性能。我们在图3中说明了每个模型的体系结构。
MLP是最简单的深度学习体系结构,它使用多个完全连接的层堆栈进行特征提取。它特别适合处理具有混合类型特征和范围的交通流。在我们的研究中,我们构建了一个包含3个隐藏层的MLP。除最后一个隐藏层有400个单元外,每个层有200个单元。CNN具有良好的空间感知能力,在NID任务中表现出显著的精确度[59]。在这项工作中,我们设计了一个具有10个一维CNN层的CNN,每个层配备108个滤波器,滤波器尺寸为5。最后,我们复制了[60]中使用的C-LSTM,我们的C-LSTM在描述流量特征的特性上运行,而不是在原始流上运行。C-LSTM结合CNN和LSTM结构分别提取空间和时间特征。数据将首先由一个有5个隐藏层的CNN处理,然后传递到一个2层LSTM进行最终预测。每个LSTM层有160个单元。我们执行NID,即黑匣子对抗性攻击,然后根据这些模型对其进行防御,我们将在下面详细介绍。
我们在两种不同的情况下考虑NID,即(i)一对全检测和(ii)一对一检测。“一对全”场景将所有类型的攻击归为一个单一的“异常”类,这将导致一个有监督的二进制分类问题。而一对一检测器则将每一次网络攻击(共14次)分成单独的类,并进行多类分类。在我们的研究中,除了最后一层的变化外,这两种情况都采用了相同的神经网络架构,因为它们的数量直接取决于用于识别的类的数量。按照惯例,我们使用80%的数据集训练和验证所有模型,并在20%的数据集上进行测试。所有模型都是通过Adam优化器[27]最小化交叉熵损失函数来训练的。超采样用于处理数据集固有的良性和恶意流量之间的类不平衡。
所有模型都在一个配备一个或多个Nvidia TITAN X, Tesla M40或/和Tesla P100 gpu的并行计算集群上进行培训和评估。神经模型使用TensorFlow[1]和TensorLayer[14]包在Python中实现。
5.1 One-to-all NID Performance
我们使用四个指标量化NIDS的性能,即准确性、精确度、召回率和F1分数,如表2所示。这些指标经常用于评估二进制分类器。
观察到所有模型都达到了很高的检测性能,所有F1分数都在0.960以上。此外,考虑的三个模型表现相似,因为每个模型获得的F1分数之间的差异从未超过0.01。这与最先进的基于深度学习的NID解决方案的性能相匹配,因此我们使用的模型可以被认为是“可靠的”。
5.2 One-to-one NID Performance
一对一入侵检测系统旨在将每种流量划分为14种异常和良性类型。我们使用相同的神经网络,这次使用归一化混淆矩阵来评估它们的性能,如图4所示。对角线元素表示预测标签与真实标签相等的点的比率,而非对角线元素表示误分类比率[38]。因此,每行元素的和为1。混淆矩阵中的对角线值越高,性能越高,表明许多正确的预测。
观察到,由于对角线值接近1,所有NID模型对大多数类型的异常都具有较高的检测精度。然而,仔细观察暴力XSS、SQL注入、渗透和暴力Web攻击,NID模型似乎倾向于将其错误分类为“良性”。此外,所有DNN在处理DoS攻击SlowhtTest和FTP暴力时都面临困难,因为它们大约50/50地混合使用。此外,C-LSTM将几乎所有DDoS攻击HOIC流量错误分类为DDoS攻击LOIC HTTP。这可能不那么重要,因为这两种攻击都属于DDoS类别。总的来说,MLP、CNN和C-LSTM达到98。4%, 98. 3%和98%。3%的分类准确率,与一对多方案中观察到的性能相当接近。
在接下来的内容中,我们将证明,尽管所考虑的NID解决方案在检测精度方面似乎是可靠的,但它们很容易通过一系列干扰和查询而受损,而不需要了解底层模型。
6 ADVERSARIAL ATTACKS AGAINST NIDS
我们考虑五个最先进的黑盒攻击方法,我们用来产生对抗样本,并妥协在SEC中讨论的预先训练的深度异常检测器。5.这些攻击包括(i)自然进化策略(NES)[24],(ii)BoundaryAttack[5],(iii)PointwiseAttack[41],(iv)HopSkipJumpAttack[9],(v)Opt-Attack[12],所有这些攻击最初都是为了破坏图像分类器而设计的。我们根据不同的指标量化了它们的性能,并仔细检查了不同特征在对抗性样本生成过程中的作用,以及每个NID模型的决策机制。
6.1 Black-box Adversarial Attack Methods
我们首先总结了针对NID使用的每种对抗性攻击技术的操作。
NES[24]是机器学习模型的黑盒梯度估计方法。估计梯度可用于投影梯度下降(如白盒攻击中使用的),以构造对抗性示例。这种方法不需要代理网络,因此在制作对抗性示例时,查询效率更高且更可靠。值得注意的是,NES在基于决策的环境中工作良好,这使得它们适合攻击NID模型。
BoundaryAttack[5]是一种通过拒绝采样遵循对抗性和非对抗性样本之间决策边界的方法。在每个步骤中,它使用受限制的独立同分布样本并遵循高斯分布,从一个大的扰动开始,不断地减小扰动直到成功。这种攻击非常灵活,可以适应一组敌对标准。
PointwiseAttack[41]是一种简单的基于决策的攻击方法,它贪婪地最小化原始样本和敌对样本之间的L0-范数。在图像应用中,它首先引入 salt-and-pepper噪声直到错误分类,然后重复迭代每个受干扰的像素,如果受干扰的图像仍然具有对抗性,则将其重置为初始值。我们实现了一种类似的方法来攻击NID模型,但用加性高斯噪声代替 salt-and-pepper 噪声,以更好地适应网络流量。
HopSkipJumpAttack[9]是一种无超参数、查询高效的攻击方法,主要包括三个步骤:(i)梯度方向估计,(ii)通过几何级数进行步长搜索,以及(iii)通过二进制搜索方法进行边界搜索。它适用于更复杂的设置,如不可微模型或离散输入转换,并在多种防御机制下实现竞争性能。
Opt-Attack[12]将基于决策的攻击投射到一个连续优化问题中,并通过随机零阶梯度更新来解决它。特别地,采用无随机梯度(RGF)方法寻找适当的扰动并收敛到平稳点。由于 Opt-Attack 攻击不依赖于梯度,因此它可以攻击除神经网络之外的其他不可微分类器,例如,梯度提升决策树。
我们使用一个修正版本的平均绝对百分比误差来量化每个未修正样本 x 和其对抗性版本 xadv 之间的偏差,即:其中N为x中扰动特征的总数,x(k)和x(k)adv分别为原始样本和对抗样本的kth特征。较小的MAPE表明原始输入x和对抗样本xadv之间具有较高的相似性。
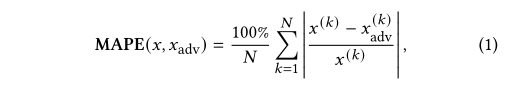
6.2 Attack Performance
我们从测试集中随机选择50,000个恶意流量,来制作对抗样本。我们使用四个性能指标量化每种攻击方法的性能,即攻击成功率(ASR)、平均良性置信度、MAPE和平均查询数。ASR被广泛用于评估对DNNs[30]的对抗性攻击的有效性,并通过成功对抗性样本的数量和总攻击尝试(在我们的案例中为50,000)之间的比率来衡量。当且仅当底层算法收敛,且对抗样本满足3.2节讨论的约束条件时,攻击尝试是成功的。平均良性置信度表示模型预测敌对样本xadv为良性的概率。较高的置信度意味着模型对在样本上做出的决策更有信心。MAPE在Eq.(1)中定义,并计算超过22个允许摄动的特征。回想一下,较低的MAPE代表原始样本和敌对样本之间较高的相似性。查询的数量表明攻击者为了生成一个成功的对抗样本应该执行多少次尝试。这可以用来衡量攻击方法的效率。查询的数量越多,可能会触发NIDS,使攻击更容易被检测到。注意,每个攻击方法和NID模型的MAPE、良性置信度和查询数量都是根据成功的攻击尝试计算的平均值。所有的攻击都是使用原始实现和Python愚箱[39]进行的。


由于篇幅的限制,在本文的其余部分,我们主要关注一对一场景
一对一场景中的攻击性能:我们在图5中展示了针对不同NID模型的每种攻击的统计数据。注意,除了在不同的NID模型之间性能相似的情况外,ASR在所有其他攻击方法的模型之间是不同的。这是因为模型使用大量的类,这使得很难制作对抗样本来匹配目标的“良性”标签。pointwismethod获得最高的ASR,最低的MAPE和更低的平均查询数。这表明这种方法在一对一的环境下是有效的。C-LSTM似乎是对抗样本最健壮的模型,因为所有攻击方法对这个NID模型获得的ASR值最低。尽管在对抗样本中获得了最高的良性置信,nesas获得的平均ASR最低。一般来说,他们还需要更多的询问来制作一个对抗性的样本。
在图6中,我们展示了在相同的一对一场景中考虑的每种恶意流量流的ASR。结合图4分析这些结果,可以发现检测率低的异常(例如Brute Force-XSS、SQL Injection、Infiltration、Brute Force-Web)更容易被攻击者伪装。这是因为对于这些流类型,模型已经有了模糊的决策边界,因此更容易被操纵。攻击者在对DoS攻击(hulk、-GoldenEye、-Slowloris、DDoS攻击(loic - udp))进行对抗样本制作时,ASR最低,因为NID模型对这些异常的检测率较高。
6.3 Adversarial Samples Analysis
6.3.1 Feature-wise MAPE。通过在图7中显示所有NID模型和攻击方法中所有成功攻击样本上的每个扰动特征的平均MAPE,我们更深入地研究生成的对抗样本。观察这两种检测场景,活动/空闲时间(即流在变为活动之前的空闲时间和流在变为活动之前的活动时间)受到的影响较小,因为相关特征在攻击过程中几乎没有变化。相比之下,那些描述在初始窗口或/和子流中向前和向后方向发送的平均字节数和包数的特征会受到更明显的干扰。这表明这些特性对NID模型的决策影响最大,因此更有可能被潜在的攻击者利用。

6.3.2 t-SNE Visualization。我们还研究了每个NID模型的内部工作,通过可视化其隐藏层的输出嵌入,以便更好地理解神经网络如何“思考”良性、恶意和敌对样本。为此,我们采用t分布随机邻居嵌入(t-SNE)[32],将每个模型最后一层隐层的维数降为2。在图8中,我们绘制了10,000个良性样本(蓝色)、10,000个敌对样本(绿色)和它们对应的用于生成它们的异常样本(粉色)的隐藏表示的t-SNE嵌入(x, y axes),以及它们的良性置信(z axis)。注意,当一个样本的良性置信度大于0.5(在决策平面之上)时,该样本将被认为是良性的。通常,t-SNE方法将具有较高相似性的数据点组织成附近的嵌入[55]。因此,它可以反映模型如何“思考”数据样本,因为类似的数据表示将聚集在一起。
观察到,通过对所有NID模型的t-SNE嵌入,可以清楚地将异常样本与良性样本区分开来。对抗性攻击的目的是通过将恶意样本带过决策边界而导致错误分类。这反映在图8中,因为敌对样本的t-SNE嵌入更接近良性嵌入簇,而它们在本质上仍然是异常的。这成功地混淆了NID模型,使敌对样本难以区分。此外,良性置信度较高的敌对样本通常更接近良性嵌入簇。
7 DEFENDING AGAINST ADVERSARIAL ATTACKS
对抗性攻击的防御机制应提高深度学习模型对对抗性样本的鲁棒性,从而降低其受到攻击的可能性,并降低不同攻击的ASR。一般而言,对抗性示例的对策可分为两类[54]:(i)反应性–在DNN接受培训后检测对抗性示例;(ii)主动-提高DNN模型对对抗性示例的鲁棒性。在本文中,我们提出了三种不同的防御机制,并将它们结合起来,以抵消上一节讨论的黑盒攻击方法产生的对抗性样本。这些防御机制包括:
(1) 模型投票集成(主动):使用投票机制对预先训练的MLP、CNN和C-LSTM进行集成,以构建更强大的模型,从而减少对手样本的错误分类;
(2) 整体对抗训练(主动):用对抗性样本扩充训练数据集,并重新训练NID模型,从而增强其对抗对抗性样本的能力;
(3) 对抗性查询检测(被动):在黑盒攻击过程中检测查询过程,以便在攻击者成功之前将其IP地址列入黑名单。
在下文中,我们详细介绍了拟议的防御机制,并展示了它们在对抗性攻击中的有效性。
7.1 Model Voting Ensembling
我们在第二节中报道的实验。6表示攻击者可以成功破坏具有高达35%ASR的NID模型。然而,只有一小部分对抗性样本可以同时绕过所有三个NID模型。这促使我们将所有这些结构结合起来,构建一个新的融合模型[56,57],以加强抵御潜在攻击的屏障。具体来说,对于每个输入流量,我们分别收集所有NID模型的决策,并使用投票过程进行分类。



如果所有模型达成共识,即所有模型都将流归为“良性”流,则该流将被归为“良性”流。否则,流量将被视为“异常”。我们认识到使用这种模型投票集成作为防御手段的几个优点,即:
(1) 为了构建成功的对抗性样本,攻击者需要同时击败所有NID模型,这比破坏单个NID模型要困难得多;
(2) 投票机制使得整个模型不可微,因此依赖于模型梯度估计的攻击方法(如NES)将受到阻碍;
(3) 投票机制易于实现,因为它不需要重新训练原始NID模型。
所提出的模型投票置乱方法是一种主动的方法,因为它提高了预训练模型对对抗性样本的鲁棒性。我们在表3中展示了一对所有场景下的融合模型的NID性能,在图9中展示了一对一场景下的混淆矩阵。回顾表2和图4,观察到观察到,在两种检测场景中,与单个组件相比,ensembling模型获得了非常接近的性能,同时实现了较低的误报率,因为它需要一致意见才能做出“良性”分类决策。
我们在同一组50000个恶意样本上重新运行了之前考虑过的五次黑盒攻击,并在图10中显示了它们的性能统计数据。请注意,良性置信度量已被放弃,因为集合模型的输出不再是概率。结合图5分析这些结果,观察到针对ensembling模型的每种攻击方法的ASR相对于攻击模型的每个组件(即MLP、CNN和LSTM)时有所下降。在最好的情况下,边界方法得到20。在一对一的情况下,攻击基于CNN的NIDS的ASR为1%,而其成功率仅为8%。攻击ensembling模型时为0%。在一对一的情况下,ASR的降低也是相当大的。这表明投票置乱机制是一种有效的防御方法。将注意力转向MAPE,观察到针对融合模型构建的对抗性样本产生较低的MAPE,这表明该防御机制对对抗性样本应用隐藏且更严格的约束,以防止它们过度偏离原始输入样本,从而提高检测。
在图11中,我们还以恶意流量类型为基础展示了ASR,针对一对一NID场景,针对ensembling模型制作对抗性样本。观察到投票置乱机制成功地保护了9种类型的对抗性样本,即。EBot、DoS攻击SLOWTTPTEST、DoS攻击Hulk、DoS攻击GoldenEye、DoS攻击Slowloris、FTP BruteForce、SSHBruteforce、DDoS攻击LOIC UDP和DDoS攻击LOIC HTTP,因为它们的ASR几乎为0%。对于像僵尸网络这样的攻击来说,这是至关重要的,因为任何成功都可能带来灾难性的后果,而这正是我们的融合技术所阻碍的。对于其他类型的恶意流量,ASR也会有不同程度的下降,但并没有那么显著,这需要进一步的防御,正如我们接下来所展示的。
7.2 Ensemble Adversarial Training (EAT)
如第3节所述。由于训练数据、模型结构和参数不透明,寻求妥协NIDS的外部对手通常无法使用白盒策略。然而,最近的文献证实,对抗性样本适用于不同的攻击方法和受害者模型[22,45,50]。因此,从防御者的角度来看,利用白盒攻击生成的对抗性样本可以提高NID模型的鲁棒性,从而抵御潜在的对抗性样本。因此,我们将整体对抗训练(EAT)作为一种额外的防御方法[45],它通过在其他静态预训练NID模型上精心编制的白盒攻击生成的对抗性示例来增强训练数据。随后,通过在扩充数据集上重新训练,对原始NID模型进行了增强。我们期望,通过建议的再培训,NID模型能够更好地对敌对样本进行分类,从而对攻击具有更强的弹性。
7.2.1 用白盒对抗样本加强NID模型 Reinforcing NID models with White-box Adversarial Samples.。我们随机选择25万个恶意流,使用三种最先进的白盒攻击方法生成对抗样本:
快速梯度符号法[18]、迭代攻击法(I-FGSM)[29]和动量迭代快速梯度符号法(MI-FGSM)[15]。基于FGSM的方法沿允许扰动的每个特征的梯度方向执行一步梯度更新,并在该方向后引入噪声。I-FGSM通过对多次迭代运行更精细的优化来生成有效的对抗性样本,从而扩展了FGSM。MI-FGSM在I-FGSM的迭代过程中引入了动量项,这有助于稳定更新方向并避免局部极值。这将导致更多可转移的对抗性样本。
由于攻击者和防御者之间的信息不对称,防御者不知道哪些特征会因攻击目的而受到干扰。因此,我们放宽了白盒设置中扰动的特征约束(见第3.2节)。然而,MAPE上的约束(≤保留20%),以限制扰动的规模。请注意,白盒攻击生成的对抗性样本不一定是有效的流量,因为它们仅用于训练目的。我们收集所有白盒攻击方法(即FGSM、i-FGSM和MI-FGSM)生成的成功对抗样本,在两种检测场景(即一对所有和一对一)中使用所有NID模型(即MLP、CNN和C-LSTM)构建,并将其与原始训练数据相结合,为EAT构建增强数据集。
我们在图12中显示了每个白盒攻击的性能。观察到,由于NID模型是透明的,并且对对抗性样本应用了更宽松的约束,因此所有白盒攻击的ASR明显高于黑盒攻击。白盒攻击还需要更少的查询来生成对抗性样本。幸运的是,攻击者通常无法访问NID模型。
7.2.2 NID Performance of Post-EAT Models.。在表4中,我们报告了EAT后同一测试集在一对所有场景中的检测性能。与EAT之前的NID模型相比(见表2和表3),新训练模型的检测性能在准确性、精密度和F1分数方面略有下降。但是,每种模型的召回率都有所提高。这表明该模型容易将一些模糊样本分类为异常,从而导致较高的假阳性率和较低的假阴性率。在一对一的情景中也观察到类似的现象。MLP、CNN、C-LSTM和ensembling模型的准确度似乎比EAT之前更差。然而,通过仔细查看图13中的混淆矩阵,post-EAT 模型对以前未能检测到的大多数异常实现了高检出率(即暴力XSS、SQL注入和暴力Web)。这表明EAT提高了NID模型的鲁棒性,使其对难以分类的异常流量更加敏感。




 7.2.3.Robustness to Old Adversarial Samples。在表5中,我们进一步显示了EAT前从模型中提取的对抗性样本的比例,这可能会影响相应的EAT后模型。观察到EAT也使每种模型对旧的对抗性样本更具弹性,因为这些比率明显低于100%。特别是只有38.06%的由旧C-LSTM制作的对抗性样本可以绕过整体对抗训练的C-LSTM。这意味着EAT使每个模型能够学习使用白盒攻击生成的对抗性样本的特征,从而修复旧设置中存在的一些“bug”。
7.2.3.Robustness to Old Adversarial Samples。在表5中,我们进一步显示了EAT前从模型中提取的对抗性样本的比例,这可能会影响相应的EAT后模型。观察到EAT也使每种模型对旧的对抗性样本更具弹性,因为这些比率明显低于100%。特别是只有38.06%的由旧C-LSTM制作的对抗性样本可以绕过整体对抗训练的C-LSTM。这意味着EAT使每个模型能够学习使用白盒攻击生成的对抗性样本的特征,从而修复旧设置中存在的一些“bug”。
7.2.4 The Effect of EAT。在图14中,我们展示了在EAT (ASREAT,图中上部的条形图)之后的每一次攻击的ASR,以及在一对一NID场景中,与应用EAT (ASR - ASREAT,图中下部的条形图)之前的ASR下降情况。在图中,x轴以下的正数表示采用EAT后ASREAT已经下降。我们观察到,在大多数模型中,每次攻击的ASR下降。这意味着EAT成功地提高了每个模型的稳健性,使它们更难以被妥协。 在一对一和一对一的NID场景下,ASR均值分别降至6.70%和5.78%。这对于实际上减少DoS和暴力破解类型的攻击特别有益。
7.3 Adversarial Query Detection
回想一下,所有黑盒攻击方法都依赖于对受害者模型的持续查询和收到的反馈。基于反馈,攻击者学会调整输入的扰动,从而破坏检测。扰动的规模通常很小,因此它们不会改变原始输入的本质。查询之间的这种内在相似性可以用来检测攻击。 因此,我们将查询检测[11]作为最终的防御机制。一旦查询被发现,则可以将攻击者的IP地址加入黑名单,防止潜在的威胁。
具体来说,对于每个IP地址,我们构建一个大小为B的缓冲区,以存储在预定义的时间段内源自该地址的流量流的特征。为了降低保存的特征的维数,并对流之间的相似度进行建模,我们采用深度相似编码器(DSE)[4],在更短的l2距离的低维空间中对相似的交通流进行编码。更准确地说,对于从给定IP地址发送的每个新流x,我们计算该流嵌入到缓冲区中的其他流之间的成对距离,计算k最近邻平均距离dxk .如果dxk低于阈值τ,即dxk <τ,这表明IP地址发送了过多的类似流量流,可以视为正在进行的攻击中的查询。当这种情况发生时,该IP地址可以被列入黑名单,从而消除了潜在的威胁。我们在图15中展示了查询检测机制的基本原理。
当检测到攻击时,该IP地址对应的缓冲区将被清除。此外,当查询检测表明有潜在的恶意参与者时,可以立即禁止他们的IP地址,或者在后续查询之后禁止他们的IP地址,正如[4]中建议的那样。这可以最大限度地减少攻击者对他们的攻击被检测到的时间的了解,因此降低了损害查询检测机制的概率。
7.3.1 Deep Similarity Encoder。基于查询检测的防御机制的核心组件是深度相似编码器[4],它是一种降低输入维数的神经网络。通过DSE嵌入后,不同的流在编码空间中的距离将会非常远,而相似的查询将会非常接近。因此,查询和流量变得更容易区分。
对于DSE,我们使用类似于图3的CNN,只是将最后一层替换为3个单元。这意味着每个交通流的嵌入是一个三维向量。我们将 ei = DSE(xi)表示为输入样本xi的嵌入。DSE可以通过最小化以下对比损耗函数来训练:
L(xi,x’i,xm, xn;θ)=||ei-e’i||22 + max(0,ω2 -||ei-e’i||22) (2)
在这里,xi,x’iB是一对相似的流量,而xm, xn是不同的流量。θ为DSE的可训练参数集,ω为常数惩罚,将||em-en||22的尺度进行正则化。我们在实验中选择ω =0.5。该函数的第一项保证了相似流量的l2距离最小,而第二项保证了不同流量对的距离最大但限制为ω。
我们使用与其他NID模型相同的从CSE-CIC-IDS2018数据集采样的训练集来训练DSE。为了训练的目的,我们通过在每个样本 xi 中加入高斯噪声σi ~N(0, α|xi |)构造x’i,即x’i = xi+ σi 。这里,α 控制高斯噪声的标准差,我们选择α = 0.15。xm, xn是从一个与 xi 不同的训练集中采样的。在训练之后,我们使用完整的训练集随机生成13,153,902对相似和不同的流。
7.3.2 Hyper-parameters Selection.查询检测需要配置三个重要的超参数,即(i)检测阈值 τ ;(ii)用于检测的邻居 k 的数量;(iii)缓冲区 B 的大小,该缓冲区存储来自同一IP地址的流量。这些参数将显著影响查询检测的性能。首先,我们选择 τ =0.00157,因为训练集中有10%的不同对和86.4%的相似对低于这个阈值。这提供了一个适当的决策边界来区分正常流量和攻击查询。k的值和B 影响检测的鲁棒性和网络入侵检测系统的计算和存储成本。我们选择B=500和k=200,因为当使用整个训练集模拟的交通流运行时,这些数字允许有效检测并产生0误报率。
7.3.3查询检测防御性能。在图16中,我们显示了查询检测后每次攻击的ASR(顶部子图中x轴上方的条),与未使用查询检测时相比的ASR减少(顶部子图中x轴下方的条),以及检测到攻击时的平均查询数(底部),针对一对一NID场景中的每种攻击方法。观察到在使用查询检测后,ASR显著下降。特别是对于所有模型,NES的ASR均达到0,因此检测率达到100%。查询检测防御平均将攻击的ASR减少8。56%和12%。在一对一和一对所有情况下,分别为38%。实际上,大多数敌对攻击都是在查询过程中检测到的。

仔细观察检测到的查询的平均数量,我们发现NES、Boundary、Pointwise和HopskipJumpAttack攻击尝试在其201stquery中被检测到。
回忆这个 k 查询检测选择的邻域大小为200,因此只有当缓冲区的样本数超过200个时才会触发检测警报。这意味着在缓冲区关闭后立即检测到攻击 k 邻居的样品。关于Opt Attackattack攻击,这总是在208个查询中检测到的。这是由于攻击的初始阶段,当它注入一些良性流量以了解要添加到对抗样本中的扰动方向时。这些样本通常是不同的,这略微增加了检测时间。请注意,尽管查询检测机制效率很高,由于攻击可能会交替使用查询(类似的样本)和乱码流量(不同的样本)填充缓冲区,从而破坏防御,因此仍然需要更大的缓冲区(B = 500)大小来进行容忍。
总的来说,通过结合模型投票感知、EAT和查询检测机制,我们的方案可以成功地防止五种主流的黑盒对抗性攻击危及基于深度学习的NID。
8 CONCLUSIONS
在本文中,我们介绍了TIKI-Taka,一个针对基于深度学习的NIDS的对抗性攻击的框架。我们在一个公开的数据集上训练了三种最先进的深度学习模型(MLP、CNN和C-LSTM),然后采用5类基于决策的对抗性攻击来破坏神经模型。实验表明,尽管具有较高的检测率,但基于深度学习的网络入侵检测系统容易受到敌对样本的攻击。为了加强网络入侵防御系统对此类威胁的防御,我们提出了三种防御方法:模型投票加密、加密对抗训练和查询检测。 据我们所知, 这些是针对针对NID的对抗性攻击提出的第一个防御机制。它们的联合使用可以降低所有攻击的成功率,使大多数恶意流量的检测率接近100%,并抵御特别重要的恶意流量,如僵尸网络和DoS。 未来的工作将侧重于处理渗透流量,这似乎对NID模型和防御方法更具弹性。
分析
引入多种模型交叉是否会对内存要求过高,为了检测率的提高牺牲这么多的性能是否值得?模型如何优化














 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









