







grep -E == egrep: 支持扩展的正则表达式
grep: 基本正则表达式
fgrep: 不使用正则表达式
-o:只的是output:只输出匹配到的内容
一.元字符
基本正则表达式:
1、^: 代表……的开始
![]()
2、$: 代表...的结束
![]()
3、. : 任意的单个字符: . -> a, b, A, C, 1, ?, *, 都是任意的单个字符,
.代表任意单个字符,*代表之前的重复0次或任意多次。.*代表任意字符重复0次或任意多次
4、* : 代表的是*之前的正则表达式重复0次或任意多次
![]()
5、[str]: [abc] ->中括号的意思是字符集,[abc]:匹配单个字符:字符可以是a, 也可是b, 也可以是c

6、[^str]: [^abc] -> 取的是abc的补集, 除了abc之外字符

7、[a-b]: 代表字符集, 也是单个字符,但是单个字符可以是a-b之间的任意字符
[0-9], [a-z], [A-Z], 使用a和b之间必须是连续的0

8、\b匹配:匹配单词边缘的空字符串
\b, \<, \>:都不做真正的匹配,只是用来判断单词是不是独立存在

9、(s|t): 或运算
匹配0401-0419,精确匹配,只能匹配这个范围内的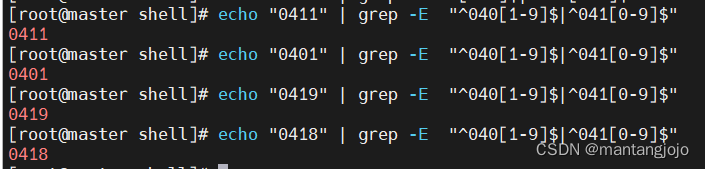
二.量词:贪婪和非贪婪
正则表达式默认为贪婪匹配(尽可能多的匹配)
在表达式后面加上?为非贪婪匹配(尽可能少的匹配)
扩展正则表达式:使用-E
-o:只输出匹配到的内容
-
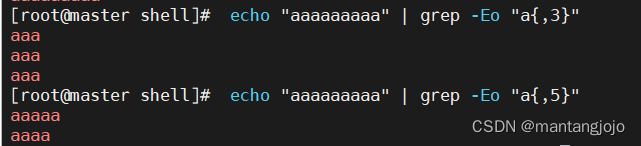
{n} 表示重复n次
-
{,m} 表示最多重复m次
-
{n,} 表示重复至少n次

-
{n,m} 表示重复至少n次,最多重复m次 --- 在匹配成功的情况下尽可能多的进行匹配

-
* 代表的是*之前的正则表达式重复0次到多次: 可以没有

-
+ 代表的是+之前的正则表达式重复1次到多次:最少有一个


-
? 代表的是?之前的正则表达式重复0次到1次:最少没有,最多一次

贪婪模式为尽可能多的去匹配(以上均为贪婪匹配)
在表达式的末尾加上?为非贪婪匹配

三.转义符:
\A: 匹配单词的开始
\b: 匹配空字符,单词开始或结束
\B: 匹配非空字符
\d: 匹配数字[0-9]
\D:匹配非数字

\s: 匹配空格,制表符,换行,记得使用-z --null-data: 使用ascii码中空字符来替换新行
\S: 匹配非空格字符

\w: 匹配数字,字母和下划线
\W: 匹配\w的补集
\Z: 匹配单词的结束 --- 相当于$用法
四.分组:"",和''
(): 如果一个正则表达式中出现了多个小括号,代表多个分组a(b(c(d)))e --- 3 个分组
自动编号: 从左到右去数左括号,第一个左括号:代表分组1,第二个左括号代表分组2, 一次类推
分组0去哪儿了?分组0: 匹配成功的整个字符串
引用的时候:使用\number来引用
(?:…): 非捕获版本,分组不能被引用
(?P<name>…) : 给分组命名
引用两种方式:通过组号引用:\number
通过组名引用:(?P=name)
(?#…): 注释,不参加匹配
(?=…) :正向预搜索,即判定条件, 它不消耗我们的分组: 只做判定条件不返回
windows10 windows98 windows99 -> 当windows后面是10的时候,给我返回windows, 说明了我们匹配的时候:windows10 -》 先去判定windows之后是10的话,匹配成功,且返回内容不包含10
(?!…): 对正向预搜索的取非, windows(?=10) -> windows(?!10)
(?<=…): 反向预搜索:
Linux8, window8, mac8 -> 如果我的8前面是Linux时候匹配成功,返回8,不消耗分组内容 (?<=Linux)8
(?<!…):对反向预搜索的取非:
取非(?<=Linux)8-> (?<!Linux)8, 8前面不是Linux的时候,匹配成功
(?(id/name)yes-pattern|no-pattern)
# id和name指的就是分组的组号和组名
如果这个分组可以匹配得到:执行yes-pattern, 匹配不到: 执行no-pattern















 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









