








在网络中,为了完成通信,必须使用多层上的多种协议。这些协议按照层次顺序组合在一起,构成了协议栈(Protocol STack),也称为协议族(Protocol Suite)。
协议栈形象的反映了一个网络中文件传输的过程:由上层协议到底层协议,再由底层协议到上层协议。使用最广泛的是英特网协议栈,由上到下的协议分别是:应用层(HTTP,TELNET,DNS,EMAIL等),运输层(TCP,UDP),网络层(IP),链路层(WI-FI,以太网,令牌环,FDDI等),物理层。
主要的协议栈:
OSI协议栈 OSI协议栈是由国际标准化组织(ISO),为提倡世界范围的互操作性而定义的。它通常被用于其它协议栈进行比较的标准。
NetWare SPX/IPX协议 NetWare串行分组交换/网间分组交换(SPX/IPX)协议,是由NovellNetWare使用的一种本质性协议(nativeprotocol)。它源于Xerox网络系统(XNS)协议栈。
TCP/IP协议组 传输控制协议/因特网协议(TCP/IP)是最早的网络协议栈之一。它最初是由美国国防部为将多厂商网络产品连接在一起而实现的。其中IP部分提供了一种对互联网络连接的最好定义,并且被许多厂商用于在局域或广域互联产品。
IBM/Microsoft协议组 IBM和Microsoft进行互联的产品通常是结合在一起的,这是因为这两个公司联合起来开发使用他们的产品,例如,L管理器和OS/2。
AppleTalk协议 AppleTalk协议是由Apple Computer为互联Apple Macintosh系统而定义的。
1:函数调用。协议栈各层之间通过函数调用来传递数据包和相关的数据结构。linux和bsd等开源系统采用这种方法。
2:消息传递。也就是基于流消息的协议栈构建方法。各层直接通过传递事件或消息来传递数据包和相关的数据结构。据说solaris和windows等商业操作系统采用这种方法。
3:包队列。各层直接通过包队列(queue)来连接,各层都实现为独立的进程或线程,通过轮询来收发数据包。线程主动去收发包,而不是通过事件来通知。有些系统的某些模块会采用这种方法。

uIP特性
uIP协议栈去掉了完整的TCP/IP中不常用的功能,简化了通讯流程,但保留了网络通信必须使用的协议,设计重点放在了IP/TCP/ICMP/UDP/ARP这些网络层和传输层协议上,保证了其代码的通用性和结构的稳定性。
由于uIP协议栈专门为嵌入式系统而设计,因此还具有如下优越功能:
(1) 代码非常少,其协议栈代码不到6K,很方便阅读和移植。
(2) 占用的内存数非常少,RAM占用仅几百字节。
(3) 其硬件处理层、协议栈层和应用层共用一个全局缓存区,不存在数据的拷贝,且发送和接收都是依靠这个缓存区,极大的节省空间和时间。
(4) 支持多个主动连接和被动连接并发。
(5) 其源代码中提供一套实例程序:web服务器,web客户端,电子邮件发送程序(SMTP客户端),Telnet服务器, DNS主机名解析程序等。通用性强,移植起来基本不用修改就可以通过。
(6) 对数据的处理采用轮循机制,不需要操作系统的支持。
由于uIP对资源的需求少和移植容易,大部分的8位微控制器都使用过uIP协议栈, 而且很多的著名的嵌入式产品和项目(如卫星,Cisco路由器,无线传感器网络)中都在使用uIP协议栈。
uIP架构
uIP相当于一个代码库,通过一系列的函数实现与底层硬件和高层应用程序的通讯,对于整个系统来说它内部的协议组是透明的,从而增加了协议的通用性。uIP协议栈与系统底层和高层应用之间的关系如图2-1所示。
从上图可以看出,uIP协议栈主要提供了三个函数供系统底层调用。即uip_init(), uip_input() 和uip_periodic()。其与应用程序的主要接口是UIP_APPCALL( )。
uip_init()是系统初始化时调用的,主要初始化协议栈的侦听端口和默认所有连接是关闭的。
当网卡驱动收到一个输入包时,将放入全局缓冲区uip_buf中,包的大小由全局变量uip_len约束。同时将调用uip_input()函数,这个函数将会根据包首部的协议处理这个包和需要时调用应用程序。当uip_input()返回时,一个输出包同样放在全局缓冲区uip_buf里,大小赋给uip_len。如果uip_len是0,则说明没有包要发送。否则调用底层系统的发包函数将包发送到网络上。
uIP周期计时是用于驱动所有的uIP内部时钟事件。当周期计时激发,每一个TCP连接都会调用uIP函数uip_periodic()。类似于uip_input()函数。uip_periodic()函数返回时,输出的IP包要放到uip_buf中,供底层系统查询uip_len的大小发送。
由于使用TCP/IP的应用场景很多,因此应用程序作为单独的模块由用户实现。uIP协议栈提供一系列接口函数供用户程序调用,其中大部分函数是作为C的宏命令实现的,主要是为了速度、代码大小、效率和堆栈的使用。用户需要将应用层入口程序作为接口提供给uIP协议栈,并将这个函数定义为宏UIP_APPCALL()。这样,uIP在接受到底层传来的数据包后,在需要送到上层应用程序处理的地方,调用UIP_APPCALL( )。在不用修改协议栈的情况下可以适配不同的应用程序。
uIP在MCS-51单片机上的移植
1.为此项目建立一个keil C工程,建立src目录存放源文件。
2.通过阅读uip-1.0\unix\main.c,了解uIP的的主循环代码架构,并将main.c放到src目录下。
3.仿照uip-1.0\unix\tapdev.c写网卡驱动程序,与具体硬件相关。这一步比较费点时间,不过好在大部分网卡芯片的驱动程序都有代码借鉴或移植。驱动需要提供三个函数,以RTL9019AS驱动为例。
etherdev_init():网卡初始化函数,初始化网卡的工作模式。
u16_t etherdev_read(void):读包函数。将网卡收到的数据放入全局缓存区uip_buf中,返回包的长度,赋给uip_len。
void etherdev_send(void):发包函数。将全局缓存区uip_buf里的数据(长度放在uip_len中)发送出去。
所以,收包和发包主要是操作uip_buf和uip_len。具体驱动分析可参考《第三章 网络芯片的驱动》。
4.由于uIP协议栈需要使用时钟,为TCP和ARP的定时器服务。因此使用单片机的定时器0用作时钟,每20ms让计数TIck_cnt加1,这样,25次计数(0.5S)满了后可以调用TCP的定时处理程序。10S后可以调用ARP老化程序。对uIP1.0版本,增加了timer.c/timer.h,专门用来管理时钟,都放到src下。
5.uIP协议栈的主要内容在uip-1.0\uip\下的uip.c/uip.h中,放到src下。如果需要ARP协议,需要将uip_arp.c和uip_arp.h也放到src下。
6.uipopt.h/uip-cONf.h是配置文件,用来设置本地的IP地址、网关地址、MAC地址、全局缓冲区的大小、支持的最大连接数、侦听数、ARP表大小等。需要放在src下,并且根据需要配置。在V1.00版本中对配置做了如下修改:
(1)配置IP地址,默认先关IP,在初始化中再设定。
#define UIP_IPADDR0 192
#define UIP_IPADDR1 168
#define UIP_IPADDR2 1
#define UIP_IPADDR3 9
#define UIP_NETMASK0 255
#define UIP_NETMASK1 255
#define UIP_NETMASK2 255
#define UIP_NETMASK3 0
#define UIP_DRIPADDR0 192
#define UIP_DRIPADDR1 168
#define UIP_DRIPADDR2 1
#define UIP_DRIPADDR3 1
(2)使能MAC地址
#define UIP_FIXEDETHADDR 1
#define UIP_ETHADDR0 0x00
#define UIP_ETHADDR1 0x4f
#define UIP_ETHADDR2 0x49
#define UIP_ETHADDR3 0x12
#define UIP_ETHADDR4 0x12
#define UIP_ETHADDR5 0x13
(3)使能ping功能
#define UIP_PINGADDRCONF 1
(4)关闭主动请求连接的功能
#define UIP_ACTIVE_OPEN 0
(5)将uip_tcp_appstate_t定位u8_t类型。
(6)由于单片机是大端结构,因此宏定义需要修改
#define UIP_CONF_BYTE_ORDER UIP_BIG_ENDIAN
(7)暂时不移植打印信息,先关闭
#define UIP_CONF_LOGGING 0
(8)定义数据结构类型
typedef unsigned char u8_t;
typedef unsigned int u16_t;
typedef unsigned long u32_t;
7. 如果使用keil C的小模式编译,需要在大部分的RAM的变量前增加xdata。
8.data为keil C的关键词,代码中所有出现data的地方(主要是参数、局部变量、结构体成员)改为pucdata或ucdata。
9.解决编译过程中的错误。uIP协议栈为C语言编写,编译过程中的问题比较少,并且容易解决。
uIP的主控制循环
通过实际的代码说明uIP协议栈的主控制循环。
void main(void)
{
/*省略部分代码*/
/*设置TCP超时处理时间和ARP老化时间*/
timer_set(&periodic_timer, CLOCK_CONF_SECOND / 2);
timer_set(&arp_timer, CLOCK_CONF_SECOND * 10);
/*定时器初始化*/
init_Timer();
/*协议栈初始化*/
uip_init();
uip_arp_init();
/*应用层初始化*/
example1_init();
/*驱动层初始化*/
etherdev_init();
/*IP地址、网关、掩码设置*/
uip_ipaddr(ipaddr, 192,168,1,9);
uip_sethostaddr(ipaddr);
uip_ipaddr(ipaddr, 192,168,1,16);
uip_setdraddr(ipaddr);
uip_ipaddr(ipaddr, 255,255,255,0);
uip_setnetmask(ipaddr);
/*主循环*/
while(1)
{
/*从网卡读数据*/
uip_len = etherdev_read();
/*如果存在数据则按协议处理*/
if(uip_len > 0)
{
/*收到的是IP数据,调用uip_input()处理*/
if(BUF->type == htons(UIP_ETHTYPE_IP))
{
uip_arp_ipin();
uip_input();
/*处理完成后,如果uip_buf中有数据,则调用etherdev_send 发送出去*/
if(uip_len > 0)
{
uip_arp_out();
etherdev_send();
}
}
/*收到的是ARP数据,调用uip_arp_arpin()处理*/
else if(BUF->type == htons(UIP_ETHTYPE_ARP)) {
uip_arp_arpin();
if(uip_len > 0)
{
etherdev_send();
}
}
}
/*查看0.5S是否到了,到了则调用uip_periodic处理TCP超时程序*/
else if(timer_expired(&periodic_timer))
{
timer_reset(&periodic_timer);
for(i = 0; i < UIP_CONNS; i++)
{
uip_periodic(i);
if(uip_len > 0)
{
uip_arp_out();
etherdev_send();
}
}
/*查看10S是否到了,到了则调用ARP处理程序*/
if(timer_expired(&arp_timer))
{
timer_reset(&arp_timer);
uip_arp_timer();
}
}
}
return;
}
uIP协议栈提供的主要接口
提供的接口在uip.h中,为了减少函数调用造成的额外支出,大部分接口函数以宏命令实现的。
1.初始化uIP协议栈:uip_init()
2.处理输入包:uip_input()
3.处理周期计时事件:uip_periodic()
4.开始监听端口:uip_listen()
5.连接到远程主机:uip_connect()
6.接收到连接请求:uip_connected()
7.主动关闭连接:uip_close()
8.连接被关闭:uip_closed()
9.发出去的数据被应答:uip_acked()
10.在当前连接发送数据:uip_send()
11.在当前连接上收到新的数据:uip_newdata()
12.告诉对方要停止连接:uip_stop()
13.连接被意外终止:uip_aborted()
ZigBee(IEEE802.15.4)是一种低速率(2~200kbps)WPAN IEEE标准,传输速率只有100kbps;同时,它又具有功耗低、架构简单、成本低的特点,满足多种无线要求,尤其在工控(监视器、传感器和自动控制设备)等领域更是显示出其独有的优势。
本文介绍了ZigBee技术及其协议栈的结构,并针对该协议栈中的内存管理和时间管理技术为ZigBee协议栈的设计了内存分类管理办法和基于时钟队列的软定时器模型,测试表明,该设计方法能够有效的提高ZIGEE协议栈稳定性和实时性。
1、前言
随着射频技术、集成电路技术的发展,无线通信功能的实现越来越容易,数据传输速度也越来越快。本文在分析了ZigBee网络特点的基础上,对ZigBee通信协议栈实现中的内存,时钟管理等关键技术进行了研究,并提出了相应的实现方案。
2、ZigBee技术及其优势
ZigBee技术是一种近距离、低复杂度、低功耗、低数据速率低成本的双向无线通信技术,主要适合于自动控制和远程控制领域,可以嵌入各种设备中,同时支持地理定位功能。
2.1 ZigBee协议栈结构
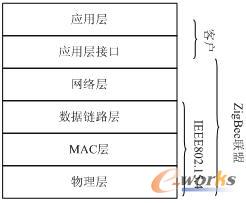
图1 ZigBee的体系结构
ZigBee Protocol STack体系结构如图1所示,它主要有5层体系组成。由ZigBee联盟与IEEE 802. 15.4的任务小组来共同担任标准的制定。其中物理层、MAC层标准主要由IEEE802. 15. 4的任务小组完成.而数据链路接层,以及传输过程中的网络层、还有与用户的接口是由ZigBee联盟主导。
在这个通信协议层次中,IEEE802.15.4/ZigBee各层协议的功能如下:
◆ 物理层。IEEE802.15.4运行在2.4 GHz ISM频段。采用直接序列扩频DSSS(Direct Sequence SpreadSpectrum)调制方式,以降低数字集成电路的成本,并且都使用相同的包结构,以便低作业周期、低功耗地运作。
◆ MAC层。负责处理所有的物理无线信道访问,并产生网络信号和同步信号,支持PAN连接和分离,提供两个对等MAC实体之间可靠的链路等。
◆ 网络接口层。负责处理ZigBee网络路由,实现网络地址和MAC地址的相互转换。
◆ 应用层。为用户应用进程间数据通信提供的接口。
发送时,ZIGBEE应用进程在调用应用层服务时,应该提供所有服务所需的参数;然后由应用层服务将数据经过编码后,传给网络接口层对象,调用网络层数据传输服务把数据发送出去。
接收时,应用层收到来自通信端口的数据后,上传给应用层服务;由应用层服务根据服务报文中的目的应用进程标识ID,将接收到的数据传送到应用层中相应的用户应用进程,由用户应用进程对相应的参量进行更新和进一步的处理。
2.2 Zigbee技术的主要优点
1) 省电。由于工作周期很短、收发信息功耗较低、并且采用了休眠模式, Zigbee技术可以确保2节五号电池支持长达6个月到2年左右的使用时间,当然不同的应用功耗是不同的。
2) 可靠。采用了碰撞避免机制,同时为需要固定带宽的通信业务预留了专用时隙,避免了发送数据时的竞争和冲突.MAC层采用了完全确认的数据传输机制,每个发送的数据包都必须等待接收方的确认信息。
3) 成本低。模块的初始成本估计在6美元左右,很快就能降到1. 5美元到2. 5美元之间,且Zigbee协议是免专利费的。
4) 时延短。针对时延敏感的应用做了优化,通信时延和从休眠状态激活的时延都非常短,设备搜索时延典型值为30 ms,休眠激活时延典型值是15 ms,活动设备信道接入时延为15 ms。
5) 网络容量大。一个ZigBee网络可以容纳最多254个从设备和一个主设备,一个区域内可以同时存在最多100个ZigBee网络。
6) 安全。ZigBee提供了数据完整性检查和鉴权功能,加密算法采用AES-128,同时各个应用可以灵活确定其安全属性。
3、ZIGBEE协议中的内存管理
嵌入式系统软件设计中采取的内存管理方案有两种――静态分配和动态分配。一般来说,嵌入式系统总是两种方案的组合,纯粹的静态分配一般只使用在不计成本来保证严格实时性的场合,而且静态分配容易使系统失去灵活性。考虑到ZigBee协议栈主要应用于低速率低传输量的网络设备中,所以我们在ZigBee协议栈设计中主要采用动态内存管理方式。动态内存管理机制在嵌入式软件设计是难点,也是直接关系到整个系统性能的关键,它必须满足以下几个特性:
- 快速性:为保证实时性,要求简单,快速地分配内存,有时候不需要过于复杂和完善。
- 可靠性:内存分配地请求必须得到满足,内存分配失败可能带来灾难性的的后果。
- 高效性:在嵌入式系统中,内存资源有限,所以必须高效的利用系统中有限的内存资源。
在ZigBee协议栈设计中,针对网络部分和非网络部分的内存需求,我们把整个系统内存分成报文缓冲区和通用缓冲区两个不同的区域。先从系统申请固定大小的静态内存做为报文缓冲区和通用缓冲区,在每块内存区上定义自身的内存分配和回收算法,通过这种设计,能够确保网络系统不使用系统全部可用内存,应用程序也不会使用网络已用内存,从而实现了内存区域隔离,也防止了协议栈耗尽所有系统内存,提高了系统的稳定性和可靠性。
3.1 报文缓冲区
ZigBee协议中用户数据从本地嵌入式设备传输到远程设备的过程中,要经过各层协议,对消息的封装,去封装和拷贝操作几乎是不可避免的。而通常所采用的用一段连续的内存区来存储,传递数据的做法会有一下的缺陷:
(1)当从上层向下层传递数据时,下层协议需要对数据进行封装,而上层在申请内存时不会考虑到下层的需要。这样就会导致下层协议处理时需要重新申请内存并进行内存拷贝,从而影响程序的效率。
(2)当从下层向上层传递数据时,下层协议专有的数据结构赢得对上层协议不可见。因此也需要重新申请内存进行拷贝。
(3)随着数据的逐层处理,其内容可能有所增删,而连续内存很难处理这样动态的数据增删。
因此,必须要有一种能适应数据动态增删,而在逻辑上又呈现连续性的数据结构,以满足各层之间的数据传递,而不是进行内存拷贝。因此在ZigBee协议栈设计中采取的报文内存管理方案必须满足以下要求:
(1)适合存放不同长度的数据。
(2)方便地操作变长缓存。
(3)尽量减少为完成这些操作所做的数据拷贝。
综合考虑系统效率和ZigBee网络报文的特点,在ZigBee协议栈设计中,我们设计的每个缓冲块的长度固定,大小以满足ZigBee网络中的大多数报文的长度为标准,这里我们设置每个缓冲块的长度为128字节,大于这个长度的报文,就用多个缓冲块形成的缓冲链来满足。
ZIGBEE_BUFFER类型的缓冲区是报文缓冲区,其内部结构如图2所示,该结构包括两个指针,两个长度域,其中next 域指针指向下一个ZIGBEE_BUFFER的缓冲块,pdata域指向ZIGBEE_BUFFER中的数据起始位,tot_len域包括整个数据链的数据长度,len域包含该缓冲块中的数据长度。ZIGBEE_BUFFER整个结构的大小取决域所使用的处理器体系结构中一个指针的大小及可能的最小alignment的大小。在带有32位指针和4个字节alignment的体系结构,整个的大小为16字节。

图2 ZIGBEE_BUFFER报文缓冲区
一个ZIGBEE_BUFFER链,如图3所示:
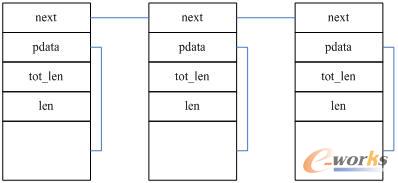
图3 ZIGBEE_BUFFER链结构
缓冲区的操作函数:
void buf_init( void );
zigbee_buf_t * buf_alloc( void );
zigbee_buf_t * buf_new(u16_t tot_len);
void buf_delete(zigbee_buf_t *buffer);
zigbee_buf_t * buf_adjust(zigbee_buf_t *buffer, s16_t flen, s16_t blen);
void buf_read(zigbee_buf_t *buffer, u8_t *pdata, u16_t *len);
void buf_write(zigbee_buf_t *buffer, u8_t *pdata, u16_t *len);
对报文缓冲区使用这种设计方法,能够实现从中断发送,到协议处理,用户接收等整个过程中,数据只需要一次拷贝,减少了对数据空间需求(不用频繁地进行数据硬复制),从而提高了ZIGBEE协议处理地实时性。
3.2 通用缓冲区
在ZigBee协议栈设计中,通用缓冲区管理的实现很简单,它分配和回收邻近的内存区域并且调整已分配的内存块。它使用系统中全部内存的特定区域, ZIGBEE_MEM类型的缓冲区是通用缓冲区,主要满足协议栈中与报文无关的内存需求。
在ZIGBEE_RAM内部,内存管理通过将一种小的结构放置在每一个被分配的内存块的顶端上来追踪分配的内存,这个结构(图4)设置两个指针指向内存中下一个和前一个分配块,还有一个flag标志用来指示这个内存块是否已经被分配。使用最先适用的原则,通过搜索一个未使用的内存块来分配内存。当一个内存块被释放时,flag标志被设为0,为了防止碎片,检测下一个和上一个内存块的flag标志,如果它们还没有被使用,几个块合并成一个大的未使用的块。

图4 ZIGBEE_RAM结构
4、ZigBee协议中的时钟管理
在ZigBee协议栈设计中,定时器的有效管理尤为重要,能不能对定时器进行合理的管理往往成为提高整个协议栈实时性能的瓶颈。对定时器的组织和管理最简单的方式是采取先进先出(FIFO)方式的链表单队列,这种组织管理方式会有一下两个问题:
(1)定时队列太长,找到所有到点定时器的时间开销难以接受;
(2)当定时器中断发生时要对所有的定时器的时长域进行减法操作,该部分时间性开销也很大。
另外,在实现ZigBee协议的芯片中,外设资源相对有限,为了使该协议栈能够广泛的应用于多种硬件平台,我们使用一个硬件定时器为基准时钟,然后在其基础上设计了简单递增时钟队列,以满足ZigBee系统对时间的要求。
在系统中,为每个任务分配申请一个简单相对递增时钟队列,队列中的定时节点按照定时时长排列有序,时长短的靠前,如图5所示,定时节点1的时长为5 ticks, 定时节点2的时长为2ticks, 定时节点3的时长为4ticks, 在队列中,定时节点的时长值改为相对前一定时节点时长的差值,即相对时长。当时钟中断发生时,只需对队头的时长域进行减1操作,所有的到点定时节点也均集中于队列的前面。
每个队列中又可以有多个时钟节点。逻辑时钟队列中,每个定时节点的数据结构如下所示:
typedef void (* timer_fun)(void *arg);
struct timer_node{
struct timer_node *next; /* 指向下一个定时节点 */
u32 time; /* 定时时间 */
timer_fun hander; /* 定时时间到后执行的函数 */
void *arg; /* 定时时间到后执行函数的参数 */
}
一个时钟队列如下图所示:

图5 ZIGBEE时钟队列
逻辑时钟队列的处理函数有:
void time_queue_init( void );
u8_t time_task_add(u32_t msec, time_fun hander, void *arg);
u8_t time_task_delete(time_fun hander, void *arg);
在ZIGBEE协议栈设计中,利用此种定时队列,能够使用一个基准定时器就可以简单,有效的实现确定性调度和时间同步所需的定时功能。
5、结论
本协议栈设计采用标准C进行开发,并在chipcON公司出产的cc2430芯片上进行了测试,测试结果表明:采用分类链式内存管理和相对递增时钟队列的内存和时钟管理方法的ZigBee通信协议栈通信过程稳定,速度快。
蓝牙协议栈就是SIG(Special Intersted Group)定义的一组协议的规范,目标是允许遵循规范的蓝牙应用应用能够进行相互间操作,图1-1就是完整的蓝牙协议栈和部分PROFILE:

图1-1
接着介绍下蓝牙里面PROFILE的定义,PROFILE既是配置文件,配置文件定义了可能的应用,蓝牙配置文件表达了一般行为,蓝牙设备可以通过这些行为与其它设备进行通信。蓝牙技术定义了广泛的配置文件,描述了许多不同类型的使用案例。按照蓝牙规格中提供的指导,开发商可以创建应用程序以与其它符合蓝牙规格的设备协同工作。 到目前为止,蓝牙一共有22个PROFILE,在这里我就不详细介绍图1-1的协议和每个PROFILE了。
在这里我想详细介绍下已经实现了r的协议栈。
Widcomm: 第一个windows上的协议栈,由Widcomm公司开发,也就是现在的BROADCOM .
Microsoft Windows stack: Windows XP SP2中包括了这个内建的协议栈,开发者也可以调用其API开发第三方软件。
TOSHIBA stack: 它也是基于Windows的,不支持第三方开发,但它把协议栈授权给一些laptop商(sony, asus等,我的本本上就是TOSHIBA的)。它支持的PROFILE有: SPP, DUN, FAX, LAP, OPP, FTP, HID, HCRP, PAN, BIP, HSP, HFP , A2DP, AVRCP, GAVDP)
BlueSoleil: 著名的IVT公司的产品,这个应该是个中国公司,值得自豪。该产品可以用于桌面和嵌入式,他也支持第三方开发,DUN, FAX, HFP, HSP, LAP, OBEX, OPP, PAN SPP, AV, BIP, FTP, GAP, HID, SDAP, and SYNC。
Bluez: Linux官方协议栈,该协议栈的上层用Socket封装,便于开发者使用,通过DBUS与其它应用程序通信。那么最近我的工作就是移植bluez 4.x到板子上。
Affix: NOKIA公司的协议栈,在Symbian系统上运行,具体的没找到资料
BlueDragon:东软公司产品,值得骄傲,好像2002年6月就通过了蓝牙的认证,支持的PROFILE:SDP、Serial-DevB、AVCTP、AVRCP-Controller、AVRCP-Target、Headset-AG、Headset-HS、OPP-Client、OPP-Server、CT-GW、CT-Term、Intercom、FT-Server、FT-Client、GAP、SDAP、Serial-DevA、AVDTP、GAVDP、A2DP-Source、A2DP-Sink。
BlueMagic:美国Open Interface 公司for portable embedded divce的协议栈,iphone(apple),nav-u(sony)等很多电子产品都用该商业的协议栈,BlueMagic 3.0是第一个通过bluetooth 协议栈1.1认证的协议栈,那么我现在就在用它,那么该栈用起来简单,API清晰明了。实现了的PROFILE有:HCI,L2CAP,RFCOMM,A/V,Remote,Control,A/V,Streaming,BIP,BPP,DUN,FAX,FTP,GAP,Hands-Free,and,Headset,HCRP,HID,OBEX,OPP,PAN,BNEP,PBAP,SAP,SPP,Synchronization,SyncML,Telephony,XML.
BCHS-Bluecore Host Software: 蓝牙芯片CSR的协议栈,同时他也提供了一些上层应用的PROFILE的库,当然了它也是为嵌入式产品了,支持的PROFILE有:A2DP,AVRCP,PBAP,BIP,BPP,CTP,DUN,FAX,FM API,FTP GAP,GAVDP,GOEP,HCRP,Headset,HF1.5,HID,ICP,JSR82,LAP Message AccessPROFILE,OPP,PAN,SAP,SDAP,SPP,SYNC,SYNC ML。
Windows CE:微软给Windows CE开发的协议栈,但是windows ce本身也支持其它的协议栈
BlueLet:IVT公司for embedded product的清量级协议栈。
ftp://ftp.FreeBSD.org/pub/FreeBSD- STable/src/sys.netinet
2:uC/IP是由Guy Lancaster编写的一套基于uC/OS且开放源码的TCP/IP协议栈,亦可移植到其它操作系统,是一套完全免费的、可供研究的TCP/IP协议栈,uC/IP大部分源码是从公开源码BSD发布站点和KA9Q(一个基于DOS单任务环境运行的TCP/IP协议栈)移植过来。uC/IP具有如下一些特点:带身份验证和报头压缩支持的PPP协议,优化的单一请求/回复交互过程,支持IP/TCP/UDP协议,可实现的网络功能较为强大,并可裁减。 UCIP协议栈被设计为一个带最小化用户接口及可应用串行链路网络模块。根据采用CPU、编译器和系统所需实现协议的多少,协议栈需要的代码容量空间在 30-60KB之间。
http://ucip.sourceforge.net
3、 LwIP是瑞士计算机科学院(Swedish Institute of Computer Science)的Adam Dunkels等开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。LwIP的含义是Light Weight(轻型)IP协议,相对于uip。LwIP可以移植到操作系统上,也可以在无操作系统的情况下独立运行。LwIP TCP/IP实现的重点是在保持TCP协议主要功能的基础上减少对RAM的占用,一般它只需要几十K的RAM和40K左右的ROM就可以运行,这使 LwIP协议栈适合在低端嵌入式系统中使用。LwIP的特性如下:支持多网络接口下的IP转发,支持ICMP协议,包括实验性扩展的的UDP(用户数据报协议),包括阻塞控制,RTT估算和快速恢复和快速转发的TCP(传输控制协议),提供专门的内部回调接口(Raw API)用于提高应用程序性能,并提供了可选择的Berkeley接口API。
http://sics.se/~sdam/lwip/
4、uIP是专门为8位和16位控制器设计的一个非常小的TCP/IP栈。完全用C编写,因此可移植到各种不同的结构和操作系统上,一个编译过的栈可以在几KB ROM或几百字节RAM中运行。uIP中还包括一个HTTP服务器作为服务内容。许可:BSD许用证http://dunkels.com/adam/uip/
5、TinyTcp 栈是TCP/IP的一个非常小和简单的实现,它包括一个FTP客户。TinyTcp是为了烧入ROM设计的并且现在开始对大端结构似乎是有用的(初始目标是68000芯片)。TinyTcp也包括一个简单的以太网驱动器用于3COM多总线卡http://ftp.ecs.sotON.ac.uk/pub/elks/utils/tiny-tcp.txt
一、lwIP 介绍
lwIP是瑞士计算机科学院(Swedish INStitute of Computer Science)的Adam Dunkels等开发的一套用于嵌入式系统的开放源代码TCP/IP协议栈。Lwip既可以移植到操作系统上,又可以在无操作系统的情况下独立运行.
二、lwIP移植介绍
整个移植过程主要参考网络上关于移植到ucos 的说明和源码。
1. 目录及文件介绍
原版的lwIP1.1.0包含两个目录src 和 doc
移植后增加如下文件和目录
[Arch]
Lib_arch.c本系统没用,系统中没有实现的C库函数可以写到这里
Sys_arch.c 移植的主要工作在这里,关于信号量、消息队列、任务创建
[RX4000] 项目目录
[Include]
[Arch]
cc.h 类型定义 大小端设置 PACK定义等
init.h
lib.h 跟Lib_arch.c对应 函数声明
perf.h 没用
sys_arch.h 跟Sys_arch.c对应的一些类型定义和宏定义
[Netif]
Dm9000a.h
Ne2kif.h
[Netif]
Dm_netif.c 网卡驱动与系统关联的抽象层
Dm9000a.c网卡的硬件操作函数
Ne2kif.c 没用
[Init]
Lwip.c 协议栈初始化和DHCP初始化
Lwipopts.h 协议栈相关参数设置
[Dns]
Dns.c 增加域名解析函数 gethoSTbyname (非可重入函数)
Dns.h
2. 移植相关函数介绍
1) sys_init
这个很简单,就是一些全局量的初始化
2) sys_thread_new sys_arch_timeouts
相关的三个全局变量如下
struct sys_timeouts lwip_timeouts[LWIP_TASK_MAX];
为每一个由sys_thread_new创建的任务分配一个存放信号量超时信息的列表
struct sys_timeouts null_timeouts;
为一个超过任务上限数的任务和不是由sys_thread_new创建的任务取超时列表时返回使用。
MMAC_RTOS_TASK_ID LWIP_TASKS[LWIP_TASK_MAX];
任务id存放顺序与lwip_timeouts相对应
sys_thread_new用来创建一个新的任务,保存任务ID。sys_arch_timeouts
就是通过取得任务ID返回任务对应的timeouts结构,从而可以添加、删除和判断超时的功能
3) sys_sem_new sys_sem_free sys_sem_signal sys_arch_sem_wait
sys_sem_new创建一个信号灯并初始化灯的数量返回sys_sem_t 类型的变量,定义是这样的typedef MMAC_RTOS_SEMAPHORE *sys_sem_t; 由于返回失败要返回NULL值所以就定义了系统信号量的指针为抽象信号量类型。因此在sys_sem_new和 sys_sem_free 分别要进行内存申请和释放的工作。
sys_sem_signal释放一个灯,sys_arch_sem_wait 等待信号,其中参数timeout是以ms为单位的,若wei零则表示永远等待一直到信号的来临。
在这个信号系统中本人还存在一个疑问,具体在5”存在的问题”中进行说明
4) sys_mbox_new sys_mbox_free sys_mbox_post sys_arch_mbox_fetch
同上原因在类型的定义成指针的。那sys_mbox_new 和sys_mbox_free同样要进行内存的申请和释放。在系统中消息队列发送和接收的都是指向数据的指针,因为在发送前所有的数据都已经存放在一个全局的用来管理内存的变量中。所以发送的内容就是四个字节。发送是还要判断发送msg是否为NULL。因为发送的是msg的指针,而不是内容还要取一下地址,NULL明显不能取址,所以有一个专门的static int *msg_null=NULL (这里的=NULL 并不重要可以使任何值 * 也可以不要,因为要的是变量的地址在内存中的唯一性)用来发送“NULL”信息,使msg = &msg_null再发送。接收到后也要进行 *msg ==&msg_null的判断。接收时也要进行msg NULL的判断,若msg为NULL就需要零时申请一个空间进行接收。还要注意发送和接收时msg的类型,发送是void* 的 ,接收是void **,要做好相应的处理。
3. 移植中相关配置的介绍
1) SYS_LIGHTWEIGHT_PROT
我的理解应该是是否使用系统临界区变量,由于本系统没有单独的临界区变量,所以就设置成 0 ,那就用信号灯来完成该任务。且sys_arch.h中的最后三个宏也要定义成空。
2) 累加和
关闭所有的累加检查,因为硬件已有该功能了
#define CHECKSUM_GEN_IP 0
#define CHECKSUM_GEN_UDP 0
#define CHECKSUM_GEN_TCP 0
#define CHECKSUM_CHECK_IP 0
#define CHECKSUM_CHECK_UDP 0
#define CHECKSUM_CHECK_TCP 0
3) LWIP_HAVE_LOOPIF
是否开启回环,在还没有网卡驱动的时候,可以设置为 1 添加loop设备进行调试运行。
4) 内存分配设定
在协议栈中很多内存都是事先申请的,有协议栈自己进行管理。据我了解有三大块内存PBUF MEMP MEM。在lwipopts.h中的Memory options中定义了各块内存的种类及各种类的数量。这部分的设置要仔细斟酌。具体就不再详述了。
5) TCP_SND_BUF
该设置对网络传输的速度由很大的影响。Ucos+lwIP的源码中的默认设置是256,用socket进行速度测试时却只有区区的1KB/S左右的速度。最后改成8192后速度达到 600KB/S。
6) LWIP_DHCP
本系统需要DHCP支持因此需要设置为 1。在他下面有一个DHCP_DOES_ARP_CHECK的宏设置为 0。 开启后出现错误。原因不明。
4. 移植中碰到的问题总结
1) 同时支持UDP及TCP及DHCP的支持
不再详述看出始化代码
void Task_lwip_init(void * pParam)
{
struct ip_aDDR ipaddr, netmask, gw;
sys_sem_t sem;
err_t result ;
int icount = 0;
int idhcpre=0;
#if LWIP_STATS
stats_init();
#endif
// initial lwIP stack
sys_init();
mem_init();
memp_init();
pbuf_init();
netif_init();
printf("LWIP:TCP/IP initiALIzing...\n");
sem = sys_sem_new(0);
tcpip_init(tcpip_init_done_ok, &sem);
sys_sem_wait(sem);
sys_sem_free(sem);
printf("LWIP:TCP/IP initialized.\n");
/*
//add loop interface //set local loop-interface 127.0.0.1
IP4_ADDR(&gw, 127,0,0,1);
IP4_ADDR(&ipaddr, 127,0,0,1);
IP4_ADDR(&netmask, 255,0,0,0);
netif_add(&loop_if, &ipaddr, &netmask, &gw, NULL, loopif_init, tcpip_input);
netif_set_default(&loop_if);
netif_set_up(&loop_if);
//*/
#if 0
IP4_ADDR(&gw, 192,168,0,2);
IP4_ADDR(&ipaddr, 192,168,0,186);
IP4_ADDR(&netmask, 255,255,255,0);
netif_add(&dm9if_if, &ipaddr, &netmask, &gw, NULL, dm9_netif_init, tcpip_input);
netif_set_default(&dm9if_if);
netif_set_up(&dm9if_if);
#else
IP4_ADDR(&gw, 0,0,0,0);
IP4_ADDR(&ipaddr, 0,0,0,0);
IP4_ADDR(&netmask, 0,0,0,0);
netif_add(&dm9if_if, &ipaddr, &netmask, &gw, NULL, dm9_netif_init, udp_input);//添加udp支持
printf("LWIP:waiting for neif init \n");
MMAC_RTOS_Sleep( 3500);
for(idhcpre = 0; idhcpre<4; idhcpre++ )//dhcp最多重试4遍
{
printf("LWIP:start dhcp request \n");
result = dhcp_start(&dm9if_if);//广播dhcp请求
IP4_ADDR(&ipaddr, 0,0,0,0);
for(icount = 0; (icount < 10) && (ipaddr.addr == 0); icount ++ )
{
ipaddr.addr = dm9if_if.ip_addr.addr;
MMAC_RTOS_Sleep( 1000);
} // if failed ipaddr = 0.0.0.0 ;timeout = 10 * 1000 ms
//等待dhcp是否接受到IP了
// add dns server ip
dns_add(0,&dm9if_if.dhcp->offered_dns_addr[0]);
dns_add(1,&dm9if_if.dhcp->offered_dns_addr[1]);
//不需要dns的去掉上面两句
dhcp_stop(&dm9if_if); //一次dhcp结束
if (ipaddr.addr != 0)
break;
}
gw.addr = dm9if_if.gw.addr;
ipaddr.addr = dm9if_if.ip_addr.addr;
netmask.addr = dm9if_if.netmask.addr;
//netif_remove(&dm9if_if);
netif_add(&dm9if_if_tcp, &ipaddr, &netmask, &gw, NULL, dm9_netif_init, tcpip_input);//添加tcp支持
netif_set_up(&dm9if_if_tcp);
netif_set_up(&dm9if_if);
netif_set_default(&dm9if_if_tcp);
#endif
sprintf(STRIPADDR,"%d.%d.%d.%d",ip4_addr1(&ipaddr), ip4_addr2(&ipaddr),ip4_addr3(&ipaddr),ip4_addr4(&ipaddr));
printf("LWIP:IPADDR = %s\n",STRIPADDR);
if (ipaddr.addr != 0)
{
//------------------------------------------------------------
//
// http thread, a web page can be browsed
// sys_thread_new(httpd_init, (void*)"httpd",TCPIP_THREAD_PRIO);
//------------------------------------------------------------
sys_thread_new(test_net, NULL, TCPIP_THREAD_PRIO);
}
/* Block for ever. */
sem = sys_sem_new(0);
sys_sem_wait(sem);
}
2)对齐问题
PBUF_LINK_HLEN 16
static u8_t ip_reassbitmap[MEM_ALIGN_SIZE(IP_REASS_BUFSIZE / (8 * 8))];
在调试的时候经常碰到内存访问错误的异常,最后查得原因是内存的起始地址不再4的倍数上,导致不能访问。因为内存申请时有字节数来的,有时要强制转换为某种结构。为了保证地址不错,PBUF_LINK_HLEN 定义为16,ip_reassbitmap的大小也变成4的倍数。因为它的大小不是4的倍数,就导致附近的内存分配起始不是4的倍数。这个解决办法由点不好,但是没有办法,我用 align 等声明没有作用。
3)大包ping问题
原因是以太网络中,最大允许的包大小为1514字节,若用pc机ping –l 2000 ip地址 测试,pc会把ip包分解成多个发送,lwIP接受后会把他数据合成方在pbuf中,并直接发送出去,可惜程序中不会把包分解发送。导致发送网络不允许的包。这样不但pc接受不到包,而且lwIP也出现问题。
解决方法,在发送的地方,若包大于1514就不给发送。虽然解决不了大包ping不通问题,但至少lwIP不会死。
5. 存在的问题
1)没有对应得任务释放函数,除非以后的任务都是一直存在不需释放的
2)DNS gethostbyname 的不可重入问题
3)DHCP_DOES_ARP_CHECK 设置为1 死机
4)信号量中timeout 管理的疑问
操作系统中本身带有的函数就已经有timeout参数了,用它多此一举。但想想是不是为了没有timeout的操作系统准备的呢。但它在运行过程中又没有使用到,也没有找到什么代码来确定某个sem已经超时,而仅仅使用了我使用嵌入式操作系统的timeout。
三、上层开发接口
1.Socket 接口 sockets.h
#define accept(a,b,c) lwip_accept(a,b,c)
#define bind(a,b,c) lwip_bind(a,b,c)
#define shutdown(a,b) lwip_shutdown(a,b)
#define close(s) lwip_close(s)
#define connect(a,b,c) lwip_connect(a,b,c)
#define getsockname(a,b,c) lwip_getsockname(a,b,c)
#define getpeername(a,b,c) lwip_getpeername(a,b,c)
#define setsockopt(a,b,c,d,e) lwip_setsockopt(a,b,c,d,e)
#define getsockopt(a,b,c,d,e) lwip_getsockopt(a,b,c,d,e)
#define listen(a,b) lwip_listen(a,b)
#define recv(a,b,c,d) lwip_recv(a,b,c,d)
#define read(a,b,c) lwip_read(a,b,c)
#define recvfrom(a,b,c,d,e,f) lwip_recvfrom(a,b,c,d,e,f)
#define send(a,b,c,d) lwip_send(a,b,c,d)
#define sendto(a,b,c,d,e,f) lwip_sendto(a,b,c,d,e,f)
#define socket(a,b,c) lwip_socket(a,b,c)
#define write(a,b,c) lwip_write(a,b,c)
#define select(a,b,c,d,e) lwip_select(a,b,c,d,e)
#define ioctlsocket(a,b,c) lwip_ioctl(a,b,c)
2.Dns 客户端 dns.h
struct hostent *gethostbyname(const char *name);















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









