









前言
有时候经常需要解析XML文件中的数据,将数据转化成Java中的对象,为了不重复编写代码,能否编写一个简单通用的XML解析类?即对于一般的XML文件,均可以解析成对应的Java对象?
SAX解析
SAX (Simple API for XML):该规范和DOM规范有着明显的区别,虽然SAX也是一套对XML文档进行分析的规范,但是其并不是基于XML文档的树形结构的,而是以数据流的方式,来先后处理所碰到的XML文档中的内容,由此我们可以推断出,SAX解析器肯定也不会象DOM解析器那样要把XML分析成树形数据结构后完全保存于内存中。事实的确如此,SAX解析器是顺序读取XML文档的内容,每碰到一个需要处理的内容就会出发一种类似于windows操作系统中消息系统的机制,也就是一种基于事件的处理机制,是一种回调的形式。SAX规范要求所有基于SAX规范的解析器,都有一套默认的事件处理函数,而用户都可以根据自己的需求来重写这些默认处理函数,从而按自己的要求处理当某事件发生时的工作。
综上所述,可以了解到SAX解析器不需要将XML文档全部读入内存后,才开始分析,SAX解析器工作时所消耗的内存比DOM解析器要少;由于SAX的特点,它不能全局的获取XML的结构,所以它不能够随意读取XML文档中的任意一个节点内容;同时也因为SAX是顺序的读取XML文档,然后根据所碰到的东西来出发特定的处理,这也决定了SAX不能对不存在的XML文档进行处理,也就是说SAX不能创建新的XML文档;同理,SAX不能通过找到特定的某个节点,来对其进行修改。
Java反射机制
Java反射说的是在运行状态中,对于任何一个类,我们都能够知道这个类有哪些方法和属性。对于任何一个对象,我们都能够对它的方法和属性进行调用。我们把这种动态获取对象信息和调用对象方法的功能称之为反射机制。
在这里,我们只需要用到反射机制中获取类属性的功能。例子如下:
User.java
package org.mao.reflect;
public class User {
private String name;
private String gender;
private String birthday;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getBirthday() {
return birthday;
}
public void setBirthday(String birthday) {
this.birthday = birthday;
}
}
Main.java
public class Main {
public static void main(String[] args) throws Exception{
// 通过User.class获取Class对象
Class clazz = Class.forName(User.class);
System.out.println(clazz);
// 创建类的对象
Object obj = clazz.newInstance();
// 获得字段
Field[] declaredFields = clazz.getDeclaredFields();
for (int i = 0; i < declaredFields.length; i++) {
System.out.println(declaredFields[i].getName());
}
// 获得单个字段
Field field = clazz.getDeclaredField("name");
// 字段有可能是私有的,这时候要设置为可访问
field.setAccessible(true);
// 给属性赋值 即: name = 张三
field.set(obj, "张三");
// 获得属性值,相当于 String name = user.name;
String name = (String) field.get(obj);
field.setAccessible(false);
System.out.println(name);
}
}

编写XML文件对应的JavaBean
假设有如下XML文件:Book.xml
<?xml version="1.0" encoding="gb2312"?>
<books>
<book id="p0001" bookcategory="文艺" amount="150" remain="80" discount="8.5">
<title>三国演义</title>
<author>罗贯中</author>
<publisher>文艺出版社</publisher>
<ISBN>0-764-58007-8</ISBN>
<price>80</price>
</book>
<book id="p0002" bookcategory="文艺" amount="300" remain="180" discount="8.7">
<title>红楼梦</title>
<author>曹雪芹</author>
<publisher>三秦出版社</publisher>
<ISBN>7805468397</ISBN>
<price>22</price>
</book>
<book id="p0003" bookcategory="文艺" amount="200" remain="175" discount="8.5">
<title>西游记(上下册)</title>
<author>吴承恩</author>
<publisher>人民文学出版社</publisher>
<ISBN>7020008739</ISBN>
<price>40.12</price>
</book>
<book id="p0189" bookcategory="计算机" amount="230" remain="160" discount="8.0">
<title>VB.NET程序设计语言</title>
<author>微软公司著</author>
<publisher>高等教育出版社</publisher>
<ISBN>7-04-013188-9</ISBN>
<price>86.00</price>
</book>
<book id="p0028" bookcategory="计算机" amount="100" remain="90" discount="7.5">
<title>JavaScript速成教程</title>
<author>Michael Moncur著</author>
<publisher>机械工业出版社</publisher>
<ISBN>7-111-09070-5</ISBN>
<price>28.00</price>
</book>
</books>
编写成对应的JavaBean:Book.java
public class Book {
private String id;
private String bookcategory;
private String amount;
private String remain;
private String discount;
private String title;
private String author;
private String publisher;
private String ISBN;
private String price;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getBookcategory() {
return bookcategory;
}
public void setBookcategory(String bookcategory) {
this.bookcategory = bookcategory;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
public String getRemain() {
return remain;
}
public void setRemain(String remain) {
this.remain = remain;
}
public String getDiscount() {
return discount;
}
public void setDiscount(String discount) {
this.discount = discount;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublisher() {
return publisher;
}
public void setPublisher(String publisher) {
this.publisher = publisher;
}
public String getISBN() {
return ISBN;
}
public void setISBN(String iSBN) {
ISBN = iSBN;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return "Book [id=" + id + ", bookcategory=" + bookcategory + ", amount=" + amount + ", remain=" + remain
+ ", discount=" + discount + ", title=" + title + ", author=" + author + ", publisher=" + publisher
+ ", ISBN=" + ISBN + ", price=" + price + "]";
}
}
实现SAX解析
新建一个类XmlParseHandler.java,该类需要继承DefaultHandler或者实现ContentHandler接口,这里我们通过继承DefaultHandler(实现了ContentHandler接口)的方式,该类是SAX解析的核心所在,要重写以下几个我们关心的方法。
- startDocument():文档解析开始时调用,该方法只会调用一次
- startElement(String uri, String localName, String qName,
Attributes attributes):标签(节点)解析开始时调用- uri:xml 文档的命名空间
- localName:标签的名字
- qName:带命名空间的标签的名字
- attributes:标签的属性集
- characters(char[] ch, int start, int length):解析标签的内容的时候调用
- ch:当前读取到的TextNode(文本节点)的字节数组
- start:字节开始的位置,为0则读取全部
- length:当前TextNode的长度
- endElement(String uri, String localName, String qName):标签(节点)解析结束后调用
- endDocument():文档解析结束后调用,该方法只会调用一次
重写startElement
在startElement中先判断当前的标签是否是对应的java对象,如果是则说明接下来是一个类的信息,新建一个Ocject对象用来存放这个对象的信息,封装到Object对象中。并记录当前的标签
public void startElement(String uri, String localName, String qName, Attributes attributes) {
currentTag = qName;
// 是否的Java对象,是则创建对象来保存解析的数据
if (nodeName.equals(qName)) {
try {
this.object = clazz.newInstance();
} catch (Exception e) {
System.out.println("对像创建失败");
}
}
if (attributes != null) {
Field[] declaredFields = clazz.getDeclaredFields();
try {
for (int i = 0; i < attributes.getLength(); i++) {
for (int j = 0; j < declaredFields.length; j++) {
String fieldname = declaredFields[j].getName();
if (attributes.getQName(i).equals(fieldname)) {
declaredFields[j].setAccessible(true);
declaredFields[j].set(object, attributes.getValue(i));
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
重写characters
// 当解析到标签中的内容的时候调用(换行也是文本内容)
public void characters(char[] ch, int start, int length) {
String contents = new String(ch, start, length).trim();
if (!contents.isEmpty()) {
Field[] declaredFields = clazz.getDeclaredFields();
try {
for (int i = 0; i < declaredFields.length; i++) {
String fieldname = declaredFields[i].getName();
if (currentTag.equals(fieldname)) {
declaredFields[i].setAccessible(true);
declaredFields[i].set(object, contents);
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
重写endElement
在这个方法中判断当前java对象是否解析结束,是则将对象添加到list中。
@Override
public void endElement(String uri, String localName, String name) throws SAXException {
super.endElement(uri, localName, name);
if (name.equals(nodeName)) {
list.add(object);
object = null;
}
}
完整代码
XmlParseHandler.java
public class XmlParseHandler extends DefaultHandler {
// xml节点名称
private String nodeName;
// JavaBean类对象
private Class clazz;
// 存储解析的数据
private Object object;
// 存储所有解析的数据
private List<Object> list;
// 当前xml标签
private String currentTag;
// 构造方法 做些初始化工作
public XmlParseHandler(String nodeName, Class clazz) {
this.nodeName = nodeName;
this.clazz = clazz;
this.list = new ArrayList<Object>();
}
// 返回所有数据
public List<Object> getList() {
return list;
}
@Override
public void startDocument() {
System.out.println("开始解析文档");
}
@Override
public void endDocument() {
System.out.println("结束解析文档");
}
public void startElement(String uri, String localName, String qName, Attributes attributes) {
currentTag = qName;
if (nodeName.equals(qName)) {
try {
this.object = clazz.newInstance();
} catch (Exception e) {
System.out.println("对像创建失败");
}
}
if (attributes != null) {
Field[] declaredFields = clazz.getDeclaredFields();
try {
for (int i = 0; i < attributes.getLength(); i++) {
for (int j = 0; j < declaredFields.length; j++) {
String fieldname = declaredFields[j].getName();
if (attributes.getQName(i).equals(fieldname)) {
declaredFields[j].setAccessible(true);
declaredFields[j].set(object, attributes.getValue(i));
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 每一个标签结束时调用
public void endElement(String uri, String localName, String qName) {
if (nodeName.equals(qName)) {
list.add(object);
object = null;
}
currentTag = null;
}
// 当解析到标签中的内容的时候调用(换行也是文本内容)
public void characters(char[] ch, int start, int length) {
String contents = new String(ch, start, length).trim();
if (!contents.isEmpty()) {
Field[] declaredFields = clazz.getDeclaredFields();
try {
for (int i = 0; i < declaredFields.length; i++) {
String fieldname = declaredFields[i].getName();
if (currentTag.equals(fieldname)) {
declaredFields[i].setAccessible(true);
declaredFields[i].set(object, contents);
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
MainApp.java
public class MainApp {
public static void main(String[] args) throws Exception {
try {
// 创建指向的文件的对象
File file = new File("src/Book.xml");
// 1. 得到SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
// 2. 让工厂生产一个sax解析器
SAXParser parser = spf.newSAXParser();
// 要解析的node节点 和 解析为的object的类全路径
XmlParseHandler handler = new XmlParseHandler("book", Book.class);
// 3. 传入输入流和handler,解析
parser.parse(new FileInputStream(file), handler);
// 4. 获得解析结果
List<Object> list = handler.getList();
// 5. 遍历输出结果
System.out.println("对其进行遍历,结果如下");
for (Object object : list) {
Book book = (Book) object;
System.out.println(book.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试结果
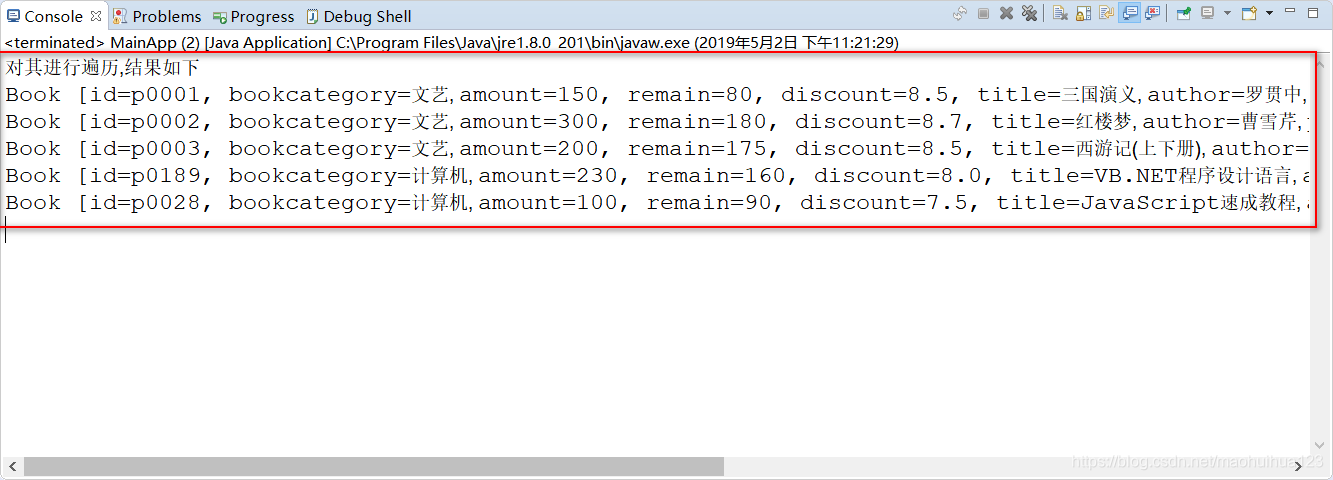
解析其XML文件
如果更换要解析的XML文件,我们需要做如下步骤:
-
编写XML文件对应的实体Java类。
-
修改
MainApp.java类。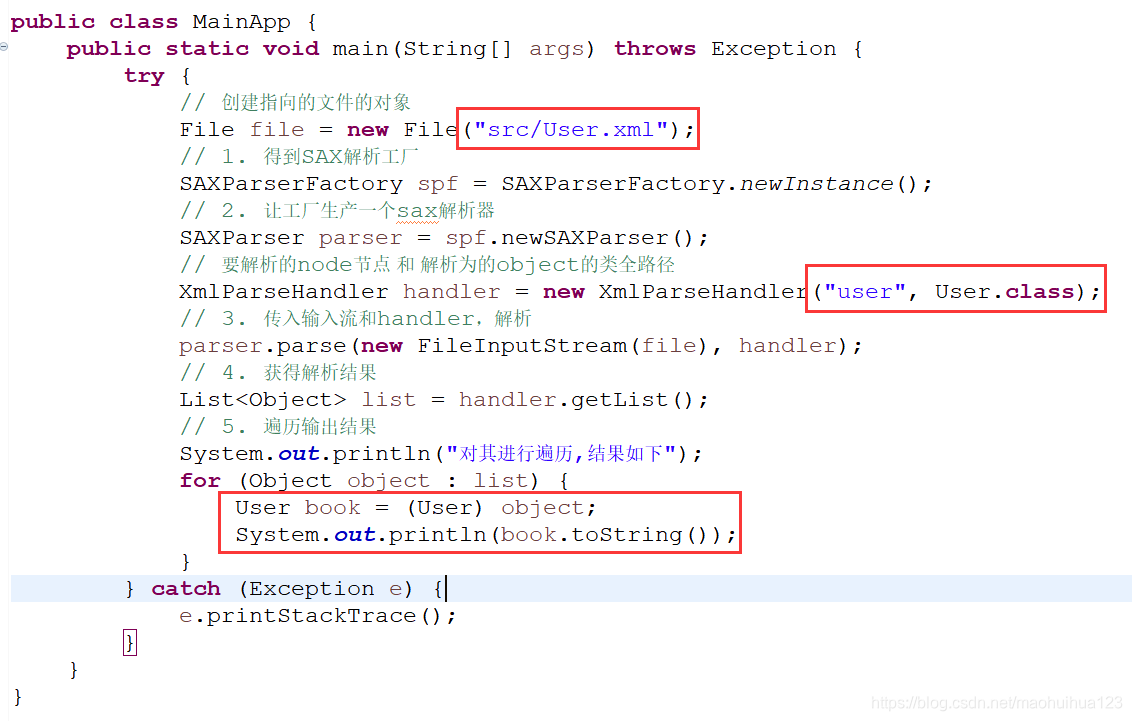
假设有如下XML文件:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1">
<name>毕向东</name>
<password>bxd123</password>
</user>
<user id="2">
<name>韩顺平</name>
<password>hsp123</password>
</user>
<user id="3">
<name>马士兵</name>
<password>msb123</password>
</user>
</users>
编写JavaBean
public class User {
private String id;
private String name;
private String password;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", password=" + password + "]";
}
}
修改 MainApp.java
public class MainApp {
public static void main(String[] args) throws Exception {
try {
// 创建指向的文件的对象
File file = new File("src/User.xml");
// 1. 得到SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
// 2. 让工厂生产一个sax解析器
SAXParser parser = spf.newSAXParser();
// 要解析的node节点 和 解析为的object的类全路径
XmlParseHandler handler = new XmlParseHandler("user", User.class);
// 3. 传入输入流和handler,解析
parser.parse(new FileInputStream(file), handler);
// 4. 获得解析结果
List<Object> list = handler.getList();
// 5. 遍历输出结果
System.out.println("对其进行遍历,结果如下");
for (Object object : list) {
User book = (User) object;
System.out.println(book.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:

结语
效果还不错,但还是有许多不足。突发性的想法,谨此记录。














 1712
1712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









