






 本文介绍了Redis主从复制时可能遇到的问题,包括端口、权限验证和主从状态处理。此外,探讨了Redis的三种复制机制:薪火相传、反客为主以及哨兵模式,重点讲解了哨兵模式如何自动处理主服务器宕机情况,实现故障转移和集群的动态管理。
本文介绍了Redis主从复制时可能遇到的问题,包括端口、权限验证和主从状态处理。此外,探讨了Redis的三种复制机制:薪火相传、反客为主以及哨兵模式,重点讲解了哨兵模式如何自动处理主服务器宕机情况,实现故障转移和集群的动态管理。
redis在搭建时会碰到的问题:1.再同一台机器上你要用不用的端口实现主从复制,你ip用的是回环网络 从服务器设置ip时也是回环网络而要是在不同的服务器上实现主从复制,因为你用的是真实Ip网段必须是在同一段落里。
2.权限验证:redis默认是没有密码的为了数据库的安全你希望外来的数据都是经过身份验证的,所以要设置密码你主配置文件设置了密码从配置文件就必须也要设置跟主配置文件一样的密码,从服务器在连接主服务器时才能验证成功,不然主服务器会拒绝从服务器的连接从服务器会不停尝试连接主服务器直至主从复制超时,导致失败。
3.在主从复制过程中如果主机突然宕机那从服务器是什么状态,里面的数据是否还会有:
127.0.0.1:6379> SHUTDOWN
not connected> exit
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
这是主服务器宕机后从服务器的状态以及查询出里面的数据
127.0.0.1:6381> keys *
1) "v5"
2) "v1"
3) "v6"
4) "v2"
5) "v3"
现在从服务器是静默的状态,主从复制的关系还是存在的,从
服务器在默默等待主服务器修好后重新启动复制
接下来咱们把主服务器重新启动,并在里面在输入几个键值,看看从服务器可以获取吗
127.0.0.1:6379> set m7 36
OK
127.0.0.1:6379> set m8 54
OK
127.0.0.1:6381> get m7
"36"
127.0.0.1:6381> get m8
"54"
原理:虽然主服务器当机了,不过他们的关系是不会变的 从服务器会默默地等待主服务器修好后重新上线继续执行之前的主从关系并同步主服务器中最新的数据而不是在主服务器宕机后取而代之 。
从服务器宕机后要如何修复:修复从服务器出现的问题重新启动从服务器,不过现在它的身份就不是slave了而是master你需要重新执行之前从服务器连接主服务器的命令以便让它重新成为slave(每宕机一次都要重新执行),除非你在配置文件中写入改配置让redis启动时就执行读取主从复制的关系
127.0.0.1:6382> SHUTDOWN
not connected> exit
[root@sanmao ~]# redis-server /usr/local/myredis/redis6382.conf
[root@sanmao ~]# redis-cli -p 6382 -a 666666
127.0.0.1:6382> info replication
# Replication
role:master
connected_slaves:0
master_replid:1d29bfcd6a0319609f8f11de391efddac45ba396
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:214376
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6382> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6382> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
还有一点 主从复制同样也具有读写分离的功能,主服务器可以写入和读取 而从服务器就只能读取主服务器的数据不能输入数据
既然这样那主服务器的压力就会相当大一般工作中一个主服务器往往要设置很多从服务器如何优化减轻主服务器压力就需要redis的第二种复制机制薪火相传

在这里要注意一点就是从配置文件中不仅要配置主服务器的身份验证密码还要设置自己下发给第二个从服务器的身份验证,因为你同时身兼从服务器和主服务器的作用(就相当于短跑中的接力,一棒一棒的传递下去) 密码必须和你的上级主服务器一样
在上个实例中6379下面有6381和6382两个从服务器 把6381变成6382的master从而减轻6379的写压力,让他们成为相互传递的关系。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=217078,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=217064,lag=1
127.0.0.1:6382> SLAVEOF 127.0.0.1 6381
OK
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_repl_offset:217274
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6382,state=online,offset=217274,lag=0
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=217358,lag=1
这样就可以一个从服务器为主服务器负担很多其他服务器的写压力。
redis的第三种复制机制是反客为主,它可以把第一种主从复制的中从服务器的静默状态变为主动状态,使原有的两个从服务器变成一主已从的关系,继续主从复制但是等原主服务器回来后它们就是两个不同的关系了要想再加入那只能以slave的身份加入了

redis三种复制模式都介绍完了,但随着技术的变化你不可能实时的去盯着它吧,工作时还可以要是在半夜出现宕机现象要怎么办所已研发出了redis的又一种模式就是很重要的哨兵模式。
哨兵模式顾名思义就是反客为主的自动版,它会自动的监控主服务器的运行状态在主服务器出现宕机情况后实行投票机制从剩下的从服务器中选出一个升为主服务器继续执行程序并监控,等原先的主服务器修复后重启后自动添加为slave:
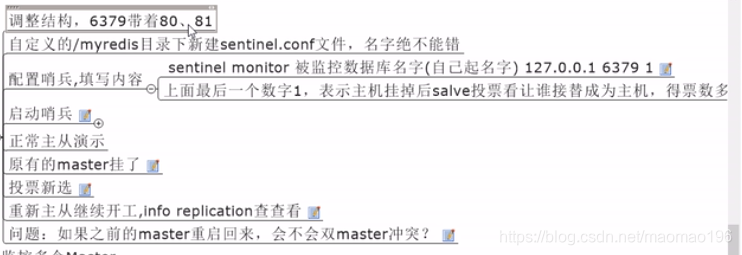
首先拷贝你redis目录下的sentinel.conf文件到你的myredis文件里,之后修改文件名为sentinel6379.conf并配置里面的文件只需要把这行在下方复制一下把注释删掉 在输入你的mymaster(master的别名)以及密码 保存退出

在redis的目录下运行
redis-sentinel /usr/local/myredis/sentinel.conf
[root@sanmao ~]# redis-sentinel /usr/local/myredis/sentinel.conf
4629:X 13 Sep 19:43:25.093 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
4629:X 13 Sep 19:43:25.093 # Redis version=4.0.1, bits=64, commit=00000000, modified=0, pid=4629, just started
4629:X 13 Sep 19:43:25.093 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.1 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 4629
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
4629:X 13 Sep 19:43:25.094 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
4629:X 13 Sep 19:43:25.132 # Sentinel ID is 634edb681de8bfafd54f539ff808edb3f4669caa
4629:X 13 Sep 19:43:25.132 # +monitor master mymaster 127.0.0.1 6379 quorum 2
4629:X 13 Sep 19:43:25.132 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
4629:X 13 Sep 19:43:25.169 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
现在哨兵就在监控你的主服务器,把6379现在停掉观察它后面的动作再加以验证和结合原理就可以知道是怎么操作的了
15798:X 13 Sep 20:19:57.711 # +sdown master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.711 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
15798:X 13 Sep 20:19:57.711 # +new-epoch 3
15798:X 13 Sep 20:19:57.711 # +try-failover master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.742 # +vote-for-leader e3775f85521398462d76e976c39563b274ba9952 3
15798:X 13 Sep 20:19:57.742 # +elected-leader master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.742 # +failover-state-select-slave master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.827 # +selected-slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.827 * +failover-state-send-slaveof-noone slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:57.892 * +failover-state-wait-promotion slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:58.213 # +promoted-slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:58.213 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:58.235 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:59.239 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:59.239 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:59.316 # +failover-end master mymaster 127.0.0.1 6379
15798:X 13 Sep 20:19:59.316 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6382
15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382
15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
从上面可以看出哨兵检测到主服务器6379宕机了,哨兵开始故障转移 在主服务器下的从服务器里挑选出一个新的当master,再通过投票选举 最终选6382为新的master
127.0.0.1:6382> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=293342,lag=0
master_replid:afd890cd0e2980239ddc3de57f508645d0325040
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:293342
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:251754
repl_backlog_histlen:41589
而6381还是slave,现在等于6382和6381成为一主一从的关系,原先的6379在修复后重新启动会不会和现在的6382冲突呢?答案是不会的因为哨兵会自动把它变为 slave
15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382
15798:X 13 Sep 20:19:59.316 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
15798:X 13 Sep 20:20:29.338 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
15798:X 13 Sep 20:35:38.103 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6382
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6382
master_link_status:up
master_last_io_seconds_ago:0

















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









