








可以看到consul可以有多个数据中心,多个数据中心构成consul集群,每个数据中心内,包含3个或5个(官方推荐)的consul sever,这样可以以较快的速度达成共识,以及可以高达上千个的consul client,每个数据中心有个一leader,所有数据中心的server组成的集群可以选举出一个leader,因为每个数据中心的节点是一个raft集合。从上边这个图中可以看到,consul client通过rpc的方式将请求转发到consul server ,consul server 再将请求转发到 server leader,server leader处理所有的请求,并将信息同步到其他的server中去。当一个数据中心的server没有leader的时候,这时候请求会被转发到其他的数据中心的consul server上,然后再转发到本数据中心的server leader上。
关于一些关键词,以下来自http://www.cnblogs.com/shanyou/p/6286207.html
- Agent——agent是一直运行在Consul集群中每个成员上的守护进程。通过运行 consul agent 来启动。agent可以运行在client或者server模式。指定节点作为client或者server是非常简单的,除非有其他agent实例。所有的agent都能运行DNS或者HTTP接口,并负责运行时检查和保持服务同步。
- Client——一个Client是一个转发所有RPC到server的代理。这个client是相对无状态的。client唯一执行的后台活动是加入LAN gossip池。这有一个最低的资源开销并且仅消耗少量的网络带宽。
- Server——一个server是一个有一组扩展功能的代理,这些功能包括参与Raft选举,维护集群状态,响应RPC查询,与其他数据中心交互WAN gossip和转发查询给leader或者远程数据中心。
- DataCenter——虽然数据中心的定义是显而易见的,但是有一些细微的细节必须考虑。例如,在EC2中,多个可用区域被认为组成一个数据中心?我们定义数据中心为一个私有的,低延迟和高带宽的一个网络环境。这不包括访问公共网络,但是对于我们而言,同一个EC2中的多个可用区域可以被认为是一个数据中心的一部分。
- Consensus——在我们的文档中,我们使用Consensus来表明就leader选举和事务的顺序达成一致。由于这些事务都被应用到有限状态机上,Consensus暗示复制状态机的一致性。
- Gossip——Consul建立在Serf的基础之上,它提供了一个用于多播目的的完整的gossip协议。Serf提供成员关系,故障检测和事件广播。更多的信息在gossip文档中描述。这足以知道gossip使用基于UDP的随机的点到点通信。
- LAN Gossip——它包含所有位于同一个局域网或者数据中心的所有节点。
- WAN Gossip——它只包含Server。这些server主要分布在不同的数据中心并且通常通过因特网或者广域网通信。
- RPC——远程过程调用。这是一个允许client请求server的请求/响应机制。
关于Gossip协议,以下来自http://blog.csdn.net/chen77716/article/details/6275762
Gossip算法因为Cassandra而名声大噪,Gossip看似简单,但要真正弄清楚其本质远没看起来那么容易。为了寻求Gossip的本质,下面的内容主要参考Gossip的原始论文:<<Efficient Reconciliation and Flow Control for Anti-Entropy Protocols>>。
1. Gossip背景
Gossip算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都会知道该八卦的信息,这种方式也与病毒传播类似,因此Gossip有众多的别名“闲话算法”、“疫情传播算法”、“病毒感染算法”、“谣言传播算法”。
但Gossip并不是一个新东西,之前的泛洪查找、路由算法都归属于这个范畴,不同的是Gossip给这类算法提供了明确的语义、具体实施方法及收敛性证明。
2. Gossip特点
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
要注意到的一点是,即使有的节点因宕机而重启,有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,Gossip天然具有分布式容错的优点。
3. Gossip本质
Gossip是一个带冗余的容错算法,更进一步,Gossip是一个最终一致性算法。虽然无法保证在某个时刻所有节点状态一致,但可以保证在”最终“所有节点一致,”最终“是一个现实中存在,但理论上无法证明的时间点。
因为Gossip不要求节点知道所有其他节点,因此又具有去中心化的特点,节点之间完全对等,不需要任何的中心节点。实际上Gossip可以用于众多能接受“最终一致性”的领域:失败检测、路由同步、Pub/Sub、动态负载均衡。
但Gossip的缺点也很明显,冗余通信会对网路带宽、CUP资源造成很大的负载,而这些负载又受限于通信频率,该频率又影响着算法收敛的速度,后面我们会讲在各种场合下的优化方法。
4. Gossip节点的通信方式及收敛性
根据原论文,两个节点(A、B)之间存在三种通信方式:
- push: A节点将数据(key,value,version)及对应的版本号推送给B节点,B节点更新A中比自己新的数据
- pull:A仅将数据key,version推送给B,B将本地比A新的数据(Key,value,version)推送给A,A更新本地
- push/pull:与pull类似,只是多了一步,A再将本地比B新的数据推送给B,B更新本地
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,push需通信1次,pull需2次,push/pull则需3次,从效果上来讲,push/pull最好,理论上一个周期内可以使两个节点完全一致。直观上也感觉,push/pull的收敛速度是最快的。
假设每个节点通信周期都能选择(感染)一个新节点,则Gossip算法退化为一个二分查找过程,每个周期构成一个平衡二叉树,收敛速度为O(n2 ),对应的时间开销则为O(logn )。这也是Gossip理论上最优的收敛速度。但在实际情况中最优收敛速度是很难达到的,假设某个节点在第i个周期被感染的概率为pi ,第i+1个周期被感染的概率为pi+1 ,则pull的方式:
![]()
而push为:
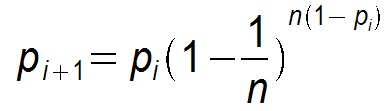
显然pull的收敛速度大于push,而每个节点在每个周期被感染的概率都是固定的p(0<p<1),因此Gossip算法是基于p的平方收敛,也成为概率收敛,这在众多的一致性算法中是非常独特的。
个Gossip的节点的工作方式又分两种:
- Anti-Entropy(反熵):以固定的概率传播所有的数据
- Rumor-Mongering(谣言传播):仅传播新到达的数据
Anti-Entropy模式有完全的容错性,但有较大的网络、CPU负载;Rumor-Mongering模式有较小的网络、CPU负载,但必须为数据定义”最新“的边界,并且难以保证完全容错,对失败重启且超过”最新“期限的节点,无法保证最终一致性,或需要引入额外的机制处理不一致性。我们后续着重讨论Anti-Entropy模式的优化。
5. Anti-Entropy的协调机制
协调机制是讨论在每次2个节点通信时,如何交换数据能达到最快的一致性,也即消除两个节点的不一致性。上面所讲的push、pull等是通信方式,协调是在通信方式下的数据交换机制。协调所面临的最大问题是,因为受限于网络负载,不可能每次都把一个节点上的数据发送给另外一个节点,也即每个Gossip的消息大小都有上限。在有限的空间上有效率地交换所有的消息是协调要解决的主要问题。
在讨论之前先声明几个概念:
- 令N = {p,q,s,...}为需要gossip通信的server集合,有界大小
- 令(p1,p2,...)是宿主在节点p上的数据,其中数据有(key,value,version)构成,q的规则与p类似。
为了保证一致性,规定数据的value及version只有宿主节点才能修改,其他节点只能间接通过Gossip协议来请求数据对应的宿主节点修改。
5.1 精确协调(Precise Reconciliation)
精确协调希望在每次通信周期内都非常准确地消除双方的不一致性,具体表现为相互发送对方需要更新的数据,因为每个节点都在并发与多个节点通信,理论上精确协调很难做到。精确协调需要给每个数据项独立地维护自己的version,在每次交互是把所有的(key,value,version)发送到目标进行比对,从而找出双方不同之处从而更新。但因为Gossip消息存在大小限制,因此每次选择发送哪些数据就成了问题。当然可以随机选择一部分数据,也可确定性的选择数据。对确定性的选择而言,可以有最老优先(根据版本)和最新优先两种,最老优先会优先更新版本最新的数据,而最新更新正好相反,这样会造成老数据始终得不到机会更新,也即饥饿。
当然,开发这也可根据业务场景构造自己的选择算法,但始终都无法避免消息量过多的问题。
5.2 整体协调(Scuttlebutt Reconciliation)
整体协调与精确协调不同之处是,整体协调不是为每个数据都维护单独的版本号,而是为每个节点上的宿主数据维护统一的version。比如节点P会为(p1,p2,...)维护一个一致的全局version,相当于把所有的宿主数据看作一个整体,当与其他节点进行比较时,只需必须这些宿主数据的最高version,如果最高version相同说明这部分数据全部一致,否则再进行精确协调。
整体协调对数据的选择也有两种方法:
- 广度优先:根据整体version大小排序,也称为公平选择
- 深度优先:根据包含数据多少的排序,也称为非公平选择。因为后者更有实用价值,所以原论文更鼓励后者
6. Cassandra中的实现
经过验证,Cassandra实现了基于整体协调的push/push模式,有几个组件:
三条消息分别对应push/pull的三个阶段:
- GossipDigitsMessage
- GossipDigitsAckMessage
- GossipDigitsAck2Message
还有三种状态:
- EndpointState:维护宿主数据的全局version,并封装了HeartBeat和ApplicationState
- HeartBeat:心跳信息
- ApplicationState:系统负载信息(磁盘使用率)
Cassandra主要是使用Gossip完成三方面的功能:
- 失败检测
- 动态负载均衡
- 去中心化的弹性扩展
7. 总结
Gossip是一种去中心化、容错而又最终一致性的绝妙算法,其收敛性不但得到证明还具有指数级的收敛速度。使用Gossip的系统可以很容易的把Server扩展到更多的节点,满足弹性扩展轻而易举。
唯一的缺点是收敛是最终一致性,不使用那些强一致性的场景,比如2pc。
关于raft协议,以下来自http://www.jdon.com/artichect/raft.html
过去, Paxos一直是分布式协议的标准,但是Paxos难于理解,更难以实现,Google的分布式锁系统Chubby作为Paxos实现曾经遭遇到很多坑。
来自Stanford的新的分布式协议研究称为Raft,它是一个为真实世界应用建立的协议,主要注重协议的落地性和可理解性。
在了解Raft之前,我们先了解Consensus一致性这个概念,它是指多个服务器在状态达成一致,但是在一个分布式系统中,因为各种意外可能,有的服务器可能会崩溃或变得不可靠,它就不能和其他服务器达成一致状态。这样就需要一种Consensus协议,一致性协议是为了确保容错性,也就是即使系统中有一两个服务器当机,也不会影响其处理过程。
为了以容错方式达成一致,我们不可能要求所有服务器100%都达成一致状态,只要超过半数的大多数服务器达成一致就可以了,假设有N台服务器,N/2 +1 就超过半数,代表大多数了。
Paxos和Raft都是为了实现Consensus一致性这个目标,这个过程如同选举一样,参选者需要说服大多数选民(服务器)投票给他,一旦选定后就跟随其操作。Paxos和Raft的区别在于选举的具体过程不同。
在Raft中,任何时候一个服务器可以扮演下面角色之一:
- Leader: 处理所有客户端交互,日志复制等,一般一次只有一个Leader.
- Follower: 类似选民,完全被动
- Candidate候选人: 类似Proposer律师,可以被选为一个新的领导人。
Raft阶段分为两个,首先是选举过程,然后在选举出来的领导人带领进行正常操作,比如日志复制等。下面用图示展示这个过程:
1. 任何一个服务器都可以成为一个候选者Candidate,它向其他服务器Follower发出要求选举自己的请求:

2. 其他服务器同意了,发出OK。

注意如果在这个过程中,有一个Follower当机,没有收到请求选举的要求,因此候选者可以自己选自己,只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的。
3. 这样这个候选者就成为了Leader领导人,它可以向选民也就是Follower们发出指令,比如进行日志复制。

4. 以后通过心跳进行日志复制的通知

5. 如果一旦这个Leader当机崩溃了,那么Follower中有一个成为候选者,发出邀票选举。

6. Follower同意后,其成为Leader,继续承担日志复制等指导工作:

值得注意的是,整个选举过程是有一个时间限制的,如下图:

Splite Vote是因为如果同时有两个候选人向大家邀票,这时通过类似加时赛来解决,两个候选者在一段timeout比如300ms互相不服气的等待以后,因为双方得到的票数是一样的,一半对一半,那么在300ms以后,再由这两个候选者发出邀票,这时同时的概率大大降低,那么首先发出邀票的的候选者得到了大多数同意,成为领导者Leader,而另外一个候选者后来发出邀票时,那些Follower选民已经投票给第一个候选者,不能再投票给它,它就成为落选者了,最后这个落选者也成为普通Follower一员了。
日志复制
下面以日志复制为例子说明Raft算法,假设Leader领导人已经选出,这时客户端发出增加一个日志的要求,比如日志是"sally":

2. Leader要求Followe遵从他的指令,都将这个新的日志内容追加到他们各自日志中:

3.大多数follower服务器将日志写入磁盘文件后,确认追加成功,发出Commited Ok:

4. 在下一个心跳heartbeat中,Leader会通知所有Follwer更新commited 项目。
对于每个新的日志记录,重复上述过程。
如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。
总结:目前几乎所有语言都已经有支持Raft算法的库包,具体可参考:raftconsensus.github.io
CAP定理
ZooKeeper在服务发现中应用
Raft英文动画演示的文字
So What is Distributed Consensus?
Let's start with an example...Let's say we have a single node system
For this example, you can think of our node as a database server that stores a single value.
We also have a client that can send a value to the server.
Coming to agreement, or consensus, on that value is easy with one node.
But how do we come to consensus if we have multiple nodes?
That's the problem of distributed consensus.
Raft is a protocol for implementing distributed consensus.
Let's look at a high level overview of how it works.
A node can be in 1 of 3 states:The Follower state,the Candidate state,or the Leader state.
All our nodes start in the follower state.
If followers don't hear from a leader then they can become a candidate.
The candidate then requests votes from other nodes.
Nodes will reply with their vote.
The candidate becomes the leader if it gets votes from a majority of nodes.
This process is called Leader Election.
All changes to the system now go through the leader.
Each change is added as an entry in the node's log.
This log entry is currently uncommitted so it won't update the node's value.
To commit the entry the node first replicates it to the follower nodes...
then the leader waits until a majority of nodes have written the entry.
The entry is now committed on the leader node and the node state is "5".
The leader then notifies the followers that the entry is committed.
The cluster has now come to consensus about the system state.
This process is called Log Replication.
Leader Election
In Raft there are two timeout settings which control elections.
First is the election timeout.
The election timeout is the amount of time a follower waits until becoming a candidate.
The election timeout is randomized to be between 150ms and 300ms.
After the election timeout the follower becomes a candidate and starts a new election term......votes for itself......and sends out Request Vote messages to other nodes.
If the receiving node hasn't voted yet in this term then it votes for the candidate.....and the node resets its election timeout.
Once a candidate has a majority of votes it becomes leader.
The leader begins sending out Append Entries messages to its followers.
These messages are sent in intervals specified by the heartbeat timeout.
Followers then respond to each Append Entries message.
This election term will continue until a follower stops receiving heartbeats and becomes a candidate.
Let's stop the leader and watch a re-election happen.
Node B is now leader of term 2.
Requiring a majority of votes guarantees that only one leader can be elected per term.
If two nodes become candidates at the same time then a split vote can occur.
Let's take a look at a split vote example...
Two nodes both start an election for the same term......and each reaches a single follower node before the other.
Now each candidate has 2 votes and can receive no more for this term.
The nodes will wait for a new election and try again.
Node D received a majority of votes in term 5 so it becomes leader.
Log Replication
Term: 1
Node BTerm: 1Leader: A
Node CTerm: 1Leader: A
Once we have a leader elected we need to replicate all changes to our system to all nodes.
This is done by using the same Append Entries message that was used for heartbeats.
Let's walk through the process.
First a client sends a change to the leader.
The change is appended to the leader's log......then the change is sent to the followers on the next heartbeat.
An entry is committed once a majority of followers acknowledge it.....and a response is sent to the client.
Now let's send a command to increment the value by "2".
Our system value is now updated to "7".
Raft can even stay consistent in the face of network partitions.
Let's add a partition to separate A & B from C, D & E.
Because of our partition we now have two leaders in different terms.
Let's add another client and try to update both leaders.
One client will try to set the value of node B to "3".
Node B cannot replicate to a majority so its log entry stays uncommitted.
The other client will try to set the value of node C to "8".
This will succeed because it can replicate to a majority.
Now let's heal the network partition.
Node B will see the higher election term and step down.
Both nodes A & B will roll back their uncommitted entries and match the new leader's log.
Our log is now consistent across our cluster.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









