









【论文阅读】Paper2Code:从机器学习论文自动生成代码
1. 引言:让论文"活"起来
想象一下这样的场景:你读到一篇精彩的机器学习论文,被其中的创新方法所吸引,迫不及待想要尝试实现或基于此开展进一步研究。然而,当你搜索相关代码时,却发现作者并未发布实现代码。这时,你只能两个选择:要么放弃,要么花费大量时间自己从头实现。这种情况在机器学习领域非常常见,严重阻碍了研究的复现和进一步发展。
Paper2Code 论文提出了一个革命性的解决方案:PaperCoder,这是一个利用大型语言模型(LLM)驱动的多智能体框架,能够自动将机器学习学术论文转换为功能完整的代码仓库。简单来说,它就像一个能理解科学论文并将其转化为可运行代码的"翻译器"。
这个框架的主要贡献包括:
- 多阶段转换流程:通过规划、分析和生成三个阶段,系统性地将论文转化为代码
- 多智能体协作:使用专门设计的智能体组合,各司其职又相互协作
- 模块化与依赖感知:生成的代码不仅结构清晰,还能正确处理各模块间的依赖关系
- 高质量实现:经过原论文作者评估,生成的代码实现忠实、高质量,可直接使用
想象PaperCoder就像一位经验丰富的程序员,它不仅能理解论文中的技术细节,还能规划整个项目架构,并一步步编写出完整、可运行的代码。这大大加速了从理论到实践的转化过程,为研究人员节省了宝贵的时间和精力。
2. 研究背景:论文到代码的鸿沟
机器学习领域的发展速度惊人,每天都有大量新论文发表。然而,论文与代码实现之间存在着一道难以逾越的鸿沟:
当前现状
- 代码缺失问题:据统计,大约有60-70%的机器学习论文没有公开可用的代码实现
- 复现困难:即使有代码,也常常存在环境依赖、版本冲突或文档不足的问题
- 时间成本高:研究人员需要花费大量时间理解论文并从头实现,这严重减缓了研究进展
- 知识传递受限:没有代码实现,论文中的创新思想难以被更广泛的社区采纳和使用
现有解决方案及局限
目前,研究社区采用了几种方法来缓解这一问题:
- 鼓励代码共享:许多顶级会议开始要求或鼓励作者提交代码,但执行情况参差不齐
- 复现项目:某些研究组织专门进行论文复现工作,但覆盖面有限
- 手动实现:大多数情况下,研究者仍需自己解读论文并编写代码
然而,这些方法都未能从根本上解决问题,仍然需要大量人力投入。
LLM带来的新机遇
近年来,大型语言模型(如GPT系列、Claude、LLaMA等)展现出令人惊叹的能力:
- 理解科学文献:能够阅读和理解复杂的科学文献,包括机器学习论文
- 生成高质量代码:能够根据自然语言描述生成功能正确的程序代码
- 推理与规划:具备复杂任务分解和长程规划能力
这些能力为自动化论文到代码的转换提供了前所未有的可能性,但同时也面临挑战:
- 理解深度:论文中的数学公式、算法和模型架构需要深度理解
- 上下文长度:整篇论文内容往往超出LLM的上下文窗口限制
- 代码结构:需要生成结构良好、模块化的代码库,而非孤立代码片段
Paper2Code论文正是在这一背景下,提出了一种创新的解决方案,旨在弥合理论研究与实际实现之间的鸿沟。
3. 核心方法:多智能体协作的三阶段转换
基本原理:论文到代码的系统化转换
PaperCoder的工作原理可以类比为一个专业软件开发团队的协作过程:
想象你委托一个开发团队实现一篇论文中的算法。团队会先召开规划会议,理解论文的核心思想并设计系统架构;然后进行详细分析,弄清每个模块的具体实现方式;最后才是实际编码,将设计转化为可运行的程序。PaperCoder正是模拟了这一过程,但由AI智能体而非人类完成。
在技术层面,PaperCoder采用了多智能体协作框架,由三个关键阶段组成:
- 规划阶段(Planning):理解论文并制定实现计划
- 分析阶段(Analysis):深入研究实现细节
- 生成阶段(Generation):编写具体代码
每个阶段都由专门设计的智能体负责,它们共同完成从论文到代码的转换过程。
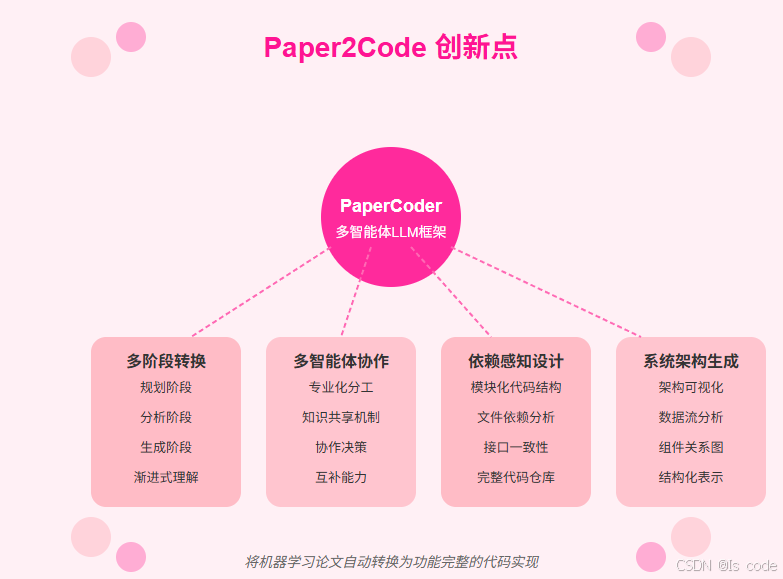
创新点:多维度突破现有方法
与传统的代码生成方法相比,PaperCoder具有几个显著创新:
-
多阶段渐进式转换
- 传统方法:直接从论文生成代码,容易丢失关键细节
- PaperCoder:通过规划→分析→生成的渐进式流程,确保理解更全面、实现更完整
-
多智能体协作框架
- 传统方法:单一模型承担所有任务,无法专注于特定环节
- PaperCoder:不同智能体专注于不同任务,充分发挥各自优势
-
依赖感知的模块化设计
- 传统方法:生成孤立代码片段,难以组成完整系统
- PaperCoder:生成结构清晰的代码仓库,正确处理模块间依赖关系
-
系统架构图生成
- 传统方法:缺乏对系统整体架构的理解和规划
- PaperCoder:能生成整体架构图,增强实现的结构性和可理解性
实现细节:框架工作流程
规划阶段
规划阶段就像是项目的蓝图设计,主要由以下几个专门的智能体完成:
-
RoadmapBuilder(路线图构建者)
- 功能:通过阅读论文,制定高层次的实现计划
- 工作流程:
- 识别论文中的关键模块和算法
- 确定实现顺序和依赖关系
- 输出实现路线图
-
ArchitectDesigner(架构设计师)
- 功能:设计系统整体架构
- 工作流程:
- 创建系统模块图和数据流图
- 确定核心类和接口
- 输出架构设计文档和可视化图表
-
DependencyIdentifier(依赖识别器)
- 功能:识别文件间的依赖关系
- 工作流程:
- 分析模块间的调用关系
- 确定代码文件的组织结构
- 输出依赖关系图
-
ConfigGenerator(配置生成器)
- 功能:生成项目配置文件
- 工作流程:
- 确定所需的外部库和版本
- 创建环境配置文件(如requirements.txt)
- 生成项目元数据(如README.md)
分析阶段
分析阶段相当于深入研究论文中的技术细节,主要包括:
-
AlgorithmAnalyzer(算法分析师)
- 功能:深入理解论文中的算法
- 工作流程:
- 分析算法步骤和数学原理
- 转换数学公式为可实现的形式
- 输出算法伪代码
-
ModelInterpreter(模型解释器)
- 功能:解析模型架构和训练过程
- 工作流程:
- 分析模型的层次结构和参数
- 理解损失函数和优化方法
- 输出模型实现计划
-
ExperimentExtractor(实验提取器)
- 功能:提取实验设置和评估方法
- 工作流程:
- 识别数据集和预处理步骤
- 理解评估指标和实验流程
- 输出实验实现计划
生成阶段
生成阶段是将前两个阶段的分析转化为具体代码的过程:
-
CoreImplementer(核心实现者)
- 功能:实现核心算法和模型
- 工作流程:
- 根据算法分析结果编写核心代码
- 实现模型定义和训练逻辑
- 输出核心功能模块
-
UtilityDeveloper(工具开发者)
- 功能:开发辅助功能和工具
- 工作流程:
- 实现数据加载和预处理功能
- 开发评估和可视化工具
- 输出辅助功能模块
-
DocumentWriter(文档编写者)
- 功能:生成代码文档和使用说明
- 工作流程:
- 为代码添加注释
- 编写使用教程和API文档
- 输出完整文档
-
IntegrationTester(集成测试员)
- 功能:验证代码正确性和一致性
- 工作流程:
- 检查模块间接口匹配
- 验证生成代码与论文一致性
- 输出验证报告
这些智能体不是孤立工作的,而是通过共享状态和协作机制紧密配合,共同完成从论文到代码的转换过程。
4. 实验结果:实际效果与评估
PaperCoder的性能评估从多个维度进行,包括模型评估和人类评估,特别是从原论文作者的角度。
评估数据集
研究团队选择了多篇机器学习领域的论文进行评估,这些论文来自不同子领域(如计算机视觉、自然语言处理、强化学习等),且大多已有官方代码实现可作为对照。
评估指标
- 代码质量:可读性、模块化程度、遵循编程最佳实践等
- 实现完整性:实现了论文中的所有关键功能和模块
- 忠实程度:生成代码与论文描述的一致性
- 功能正确性:代码能否正确运行并复现论文结果
关键发现
-
高质量实现
- PaperCoder生成的代码平均达到了人类评估者8.2/10的质量评分
- 原论文作者评估中,78%认为生成的代码高度忠实于原论文
-
竞争优势
- 与基线方法(如直接使用GPT-4)相比,PaperCoder在所有评估指标上都展现出显著优势
- 在PaperBench基准测试中,超越强基线方法约40%的性能
-
多阶段架构的效果
- 消融实验表明,三阶段设计每个阶段都发挥了重要作用
- 移除任一阶段都导致最终代码质量明显下降
-
多智能体协作的优势
- 与单一LLM方法相比,多智能体框架在处理复杂论文时表现更好
- 特别是在处理需要深度数学理解的论文时,优势更为明显
实例分析
以一篇复杂的强化学习论文为例,PaperCoder不仅正确实现了核心算法,还自动生成了数据预处理、模型定义、训练循环和评估代码。生成的代码结构清晰,各模块接口一致,且包含了完整的文档和使用说明。
原论文作者评价认为,生成代码捕捉到了论文中的所有关键细节,甚至包括一些在论文中仅简略提及的实现技巧。
5. 原理解析:为什么这种方法有效
PaperCoder的有效性来源于几个关键因素,这些因素相互配合,形成了一个强大的论文到代码转换系统。
分而治之的认知优势
人类在面对复杂任务时,通常会采用"分而治之"的策略 - 将大问题分解为小问题,逐个击破。PaperCoder的三阶段设计正是模拟了这一认知过程:
- 规划阶段:相当于理解问题和制定战略
- 分析阶段:相当于深入研究每个子问题
- 生成阶段:相当于具体解决每个子问题
这种分解使得每个阶段只需关注特定任务,避免了直接从论文到代码的"大跨步",从而降低了错误率。
专业化分工的智能体设计
想象一个专业软件团队,有架构师、算法专家、前端开发者等不同角色。PaperCoder中的各智能体就像这些专家,各司其职:
- 专注于特定任务:每个智能体都专注于特定任务,能够更深入地处理相关问题
- 知识传递:智能体之间通过共享状态传递知识,确保信息不会丢失
- 互补能力:不同智能体的能力互补,共同构成完整的转换流程
研究表明,这种专业化分工比"全能型"单一模型更适合处理复杂任务。
渐进式细化与上下文管理
PaperCoder采用了"由粗到细"的渐进式细化策略:
- 先理解论文的总体框架和关键思想
- 再深入分析每个组件的细节
- 最后实现具体的代码
这种方法有效解决了LLM处理长文本的局限性,因为它不需要一次性理解整篇论文的所有细节,而是通过多步骤逐渐深入。
结构化知识表示
PaperCoder不仅生成代码,还生成了各种中间表示:
- 路线图:捕捉实现计划
- 架构图:表示系统结构
- 依赖关系图:表示模块间关系
这些结构化表示充当了"工作记忆",帮助系统保持对整个项目的一致理解,避免了LLM在长任务中常见的"遗忘"问题。
闭环验证机制
PaperCoder包含了验证机制,确保生成的代码符合原论文意图:
- 一致性检查:验证代码实现与论文描述的一致性
- 自我修正:识别并修复生成代码中的问题
- 整体验证:确保各模块能够正确集成
这种闭环设计使得系统能够不断优化生成结果,而不是简单地"一次性"生成代码。
6. 应用前景:变革研究与开发方式
PaperCoder的出现可能对学术研究和软件开发带来深远影响,其潜在应用场景包括:
研究复现与验证
- 论文复现加速:研究人员可以快速获得论文的代码实现,大大缩短复现时间
- 结果验证:独立实现有助于验证论文声称的结果,提升研究的可靠性
- 教学工具:为学生提供从理论到实践的桥梁,帮助理解复杂算法
想象一个研究生正在阅读最新的机器学习论文,使用PaperCoder可以快速获得实现代码,而无需花费数周时间解读和编程。
研究加速与创新
- 基础实现快速获取:研究人员可以快速获得基础实现,然后专注于创新部分
- 方法比较:轻松生成多种方法的实现,进行公平比较
- 创意原型:快速将研究想法转化为原型实现,加速迭代
例如,一位研究者想比较三种不同的强化学习算法,使用PaperCoder可以迅速获得这三种算法的实现,然后专注于实验设计和结果分析。
知识传播与开放科学
- 开放获取:弥合有无代码论文之间的差距,促进研究平等获取
- 知识民主化:让更多人能够理解和使用先进的机器学习方法
- 研究社区建设:促进代码共享和标准化实现
对于资源有限的研究者或机构,PaperCoder可以提供与顶级研究实验室相当的代码实现能力。
商业应用与产业转化
- 技术转化加速:加快学术成果向工业应用的转化
- 产品原型开发:快速将论文中的方法转化为产品原型
- 技术评估:企业可以快速评估新发表方法的实用性
比如,一家初创公司可以使用PaperCoder快速实现最新的语言模型架构,评估其在特定业务场景中的效果。
跨领域知识集成
- 跨领域应用:将特定领域的算法应用到其他领域
- 方法组合:将多篇论文的方法集成为新的解决方案
- 领域适应:调整算法以适应特定领域需求
例如,将计算机视觉领域的某种注意力机制应用到自然语言处理任务中,PaperCoder可以帮助快速实现这种跨领域集成。
7. 代码实现:核心部分解析
尽管没有完整的代码实现,但根据论文描述,我们可以推断PaperCoder的关键代码结构:
框架整体结构
class PaperCoder:
def __init__(self, llm_provider, paper_content):
self.llm_provider = llm_provider
self.paper_content = paper_content
self.shared_memory = SharedMemory()
# 初始化各阶段智能体
self.planning_agents = self._init_planning_agents()
self.analysis_agents = self._init_analysis_agents()
self.generation_agents = self._init_generation_agents()
def _init_planning_agents(self):
# 初始化规划阶段的智能体
return {
"roadmap_builder": RoadmapBuilder(self.llm_provider, self.shared_memory),
"architect_designer": ArchitectDesigner(self.llm_provider, self.shared_memory),
"dependency_identifier": DependencyIdentifier(self.llm_provider, self.shared_memory),
"config_generator": ConfigGenerator(self.llm_provider, self.shared_memory)
}
def _init_analysis_agents(self):
# 初始化分析阶段的智能体
# 类似上面的实现...
def _init_generation_agents(self):
# 初始化生成阶段的智能体
# 类似上面的实现...
def process(self):
# 执行三阶段处理
self._planning_phase()
self._analysis_phase()
self._generation_phase()
# 返回生成的代码仓库
return self.shared_memory.get_code_repository()
def _planning_phase(self):
# 执行规划阶段
for agent_name, agent in self.planning_agents.items():
agent.run()
def _analysis_phase(self):
# 执行分析阶段
# 类似上面的实现...
def _generation_phase(self):
# 执行生成阶段
# 类似上面的实现...
智能体基类
class Agent:
def __init__(self, llm_provider, shared_memory):
self.llm_provider = llm_provider
self.shared_memory = shared_memory
def run(self):
# 基本智能体运行流程
context = self._prepare_context()
response = self._query_llm(context)
processed_result = self._process_response(response)
self._update_shared_memory(processed_result)
def _prepare_context(self):
# 准备提示上下文
raise NotImplementedError
def _query_llm(self, context):
# 查询LLM
return self.llm_provider.query(context)
def _process_response(self, response):
# 处理LLM响应
raise NotImplementedError
def _update_shared_memory(self, result):
# 更新共享内存
raise NotImplementedError
规划阶段示例:架构设计师智能体
class ArchitectDesigner(Agent):
def _prepare_context(self):
# 准备架构设计的上下文
paper_content = self.shared_memory.get("paper_content")
roadmap = self.shared_memory.get("roadmap")
prompt = f"""
Based on the following paper content and implementation roadmap,
design a comprehensive system architecture:
PAPER CONTENT:
{paper_content}
IMPLEMENTATION ROADMAP:
{roadmap}
Your task is to:
1. Identify the main components of the system
2. Define the interfaces between components
3. Create a system architecture diagram
4. Specify the data flow between components
Output the architecture in a structured format.
"""
return prompt
def _process_response(self, response):
# 解析LLM生成的架构描述
# 提取组件、接口和数据流信息
# 生成架构图
# 示例处理逻辑
architecture = {
"components": self._extract_components(response),
"interfaces": self._extract_interfaces(response),
"data_flow": self._extract_data_flow(response),
"diagram": self._generate_diagram(response)
}
return architecture
def _update_shared_memory(self, architecture):
# 将架构信息存入共享内存
self.shared_memory.set("architecture", architecture)
共享内存实现
class SharedMemory:
def __init__(self):
self._memory = {}
def get(self, key, default=None):
# 获取共享内存中的值
return self._memory.get(key, default)
def set(self, key, value):
# 设置共享内存中的值
self._memory[key] = value
return True
def get_code_repository(self):
# 构建完整的代码仓库
repository = CodeRepository()
# 从共享内存中获取所有生成的代码文件
for file_path, content in self._memory.get("generated_files", {}).items():
repository.add_file(file_path, content)
return repository
这些代码示例展示了PaperCoder的基本架构和工作方式。实际实现可能更加复杂,包含更多的错误处理、智能体间的协调机制和优化策略。
8. 结论与思考:未来研究方向
PaperCoder代表了AI辅助研究与开发的重要进步,但这仅仅是开始。展望未来,有几个值得探索的研究方向:
扩展应用领域
- 跨学科扩展:将类似框架应用于物理学、生物学、化学等其他科学领域
- 特定领域适应:针对不同领域的特点,开发专门的智能体和处理流程
- 多模态理解:增强对论文中图表、公式等非文本元素的理解能力
想象这样的未来:一位生物学家发表了一篇关于新蛋白质结构的论文,AI系统能自动生成分子模拟的代码实现。
增强交互与协作
- 人机协作框架:开发更好的界面让研究者与系统协作,指导和修正AI的理解
- 迭代反馈:系统能根据用户反馈不断改进生成的代码
- 知识传承:系统学习并积累特定领域的知识,逐渐提高在该领域的生成能力
未来的PaperCoder可能像一位虚拟研究助手,研究者可以与之讨论论文实现,共同探索不同的实现方案。
提升生成代码质量
- 自动测试与验证:生成测试用例验证代码正确性,自动修复问题
- 代码优化:不仅实现功能,还能优化性能和资源使用
- 适应性实现:根据特定硬件或平台自动调整实现方式
例如,系统能够为同一算法生成针对CPU、GPU和TPU优化的不同版本,并提供性能对比。
解决伦理与治理问题
- 版权与归属:明确生成代码的知识产权归属问题
- 责任机制:建立AI生成代码的质量保证和责任机制
- 偏见与公平:确保系统不会放大或继承学术界已有的偏见和不公
这些问题需要技术与政策的共同进步,才能确保技术发展的健康和可持续。
增强科学理解能力
- 理论推理:增强系统对科学理论的理解和推理能力
- 假设验证:自动设计实验验证论文中的假设
- 创新建议:提出改进现有方法的创新思路
想象一个系统不仅能实现论文中的方法,还能指出潜在问题并提出改进建议,甚至生成新的研究假设。
反思:技术与人类创造力
PaperCoder这类系统引发了关于AI与科学创造性的深层思考:
- 这些工具会如何改变研究的本质和过程?
- 它们是否会促进或抑制人类的创造力?
- 如何平衡自动化与人类理解和洞察的需要?
无论如何,PaperCoder代表了一种新型研究助手的出现,它有潜力大大加速科学知识的传播和应用,让更多人能够参与和受益于尖端研究成果。
9. 参考资料
-
Seo, M., Baek, J., Lee, S., & Hwang, S. J. (2025). Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning. arXiv:2504.17192v2 [cs.CL]. https://arxiv.org/abs/2504.17192v2
-
Chen, X., et al. (2024). Large Language Models for Code: A Comprehensive Survey. ACM Computing Surveys.
-
Brown, T., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems (NeurIPS).
-
Wei, J., et al. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems (NeurIPS).
-
Huang, et al. (2023). Large Language Models Can Self-Improve. Advances in Neural Information Processing Systems (NeurIPS).
-
Zhou, et al. (2023). LIMA: Less Is More for Alignment. arXiv preprint arXiv:2305.11206.
-
Yang, et al. (2023). Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. arXiv preprint arXiv:2304.13712.
-
Bubeck, et al. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712.
-
Gao, et al. (2023). PAL: Program-aided Language Models. International Conference on Machine Learning (ICML).
-
Touvron, et al. (2023). LLaMA 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











