









从银行转账到微服务:深度解析ACID与BASE如何守护你的数据安全
引言:当数据操作遇上现实世界的混乱
想象这样一个场景:你通过手机银行给朋友转账1000元。点击确认后,突然网络断开、手机死机或银行系统崩溃。几分钟后,一切恢复正常,但现在有三种可能的状态:
- 钱从你账户扣除,但朋友没收到
- 朋友收到了钱,但你的账户没扣款
- 转账完全没有发生
哪一种结果是可接受的?显然只有第三种,即"要么完全成功,要么完全不发生"。这正是数据库事务存在的根本原因——确保在不可预测的现实世界中,数据操作仍能保持一致性和可靠性。
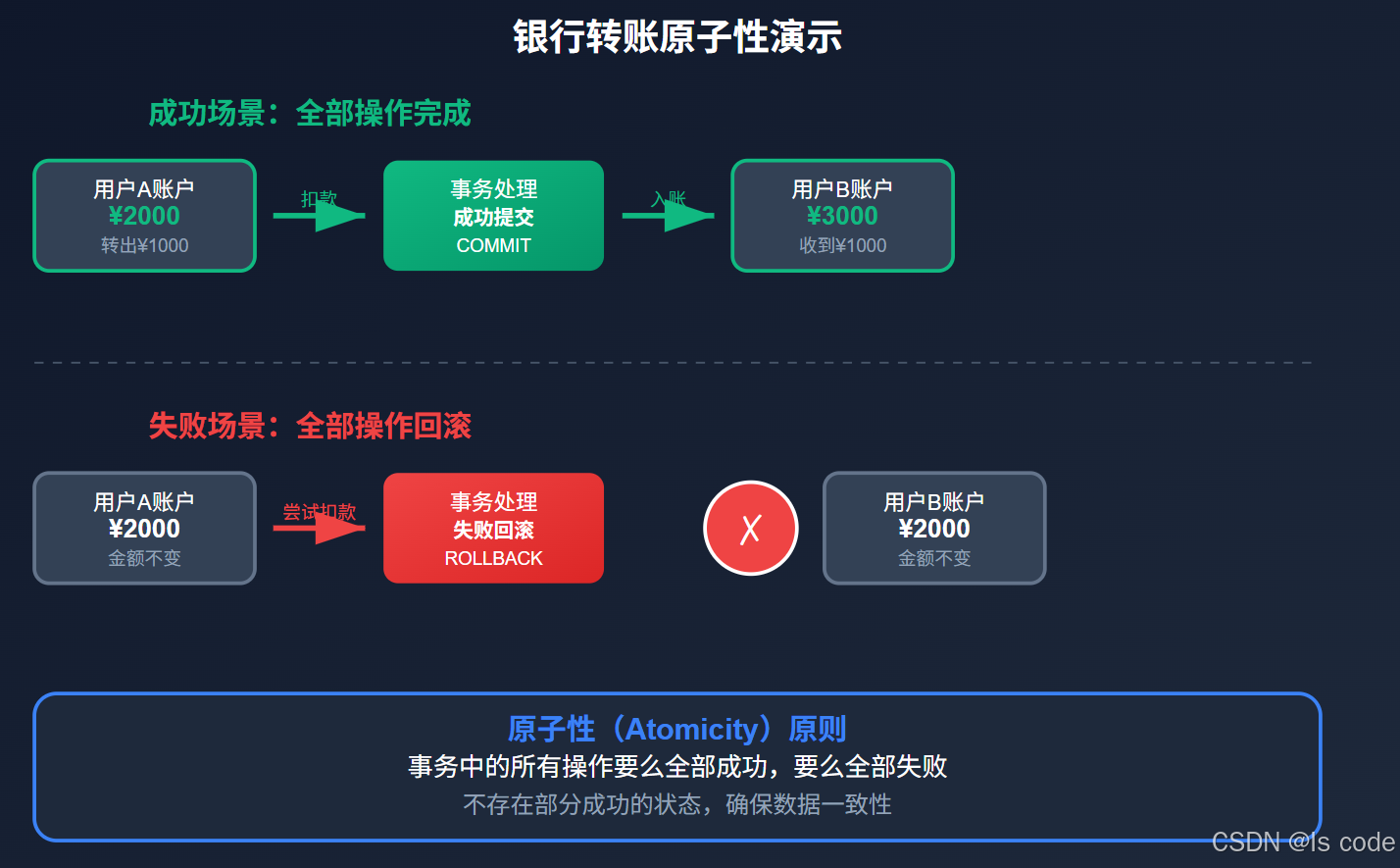
图1:银行转账场景中的原子性演示
今天,我们将探索两种主要的数据库事务模型——ACID和BASE,了解它们如何以不同方式解决数据一致性问题,以及在现代应用架构中如何选择和组合它们。
ACID模型:数据库的"强承诺"
ACID是关系数据库事务的经典保证,它代表四个关键特性。让我们通过日常类比来理解它们:
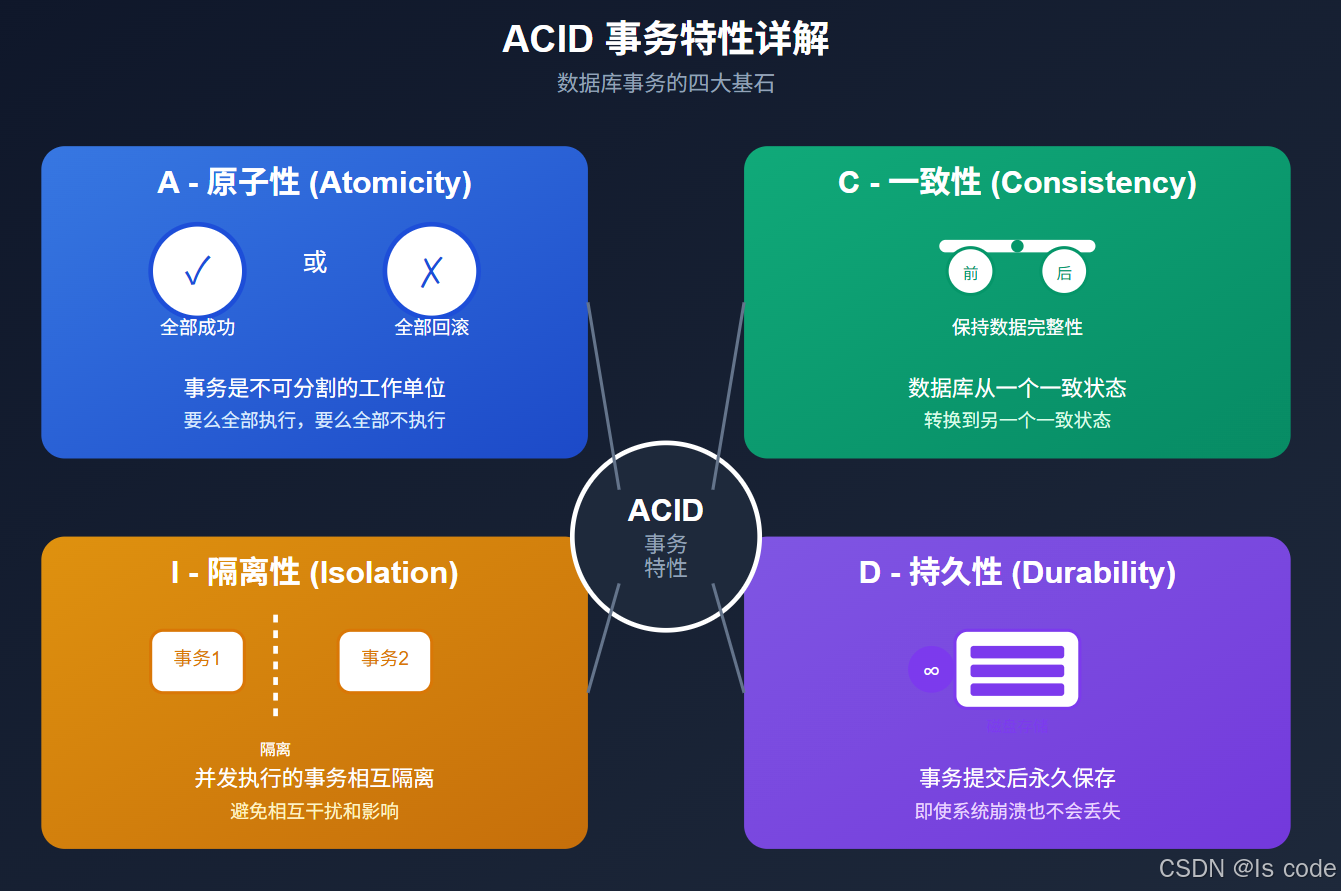
图2:ACID四个特性的可视化展示
原子性(Atomicity):“全有或全无”
想象你在组装一台电脑,需要安装CPU、内存、硬盘等组件。如果中途发现CPU损坏,你会怎么做?你会拆掉所有已经装好的部件,退回到开始状态,而不是留下一台半成品电脑。
原子性保证事务中的所有操作要么全部完成,要么全部不执行,不存在部分完成的状态。
# 银行转账中的原子性示例
def transfer_money(from_account, to_account, amount):
try:
# 开始事务
connection.begin()
# 操作1: 从一个账户扣款
update_balance(from_account, -amount)
# 操作2: 向另一个账户增加金额
update_balance(to_account, amount)
# 提交事务
connection.commit()
return "转账成功"
except Exception as e:
# 如果任何操作失败,回滚整个事务
connection.rollback()
return f"转账失败: {str(e)}"
如果在任意点发生错误,整个转账过程将被"撤销",保持账户余额不变。
一致性(Consistency):“遵守规则”
一致性类似于物理定律,比如能量守恒。在银行系统中,无论进行什么操作,所有账户的总金额应该保持不变(除非有存款或取款)。
一致性确保事务将数据库从一个有效状态转变为另一个有效状态,不违反任何完整性约束。
# 银行转账中的一致性示例
def transfer_money(from_account, to_account, amount):
# 检查账户是否存在
if not account_exists(from_account) or not account_exists(to_account):
return "账户不存在"
# 检查余额是否充足
if get_balance(from_account) < amount:
return "余额不足"
# 验证金额是否为正
if amount <= 0:
return "转账金额必须大于零"
# 执行转账(原子性保证)
try:
connection.begin()
update_balance(from_account, -amount)
update_balance(to_account, amount)
connection.commit()
return "转账成功"
except Exception as e:
connection.rollback()
return f"转账失败: {str(e)}"
一致性规则可以是:
- 账户余额不能为负
- 转账金额必须大于零
- 转账前后,系统总金额保持不变
隔离性(Isolation):“各走各的路”
想象在繁忙的十字路口,没有红绿灯会发生什么?车辆互相碰撞。交通信号灯确保不同方向的车流互不干扰,有序通行。
隔离性确保并发执行的事务互不干扰,就像它们是顺序执行的一样。
# 不同隔离级别的示例:读未提交(Read Uncommitted)
connection.execute("SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED")
# 读已提交(Read Committed)
connection.execute("SET TRANSACTION ISOLATION LEVEL READ COMMITTED")
# 可重复读(Repeatable Read)
connection.execute("SET TRANSACTION ISOLATION LEVEL REPEATABLE READ")
# 串行化(Serializable)
connection.execute("SET TRANSACTION ISOLATION LEVEL SERIALIZABLE")
隔离性可以防止以下问题:
- 脏读:读取到其他事务未提交的数据
- 不可重复读:同一事务内多次读取同一数据得到不同结果
- 幻读:同一事务内多次查询返回的结果集不同
持久性(Durability):“写入石头,而非沙滩”
你在纸上写下重要信息后,可能会将其拍照或扫描备份,以防纸张丢失。
持久性确保一旦事务提交,其结果就永久保存,即使系统崩溃也不会丢失。
# 持久性通常通过数据库配置实现
# MySQL示例:确保事务提交后写入磁盘
connection.execute("SET innodb_flush_log_at_trx_commit = 1")
数据库通过以下机制实现持久性:
- 事务日志(WAL, Write-Ahead Logging)
- 检查点(Checkpoints)
- 数据复制
ACID在实际应用中的挑战
关系数据库如MySQL、PostgreSQL都严格实现了ACID特性,但这种严格的保证在以下场景中面临挑战:
1. 高并发系统
想象一个热门电商网站的"秒杀"活动,数百万用户同时访问。ACID事务可能导致大量锁定和争用,严重影响性能。
2. 分布式系统
当数据分散在多个服务器上时,完全的ACID保证变得极其昂贵,甚至不可能实现。这涉及到分布式系统的基础理论:CAP定理。
CAP定理:不可能三角
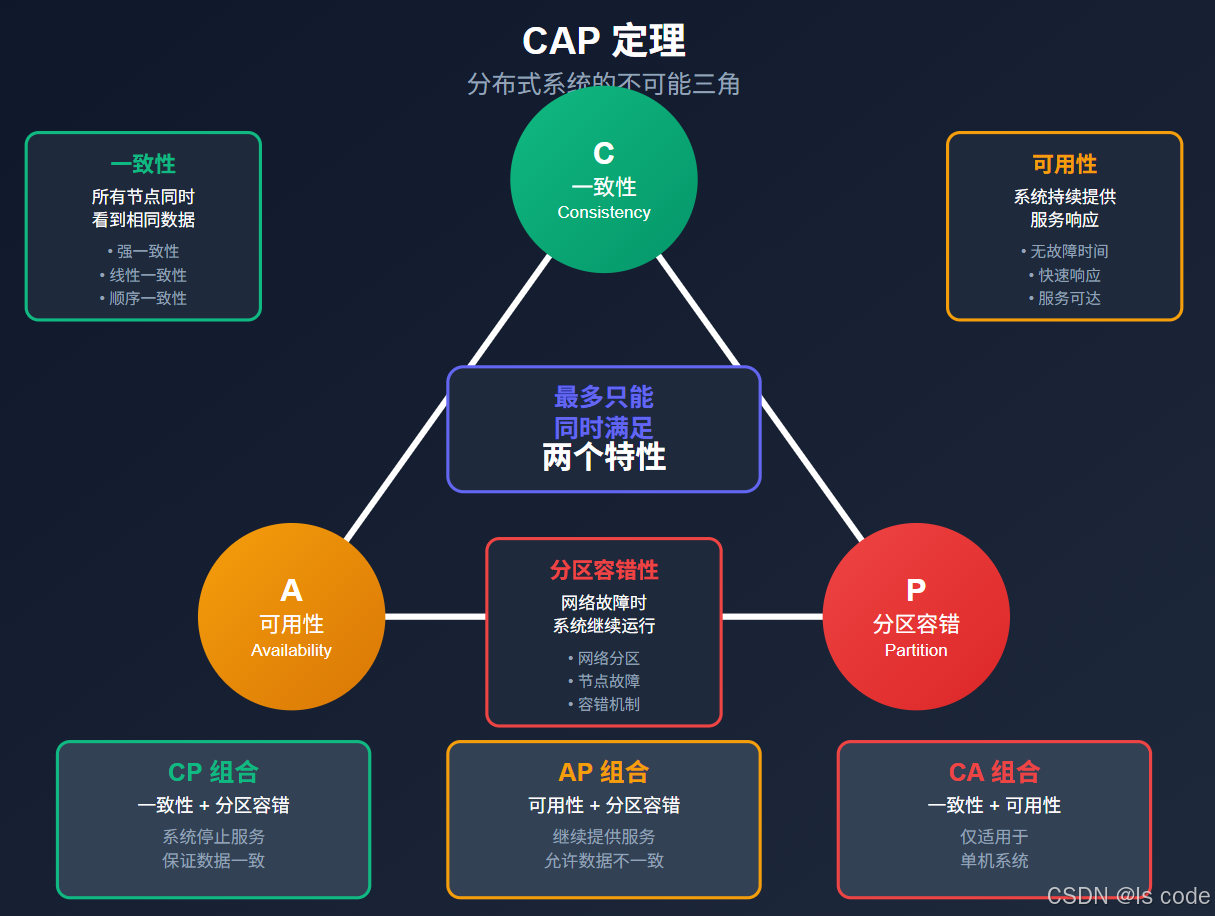
图3:CAP定理的不可能三角
CAP定理指出,在分布式系统中,以下三个特性最多只能同时满足两个:
- 一致性©:所有节点同时看到相同的数据
- 可用性(A):每个请求都能得到响应(成功或失败)
- 分区容错性§:即使部分网络故障,系统仍能继续运行
在实际的分布式系统中,网络分区是不可避免的,所以我们必须在C和A之间做出选择。这就是为什么需要更灵活的事务模型——BASE。
BASE模型:分布式世界的"柔性承诺"
BASE是对ACID的一种妥协,更适合分布式系统,代表:
- 基本可用(Basically Available)
- 软状态(Soft State)
- 最终一致性(Eventually Consistent)
让我们通过日常类比理解这些概念:
基本可用(Basically Available)
想象一家繁忙的餐厅,高峰期可能无法提供完整菜单,但仍能保证基本服务。系统在面对故障时可能降级服务,但不会完全不可用。
# 电商系统中的基本可用示例
def get_product_details(product_id):
try:
# 尝试获取完整产品信息
full_details = product_service.get_details(product_id)
return full_details
except ServiceTimeout:
# 服务超时时,返回缓存的基本信息
basic_info = cache.get(f"product:{product_id}:basic")
return basic_info
except ServiceUnavailable:
# 服务不可用时,返回最小产品信息集
return {
"product_id": product_id,
"name": "商品信息加载中...",
"status": "unavailable"
}
软状态(Soft State)
考虑邮件系统:当你发送邮件时,它可能不会立即出现在收件人的收件箱中,系统处于"软状态"——接受了临时的不一致。
软状态意味着系统可能存在短暂的不一致状态,不需要所有操作都即时反映。
# 社交媒体点赞功能中的软状态示例
def like_post(user_id, post_id):
# 立即更新本地计数器(可能与实际总数不同步)
cache.increment(f"post:{post_id}:likes")
# 异步更新数据库(最终一致)
background_tasks.add_task(update_like_in_database, user_id, post_id)
# 立即返回给用户,展示乐观的UI更新
return {
"status": "success",
"local_count": cache.get(f"post:{post_id}:likes")
}
最终一致性(Eventually Consistent)
回想在线银行转账:有时资金并不立即出现在接收方账户,系统会显示"处理中",但最终会达到一致状态。
最终一致性保证如果没有新的更新,数据最终将传播到所有节点,系统达到一致状态。
# 分布式系统中的最终一致性示例
def update_user_profile(user_id, new_data):
# 更新主数据库
primary_db.update_user(user_id, new_data)
# 发布更新事件到消息队列
message_queue.publish("user_updated", {
"user_id": user_id,
"data": new_data,
"timestamp": time.time()
})
return {
"status": "success",
"message": "资料已更新,可能需要几分钟才能在所有系统中生效"
}
ACID vs BASE:如何选择?
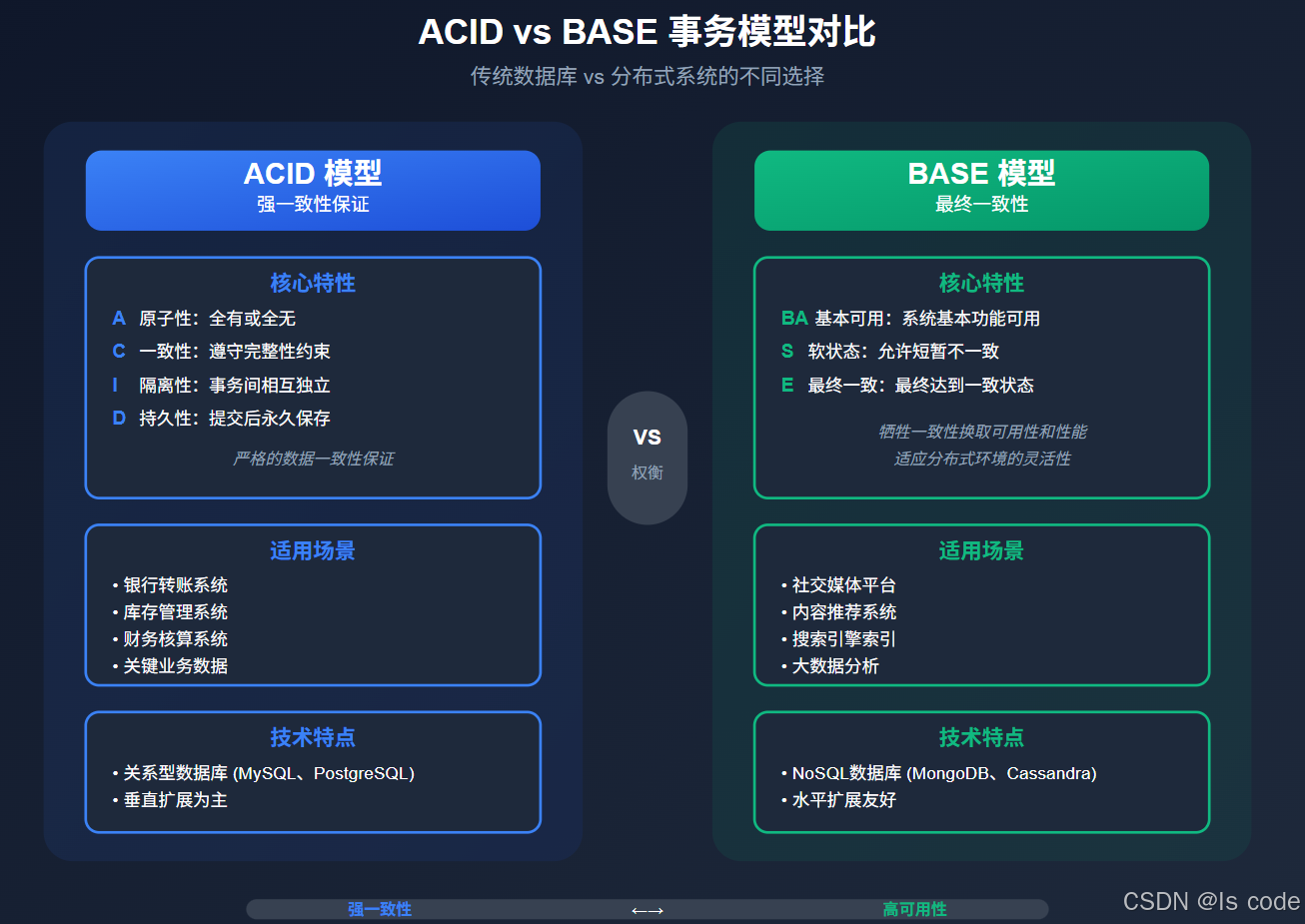
图4:ACID与BASE事务模型对比
ACID和BASE并非对立关系,而是连续体的两端。选择取决于你的具体需求:
| 特性 | ACID适用场景 | BASE适用场景 |
|---|---|---|
| 数据一致性 | 银行、金融交易、库存管理 | 社交媒体、内容推荐、日志系统 |
| 系统规模 | 中小规模、单机或有限分布式 | 大规模分布式系统、全球部署 |
| 操作延迟 | 低延迟要求、实时操作 | 可接受短暂延迟、异步操作 |
| 故障模式 | 宁可拒绝服务也不破坏一致性 | 宁可提供部分服务也不完全不可用 |
实战案例:构建电商订单系统
让我们通过构建电商订单系统,展示如何在实际项目中结合ACID和BASE模型:
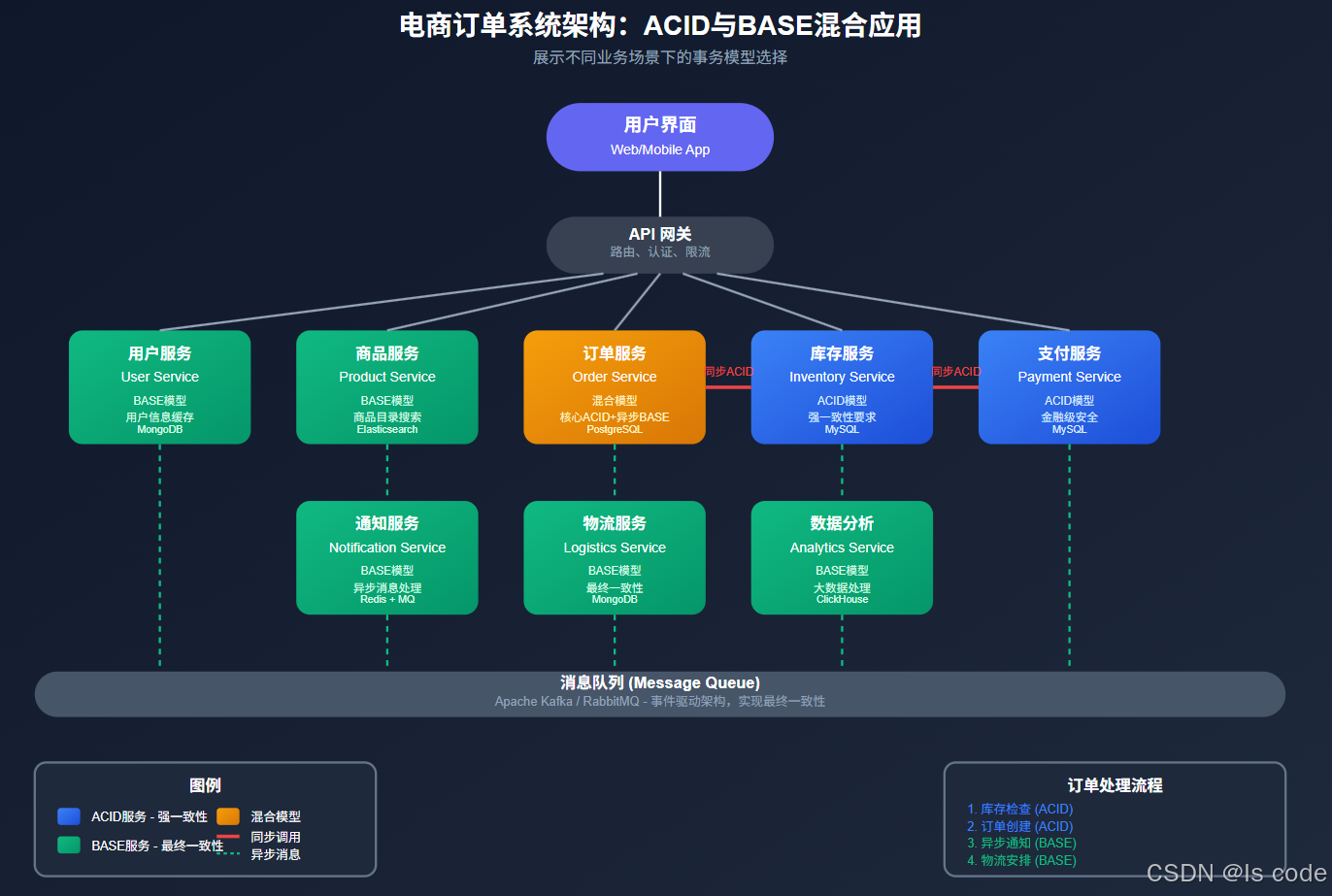
图5:电商订单系统中ACID与BASE的混合应用
系统架构
我们的电商系统包括以下微服务:
- 用户服务:管理用户账户和信息
- 产品服务:管理商品目录和库存
- 订单服务:处理订单创建和支付
- 物流服务:管理订单配送
- 通知服务:发送邮件和短信通知
混合事务策略
# 订单创建过程
def create_order(user_id, items, shipping_address):
# 第1阶段:库存检查和锁定(需要一致性)
try:
# 使用ACID事务检查并锁定库存
connection.begin()
# 验证所有商品库存充足
for item in items:
available = inventory_service.check_availability(
item['product_id'],
item['quantity']
)
if not available:
connection.rollback()
return {
"status": "failed",
"reason": f"商品 {item['product_id']} 库存不足"
}
# 创建订单记录
order_id = order_service.create_order_record(user_id, items, shipping_address)
# 锁定库存
for item in items:
inventory_service.reserve_inventory(
item['product_id'],
item['quantity'],
order_id
)
# 提交事务
connection.commit()
except Exception as e:
connection.rollback()
return {"status": "failed", "reason": str(e)}
# 第2阶段:异步处理(使用BASE模型)
try:
# 初始化支付(异步)
payment_task_id = payment_service.initialize_payment(order_id)
# 发送确认邮件(异步)
notification_service.send_order_confirmation(user_id, order_id)
# 准备物流(异步)
logistics_service.prepare_shipment(order_id)
return {
"status": "success",
"order_id": order_id,
"message": "订单已创建,正在处理支付"
}
except Exception as e:
# 记录错误,但不影响订单创建的成功状态
error_tracking.log_error(f"订单后处理异常: {str(e)}")
return {
"status": "success",
"order_id": order_id,
"message": "订单已创建,但部分系统处理异常,请稍后查看订单状态"
}
补偿事务和最终一致性
对于BASE模型下的操作,我们需要实现补偿机制确保最终一致性:
# 支付失败后的库存释放(补偿事务)
def handle_payment_failure(order_id):
try:
# 获取订单信息
order = order_service.get_order(order_id)
# 修改订单状态
order_service.update_status(order_id, "PAYMENT_FAILED")
# 释放库存(补偿事务)
for item in order['items']:
inventory_service.release_inventory(
item['product_id'],
item['quantity'],
order_id
)
# 通知用户
notification_service.send_payment_failure_notice(order['user_id'], order_id)
return {"status": "success", "message": "支付失败处理完成"}
except Exception as e:
# 记录错误,安排重试
error_tracking.log_error(f"支付失败处理异常: {str(e)}")
retry_queue.add_task(
handle_payment_failure,
order_id,
retry_delay=300 # 5分钟后重试
)
return {"status": "error", "message": "处理异常,已安排重试"}
事件溯源和CQRS模式
对于复杂的分布式系统,可以采用事件溯源和CQRS(命令查询职责分离)模式:
# 订单事件溯源示例
def process_order_event(event):
event_type = event['type']
order_id = event['order_id']
timestamp = event['timestamp']
data = event['data']
# 持久化事件
event_store.save_event(order_id, event_type, data, timestamp)
# 根据事件类型处理
if event_type == "ORDER_CREATED":
# 更新订单视图
order_view_service.create_order(order_id, data)
elif event_type == "PAYMENT_RECEIVED":
# 更新订单状态
order_view_service.update_payment_status(order_id, data)
# 触发发货流程
logistics_service.initiate_shipment(order_id)
elif event_type == "INVENTORY_RESERVED":
# 更新库存视图
inventory_view_service.update_reserved_quantity(
data['product_id'],
data['quantity']
)
# ... 处理其他事件类型
常见问题与解答
Q1: 什么情况下应该坚持使用ACID?
答: 处理涉及金钱、法律责任或关键业务数据的操作时,ACID事务不可妥协。例如:
- 资金转账
- 库存变动与结算
- 合同签署
- 医疗记录更新
Q2: BASE模型会导致数据丢失吗?
答: BASE模型本身不会导致数据丢失,但它接受数据可能暂时处于不一致状态。设计良好的BASE系统应该包含:
- 持久的事件日志
- 失败重试机制
- 补偿事务
- 定期一致性检查
Q3: 混合使用ACID和BASE的最佳实践是什么?
答:
- 识别核心业务领域,对关键操作使用ACID
- 将系统分解成可独立扩展的服务
- 使用消息队列解耦服务间通信
- 实现补偿事务处理失败
- 建立监控系统及时发现不一致
Q4: 不同数据库系统对ACID的支持程度如何?
答:
- 关系型数据库 (MySQL, PostgreSQL, Oracle):完全支持ACID
- NoSQL文档数据库 (MongoDB):单文档级别ACID,多文档事务有限支持
- 键值存储 (Redis):单键操作原子性,有限事务支持
- 列式数据库 (Cassandra):通常采用BASE模型,提供最终一致性
- 图数据库 (Neo4j):支持ACID事务
- NewSQL (Google Spanner, CockroachDB):试图在分布式环境中提供完整ACID
结语:事务模型的未来
随着分布式系统的普及,传统的ACID和BASE模型正在融合,出现了像谷歌Spanner这样尝试在全球规模提供ACID保证的新技术。但无论技术如何发展,理解事务的基本原理始终是设计可靠系统的关键。
在系统设计中,应该根据业务需求和数据特性,灵活选择适合的事务模型。有时候,最佳解决方案不是选择ACID或BASE,而是明智地结合两者,取长补短。
当我们转向更分布式、更复杂的系统时,请记住:数据一致性不仅仅是技术问题,更是业务需求的反映。只有理解了业务对一致性的真正需求,才能设计出既满足功能需求又高效可靠的系统。
本文是"数据库技术系列"的重要篇章,通过银行转账到电商系统的案例,深入解析了ACID和BASE事务模型的原理与应用。在下一篇文章中,我们将探索数据库索引的世界,了解这一提升查询性能的关键技术。
📚 推荐阅读:
- 《设计数据密集型应用》- 深入理解现代数据系统
- 《数据库系统概念》- 事务理论基础
- 《微服务架构设计模式》- 分布式系统实践




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











