









从零构建网络爬虫:HTTP协议深度解析与Python请求实战
关键词: HTTP协议、网络爬虫、Python爬虫、请求头、响应码、Cookie、Session、User-Agent、反爬虫、请求构建
摘要: 本文通过费曼学习法深入解析网络爬虫的基础知识,从HTTP协议的本质出发,用生活化的类比帮助读者理解网络通信原理。文章详细介绍了HTTP请求的构建方法、常见反爬虫机制的应对策略,以及Python实现爬虫的最佳实践,让你从零基础成长为爬虫开发专家。
引言:为什么说理解HTTP协议是爬虫开发的第一课?
想象一下,你要去图书馆借书。你需要知道图书馆的开放时间、借书规则、如何与管理员沟通,以及如何正确填写借书单。网络爬虫的工作原理与此类似:HTTP协议就是网络世界的"借书规则",它定义了客户端(你)和服务器(图书馆)之间的通信方式。
不理解HTTP协议就写爬虫,就像不懂图书馆规则就去借书——你可能会被拒绝服务,甚至被"拉黑"。本文将带你深入理解HTTP协议的每个细节,掌握构建高效、稳定爬虫的核心技能。
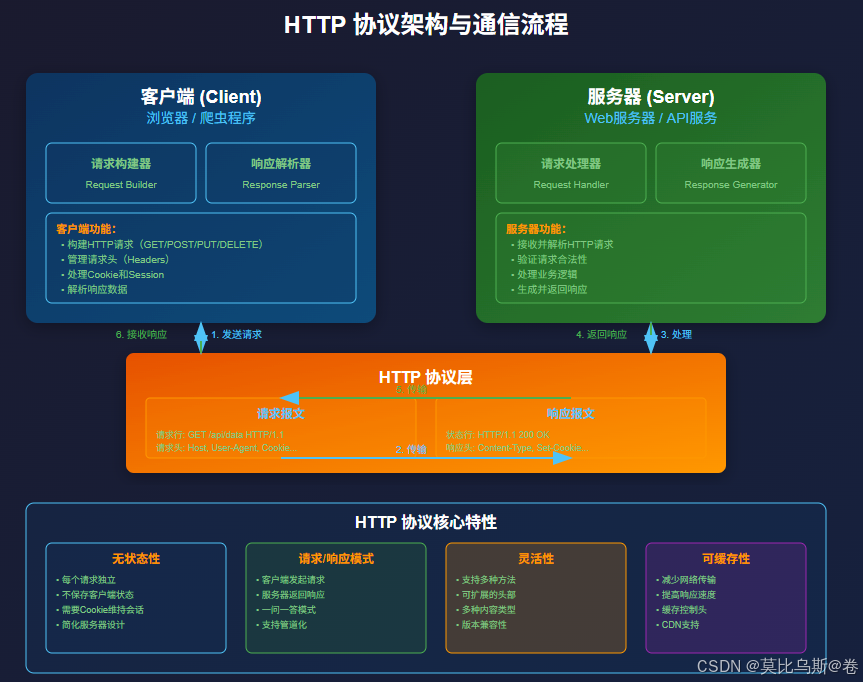
第一部分:HTTP协议的本质
1.1 什么是HTTP协议?
HTTP(HyperText Transfer Protocol)是互联网的基础协议,它定义了浏览器和服务器之间的对话规则。
# HTTP请求的基本结构示例
import requests
# 一个简单的HTTP GET请求
response = requests.get('https://httpbin.org/get')
# 查看请求和响应的详细信息
print(f"请求方法: {response.request.method}")
print(f"请求URL: {response.request.url}")
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.text[:200]}...")
1.2 HTTP请求的组成部分
1. 请求行(Request Line)
# 请求行包含:方法 + URL + 协议版本
# GET /api/users HTTP/1.1
# Python中构建不同类型的请求
def demonstrate_http_methods():
"""演示不同的HTTP方法"""
base_url = "https://httpbin.org"
# GET请求 - 获取资源
get_response = requests.get(f"{base_url}/get")
print(f"GET请求状态: {get_response.status_code}")
# POST请求 - 创建资源
post_data = {"name": "张三", "age": 25}
post_response = requests.post(f"{base_url}/post", json=post_data)
print(f"POST请求状态: {post_response.status_code}")
# PUT请求 - 更新资源
put_response = requests.put(f"{base_url}/put", json=post_data)
print(f"PUT请求状态: {put_response.status_code}")
# DELETE请求 - 删除资源
delete_response = requests.delete(f"{base_url}/delete")
print(f"DELETE请求状态: {delete_response.status_code}")
demonstrate_http_methods()
2. 请求头(Request Headers)
# 请求头是爬虫伪装的关键
def build_headers():
"""构建常用的请求头"""
headers = {
# 用户代理 - 告诉服务器你是什么浏览器
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
# 接受的内容类型
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 接受的语言
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
# 接受的编码
'Accept-Encoding': 'gzip, deflate, br',
# 来源页面
'Referer': 'https://www.google.com/',
# 连接类型
'Connection': 'keep-alive',
# 缓存控制
'Cache-Control': 'max-age=0'
}
return headers
# 使用自定义请求头
headers = build_headers()
response = requests.get('https://httpbin.org/headers', headers=headers)
print("服务器看到的请求头:")
print(response.json()['headers'])
3. 请求体(Request Body)
# 不同格式的请求体
def demonstrate_request_bodies():
"""演示不同类型的请求体"""
url = "https://httpbin.org/post"
# 1. 表单数据 (application/x-www-form-urlencoded)
form_data = {
'username': 'user123',
'password': 'pass456'
}
response1 = requests.post(url, data=form_data)
print("表单数据请求:")
print(response1.json()['form'])
# 2. JSON数据 (application/json)
json_data = {
'name': '产品A',
'price': 99.99,
'tags': ['热销', '新品']
}
response2 = requests.post(url, json=json_data)
print("\nJSON数据请求:")
print(response2.json()['json'])
# 3. 文件上传 (multipart/form-data)
files = {
'file': ('test.txt', 'Hello World!', 'text/plain')
}
response3 = requests.post(url, files=files)
print("\n文件上传请求:")
print(response3.json()['files'])
demonstrate_request_bodies()
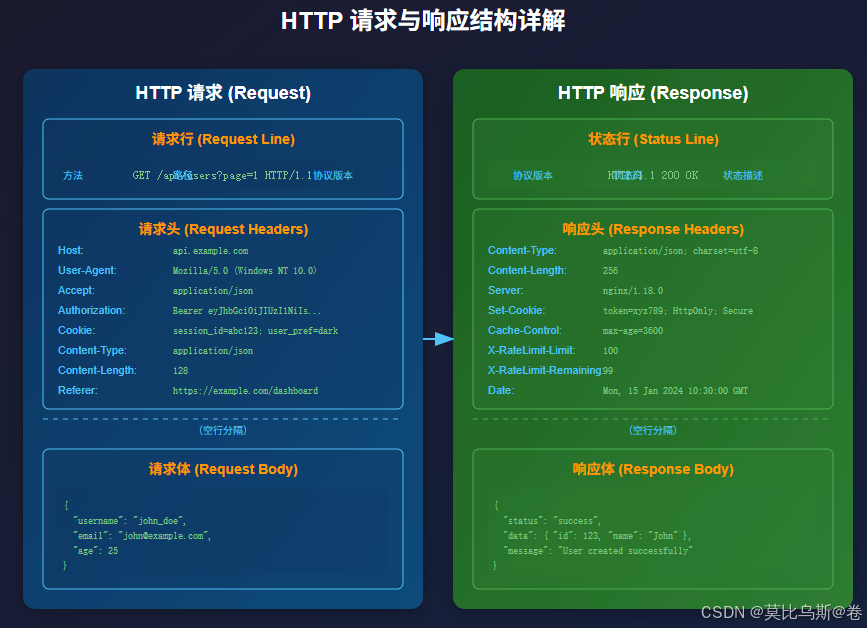
1.3 HTTP响应的解析
class HTTPResponseParser:
"""HTTP响应解析器"""
def __init__(self, response):
self.response = response
def parse_status(self):
"""解析状态码"""
status_codes = {
200: "成功 - 请求已成功处理",
201: "已创建 - 成功创建了新资源",
204: "无内容 - 请求成功但无返回内容",
301: "永久重定向",
302: "临时重定向",
304: "未修改 - 资源未改变",
400: "错误请求 - 请求格式错误",
401: "未授权 - 需要身份验证",
403: "禁止访问 - 服务器拒绝请求",
404: "未找到 - 请求的资源不存在",
429: "请求过多 - 触发了速率限制",
500: "服务器错误",
502: "网关错误",
503: "服务不可用"
}
code = self.response.status_code
description = status_codes.get(code, "未知状态码")
return f"{code} - {description}"
def parse_headers(self):
"""解析响应头"""
important_headers = {
'Content-Type': '内容类型',
'Content-Length': '内容长度',
'Set-Cookie': 'Cookie设置',
'Server': '服务器类型',
'X-RateLimit-Limit': '速率限制',
'X-RateLimit-Remaining': '剩余请求数'
}
headers_info = {}
for key, desc in important_headers.items():
if key in self.response.headers:
headers_info[desc] = self.response.headers[key]
return headers_info
def parse_cookies(self):
"""解析Cookies"""
return dict(self.response.cookies)
def get_encoding(self):
"""获取编码信息"""
return {
'声明编码': self.response.encoding,
'检测编码': self.response.apparent_encoding,
'内容编码': self.response.headers.get('Content-Encoding', 'None')
}
# 使用示例
response = requests.get('https://httpbin.org/get')
parser = HTTPResponseParser(response)
print("状态码解析:", parser.parse_status())
print("响应头信息:", parser.parse_headers())
print("编码信息:", parser.get_encoding())
第二部分:Cookie与Session管理
2.1 理解Cookie机制
Cookie就像是网站给你的"会员卡",每次访问时出示这张卡,网站就知道你是谁。
import requests
from http.cookiejar import CookieJar
class CookieManager:
"""Cookie管理器"""
def __init__(self):
self.session = requests.Session()
self.cookie_jar = CookieJar()
def demonstrate_cookie_usage(self):
"""演示Cookie的使用"""
# 1. 获取Cookie
response = self.session.get('https://httpbin.org/cookies/set/user_id/12345')
print("设置的Cookie:", dict(response.cookies))
# 2. 发送带Cookie的请求
response2 = self.session.get('https://httpbin.org/cookies')
print("服务器收到的Cookie:", response2.json())
# 3. 手动设置Cookie
self.session.cookies.set('session_token', 'abc123xyz', domain='httpbin.org')
# 4. 查看所有Cookie
print("\n当前所有Cookie:")
for cookie in self.session.cookies:
print(f" {cookie.name} = {cookie.value} (域名: {cookie.domain})")
def save_cookies(self, filename):
"""保存Cookie到文件"""
import pickle
with open(filename, 'wb') as f:
pickle.dump(self.session.cookies, f)
print(f"Cookie已保存到 {filename}")
def load_cookies(self, filename):
"""从文件加载Cookie"""
import pickle
with open(filename, 'rb') as f:
cookies = pickle.load(f)
self.session.cookies.update(cookies)
print(f"Cookie已从 {filename} 加载")
# 使用示例
cookie_mgr = CookieManager()
cookie_mgr.demonstrate_cookie_usage()
2.2 Session会话保持
class SessionManager:
"""会话管理器 - 模拟登录状态保持"""
def __init__(self):
self.session = requests.Session()
# 设置默认请求头
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
def login_example(self, username, password):
"""模拟登录过程"""
# 1. 访问登录页面(获取CSRF token等)
login_page = self.session.get('https://httpbin.org/forms/post')
# 2. 提交登录表单
login_data = {
'username': username,
'password': password,
'remember_me': 'on'
}
login_response = self.session.post(
'https://httpbin.org/post',
data=login_data
)
if login_response.status_code == 200:
print("登录成功!")
# Session会自动保存服务器返回的Cookie
return True
else:
print("登录失败!")
return False
def access_protected_resource(self):
"""访问需要登录的资源"""
# 使用同一个session,自动携带登录时的Cookie
response = self.session.get('https://httpbin.org/cookies')
return response.json()
def maintain_session(self):
"""保持会话活跃"""
# 定期发送心跳请求,防止session过期
heartbeat_response = self.session.get('https://httpbin.org/get')
return heartbeat_response.status_code == 200
# 完整的会话管理流程
def complete_session_workflow():
"""完整的会话管理工作流程"""
session_mgr = SessionManager()
# 1. 登录
if session_mgr.login_example('user123', 'pass456'):
# 2. 访问受保护资源
data = session_mgr.access_protected_resource()
print("获取的数据:", data)
# 3. 保持会话
if session_mgr.maintain_session():
print("会话保持成功")
complete_session_workflow()
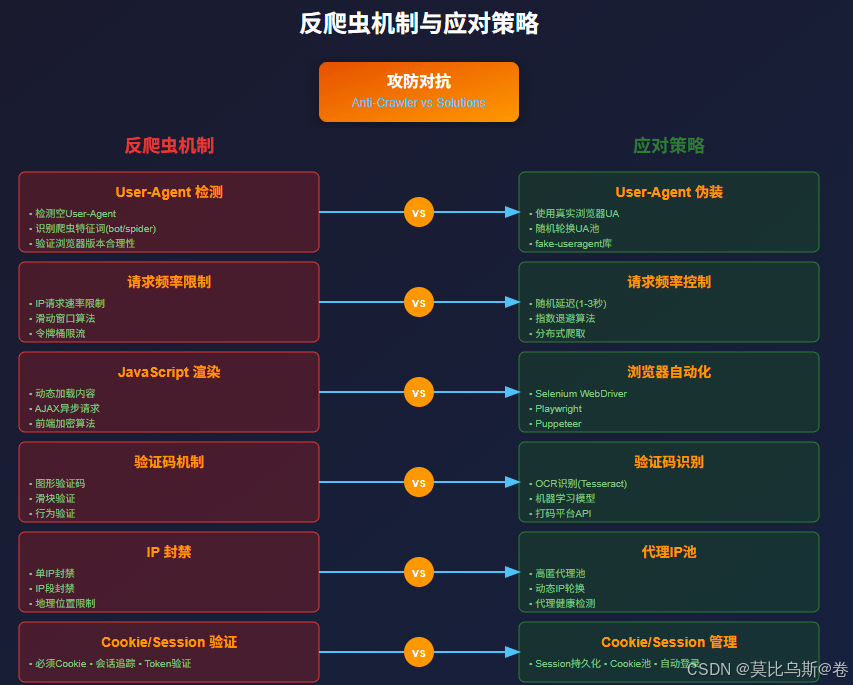
第三部分:反爬虫机制与应对策略
3.1 常见反爬虫机制
class AntiCrawlerDetector:
"""反爬虫检测器"""
def __init__(self):
self.detection_methods = {
'user_agent': self.check_user_agent,
'request_rate': self.check_request_rate,
'referer': self.check_referer,
'cookies': self.check_cookies,
'javascript': self.check_javascript,
'ip_blocking': self.check_ip_blocking
}
def check_user_agent(self, headers):
"""检查User-Agent"""
ua = headers.get('User-Agent', '')
# 常见的爬虫特征
bot_keywords = ['bot', 'crawler', 'spider', 'scraper', 'python-requests']
for keyword in bot_keywords:
if keyword.lower() in ua.lower():
return False, f"检测到爬虫关键词: {keyword}"
if not ua:
return False, "缺少User-Agent"
return True, "User-Agent正常"
def check_request_rate(self, request_times):
"""检查请求频率"""
if len(request_times) < 2:
return True, "请求次数不足"
# 计算平均请求间隔
intervals = []
for i in range(1, len(request_times)):
interval = request_times[i] - request_times[i-1]
intervals.append(interval)
avg_interval = sum(intervals) / len(intervals)
if avg_interval < 0.5: # 平均间隔小于0.5秒
return False, f"请求过快: 平均间隔{avg_interval:.2f}秒"
return True, "请求频率正常"
def check_referer(self, headers, expected_domain):
"""检查Referer"""
referer = headers.get('Referer', '')
if not referer:
return False, "缺少Referer"
if expected_domain not in referer:
return False, f"Referer不匹配: {referer}"
return True, "Referer正常"
3.2 反爬虫应对策略
import time
import random
from fake_useragent import UserAgent
class AntiAntiCrawler:
"""反-反爬虫策略实现"""
def __init__(self):
self.ua = UserAgent()
self.session = requests.Session()
self.request_count = 0
def get_random_headers(self):
"""生成随机请求头"""
headers = {
'User-Agent': self.ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': random.choice([
'zh-CN,zh;q=0.9,en;q=0.8',
'en-US,en;q=0.9',
'zh-CN,zh;q=0.8,zh-TW;q=0.7'
]),
'Accept-Encoding': 'gzip, deflate, br',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
return headers
def random_delay(self, min_delay=1, max_delay=3):
"""随机延迟"""
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
return delay
def rotate_proxy(self):
"""代理轮换(示例)"""
proxy_list = [
'http://proxy1.com:8080',
'http://proxy2.com:8080',
'http://proxy3.com:8080'
]
proxy = random.choice(proxy_list)
return {
'http': proxy,
'https': proxy
}
def smart_request(self, url, **kwargs):
"""智能请求 - 综合反爬虫策略"""
# 1. 设置随机请求头
headers = self.get_random_headers()
if 'headers' in kwargs:
headers.update(kwargs['headers'])
kwargs['headers'] = headers
# 2. 添加随机延迟
if self.request_count > 0:
delay = self.random_delay()
print(f"延迟 {delay:.2f} 秒...")
# 3. 使用代理(如果需要)
# kwargs['proxies'] = self.rotate_proxy()
# 4. 发送请求
try:
response = self.session.get(url, **kwargs)
self.request_count += 1
# 5. 检查响应
if response.status_code == 429:
print("触发速率限制,等待60秒...")
time.sleep(60)
return self.smart_request(url, **kwargs)
return response
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
def handle_javascript_challenge(self, url):
"""处理JavaScript挑战(使用Selenium)"""
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 配置Chrome选项
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
# 创建浏览器实例
driver = webdriver.Chrome(options=chrome_options)
try:
# 访问页面
driver.get(url)
# 等待JavaScript执行
time.sleep(3)
# 获取页面源码
page_source = driver.page_source
# 获取Cookies
cookies = driver.get_cookies()
return page_source, cookies
finally:
driver.quit()
# 使用示例
anti_crawler = AntiAntiCrawler()
# 智能请求
response = anti_crawler.smart_request('https://httpbin.org/get')
if response:
print(f"请求成功: {response.status_code}")
第四部分:高级请求技巧
4.1 并发请求优化
import asyncio
import aiohttp
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
class ConcurrentCrawler:
"""并发爬虫实现"""
def __init__(self, max_workers=10):
self.max_workers = max_workers
self.results = []
def fetch_url_sync(self, session, url):
"""同步请求单个URL"""
try:
response = session.get(url, timeout=10)
return {
'url': url,
'status': response.status_code,
'length': len(response.content),
'success': True
}
except Exception as e:
return {
'url': url,
'error': str(e),
'success': False
}
def concurrent_requests_threading(self, urls):
"""使用线程池的并发请求"""
start_time = time.time()
results = []
with requests.Session() as session:
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
# 提交所有任务
future_to_url = {
executor.submit(self.fetch_url_sync, session, url): url
for url in urls
}
# 获取结果
for future in as_completed(future_to_url):
result = future.result()
results.append(result)
print(f"完成: {result['url']} - 状态: {result.get('status', 'ERROR')}")
elapsed_time = time.time() - start_time
print(f"\n线程池并发完成 {len(urls)} 个请求,耗时: {elapsed_time:.2f} 秒")
return results
async def fetch_url_async(self, session, url):
"""异步请求单个URL"""
try:
async with session.get(url) as response:
content = await response.read()
return {
'url': url,
'status': response.status,
'length': len(content),
'success': True
}
except Exception as e:
return {
'url': url,
'error': str(e),
'success': False
}
async def concurrent_requests_async(self, urls):
"""使用异步IO的并发请求"""
start_time = time.time()
# 创建连接池限制
connector = aiohttp.TCPConnector(limit=self.max_workers)
timeout = aiohttp.ClientTimeout(total=30)
async with aiohttp.ClientSession(connector=connector, timeout=timeout) as session:
# 创建所有任务
tasks = [self.fetch_url_async(session, url) for url in urls]
# 并发执行
results = await asyncio.gather(*tasks)
elapsed_time = time.time() - start_time
print(f"\n异步IO并发完成 {len(urls)} 个请求,耗时: {elapsed_time:.2f} 秒")
return results
# 性能对比测试
def performance_comparison():
"""对比不同并发方式的性能"""
urls = [f'https://httpbin.org/delay/{i%3}' for i in range(20)]
crawler = ConcurrentCrawler(max_workers=5)
# 1. 顺序请求(作为对比)
print("=== 顺序请求 ===")
start = time.time()
session = requests.Session()
for url in urls:
crawler.fetch_url_sync(session, url)
sequential_time = time.time() - start
print(f"顺序请求耗时: {sequential_time:.2f} 秒")
# 2. 线程池并发
print("\n=== 线程池并发 ===")
crawler.concurrent_requests_threading(urls)
# 3. 异步IO并发
print("\n=== 异步IO并发 ===")
asyncio.run(crawler.concurrent_requests_async(urls))
# 运行性能对比
# performance_comparison()
4.2 请求重试机制
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
class SmartRetrySession:
"""智能重试会话"""
def __init__(self,
retries=3,
backoff_factor=0.3,
status_forcelist=(500, 502, 504)):
self.session = requests.Session()
# 配置重试策略
retry_strategy = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
allowed_methods=["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"]
)
# 应用重试策略
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("http://", adapter)
self.session.mount("https://", adapter)
def request_with_retry(self, method, url, **kwargs):
"""带重试的请求"""
max_retries = 3
retry_count = 0
while retry_count < max_retries:
try:
response = self.session.request(method, url, **kwargs)
# 检查响应
if response.status_code < 400:
return response
elif response.status_code == 429: # Too Many Requests
# 从响应头获取重试时间
retry_after = int(response.headers.get('Retry-After', 60))
print(f"速率限制,等待 {retry_after} 秒后重试...")
time.sleep(retry_after)
else:
response.raise_for_status()
except requests.exceptions.RequestException as e:
retry_count += 1
if retry_count >= max_retries:
print(f"重试 {max_retries} 次后仍然失败: {e}")
raise
# 指数退避
wait_time = (2 ** retry_count) + random.uniform(0, 1)
print(f"请求失败,{wait_time:.2f} 秒后重试 ({retry_count}/{max_retries})...")
time.sleep(wait_time)
return None
# 使用示例
retry_session = SmartRetrySession()
response = retry_session.request_with_retry('GET', 'https://httpbin.org/status/500')
第五部分:实战案例
5.1 构建一个完整的爬虫类
import json
import csv
from datetime import datetime
from urllib.parse import urljoin, urlparse
class WebCrawler:
"""完整的网页爬虫实现"""
def __init__(self, base_url, output_format='json'):
self.base_url = base_url
self.domain = urlparse(base_url).netloc
self.session = requests.Session()
self.visited_urls = set()
self.output_format = output_format
self.data = []
# 设置请求头
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
def is_valid_url(self, url):
"""验证URL是否有效"""
try:
result = urlparse(url)
return all([result.scheme, result.netloc])
except:
return False
def normalize_url(self, url):
"""标准化URL"""
# 处理相对路径
if not url.startswith(('http://', 'https://')):
url = urljoin(self.base_url, url)
# 移除锚点
url = url.split('#')[0]
# 移除末尾斜杠
if url.endswith('/'):
url = url[:-1]
return url
def extract_data(self, response):
"""从响应中提取数据"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# 提取页面信息
data = {
'url': response.url,
'title': soup.find('title').text if soup.find('title') else '',
'status_code': response.status_code,
'content_length': len(response.content),
'response_time': response.elapsed.total_seconds(),
'timestamp': datetime.now().isoformat()
}
# 提取所有链接
links = []
for link in soup.find_all('a', href=True):
href = self.normalize_url(link['href'])
if self.is_valid_url(href) and self.domain in href:
links.append(href)
data['links'] = links
data['link_count'] = len(links)
# 提取meta信息
meta_tags = {}
for meta in soup.find_all('meta'):
if meta.get('name'):
meta_tags[meta.get('name')] = meta.get('content', '')
data['meta_tags'] = meta_tags
return data
def crawl_page(self, url, depth=0, max_depth=2):
"""爬取单个页面"""
if depth > max_depth:
return
if url in self.visited_urls:
return
self.visited_urls.add(url)
try:
print(f"爬取: {url} (深度: {depth})")
# 添加延迟
time.sleep(random.uniform(0.5, 1.5))
# 发送请求
response = self.session.get(url, timeout=10)
response.raise_for_status()
# 提取数据
page_data = self.extract_data(response)
page_data['depth'] = depth
self.data.append(page_data)
# 递归爬取链接
for link in page_data['links'][:10]: # 限制每页爬取的链接数
self.crawl_page(link, depth + 1, max_depth)
except Exception as e:
print(f"爬取失败 {url}: {e}")
self.data.append({
'url': url,
'error': str(e),
'depth': depth,
'timestamp': datetime.now().isoformat()
})
def save_results(self, filename='crawl_results'):
"""保存爬取结果"""
if self.output_format == 'json':
with open(f'{filename}.json', 'w', encoding='utf-8') as f:
json.dump(self.data, f, ensure_ascii=False, indent=2)
print(f"结果已保存到 {filename}.json")
elif self.output_format == 'csv':
if not self.data:
return
keys = self.data[0].keys()
with open(f'{filename}.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=keys)
writer.writeheader()
writer.writerows(self.data)
print(f"结果已保存到 {filename}.csv")
def get_statistics(self):
"""获取爬取统计信息"""
total_pages = len(self.data)
successful_pages = len([d for d in self.data if 'error' not in d])
failed_pages = total_pages - successful_pages
avg_response_time = sum(d.get('response_time', 0) for d in self.data) / max(successful_pages, 1)
total_links = sum(d.get('link_count', 0) for d in self.data)
return {
'总页面数': total_pages,
'成功页面': successful_pages,
'失败页面': failed_pages,
'平均响应时间': f"{avg_response_time:.2f}秒",
'发现链接总数': total_links,
'唯一URL数': len(self.visited_urls)
}
# 使用示例
def run_crawler_example():
"""运行爬虫示例"""
crawler = WebCrawler('https://example.com', output_format='json')
# 开始爬取
crawler.crawl_page(crawler.base_url, max_depth=2)
# 保存结果
crawler.save_results('example_crawl')
# 显示统计信息
stats = crawler.get_statistics()
print("\n爬取统计:")
for key, value in stats.items():
print(f" {key}: {value}")
# run_crawler_example()
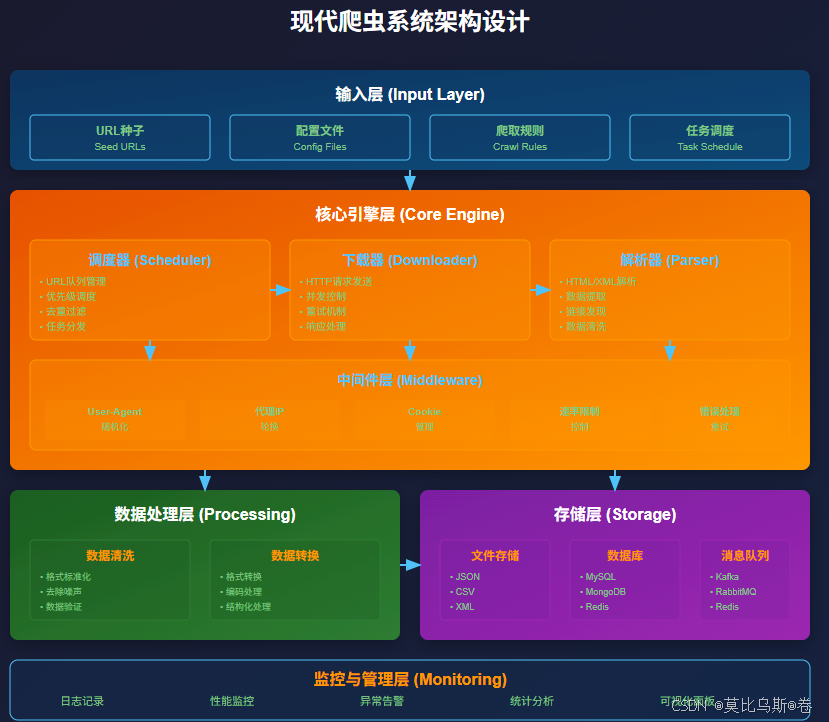
第六部分:最佳实践与注意事项
6.1 爬虫道德与法律
class EthicalCrawler:
"""道德爬虫实践"""
def __init__(self):
self.robots_cache = {}
def check_robots_txt(self, url):
"""检查robots.txt"""
from urllib.robotparser import RobotFileParser
parsed_url = urlparse(url)
robots_url = f"{parsed_url.scheme}://{parsed_url.netloc}/robots.txt"
# 缓存robots.txt
if robots_url not in self.robots_cache:
rp = RobotFileParser()
rp.set_url(robots_url)
try:
rp.read()
self.robots_cache[robots_url] = rp
except:
return True # 如果无法读取,默认允许
rp = self.robots_cache[robots_url]
return rp.can_fetch("*", url)
def get_crawl_delay(self, url):
"""获取爬取延迟"""
parsed_url = urlparse(url)
robots_url = f"{parsed_url.scheme}://{parsed_url.netloc}/robots.txt"
if robots_url in self.robots_cache:
rp = self.robots_cache[robots_url]
delay = rp.crawl_delay("*")
return delay if delay else 1.0
return 1.0 # 默认延迟1秒
def respectful_crawl(self, url):
"""尊重网站规则的爬取"""
# 1. 检查robots.txt
if not self.check_robots_txt(url):
print(f"robots.txt 禁止爬取: {url}")
return None
# 2. 获取爬取延迟
delay = self.get_crawl_delay(url)
print(f"等待 {delay} 秒...")
time.sleep(delay)
# 3. 发送请求
headers = {
'User-Agent': 'EthicalCrawler/1.0 (Contact: your-email@example.com)'
}
try:
response = requests.get(url, headers=headers, timeout=10)
return response
except Exception as e:
print(f"请求失败: {e}")
return None
# 爬虫最佳实践清单
CRAWLER_BEST_PRACTICES = """
爬虫开发最佳实践清单:
1. 遵守robots.txt
- 始终检查并遵守网站的robots.txt文件
- 尊重Crawl-delay指令
2. 控制请求频率
- 添加合理的延迟(1-3秒)
- 避免并发请求同一网站
- 实现请求速率限制
3. 标识身份
- 使用描述性的User-Agent
- 提供联系方式
4. 处理错误
- 实现重试机制
- 正确处理各种HTTP状态码
- 记录错误日志
5. 数据存储
- 及时保存数据,避免重复爬取
- 使用增量爬取策略
- 定期清理过期数据
6. 法律合规
- 遵守网站服务条款
- 尊重版权和隐私
- 不爬取个人敏感信息
7. 性能优化
- 使用连接池
- 启用HTTP压缩
- 缓存DNS查询
8. 监控告警
- 监控爬虫运行状态
- 设置异常告警
- 记录性能指标
"""
print(CRAWLER_BEST_PRACTICES)
结语:从理解到精通
通过本文的学习,你已经掌握了网络爬虫开发的核心知识:
- HTTP协议基础:理解了请求和响应的完整生命周期
- 请求构建技巧:学会了如何构建各种类型的HTTP请求
- 反爬虫应对:掌握了常见反爬虫机制的识别和应对方法
- 高级技术应用:了解了并发、异步、重试等高级技巧
- 道德规范遵守:明白了如何开发合法合规的爬虫
记住,爬虫技术是一把双刃剑。合理使用可以帮助我们高效获取公开数据,但滥用则可能触犯法律。始终保持对技术的敬畏之心,在合法合规的前提下探索数据的价值。
爬虫开发不仅是技术活,更是一门需要智慧和耐心的艺术。继续深入学习,你将在这个领域发现更多精彩!
扩展学习资源
- HTTP协议规范:RFC 7230-7235
- Python官方文档:requests、urllib、http.client
- 爬虫框架:Scrapy、BeautifulSoup、Selenium
- 反爬虫研究:《Python3反爬虫原理与绕过实战》
- 法律法规:《网络安全法》、《数据安全法》
- 性能优化:aiohttp、httpx异步HTTP客户端
ots.txt文件- 尊重Crawl-delay指令
-
控制请求频率
- 添加合理的延迟(1-3秒)
- 避免并发请求同一网站
- 实现请求速率限制
-
标识身份
- 使用描述性的User-Agent
- 提供联系方式
-
处理错误
- 实现重试机制
- 正确处理各种HTTP状态码
- 记录错误日志
-
数据存储
- 及时保存数据,避免重复爬取
- 使用增量爬取策略
- 定期清理过期数据
-
法律合规
- 遵守网站服务条款
- 尊重版权和隐私
- 不爬取个人敏感信息
-
性能优化
- 使用连接池
- 启用HTTP压缩
- 缓存DNS查询
-
监控告警
- 监控爬虫运行状态
- 设置异常告警
- 记录性能指标
“”"
print(CRAWLER_BEST_PRACTICES)
## 结语:从理解到精通
通过本文的学习,你已经掌握了网络爬虫开发的核心知识:
1. **HTTP协议基础**:理解了请求和响应的完整生命周期
2. **请求构建技巧**:学会了如何构建各种类型的HTTP请求
3. **反爬虫应对**:掌握了常见反爬虫机制的识别和应对方法
4. **高级技术应用**:了解了并发、异步、重试等高级技巧
5. **道德规范遵守**:明白了如何开发合法合规的爬虫
记住,爬虫技术是一把双刃剑。合理使用可以帮助我们高效获取公开数据,但滥用则可能触犯法律。始终保持对技术的敬畏之心,在合法合规的前提下探索数据的价值。
爬虫开发不仅是技术活,更是一门需要智慧和耐心的艺术。继续深入学习,你将在这个领域发现更多精彩!
## 扩展学习资源
- **HTTP协议规范**:RFC 7230-7235
- **Python官方文档**:requests、urllib、http.client
- **爬虫框架**:Scrapy、BeautifulSoup、Selenium
- **反爬虫研究**:《Python3反爬虫原理与绕过实战》
- **法律法规**:《网络安全法》、《数据安全法》
- **性能优化**:aiohttp、httpx异步HTTP客户端
- **分布式爬虫**:Scrapy-Redis、PySpider




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











