









【服务器与部署 11】Python应用性能监控实战:从零构建企业级监控告警体系
关键词:Python性能监控、APM、Prometheus、Grafana、告警系统、性能指标、监控架构、运维自动化、系统监控、性能优化
摘要:本文深入探讨Python应用性能监控的完整实施方案,从基础指标收集到企业级监控平台搭建,涵盖四大黄金指标、监控工具选型、告警策略设计等核心内容。通过实战案例和最佳实践,帮助开发者构建可靠、高效的性能监控体系,确保应用稳定运行。
文章目录
一、引言:为什么性能监控如此重要?
想象一下,你的Python应用在凌晨3点突然崩溃,用户投诉电话响个不停,而你却浑然不知。这种情况下,你可能需要花费数小时甚至数天来定位问题,损失的不仅是用户体验,还有公司的声誉和收入。
性能监控就像是应用的"健康体检",它能够:
- 提前发现问题:在用户感知之前识别潜在故障
- 快速定位根因:通过详细指标快速缩小问题范围
- 优化系统性能:基于数据驱动的性能调优
- 保障业务连续性:通过告警机制确保及时响应
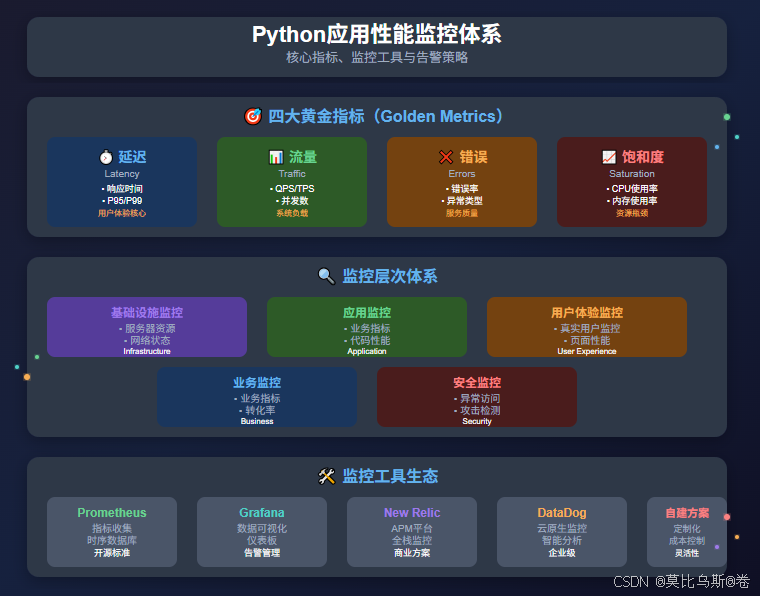
二、四大黄金指标:监控的核心基石
2.1 延迟(Latency)
延迟是用户体验的核心指标,包括:
- 响应时间:从请求发出到收到响应的时间
- P95/P99分位数:95%或99%的请求响应时间
- 平均响应时间:所有请求的平均处理时间
import time
import functools
from collections import defaultdict
class LatencyMonitor:
def __init__(self):
self.metrics = defaultdict(list)
def measure_latency(self, func_name):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = func(*args, **kwargs)
return result
finally:
end_time = time.time()
latency = (end_time - start_time) * 1000 # 毫秒
self.metrics[func_name].append(latency)
return wrapper
return decorator
def get_percentile(self, func_name, percentile):
"""计算指定函数的分位数延迟"""
if func_name not in self.metrics:
return None
latencies = sorted(self.metrics[func_name])
if not latencies:
return None
index = int(len(latencies) * percentile / 100)
return latencies[min(index, len(latencies) - 1)]
# 使用示例
monitor = LatencyMonitor()
@monitor.measure_latency('database_query')
def query_user_data(user_id):
# 模拟数据库查询
time.sleep(0.1)
return f"User {user_id} data"
# 执行一些查询
for i in range(100):
query_user_data(i)
# 获取P95延迟
p95_latency = monitor.get_percentile('database_query', 95)
print(f"P95 延迟: {p95_latency:.2f}ms")
2.2 流量(Traffic)
流量指标反映系统负载情况:
- QPS(每秒查询数):每秒处理的请求数量
- TPS(每秒事务数):每秒完成的事务数量
- 并发用户数:同时在线的用户数量
import threading
import time
from collections import deque
class TrafficMonitor:
def __init__(self, window_size=60):
self.window_size = window_size
self.requests = deque()
self.lock = threading.Lock()
def record_request(self):
"""记录一次请求"""
with self.lock:
current_time = time.time()
self.requests.append(current_time)
# 清理过期数据
cutoff_time = current_time - self.window_size
while self.requests and self.requests[0] < cutoff_time:
self.requests.popleft()
def get_qps(self):
"""获取当前QPS"""
with self.lock:
return len(self.requests) / self.window_size
def get_current_requests(self):
"""获取当前时间窗口内的请求数"""
with self.lock:
return len(self.requests)
# Flask应用集成示例
from flask import Flask, request, g
app = Flask(__name__)
traffic_monitor = TrafficMonitor()
@app.before_request
def before_request():
traffic_monitor.record_request()
g.start_time = time.time()
@app.route('/api/users/<int:user_id>')
def get_user(user_id):
# 模拟业务逻辑
time.sleep(0.05)
return {'user_id': user_id, 'name': f'User {user_id}'}
@app.route('/metrics')
def metrics():
return {
'qps': traffic_monitor.get_qps(),
'current_requests': traffic_monitor.get_current_requests()
}
2.3 错误率(Errors)
错误指标帮助识别系统健康状况:
- HTTP错误率:4xx、5xx状态码比例
- 异常率:应用程序异常发生频率
- 失败率:请求失败的比例
import logging
from collections import defaultdict, Counter
from datetime import datetime, timedelta
class ErrorMonitor:
def __init__(self):
self.error_counts = defaultdict(int)
self.total_requests = 0
self.error_details = []
def record_request(self, status_code, error_type=None, error_message=None):
"""记录请求结果"""
self.total_requests += 1
if status_code >= 400:
self.error_counts[status_code] += 1
self.error_details.append({
'timestamp': datetime.now(),
'status_code': status_code,
'error_type': error_type,
'error_message': error_message
})
def get_error_rate(self):
"""获取总体错误率"""
if self.total_requests == 0:
return 0.0
total_errors = sum(self.error_counts.values())
return (total_errors / self.total_requests) * 100
def get_error_breakdown(self):
"""获取错误类型分布"""
return dict(self.error_counts)
def get_recent_errors(self, minutes=5):
"""获取最近N分钟的错误"""
cutoff_time = datetime.now() - timedelta(minutes=minutes)
return [
error for error in self.error_details
if error['timestamp'] > cutoff_time
]
# 异常装饰器
def monitor_exceptions(error_monitor):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
try:
result = func(*args, **kwargs)
error_monitor.record_request(200) # 成功
return result
except ValueError as e:
error_monitor.record_request(400, 'ValueError', str(e))
raise
except Exception as e:
error_monitor.record_request(500, type(e).__name__, str(e))
raise
return wrapper
return decorator
# 使用示例
error_monitor = ErrorMonitor()
@monitor_exceptions(error_monitor)
def process_data(data):
if not data:
raise ValueError("数据不能为空")
if len(data) > 1000:
raise RuntimeError("数据量过大")
return {"processed": len(data)}
# 模拟一些请求
test_cases = [
[], # 会引发ValueError
list(range(100)), # 正常
list(range(2000)), # 会引发RuntimeError
list(range(50)), # 正常
]
for data in test_cases:
try:
process_data(data)
except:
pass
print(f"错误率: {error_monitor.get_error_rate():.2f}%")
print(f"错误分布: {error_monitor.get_error_breakdown()}")
2.4 饱和度(Saturation)
饱和度指标反映资源使用情况:
- CPU使用率:处理器资源占用
- 内存使用率:内存资源占用
- 磁盘I/O:存储读写负载
- 网络带宽:网络传输负载
import psutil
import time
import threading
class SaturationMonitor:
def __init__(self):
self.metrics = {}
self.monitoring = False
self.monitor_thread = None
def start_monitoring(self, interval=5):
"""开始监控系统资源"""
self.monitoring = True
self.monitor_thread = threading.Thread(target=self._monitor_loop, args=(interval,))
self.monitor_thread.daemon = True
self.monitor_thread.start()
def stop_monitoring(self):
"""停止监控"""
self.monitoring = False
if self.monitor_thread:
self.monitor_thread.join()
def _monitor_loop(self, interval):
"""监控循环"""
while self.monitoring:
self.metrics = {
'cpu_percent': psutil.cpu_percent(interval=1),
'memory_percent': psutil.virtual_memory().percent,
'disk_usage': psutil.disk_usage('/').percent,
'network_io': psutil.net_io_counters()._asdict(),
'timestamp': time.time()
}
time.sleep(interval)
def get_current_metrics(self):
"""获取当前指标"""
return self.metrics.copy()
def check_saturation_alerts(self):
"""检查饱和度告警"""
alerts = []
if self.metrics.get('cpu_percent', 0) > 80:
alerts.append(f"CPU使用率过高: {self.metrics['cpu_percent']:.1f}%")
if self.metrics.get('memory_percent', 0) > 85:
alerts.append(f"内存使用率过高: {self.metrics['memory_percent']:.1f}%")
if self.metrics.get('disk_usage', 0) > 90:
alerts.append(f"磁盘使用率过高: {self.metrics['disk_usage']:.1f}%")
return alerts
# 使用示例
saturation_monitor = SaturationMonitor()
saturation_monitor.start_monitoring(interval=2)
try:
# 模拟运行一段时间
time.sleep(10)
# 检查当前指标
current_metrics = saturation_monitor.get_current_metrics()
print("当前系统指标:")
print(f"CPU: {current_metrics.get('cpu_percent', 0):.1f}%")
print(f"内存: {current_metrics.get('memory_percent', 0):.1f}%")
print(f"磁盘: {current_metrics.get('disk_usage', 0):.1f}%")
# 检查告警
alerts = saturation_monitor.check_saturation_alerts()
if alerts:
print("⚠️ 饱和度告警:")
for alert in alerts:
print(f" - {alert}")
else:
print("✅ 系统资源使用正常")
finally:
saturation_monitor.stop_monitoring()
三、监控工具选型与架构设计
3.1 开源监控方案:Prometheus + Grafana
这是目前最流行的开源监控方案,具有以下优势:
- Prometheus:强大的时序数据库和指标收集系统
- Grafana:灵活的可视化平台
- AlertManager:智能告警管理
# prometheus_client集成示例
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import time
import random
# 定义指标
REQUEST_COUNT = Counter('http_requests_total', 'Total HTTP requests', ['method', 'endpoint'])
REQUEST_LATENCY = Histogram('http_request_duration_seconds', 'HTTP request latency')
ACTIVE_CONNECTIONS = Gauge('active_connections', 'Number of active connections')
class PrometheusMonitor:
def __init__(self):
self.active_connections = 0
def record_request(self, method, endpoint, latency):
"""记录请求指标"""
REQUEST_COUNT.labels(method=method, endpoint=endpoint).inc()
REQUEST_LATENCY.observe(latency)
def set_active_connections(self, count):
"""设置活跃连接数"""
self.active_connections = count
ACTIVE_CONNECTIONS.set(count)
def start_metrics_server(self, port=8000):
"""启动指标服务器"""
start_http_server(port)
print(f"Prometheus metrics server started on port {port}")
# Flask应用集成
from flask import Flask, request, g
app = Flask(__name__)
prometheus_monitor = PrometheusMonitor()
@app.before_request
def before_request():
g.start_time = time.time()
prometheus_monitor.set_active_connections(
prometheus_monitor.active_connections + 1
)
@app.after_request
def after_request(response):
latency = time.time() - g.start_time
prometheus_monitor.record_request(
method=request.method,
endpoint=request.endpoint or 'unknown',
latency=latency
)
prometheus_monitor.set_active_connections(
prometheus_monitor.active_connections - 1
)
return response
@app.route('/api/users')
def get_users():
# 模拟业务逻辑
time.sleep(random.uniform(0.01, 0.1))
return {'users': [{'id': i, 'name': f'User {i}'} for i in range(10)]}
@app.route('/health')
def health_check():
return {'status': 'healthy', 'timestamp': time.time()}
if __name__ == '__main__':
# 启动指标服务器
prometheus_monitor.start_metrics_server(8000)
# 启动Flask应用
app.run(host='0.0.0.0', port=5000)
3.2 商业监控方案:New Relic / DataDog
商业方案提供更完整的开箱即用体验:
# New Relic集成示例
import newrelic.agent
# 应用初始化
newrelic.agent.initialize('newrelic.ini')
@newrelic.agent.function_trace()
def database_query(query):
"""被监控的数据库查询函数"""
# 模拟数据库查询
time.sleep(0.05)
return f"Query result for: {query}"
@newrelic.agent.background_task()
def process_background_job(job_data):
"""后台任务监控"""
# 模拟后台处理
time.sleep(1)
return f"Processed job: {job_data}"
# 自定义指标
def record_custom_metric(metric_name, value):
"""记录自定义指标"""
newrelic.agent.record_custom_metric(metric_name, value)
# 错误追踪
def handle_error(error):
"""错误处理和追踪"""
newrelic.agent.record_exception()
# 其他错误处理逻辑
四、告警策略设计
4.1 告警规则设计
import json
import smtplib
from email.mime.text import MIMEText
from datetime import datetime, timedelta
from dataclasses import dataclass
from typing import List, Dict, Any
from enum import Enum
class AlertSeverity(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
@dataclass
class AlertRule:
name: str
metric: str
operator: str # '>', '<', '>=', '<=', '=='
threshold: float
duration: int # 持续时间(秒)
severity: AlertSeverity
description: str
@dataclass
class Alert:
rule_name: str
severity: AlertSeverity
message: str
timestamp: datetime
resolved: bool = False
resolution_time: datetime = None
class AlertManager:
def __init__(self):
self.rules: List[AlertRule] = []
self.active_alerts: List[Alert] = []
self.alert_history: List[Alert] = []
self.notification_channels = {}
def add_rule(self, rule: AlertRule):
"""添加告警规则"""
self.rules.append(rule)
def add_notification_channel(self, name: str, channel):
"""添加通知渠道"""
self.notification_channels[name] = channel
def evaluate_rules(self, metrics: Dict[str, Any]):
"""评估告警规则"""
new_alerts = []
for rule in self.rules:
if rule.metric not in metrics:
continue
current_value = metrics[rule.metric]
# 评估条件
if self._evaluate_condition(current_value, rule.operator, rule.threshold):
# 检查是否已有相同告警
existing_alert = self._find_active_alert(rule.name)
if not existing_alert:
alert = Alert(
rule_name=rule.name,
severity=rule.severity,
message=f"{rule.description} - 当前值: {current_value}, 阈值: {rule.threshold}",
timestamp=datetime.now()
)
new_alerts.append(alert)
self.active_alerts.append(alert)
# 发送新告警
for alert in new_alerts:
self._send_alert(alert)
return new_alerts
def _evaluate_condition(self, value, operator, threshold):
"""评估条件"""
if operator == '>':
return value > threshold
elif operator == '<':
return value < threshold
elif operator == '>=':
return value >= threshold
elif operator == '<=':
return value <= threshold
elif operator == '==':
return value == threshold
return False
def _find_active_alert(self, rule_name):
"""查找活跃告警"""
for alert in self.active_alerts:
if alert.rule_name == rule_name and not alert.resolved:
return alert
return None
def _send_alert(self, alert: Alert):
"""发送告警"""
print(f"🚨 告警: {alert.message}")
# 根据严重程度选择通知渠道
if alert.severity == AlertSeverity.CRITICAL:
self._send_to_all_channels(alert)
elif alert.severity == AlertSeverity.HIGH:
self._send_email(alert)
self._send_slack(alert)
else:
self._send_slack(alert)
def _send_to_all_channels(self, alert: Alert):
"""发送到所有渠道"""
for channel_name, channel in self.notification_channels.items():
try:
channel.send(alert)
except Exception as e:
print(f"发送到 {channel_name} 失败: {e}")
def _send_email(self, alert: Alert):
"""发送邮件告警"""
# 邮件发送逻辑
pass
def _send_slack(self, alert: Alert):
"""发送Slack告警"""
# Slack发送逻辑
pass
def resolve_alert(self, rule_name: str):
"""解决告警"""
for alert in self.active_alerts:
if alert.rule_name == rule_name and not alert.resolved:
alert.resolved = True
alert.resolution_time = datetime.now()
self.alert_history.append(alert)
print(f"✅ 告警已解决: {alert.message}")
break
# 使用示例
alert_manager = AlertManager()
# 添加告警规则
alert_manager.add_rule(AlertRule(
name="high_cpu_usage",
metric="cpu_percent",
operator=">",
threshold=80.0,
duration=300, # 5分钟
severity=AlertSeverity.HIGH,
description="CPU使用率过高"
))
alert_manager.add_rule(AlertRule(
name="high_error_rate",
metric="error_rate",
operator=">",
threshold=5.0,
duration=60, # 1分钟
severity=AlertSeverity.CRITICAL,
description="错误率过高"
))
alert_manager.add_rule(AlertRule(
name="low_disk_space",
metric="disk_usage",
operator=">",
threshold=90.0,
duration=600, # 10分钟
severity=AlertSeverity.MEDIUM,
description="磁盘空间不足"
))
# 模拟指标数据
test_metrics = {
'cpu_percent': 85.0,
'error_rate': 2.5,
'disk_usage': 95.0,
'memory_percent': 70.0
}
# 评估告警
alerts = alert_manager.evaluate_rules(test_metrics)
print(f"触发了 {len(alerts)} 个告警")
4.2 告警收敛与抑制
import time
from collections import defaultdict
class AlertSuppression:
def __init__(self):
self.suppression_rules = {}
self.alert_counts = defaultdict(int)
self.last_alert_time = defaultdict(float)
def add_suppression_rule(self, rule_name, max_alerts_per_hour=10, silence_duration=300):
"""添加抑制规则"""
self.suppression_rules[rule_name] = {
'max_alerts_per_hour': max_alerts_per_hour,
'silence_duration': silence_duration
}
def should_suppress_alert(self, rule_name):
"""判断是否应该抑制告警"""
if rule_name not in self.suppression_rules:
return False
current_time = time.time()
rule = self.suppression_rules[rule_name]
# 检查静默期
if rule_name in self.last_alert_time:
time_since_last = current_time - self.last_alert_time[rule_name]
if time_since_last < rule['silence_duration']:
return True
# 检查频率限制
hour_ago = current_time - 3600
# 这里简化处理,实际应该维护时间窗口
if self.alert_counts[rule_name] >= rule['max_alerts_per_hour']:
return True
return False
def record_alert(self, rule_name):
"""记录告警发送"""
self.alert_counts[rule_name] += 1
self.last_alert_time[rule_name] = time.time()
# 集成到AlertManager
class EnhancedAlertManager(AlertManager):
def __init__(self):
super().__init__()
self.suppression = AlertSuppression()
def _send_alert(self, alert: Alert):
"""发送告警(带抑制逻辑)"""
if self.suppression.should_suppress_alert(alert.rule_name):
print(f"⏸️ 告警被抑制: {alert.rule_name}")
return
super()._send_alert(alert)
self.suppression.record_alert(alert.rule_name)
五、实战案例:Django应用监控
5.1 完整的Django监控集成
# monitoring/middleware.py
import time
import logging
from django.utils.deprecation import MiddlewareMixin
from prometheus_client import Counter, Histogram, Gauge
# Prometheus指标
REQUEST_COUNT = Counter('django_requests_total', 'Total requests', ['method', 'endpoint', 'status'])
REQUEST_LATENCY = Histogram('django_request_duration_seconds', 'Request latency')
ACTIVE_REQUESTS = Gauge('django_active_requests', 'Active requests')
class MonitoringMiddleware(MiddlewareMixin):
def __init__(self, get_response):
self.get_response = get_response
super().__init__(get_response)
def process_request(self, request):
request.start_time = time.time()
ACTIVE_REQUESTS.inc()
def process_response(self, request, response):
# 计算请求时间
if hasattr(request, 'start_time'):
duration = time.time() - request.start_time
REQUEST_LATENCY.observe(duration)
# 记录请求指标
REQUEST_COUNT.labels(
method=request.method,
endpoint=request.resolver_match.url_name if request.resolver_match else 'unknown',
status=response.status_code
).inc()
ACTIVE_REQUESTS.dec()
return response
def process_exception(self, request, exception):
ACTIVE_REQUESTS.dec()
logging.error(f"Request exception: {exception}", exc_info=True)
# monitoring/views.py
from django.http import JsonResponse
from prometheus_client import generate_latest, CONTENT_TYPE_LATEST
from django.http import HttpResponse
def metrics_view(request):
"""Prometheus指标端点"""
return HttpResponse(generate_latest(), content_type=CONTENT_TYPE_LATEST)
def health_check(request):
"""健康检查端点"""
return JsonResponse({
'status': 'healthy',
'timestamp': time.time(),
'version': '1.0.0'
})
# monitoring/management/commands/start_monitoring.py
from django.core.management.base import BaseCommand
from monitoring.monitors import start_system_monitoring
class Command(BaseCommand):
help = 'Start system monitoring'
def handle(self, *args, **options):
start_system_monitoring()
self.stdout.write(self.style.SUCCESS('System monitoring started'))
5.2 数据库查询监控
# monitoring/db_monitor.py
import time
import logging
from django.db import connection
from contextlib import contextmanager
class DatabaseMonitor:
def __init__(self):
self.slow_query_threshold = 1.0 # 1秒
self.query_count = 0
self.total_time = 0
@contextmanager
def monitor_query(self, query):
start_time = time.time()
try:
yield
finally:
duration = time.time() - start_time
self.query_count += 1
self.total_time += duration
if duration > self.slow_query_threshold:
logging.warning(f"慢查询检测: {duration:.3f}s - {query[:100]}...")
def get_stats(self):
return {
'query_count': self.query_count,
'total_time': self.total_time,
'avg_time': self.total_time / max(self.query_count, 1)
}
# 在Django中使用
from django.db.models.signals import post_save, post_delete
from django.dispatch import receiver
db_monitor = DatabaseMonitor()
@receiver(post_save)
def monitor_save(sender, **kwargs):
# 监控模型保存操作
pass
@receiver(post_delete)
def monitor_delete(sender, **kwargs):
# 监控模型删除操作
pass
六、最佳实践与常见问题
6.1 监控最佳实践
-
分层监控:
- 基础设施层:服务器、网络、存储
- 应用层:业务逻辑、API性能
- 用户体验层:页面加载、交互响应
-
指标选择:
- 选择有意义的指标
- 避免指标过载
- 关注业务关键指标
-
告警设计:
- 合理设置阈值
- 避免告警风暴
- 分级告警处理
6.2 常见问题解决
# 问题1: 指标数据过多导致存储压力
class MetricsAggregator:
def __init__(self, aggregation_interval=60):
self.aggregation_interval = aggregation_interval
self.raw_metrics = []
self.aggregated_metrics = []
def add_metric(self, metric_name, value, timestamp):
self.raw_metrics.append({
'name': metric_name,
'value': value,
'timestamp': timestamp
})
def aggregate_metrics(self):
"""聚合指标数据"""
# 按时间窗口聚合
aggregated = {}
for metric in self.raw_metrics:
window = metric['timestamp'] // self.aggregation_interval
key = (metric['name'], window)
if key not in aggregated:
aggregated[key] = []
aggregated[key].append(metric['value'])
# 计算统计值
for (name, window), values in aggregated.items():
self.aggregated_metrics.append({
'name': name,
'window': window,
'avg': sum(values) / len(values),
'max': max(values),
'min': min(values),
'count': len(values)
})
# 清理原始数据
self.raw_metrics.clear()
# 问题2: 监控系统本身的性能影响
class LightweightMonitor:
def __init__(self, sampling_rate=0.1):
self.sampling_rate = sampling_rate
self.metrics_buffer = []
self.buffer_size = 1000
def record_metric(self, name, value):
"""轻量级指标记录"""
if random.random() < self.sampling_rate:
self.metrics_buffer.append({
'name': name,
'value': value,
'timestamp': time.time()
})
# 批量发送
if len(self.metrics_buffer) >= self.buffer_size:
self._flush_metrics()
def _flush_metrics(self):
"""批量发送指标"""
# 异步发送指标数据
threading.Thread(target=self._send_metrics, args=(self.metrics_buffer.copy(),)).start()
self.metrics_buffer.clear()
def _send_metrics(self, metrics):
"""发送指标数据"""
# 实际发送逻辑
pass
七、总结与展望
性能监控是保障Python应用稳定运行的关键基础设施。通过本文的深入探讨,我们了解了:
- 四大黄金指标:延迟、流量、错误率、饱和度是监控的核心
- 监控工具选型:开源方案vs商业方案的权衡
- 告警策略设计:智能告警避免噪音干扰
- 实战案例:Django应用的完整监控方案
7.1 未来发展趋势
-
AI驱动的监控:
- 异常检测算法
- 预测性告警
- 自动根因分析
-
云原生监控:
- 容器化应用监控
- 服务网格可观测性
- 分布式追踪
-
业务监控融合:
- 技术指标与业务指标结合
- 用户体验监控
- 实时业务洞察
7.2 实施建议
- 循序渐进:从基础指标开始,逐步完善监控体系
- 重点突出:关注核心业务指标和关键用户路径
- 持续优化:根据实际运行情况调整监控策略
- 团队协作:建立监控文化,全员参与监控体系建设
通过构建完善的性能监控体系,我们能够:
- 提前发现和解决问题
- 持续优化应用性能
- 保障用户体验
- 支撑业务快速发展
记住,监控不是目的,而是手段。最终目标是构建稳定、可靠、高性能的Python应用系统。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











